文章目录
- 1、配置总内存
- 2、JobManager 内存模型
- 3、TaskManager 内存模型
- 4、图形化展示
- 5、实际案例计算内存分配
1、配置总内存
Flink JVM 进程的进程总内存(Total Process Memory)包含了由 Flink 应用使用的内存(Flink 总内存)以及由运行 Flink 的 JVM 使用的内存。 Flink 总内存(Total Flink Memory)包括 JVM 堆内存(Heap Memory)和堆外内存(Off-Heap Memory)。 其中堆外内存包括直接内存(Direct Memory)和本地内存(Native Memory)。详细的配置参数:https://nightlies.apache.org/flink/flink-docs-release-1.12/zh/deployment/config.html

配置 Flink 进程内存最简单的方法是指定以下两个配置项中的任意一个:
| 配置项 | TaskManager 配置参数 | JobManager 配置参数 |
|---|---|---|
| Flink 总内存 | taskmanager.memory.flink.size | jobmanager.memory.flink.size |
| 进程总内存 | taskmanager.memory.process.size | jobmanager.memory.process.size |
Flink 启动需要明确配置:
| TaskManager | JobManager |
|---|---|
| taskmanager.memory.flink.size | jobmanager.memory.flink.size |
| taskmanager.memory.process.size | jobmanager.memory.process.size |
| taskmanager.memory.task.heap.size 和 | |
| taskmanager.memory.managed.size | jobmanager.memory.heap.size |
不建议同时设置进程总内存和 Flink 总内存。 这可能会造成内存配置冲突,从而导致部署失败。 额外配置其他内存部分时,同样需要注意可能产生的配置冲突。

2、JobManager 内存模型
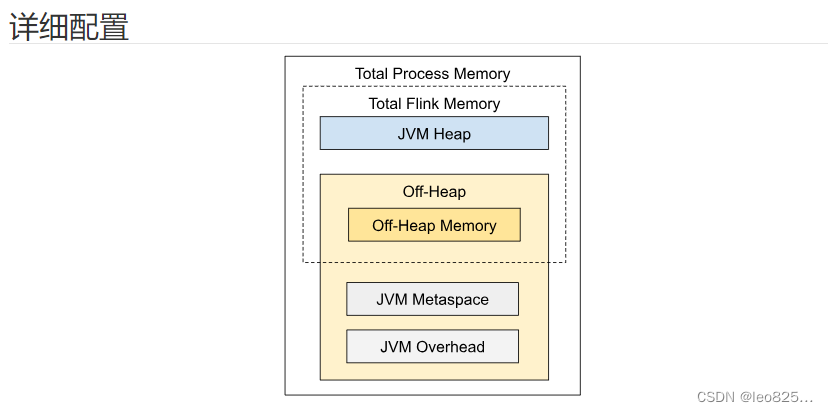
如上图所示,下表中列出了 Flink JobManager 内存模型的所有组成部分,以及影响其大小的相关配置参数。
| 组成部分 | 配置参数 | 描述 |
|---|---|---|
| JVM 堆内存 | jobmanager.memory.heap.size | JobManager 的 JVM 堆内存。 |
| 堆外内存 | jobmanager.memory.off-heap.size | JobManager 的堆外内存(直接内存或本地内存)。 |
| JVM Metaspace | jobmanager.memory.jvm-metaspace.size | Flink JVM 进程的 Metaspace。 |
