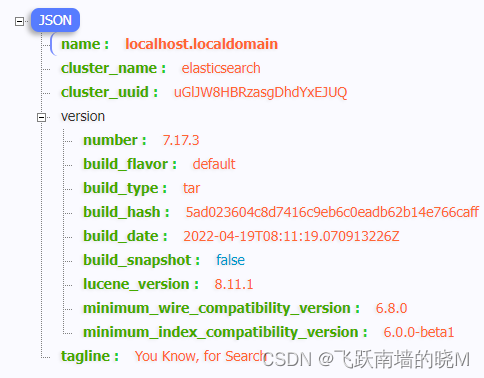
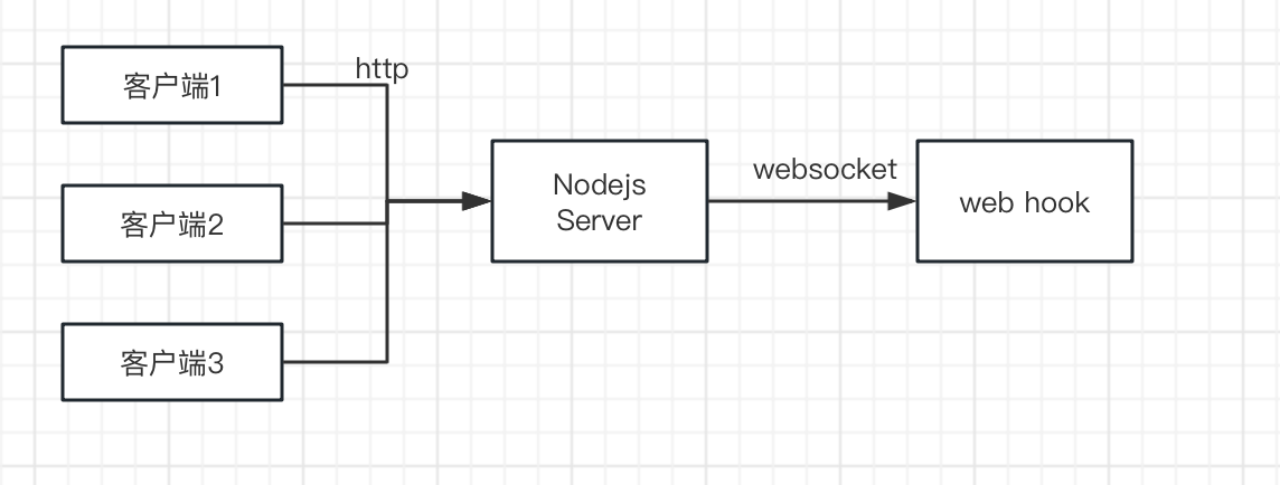
# 分布式搜索引擎01该笔记是根据黑马程序员的课来自己写了一遍的,b站有对应教程和资料
第一部分
第二部分
第三部分
– elasticsearch基础
0.学习目标
1.初识elasticsearch
1.1.了解ES
1.1.1.elasticsearch的作用
elasticsearch是一款非常强大的开源搜索引擎,具备非常多强大功能,可以帮助我们从海量数据中快速找到需要的内容
例如:
-
在GitHub搜索代码
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
-
在电商网站搜索商品

-
在百度搜索答案
-
在打车软件搜索附近的车
都是搜索引擎的使用场景
1.1.2.ELK技术栈
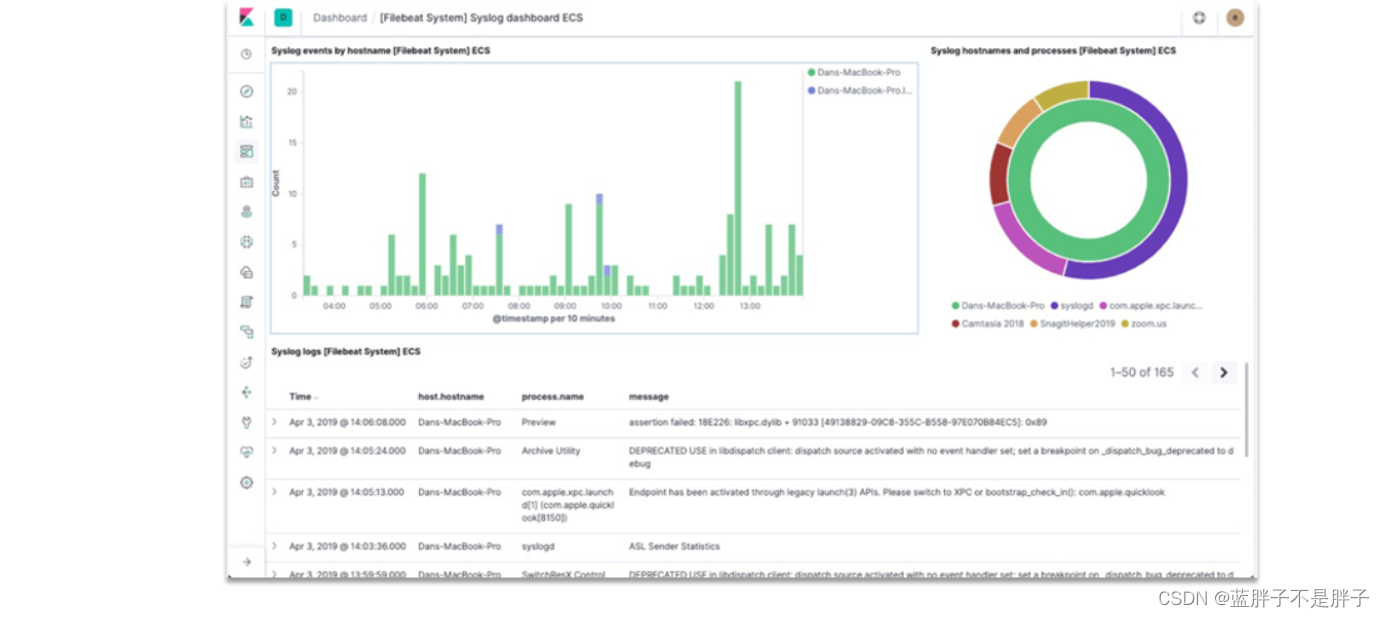
elasticsearch结合kibana、Logstash、Beats,也就是elastic stack(ELK)。拥有专门的web页面,被广泛应用在日志数据分析、实时监控等领域:
而elasticsearch是elastic stack的核心,负责存储、搜索、分析数据。

1.1.3.elasticsearch和lucene
elasticsearch底层是基于lucene来实现的。
Lucene是一个Java语言的搜索引擎类库,是Apache公司的顶级项目,由DougCutting于1999年研发。官网地址:https://lucene.apache.org/ 。

elasticsearch的发展历史:
- 2004年Shay Banon基于Lucene开发了Compass
- 2010年Shay Banon 重写了Compass,取名为Elasticsearch。

1.1.4.为什么不是其他搜索技术?
目前比较知名的搜索引擎技术排名:
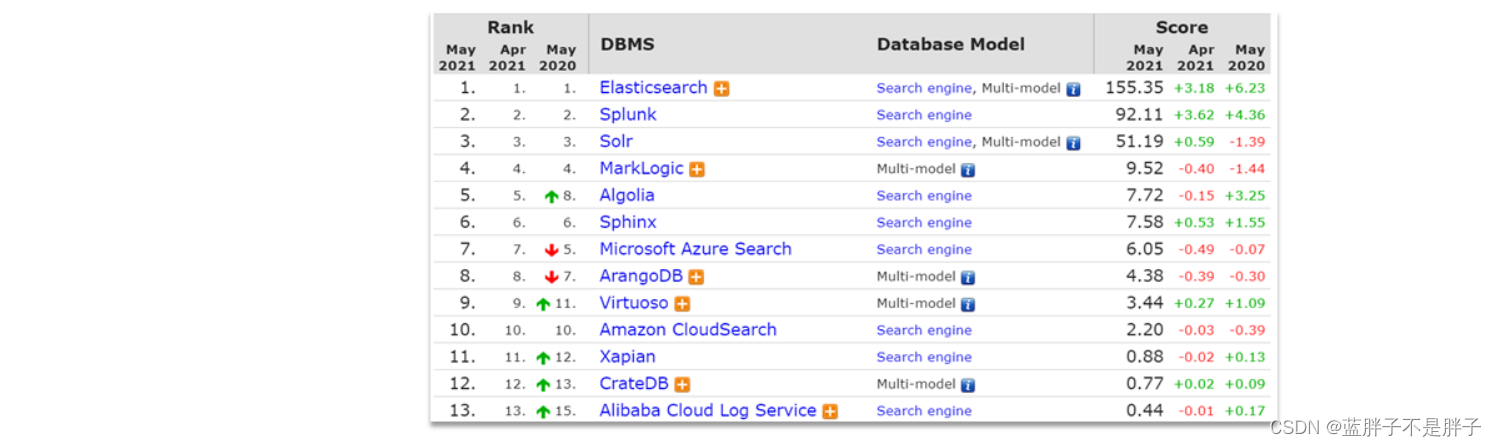
虽然在早期,Apache Solr是最主要的搜索引擎技术,但随着发展elasticsearch已经渐渐超越了Solr,独占鳌头:
1.1.5.总结
什么是elasticsearch?
- 一个开源的分布式搜索引擎,可以用来实现搜索、日志统计、分析、系统监控等功能
什么是elastic stack(ELK)?
- 是以elasticsearch为核心的技术栈,包括beats、Logstash、kibana、elasticsearch
什么是Lucene?
