一、数据库约束
约束:按照一定条件进行规范的做事;
表定义的时候,某些字段保存的数据需要按照一定的约束条件;
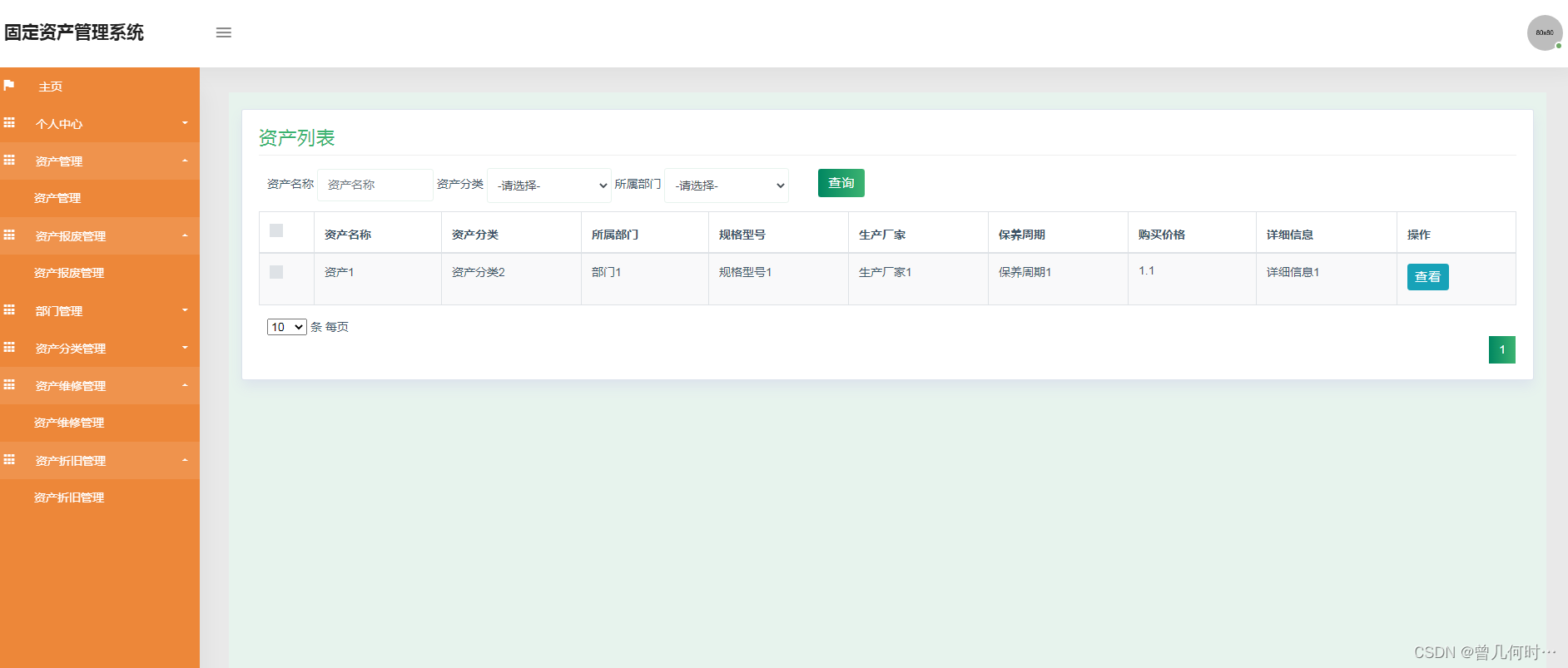
1.null约束
- 字段null:该字段可以为空;not null:该字段不能为空
- 不指定的话就是null
id int not null;
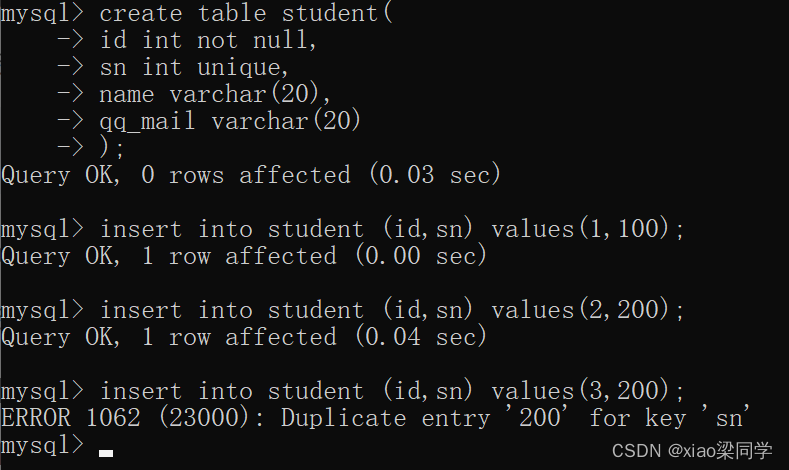
2.unique:唯一约束
表示某个字段,不能重复(实际可以使用多个字段来建立unique唯一约束)
null不进行unique唯一校验;
sn int unique;
当sn重复时便会报错
3.default:默认值约束
表示某个字段设置了default及默认值,插入的时候该列不插入,就会插入默认值。
显示的插入数据即使是null,默认值也不会生效
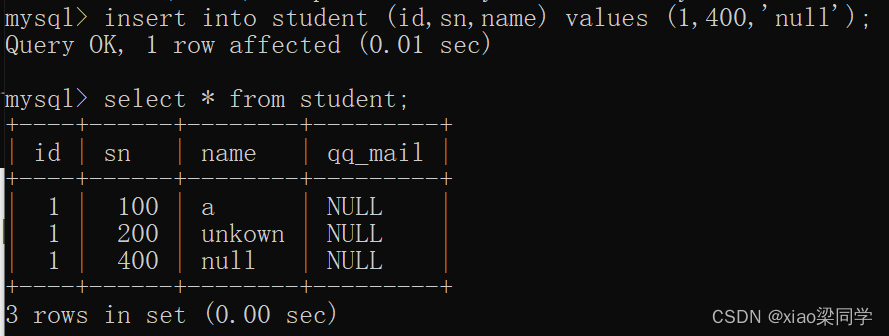
name varchar(20) default 'unkown';
插入的字段不使用name,才会插入默认值:
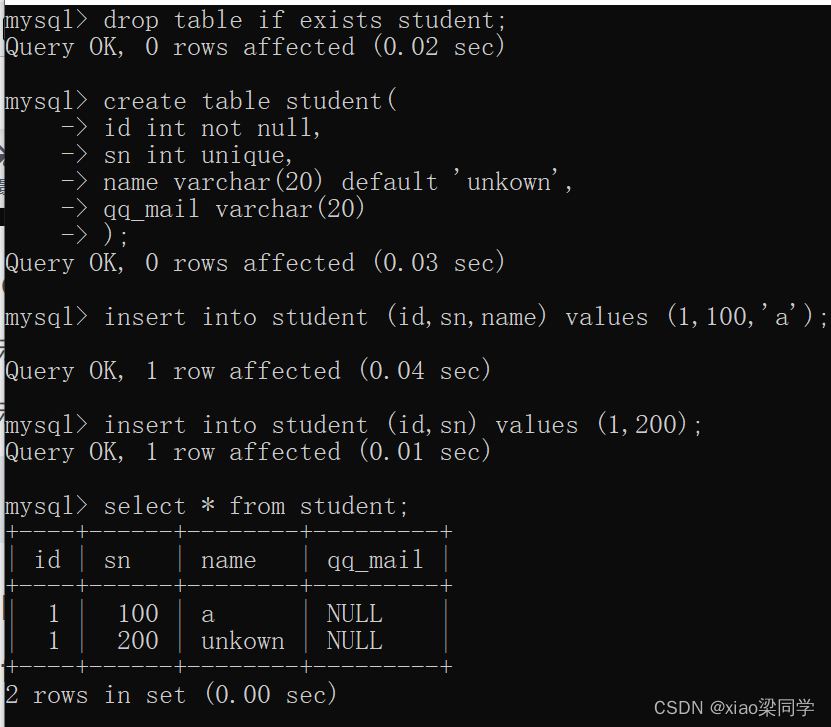
