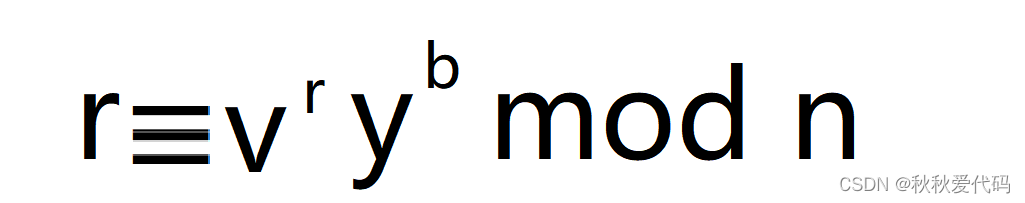1. 数据集准备(Data preparation)
进入wespeaker目录文件/home/username/wespeaker/examples/voxceleb/v2
对run.sh文件进行编辑
vim run.sh可以看到run.sh里面的配置内容
#数据集下载,解压
stage=1
#插入噪音,制作音频文件
stop_stage=2
#数据集放置的源目录,这里要求数据集放在run.sh所在目录下data/download_data文件夹中
data=data
#shard格式
data_type="shard" # shard/raw在运行run.sh 时的起始stage 和结束stage,默认两个都设置为-1
- stage 1&2 是数据集的处理、目录制作,
- stage 3 模型训练,
- stage 4 用训练的模型提取embedding,
- stage 5 计算余弦相似度、EER、minDCF,
- stage 6 将上一步计算结果归一化,
- stage 7 导出模型,
- stage 8 对模型做fine-tune。
shard格式:raw 格式的音频未经过分片、拆分,就是原本下载解压后的文件,训练时只能逐个读取音频,适用于数据集较小时;shard 将会把音频打包成若干个分片,每个分片包含了多个音频,在模型训练读数据时每次能读入一批数据,减少了磁盘IO 次数,但是将音频打包成分卷,占
据更大的存储空间,当数据集较大时利用shard 格式能显著提高训练速度。
1.1 run.sh stage 1处理
if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; thenecho "Prepare datasets ..."
#这里传入参数stage=2,stop_stage=4,与run.sh中的stage无关./local/prepare_data.sh --stage 2 --stop_stage 4 --data ${data}
fi
这里如果stage = 1,则会执行./local/prepare_data.sh 并传入参数 stage =2 , stop_stage =4,这里的stage与run.sh中的stage 无关。
在prepare_data.sh文件中
- stage 1: 下载数据包,合并分包并做md5校验
- stage 2: 解压数据包,放在指定目录下
- stage 3: Convert voxceleb2 wav format from m4a to wav using ffmpeg.
- stage 4: Prepare wav.scp for each dataset
./local/prepare_data.sh文件
data=`realpath ${data}`
download_dir=${data}/download_data
rawdata_dir=${data}/raw_data# stage 1主要是下载文件,包括musan.tar.gz, rirs_noises.zip, vox1_test_wav.zip vox1_dev_wav.zip, and vox2_aac.zip
if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; thenecho "Download musan.tar.gz, rirs_noises.zip, vox1_test_wav.zip, vox1_dev_wav.zip, and vox2_aac.zip."echo "This may take a long time. Thus we recommand you to download all archives above in your own way first."./local/download_data.sh --download_dir ${download_dir}
fi可以看到在prepare_data.sh文件中,输入的stage =1,则执行download_data.sh文件。
./local/download_data.sh中下载vox2_dev_acc分卷为例
if [ ! -f ${download_dir}/vox2_aac.zip ]; thenecho "Downloading vox2_aac.zip ..."for part in a b c d e f g h; do
#下载分卷wget --no-check-certificate https://thor.robots.ox.ac.uk/~vgg/data/voxceleb/vox1a/vox2_dev_aac_parta${part} -P ${download_dir} &donewait
#合并分卷cat ${download_dir}/vox2_dev_aac* >${download_dir}/vox2_aac.zip
#md5校验md5=$(md5sum ${download_dir}/vox2_aac.zip | awk '{print $1}')[ $md5 != "bbc063c46078a602ca71605645c2a402" ] && echo "Wrong md5sum of vox2_aac.zip" && exit 1
fi
注意:这里如果已经自己下载分卷,则在命令行单独对分卷进行合并,以及md5校验,无需下载数据包。
修改过无需下载的./local/download_data.sh版本如下:
download_dir=data/download_data#. tools/parse_options.sh || exit 1[ ! -d ${download_dir} ] && mkdir -p ${download_dir}#if [ ! -f ${download_dir}/musan.tar.gz ]; thenecho "Downloading musan.tar.gz ..."
# wget --no-check-certificate https://openslr.elda.org/resources/17/musan.tar.gz -P ${download_dir}md5=$(md5sum ${download_dir}/musan.tar.gz | awk '{print $1}')[ $md5 != "0c472d4fc0c5141eca47ad1ffeb2a7df" ] && echo "Wrong md5sum of musan.tar.gz" && exit 1
#fi#if [ ! -f ${download_dir}/rirs_noises.zip ]; thenecho "Downloading rirs_noises.zip ..."
# wget --no-check-certificate https://us.openslr.org/resources/28/rirs_noises.zip -P ${download_dir}md5=$(md5sum ${download_dir}/rirs_noises.zip | awk '{print $1}')[ $md5 != "e6f48e257286e05de56413b4779d8ffb" ] && echo "Wrong md5sum of rirs_noises.zip" && exit 1
#fi#if [ ! -f ${download_dir}/vox1_test_wav.zip ]; thenecho "Downloading vox1_test_wav.zip ..."