- 是Apache的开源搜索引擎类库,提供了搜索引擎的核心API
1.2.倒排索引
倒排索引的概念是基于MySQL这样的正向索引而言的。
1.2.1.正向索引
那么什么是正向索引呢?例如给下表(tb_goods)中的id创建索引:
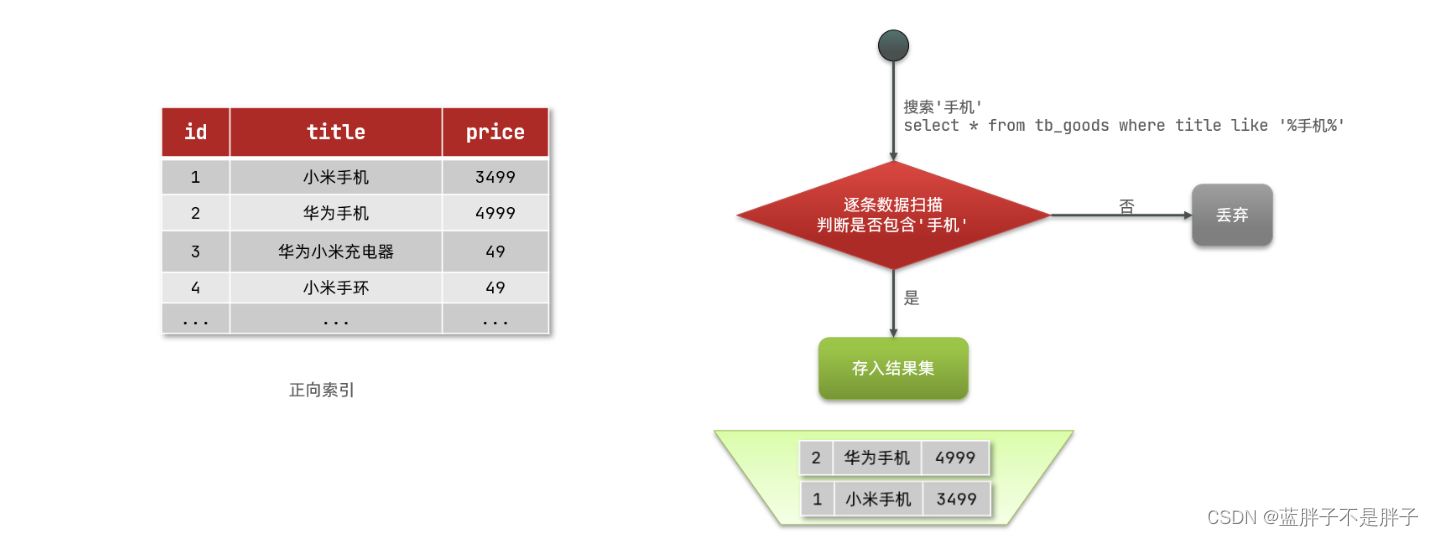
如果是根据id查询,那么直接走索引,查询速度非常快。
但如果是基于title做模糊查询,只能是逐行扫描数据,流程如下:
1)用户搜索数据,条件是title符合"%手机%"
2)逐行获取数据,比如id为1的数据
3)判断数据中的title是否符合用户搜索条件
4)如果符合则放入结果集,不符合则丢弃。回到步骤1
逐行扫描,也就是全表扫描,随着数据量增加,其查询效率也会越来越低。当数据量达到数百万时,就是一场灾难,查找服务消耗的事件不可想象
1.2.2.倒排索引
倒排索引中有两个非常重要的概念:
- 文档(
Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息 - 词条(
Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
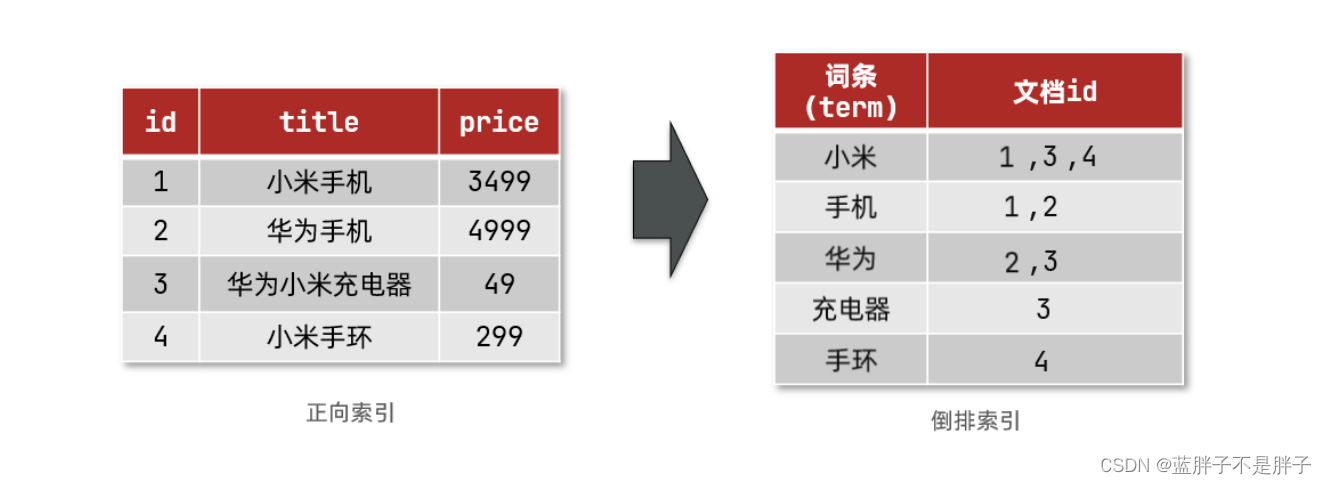
创建倒排索引是对正向索引的一种特殊处理,流程如下:
- 将每一个文档的数据利用算法分词,得到一个个词条
- 创建表,每行数据包括词条、词条所在文档id、位置等信息
- 因为词条唯一性,可以给词条创建索引,例如hash表结构索引
如图:
倒排索引的搜索流程如下(以搜索"华为手机"为例):
1)用户输入条件"华为手机"进行搜索。
2)对用户输入内容分词,得到词条:华为、手机。
3)拿着词条在倒排索引中查找,可以得到包含词条的文档id:1、2、3。
4)拿着文档id到正向索引中查找具体文档。
如图:
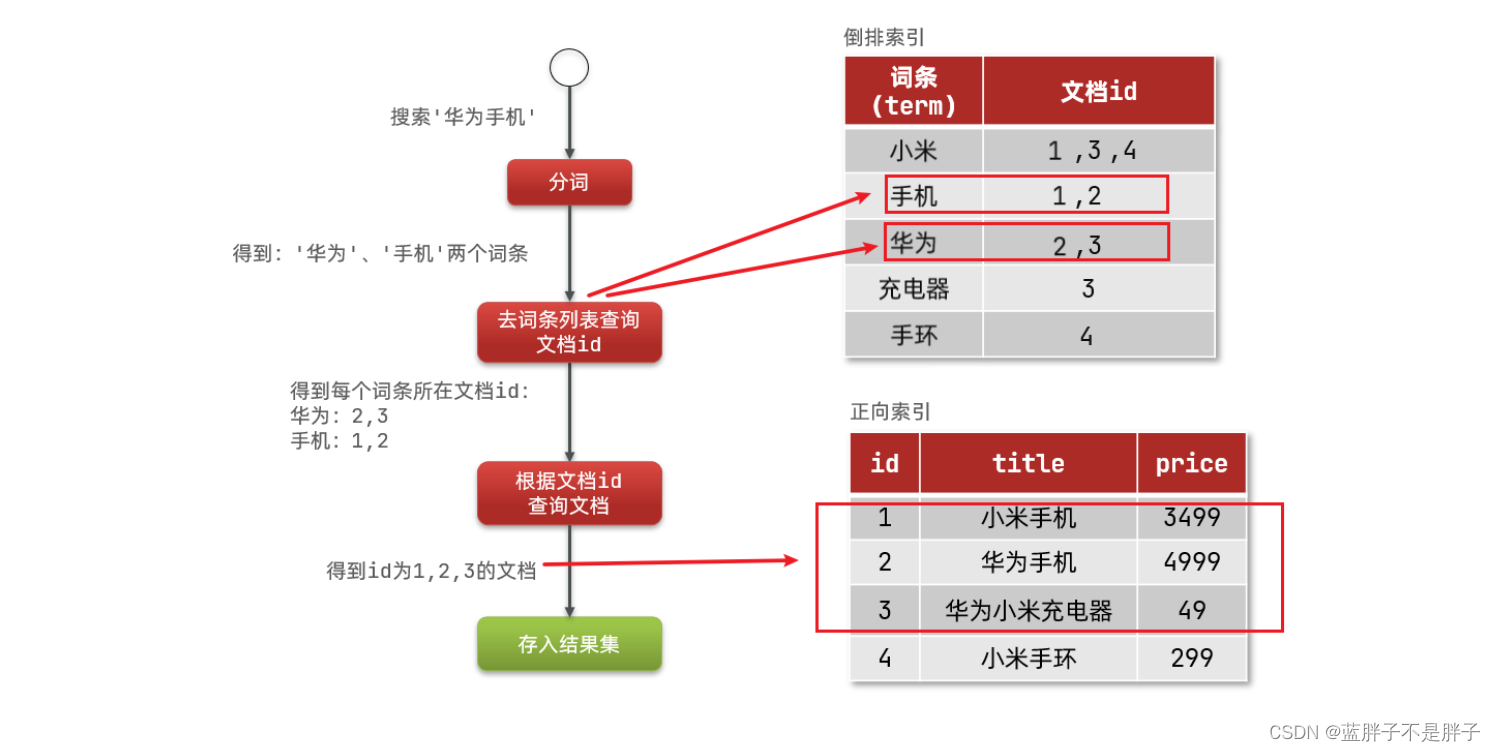
虽然要先查询倒排索引,再查询倒排索引,但是无论是词条、还是文档id都建立了索引,查询速度非常快!无需全表扫描。而向mysql的条件查找就会消耗过多的资源
1.2.3.正向和倒排
那么为什么一个叫做正向索引,一个叫做倒排索引呢?
-
正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
-
而倒排索引则相反,是先找到用户要搜索的词条,根据词条得到保护词条的文档的id,然后根据id获取文档。是根据词条找文档的过程。
大部分的搜索引擎都采用倒排索引,先进行分词查询,在查找文档
那么两者方式的优缺点是什么呢?
正向索引:
- 优点:
- 可以给多个字段创建索引
- 根据索引字段搜索、排序速度非常快
- 缺点:
- 根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描。
倒排索引:
- 优点:
- 根据词条搜索、模糊搜索时,速度非常快
- 缺点:
- 只能给词条创建索引,而不是字段
- 无法根据字段做排序
1.3.es的一些概念
elasticsearch中有很多独有的概念,与mysql中略有差别,但也有相似之处。
1.3.1.文档和字段
elasticsearch是面向**文档(Document)**存储的,可以是数据库中的一条商品数据,一个订单信息。
文档数据格式都会被序列化为json格式后存储在elasticsearch中:

而Json文档中往往包含很多的字段(Field),类似于数据库中的列。
1.3.2.索引和映射
索引(Index),就是相同类型的文档的集合。
例如:
- 所有用户文档,就可以组织在一起,称为用户的索引 类似于同一张表;
- 所有商品的文档,可以组织在一起,称为商品的索引;
- 所有订单的文档,可以组织在一起,称为订单的索引;

因此,我们可以把索引当做是数据库中的表。
数据库的表会有约束信息,用来定义表的结构、字段的名称、类型等信息。因此,索引库中就有映射(mapping),是索引中文档的字段约束信息,类似表的结构约束。

1.3.3.mysql与elasticsearch
我们统一的把mysql与elasticsearch的概念做一下对比:
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
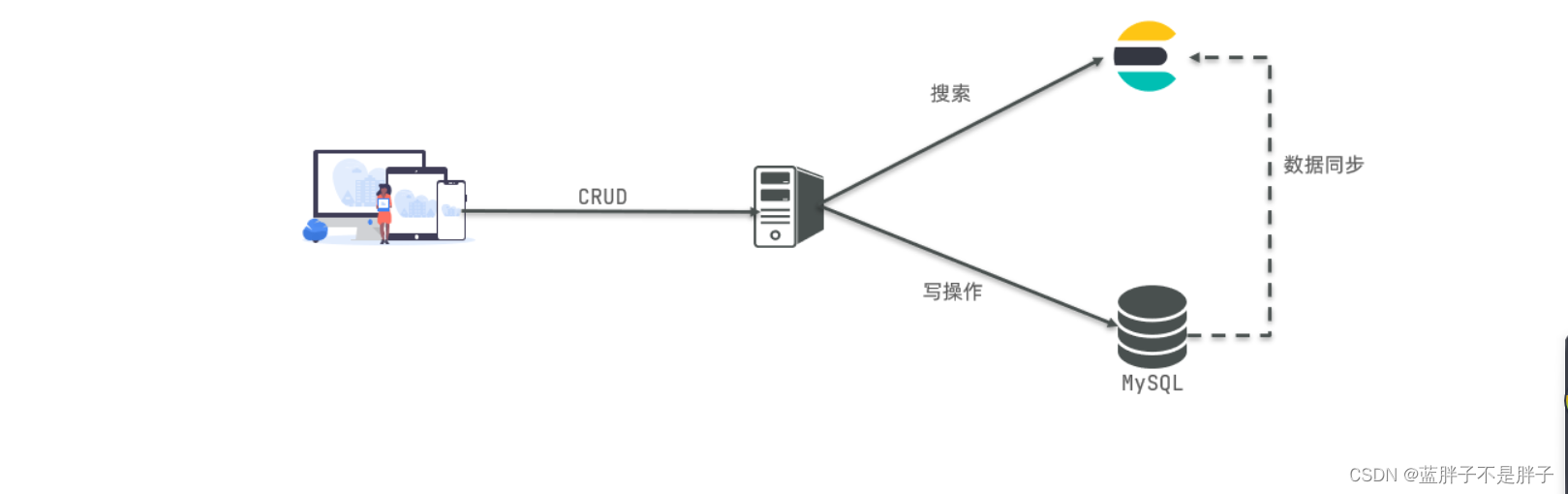
是不是说,我们学习了elasticsearch就不再需要mysql了呢?
