目录
三次握手
为什么握手需要三次
四次挥手
为什么挥手需要四次
TCP的可靠传输如何保证
TIME_WAIT等待的时间是2MSL
三次握手
三次握手其实就是指建立一个TCP连接。进行三次握手的主要作用就是为了确认双方的接收能力和发送能力是否正常、指定自己的初始化序列号为后面的可靠性传送做准备。
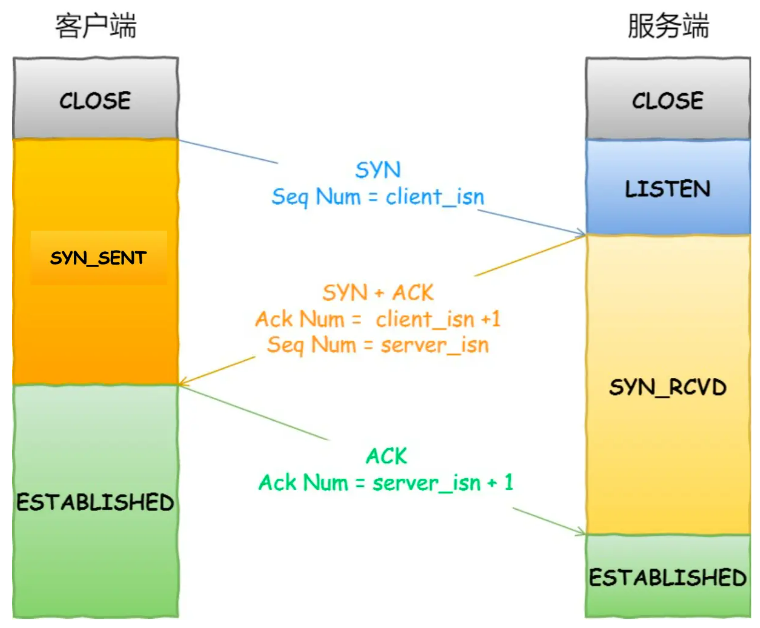
- 一开始,客户端和服务端都处于 CLOSE 状态。先是服务端主动监听某个端口,处于 LISTEN 状态
- 客户端会随机初始化序号(client_isn),将此序号置于 TCP 首部的「序号」字段中,同时把 SYN 标志位置为 1,表示 SYN 报文。接着把第一个 SYN 报文发送给服务端,表示向服务端发起连接,该报文不包含应用层数据,之后客户端处于 SYN-SENT 状态。
- 服务端收到客户端的 SYN 报文后,首先服务端也随机初始化自己的序号(server_isn),将此序号填入 TCP 首部的「序号」字段中,其次把 TCP 首部的「确认应答号」字段填入 client_isn + 1, 接着把 SYN 和 ACK 标志位置为 1。最后把该报文发给客户端,该报文也不包含应用层数据,之后服务端处于 SYN-RCVD 状态。
- 客户端收到服务端报文后,还要向服务端回应最后一个应答报文,首先该应答报文 TCP 首部 ACK 标志位置为 1 ,其次「确认应答号」字段填入 server_isn + 1 ,最后把报文发送给服务端,这次报文可以携带客户到服务端的数据,之后客户端处于 ESTABLISHED 状态。
- 服务端收到客户端的应答报文后,也进入 ESTABLISHED 状态。
从上面的过程可以发现第三次握手是可以携带数据的,前两次握手是不可以携带数据的,这也是面试常问的题。
一旦完成三次握手,双方都处于 ESTABLISHED 状态,此时连接就已建立完成,客户端和服务端就可以相互发送数据了。
为什么握手需要三次
相信大家比较常回答的是:“因为三次握手才能保证双方具有接收和发送的能力。”
这回答是没问题,但这回答是片面的,并没有说出主要的原因。
接下来,以三个方面分析三次握手的原因:
- TCP 使用三次握手建立连接的最主要原因是防止「历史连接」初始化了连接。
- 三次握手才可以同步双方的初始序列号
- 三次握手才可以避免资源浪费
原因一:避免历史连接
简单来说,三次握手的首要原因是为了防止旧的重复连接初始化造成混乱。
我们考虑一个场景,客户端先发送了 SYN(seq = 90)报文,然后客户端宕机了,而且这个 SYN 报文还被网络阻塞了,服务端并没有收到,接着客户端重启后,又重新向服务端建立连接,发送了 SYN(seq = 100)报文(注意!不是重传 SYN,重传的 SYN 的序列号是一样的)。