| JVM 开销 | jobmanager.memory.jvm-overhead.min、jobmanager.memory.jvm-overhead.max、jobmanager.memory.jvm-overhead.fraction | 用于其他 JVM 开销的本地内存,例如栈空间、垃圾回收空间等。该内存部分为基于进程总内存的受限的等比内存部分。 |
如配置总内存中所述,另一种配置 JobManager 内存的方式是明确指定 JVM 堆内存的大小(jobmanager.memory.heap.size)。 通过这种方式,用户可以更好地掌控用于以下用途的 JVM 堆内存大小。
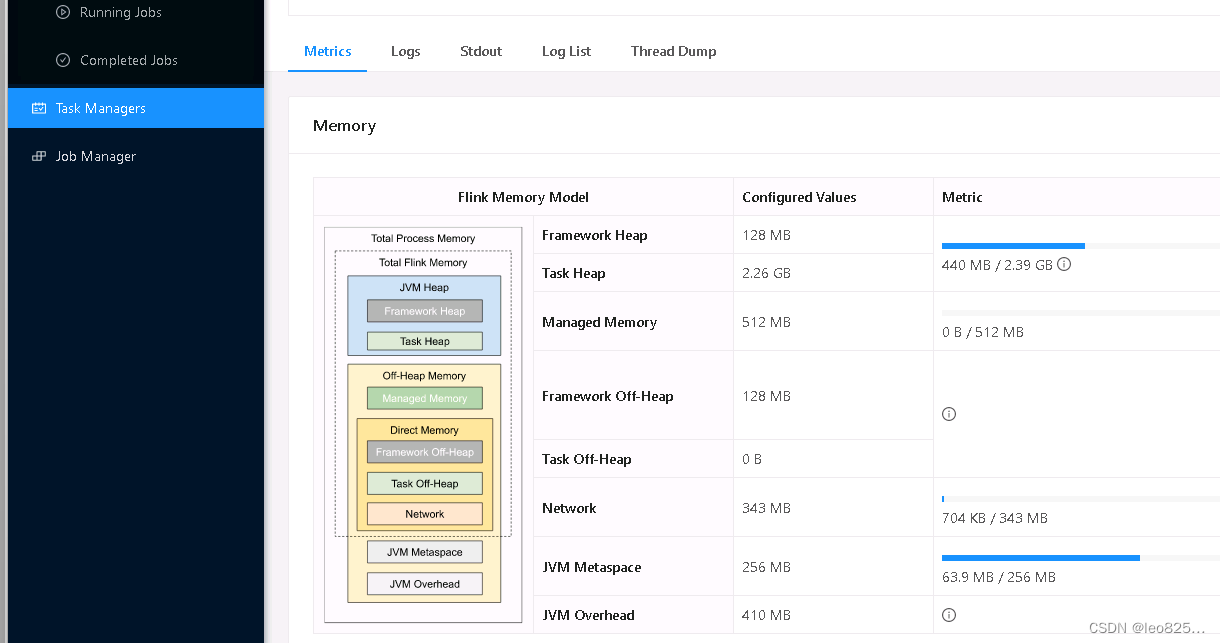
3、TaskManager 内存模型
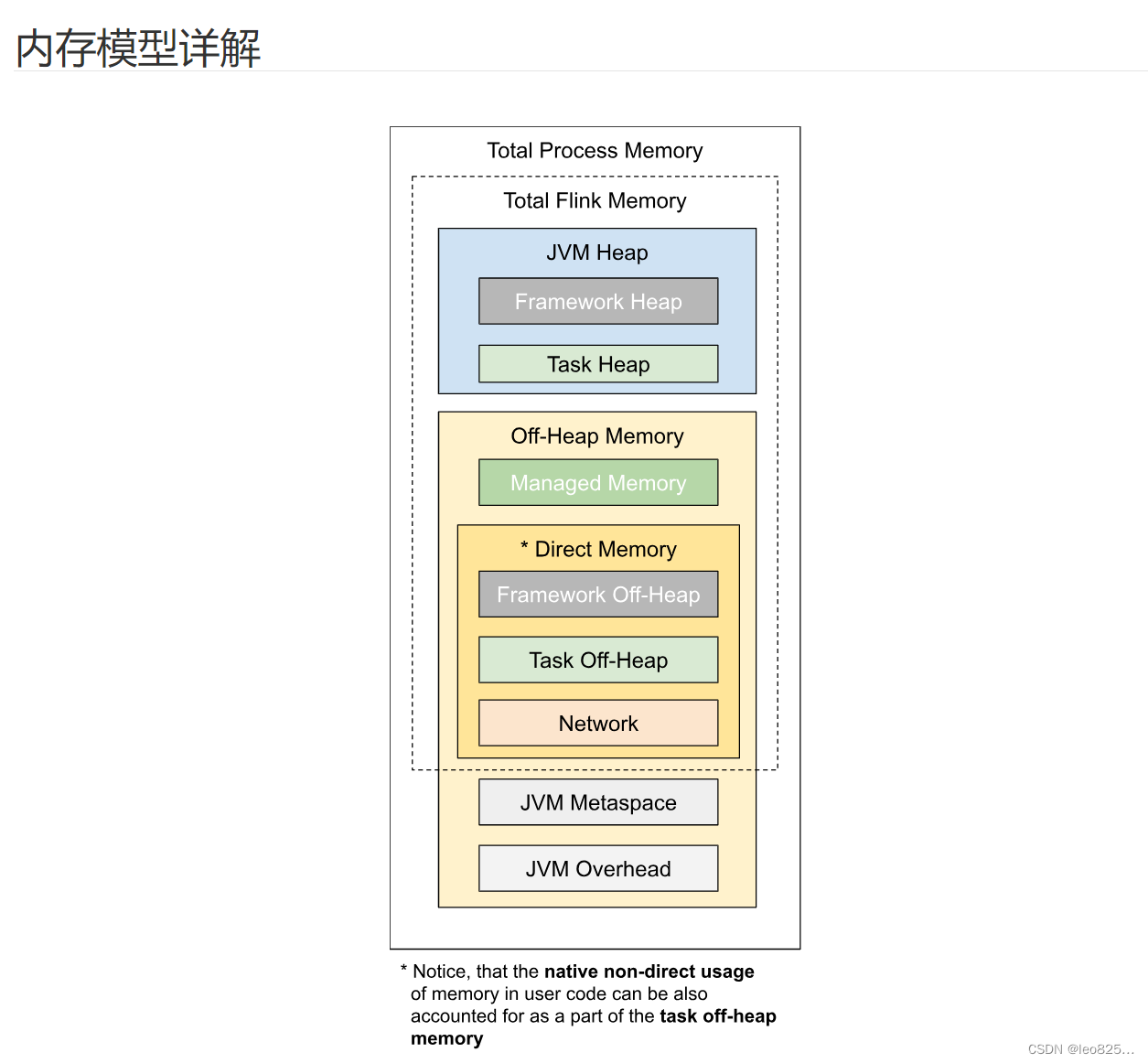
如上图所示,下表中列出了 Flink TaskManager 内存模型的所有组成部分,以及影响其大小的相关配置参数。
| 组成部分 | 配置参数 | 描述 |
|---|---|---|
| 框架堆内存(Framework Heap Memory) | taskmanager.memory.framework.heap.size | 用于 Flink 框架的 JVM 堆内存(进阶配置)。 |
| 任务堆内存(Task Heap Memory) | taskmanager.memory.task.heap.size | 用于 Flink 应用的算子及用户代码的 JVM 堆内存。 |
| 托管内存(Managed memory) | taskmanager.memory.managed.size、taskmanager.memory.managed.fraction | 由 Flink 管理的用于排序、哈希表、缓存中间结果及 RocksDB State Backend 的本地内存。 |
| 框架堆外内存(Framework Off-heap Memory) | taskmanager.memory.framework.off-heap.size | 用于 Flink 框架的堆外内存(直接内存或本地内存)(进阶配置)。 |
| 任务堆外内存(Task Off-heap Memory) | taskmanager.memory.task.off-heap.size | 用于 Flink 应用的算子及用户代码的堆外内存(直接内存或本地内存)。 |
| 网络内存(Network Memory) | taskmanager.memory.network.min、taskmanager.memory.network.max、taskmanager.memory.network.fraction | 用于任务之间数据传输的直接内存(例如网络传输缓冲)。该内存部分为基于 Flink 总内存的受限的等比内存部分。 |
| JVM Metaspace | taskmanager.memory.jvm-metaspace.size | Flink JVM 进程的 Metaspace。 |
| JVM 开销 | taskmanager.memory.jvm-overhead.min、taskmanager.memory.jvm-overhead.max、taskmanager.memory.jvm-overhead.fraction | 用于其他 JVM 开销的本地内存,例如栈空间、垃圾回收空间等。该内存部分为基于进程总内存的受限的等比内存部分。 |
