中文LLaMA
尽管 LLaMA 和 Alpaca 在 NLP 领域取得了重大进展, 它们在处理中文语言任务时, 仍存在一些局限性。这 些原始模型在字典中仅包含数百个中文 tokens (可以理解为单词),导致编码和解码中文文本的效率受到了很大 影响。
之前已经对原始 LLaMA 技术进行了深入解读, LLaMA 基于 transformer 结构进行了一些改进, 比如预归一 化、 SwiGLU 激活函数以及旋转embedding 。LLaMA 的参数总数在 7B 到 65B 之间。实验数据表明, LLaMA 在 保持更小模型尺寸的同时,与其他的 LLM 相比(比如 GPT-3),具有相当的竞争性。
LLaMA 在公开可用的语料库中预训练了 1T 到 1.4T 个 token,其中大部分数据是英文, 因此 LLaMA 理解 和生成中文的能力受到限制。为了解决这个问题, 中文版的 LLaMA 在原始 LLaMA 模型的基础上, 扩充了包含 20K 中文 token 的中文词典, 提升了编码效率, 从而提升了模型处理和生成中文文本的能力, 增强了基础语义理 解能力。
然而,直接在中文语料库上对 LLaMA 进行预训练也存在相应的挑战:
-
1、原始 LLaMA tokenizer 词汇表中只有不到一千个中文字符。虽然 LLaMA tokenizer 可以通过回退到字节 来支持所有的中文字符,但这种回退策略会显著增加序列长度,同时会降低处理中文文本的效率。
-
2、字节 tokens 不仅用于表示中文字符, 还用于表示其它 UTF-8 tokens,这使得字节 tokens 难以学习中文 字符的语义含义。
为了解决这些问题,作者提出了以下两个解决方案来扩展 LLaMA tokenizer 中的中文词汇:
-
1、在中文语料库上使用 SentencePiece 训练一个中文tokenizer,使用 20000 个词汇大小。然后将中文tokenizer 与原始 LLaMA tokenizer 合并, 通过组合它们的词汇表, 最终获得一个合并的 tokenizer,称为中文 LLaMA tokenizer,词汇表大小为 49953。
-
2、为了使模型适应上一步产生的中文 LLaMA tokenizer,研究人员将 word embeddings 和语言模型的head 从 V × H 调整为 V’× H 的形状, 其中 V = 32,000 代表原始词汇表的大小, 而 V’ = 49,953 则是中文 LLaMA tokenizer 的词汇表大小。新行附加到原始嵌入矩阵的末尾, 确保原始词汇表中的 token embedding 不受影 响。
使用中文 LLaMA 分词器, 相比于原始的 LLaMA 分词器, 生成的 token 数减少了一半左右, 原因是, 前者 的编码长度有了明显的减少, 如下表所示。给定固定的上下文长度时, 相比于原始 LLaMA 分词器, 新模型可 以容纳约两倍的信息, 且生成速度快两倍。这表明, 新模型在提高 LLaMA 模型的中文理解和生成能力方面是有 效的。

原始 LLaMA 和中文 LLaMA 的 tokenizer 对比示例。
得到了中文 LLaMA 分词器后,研究人员使用中文 LLaMA 分词器,基于标准 Casual Language Modeling(CLM)
