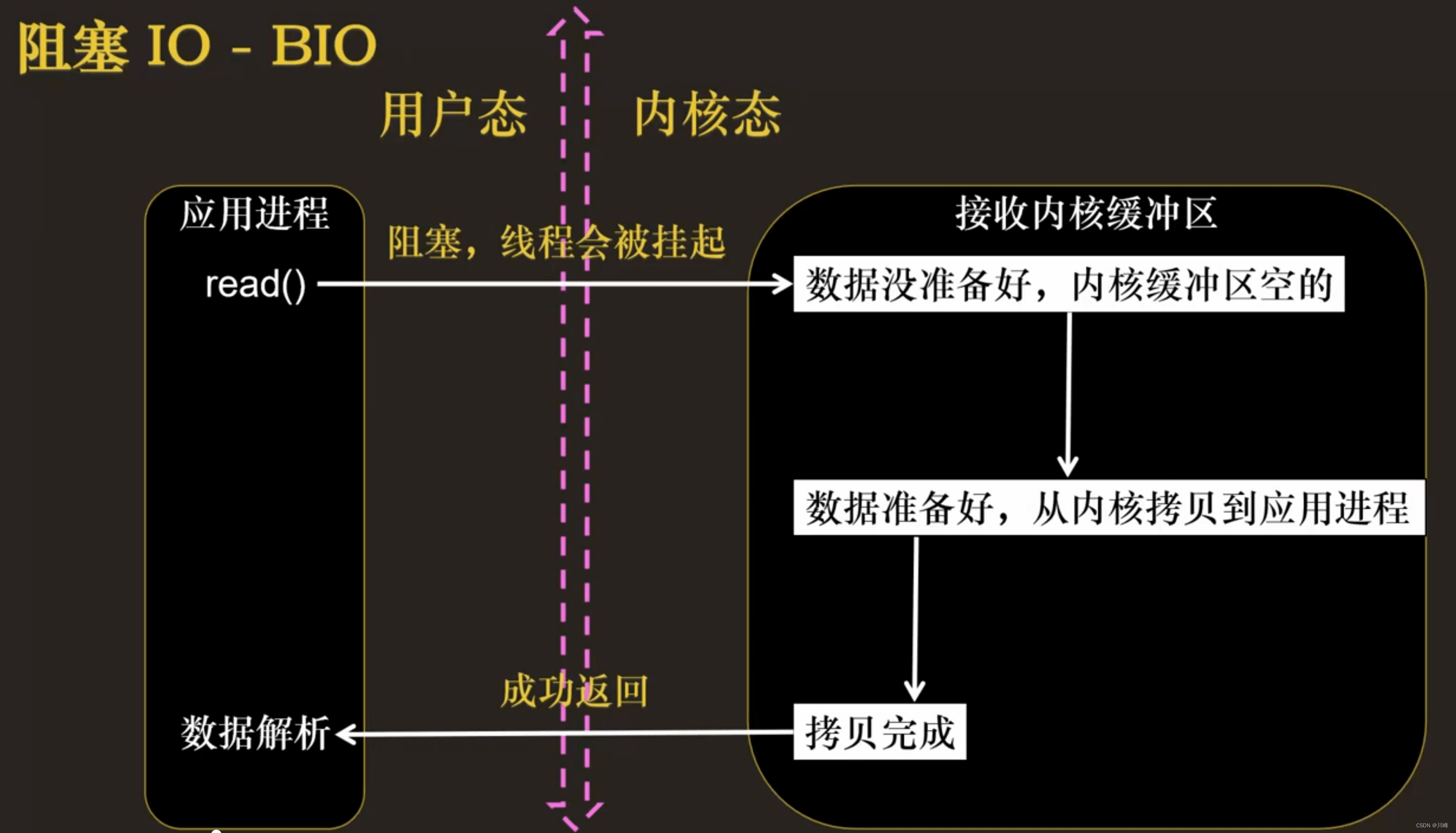
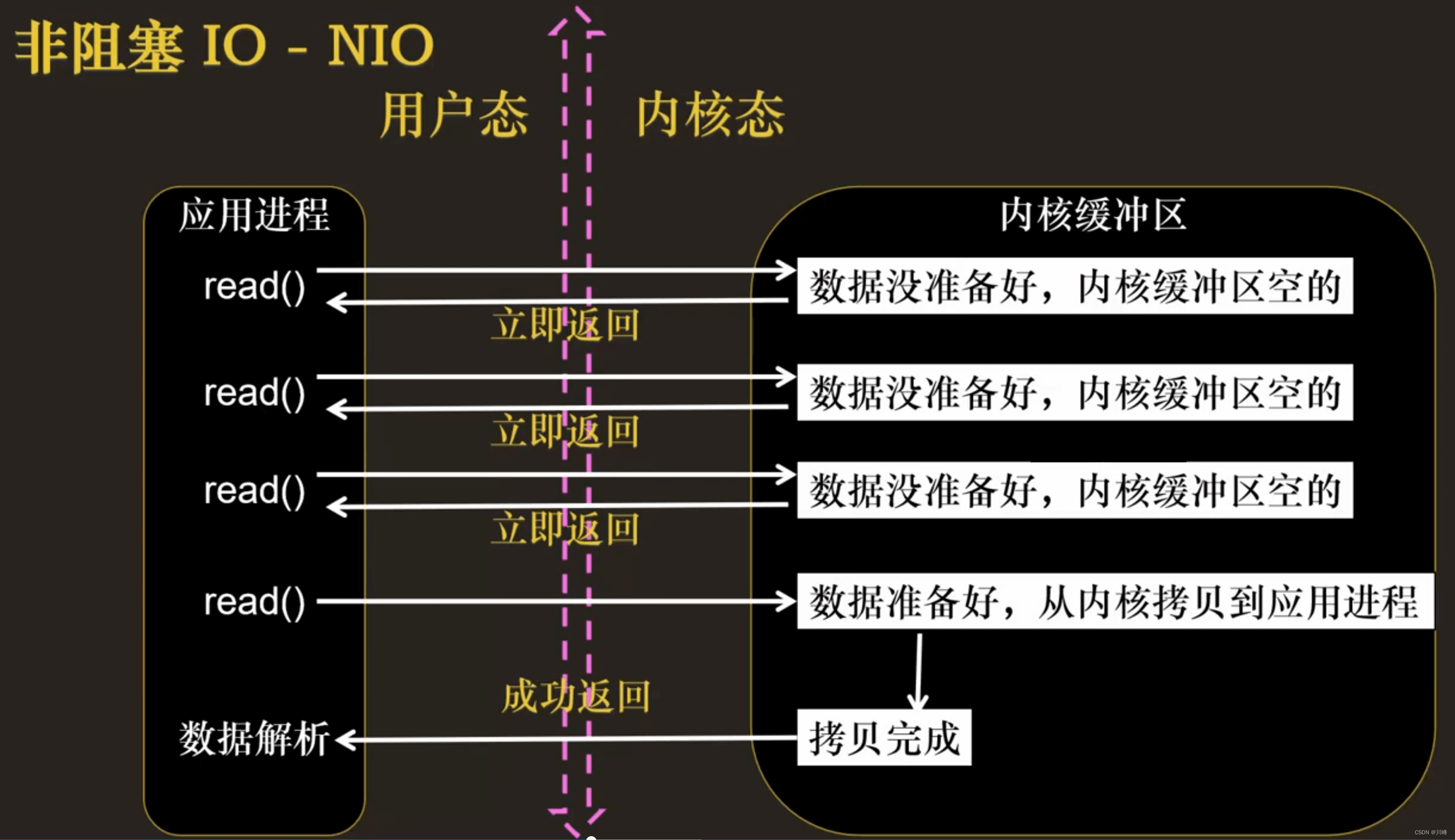
阻塞 IO 和 非阻塞 IO
阻塞 I/O 和 非阻塞 I/O 的主要区别:
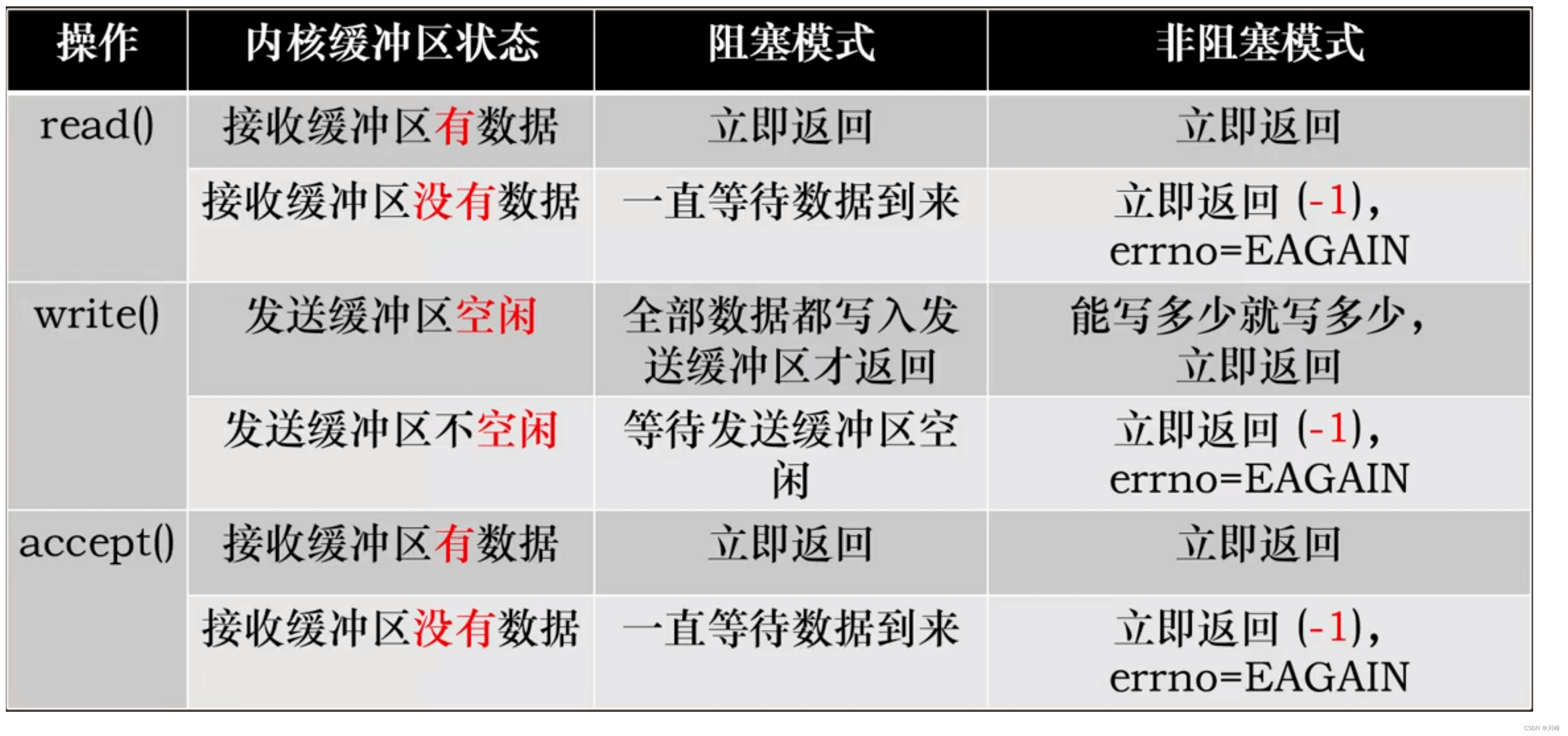
- 阻塞 I/O 执行用户程序操作是同步的,调用线程会被阻塞挂起,会一直等待内核的 I/O 操作完成才返回用户进程,唤醒挂起线程
- 非阻塞 I/O 执行用户程序操作是异步的,读写操作调用后内核会立即返回给用户一个状态值,用户可以立即执行其他操作。
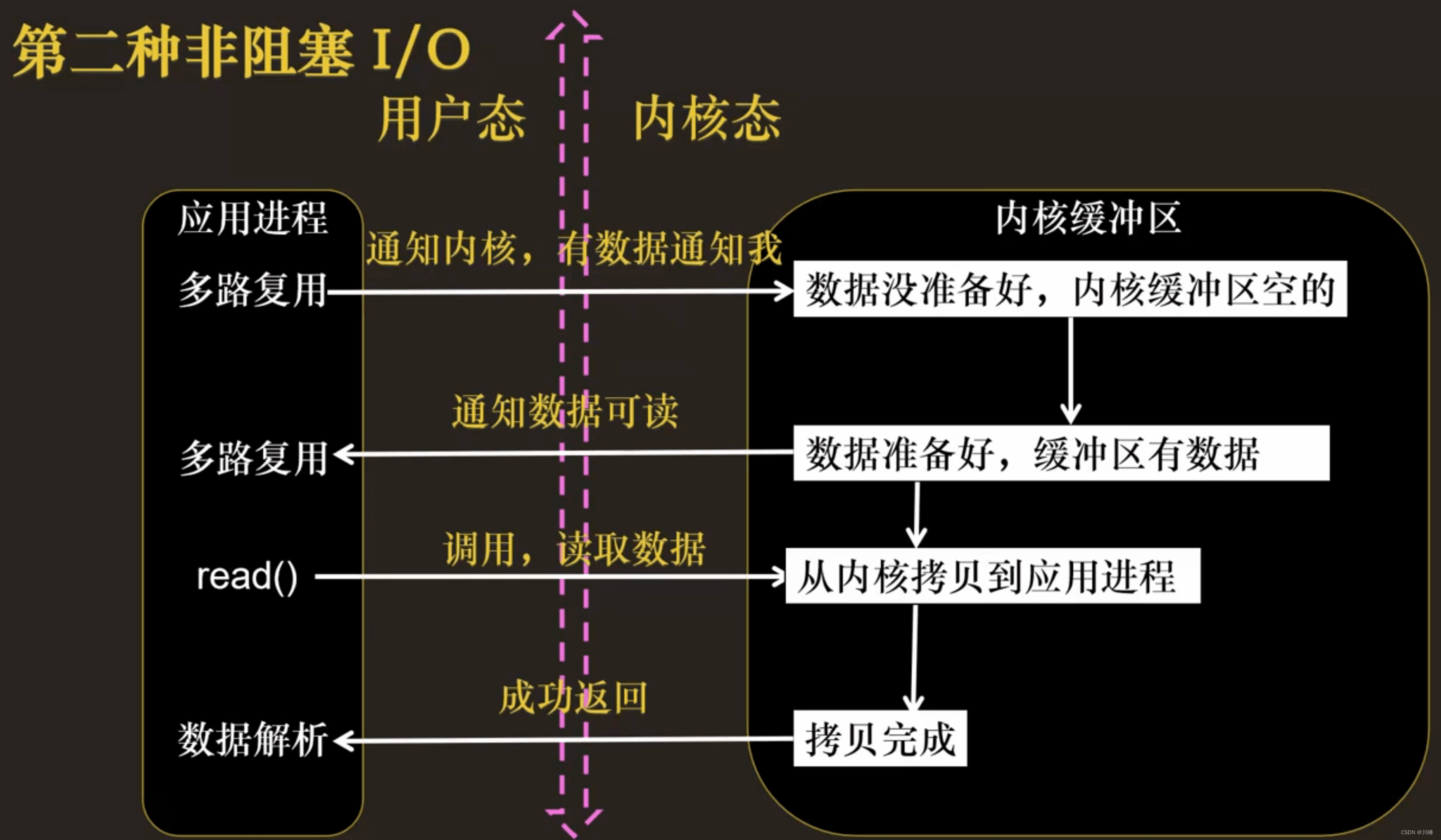
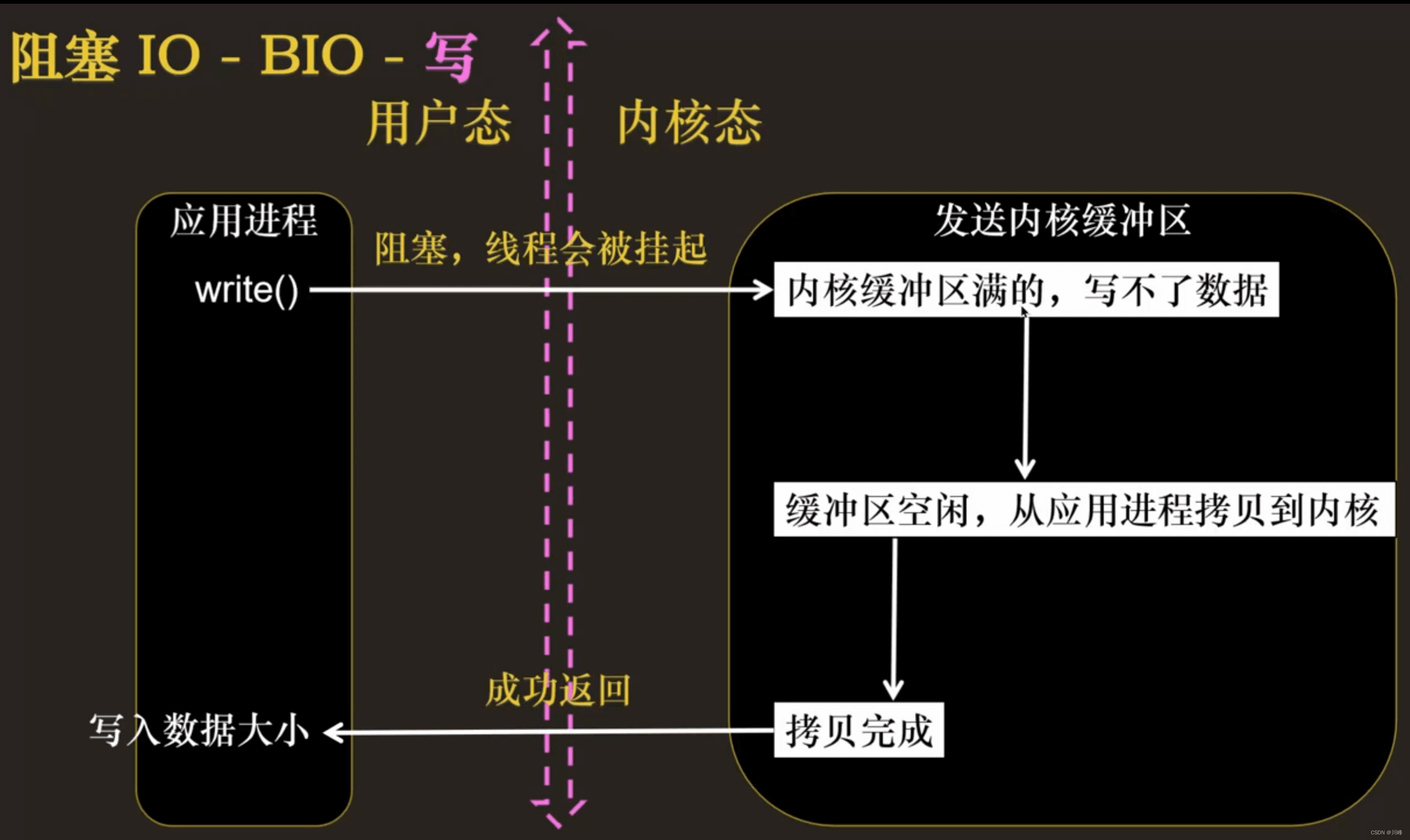
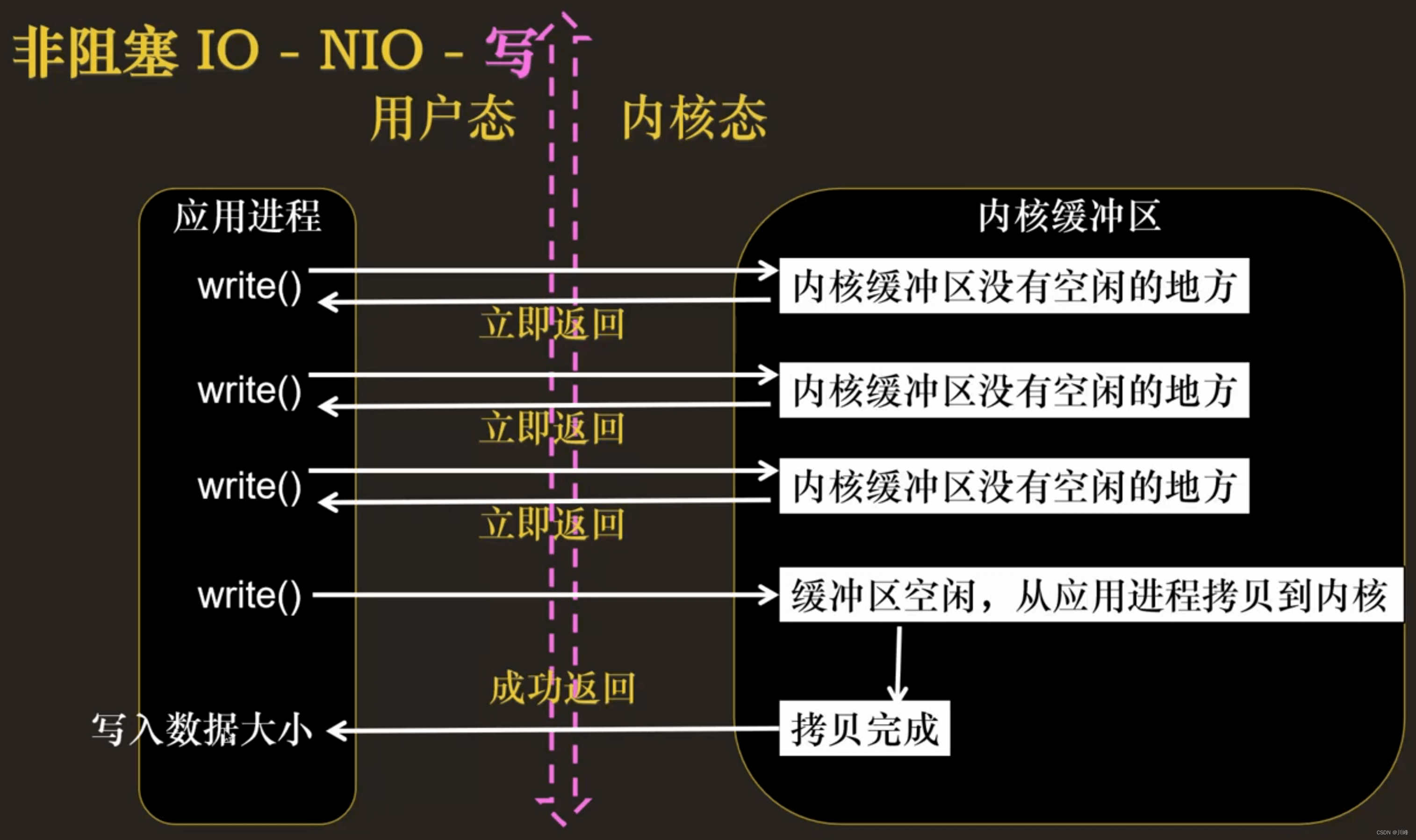
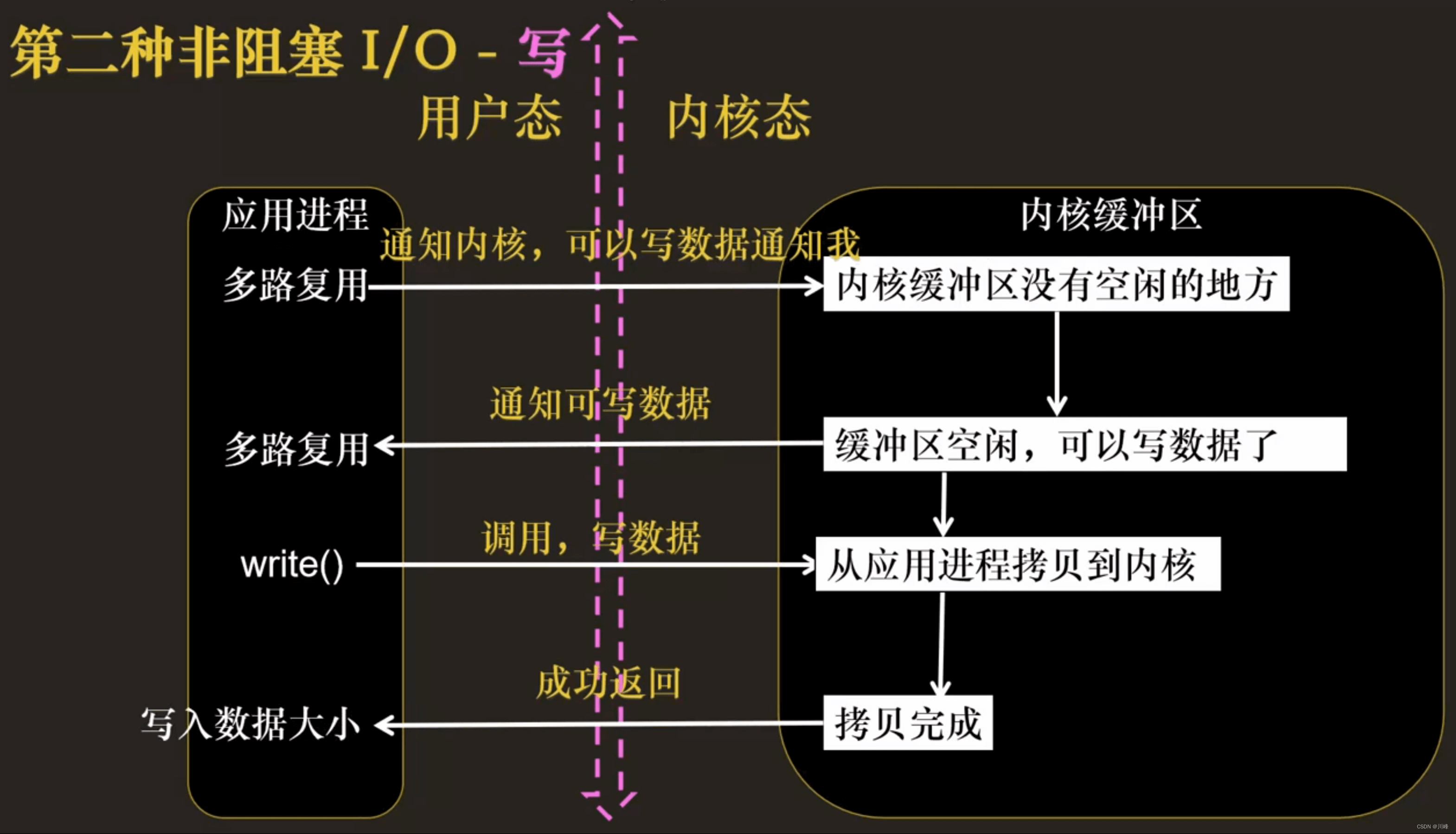
多路复用的概念
先看一个例子
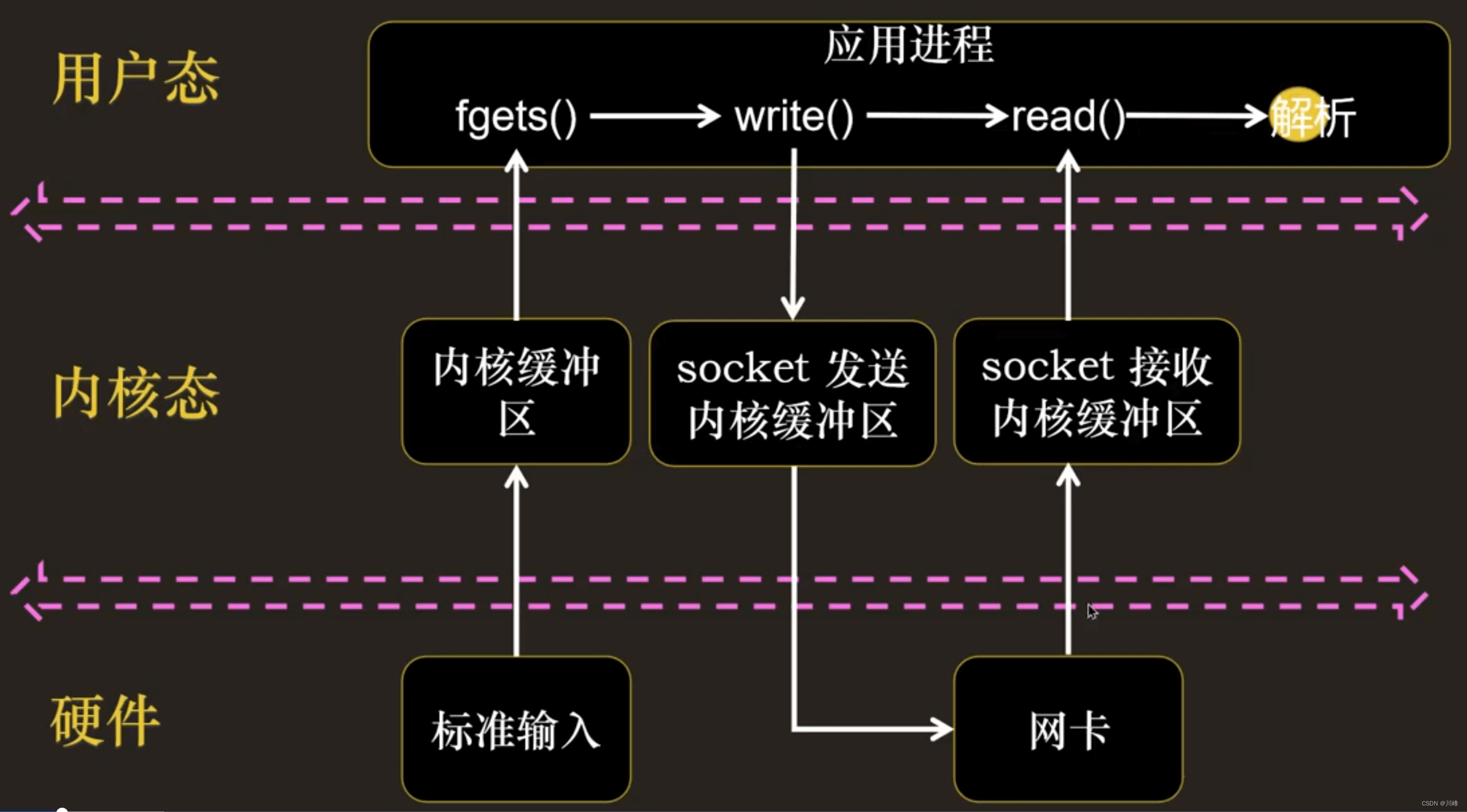
这里一旦使用 fgets() 方法等待标准输入,就没有办法在 Socket 有数据的时候读出数据:
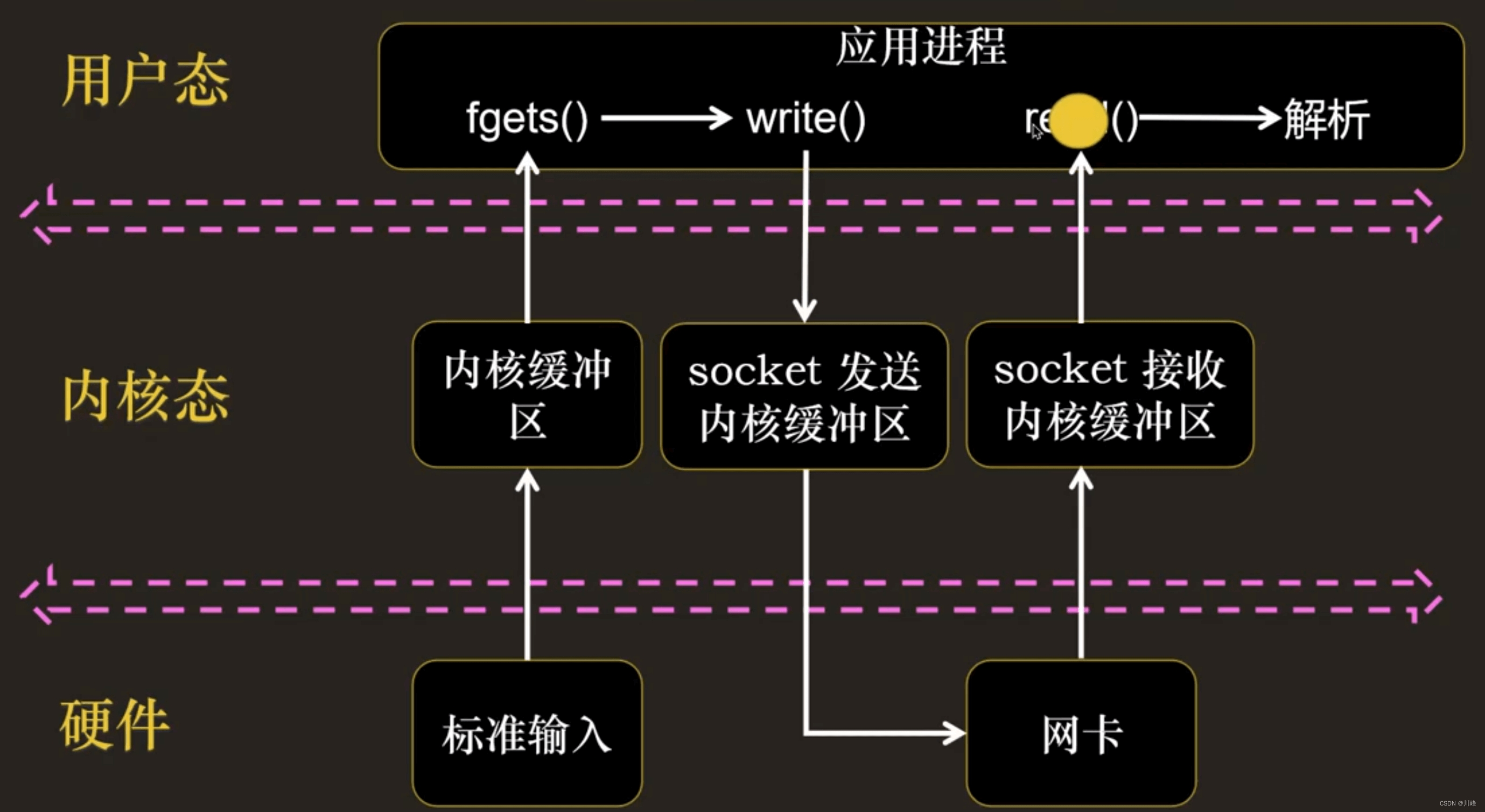
I/O 多路复用:把标准输入、Socket等都看做 I/O 的一路,多路复用的意思,就是在任何一路 I/O 有事件发生的情况下,通知应用程序去处理相应的 I/O 事件
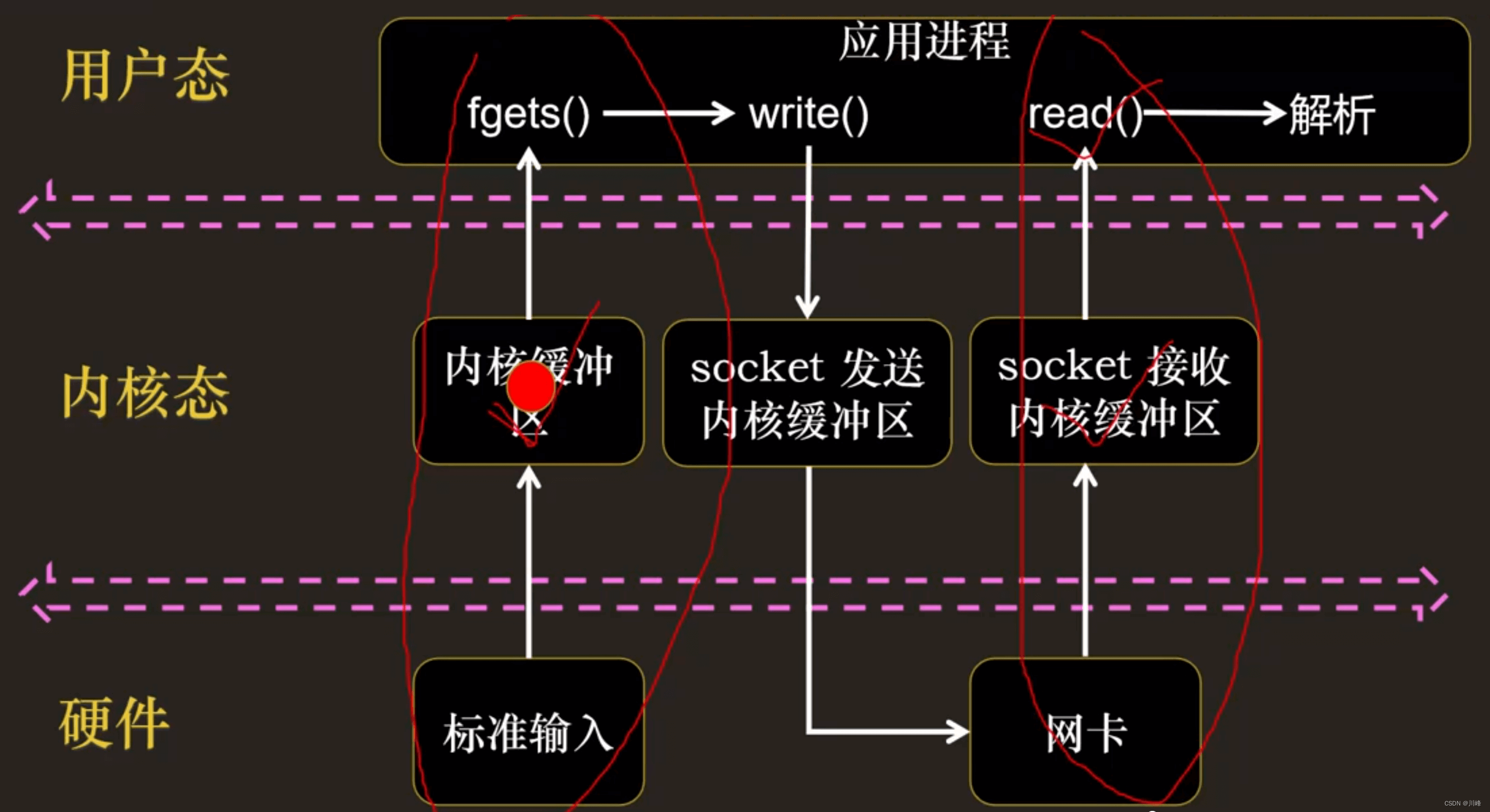
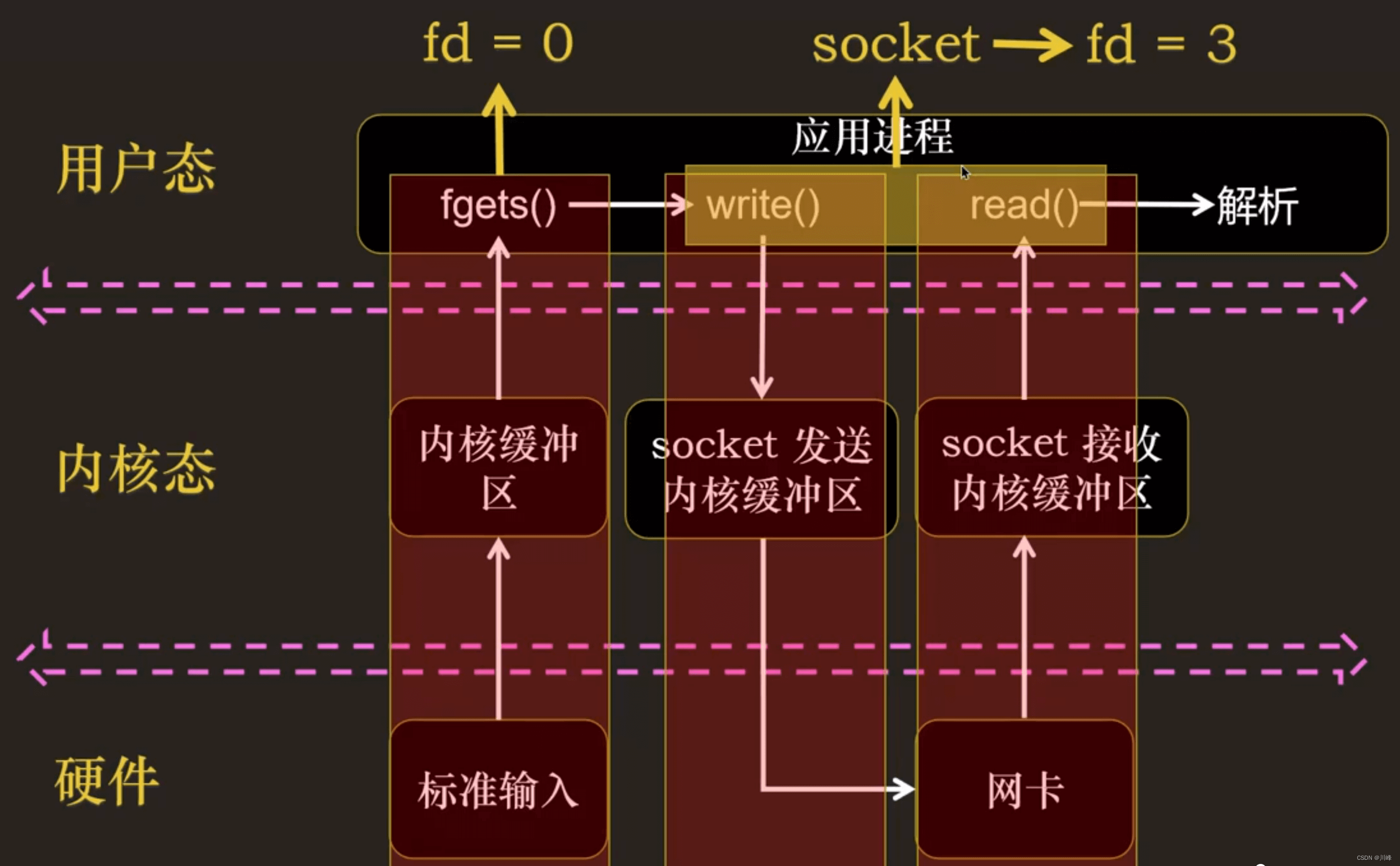
多路中的每一路本质上就是一个 fd:
什么是 I/O 事件,例如:
- I/O 事件一:fd 对应的内核缓冲区来了数据,可读;
- I/O 事件二:fd 对应的内核缓冲区空闲,可写;
- I/O 事件三:fd 出现异常
多路复用技术的实现主要有:
- ① select
- ② poll
- ③ epoll