我们可以看到,有些内存部分的大小可以直接通过一个配置参数进行设置,有些则需要根据多个参数进行调整。通常情况下,不建议对框架堆内存和框架堆外内存进行调整。 除非你非常肯定 Flink 的内部数据结构及操作需要更多的内存。 这可能与具体的部署环境及作业结构有关,例如非常高的并发度。 此外,Flink 的部分依赖(例如 Hadoop)在某些特定的情况下也可能会需要更多的直接内存或本地内存。
4、图形化展示
JobManager 内存直观展示
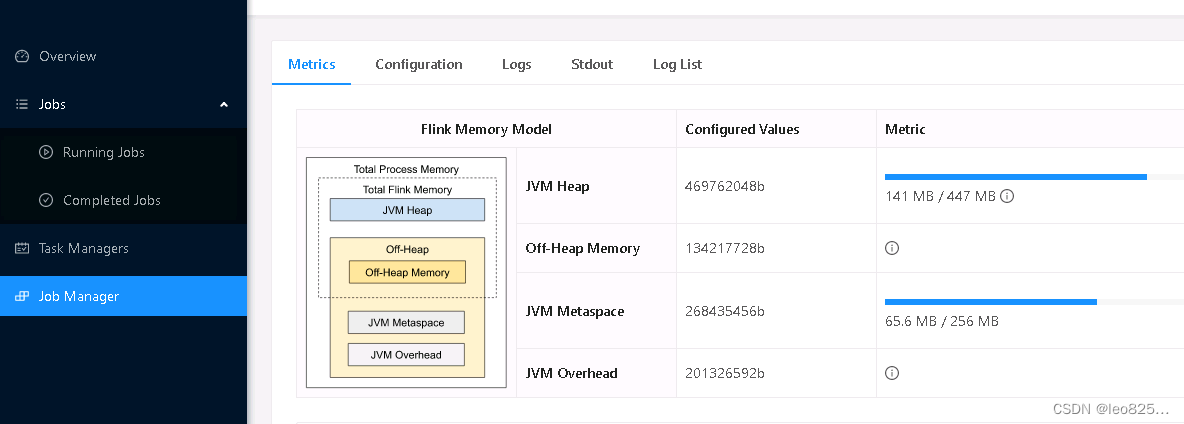
TaskManager 内存直观展示
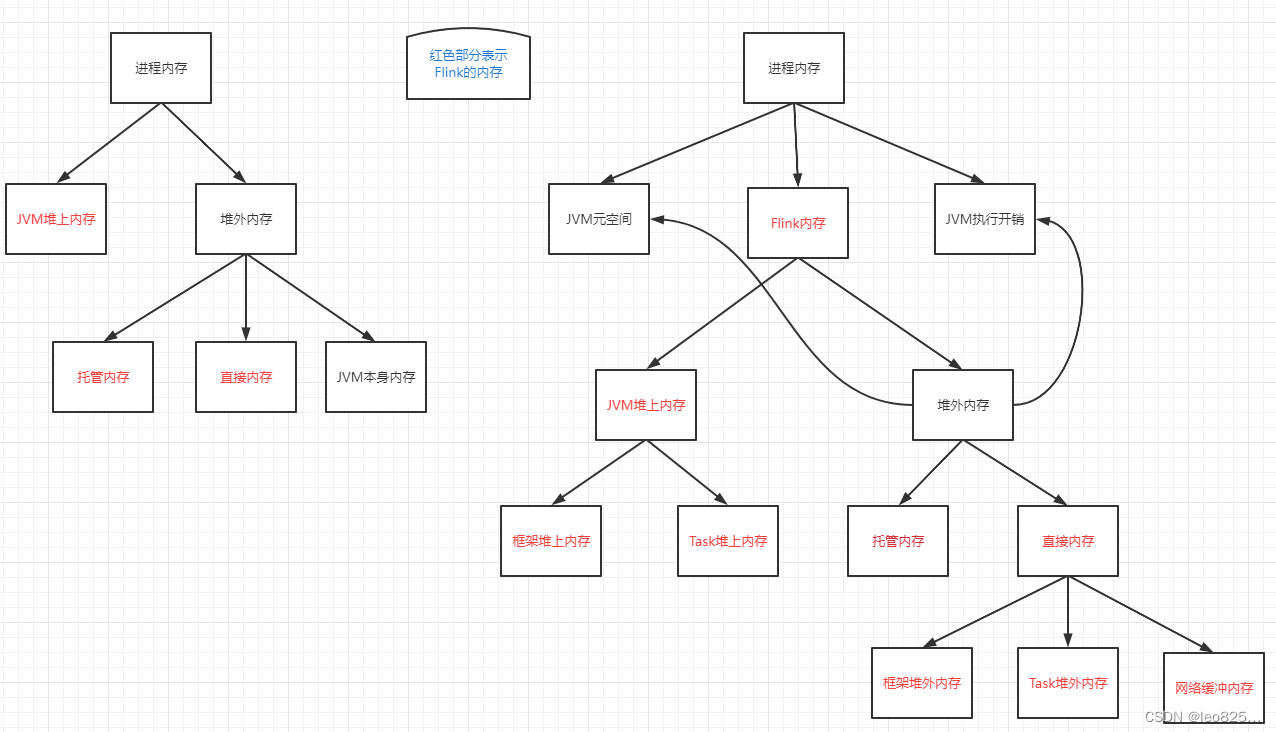
树状图表示:
5、实际案例计算内存分配
如果是 Flink On YARN 模式下:
taskmanager.memory.process.size = 4096 MB = 4G
taskmanager.memory.network.fraction = 0.15
taskmanager.memory.managed.fraction = 0.45
然后根据以上参数,就可以计算得到各部分的内存大小:
taskmanager.memory.jvm-overhead = 4096 * 0.1 = 409.6 MB
taskmanager.memory.flink.size = 4096 - 409.6 - 256 = 3430.4 MB
taskmanager.memory.network = 3430.4 * 0.15 = 514.56 MB
taskmanager.memory.managed = 3430.4 * 0.45 = 1543.68 MB
taskmanager.memory.task.heap.size = 3430.4 - 128 * 2 - 1543.68 - 514.56 = 1116.16 MB

Flink 启动参考配置参数:
/home/dev/soft/flink/bin/flink run \-m yarn-cluster \-yD akka.ask.timeout='360 s' \-yD akka.framesize=20485760b \-yD blob.fetch.backlog=1000 \-yD blob.fetch.num-concurrent=500 \-yD blob.fetch.retries=50 \-yD blob.storage.directory=/data1/flinkdir \-yD env.java.opts.jobmanager='-XX:ErrorFile=/tmp/java_error_%p.log -XX:+PrintGCDetails -XX:-OmitStackTraceInFastThrow -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=512m -XX:+UseG1GC -XX:MaxGCPauseMillis=300 -XX:InitiatingHeapOccupancyPercent=50 -XX:+ExplicitGCInvokesConcurrent -XX:+AlwaysPreTouch -XX:AutoBoxCacheMax=20000 -XX:G1HeapWastePercent=5 -XX:G1ReservePercent=25 -Dfile.encoding=UTF-8' \-yD env.java.opts.taskmanager='-XX:ErrorFile=/tmp/java_error_%p.log -XX:+PrintGCDetails -XX:-OmitStackTraceInFastThrow -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=1024m -XX:+UseG1GC -XX:MaxGCPauseMillis=300 -XX:InitiatingHeapOccupancyPercent=50 -XX:+ExplicitGCInvokesConcurrent -XX:+AlwaysPreTouch -XX:AutoBoxCacheMax=20000 -Dsun.security.krb5.debug=false -Dfile.encoding=UTF-8' \-yD env.java.opts='-XX:ErrorFile=/tmp/java_error_%p.log -XX:+PrintGCDetails -XX:-OmitStackTraceInFastThrow -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=1024m -Dfile.encoding=UTF-8' \-yD execution.attached=false \-yD execution.buffer-timeout='1000 ms' \-yD execution.checkpointing.externalized-checkpoint-retention=RETAIN_ON_CANCELLATION \-yD execution.checkpointing.interval='30 min' \-yD execution.checkpointing.max-concurrent-checkpoints=1 \-yD execution.checkpointing.min-pause='2 min' \-yD execution.checkpointing.mode=EXACTLY_ONCE \-yD execution.checkpointing.timeout='28 min' \-yD execution.checkpointing.tolerable-failed-checkpoints=8 \-yD execution.checkpointing.unaligned=true \-yD execution.checkpointing.unaligned.forced=true \-yD heartbeat.interval=60000 \-yD heartbeat.rpc-failure-threshold=5 \-yD heartbeat.timeout=340000 \-yD io.tmp.dirs=/data1/flinkdir \-yD jobmanager.heap.size=1024m \-yD jobmanager.memory.jvm-metaspace.size=268435456b \-yD