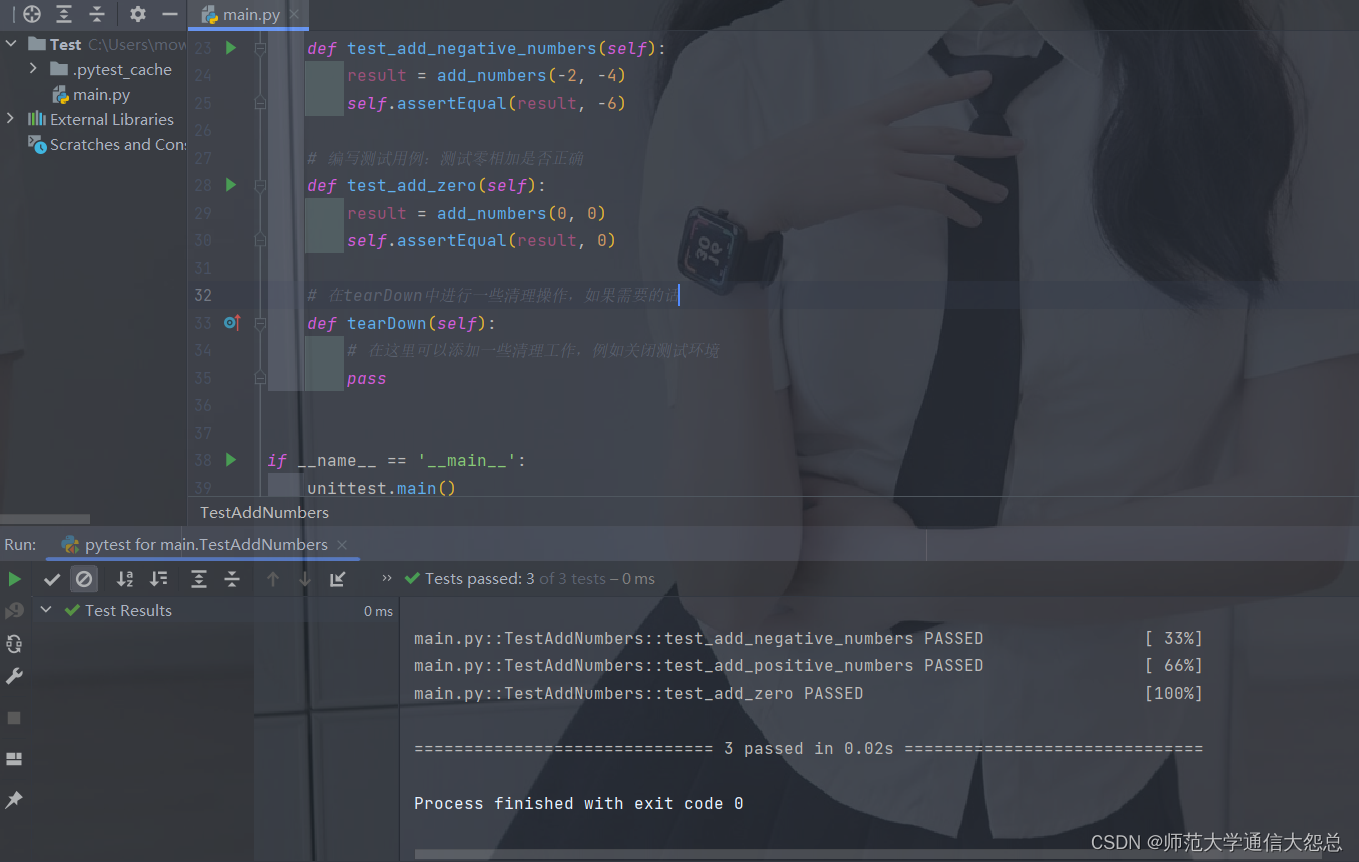
1.Spring bean的生命周期
- 实例化 Instantiation
- 属性赋值 Populate
- 初始化 Initialization
- 销毁 Destruction
2.Spring AOP的创建在bean的哪个时期进行的

(图片转载自Spring Bean的完整生命周期(带流程图,好记))
3.MQ如何保证消息在断电的情况下依然不丢失
持久化到硬盘,就是写入磁盘
4.MQ如何保证消息可靠性
从消息生产者到交换机,用return回调保证消息可靠性,这是消息级可靠,放在消息中定义;
从交换机到队列,用confirm回调保障消息可靠性,这是对象级可靠,放在template中定义;
从交换机到队列,做消息的持久化;
以上是发送的可靠性保障。
然后消费的可靠保障,就设置消息重试,包括发送消息重试、消费者重试,还有重试失败后的入库。
5.你在项目中遇到哪些问题怎么解决的
一个业务模块,物流信息模块,需要优化。
优化了5个方面。分别是换用数据库、解决缓存穿透、雪崩、击穿问题、优化布隆过滤器。
详细回答:
好的。我做的物流信息模块,具体实现了用户查看物流进度的需求。用户查看的物流进度,是一条条追加的,从广州到长沙,首先从揽收的营业点开始,到区分拣中心,再到广州转运中心,再到长沙转运中心、岳麓区分拣中心、具体的营业点,首先显示“快递已揽收”,然后显示“快递已到广州某区分拣中心”...总而言之,一个用户的一件快递,也就是一条订单,可能会有多条运单数据。第一个优化的地方就在这里。试想一下,如果我们使用MySQL存储用户查看的信息,势必会产生多条数据。而使用MongoDB,可以在一条数据中添加多个字段,这样用一条数据就能存下一个订单的信息。
而第二个优化的情景则是解决缓存雪崩的问题。缓存雪崩是指短时间乃至同时有很多Redis的key失效,这时候的访问可能就会给数据库带来很大压力乃至让数据库崩溃。应对这种情况,我们设置了随机过期时间,然后进行了服务降级,也就是对非核心数据的访问暂缓,返回指定的信息。
还有一种情况是Redis宕机,这时候我们用到了Caffeine和Redis做了多级缓存。
第三个优化的地方,我们面对了可能存在的缓存穿透问题。一个数据如果在多级缓存和数据库中都没有,那么每次访问都会访问到数据库,过多这样的访问可能会造成服务器崩溃,这就是缓存穿透问题。为了解决这个问题,我们使用了布隆过滤器。布隆过滤器用一些算法比如哈希算法将被过滤的数据映射到一个很长的位图上,将原本的0置为1。下次访问数据时,我们首先将查询的数据投入布隆过滤器,如果过滤结果为0则表示不存在,就直接返回。
第四个优化的地方在于,布隆过滤器过滤结果为1,也不一定保证就存在数据,因为有可能两个不同的数据哈希值一样。这时候我们可以增加算法,但计算时也需要耗时,增加过多也会让效率很低。所以应该适当添加算法数量,不用过少,也不能过多。