任务, 对中文 LLaMA 模型进行预训练。对于给定的输出 token 序列: x = (x0 , x1 , x2 , ..., xi−1 ),模型使用自回归 的方式训练,以预测下一个 token。目标即最小化负对数似然:
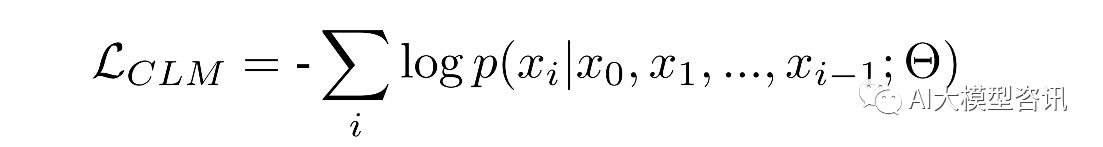
其中, xi 表示预测的 token;x0 , x1 , x2 , ..., xi−1 表示上下文。
采用 LoRA 的高效参数微调方法,在冻结原模型 LLaMA 参数的情况下,通过往模型中加入额外的网络层,并 只训练这些新增的网络层参数。这种方法大大减少了总可训练参数, 使得用更少的计算资源训练 LLaMA,LoRA 的原理其实并不复杂, 它的核心思想是在原始预训练语言模型旁边增加一个旁路, 做一个降维再升维的操作, 来 模拟所谓的 intrinsic rank (预训练模型在各类下游任务上泛化的过程其实就是在优化各类任务的公共低维本征 (low-dimensional intrinsic) 子空间中非常少量的几个自由参数)。为了在计算资源紧张的情况下实现参数高效的 训练,作者将 LoRA 训练应用于论文中的所有中文 LLaMA 和 Alpaca 模型,包括预训练和微调阶段。

在训练时, 固定预训练语言模型的参数, 只训练降维矩阵 A 与升维矩阵 B。而模型的输入输出维度不变, 输 出时将 BA 与预训练语言模型的参数叠加。用随机高斯分布初始化 A,用 θ 矩阵初始化 B。这样能保证训练开始 时,新增的通路 BA = θ 从,而对模型结果没有影响。
在推理时, 将左右两部分的结果加到一起即可, h = Wx + BAx = (W + BA)x,所以, 只要将训练完成的 矩阵乘积 BA 跟原本的权重矩阵 W 加到一起作为新权重参数替换原始预训练语言模型的 W 即可, 不会增加额 外的计算资源。
Tokenizer
LLaMA 的训练语料以英文为主, 使用字节对编码(BPE) 算法对数据进行分词, 使用 SentencePiece 的实现, 词表大小只有 32000。词表里的中文 token 很少, 只有几百个, 预训练中没有出现过或者出现得很少的语言学习 得不充分,而且,对中文分词的编码效率比较低。值得注意的是,作者将所有数字分割成单个数字。
讲解 SentencePiece 之前, 我们先讲解下分词器(Tokenizer)。简单点说分词器就是将字符序列转化为数字序 列, 对应模型的输入。通常情况下, Tokenizer 有三种粒度: word/char/subword,这三种粒度分词截然不同, 各有 利弊:
-
1. word: 按照词进行分词, 如: Today is sunday. 则根据空格或标点进行分割 [today, is, sunday, .],对于 word 粒 度分词, 其优点是词的边界和含义得到保留; 缺点是: 1) 词表大, 稀有词学不好; 2 ) OOV (可能超出词 表外的词); 3) 无法处理单词形态关系和词缀关系, 会将两个本身意思一致的词分成两个毫不相同的 ID, 在英文中尤为明显,如: cat ,cats。
-
2. character:按照单字符进行分词, 就是以 char 为最小粒度。如: Today is sunday. 则会分割成 [t,o,d,a,y, .... ,s,u,n ,d ,a,y ,.],对于 character 粒度分词, 其优点是词表极小, 比如: 26 个英文字母几乎可以 组合出所有词, 5000 多个中文常用字基本也能组合出足够的词汇; 缺点是: 1) 无法承载丰富的语义, 英 文中尤为明显,但中文却是较为合理,中文中用此种方式较多。 2)序列长度大幅增长;