并不是如此,两者各自有自己的擅长支出:
-
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
-
Elasticsearch:擅长海量数据的搜索、分析、计算
因此在企业中,往往是两者结合使用:
- 对安全性要求较高的写操作,使用mysql实现
- 对查询性能要求较高的搜索需求,使用elasticsearch实现
- 两者再基于某种方式,实现数据的同步,保证一致性
1.4.安装es、kibana
1.4.1.安装
我这里采用的是 uabntu 使用docker 安装
1.部署单点es
1.1.创建网络
因为我们还需要部署kibana容器,因此需要让es和kibana容器互联。这里先创建一个网络:
1.
docker network create es-net
1.2.拉取镜像
- 拉取Elasticsearch镜像:
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.15.0
上述命令将拉取官方提供的Elasticsearch 7.15.0版本的镜像。
- 拉取Kibana镜像:
docker pull docker.elastic.co/kibana/kibana:7.15.0
下载成功
1.3.运行
运行docker命令,部署单点es:
docker run -d \--name es \-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \-e "discovery.type=single-node" \-v es-data:/usr/share/elasticsearch/data \-v es-plugins:/usr/share/elasticsearch/plugins \--privileged \--network es-net \-p 9200:9200 \-p 9300:9300 \docker.elastic.co/elasticsearch/elasticsearch:7.15.0命令解释:
-e "cluster.name=es-docker-cluster":设置集群名称-e "http.host=0.0.0.0":监听的地址,可以外网访问-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小-e "discovery.type=single-node":单点-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录--privileged:授予逻辑卷访问权--network es-net:加入一个名为es-net的网络中-p 9200:9200:端口映射配置
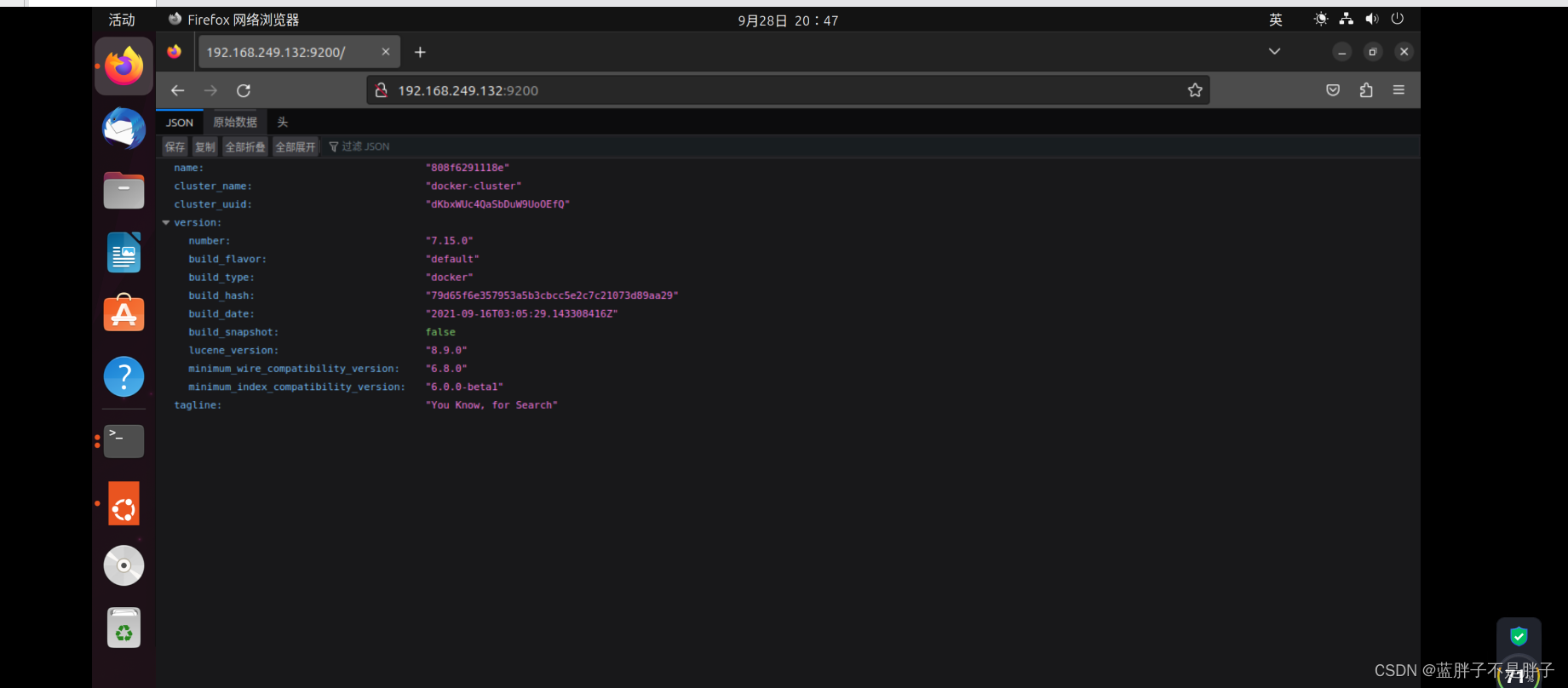
在浏览器中输入:http://ip:9200 即可看到elasticsearch的响应结果:
2.部署kibana
kibana可以给我们提供一个elasticsearch的可视化界面,便于我们学习。
2.1.部署
运行docker命令,部署kibana
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
docker.elastic.co/kibana/kibana:7.15.0
--network es-net:加入一个名为es-net的网络中,与elasticsearch在同一个网络中-e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch-p 5601:5601:端口映射配置
kibana启动一般比较慢,需要多等待一会,可以通过命令:
docker logs -f kibana
查看运行日志,当查看到下面的日志,说明成功:
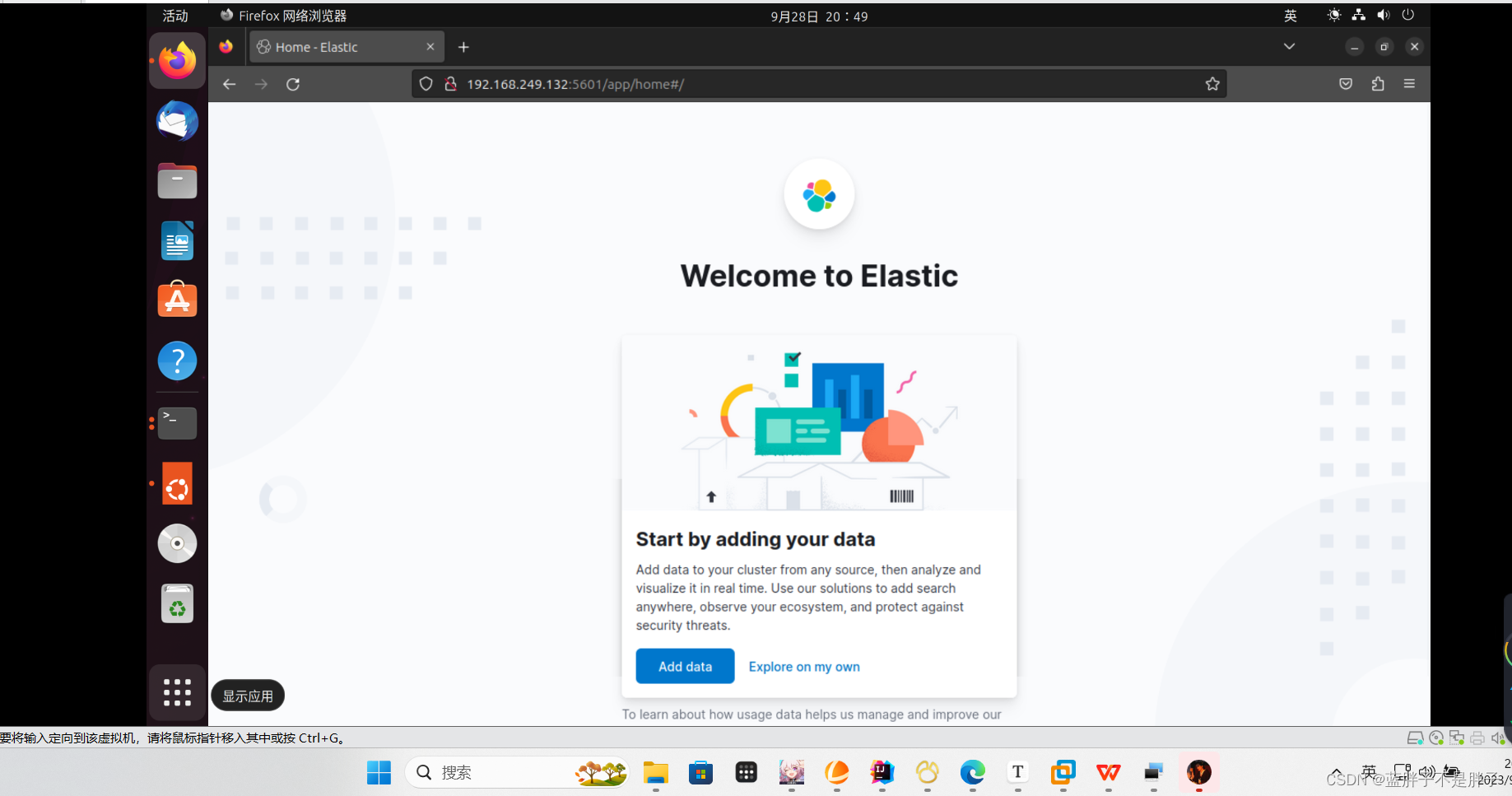