第四,我们优化了缓存击穿问题。高并发场景下指定的key失效,就会造成缓存击穿问题。我们用加锁的方式来处理这个情况。
更多可见我上篇博客面试打底稿⑦ 项目一的第三部分_zrc007007的博客-CSDN博客
6.MySQL在大量数据情况下如何对查询进行优化
分三种情况讨论:
- 单条SQL运行慢
- 部分SQL运行慢
- 整个SQL运行慢
详细回答:
就拿MySQL来说吧。对于需要优化的,查询慢的数据库,分三种情况讨论:
- 单条SQL运行慢
- 部分SQL运行慢
- 整个SQL运行慢
单条SQL运行慢
对于第一种情况,单条SQL运行慢,一般有两种常见原因:
- 未正常创建或使用索引
- 表中数据量太多了
首先,我们检查是否正常创建了索引;
然后,检查是否正常触发了索引查询。
以下情况不能触发索引,应该避免:
-
在 where 子句中使用 != 或者 <> 操作符,查询引用进行的是全表扫描;
-
前导模糊查询时触发的时全索引扫描或全表扫描,因为它不能利用索引的顺序、得一个个去找。也就是查询时不能用这样的字段: '%XX' 或 '%XX%';
-
带有条件or,or条件中不是每个列都有索引时。这时候必须在每个列上面都加上索引才能触发索引查询;
-
在 where 子句中对字段进行表达式操作。
以下技巧可以优化索引查询的速度:
-
尽量使用主键查询,而非其他索引,因为主键查询不会触发回表查询;
-
查询语句尽可能简单,大语句拆小语句,减少锁时间;
-
尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型;
-
用 exists 替代 in 查询;
-
避免在索引列上使用 is null 和 is not null。
其次,对于数据量过大的数据库,我们可以作数据拆分。
数据拆分分为垂直拆分和水平拆分。
垂直拆分一般这样来拆分:
-
把不常用的字段单独放在一张表;
-
把 text,blog 等大字段拆分出来放在附表中;
-
经常组合查询的列放在一张表中。
表的行数一般超过200万行时,查询就会变慢。这时候就可以拆分成多个表来存放数据。 这就是水平拆分。
部分SQL运行慢
为了定位这些慢查询的SQL,我们可以开启慢查询分析。
整个SQL运行慢
我们可以进行读写分离。
更多有关可见我的前篇博客面试打底稿③ 专业技能的第三部分_zrc007007的博客-CSDN博客
7.token是如何鉴权的在你的项目中
用aop。以后补充
8.谈谈你对JVM有哪些了解以及如何调优的
首先,我们加上-Xms和-Xmx参数,并设置两个参数为一样大小,都为服务器内存GB总数一半再减1,这是基本调优的操作;
然后对于JDK1.8,可以把并行垃圾收集器改为并发垃圾收集器。
进阶调优则是用jstat -gc、jstat -gcutil查看大数据对象都有哪些,看能否作出优化处理。
更多有关可见我前篇博客面试打底稿① 专业技能的第一部分-CSDN博客
9.SpringBoot自动装配的原理有了解过嘛?
以后补充。