4.primary key:主键约束
主键一般用于某张表标识唯一的一条数据
- primary key =not null unique
仅仅unique约束的字段,还可以保存多条null的数据,也不能标识唯一的数据

主键字段不插入或者插入重复的都会报错
 一张表一般都需要设计主键
一张表一般都需要设计主键
如果使用整型主键还可以结合auto_increment,表示从1开始,++自增
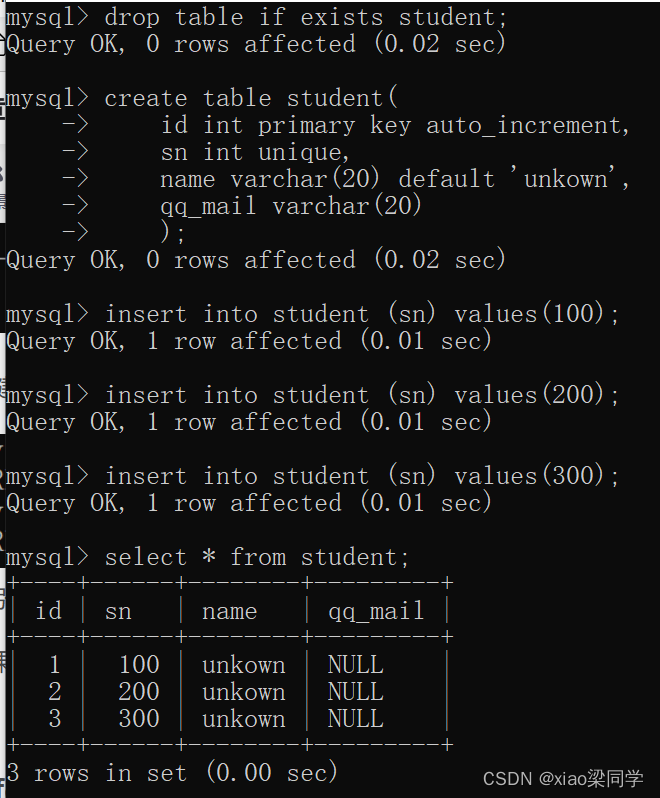
自增不是以最大值加1的方式,而是mysql记录了这个值来递增。
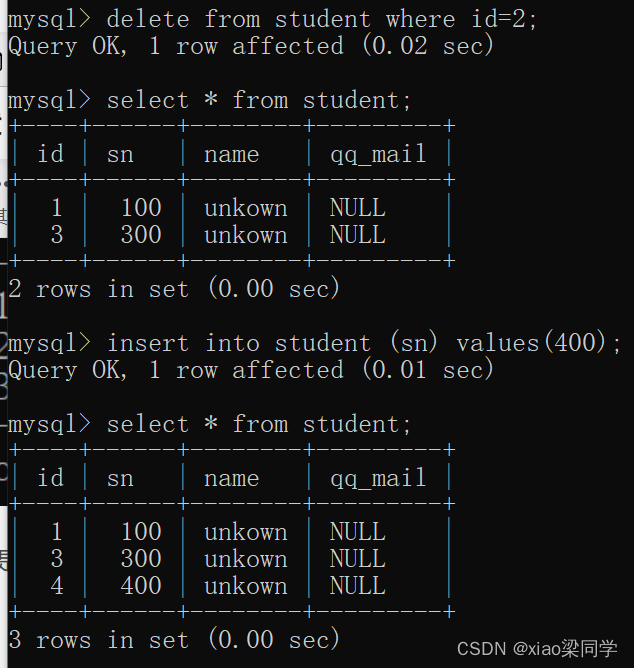
再插入数据,id就可能不连续
5.foreign key:外键约束
用于设计表与表之间的关系
表1(主表:主键)-----表2(从表:外键):就可以建立表1和表2一对一或者一对多的关系
二、表的设计
数据库设计表关系
主表的主键关联从表的外键(建立外键,不一定非要使用主键来关联,只是常用主键和外键关联)
create table 主表(
id int primary key auto_increment,
...
);
create table 从表(
id int primary key auto_increment,
...
主表_id int,
foreign key (主表_id) references 主表(id)
);
上面两个表中 蓝色部分建立关系
foreign key (主表_id) references 主表(id)--->
主表_id:从表的外键字段名;
主表:主表的表名;
id:主表的关联字段名(一般使用主键)
1.一对一的关系
比如:人对身份证
人
id:主键
name:姓名
amount:存款
username:账号
password:密码
身份证
id:主键
身份证号:*******
住址:*******
......
user_id:外键
建立人的主键与身份证外键的联系
从现实看,其实可以设计成一张表,但是人这张表查询比较频繁,如果把身份证相关的字段也放在一起,那么比较频繁的又不获取身份证信息的查询效率就比较低。
设计为一对一关系的两张表目的是:
- 数据库表设计其实就是建模(建立一种对象模型)
- 解耦:模型之间的解耦
- 效率:不经常使用的数据,单独存储,效率会比较高
2.一对多的关系
班级表
班级id
班级名称
...