客户端连续发送多次 SYN(都是同一个四元组)建立连接的报文,在网络拥堵情况下:
- 一个「旧 SYN 报文」比「最新的 SYN」 报文早到达了服务端,那么此时服务端就会回一个 SYN + ACK 报文给客户端,此报文中的确认号是 91(90+1)。
- 客户端收到后,发现自己期望收到的确认号应该是 100 + 1,而不是 90 + 1,于是就会回 RST 报文。
- 服务端收到 RST 报文后,就会释放连接。
- 后续最新的 SYN 抵达了服务端后,客户端与服务端就可以正常的完成三次握手了。
上述中的「旧 SYN 报文」称为历史连接,TCP 使用三次握手建立连接的最主要原因就是防止「历史连接」初始化了连接。
如果采用两次握手建立 TCP 连接的场景下,服务端在向客户端发送数据前,并没有阻止掉历史连接,导致服务端建立了一个历史连接,又白白发送了数据,妥妥地浪费了服务端的资源。
因此,要解决这种现象,最好就是在服务端发送数据前,也就是建立连接之前,要阻止掉历史连接,这样就不会造成资源浪费,而要实现这个功能,就需要三次握手。
所以,TCP 使用三次握手建立连接的最主要原因是防止「历史连接」初始化了连接。
原因二:同步双方初始序列号
TCP 协议的通信双方, 都必须维护一个「序列号」, 序列号是可靠传输的一个关键因素,它的作用:
- 接收方可以去除重复的数据;
- 接收方可以根据数据包的序列号按序接收;
- 可以标识发送出去的数据包中, 哪些是已经被对方收到的(通过 ACK 报文中的序列号知道);
可见,序列号在 TCP 连接中占据着非常重要的作用,所以当客户端发送携带「初始序列号」的 SYN 报文的时候,需要服务端回一个 ACK 应答报文,表示客户端的 SYN 报文已被服务端成功接收,那当服务端发送「初始序列号」给客户端的时候,依然也要得到客户端的应答回应,这样一来一回,才能确保双方的初始序列号能被可靠的同步。
四次握手其实也能够可靠的同步双方的初始化序号,但由于第二步和第三步可以优化成一步,所以就成了「三次握手」。
而两次握手只保证了一方的初始序列号能被对方成功接收,没办法保证双方的初始序列号都能被确认接收。
原因三:避免资源浪费
如果只有「两次握手」,如果客户端发送的 SYN 报文在网络中阻塞了,重复发送多次 SYN 报文,那么服务端在收到请求后就会建立多个冗余的无效链接,造成不必要的资源浪费。
即两次握手会造成消息滞留情况下,服务端重复接受无用的连接请求 SYN 报文,而造成重复分配资源。
小结
