RPC方式的优化
- 聊天系统的中RPC的选择
- Json
- protobuf
- msgpack
聊天系统的中RPC的选择
在RPC方式中,常用的三种方式:Json,protobuf,Msgback
设定一个简单的加和服务,客户端发送一个list给服务端,需要将list的数据都加和之后,返回加和的结果
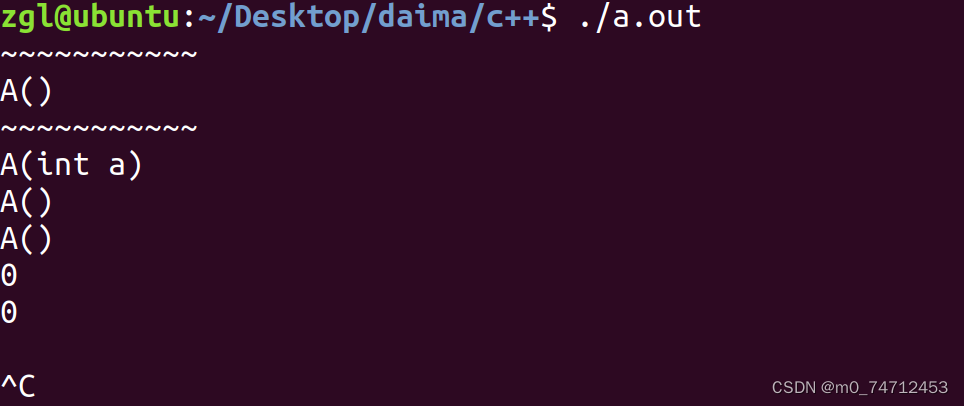
在本地机器中不使用RPC方式:
int sum(list* node){"计算加和值"return res;
}
执行10000,考虑“低数据量”和“高数据量”的两个场景
低数据量:node = [1,2] ,time:1.93ms
高数据量:node = [1,2,3,…], time:52ms
Json
Json是使用最广泛的序列化方式,广泛应用于前后端之间的通信
优点:可读性高,兼容性广泛
{“name“:”heyue“,”sex“:”\u7537“,”company“:”sina“,”age“:30}
缺点:安全性低
如果使用json进行序列化,执行同样的次数耗时:
低数据量:nums=[1,2]: 18590.62ms
高数据量:nums=[1,2,3…,1000]: 20385.60ms
protobuf
protobuf是一种比json性能更高的序列化方式,但是可读性要差一些,由于序列化之后数据是二进制的,所以其可读性会比较差
使用同样的执行次数,
低数据量:nums=[1,2]: 8654.08ms
高数据量:nums=[1,2,3…,1000]: 10014.39ms
protobuf的使用流程:
1、编写一个proto文件,其中定义需要处理的结构化数据(类似于一个结构体,内部定义了不同数据类型)