-
3. subword:按照词的 subword 进行分词。如: Today is sunday. 则会分割成 [to,day,is ,s,un,day ,.],为 了平衡以上两种方法, 提出了基于 subword 进行分词: 它可以较好的平衡词表大小与语义表达能力; 常见的子词算法有 Byte-Pair Encoding (BPE) / Byte-level BPE (BBPE )、WordPiece 、SentencePiece 等。
BPE 和 BBPE : BPE 即字节对编码。其核心思想是从字母开始, 不断找词频最高、且连续的两个 token 合 并, 直到达到目标词数。 BBPE:BBPE 核心思想将 BPE 的从字符级别扩展到子节(Byte) 级别。 BPE 的一个问 题是如果遇到了 unicode 编码, 基本字符集可能会很大。 BBPE 就是以一个字节为一种“字符”,不管实际字符集 用了几个字节来表示一个字符。这样的话, 基础字符集的大小就锁定在了 256 (28 )。采用 BBPE 的好处是可以 跨语言共用词表, 显著压缩词表的大小。而坏处就是, 对于类似中文这样的语言, 一段文字的序列长度会显著 增长。因此, BBPE based 模型可能比 BPE based 模型表现的更好。然而, BBPE sequence 比起 BPE 来说略长, 这也导致了更长的训练/推理时间。 BBPE 其实与 BPE 在实现上并无大的不同, 只不过基础词表使用256 的字节集。
WordPiece : WordPiece 算法可以看作是 BPE 的变种。不同的是, WordPiece 基于概率生成新的 subword 而 不是下一最高频字节对。 WordPiece 算法也是每次从词表中选出两个子词合并成新的子词。 BPE 选择频数最高的 相邻子词合并,而 WordPiece 选择使得语言模型概率最大的相邻子词加入词表。
SentencePiece : SentencePiece 它是谷歌推出的子词开源工具包, 它是把一个句子看作一个整体, 再拆成片 段, 而没有保留天然的词语的概念。一般地, 它把空格也当作一种特殊字符来处理, 再用 BPE 或者 Unigram 算法 来构造词汇表。 SentencePiece 除了集成了 BPE、ULM 子词算法之外, SentencePiece 还能支持字符和词级别的分 词。当前主流的一些开源大模型有很多基于 BBPE 算法使用 SentencePiece 实现分词器,下面来讲解 SentencePiece 工具的具体使用。
SentencePiece 是一种无监督的文本 tokenizer 和detokenizer ,主要用于基于神经网络的文本生成系统, 其中, 词汇量在神经网络模型训练之前就已经预先确定了。SentencePiece 实现了 subword 单元(例如,字节对编码 (BPE)) 和 unigram 语言模型), 并可以直接从原始句子训练字词模型 (subword model)。这使得我们可以制作一个不依赖 于特定语言的预处理和后处理的纯粹的端到端系统。 SentencePiece 特性如下:
-