I/O 多路复用就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但 select,poll,epoll 本质上都是同步 I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步 I/O 则无需自己负责进行读写,异步 I/O 的实现会负责把数据从内核拷贝到用户空间。
select 多路复用
首先,应用进程需要告诉内核它感兴趣的 I/O 事件,然后,内核感知设备发生的 I/O 事件,然后通知应用进程:你感兴趣的 fd 发生了你感兴趣的 I/O 事件类型。

多路中的每一路本质上就是一个 fd。
select函数定义如下:
/* According to POSIX.1-2001 */
#include <sys/select.h>
/* According to earlier standards */
#include <sys/time.h>
#include <sys/types.h>
#include <unistd.h>int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
fd_set
其中 fd_set 结构体定义如下:
#define __FD_SETSIZE 1024 typedef struct {unsigned long fds_bits[__FD_SETSIZE / (8 * sizeof(long))];
} __kernel_fd_set;
这里一个 long 占 8 个字节(64位系统),一个字节占 8 位,8 * sizeof(long) 总共占 64 位。
因此 __FD_SETSIZE / (8 * sizeof(long)) 的值是 1024/64 = 16,即数组大小16个(0-15),16个 long 数组总共有 64*16 = 1024 位 。
所以,fd_set 是长度为 1024 的比特位数组,数组索引表示文件描述符。
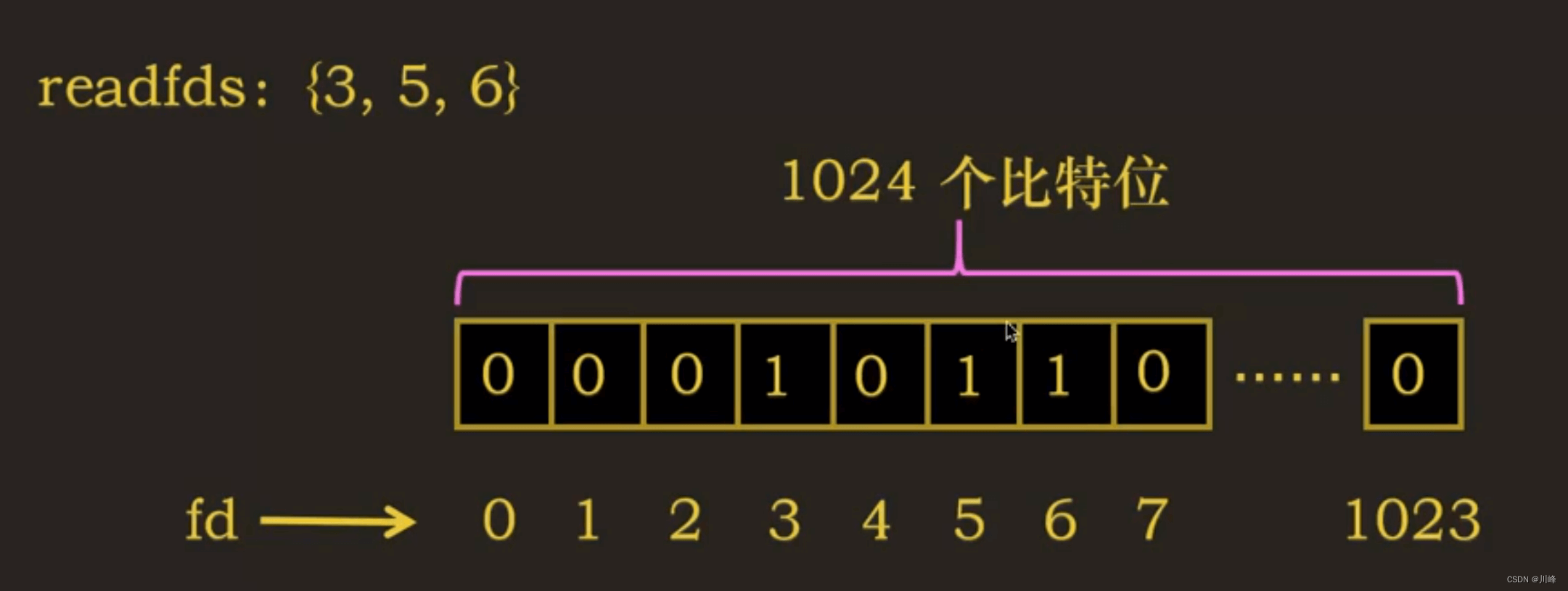
如何设置这些描述符集合
void FD_CLR(int fd, fd_set *set);
int FD_ISSET(int fd, fd_set *set);
void FD_SET(int fd, fd_set *set);
void FD_ZERO(fd_set *set);