此时,在浏览器输入地址访问:http://ip
:5601,即可看到结果
2.2.DevTools
kibana中提供了一个DevTools界面:
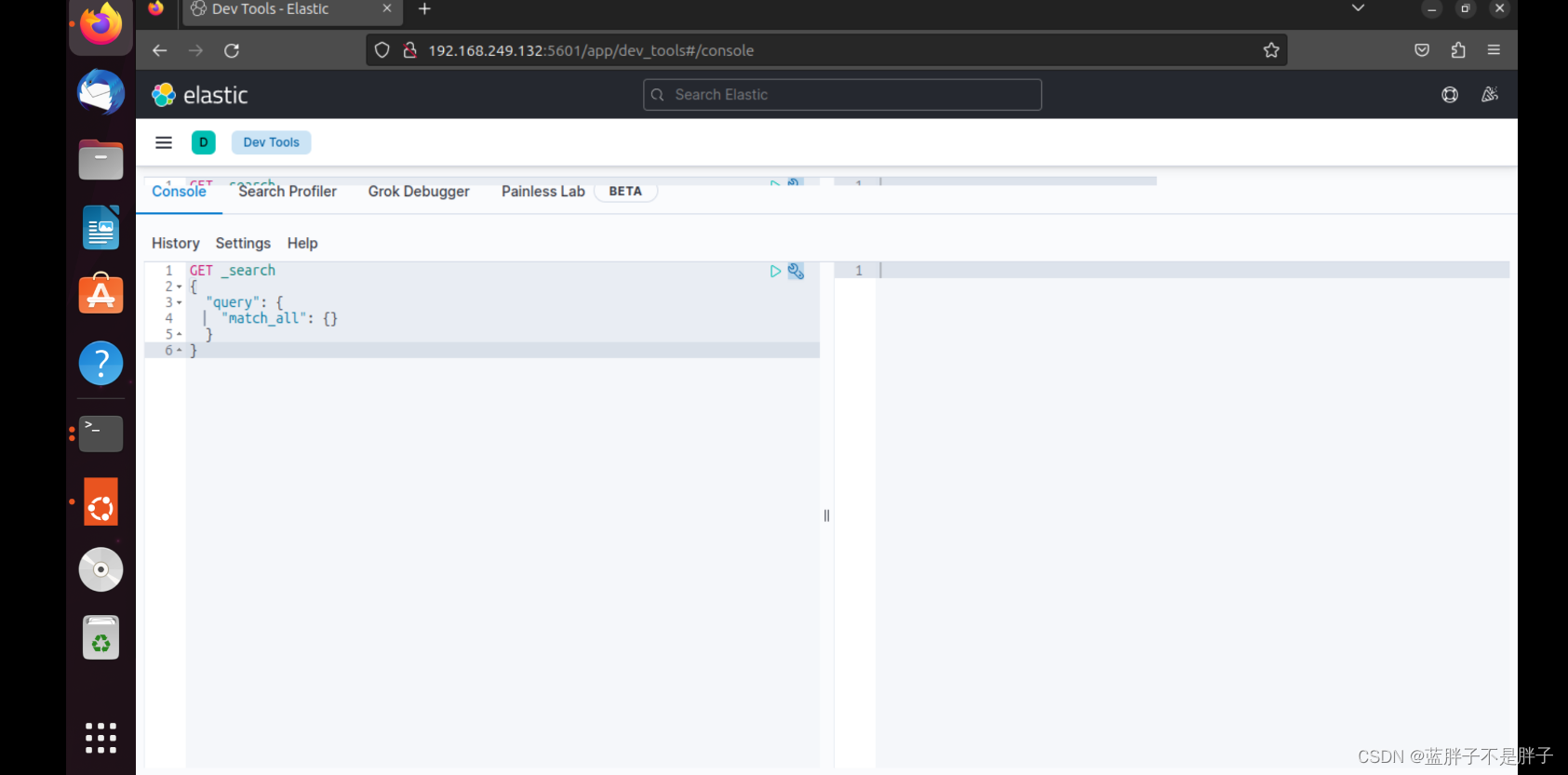
这个界面中可以编写DSL来操作elasticsearch。并且对DSL语句有自动补全功能。
1.4.2.分词器
因为es创建倒排索引时,需要对文档进行分词,默认没有中文分词(默认中文字符一字一分,根本达不到分词的效果),所以需要自己下载
1.4.2.1 链接下载形式
要在Elasticsearch中安装中文分词器,您可以使用Elasticsearch的插件管理工具进行安装。以下是安装elasticsearch-analysis-ik插件的步骤:
1.运行Elasticsearch容器。确保您已经按照之前提供的方法成功拉取并启动了Elasticsearch容器。
2.进入Elasticsearch容器的命令行界面。可以使用以下命令:
docker exec -it elasticsearch /bin/bash
这将进入运行中的Elasticsearch容器的命令行。
3.安装elasticsearch-analysis-ik插件。
在运行的Elasticsearch容器命令行中,执行以下命令来安装elasticsearch-analysis-ik插件:
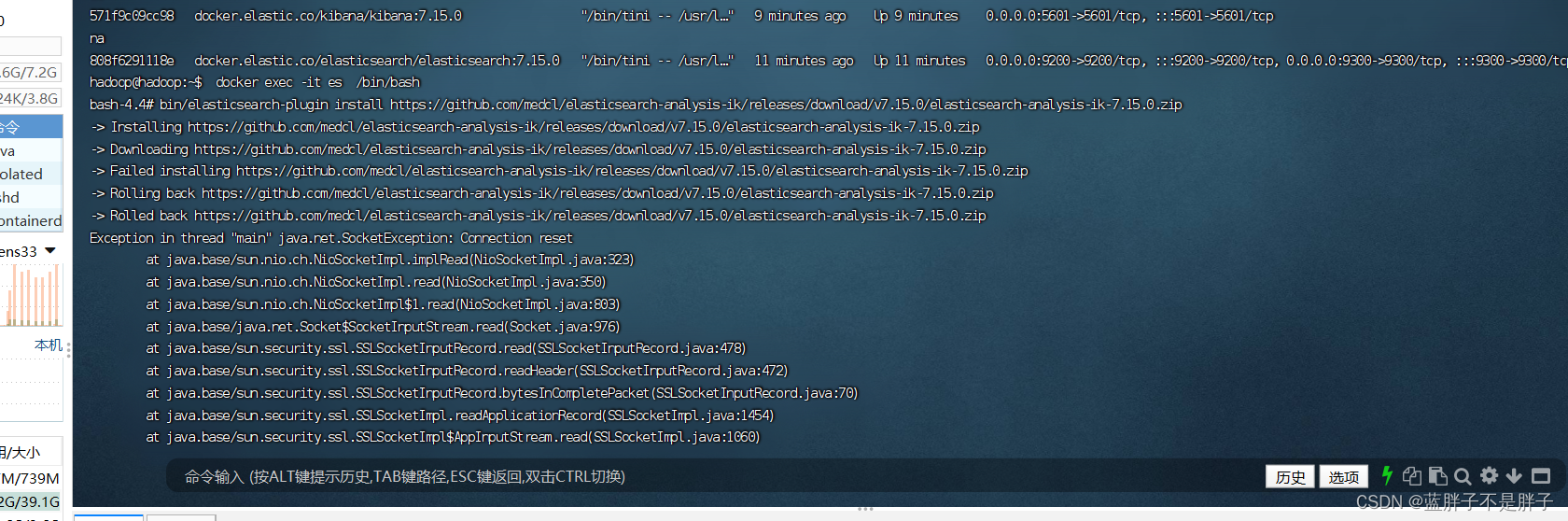
bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.15.0/elasticsearch-analysis-ik-7.15.0.zip
这将下载并安装elasticsearch-analysis-ik插件。插件的版本号与Elasticsearch版本相对应。在本例中,我们使用Elasticsearch 7.15.0,因此选择了elasticsearch-analysis-ik 7.15.0版本。
4.安装完成后,退出容器命令行。
输入 exit 命令退出Elasticsearch容器的命令行。
但是国内容易下载出错
1.4.2.2 手动下载形式
所以采用手动西在分词器,解压到插件库的操作
我的es版本对应的中文分词器插件地址
https://github.com/medcl/elasticsearch-analysis-ik/releases?page=5
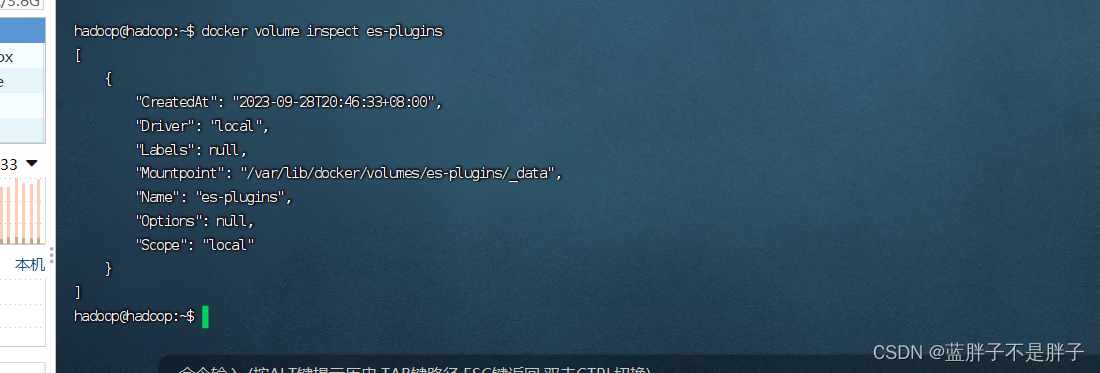
查看创建时候的插件数据卷所在目录
docker volume inspect es-plugins
把上传的插件移动到一个新建立的ik文件夹

mkdir ikmv elasticsearch-analysis-ik-7.15.0.zip ik/cd ik/
解压zip文件
unzip elasticsearch-analysis-ik-7.15.0.zip rm elasticsearch-analysis-ik-7.15.0.zip #删除不需要的解压包把这个ik包移动到插件数据卷所在的目录
sudo mv ik/ /var/lib/docker/volumes/es-plugins/_data/
查看确实引进来了

重启容器
docker restart es
查看日志
# 查看es日志
docker logs -f es
测试
IK分词器包含两种模式:
-
ik_smart:最少切分 -
ik_max_word:最细切分
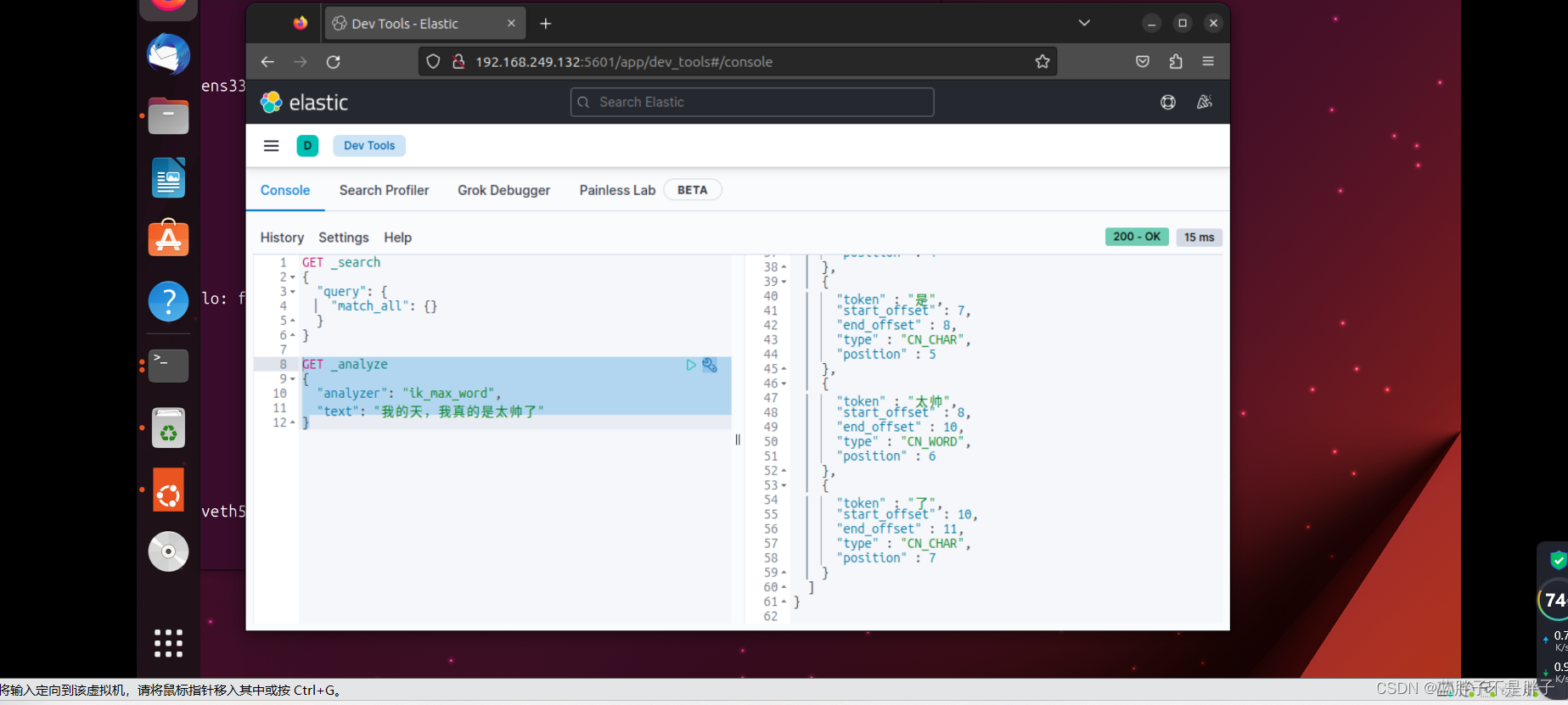
我测试按照最细切分,发现不在是一个字一个字的切分说明成功
智能切分:
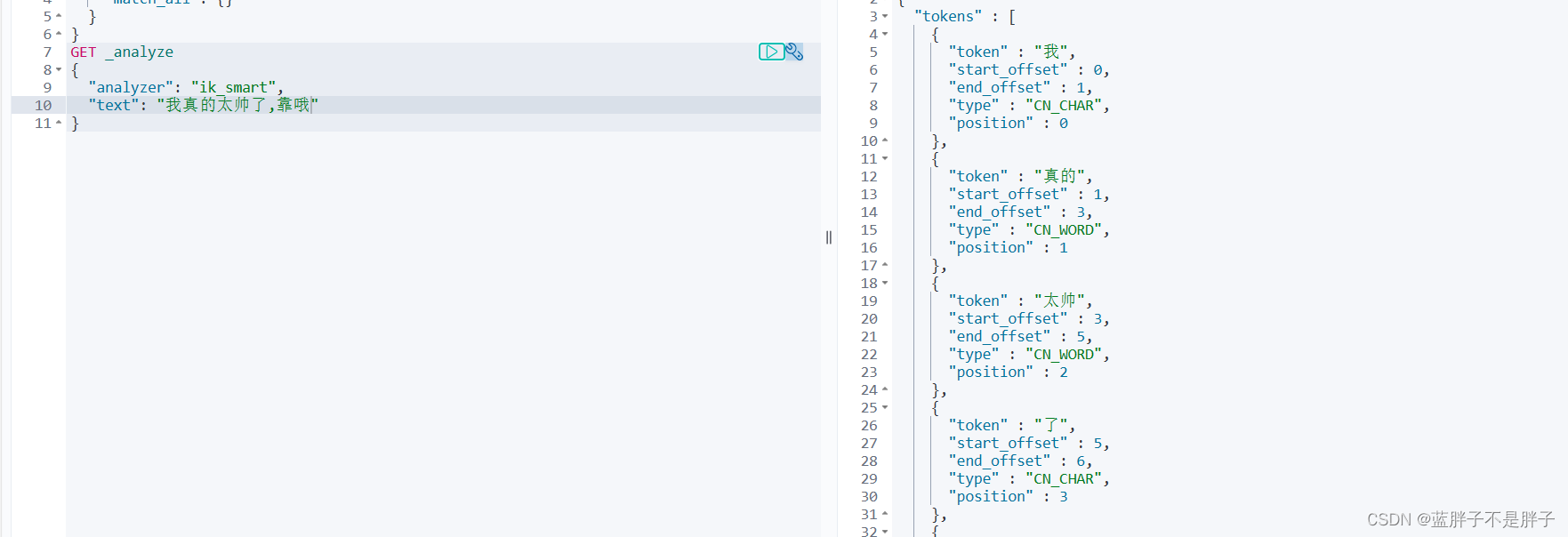
俩种模式差别不大,max会按照中文词语的最小程度划分,这样所搜的精度是提升了,但是消耗资源过大,并且返回数据会变多,一般只能模式即可
- get 后跟服务名,官方的实列是查找服务 我这里测试的是分词器服务