# wget --no-check-certificate https://thor.robots.ox.ac.uk/~vgg/data/voxceleb/vox1a/vox1_test_wav.zip -P ${download_dir}md5=$(md5sum ${download_dir}/vox1_test_wav.zip | awk '{print $1}')[ $md5 != "185fdc63c3c739954633d50379a3d102" ] && echo "Wrong md5sum of vox1_test_wav.zip" && exit 1
#fi#if [ ! -f ${download_dir}/vox1_dev_wav.zip ]; thenecho "Downloading vox1_dev_wav.zip ..."
# for part in a b c d; do
# wget --no-check-certificate https://thor.robots.ox.ac.uk/~vgg/data/voxceleb/vox1a/vox1_dev_wav_parta${part} -P ${download_dir} &
# done
# waitcat ${download_dir}/vox1_dev* >${download_dir}/vox1_dev_wav.zipmd5=$(md5sum ${download_dir}/vox1_dev_wav.zip | awk '{print $1}')[ $md5 != "ae63e55b951748cc486645f532ba230b" ] && echo "Wrong md5sum of vox1_dev_wav.zip" && exit 1
#fi#if [ ! -f ${download_dir}/vox2_aac.zip ]; thenecho "Downloading vox2_aac.zip ..."
# for part in a b c d e f g h; do
# wget --no-check-certificate https://thor.robots.ox.ac.uk/~vgg/data/voxceleb/vox1a/vox2_dev_aac_parta${part} -P ${download_dir} &
# done
# waitcat ${download_dir}/vox2_dev_aac* >${download_dir}/vox2_aac.zipmd5=$(md5sum ${download_dir}/vox2_aac.zip | awk '{print $1}')[ $md5 != "bbc063c46078a602ca71605645c2a402" ] && echo "Wrong md5sum of vox2_aac.zip" && exit 1
#fiecho "Download success !!!"


注:在手动Cat分卷合并过程中,需要注意空格,如cat vox2_dev_aac* > vox2_aac.zip,“>”号前后需要有空格保留。
1.2 run.sh运行
在运行前需要安装ffmpeg和lmdb安装包。
ffmpeg安装
wget http://www.tortall.net/projects/yasm/releases/yasm-1.3.0.tar.gztar zxvf yasm-1.3.0.tar.gzcd yasm-1.3.0./configuremake && make installwget http://www.ffmpeg.org/releases/ffmpeg-3.4.4.tar.gztar -zxvf ffmpeg-3.4.4.tar.gzcd ./ffmpeg-3.4.4./configure --enable-ffplay --enable-ffservermake && make install安装完成,使用以下命令查看
ffmpeg --version设置run.sh 起始stage 和结束stage分别为1和2;
# run.shstage=1
stop_stage=2
bash run.sh程序自动运行以下步骤:
(1) prepare_data.sh—stage 2 解压数据集
对上述的VoxCeleb1 和2、RIRS_NOISES 和MUSAN 噪声集分别做解压,prepare_data.sh
的stage 2 在download_data/所在目录data/下新建一个rawdata_dir/文件夹,然后解压到该目
录。
(2) prepare_data.sh—stage 3 Convert voxceleb2 wav format from m4a to wav using ffmpeg
(3) prepare_data.sh—stage 4 制作音频数据集索引
为每个数据集准备wav.scp,其在data/目录下新建musan、rirs、voxceleb_train、eval 四个
文件夹,然后在各个文件夹内生成wav.scp。其中voxCeleb 数据集还有两个额外目录utt2spk、
spk2utt,分别是音频对应说话人的目录索引,以及说话人对应音频的索引。
在eval/中生成enroll.map,并在trails 文件夹生成两种测试方法的测试集。
(4) make_shard_list.py—转换为shard 分卷格式
调用tools/make_shard_list.py 生成shard 分片,同时生成shard 对应的list
– num_utts_per_shard 每个shard 分卷有多少条音频
– num_threads 运行线程数
– prefix shards 分片文件前缀为”shards”
– shuffle 生成分片前对进行数据洗切,打乱顺序
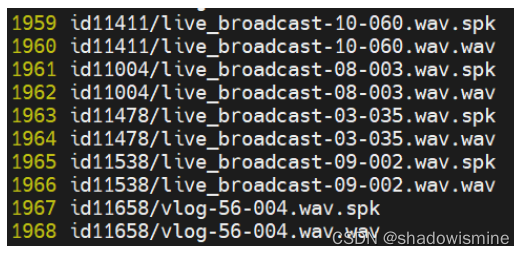
转换完成后可以查看训练集的shard 目录,其内容如下:

其中每个tar 都是一个类似压缩包的包含了多个音频的文件,vim 之后可以看到它是一个包
含原始文件的音频目录:
(5)make_raw_list.py—转换为raw 格式
make_raw 不对原本的wav.scp 做变化,其raw 类型数据依然是逐条读取,不存在分卷,在
训练时只需调用它的输出索引raw.list
(6)将噪声数据转换为LMDB 格式
LMDB(Lightning Memory-Mapped Database)是一种高性能、低延迟、内存映射键值数据库。
它被广泛应用于存储大规模数据集,特别适用于需要高效读取和写入的场景。
调用tools/make_lmdb.py,输入两个噪声集的wav.scp 目录,输出LMDB 格式的数据库文
件。通过将噪声数据集封装成LMDB 格式提高存取速度。