FD_ZERO:用来将这个set的所有元素都设置成0;FD_SET:set[fd] = 1;FD_CLR:set[fd] = 0;FD_ISSET:set[fd] == 1 ? true : false
timeval
struct timeval {long tv_sec; /* seconds */ long tv_usec; /* microseconds */
};
最后一个参数是 timeval 时间结构体
- ① 设置成空(
NULL),表示如果没有 I/O 事件发生,则select一直等待下去。 - ② 设置一个非零的值,这个表示等待固定的一段时间后从
select阻塞调用中返回 - ③ 将
tv_sec和tv_usec都设置成0,表示根本不等待,检测完毕立即返回。这种情况使用得比较少。
select 执行流程
select 底层调用流程图:https://www.processon.com/view/link/62d3fdfce401fd259605006d
下面是简要描述:
int select (int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
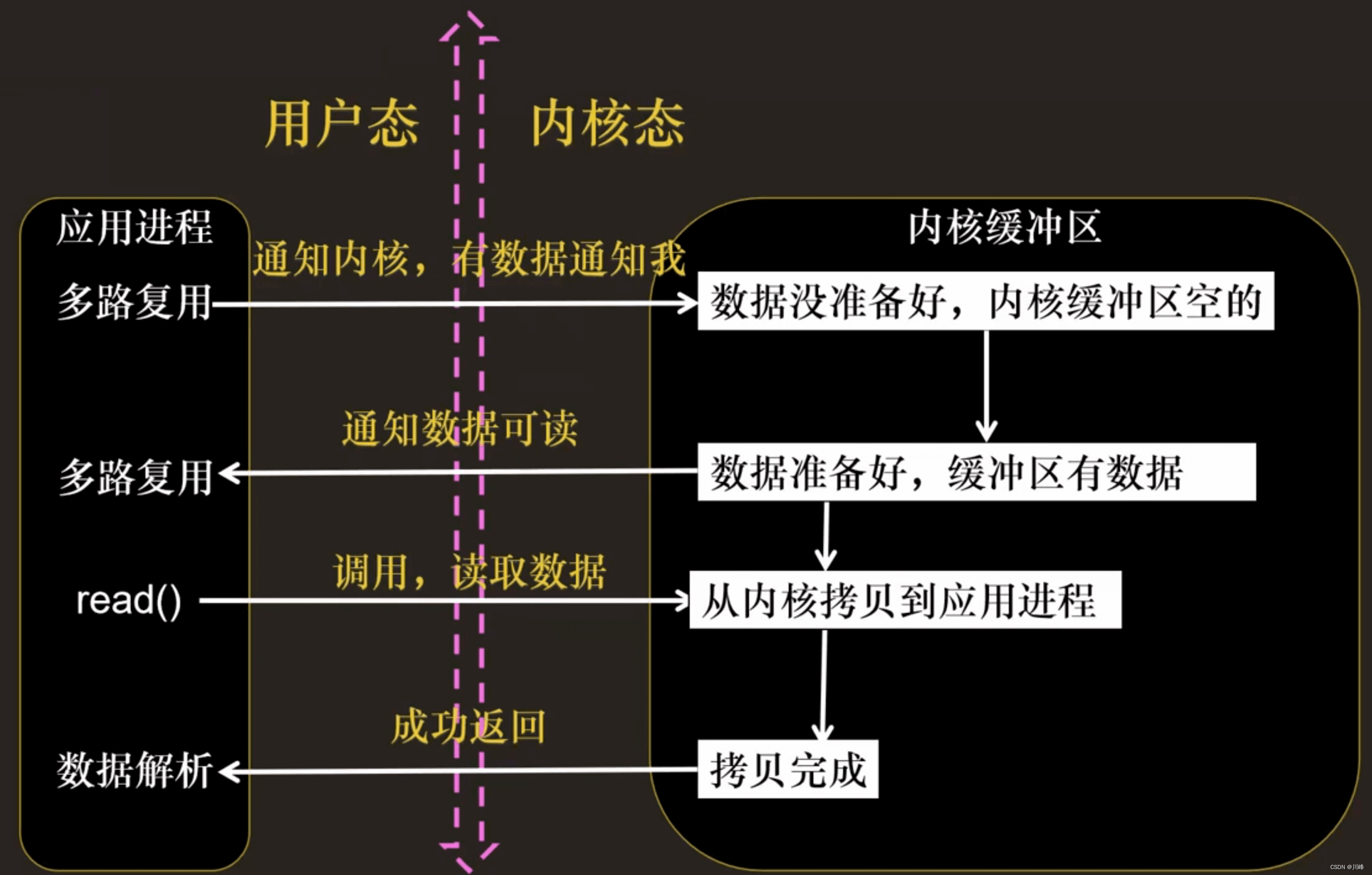
select函数监视的文件描述符分 3 类,分别是writefds、readfds和exceptfds。- 调用后
select函数会阻塞,直到有描述符就绪(可读/可写/有except),或者超时(timeout指定等待时间,如果立即返回设为null即可),函数返回。 - 当
select函数返回后,可以通过遍历fdset,来找到就绪的描述符。 fd_set是一个只包含长度为1024的比特位数组的结构体,数组的索引表示文件描述符,数组的值用1和0表示是否对当前索引的fd的 I/O 事件感兴趣。- 将这三个
fd_set文件描述符拷贝到内核态的三个数组,并创建三个对应的结果数组 - 内核中
for循环不断遍历 3 个fd_set数组中所有的fd,看其是否有可读/可写 I/O 事件发生,如果有,将结果数组的对应比特位设置为1,如果没有 I/O 事件发生,将该fd对应进程放入等待队列中(每个fd都有一个进程等待队列,当fd发生 I/O 事件时会唤醒这个进程) for循环结束后,如果一个fd都没有 I/O 事件发生,则当前调用select的进程进入休眠,让出 CPU 使用权,如果有某个fd发生 I/O 事件,就将结果数组返回,拷贝到用户态空间的三个fd_set的数组中
