文章目录
- 并查集
- 1.概念
- 2. 实现
- LRUCache
- 1. 概念
- 2. 实现
- 使用标准库实现
- 自主实现
并查集
1.概念
并查集是一个类似于森林的数据结构,并、查、集指的是多个不相干的集合直接的合并和查找,并查集使用于N个集合。适用于将多个元素分成多个集合,在分成集合的过程中要反复查询某两个元素是否存在于同一个集合的场景。
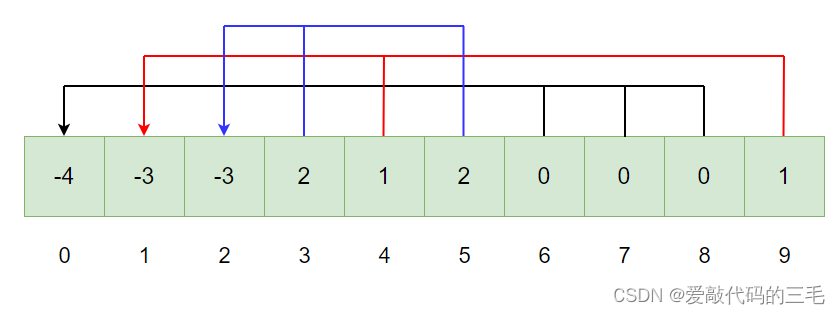
比如说:总共有10个人要去执行任务,他们想进行组队,他们的编号从0到9,入下图:假设-1表示队伍里存在一人。
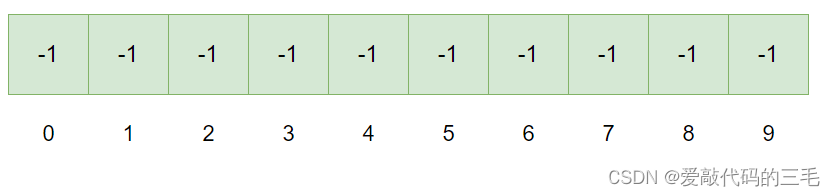
他们组成了3个队伍, 0 , 6 , 7 , 8 {0,6,7,8} 0,6,7,8 一队, 0 0 0是队长,组队这个操作其实就是进行了合并。
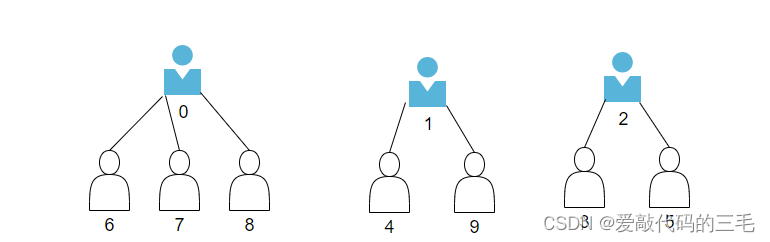
上图的关系可以用数组来表示:
- 数组的下标对应集合中元素的编号
- 数组中如果为负数,负号代表根,数字代表该集合中元素个数
- 数组中如果为非负数,代表该元素双亲在数组中的下标
从图可以看出,0下标就是一个根节点(队长),他有三个子节点(队员),同样的下标1和小标2都是一个根节点,它们都有两个子节点。
2. 实现
/*** 并查集*/
public class UnionFind {private int[] elem;public UnionFind(int size) {this.elem = new int[size];Arrays.fill(elem,-1);}/*** 查找x的根* @param x* @return*/public int findRoot(int x) {if (elem[x] == -1) {return x;}while (elem[x] >= 0) {x = elem[x];}return x;}/*** 判断两个元素是否在同一个集合* @param x* @param y* @return*/public boolean isSameSet(int x, int y) {int xRoot = findRoot(x);int yRoot = findRoot(y);if (xRoot == yRoot) {return true;}return false;}/*** 合并x和y,x和y必须是根节点,先查找根* @param x* @param y* @return*/public void union(int x,int y) {int xRoot = findRoot(x);int yRoot = findRoot(y);if (xRoot == yRoot) {// 在同一个集合的元素无需合并return;}elem[xRoot] += elem[yRoot];elem[yRoot] = xRoot;}/*** 获取并查集中有多少集合* @return*/public int getCount() {int count = 0;for (int tmp : elem) {if (tmp < 0) {count++;}}return count;}}
LRUCache
1. 概念
LRU是Least Recently Used的缩写,意思是最近最少使用,它是一种Cache替换算法 ,LRUCache其实就是淘汰最近最少使用的缓存的一种数据结构,Cache的容量有限,因此当Cache的容量用完后,而又有新的内容需要添加进来时, 就需要挑选并舍弃原有的部分内容,从而腾出空间来放新内容。LRU Cache 的替换原则就是将最近最少使用的内容替换掉。