jobmanager.memory.jvm-overhead.max=1073741824b \-yD jobmanager.memory.jvm-overhead.min=1073741824b \-yD jobmanager.memory.network.fraction=0.2 \-yD jobmanager.memory.network.max=6GB \-yD jobmanager.memory.off-heap.size=134217728b \-yD jobmanager.memory.process.size='18360 mb' \-yD metrics.reporter.promgateway.deleteOnShutdown=true \-yD metrics.reporter.promgateway.factory.class=org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporterFactory \-yD metrics.reporter.promgateway.filter.includes=\*:dqc\*,uptime,taskSlotsTotal,numRegisteredTaskManagers,taskSlotsAvailable,numberOfFailedCheckpoints,numRestarts,lastCheckpointDuration,Used,Max,Total,Count,Time:gauge,meter,counter,histogram \-yD metrics.reporter.promgateway.groupingKey="yarn=${yarn};hdfs=${hdfs};job_name=TEST-broadcast-${jobName//./-}-${provId}" \-yD metrics.reporter.promgateway.host=172.17.xxxx.xxxx \-yD metrics.reporter.promgateway.interval='60 SECONDS' \-yD metrics.reporter.promgateway.jobName="TEST-broadcast-${jobName//./-}-${provId}" \-yD metrics.reporter.promgateway.port=10080 \-yD metrics.reporter.promgateway.randomJobNameSuffix=true \-yD pipeline.name="TEST-broadcast-${jobName//./-}-${provId}" \-yD pipeline.object-reuse=true \-yD rest.flamegraph.enabled=true \-yD rest.server.numThreads=20 \-yD restart-strategy.failure-rate.delay='60 s' \-yD restart-strategy.failure-rate.failure-rate-interval='3 min' \-yD restart-strategy.failure-rate.max-failures-per-interval=3 \-yD