为什么会看这篇文章呢?因为要搞所谓分割大模型,为什么要搞分割大模型,因为最终我们要搞得是,业内领先的全自动标注系统。(标完都不需要人工再修正!!!)
OK,仰望完星空了,我们现在要脚踏实地了。来看paper,尽可能简单并且通俗易懂的讲一下。可能也没那么简单。

先看图,我的第一个问题是,什么叫Entity Segmentation,我之前也不是做segmentation的之前主要做目标检测。分割我知道有语义分割,实例分割,全景分割,这是实体分割是什么鬼?为了搞清楚这个概念也是一通好找,简单来说就是 不输出语义信息的全景分割,这个是有依据的。
- 这篇文章主要讲两个,一个是数据集,一个是模型,然后各种实验什么都就不说了。
数据集
文章提出了一个数据集,叫 EntitySeg Dataset,由Adobe 赞助开源给学术界使用。这个数据集图像分辨率非常高(当然也有低分辨率的图像),标注质量也更好,数据来源也更加丰富。
这个数据集和COCO Panoptic、ADE20 K-Panoptic相比,每个图像平均有18.1个实体,超过了COCO和ADE20K中的11.2和13.6个实体。EntitySeg数据集中实体的形状比COCO和ADE20 K更复杂。

并且“ Besides, our annotation procedure is more similar to the human visual system. As evidenced in [35], the human vision system is intrinsically class-agnostic and can recognize entities without comprehending their usage and purpose.”
模型
这篇文章的模型叫CropFormer,至于这个模型是什么我们会详细讲一下,简单来说这个模型会学N个Q(N×K,k是维度),用Q去生成mask embeddings E(N×1×1×1×K),E会被用作convolution filters,对 pixellevel mask features P2 (T ×H×W,T是image view,H是height ,W是with)处理完后生成N个segmentation masks Um (N×T ×H×W )。当然这并不是真正的模型流程。在文章中说这样的基本设计只能很好地处理单个视图输入,并且不能有效地融合来自多个视图的结果,他们搞了一种一种新的关联模块和批处理级解码器(association module and batch-level decoder)来实现Crop Former的目标,即利用完整图像的全局上下文和作物的细粒度局部细节进行高质量分割。
下面我们来看完整的流程图:
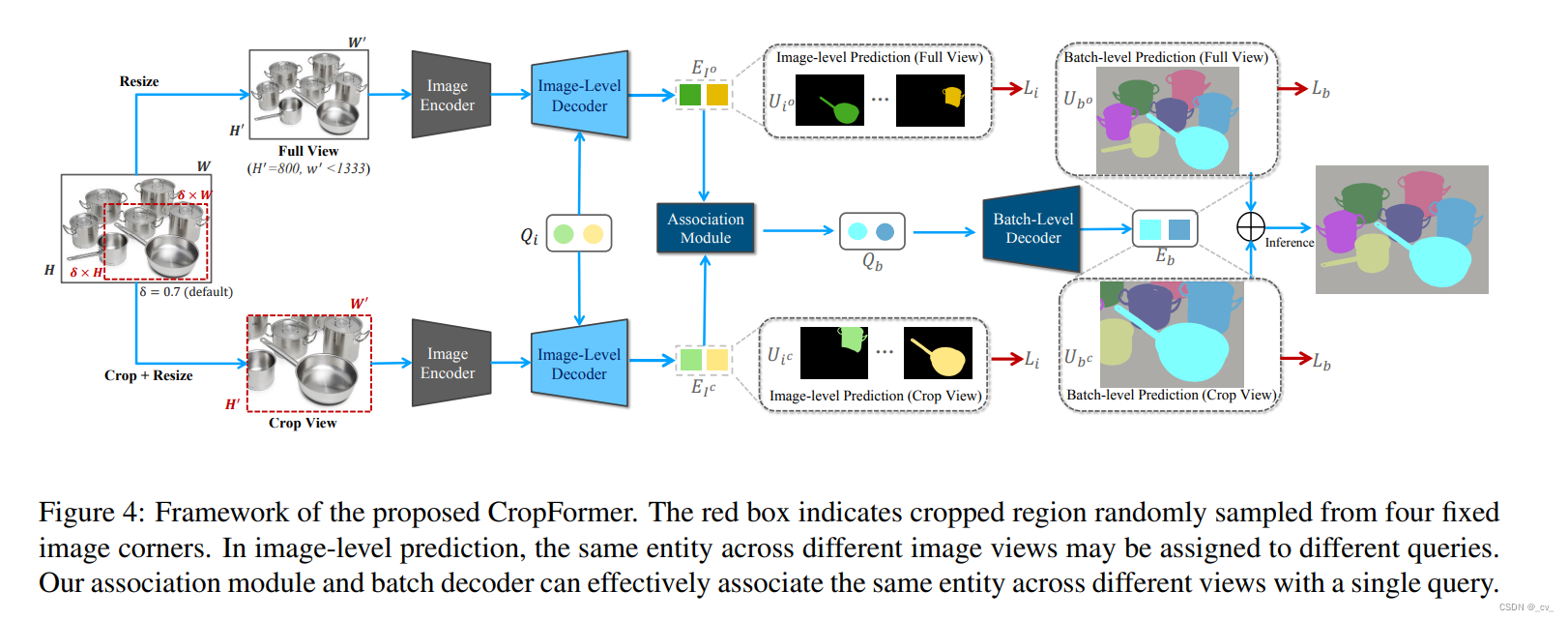
好的paper图是非常重要的,要让人一看就感觉很清晰,把上面这个图看懂了这个模型的流程也就清楚了。
- Image Encoder and Decoder
