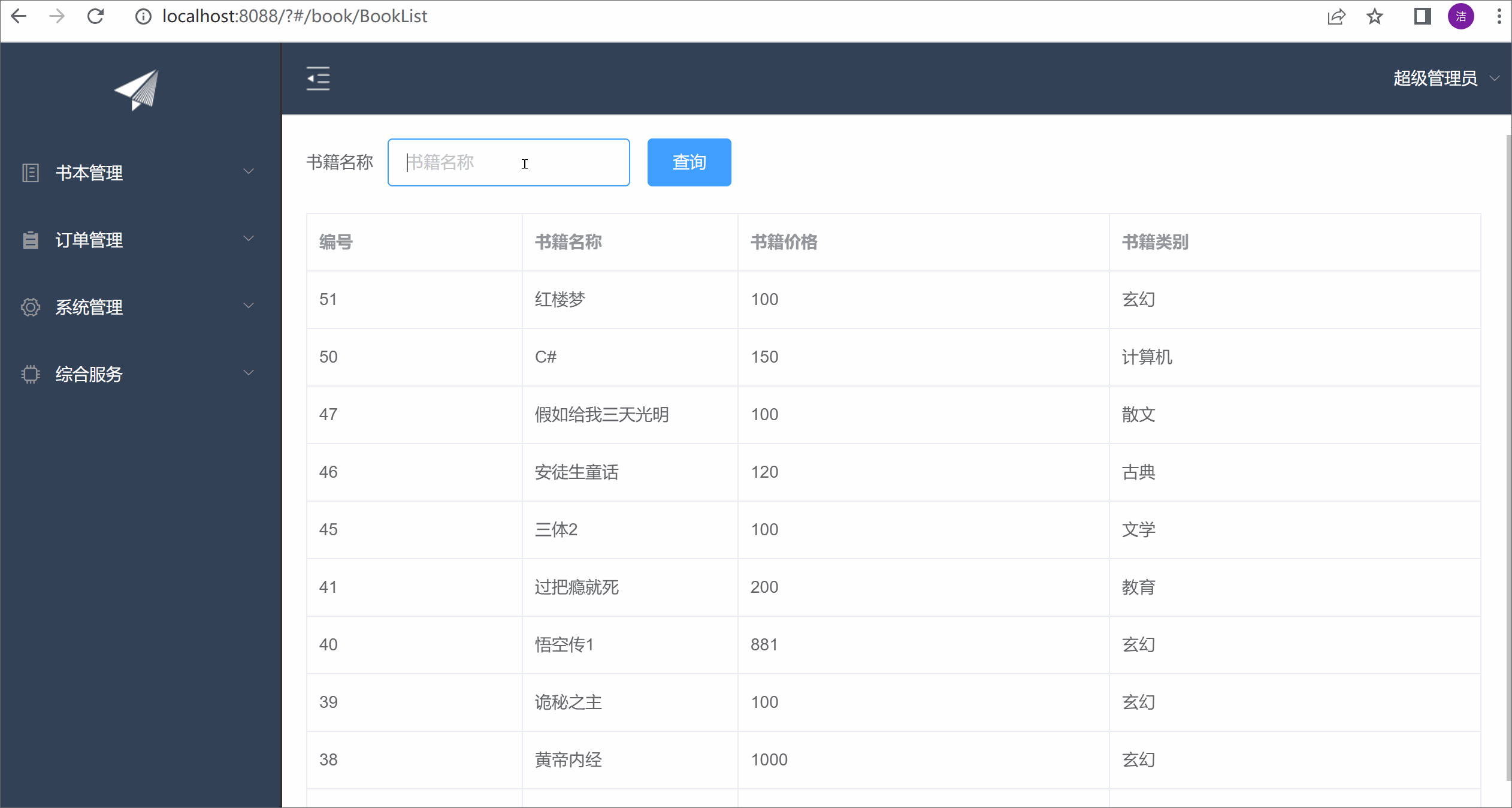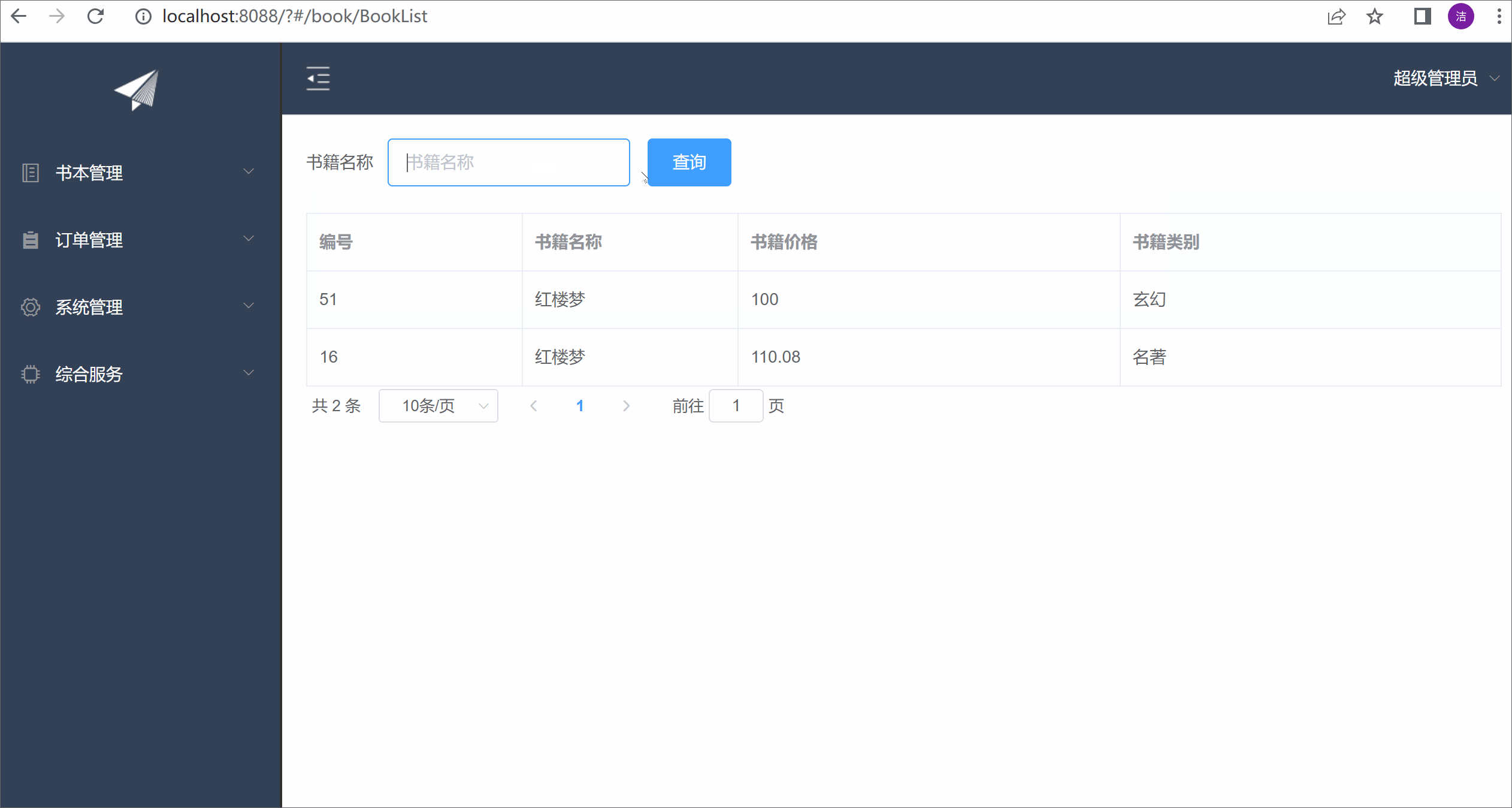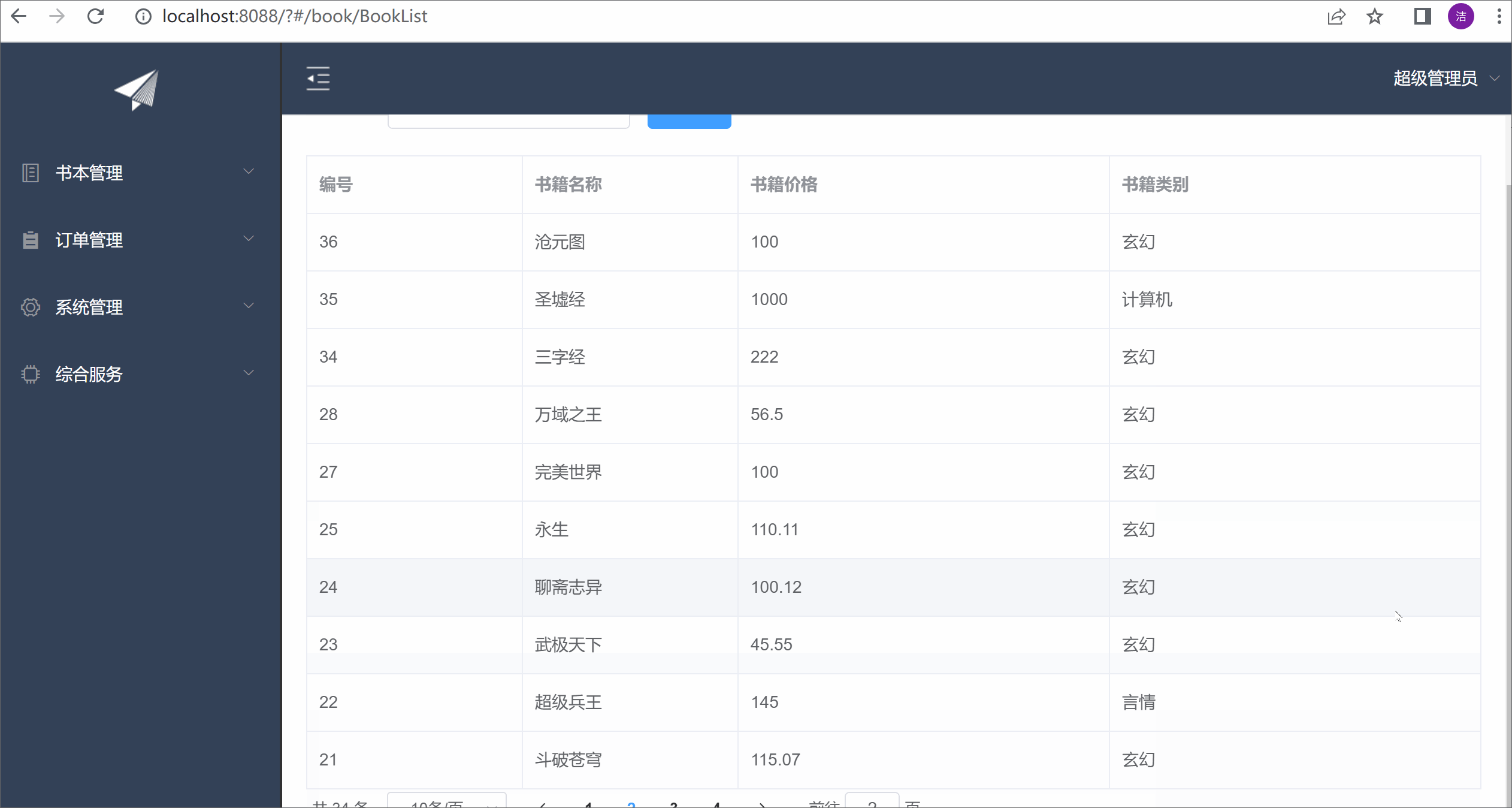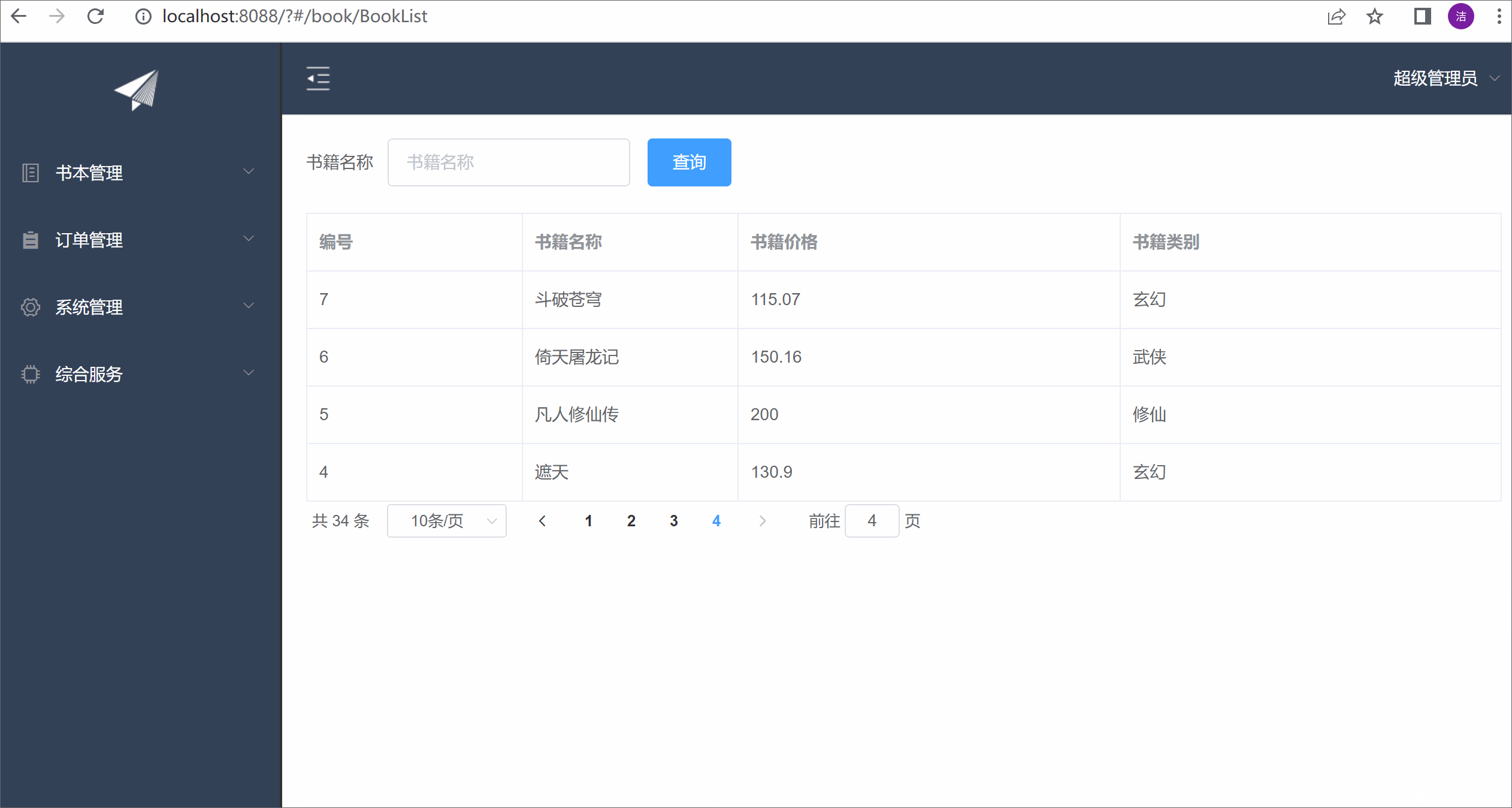
从用户请求的Headers反反爬
在访问某些网站的时候,网站通常会用判断访问是否带有头文件来鉴别该访问是否为爬虫,用来作为反爬取的一种策略。很多网站都会对Headers的User-Agent进行检测,还有一部分网站会对Referer进行检测(一些资源网站的防盗链就是检测Referer)。针对这种反爬机制,我们可以伪装headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值修改为目标网站域名或者为上一个请求地址。
分析Chrome的头信息
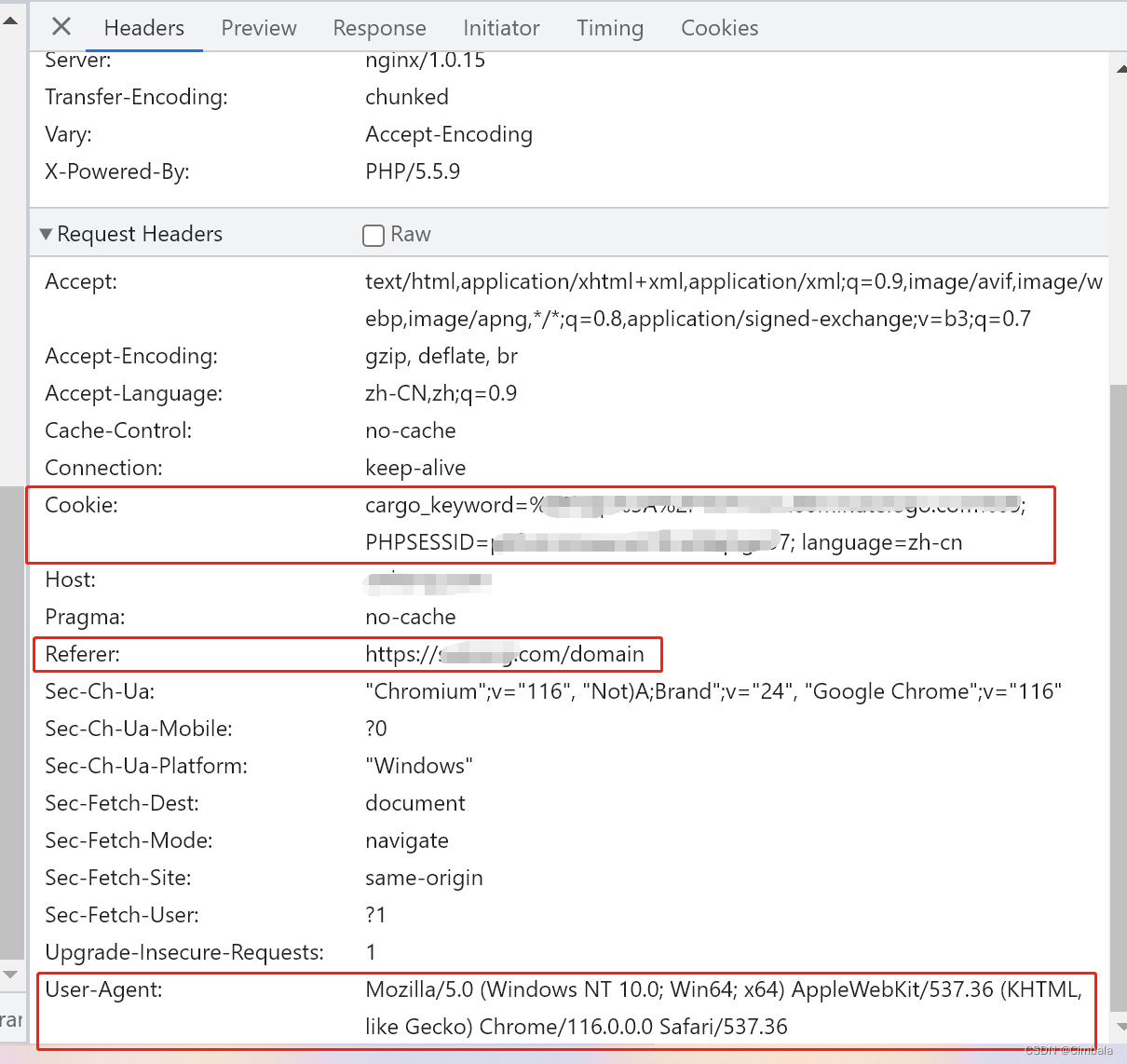
访问请求头中包含了浏览器以及系统的信息(headers所含信息众多,其中User-Agent就是用户浏览器身份的一种标识,具体可自行查询)、Referer、Cookie。
代码
引入依赖
<dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.16.1</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>easyexcel</artifactId><version>3.3.2</version></dependency>
@SpringBootTest
class CrawlerApplicationTest {@Testvoid contextLoads() {Set<String> domainResult = new HashSet<>();String urlStr = "http://ssssss.com/domain";int pageSize = 0;try {for (int i = 0; i < 194994; i++) {String crawlerUrl = "";if (i == 0) {crawler(urlStr, domainResult, null);
// crawlerUrl = "http://swkong.com/domain/index" + pageSize + ".html";
// System.out.println(pageSize);
// System.out.println(crawlerUrl);} else {String referrerUrl = "";if (i == 1) {referrerUrl = "http://ssssss.com/domain";} else {referrerUrl = "http://ssssss.com/domain/index" + (pageSize - 1) + ".html";}crawlerUrl = "http://ssssss.com/domain/index" + pageSize + ".html";crawler(crawlerUrl, domainResult, referrerUrl);System.out.println(pageSize);pageSize += 1;System.out.println(crawlerUrl);System.out.println(referrerUrl);}System.out.println("-----------------------------");}} catch (Exception e) {e.printStackTrace();System.out.println(domainResult.size());System.out.println("catch");} finally {System.out.println(domainResult.size());writeExcel(domainResult);}}public void crawler(String urlStr, Set<String> domainResult, String