1.逆强化学习的理论框架

1.teacher的行为被定义成best
2.学习的网络有两个,actor和reward
3.每次迭代中通过比较actor与teacher的行为来更新reward function,基于新的reward function来更新actor使得actor获得的reward最大。

loss的设计相当于一个排序问题,实际中多使用最大熵loss:
-log(sigmoid(P_label - P_actor))
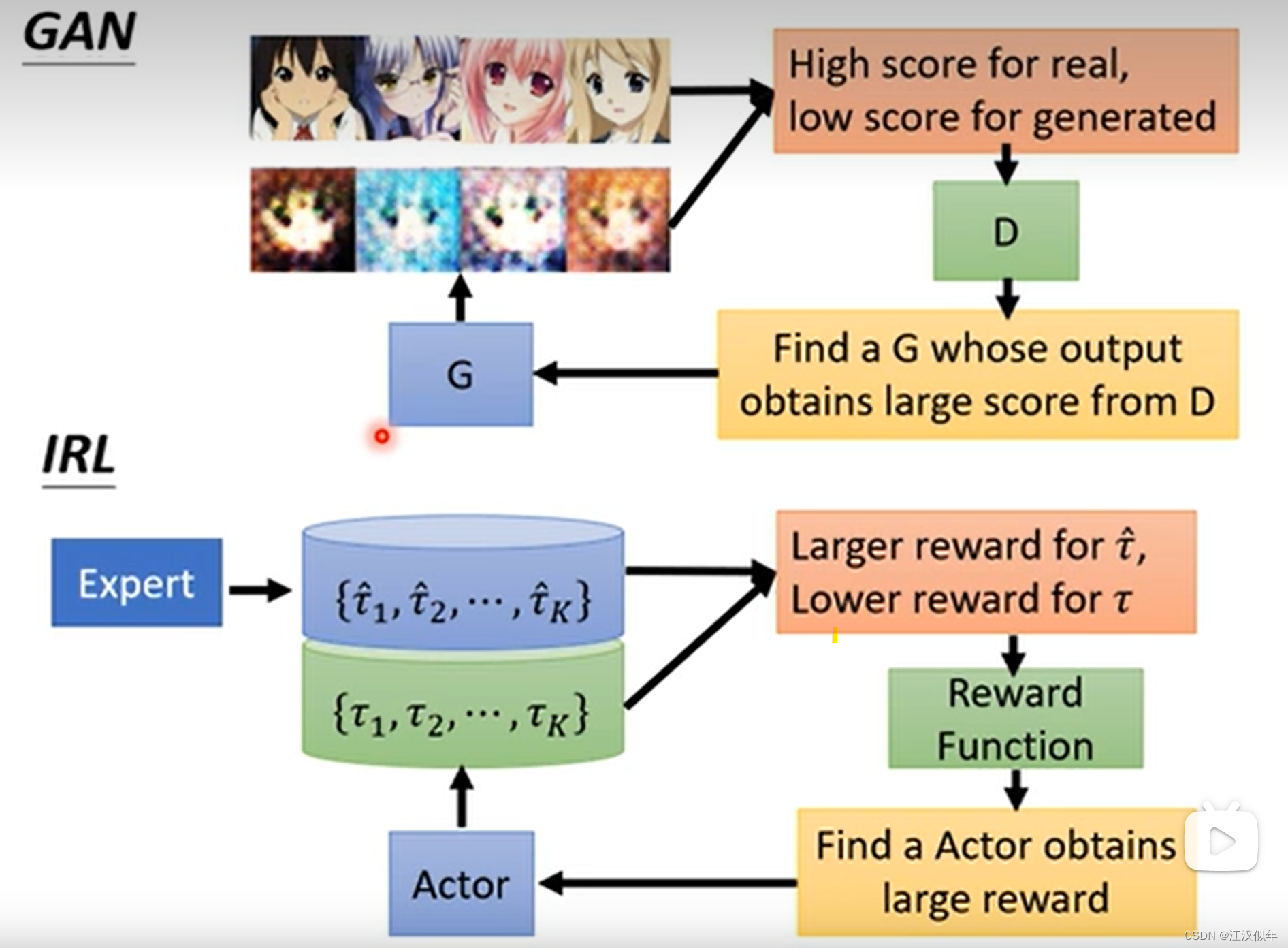
IRL与GAN在原理上相似,actor对应generator,reward function对应 discriminator,真实图片对应专家数据。




![[React源码解析] React的设计理念和源码架构 (一)](https://img-blog.csdnimg.cn/75242141fe5646f2a123486823875d6a.png)