select 缺点
-
① 支持的文件描述符的个数是有限的。在 Linux 系统中,
select的默认最大值为1024。 -
② 内核会修改用户态传递的
readfds、writefds参数的值
最佳实践:多路复用 + 非阻塞 IO
poll 多路复用
#include <poll.h>int poll(struct pollfd *fds, nfds_t nfds, int timeout);
fds:pollfd数组,存放应用进程所有感兴趣的fd及其相应的 IO 事件nfds:pollfd数组的大小,可以大于1024,突破文件描述符个数限制timeout:超时时间
如果是一个< 0的数,表示在有事件发生之前永远等待;
如果是0,表示不阻塞进程,立即返回;
如果是一个> 0的数,表示poll调用方等待指定的毫秒数后返回。
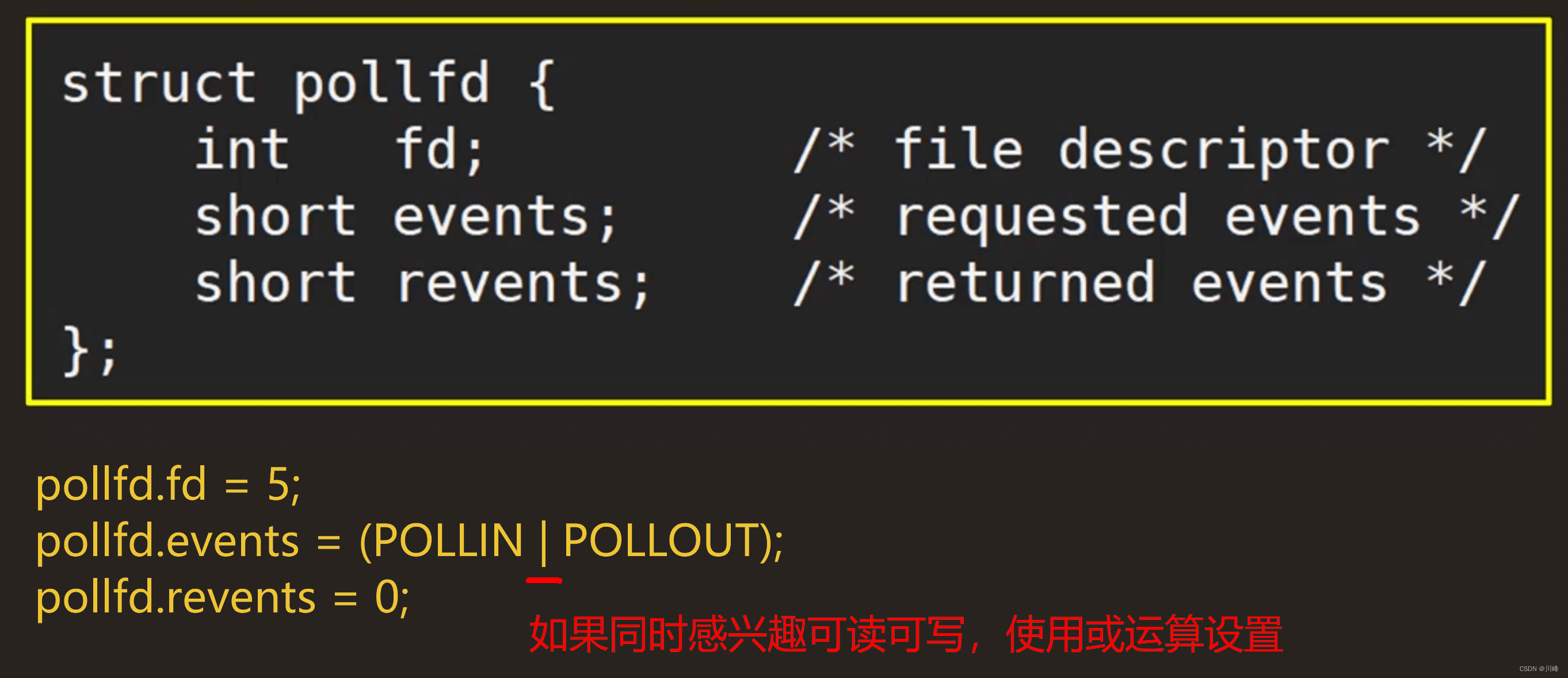
其中 pollfd 结构体定义如下:
struct pollfd { int fd; /* file descriptor */ short events; /* requested events */ short revents; /* returned events */
};
fd:感兴趣的文件描述符events:注册这个fd下感兴趣的 I/O 事件(可读事件、可写事件等)revents:内核通知的这个fd下发生的 I/O 事件,称为returned events
poll 中感兴趣的 IO 事件有哪些:
#define POLLIN Θx0001 /* any readable data available */
#define POLLPRI 0x0002 /* 00B/Urgent readable data */
#define POLLOUT 0x0004 /* file descriptor is writeable */#define POLLERR 0x0008 /* 一些错误发送 */
