文章目录
- Problems
- 403
- 代码文件
- LLaMA: Open and Efficient Foundation Language Models
- 方法
- 预训练数据
- 结构
- 优化器
- 一些加速的方法
- 结果
- Common Sense Reasoning
- Closed-book Question Answering
- Reading Comprehension
- Massive Multitask Language Understanding
- Instruction Finetuning
- 附录
- Question Answering
- Generations from LLaMA-65B
- Generations from LLaMA-I
- Llama 2: Open Foundation and Fine-Tuned Chat Models
- pretraining methodology
- Pretraining Data
- Training Details
- fine-tuning methodology
- Supervised Fine-Tuning(SFT)
- Reinforcement Learning with Human Feedback (RLHF)
Problems
403
reclone and request.
代码文件
两个测试样例:
example_text_completion.py: 文本补全示例;example_chat_completion.py: 对话生成示例.
torchrun --nproc_per_node 1 example_text_completion.py \--ckpt_dir llama-2-7b/ \--tokenizer_path tokenizer.model \--max_seq_len 128 --max_batch_size 4
torchrun --nproc_per_node 1 example_chat_completion.py \--ckpt_dir llama-2-7b-chat/ \--tokenizer_path tokenizer.model \--max_seq_len 512 --max_batch_size 6
ckpt_dir: 模型文件路径
tokenizer_path: 分词器文件路径
对于示例一, prompt中提供了需要补全的文本.
对于示例二, prompt以字典形式组织对话. 每个item包含role和content两个关键字.
role:user: 用户, 用以输入文本;role:assistant: 系统, 用以输出文本;role:system: 对系统生成对话的要求;
LLaMA: Open and Efficient Foundation Language Models
发展:
scale models -> scale data -> fast inference and scale tokens
本文的要点:
通过在更多的token上训练, 使得在不同推理开销下, 达到最佳的性能.
方法
LLaMA采用Auto Regression的方式进行预训练.
预训练数据
公开数据.

tokenizer的方法为: bytepair encoding(BPE). 总共包含1.4T个tokens.
结构
采用了之前一些被证明可行的方法:
- RMSNorm from GPT3;
- SwiGLU from PaLM;
- RoPE from GPTNeo.
优化器
- AdamW ( β 1 = 0.9 , β 2 = 0.95 , w e i g h t d e c a y = 0.1 \beta_1=0.9, \beta_2=0.95, weight~decay=0.1 β1=0.9,β2=0.95,weight decay=0.1);
- warmup 2000 step and cosine learning rate schedule;
- gradient clippping = 1.0;
一些加速的方法
- causal multi-head attention;
- reduce the amount of activations that recomputed during the backward pass.
2048块80G的A100训练21天.
结果
Common Sense Reasoning
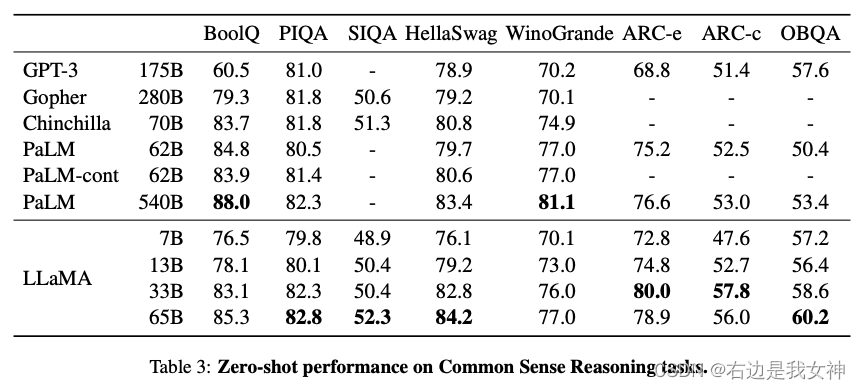
zero-shot.
CSR : 基于问题和常识性选择, 让模型做出判断.

Closed-book Question Answering


不依赖于外部信息源, 只凭借训练时学习得到的信息完成问答任务.
自由文本的评估指标. exact match perfromance
Reading Comprehension


Massive Multitask Language Understanding
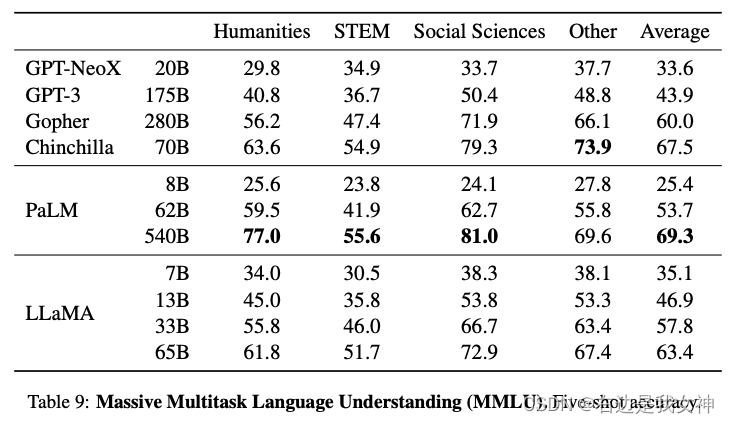

Mathematical reasoning 和 Code Generation就不再赘述.
Instruction Finetuning
待补充
附录
Question Answering

对于Natural Questions 和 TriviaQA 使用1-shot设定. 预先打印字符串:Answer these questions:\n在问题和答案之前.
Generations from LLaMA-65B
Without instruction finetuning.
Prompts are in bold.
Only present part of them.


Generations from LLaMA-I

Llama 2: Open Foundation and Fine-Tuned Chat Models
LLAMA2 : 新的训练数据组织形式, 更大的预训练语料库, 更长的上下文, grouped-query attention.
LLAMA2 : 针对对话场景的微调版本.
pretraining methodology
Pretraining Data
- a new mix of data , not including data from Meta’s products or services;
- 移除包含私人信息的数据;
- 2 trillion tokens and up-sampling the most factual sources.
Training Details
除了RMSNorm, RoPE and SwiGLU, 增加了GQA.
其余与LLaMA 1一致.
fine-tuning methodology
Supervised Fine-Tuning(SFT)
使用公开的instruction tuning data.
提取高质量的部分数据, 模型的效果仍然得到提升. Quality is All You Need.
发现人类写的注释和模型生成+人工检查的注释效果差不多.
微调细节:
- cosine learning rate schedule;
- initial lr = 2e-5;
- weight decay = 0.1;
- batch size = 64;
- sequence length = 4096.
Reinforcement Learning with Human Feedback (RLHF)
人类从模型的两个输出中选择喜欢的一个. 该反馈随后用于训练一个奖励模型. 该模型学习人类的偏好模式.