TCP 建立连接时,通过三次握手能防止历史连接的建立,能减少双方不必要的资源开销,能帮助双方同步初始化序列号。序列号能够保证数据包不重复、不丢弃和按序传输。
不使用「两次握手」和「四次握手」的原因:
- 「两次握手」:无法防止历史连接的建立,会造成双方资源的浪费,也无法可靠的同步双方序列号;
- 「四次握手」:三次握手就已经理论上最少可靠连接建立,所以不需要使用更多的通信次数。
四次挥手
双方都可以主动断开连接,断开连接后主机中的「资源」将被释放,四次挥手的过程如下图:
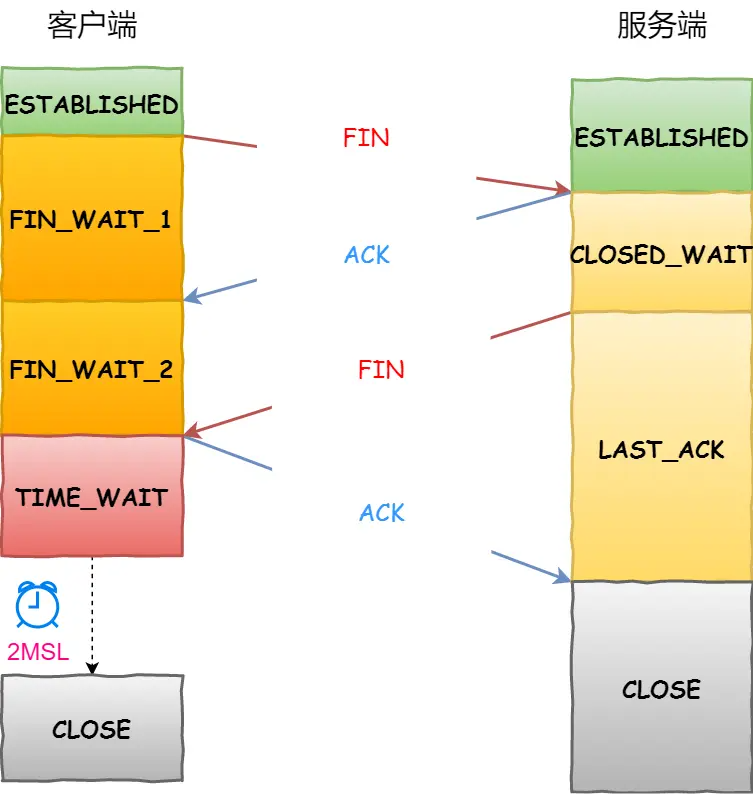
刚开始双方都处于 ESTABLISHED 状态,假如是客户端先发起关闭请求。四次挥手的过程如下:
- 客户端打算关闭连接,此时会发送一个 TCP 首部 FIN 标志位被置为 1 的报文,也即 FIN 报文,之后客户端进入 FIN_WAIT_1 状态。
- 服务端收到该报文后,就向客户端发送 ACK 应答报文,接着服务端进入 CLOSE_WAIT 状态。
- 客户端收到服务端的 ACK 应答报文后,之后进入 FIN_WAIT_2 状态。
- 等待服务端处理完数据后,也向客户端发送 FIN 报文,之后服务端进入 LAST_ACK 状态。
- 客户端收到服务端的 FIN 报文后,回一个 ACK 应答报文,之后进入 TIME_WAIT 状态
- 服务端收到了 ACK 应答报文后,就进入了 CLOSE 状态,至此服务端已经完成连接的关闭。
- 客户端在经过 2MSL 一段时间后,自动进入 CLOSE 状态,至此客户端也完成连接的关闭。
你可以看到,每个方向都需要一个 FIN 和一个 ACK,因此通常被称为四次挥手。
这里一点需要注意是:主动关闭连接的,才有 TIME_WAIT 状态。
为什么挥手需要四次
再来回顾下四次挥手双方发 FIN 包的过程,就能理解为什么需要四次了。
- 关闭连接时,客户端向服务端发送 FIN 时,仅仅表示客户端不再发送数据了但是还能接收数据。
- 服务端收到客户端的 FIN 报文时,先回一个 ACK 应答报文,而服务端可能还有数据需要处理和发送,等服务端不再发送数据时,才发送 FIN 报文给客户端来表示同意现在关闭连接。
从上面过程可知,服务端通常需要等待完成数据的发送和处理,所以服务端的 ACK 和 FIN 一般都会分开发送,因此是需要四次挥手。
TCP的可靠传输如何保证
TCP是通过一些机制来保证可靠传输的。
校验和
TCP每一段报文都有校验和,这保证了报文不被破坏或篡改,如果收到的报文在校验过程中有差错,TCP 将丢弃这个报文段和不确认收到此报文段。
序列号与确认应答