#define POLLHUP Θx0010 /* 描述符挂起 */
#define POLLNVAL Θx0020 /* 请求的事件无效 */

poll 执行流程
poll 底层调用流程图:https://www.processon.com/view/link/62d3fe350e3e74607274c241
其大致流程跟 select 相似
select vs poll
int poll (struct pollfd *fds, unsigned int nfds, int timeout);
- 不同于
select使用三个位图来表示三个fdset的方式,poll使用一个pollfd数组实现。 pollfd结构体包含了要监视的文件描述符fd, 对该fd感兴趣的 IO 事件events和内核通知fd下发生的 IO 事件revents。- 使用
nfds设置数组pollfd的大小,没有最大数量限制。 - 和
select函数一样,poll返回后,需要轮询pollfd来获取就绪的描述符。
最主要的区别是以下两点:
select支持最大的fds是1024,poll则没有这个限制select还需要遍历不感兴趣的fd, 但是poll只关心感兴趣的fd(不感兴趣的fd不存在pollfd数组中)
select/poll 的缺点
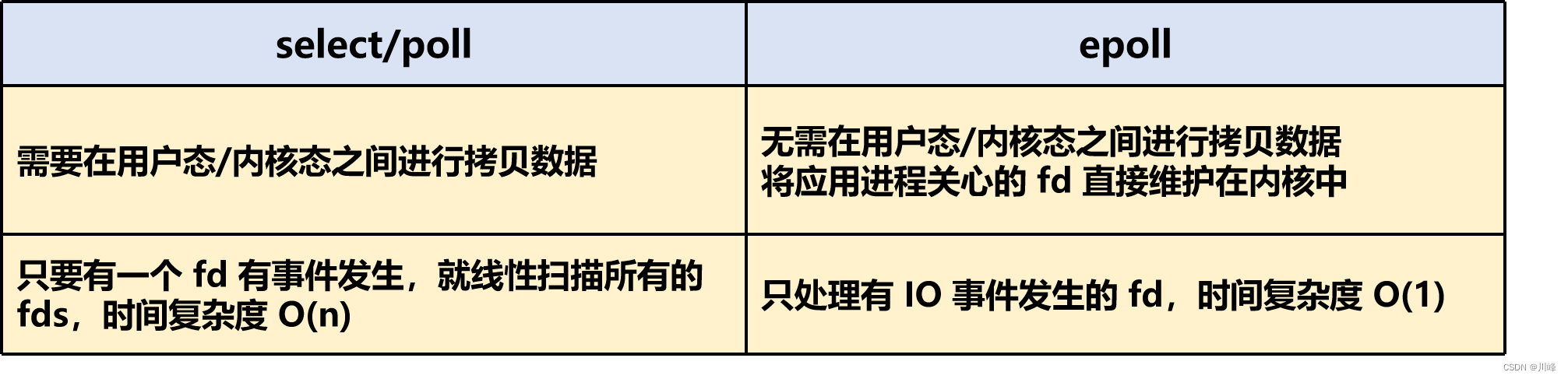
- 每次调用 select/poll 时,都需要在用户态和内核态之间拷贝数据
- 在内核中,select/poll 在检测 IO 事件时,只要有一个
fd有事件发生,就会线性扫描所有的fds,时间复杂度 O(n)
epoll 多路复用
epoll 是在 Linux 2.6 内核中提出的,是之前的 select 和 poll 的增强版本。相对于 select 和 poll 来说,epoll 更加灵活,没有描述符限制。
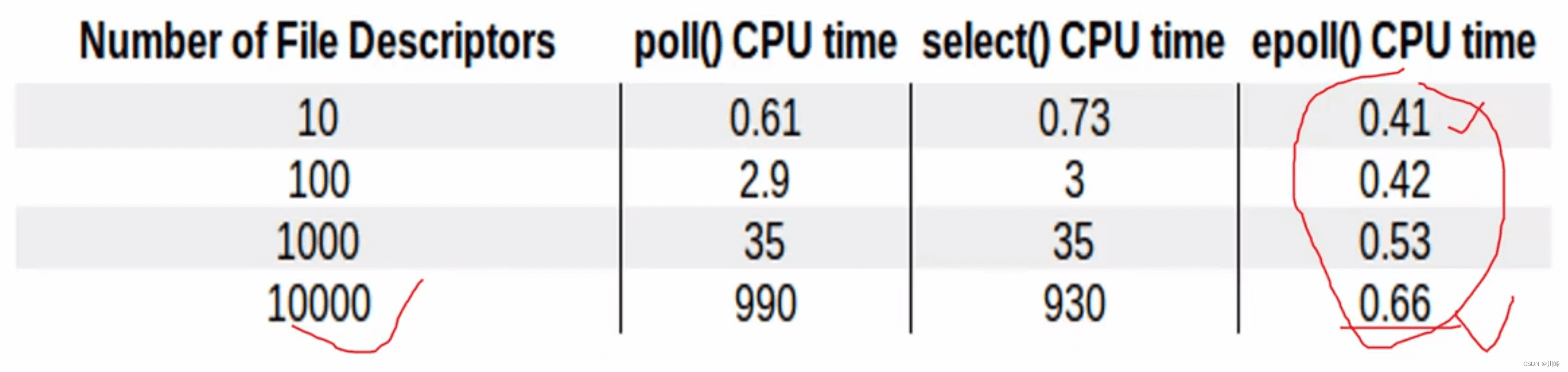
从图中可以明显地看到,epoll 的性能是最好的,即使在多达 10000 个文件描述的情况下,其性能的下降和有10个文件描述符的情况相比,差别也不是很大。而随着文件描述符的增大,常规的 select 和 poll 方法性能逐渐变得很差。
epoll 的使用
epoll_create:创建 epoll 实例