- 发送get请求给对应服务,携带参数构成完整请求
- 比如query 就是get请求的方式 match是匹配 而我访问分词器,需要指定模式,以及文本
扩展词词典
随着互联网的发展,“造词运动”也越发的频繁。出现了很多新的词语,在原有的词汇列表中并不存在。比如:“奥力给”,“哈基咪” 等。
所以我们的词汇也需要不断的更新,IK分词器提供了扩展词汇的功能。
可以看到,对于网络用于,连分词较粗的智能分词也无法将网络用词认为是词语,只能按照字裁开
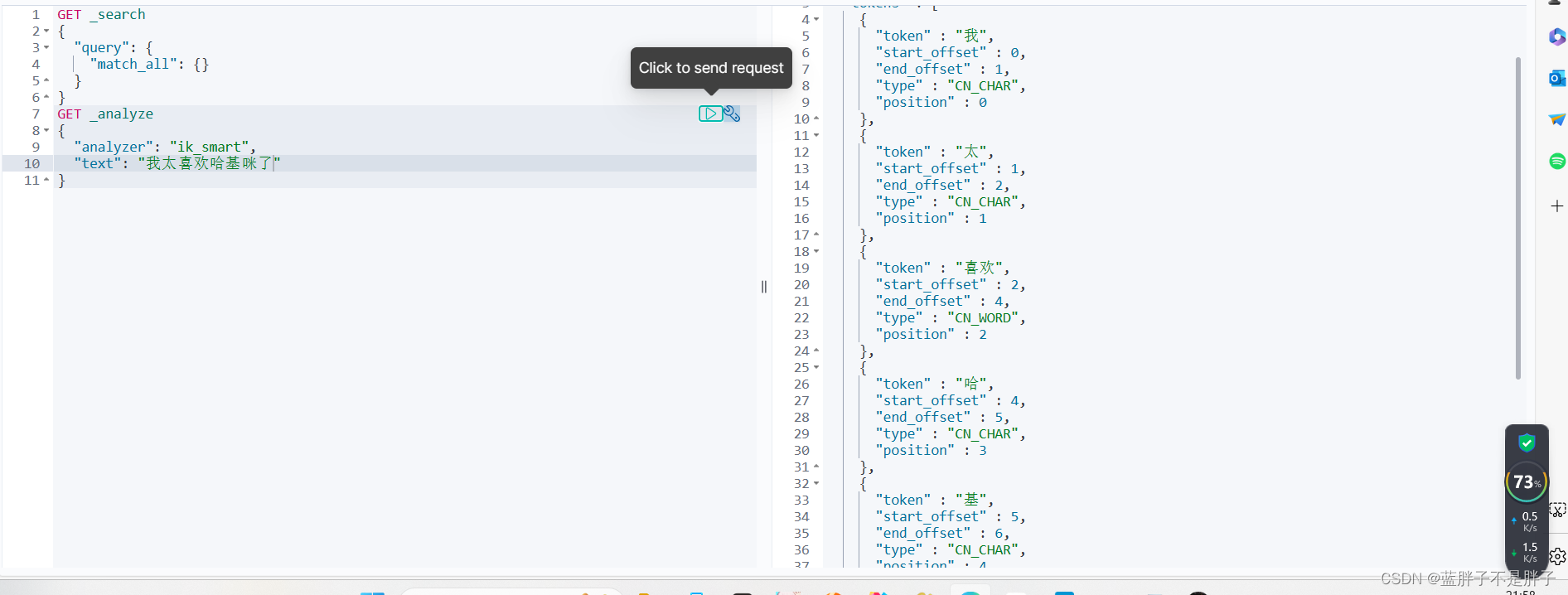
所以我们在字典中添加词语
分词器插件目录有专门的配置文件设置词语,所以我才用ubantu来演示
可以看到有专门的config文件夹
其中的xml结尾的文件就是中心配置文件,使用gedit打开文本
贴心的著名了使用方法,所以跟着他的说明,解开一个注释,并且写一个文本文件名(以dic结尾表示是字典),比如myword.dir

建立这个名字对应文本文件 这里是dic
写添加的字典词语
重启容器
docker restart es
只smart智能模式分词成功
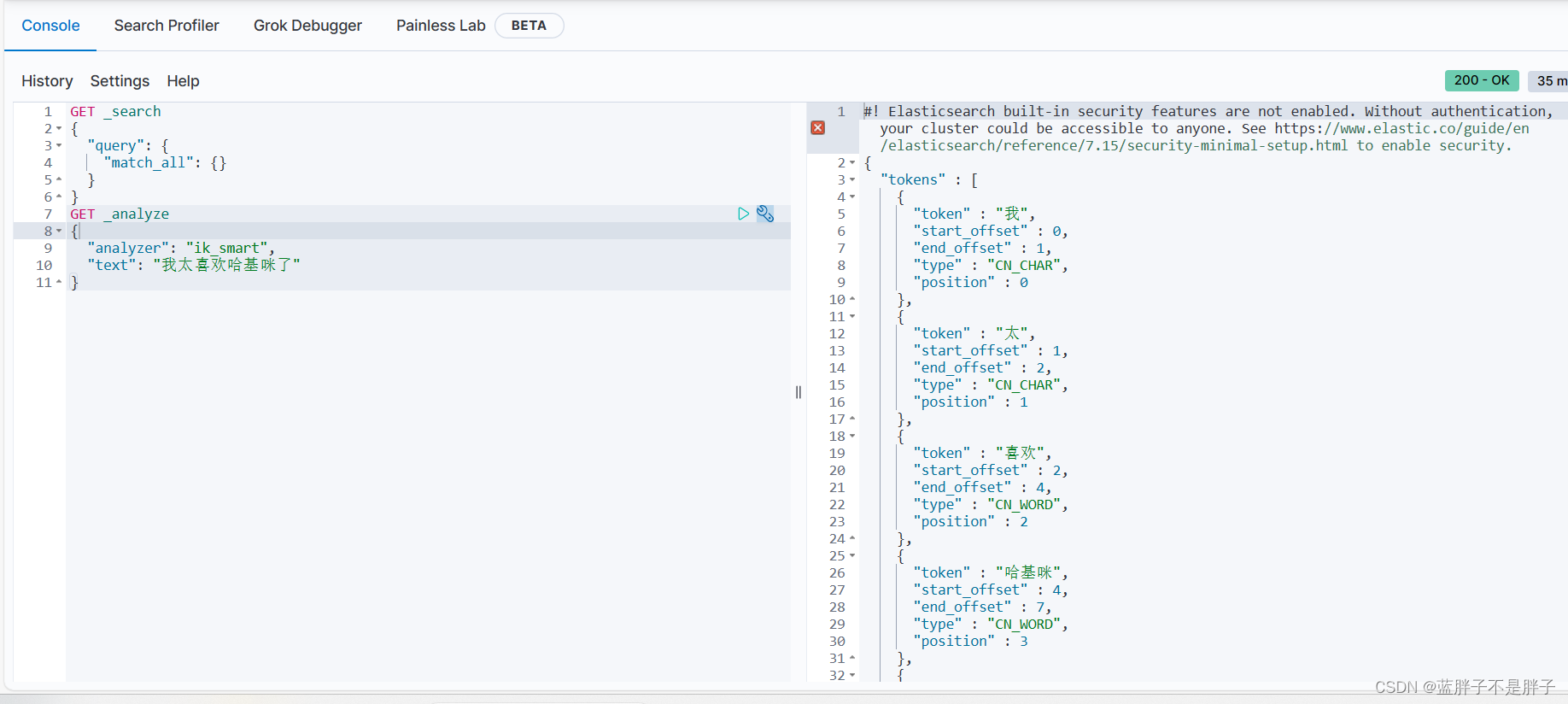
max最大精细度模式分词成功
同理,还有一个可以使用常用得停止词库,有一些的,得,in,还有禁忌词语应该不参与倒排分词处理,所以哦我们要使用停止分词得插件,使用方法也和上面一样
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典--><entry key="ext_dict">ext.dic</entry><!--用户可以在这里配置自己的扩展停止词字典 *** 添加停用词词典--><entry key="ext_stopwords">stopword.dic</entry>
</properties>
1.4.3.总结
分词器的作用是什么?
- 创建倒排索引时对文档分词
- 用户搜索时,对输入的内容分词
IK分词器有几种模式?
- ik_smart:智能切分,粗粒度
- ik_max_word:最细切分,细粒度
IK分词器如何拓展词条?如何停用词条?
- 利用config目录的IkAnalyzer.cfg.xml文件添加拓展词典和停用词典
- 在词典中添加拓展词条或者停用词条
2.索引库操作
索引库就类似数据库表,mapping映射就类似表的结构。
我们要向es中存储数据,必须先创建“库”和“表”。

2.1.mapping映射属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
- type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认为true ,也就是说所有字段都要参与倒排索引搜索,一般要设置那些参加或者不参加
- analyzer:使用哪种分词器
- properties:该字段的子字段
例如下面的json文档:
{"age": 21,"weight": 52.1,"isMarried": false,"info": "程序员Java讲师","email": "zy@itcast.cn","score": [99.1, 99.5, 98.9],"name": {"firstName": "云","lastName": "赵"}
}
对应的每个字段映射(mapping):
- age:类型为 integer;参与搜索,因此需要index为true;无需分词器
- weight:类型为float;参与搜索,因此需要index为true;无需分词器
- isMarried:类型为boolean;参与搜索,因此需要index为true;无需分词器
- info:类型为字符串,需要分词,因此是text;参与搜索,因此需要index为true;分词器可以用ik_smart
- email:类型为字符串,但是不需要分词,因此是keyword;不参与搜索,因此需要index为false;无需分词器