学生表
学生 id:主键
学生姓名
学号
班级id:外键
班级id就是班级表和学生表之间的关联
一对多其实是有方向的,包含:
(1)班级到学生:一对多,一个班级多个学生
(2)学生到班级,一对一,一个学生一个班级
3.多对多的关系
表设计的时候(这个多对多关系,在两张主表中没有外键体现):
(1)两张主表建立多对多关系
(2)使用一张单独的中间表来表示两张主表的多对多关系
学生和课程再某个业务发生后就可能产生关系:
考试:一个学生考多门课程,一门课程有多个学生考试
设计上使用中间表:
(1)两个外键:分别关联两张主表的主键
(2)还可能设计一些业务的字段,比如考试成绩
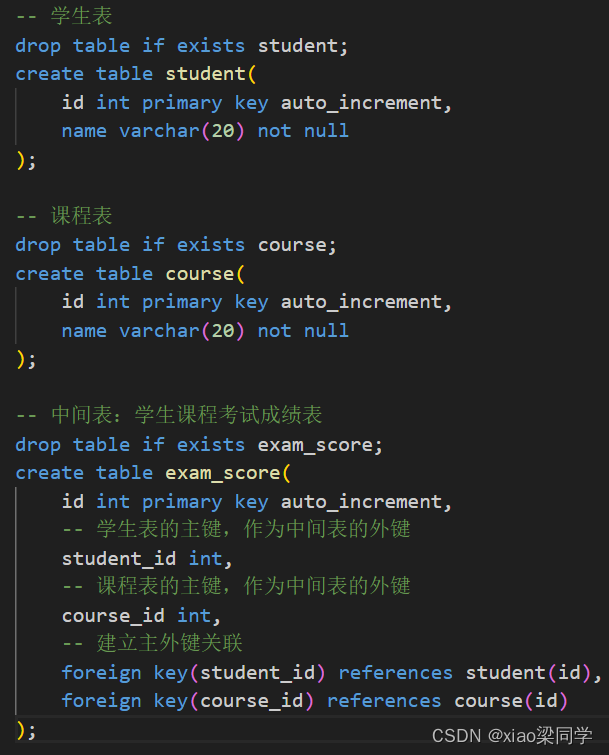
学生表和课程表是多对多的关系(逻辑上的多对多关系),主表没有关系的体系;
中间表(体现实际的多对多关系),两个外键其实就表现出多对多的关系;
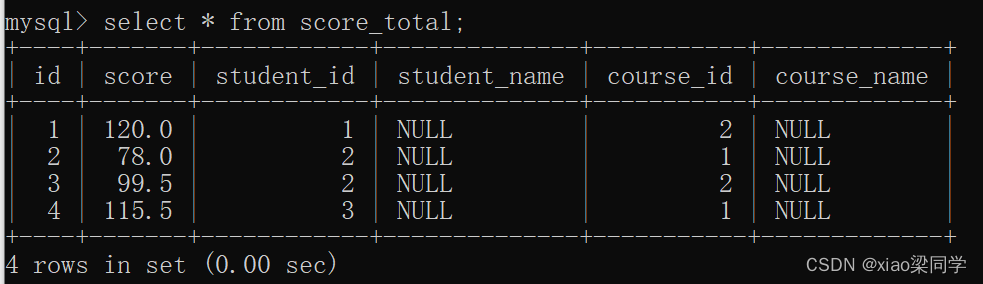
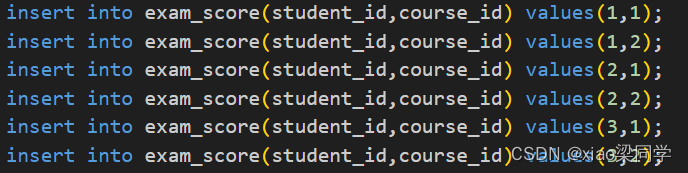
插入数据:


在MySQL中执行后:
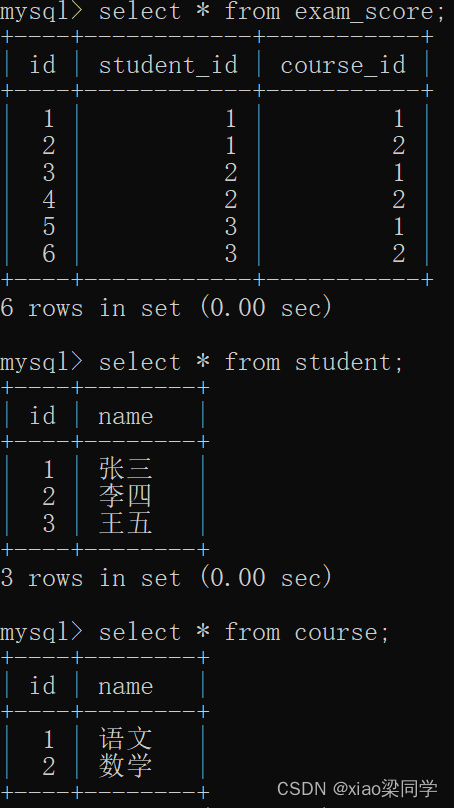
表结构上只有两个一对多关系;数据上,体现出两个一对多关系,及逻辑上的多对多关系;
- 一个学生考多个试--->学生表:中间表=1:n
- 一个课程有多个考试成绩--->课程表:中间表=1:m
- 中间表(考试成绩表)--->学生:课程=n:m
三、新增
插入操作:insert into 表 select...from 表 where... order by ... limit;
使用场景:
(1)复制表
(2)提前准备一些统计的数据(统计的sql一般关联很多表,条件可能也很复杂,执行效率可能不高),很多系统就提前运行任务,将统计的数据准备在单独的一张表中

把查询结果集返回的所有数据,按查询出来的字段顺序,插入到insert表给的字段。