#include <sys/epoll.h> int epoll_create(int size);
创建一个 epoll 实例,从 Linux 2.6.8 开始,参数 size 被忽略,但是必须大于0
关于这个参数size,在一开始的 epoll_create 实现中,是用来告知内核期望监控fd的数量,然后内核使用这部分的信息来初始化内核数据结构,在新的实现中,这个参数不再被需要,因为内核可以动态分配需要的内核数据结构。
我们只需要注意,每次将 size 设置成一个大于0的整数就可以了。
epoll_create() 返回一个文件描述符,这个文件描述符对应着这个epoll实例。Linux 中一切皆文件,epoll 也被看成是一个文件,在内核中也有 file 实例与之对应。
epoll_ctl:操作 epoll 实例中的 IO 事件
#include <sys/epoll.h>int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
- ①
epfd:epoll_create创建的epoll实例对应的文件描述符 - ②
op:对 IO 事件的操作类型
EPOLL_CTL_ADD: 向epoll实例添加fd对应的事件;
EPOLL_CTL_DEL: 向epoll实例删除fd对应的事件;
EPOLL_CTL_MOD:修改fd对应的事件。 - ③
fd:注册的事件的文件描述符,比如一个监听套接字(socket) - ④
event:表示注册的事件类型
其中 epoll_event 结构体定义如下:
struct epoll_event { uint32_t events; /* Epoll events */epoll_data_t data; /* User data variable*/
};
events 就表示事件类型,Epoll 中的 IO 事件类型主要有以下几种:
EPOLLIN:表示对应的文件描述字可以读;EPOLLOUT:表示对应的文件描述字可以写;EPOLLRDHUP:表示套接字的一端已经关闭,或者半关闭;EPOLLHUP:表示对应的文件描述字被挂起;EPOLLET:设置为edge-triggered,默认为level-triggered
epoll_wait:等待内核 I/O 事件的分发