- score:虽然是数组,但是我们只看元素的类型,类型为float;参与搜索,因此需要index为true;无需分词器
- name:类型为object,需要定义多个子属性
- name.firstName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
- name.lastName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
比如我创建一个书籍索引
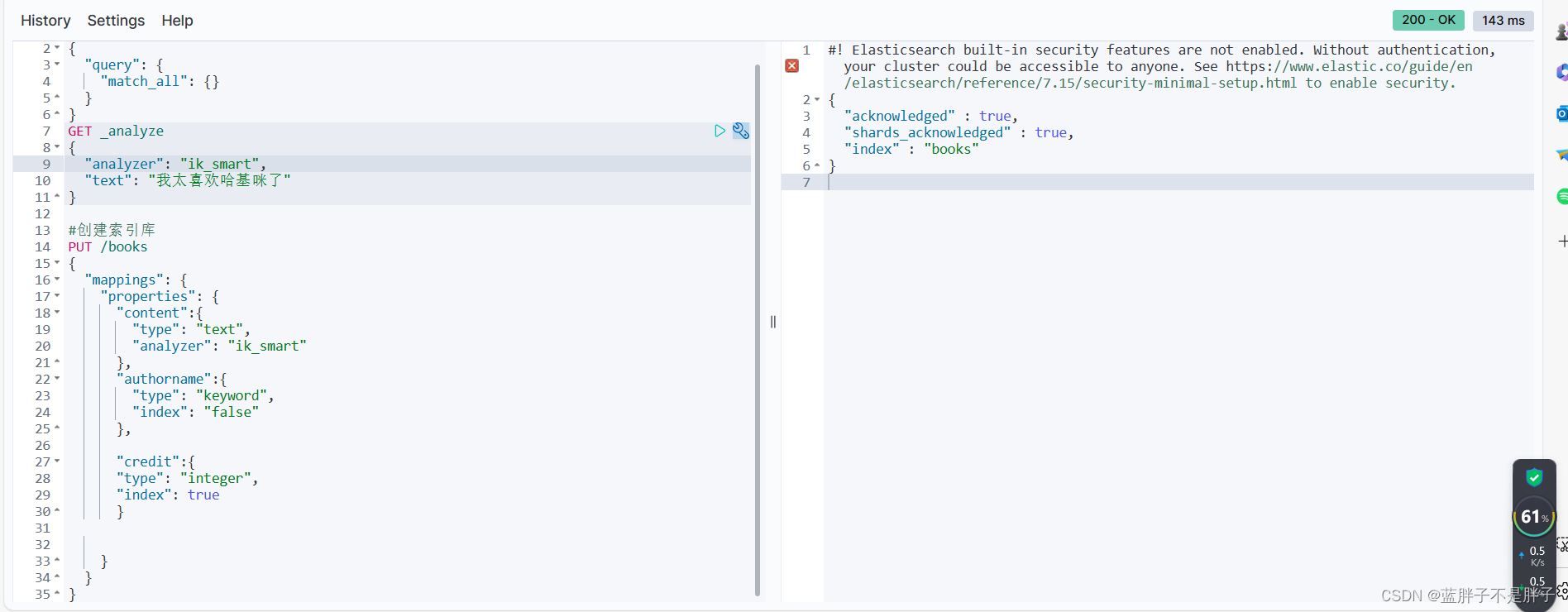
PUT /books
{"mappings": {"properties": {"content":{"type": "text","analyzer": "ik_smart"},"authorname":{"type": "keyword","index": "false"},"credit":{"type": "integer","index": true}}}
}
2.2.索引库的CRUD
这里我们统一使用Kibana编写DSL的方式来演示。
2.2.1.创建索引库和映射
基本语法:
- 请求方式:PUT
- 请求路径:/索引库名,可以自定义
- 请求参数:mapping映射
格式:
PUT /索引库名称
{"mappings": {"properties": {"字段名":{"type": "text","analyzer": "ik_smart"},"字段名2":{"type": "keyword","index": "false"},"字段名3":{"properties": {"子字段": {"type": "keyword"}}},// ...略}}
}
示例:
PUT /heima
{"mappings": {"properties": {"info":{"type": "text","analyzer": "ik_smart"},"email":{"type": "keyword","index": "falsae"},"name":{"properties": {"firstName": {"type": "keyword"}}},// ... 略}}
}
2.2.2.查询索引库结构
基本语法:
-
请求方式:GET
-
请求路径:/索引库名
-
请求参数:无
格式:
GET /索引库名
示例:
)
2.2.3.修改索引库
倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,这简直是灾难。因此索引库一旦创建,无法修改mapping。
虽然无法修改mapping中已有的字段,但是却允许添加新的字段到mapping中,因为不会对倒排索引产生影响。
语法说明:
PUT /索引库名/_mapping
{"properties": {"新字段名":{"type": "integer"}}
}
示例:
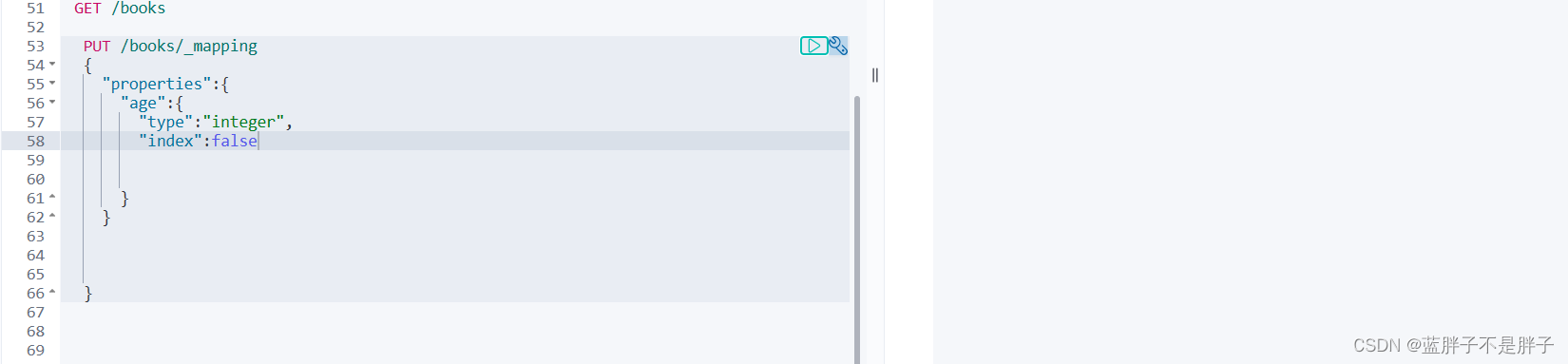
查看索引结构
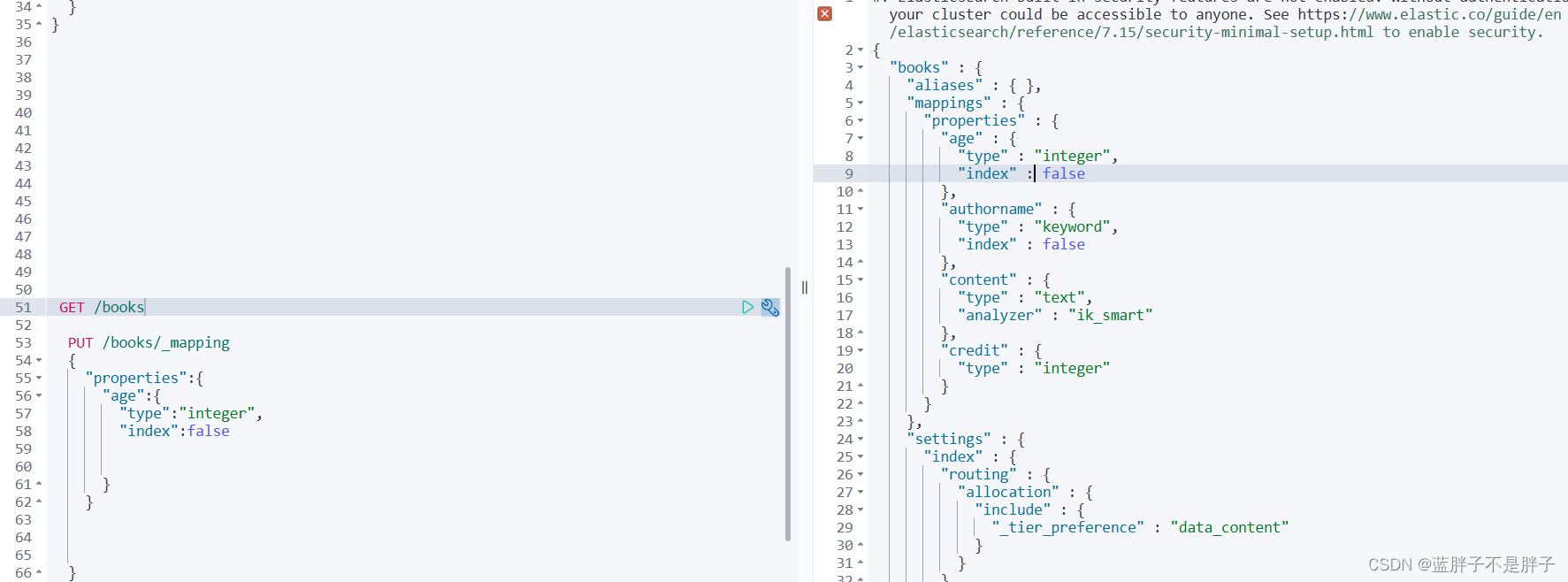
修改成功
2.2.4.删除索引库
语法:
-
请求方式:DELETE
-
请求路径:/索引库名
-
请求参数:无
格式:
DELETE /索引库名
在kibana中测试:
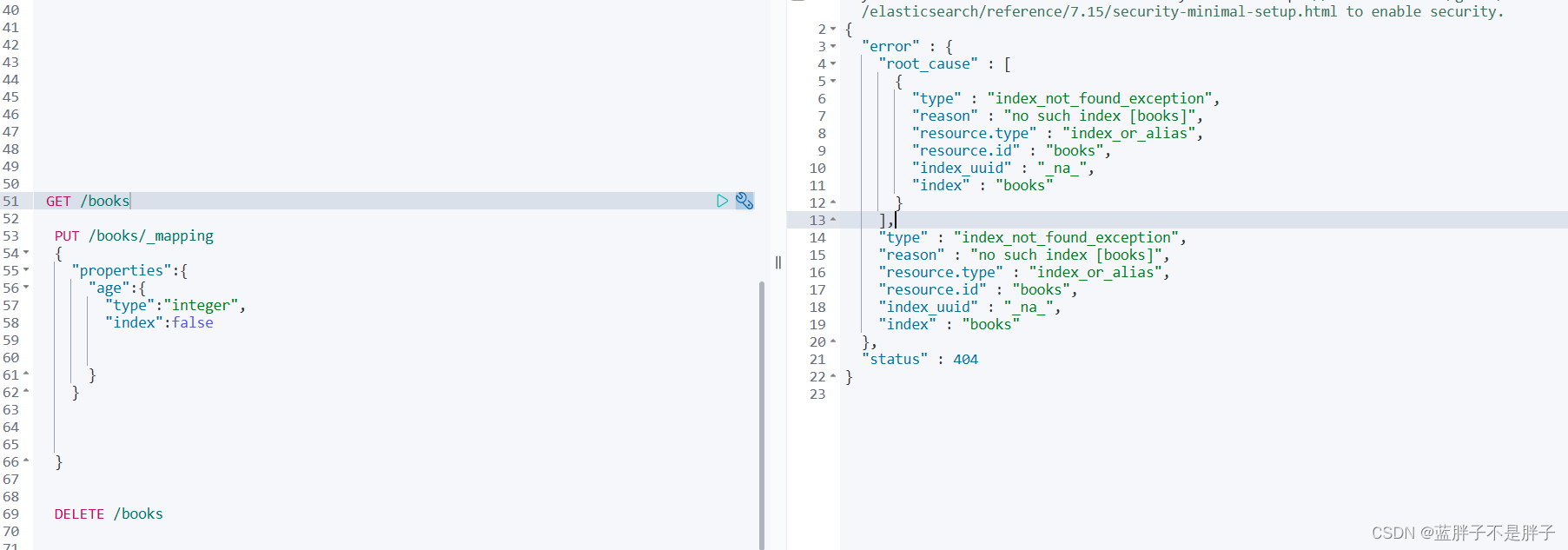
2.2.5.总结
索引库操作有哪些?
- 创建索引库:PUT /索引库名
- 查询索引库:GET /索引库名
- 删除索引库:DELETE /索引库名
- 添加字段:PUT /索引库名/_mapping
3.文档操作
3.1.新增文档
语法:
POST /索引库名/_doc/文档id
{"字段1": "值1","字段2": "值2","字段3": {"子属性1": "值3","子属性2": "值4"},// ...