2. 实现
实现高效的LRUCache可以使用哈希表+双向链表来实现。哈希表的增删改查都是 O ( 1 ) O(1) O(1),而双向链表的任意位置的删除也是 O ( 1 ) O(1) O(1)。
JDK中类似LRUCahe的数据结构LinkedHashMap
LinkedHashMap和HashMap有点类似,LinkedHashMap也是使用数组+链表实现,但LinkedHashMap使用的是双向链表且维护了一个头节点和尾巴节点,同时保证了插入顺序,也可以动态调整元素顺序。
LinkedHashMap的构造方法参数:
- initialCapacity:初始容量大小,使用无参构造方法时,此值默认是16
- loadFactor:加载因子,使用无参构造方法时,此值默认是 0.75f
- access Order:false: 基于插入顺序 true: 基于访问顺序
如果accessOrder为false表示按照插入顺序进行排序,如果为true表示按照访问顺序来排序,假设访问元素全部插入后,访问了1获取了张三,那么张三就会被放到末尾去,反之设置为false则不会进行调整。
public static void main(String[] args) {Map<Integer,String> map = new LinkedHashMap<>(16,0.75f,false);map.put(1,"张三");map.put(2,"李四");map.put(3,"王五");map.put(4,"张六");map.put(5,"李七");System.out.println(map);map.get(2);map.get(1);map.put(4,"里");System.out.println(map);}运行结果
{1=张三, 2=李四, 3=王五, 4=张六, 5=李七}
调用后
{1=张三, 2=李四, 3=王五, 4=里, 5=李七}
假设把LinkedHashMap的参数改为true
public static void main(String[] args) {Map<Integer,String> map = new LinkedHashMap<>(16,0.75f,true);map.put(1,"张三");map.put(2,"李四");map.put(3,"王五");map.put(4,"张六");map.put(5,"李七");System.out.println(map);System.out.println("调用后");map.get(2);map.get(1);map.put(4,"里");System.out.println(map);}
运行结果
{1=张三, 2=李四, 3=王五, 4=张六, 5=李七}
调用后
{3=王五, 5=李七, 2=李四, 1=张三, 4=里}
使用标准库实现
继承LinkedHashMap重写关键方法removeEldestEntry即可实现LRUCache,removeEldestEntry方法默认返回false,返回false表示LinkedHashMap没有容量限制,如果返回true表示如果元素超过了capacity就会抛弃最旧元素,最旧元素可能是最先插入的元素,也可能是插入后一直没有使用的元素也是最旧元素。