Token 数量是预先确定的: 神经网络机器翻译模型通常使用固定的词汇表进行操作。与大多数假设无限词 汇量的无监督分词算法不同, SentencePiece 在训练分词模型时, 使最终的词汇表大小固定, 例如: 8k 、16k 或 32k。
-
从原始句子进行训练: 以前的子词(sub-word) 实现假设输入句子是预标记(pre-tokenized) 的。这种约束是 有效训练所必需的, 但由于我们必须提前运行依赖于语言的分词器, 因此使预处理变得复杂。 SentencePiece 的实现速度足够快, 可以从原始句子训练模型。这对于训练中文和日文的 tokenizer 和 detokenizer 很有用, 因为在这些词之间不存在明确的空格。
-
空格被视为基本符号: 自然语言处理的第一步是文本 tokenization, 例如, 标准的英语分词器(tokenizer) 将 对文本 Hello world 进行分段。分为 [Hello] [World] [.] 这三个 token。这种情况将导致原始输入和标记化 (tokenized) 序列不可逆转换。例如, “World”和“. ”之间没有空格的信息。空格将从标记化序列中删除, 例如:Tokenize( “World. ”) == Tokenize( “World . ”)。但是, SentencePiece 将输入文本视为一系列 Unicode 字符。空格也作为普通符号处理。为了明确地将空格作为基本标记处理, SentencePiece 首先使用元符号”ff” (U+2581) 转义空格。 HelloffWorld. 然后, 将这段文本分割成小块, 例如: [Hello] [ffWor] [ld] [.]。由于空格保 留在分段文本中, 我们可以毫无歧义地对文本进行 detokenize 。detokenized = ”.join(pieces).replace(’ ’, ’ ’), 此特性可以在不依赖特定于语言的资源的情况下执行 detokenization。
-
子词正则化和 BPE-dropout: 子词正则化和 BPE-dropout 是简单的正则化方法, 它们实际上通过实时子词采 样来增强训练数据,这有助于提高神经网络机器翻译(NMT)模型的准确性和鲁棒性。
中文 LLaMA 经过词表扩充后,我们来对比一下几个基座模型 Tokenizer 的区别,如下表所示:
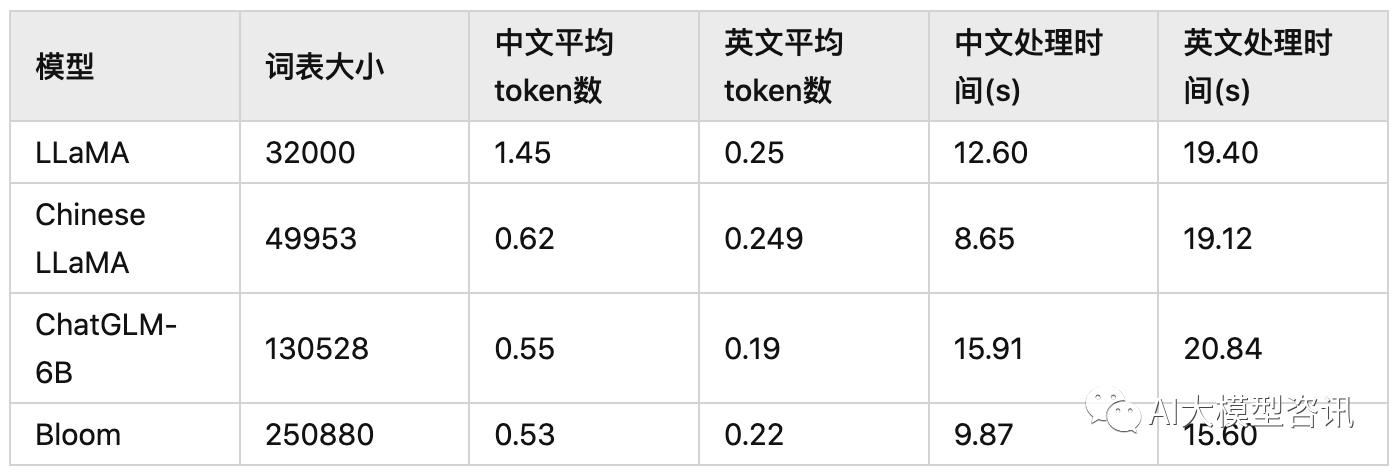
基座模型的 tokenizer 对比示例
“中文平均 token 数”表示了 tokenizer 分词后,每个中文字符对应的平均 token 数。从结果来看:
-
LLaMA 的词表是最小的, LLaMA 在中英文上的平均 token 数都是最多的, 这意味着 LLaMA 对中英文分词都会比较碎, 比较细粒度。尤其在中文上平均 token 数高达 1.45,这意味着 LLaMA 大概率会将中文字 符切分为 2 个以上的token。
-
中文 LLaMA(Chinese LLaMA) 扩展词表后, 中文平均 token 数显著降低, 会将一个汉字或两个汉字切分为 一个 token ,提高了中文编码效率。
-
ChatGLM-6B 是平衡中英文分词效果最好的tokenizer 。由于词表比较大,中文处理时间也有增加。
-
BLOOM 虽然是词表最大的, 但由于是多语种的, 在中英文上分词效率与 ChatGLM-6B 基本相当。需要注意的是, BLOOM 的 tokenizer 用了 transformers 的 BloomTokenizerFast 实现,分词速度更快。
