一般实际调优的情况就不需要去考虑mysql数据库结构或者命名优化那些。做这些优化是大动作,也不是咱们一般人去接触到的。
所以我们针对mysql的调优其实大部分还是针对索引进行优化。
我们刚接触这个表的话可以先查询当前表中所有的索引
使用
SHOW INDEX FROM yourtable;
然后了解完索引之后,去测试之前反映时间很长的sql语句,看看是索引失效还是没走索引,或者没设置索引。
或者直接使用慢日志定位效率比较低的sql语句
慢日志:
具体环境中,运行时间超过long_query_time值的SQL语句,则会被记录到慢查询日志中。
long_query_time的默认值为10,意思是记录运行10秒以上的语句。
默认情况下,MySQL数据库并不启动慢查询日志,需要手动来设置这个参数。
当然,如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志会或多或少带来一定的性能影响。
慢查询日志支持将日志记录写入文件和数据库表。
-
slow_query_log 是否开启慢查询日志 开启: set global slow_query_log = 1;
-
slow_query_log_file 指定慢查询日志的存储路径及文件(默认和数据文件放一起)
-
long_query_time 指定记录慢查询日志SQL执行时间得阈值(单位:秒,默认10秒) 如果你是处于学习阶段,想要自己看看慢查询日志,可以将阈值设置为0: set global long_query_time=0;
-
log_queries_not_using_indexes 是否记录未使用索引的SQL
优化sql之前先用Explain查询sql的执行计划
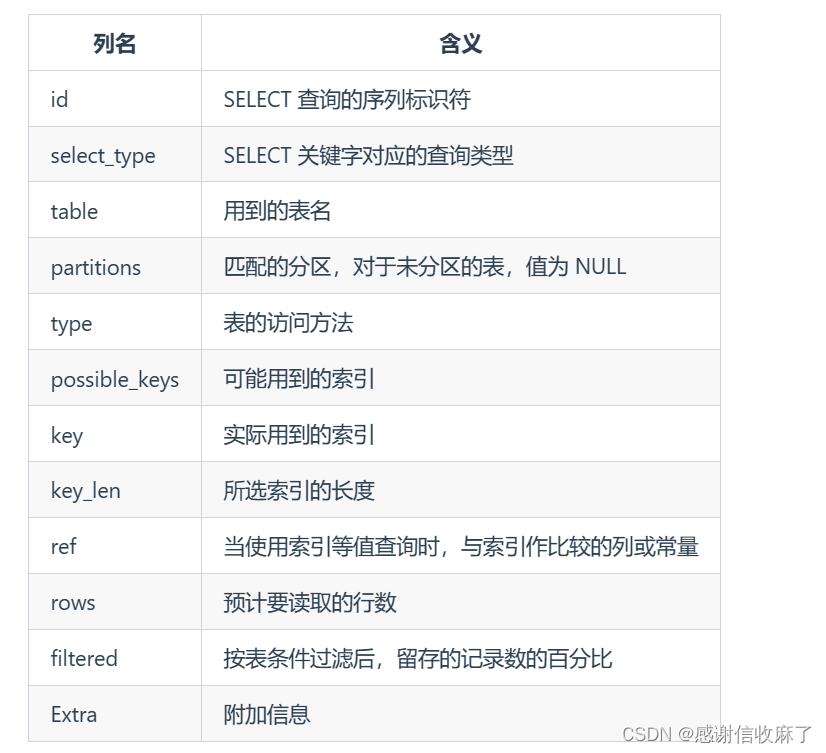
Explain sql语句mysql> explain SELECT * FROM dept_emp WHERE emp_no IN (SELECT emp_no FROM dept_emp GROUP BY emp_no HAVING COUNT(emp_no)>1);
+----+-------------+----------+------------+-------+-----------------+---------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+-------+-----------------+---------+---------+------+--------+----------+-------------+
| 1 | PRIMARY | dept_emp | NULL | ALL | NULL | NULL | NULL | NULL | 331143 | 100.00 | Using where |
| 2 | SUBQUERY | dept_emp | NULL | index | PRIMARY,dept_no | PRIMARY | 16 | NULL | 331143 | 100.00 | Using index |
+----+-------------+----------+------------+-------+-----------------+---------+---------+------+--------+----------+-------------+
一些常见的索引失效的原因
- 创建了组合索引,但查询条件未遵守最左匹配原则;
- 在索引列上进行计算、函数、类型转换等操作;
- 以
%开头的 LIKE 查询比如like '%abc'; - 查询条件中使用 or,且 or 的前后条件中有一个列没有索引,涉及的索引都不会被使用到;
- 发生隐式转换;
- 等等
尽量避免这些情况的发生,同时我们也要控制索引的数量,尽量用联合索引
确定问题并采用相应的措施
- 优化索引
- 优化SQL语句:修改SQL、IN 查询分段、时间查询分段、基于上一次数据过滤
- 改用其他实现方式:ES、数仓等
- 数据碎片处理
场景分析
案例1、最左匹配
索引
KEY `idx_shopid_orderno` (`shop_id`,`order_no`)SQL语句
select * from _t where orderno=''查询匹配从左往右匹配,要使用order_no走索引,必须查询条件携带shop_id或者索引(shop_id,order_no)调换前后顺序
案例2、隐式转换
索引
KEY `idx_mobile` (`mobile`)SQL语句
