yolo系列文章目录
文章目录
- yolo系列文章目录
- 一、SimAM注意力机制是什么?
- 二、YOLOv7使用SimAM注意力机制
- 1.在yolov7的models下面新建SimAM.py文件
- 2.在common里面导入
- 在这里插入图片描述
- 总结
一、SimAM注意力机制是什么?
论文题目:SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks
论文地址:http://proceedings.mlr.press/v139/yang21o/yang21o.pdf
源代码:https://github.com/ZjjConan/SimAM
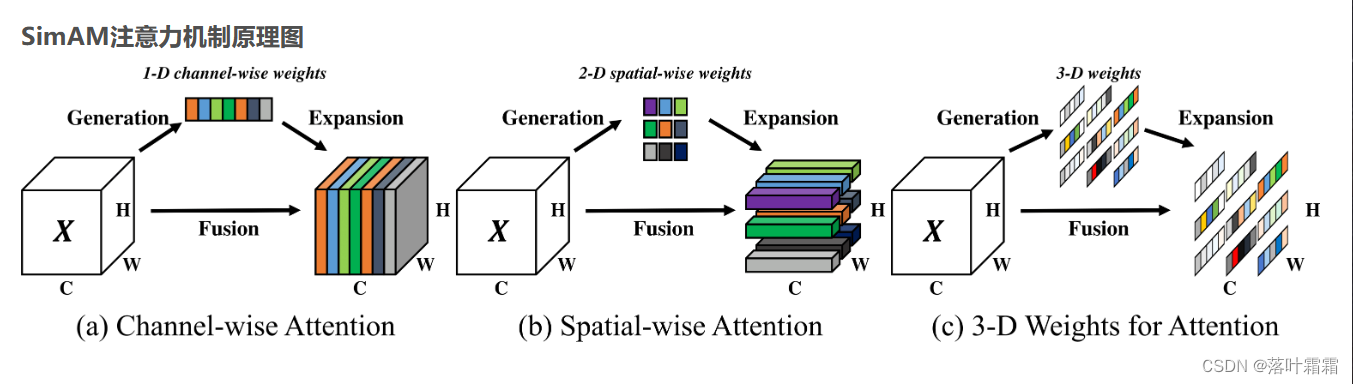
不同于现有的通道/空域注意力模块,该模块无需额外参数为特征图推导出3D注意力权值。具体来说,基于著名的神经科学理论提出优化能量函数以挖掘神经元的重要性。进一步针对该能量函数推导出一种快速解析解并表明:该解析解仅需不超过10行代码即可实现。该模块的另一个优势在于:大部分操作均基于所定义的能量函数选择,避免了过多的结构调整。最后在不同的任务上对所提注意力模块的有效性、灵活性进行验证。
二、YOLOv7使用SimAM注意力机制
1.在yolov7的models下面新建SimAM.py文件
粘贴如下:
import torch
import torch.nn as nnclass SimAM(torch.nn.Module):def __init__(self, e_lambda=1e-4):super(SimAM, self).__init__()self.activaton = nn.Sigmoid()self.e_lambda = e_lambdadef __repr__(self):s = self.__class__.__name__ + '('s += ('lambda=%f)' % self.e_lambda)return s@staticmethoddef get_module_name():return "simam"def forward(self, x):b, c, h, w = x.size()n = w * h - 1x_minus_mu_square = (x - x.mean(dim=[2, 3], keepdim=True)).pow(2)y = x_minus_mu_square / (4 * (x_minus_mu_square.sum(dim=[2, 3], keepdim=True) / n + self.e_lambda)) + 0.5return x * self.activaton(y)