restart-strategy=failure-rate \-yD security.kerberos.krb5-conf.path=/home/dev/kerberos/krb5.conf \-yD security.kerberos.login.contexts=Client,KafkaClient \-yD security.kerberos.login.keytab=/home/dev/kerberos/xxxx.keytab \-yD security.kerberos.login.principal=xxxx \-yD security.kerberos.login.use-ticket-cache=false \-yD state.backend.async=true \-yD state.backend=hashmap \-yD state.checkpoints.dir=hdfs://xxxx/flink/checkpoint/${jobName//.//}/$provId \-yD state.checkpoint-storage=filesystem \-yD state.checkpoints.num-retained=3 \-yD state.savepoints.dir=hdfs://xxxx/flink/savepoint/${jobName//.//}/$provId \-yD table.exec.hive.fallback-mapred-writer=false \-yD task.manager.memory.segment-size=4mb \-yD taskmanager.memory.framework.off-heap.size=1GB \-yD taskmanager.memory.managed.fraction=0.2 \-yD taskmanager.memory.network.fraction=0.075 \-yD taskmanager.memory.network.max=16GB \-yD taskmanager.memory.process.size='50 gb' \-yD taskmanager.network.netty.client.connectTimeoutSec=600 \-yD taskmanager.network.request-backoff.max=120000 \-yD taskmanager.network.retries=100 \-yD taskmanager.numberOfTaskSlots=10 \-yD web.timeout=900000 \-yD web.upload.dir=/data1/flinkdir \-yD yarn.application.name="TEST-broadcast-${jobName//./-}-${provId}" \-yD yarn.application.queue=$yarnQueue \-yD yarn.application-attempts=10 \









![2023年中国汽车座舱行业发展现状及趋势分析:高级人机交互(HMI)系统将逐步提升[图]](https://img-blog.csdnimg.cn/img_convert/f637b1b5c70af2b2cc3a0748a2d95bfd.png)