2、编译proto文件生成C++文件,编译结果为:一个.pb.h文件和一个.pb.c文件
3、编写main代码文件,填充proto文件中的结构体,并且将其序列化到一个数组中
msgpack
msgpcak也是一种二进制的传输协议,比json更小更快,同时整体性能比protobuf更高,也不需要预先设定proto文件,也没有相应的数据校验。
优点:性能高,速度快,序列化之后的数据包小
缺点:由于没有数据校验,使得项目的维护成本比较高
其执行10000次的耗时:
低数据量:nums=[1,2]: 1111.17ms
高数据量:nums=[1,2,3…,1000]: 1610.63ms
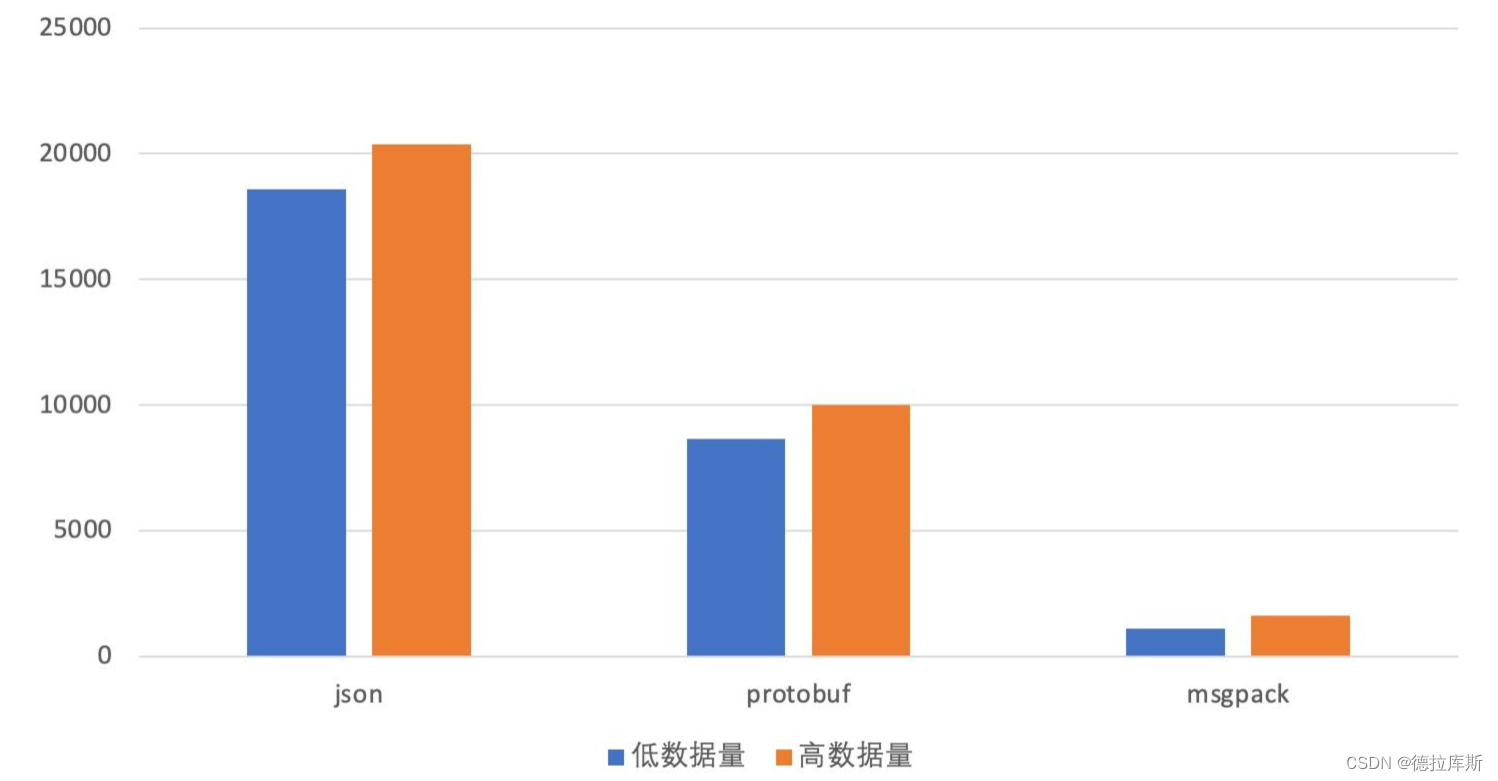
以下是三种序列化方式柱状图的对比结果:
可以看到,Protobuf相比Json,快了1倍,而msgpack相比protobuf,快了10倍,这也就是说明了各自的性能差距,但是我们不能只看性能,有时候对性能的要求不是那么高的时候,我们还需要看是否高效好用。
由于protobuf比json的可读性差,那么如果需要可读性很好但是对性能要求不是那么高的场景下,我们就可以使用Json,而在前后端之间通信最常用的就是Json(为了可读性好)
由于msgpack相比protubuf少了数据校验,所以需要相互协作的场景下,就适合使用protobuf,而在后端不同服务之间的协作一般采用protobuf。




![buuctf-[WUSTCTF2020]CV Maker](https://img-blog.csdnimg.cn/b89cf572a8b544f79d35ad553c93897c.png)