#include <sys/epoll.h>int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
-
①
epfd:epoll_create创建的epoll实例对应的文件描述符 -
②
events: 接口的返回参数,内核返回给用户态应用进程所有需要处理的 I/O 事件,这是一个数组,数组中的每个元素都是一个需要待处理的 I/O 事件。epoll 会把发生的事件的集合从内核复制到events数组中。events数组是一个用户分配好大小的数组,数组长度大于等于maxevents。(events不可以是空指针,内核只负责把数据复制到这个events数组中,不会去帮助我们在用户态中分配内存)其中
events表示具体的事件类型,事件类型取值和epoll_ctl可设置的值一样 -
③
maxevents:一个大于0的整数,表示本次epoll_wait可以返回的最大事件值。通常maxevents参数与预分配的events数组的大小是相等的。 -
④
timeout:超时事件,如果这个值设置为-1,表示不超时;如果设置为0则立即返回,即使没有任何 I/O 事件发生。设置> 0的数值,则表示等待一段时间内没有事件发生,则超时。
epoll 执行流程
epoll 原理图:https://www.processon.com/view/link/62d3fe5a7d9c08119ce3bbbc
-
epoll_cteate() : 内核会创建一个
eventpoll结构体实例,返回一个文件描述符与eventpoll实例相对应 -
epoll_ctl():注册感兴趣的
fd,以及对该fd感兴趣的事件类型 -
epoll_wait():等待内核 IO 事件分发,返回值表示要处理 IO 事件的数量,最大不超过
maxevents,需要返回给用户态的所有需要处理的 IO 事件存放在events数组中,events数组的大小由epoll_wait()返回值决定。 -
用户注册的
fd有 IO 事件发生时,就会将其对应的epitem挂到一个双向链表rdllist中(位于eventpoll结构体中) -
epoll_wait就是在一个循环中不断查看这个rdllist链表中是否有就绪事件,如果有,就将就绪事件返回,拷贝到用户空间中,如果没有,当前进程就进入休眠,CPU 被调度给其他进程使用 -