TCP发送的每一个包都有一个序列号,这可以让接收方知道自己已经接收到了那些包,哪些包丢失了,重复的包也可以根据序号丢弃,并且根据序号将包排序,同时每一个发送的包都会返回一个确认应答消息,来确保消息被接收。
重传机制
TCP 实现可靠传输的方式之一,是通过序列号与确认应答,当发送端的数据到达接收主机时,接收端主机会返回一个确认应答消息,表示已收到消息,如果数据包丢失了,就会用重传机制解决。
重传机制分为超时重传、快速重传
超时重传 :在发送数据时,设定一个定时器,当超过指定的时间后,没有收到对方的 ACK 确认应答报文,就会重发该数据。超时时间被称为RTO,一般略大于RTT,不过RTO是一个动态值。如果重传的包又超时了,即每当遇到一次超时重传的时候,都会将下一次超时时间间隔设为先前值的两倍。两次超时,就说明网络环境差,不宜频繁反复发送。
快速重传 :超时重传的问题是要等超时时间后才会重传。快速重传不以时间为驱动,而是以数据驱动重传,服务器如果收到乱序的包,也给客户端回复 ACK,比如收到乱序的包 6,7,8,9 时,服务器全都发 ACK = 5,这样客户端就知道5丢失了,当客户端收到三个相同的 ACK 报文时,会在超时之前,重传丢失的报文段,而不需要等到计时器超时。
滑动窗口
窗口大小就是指无需等待确认应答,而可以继续发送数据的最大值。
TCP 是每发送一个数据,就需要等待对方进行ACK确认应答,这显然会极大的影响传输的速率。在发送数据的时候,最好的方式是一下将所有的数据全部发送出去,然后一起确认。
于是就引入了窗口的概念,这个所谓的窗口实际上是操作系统开辟的一个缓存空间,发送方在等到确认应答返回之前,必须在缓冲区中保留已发送的数据。如果按期收到确认应答后,此时数据就可以从缓存区清除,同样接收方接收数据后也是放在这个缓存区中的,那么接收方缓存区还能接收多少数据,这个就是决定窗口大小的因素。
所以,通常窗口的大小是由接收方的窗口大小来决定的。发送方发送的数据大小不能超过接收方的窗口大小,否则接收方就无法正常接收到数据。
流量控制
发送方不能无限制的发数据给接收方,也要考虑接收方的处理能力,如果一直无限制的发数据给对方,但对方处理不过来,那么就会导致触发重发机制,从而导致网络流量的无端的浪费。
为了解决这种现象发生,TCP 提供一种机制可以让「发送方」根据「接收方」的实际接收能力控制发送的数据量,这就是所谓的流量控制。TCP使用滑动窗口来实现流量控制。滑动窗口既保证了分组无差错、有序接收,也实现了流量控制。主要的方式就是接收方返回的 ACK 中会包含自己的接收窗口的大小,并且利用大小来控制发送方的数据发送。
拥塞控制
有了流量控制为什么还需要拥塞控制?