从一个例子来直观对比不同 tokenizer 的分词结果。“男儿何不带吴钩, 收取关山五十州。”共有 16 字。几个 tokenizer 的分词结果如下:
-
LLaMA 分词为 24 个 token :[ ’ 男’, ’<0xE5>’, ’<0x84>’, ’<0xBF>’, ’ 何’, ’ 不’, ’<0xE5>’, ’<0xB8>’, ’<0xA6>’, ’<0xE5>’, ’<0x90>’, ’<0xB4>’, ’<0xE9>’, ’<0x92>’, ’<0xA9>’, ’,’, ’ 收’, ’ 取’, ’ 关’, ’ 山’, ’ 五’, ’ 十’, ’ 州’, ’。’]
-
Chinese LLaMA 分词为 14 个 token :[ ’ 男’, ’ 儿’, ’ 何’, ’ 不’, ’ 带’, ’ 吴’, ’ 钩’, ’ ,’, ’ 收取’, ’ 关’, ’ 山’, ’ 五十’, ’ 州’, ’。 ’]
-
ChatGLM-6B 分词为 11 个 token :[ ’ 男儿’, ’ 何不’, ’ 带’, ’ 吴’, ’ 钩’, ’,’, ’ 收取’, ’ 关山’, ’ 五十’, ’ 州’, ’。 ’]
-
Bloom 分词为 13 个 token :[’ 男’, ’ 儿’, ’ 何不’, ’ 带’, ’ 吴’, ’ 钩’, ’ ,’, ’ 收取’, ’ 关’, ’ 山’, ’ 五十’, ’ 州’, ’。 ’]
中文 Alpaca
在获得了预训练的中文 LLaMA 模型后, 作者利用斯坦福羊驼(Alpaca) 训练采用的方法——指令微调继续 训练该模型, 得到一个遵循指令的 LLaMA 模型—— 中文 Alpaca。继斯坦福羊驼(Stanford Alpaca) 之后, UC 伯 克利、 CMU、斯坦福等机构的学者, 联手发布了最新开源大模型骆马(Vicuna),包含 7B 和 13B 参数。我们已 经清楚 ChatGPT 的训练步骤, 可以借鉴 ChatGPT 的训练步骤, 得到一个类 ChatGPT 大模型, 下面以 Alpaca 为例介绍:
-
第一步:收集标注数据(人工标注的 prompt + 期望回答),在已有的大语言模型基础上(GPT3 、GPT-3.5、 ChatGPT),进行有监督训练,得到“模型 A ”。
-
第二步: 收集对比数据。给定一个 prompt,第一步的模型会产生多个输出, 标注人员会对这些输出答案进 行排序,训练一个 pairwise 模型(Reward 模型),即“模型 B”,模型 B 与模型 A 的模型结构不同。
-
第三步: 基于第一步、第二步的模型, 基于 PPO 强化学习算法, 训练得到最终模型, 即“模型 C”,模型 C 与模型 A 的结构相同。
因此, 在类 ChatGPT 大模型的训练过程中, 为了进行第一步的训练, 目前通常使用 OPT 、BLOOM 、GPT- J、LLaMA 等开源大模型替代 GPT3 、GPT3.5 等未开源的模型。 Stanford Alpaca 提供了基于“指令遵循数据”对 LLAMA 进行微调(supervised finetuning)的代码,完成了“类 ChatGPT 大模型训练步骤”中的第一步。