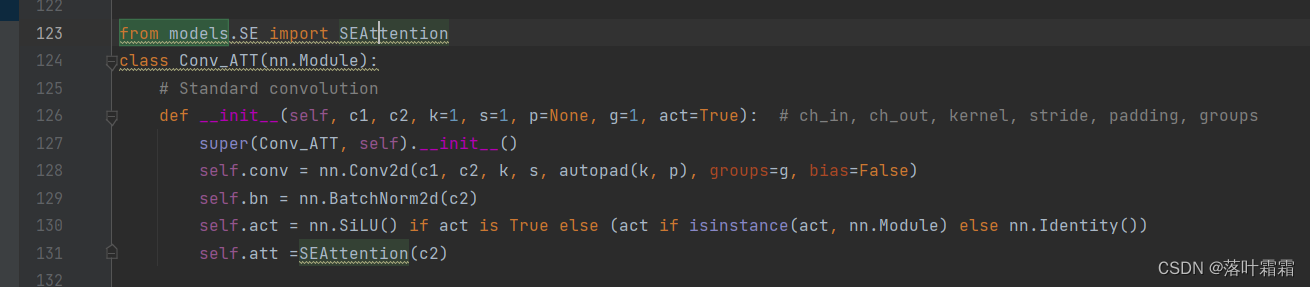
2.在common里面导入
from models.SimAM import SimAM
然后去修改con_att
修改最后一行:
self.att =SimAM()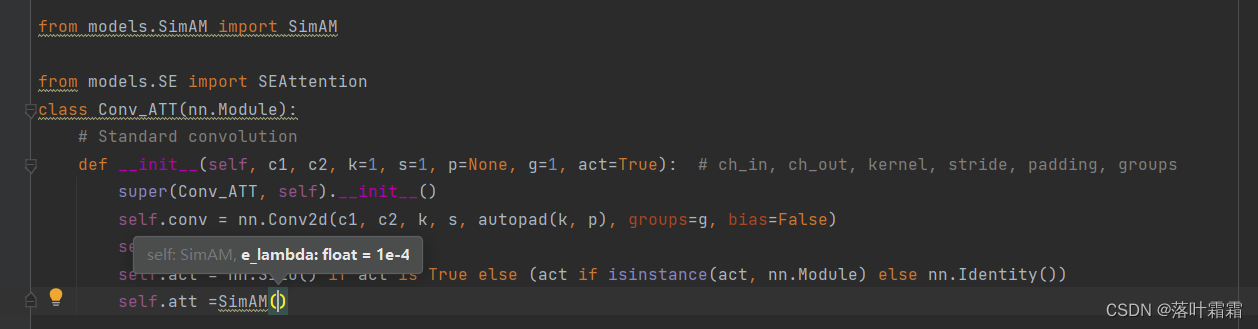
SPCC也一样
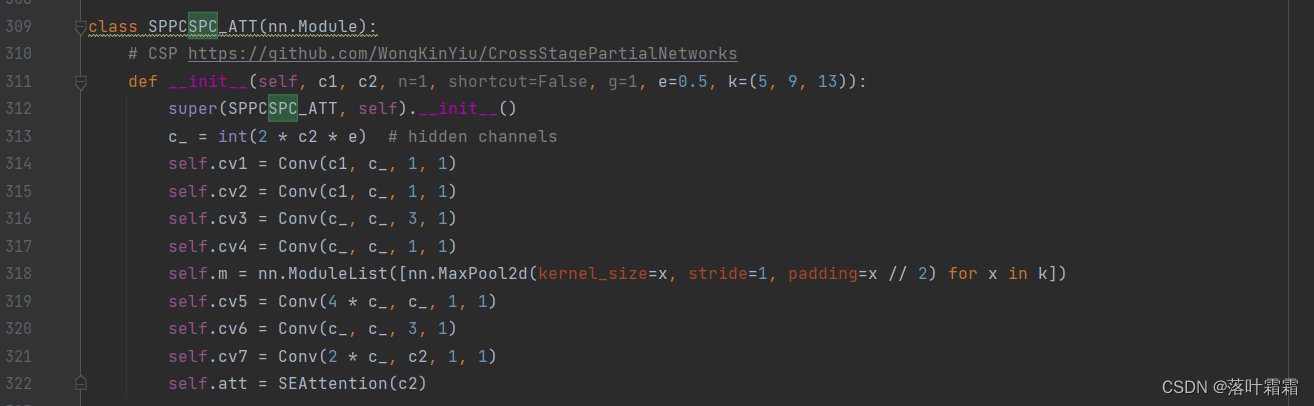
最后一行换到siam即可。
self.att =SimAM()
然后运行yaml即可。
在concat部分加注意力机制也一样。
进入models/common.py里面
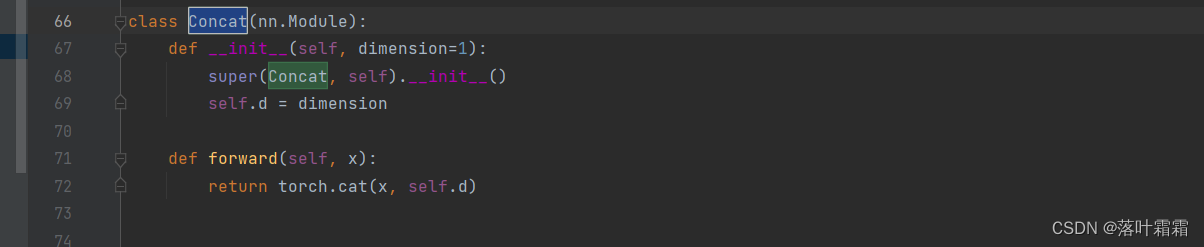
复制加上concat_att
class Concat_ATT(nn.Module):def __init__(self,channel, dimension=1):super(Concat_ATT,self).__init__()self.d = dimensionself.att = SimAM(channel)def forward(self, x):return self.att(torch.cat(x, self.d))
在yolo里面加上
elif m is Concat_ATT:c2 = sum([ch[x] for x in f])args = [c2]
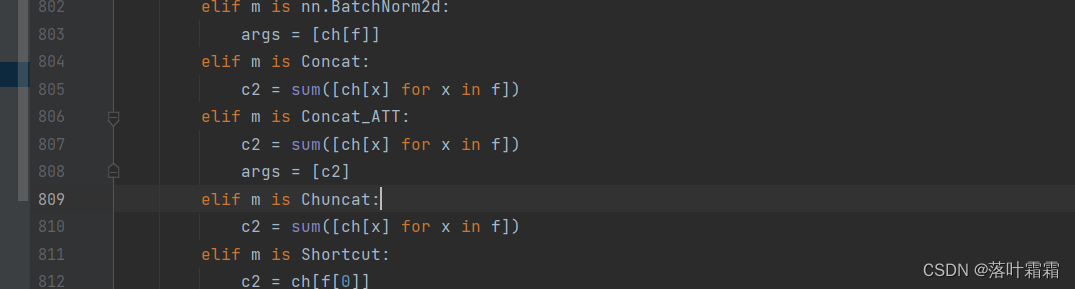
总结
siam注意力机制的添加和se注意力机制是一样的添加方法,可以根据自己的实际需求进行添加可以参考如下。
yolov7改进添加SE注意力机制
![P1017 [NOIP2000 提高组] 进制转换](https://img-blog.csdnimg.cn/5492d6e2a39d48e0b73e8fdfa246f0ad.png)





![[NISACTF 2022]popchains - 反序列化+伪协议](https://img-blog.csdnimg.cn/bdc25a942cea4657b389febe43930bcc.png#pic_center)