首先来说Image Encoder and Decoder这两个模块,我们把 image encoder 模块叫做Θ,image-level decoder 模块叫做 Φi。在上面说用Q去生成E。具体就是给定输入的 tensor (I) and queries (Qi),
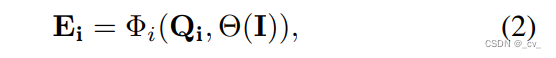
这里的 Φi(·) is a Transformer-based image-level decoder.
然后呢,用E和P去生成U,Ei是用于图像级实体性预测和像素级预测,使用低级图像特征P2(源自图像编码器Θ(I))。然后公式化是这个样
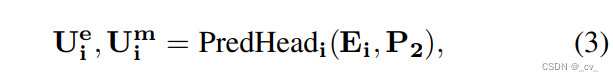
其中uie和uim分别表示实体预测和像素级掩码输出。在这里,我们使用i下标来区分图像级嵌入和掩码输出与关联模块的输出。
-
Association Module.
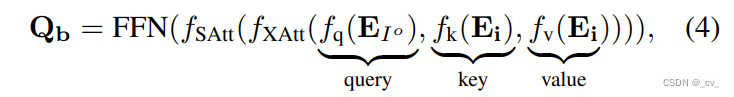
所谓的关联模块长这个样子,从里面看起f{q,k,v}(·) are linear transformations.然后就是里面的各个E,我们将全图像EI o的图像级嵌入作为查询,而将所有图像级嵌入EI作为关键字和值。
在这里我们说一下为什么会有E Io和Ic,
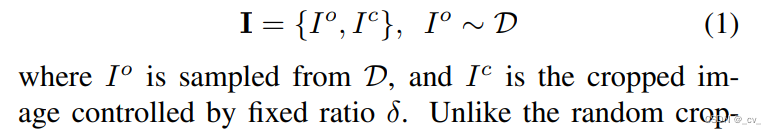
这个解释的很清楚,在一个 dataloader D 中,输入是两部分的,一部分是完整的图像,另一部分是经过裁剪的图像,两者都会经过缩放。
然后就是外面的fXAtt和fSAtt就是交叉注意力和自注意力,FFN 是一个feed-forward network。至于这个关联模块是用来干什么,后面看完就清楚了,或者看流程图也能看懂。 -
Batch-level Decoder
这个模块的公式放出来大家自己都懂了,和前面的模块是一样的,但是有细微差别在于他是Batch-level的。

Ok,很熟悉。 -
training and Inference
在训练期间分别用了两个Loss函数,Li and Lb,一个是image-level的预测,一个是batch-level的预测,这两种损失的主要区别在于完整图像和裁剪图像中的相同实体是否绑定到同一个查询。这个怎么理解呢,就是一个Q去查的是每个图像里面的物体,查到东西就行。另一个Q是因为一个batch是包含了两张图片的一个是完整的一个是裁切过的,所以这个Q是要查两张图里面一个东西,感觉像是做一个对齐和强化。这样的设计应该是这个模型效果好的原因之一。

然后就是在做推理的时候,对于最终的分割输出,是通过使用平均操作融合从完整图像和4个角的每个裁剪中获得的逐像素掩码预测。就是全图和四个角的裁切都用到了,然后融合一下,就是这样。
至于剩下的就是各种实验去验证数据集和模型设计的有效性了,就没什么好说的,这篇paper就是这样了,感兴趣的可以去对着code仔细看一下。







![[ruby on rails] postgres sql explain 优化](https://img-blog.csdnimg.cn/2277e669369c453f8ec8d2aef2d51b13.png)