Alpaca 7B 是由 Meta 的 LLaMA 7B 模型通过 52K 指令微调得到的模型。 Alpaca 与 OpenAI 的text-davinci-003 (GPT-3.5)表现类似,模型容量惊人的小,易于复现,且复现成本低(<600 美元)。
GPT-3.5 (text-davinci-003) ,ChatGPT ,Claude 和 Bing Chat 等指令遵循模型的功能越来越强大。许多用户定 期与这些模型进行交互, 且在工作中使用它们。尽管这些模型得到了广泛部署, 但它们仍有许多不足之处: 产 生虚假信息、传播社会偏见、甚至制造有毒言论。
为了解决这些紧迫问题, 学术界的参与至关重要。不幸的是, 在学术界进行指令遵循研究十分困难, 因为没 有一个易于实现的模型可以在功能上接近于 closed-source (未开源)模型(比如 OpenAI 的 GPT-3.5 )。
文章提到, Alpaca 小羊驼仅用于学术研究, 禁止任何商业用途。原因有三: 1 、Alpaca 基于 LLaMA,它有 非商业许可证,因此 Alpaca 也必须继承这一点; 2、指令数据基于 OpenAI 的 text-davinci-003,其使用条款禁止 开发与 OpenAI 竞争的模型; 3 、没有设计足够的安全措施,因此羊驼还未准备好作为一般用途。
训练方法
在学术预算下, 训练高质量的指令遵循模型具有两个挑战, 1) 一个强大的预训练语言模型; 2) 高质量的 指令遵循数据。 Meta 最新发布的 LLaMA 模型解决了第一个挑战。对于第二个挑战,根据 self-instruct 论文的介绍, 可以使用现有的强大语言模型, 自动生成指令数据。 Alpaca 正是由LLaMA 7B 模型经过有监督微调结合由OpenAI 的 GPT-3.5 生成的 52K 指令数据训练而来。
下图说明了羊驼模型的训练方法。首先, 从 self-instruct 种子集合中生成 175 个由人类撰写的指令-输出 pair 对。然后提示 text-davinci-003 使用上下文实例中的种子集合,生成更多的指令。通过简化生成过程,对 self-instruct 方法进行了改进,显著降低了成本。上述的数据生产过程产生了 52K 条独特的指令及其对应的输出,使用OpenAI 的 API,花费不足 500 美元。
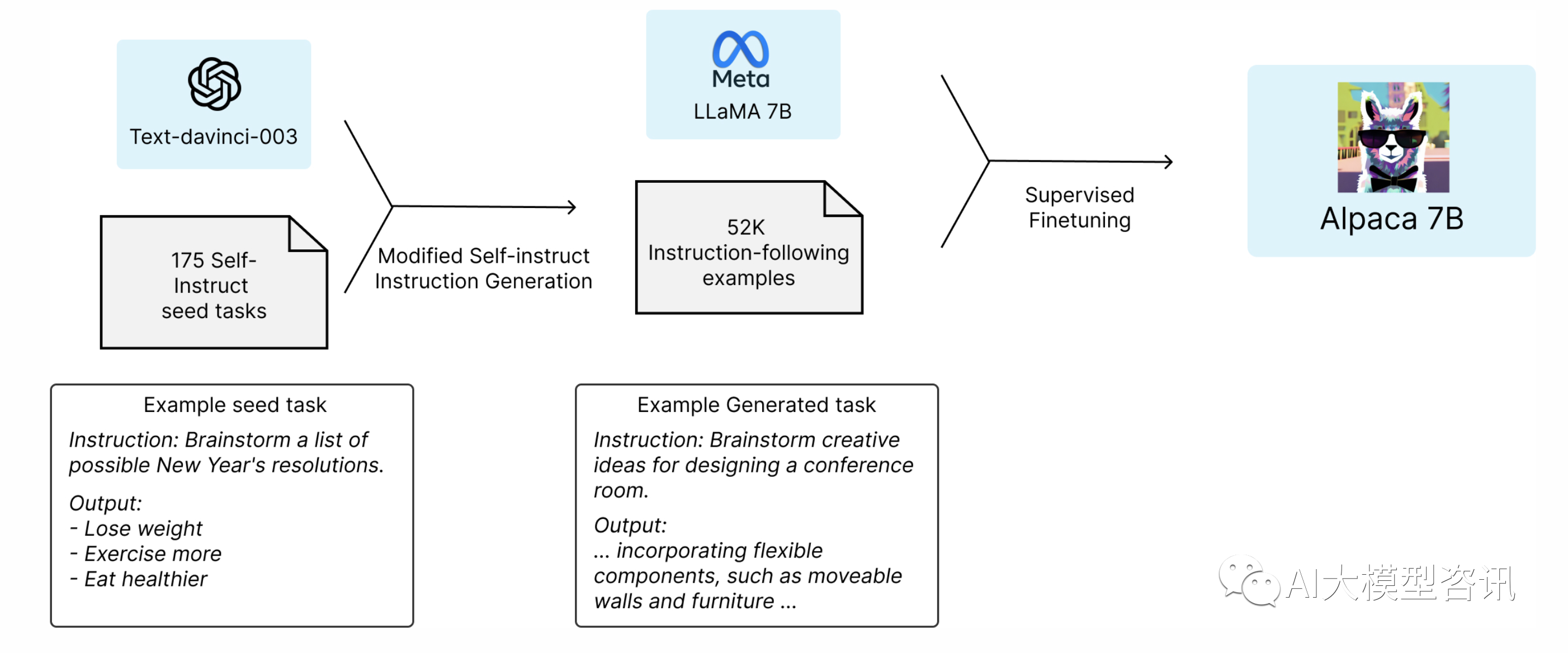
Alpaca的训练示例
得到了这个指令遵循数据集后, 利用全分片数据并行和混合精度训练等技术, 基于 Hugging Face 的训练框 架, 对 LLaMA 模型进行微调。在首次运行中, 在 8 个 80GB A100 显卡上微调 LLaMA-7B 模型, 耗时 3 小时, 这 在大多数云计算供应商上的花费不足 100 美元。
评估和局限
在 self-instruct 评估集合上, 对 Alpaca 进行人类评估。 self-instruct 评估集合由 self-instruct 的作者收集, 涵盖 了一系列面向用户的指令, 包括电子邮件写作、社交媒体、生产力工具。作者对 text-davinci-003 和 Alpaca 7B 进行 了比较, 发现两个模型的性能非常相近: Alpaca 在与text-davinci-003 的比较中, 赢得了 90 胜, 而text-davinci-003 赢得了 89 胜。
文章里也提到了 Alpaca 的一些局限性,包括幻觉、毒性以及偏见。幻觉似乎是羊驼的常见出错模式。
ps: 欢迎扫码关注公众号^_^.