referrer) throws IOException, InterruptedException {Document parse = sendRequest(urlStr, referrer);Elements dispdomain = Objects.requireNonNull(parse.getElementById("dispdomain")).getElementsByAttribute("href");getDomain(dispdomain, domainResult);System.out.println("请求地址:" + urlStr);System.out.println("__________________________________________");
// Elements xpage = Objects.requireNonNull(parse.getElementById("xpage")).getElementsByAttribute("href");
// System.out.println(xpage);
// String crawlerUrl = "http://swkong.com" + xpage.get(page).attr("href");}public void getDomain(Elements elements, Set<String> result) {for (int i = 0; i < elements.size(); i++) {String attr = elements.get(i).select("a").attr("href");if (attr.contains("?q=")) {String s = attr.split("q=")[1];result.add(s);}}System.out.println(result.size());}public Document sendRequest(String urlStr, String referrer) throws IOException {Map<String, String> cookies = new HashMap<>();cookies.put("cargo_keyword", "xxxxxxxxxxxxxxxxx");cookies.put("PHPSESSID", "xxxxxxxxxxxxxxxxx");cookies.put("language", "zh-cn");if (StringUtils.hasText(referrer)) {return Jsoup.connect(urlStr).timeout(5000).ignoreContentType(true).userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36").cookies(cookies).referrer(referrer).get();}return Jsoup.connect(urlStr).timeout(5000).ignoreContentType(true).userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36").cookies(cookies).get();}public void writeExcel(Set<String> domainResult) {List<DomainDto> resultExcel = new ArrayList<>();for (String domain : domainResult) {DomainDto domainDto = new DomainDto();domainDto.setDomainUrl(domain);resultExcel.add(domainDto);}String path = "D:\\" + System.currentTimeMillis() + ".xlsx";EasyExcel.write(path, DomainDto.class).sheet("域名").doWrite(resultExcel);}