}
示例:
POST /books/_doc/23
{"authorname":"老帅","content":"我现在也太帅了"}响应:
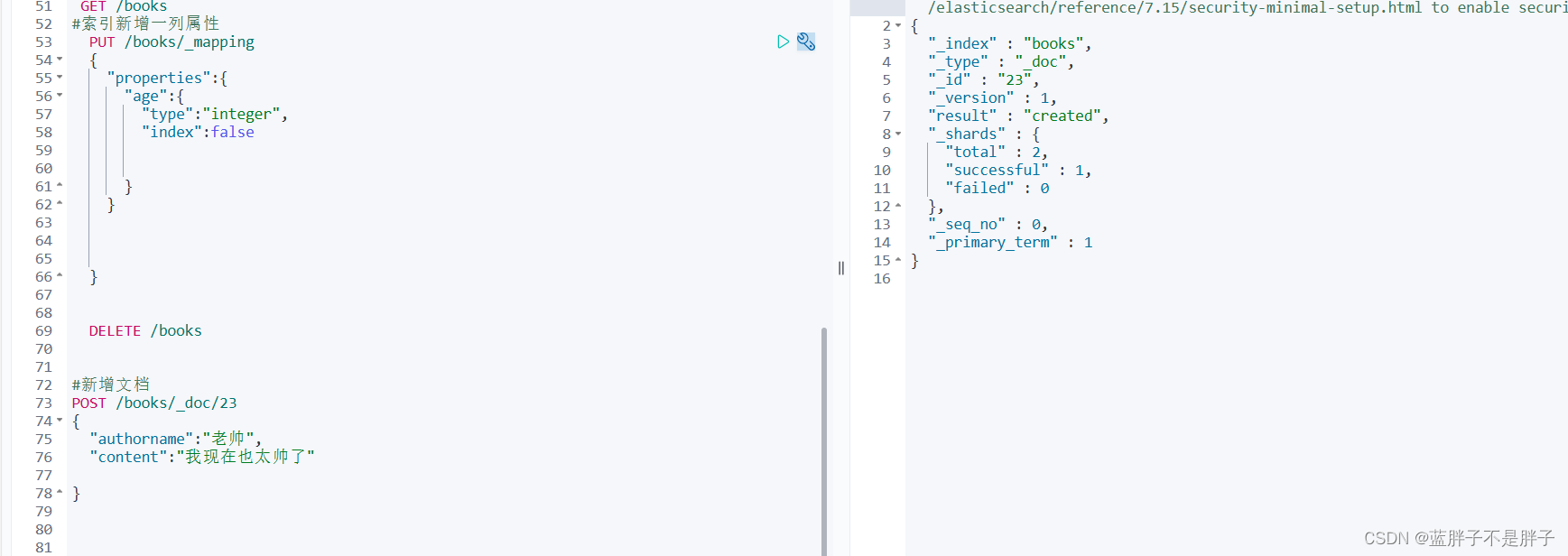
3.2.查询文档
根据rest风格,新增是post,查询应该是get,不过查询一般都需要条件,这里我们把文档id带上。
语法:
GET /{索引库名称}/_doc/{id}
通过kibana查看数据:
get /books/_doc/23
查看结果:
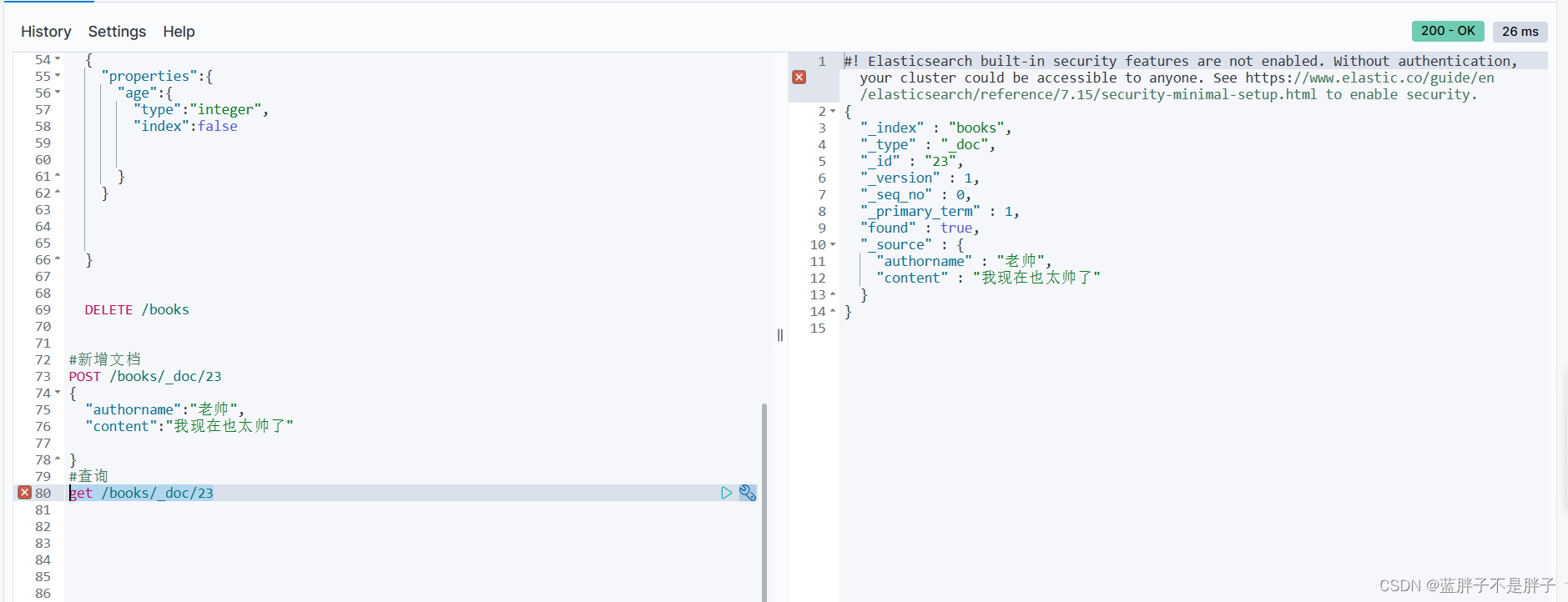
source 插入时候插入得元数据
version:文档被修改过几次的版本
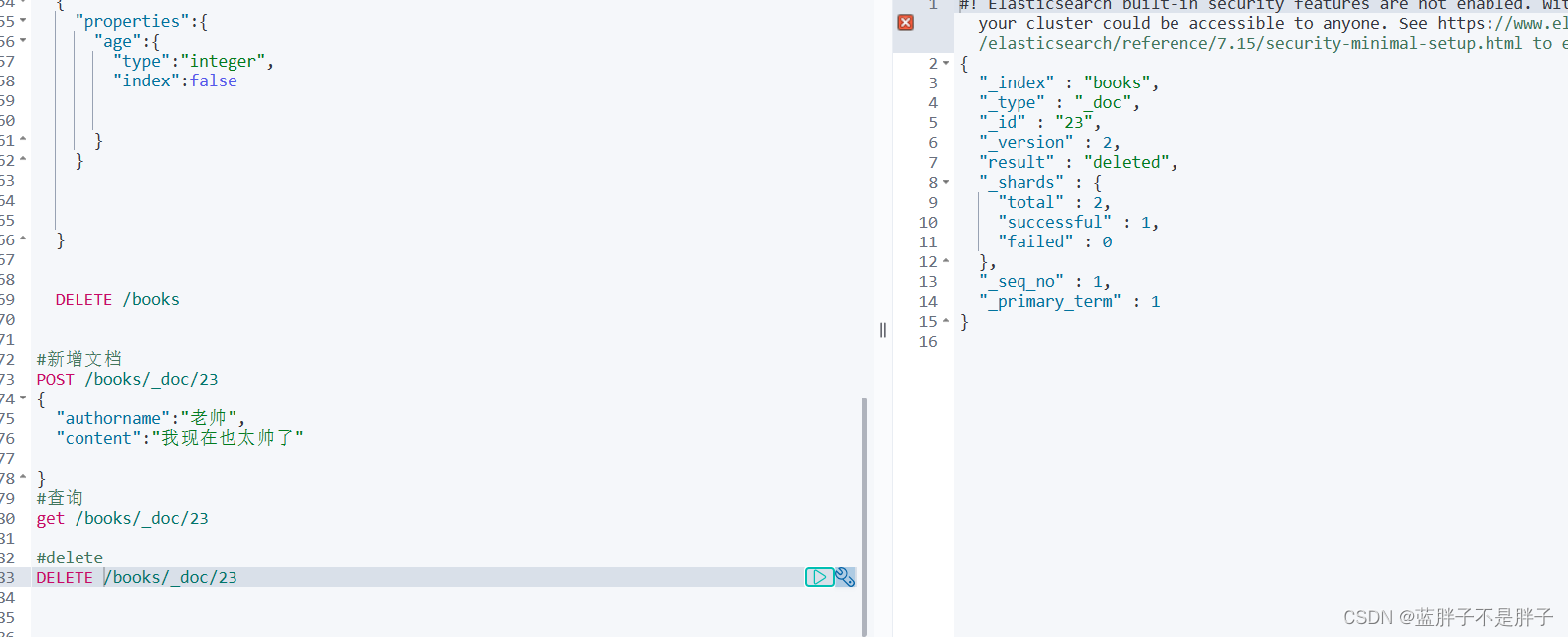
3.3.删除文档
删除使用DELETE请求,同样,需要根据id进行删除:
语法:
DELETE /{索引库名}/_doc/id值
示例:
# 根据id删除数据
DELETE /books/_doc/23
结果:
3.4.修改文档
修改有两种方式:
- 全量修改:直接覆盖原来的文档
- 增量修改:修改文档中的部分字段
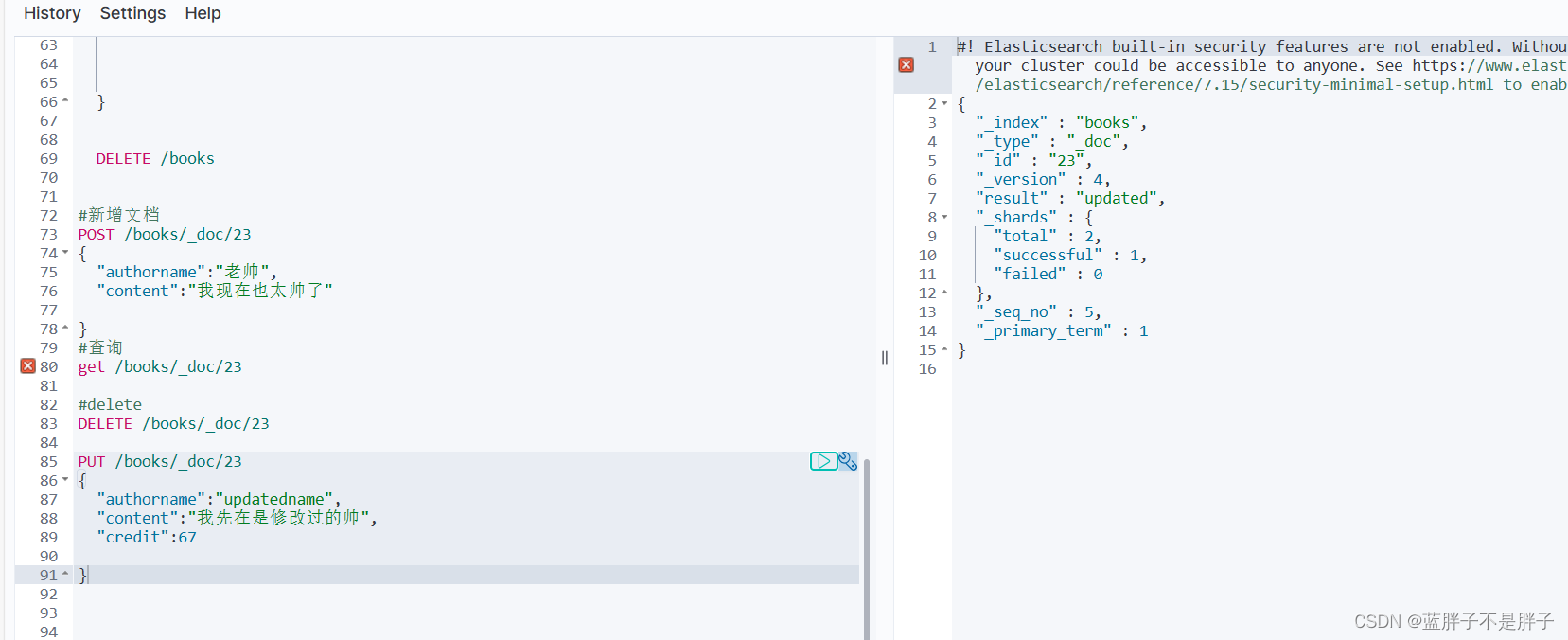
3.4.1.全量修改
全量修改是覆盖原来的文档,其本质是:
- 根据指定的id删除文档
- 新增一个相同id的文档
注意:如果根据id删除时,id不存在,第二步的新增也会执行,也就从修改变成了新增操作了。
语法:
和新增文档一样的格式,只是请求方式不变
put=delete+post的方式
PUT /{索引库名}/_doc/文档id
{"字段1": "值1","字段2": "值2",// ... 略
}示例:
PUT /books/_doc/23
{"authorname":"updatedname","content":"我先在是修改过的帅","credit":67}
3.4.2.增量修改
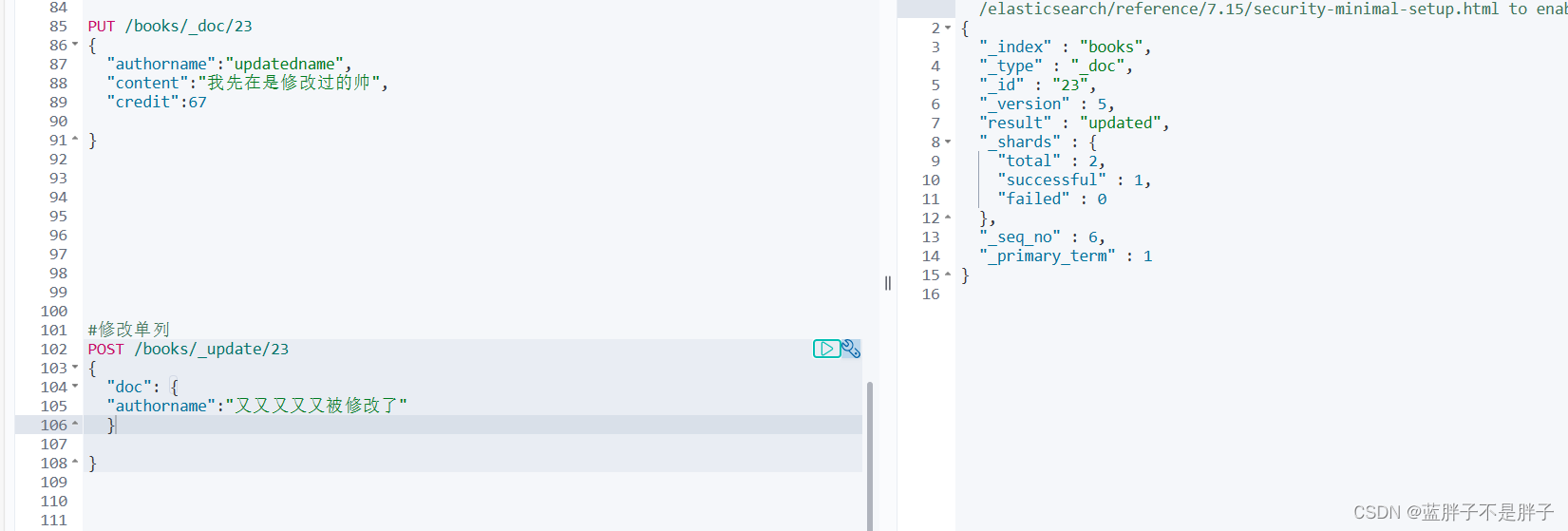
增量修改是只修改指定id匹配的文档中的部分字段。
语法:
POST /{索引库名}/_update/文档id
{"doc": {"字段名": "新的值",}
}
示例:
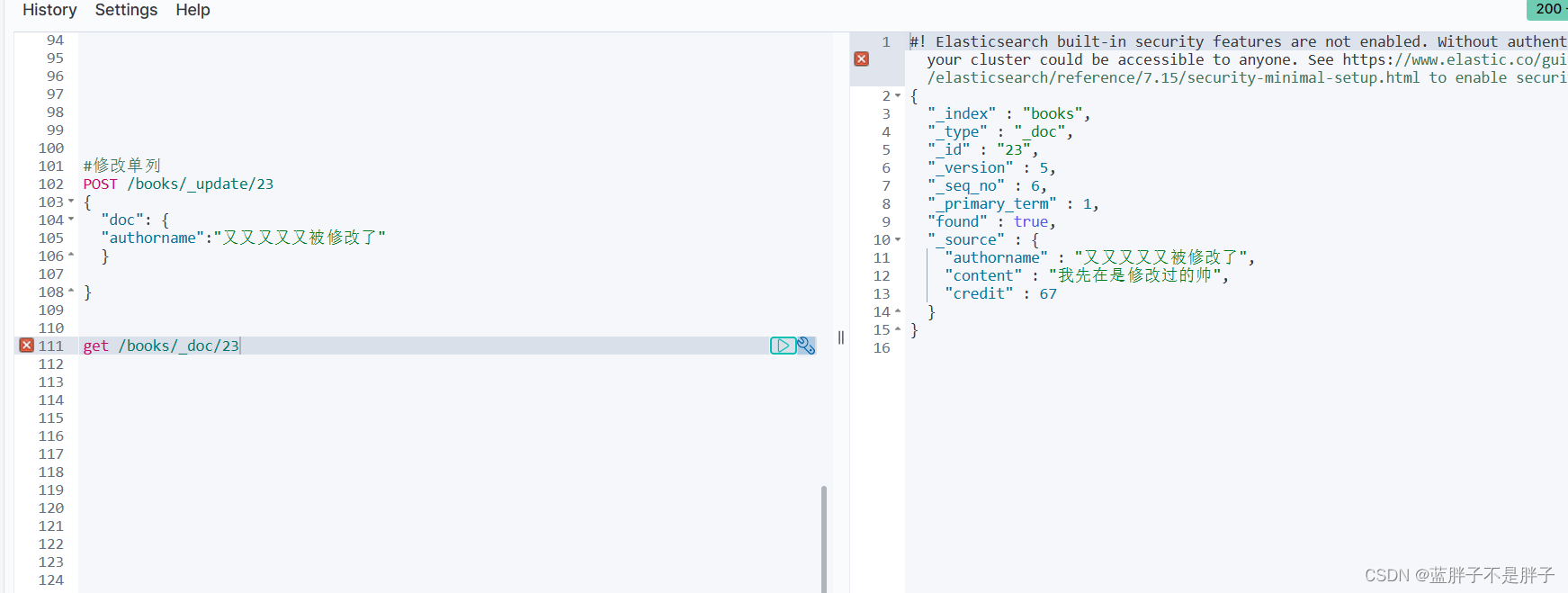
#修改单列
POST /books/_update/23
{"doc": {"authorname":"又又又又又被修改了" } }返回相应,再次查看
再次查看
3.5.总结
文档操作有哪些?
- 创建文档:POST /{索引库名}/_doc/文档id { json文档 }
- 查询文档:GET /{索引库名}/_doc/文档id
- 删除文档:DELETE /{索引库名}/_doc/文档id
- 修改文档:
- 全量修改:PUT /{索引库名}/_doc/文档id { json文档 }
- 增量修改:POST /{索引库名}/_update/文档id { “doc”: {字段}}
4.RestAPI
ES官方提供了各种不同语言的客户端,用来操作ES。这些客户端的本质就是组装DSL语句,通过http请求发送给ES。官方文档地址:https://www.elastic.co/guide/en/elasticsearch/client/index.html
其实就是es官方为各种编程语言写的客户端工具

其中的Java Rest Client又包括两种:
- Java Low Level Rest Client
- Java High Level Rest Client
我们学习的是Java HighLevel Rest Client客户端API
4.0.1.导入数据
导入到数据库
数据结构如下:
CREATE TABLE `tb_hotel` (`id` bigint(20) NOT NULL COMMENT '酒店id',`name` varchar(255) NOT NULL COMMENT '酒店名称;例:7天酒店',`address` varchar(255) NOT NULL COMMENT '酒店地址;例:航头路',`price` int(10) NOT NULL COMMENT '酒店价格;例:329',`score` int(2) NOT NULL COMMENT '酒店评分;例:45,就是4.5分',`brand` varchar(32) NOT NULL COMMENT '酒店品牌;例:如家',`city` varchar(32) NOT NULL COMMENT '所在城市;例:上海',`star_name` varchar(16) DEFAULT NULL COMMENT '酒店星级,从低到高分别是:1星到5星,1钻到5钻',`business` varchar(255) DEFAULT NULL COMMENT '商圈;例:虹桥',`latitude` varchar(32) NOT NULL COMMENT '纬度;例:31.2497',`longitude` varchar(32) NOT NULL COMMENT '经度;例:120.3925',`pic` varchar(255) DEFAULT NULL COMMENT '酒店图片;例:/img/1.jpg',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
4.0.3.mapping映射分析
创建索引库,最关键的是mapping映射,而mapping映射要考虑的信息包括:
- 字段名
- 字段数据类型
- 是否参与搜索
- 是否需要分词
- 如果分词,分词器是什么?
其中:
- 字段名、字段数据类型,可以参考数据表结构的名称和类型
- 是否参与搜索要分析业务来判断,例如图片地址,就无需参与搜索
- 是否分词呢要看内容,内容如果是一个整体就无需分词,反之则要分词
- 分词器,我们可以统一使用ik_max_word
来看下酒店数据的索引库结构:
PUT /hotel