public class MyLRUCache extends LinkedHashMap<Integer,Integer> {private int capacity;/***super(容量,负载因子,基于插入顺序/基于访问顺序);* @param capacity*/public MyLRUCache(int capacity) {super(capacity,0.75f,true);this.capacity = capacity;}public int get(int key) {Integer ret = super.get(key);if (ret == null) {return -1;}return super.get(key);}/*** 重写关键方法,默认放回false,重写后如LRU中元素大于指定容量capacity就会删除最旧元素* @param eldest* @return*/@Overrideprotected boolean removeEldestEntry(Map.Entry eldest) {return size() > capacity;}public void put(int key, int value) {super.put(key, value);}public static void main1(String[] args) {Map<Integer,String> map = new LinkedHashMap<>(16,0.75f,true);map.put(1,"张三");map.put(2,"李四");map.put(3,"王五");map.put(4,"张六");map.put(5,"李七");System.out.println(map);System.out.println("调用后");map.get(2);map.get(1);map.put(4,"里");System.out.println(map);}public static void main(String[] args) {MyLRUCache lruCache = new MyLRUCache(4);lruCache.put(1,0);lruCache.put(2,0);lruCache.put(3,0);lruCache.put(4,0);lruCache.put(5,0);System.out.println(lruCache.get(1));System.out.println(lruCache);}}自主实现
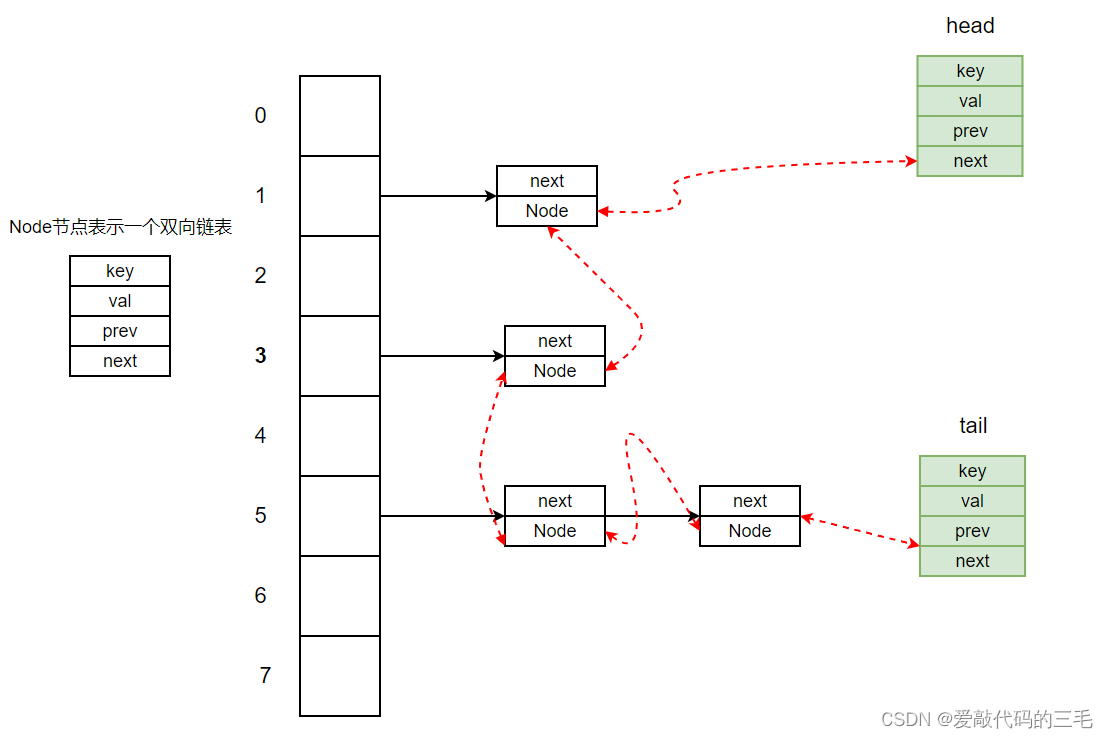
自主实现一个LRU使用标准库中的HashMap和手写的带头尾傀儡节点的双向链表来实现。
- HashMap的key存放的是存入的键值key,value是一个双向链表的节点
- 双向链表节点属性有存放的键(key)和值(value),前驱节点和后继节点
- LRU中有两个傀儡节点保证插入的顺序,每次插入元素都插入到tail节点前面
- 每次元素达到最大缓存容量时,默认丢失head节点的后一个元素
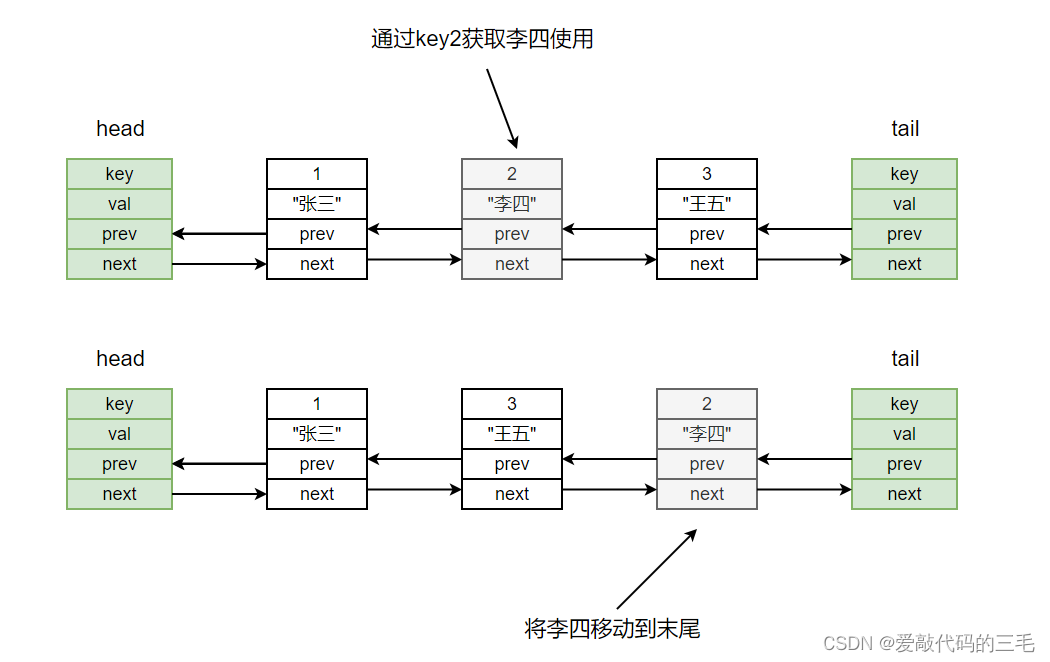
- 没一次get或者put,也就是获取或者更新元素,都把该元素移动到末尾,也就是tail前面
使用元素移动