select * from _user where mobile=12345678901隐式转换相当于在索引上做运算,会让索引失效。mobile是字符类型,使用了数字,应该使用字符串匹配,否则MySQL会用到隐式替换,导致索引失效。
案例3、大分页
索引
KEY `idx_a_b_c` (`a`, `b`, `c`)SQL语句
select * from _t where a = 1 and b = 2 order by c desc limit 10000, 10;对于大分页的场景,可以优先让产品优化需求,如果没有优化的,有如下两种优化方式,
一种是把上一次的最后一条数据,也即上面的c传过来,然后做“c < xxx”处理,但是这种一般需要改接口协议,并不一定可行。
另一种是采用延迟关联的方式进行处理,减少SQL回表,但是要记得索引需要完全覆盖才有效果,SQL改动如下
select t1.* from _t t1, (select id from _t where a = 1 and b = 2 order by c desc limit 10000, 10) t2 where t1.id = t2.id;案例4、in + order by
索引
KEY `idx_shopid_status_created` (`shop_id`, `order_status`, `created_at`)SQL语句
select * from _order where shop_id = 1 and order_status in (1, 2, 3) order by created_at desc limit 10in查询在MySQL底层是通过n*m的方式去搜索,类似union,但是效率比union高。
in查询在进行cost代价计算时(代价 = 元组数 * IO平均值),是通过将in包含的数值,一条条去查询获取元组数的,因此这个计算过程会比较的慢,所以MySQL设置了个临界值(eq_range_index_dive_limit),5.6之后超过这个临界值后该列的cost就不参与计算了。因此会导致执行计划选择不准确。默认是200,即in条件超过了200个数据,会导致in的代价计算存在问题,可能会导致Mysql选择的索引不准确。
处理方式,可以(order_status, created_at)互换前后顺序,并且调整SQL为延迟关联。
案例5、范围查询阻断,后续字段不能走索引
索引
KEY `idx_shopid_created_status` (`shop_id`, `created_at`, `order_status`)SQL语句
select * from _order where shop_id = 1 and created_at > '2021-01-01 00:00:00' and order_status = 10范围查询还有“IN、between”
案例6、不等于、不包含不能用到索引的快速搜索。(可以用到ICP)
select * from _order where shop_id=1 and order_status not in (1,2)
select * from _order where shop_id=1 and order_status != 1在索引上,避免使用NOT、!=、<>、!<、!>、NOT EXISTS、NOT IN、NOT LIKE等
案例7、优化器选择不使用索引的情况
如果要求访问的数据量很小,则优化器还是会选择辅助索引,但是当访问的数据占整个表中数据的蛮大一部分时(一般是20%左右),优化器会选择通过聚集索引来查找数据。
select * from _order where order_status = 1查询出所有未支付的订单,一般这种订单是很少的,即使建了索引,也没法使用索引。
案例8、复杂查询
select sum(amt) from _t where a = 1 and b in (1, 2, 3) and c > '2020-01-01';
select * from _t where a = 1 and b in (1, 2, 3) and c > '2020-01-01' limit 10;如果是统计某些数据,可能改用数仓进行解决;
如果是业务上就有那么复杂的查询,可能就不建议继续走SQL了,而是采用其他的方式进行解决,比如使用ES等进行解决。
案例9、asc和desc混用
select * from _t where a=1 order by b desc, c ascdesc 和asc混用时会导致索引失效
案例10、大数据
对于推送业务的数据存储,可能数据量会很大,如果在方案的选择上,最终选择存储在MySQL上,并且做7天等有效期的保存。
那么需要注意,频繁的清理数据,会照成数据碎片,需要联系DBA进行数据碎片处理。