流量控制是针对接收者的,它是控制发送者的发送速度从而使接收者来得及接收,防止分组丢失的。即防止发送方的数据填满接收方的缓存区。
拥塞控制:拥塞控制是作用于网络的,它是防止过多的数据注入到网络中,避免出现网络负载过大的情况。即防止发送方的数据填满整个网络
在网络出现拥堵时减少数据包的发送,网络恢复后它又会增加数据包的发送,这就是拥塞控制。
拥塞控制算法:
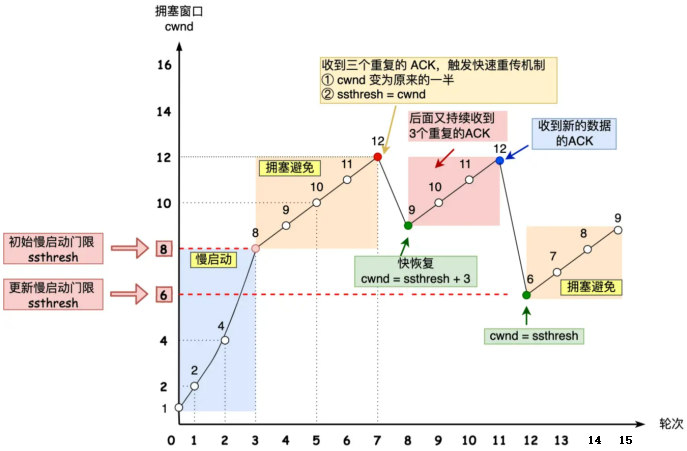
慢启动:TCP 在刚建立连接完成后并不知道网络情况,它会一点一点的提高发送数据包的数量来试探网络的情况,它的主要原理就是:当发送方每收到一个 ACK,拥塞窗口 cwnd 的大小就会加 1。当然也不可能无限制的增加拥塞窗口 cwnd 的大小,有一个叫慢启动门限 ssthresh (slow start threshold)状态变量,当cwnd 小于该值时就增加,大于等于该值时就会启动拥塞避免算法。慢开始算法只是在TCP连接建立时和网络出现超时时才使用
拥塞避免算法:进入拥塞避免算法后,它的规则是:每当收到一个 ACK 时,拥塞窗口cwnd 增加 1/cwnd,假设cwnd现在是8,那么进入拥塞避免算法后,收到ACK时,它增加了1/8。也就是说增长变的缓慢了,即使缓慢的增长,它也是无限制的,这样网络就会慢慢进入了拥塞的状况,当出现包丢失,触发重传机制的时候,就进入了拥塞发生算法。
拥塞发生算法:当网络出现拥塞,也就是会发生数据包重传,触发重传机制,前面我们知道重传机制分为超时重传和快速重传两种情况,当发生了超时重传时才会使用拥塞发生算法,此时它会将ssthresh 设置为cwnd/2 ,并将cwnd 重置为初始值。接着,就重新开始慢启动,慢启动是会突然减少数据流的。这种方式太激进会造成网络卡顿。当发生快速重传时,TCP 认为这种情况不严重,因为大部分没丢,只丢了一小部分,则 ssthresh 和 cwnd 变化如下,cwnd = cwnd/2 ,也就是设置为原来的一半;ssthresh = cwnd。进入快速恢复算法
快速恢复算法: 快速重传和快速恢复算法一般同时使用,进入快速恢复算法后,拥塞窗口 cwnd = ssthresh + 3,重传丢失的数据包。快速恢复是针对拥塞发生后对慢启动的优化。
TIME_WAIT等待的时间是2MSL
MSL 报文最大生存时间,它是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。
为了保证客户端发送的最后一个ACK报文段能够到达服务器。因为这个ACK有可能丢失,从而导致处在LAST-ACK状态的服务器收不到对FIN-ACK的确认报文。服务器会超时重传这个FIN-ACK,接着客户端再重传一次确认,重新启动时间等待计时器。最后客户端和服务器都能正常的关闭。假设客户端不等待2MSL,而是在发送完ACK之后直接释放关闭,一但这个ACK丢失的话,服务器就无法正常的进入关闭连接状态。
TIME_WAIT 等待 2 倍的 MSL,比较合理的解释是: 网络中可能存在来自发送方的数据包,当这些发送方的数据包被接收方处理后又会向对方发送响应,所以一来一回需要等待 2 倍的时间。