public class LRUCache {static class Node {int key;int val;Node prev;Node next;public Node() {}public Node(int key,int val) {this.key = key;this.val = val;}@Overridepublic String toString() {return "Node{" +"key=" + key +", val=" + val +'}';}}// 最大容量private int capacity;// 头尾傀儡节点private Node head;private Node tail;private Map<Integer,Node> map;// 链表有效元素个数private int size;public LRUCache(int capacity) {this.capacity = capacity;this.map = new HashMap<>();this.head = new Node();this.tail = new Node();this.head.next = tail;this.tail.prev = head;}/*** 从LRUCache中获取元素* @param key* @return*/public int get(int key) {Node node = map.get(key);if (node != null) {// 把node放到链表尾部moveNodeIsTail(node);return node.val;}// 不存在返回-1return -1;}/*** 将node节点移动到链表尾部* @param node*/private void moveNodeIsTail(Node node) {node.prev.next = node.next;node.next.prev = node.prev;tail.prev.next = node;node.prev = tail.prev;node.next = tail;tail.prev = node;}/*** 添加元素到LRUCache中* @param key* @param val*/public void put(int key,int val) {Node tmp = map.get(key);if (tmp == null) {// 不存在就创建节点添加到尾部Node node = new Node(key,val);map.put(key,node);tail.prev.next = node;node.prev = tail.prev;node.next = tail;tail.prev = node;this.size++;// 判断是否超过容量capacityif (this.size > capacity) {// 丢弃链表第一个元素(长时间未使用元素)Node cur = head.next;cur.next.prev = head;head.next = cur.next;map.remove(cur.key);}} else {// 存在就直接更新值并放到尾部tmp.val = val;moveNodeIsTail(tmp);}}public void print() {Node cur = head.next;while (cur != tail) {System.out.print(cur+" ");cur = cur.next;}System.out.println();}
}



![[Machine learning][Part3] numpy 矢量矩阵操作的基础知识](https://img-blog.csdnimg.cn/5ebe08b97ac94f8283df2adfd4a95054.png)