进程被唤醒的条件:
1)进程超时
2)进程收到一个signal信号
3)某个fd上有事件发生
4)当前进程被CPU重新调度
epoll vs select/poll
select/poll 的缺点:
-
① 每次调用 select/poll 时都需要在用户态/内核态之间进行拷贝数据
-
② 在内核中,select/poll 在检测 IO 事件时,只要有一个
fd有事件发生,就会线性扫描所有的 fds,时间复杂度 O(n)
与 select/poll 的缺点相比,epoll 的高效之处是:
- ① 将应用进程关心的 fd 直接维护在内核中,不再进行用户态和内核态间的拷贝(使用红黑树维护,高效增删改)
- ② epoll 只处理有 IO 事件发生的 fd,不会扫描所有的 fds,时间复杂度 O(1)
条件触发 和 边缘触发
条件触发(Level_triggered):又叫水平触发,当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据一次性全部读写完(如读写缓冲区太小),那么下次调用 epoll_wait() 时,它还会通知你在上没读写完的文件描述符上继续读写,当然如果你一直不去读写,它会一直通知你!!!如果系统中有大量你不需要读写的就绪文件描述符,而它们每次都会返回,这样会大大降低处理程序检索自己关心的就绪文件描述符的效率!!!
边缘触发(Edge_triggered):当被监控的文件描述符上有可读写事件发生时,epoll_wait() 会通知处理程序去读写。如果这次没有把数据全部读写完(如读写缓冲区太小),那么下次调用 epoll_wait() 时,它不会通知你,也就是它只会通知你一次,直到该文件描述符上出现第二次可读写事件才会通知你!!!这种模式比水平触发效率高,系统不会充斥大量你不关心的就绪文件描述符!!
总结:
- 条件触发:只要满足事件的条件,比如有数据需要读,就一直不断的把这个事件传递给用户
- 边缘触发:只有第一次满足条件的时候才触发,之后就不会再传递同样的事件了
- 边缘触发的效率比条件触发的效率高,epoll 支持边缘触发和条件触发,默认是条件触发,select 和 poll 都是条件触发