{"mappings": {"properties": {"id": {"type": "keyword"},"name":{"type": "text","analyzer": "ik_max_word","copy_to": "all"},"address":{"type": "keyword","index": false},"price":{"type": "integer"},"score":{"type": "integer"},"brand":{"type": "keyword","copy_to": "all"},"city":{"type": "keyword","copy_to": "all"},"starName":{"type": "keyword"},"business":{"type": "keyword"},"location":{"type": "geo_point"},"pic":{"type": "keyword","index": false},"all":{"type": "text","analyzer": "ik_max_word"}}}
}

location:是俩个数据,经纬度拼接起来
几个特殊字段说明:
-
location:地理坐标,里面包含精度、纬度
-
all:一个组合字段,其目的是将多字段的值 利用copy_to合并,提供给用户搜索
主要是多个查询条件搜索的时候使用,比如我想查询多个条件,名字价格,es就会使用copy to 将多个字段的条件复制到一个新字段中进行倒排索引查找,这样就变成了一个字段进行优化,all采用精确分词来提供搜索效率

4.0.4.初始化RestClient
在elasticsearch提供的API中,与elasticsearch一切交互都封装在一个名为RestHighLevelClient的类中,必须先完成这个对象的初始化,建立与elasticsearch的连接。
分为三步:
1)引入es的RestHighLevelClient依赖:
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
2)因为SpringBoot默认的ES版本是7.6.2,所以我们需要覆盖默认的ES版本:
<properties><java.version>1.8</java.version><elasticsearch.version>7.15.0</elasticsearch.version>
</properties>
3)初始化RestHighLevelClient:
初始化的代码如下:
像服务器创建客户端对象
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.249.132:9200")
));
这里为了单元测试方便,我们创建一个测试类HotelIndexTest,然后将初始化的代码编写在@BeforeEach方法中:
package cn.itcast.hotel;import org.apache.http.HttpHost;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;import java.io.IOException;public class HotelIndexTest {private RestHighLevelClient client;@BeforeEachvoid setUp() {this.client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.150.101:9200")));}@AfterEachvoid tearDown() throws IOException {this.client.close();}
}
4.1.创建索引库
4.1.1.代码解读
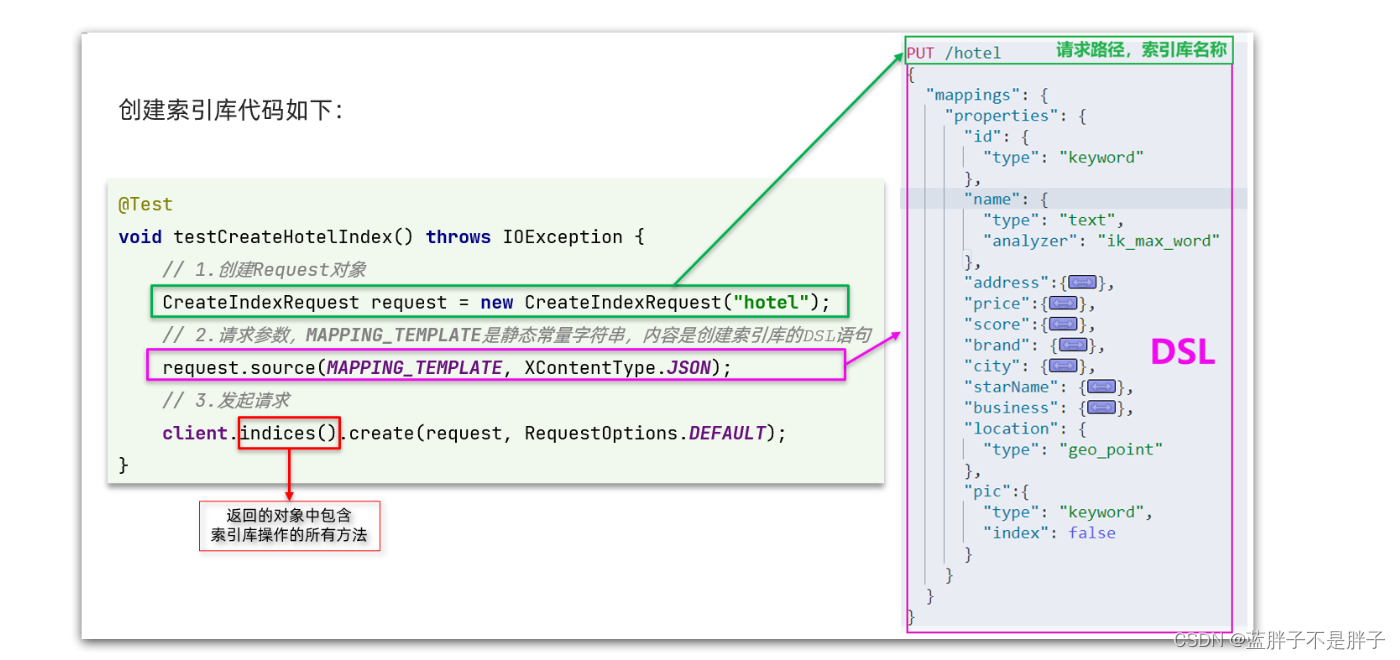
创建索引库的API如下:
代码分为三步:
- 1)创建Request对象。因为是创建索引库的操作,因此Request是CreateIndexRequest。
- 2)添加请求参数,其实就是DSL的JSON参数部分。因为json字符串很长,这里是定义了静态字符串常量MAPPING_TEMPLATE,让代码看起来更加优雅。
- 3)发送请求,client.indices()方法的返回值是IndicesClient类型,封装了所有与索引库操作有关的方法。
4.1.2.完整示例
在hotel-demo的cn.itcast.hotel.constants包下,创建一个类,定义mapping映射的JSON字符串常量:
package cn.itcast.hotel.constants;public class HotelConstants {public static final String MAPPING_TEMPLATE = "{\n" +" \"mappings\": {\n" +" \"properties\": {\n" +" \"id\": {\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"name\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"address\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"price\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"score\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"brand\":{\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"city\":{\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"starName\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"business\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"location\":{\n" +" \"type\": \"geo_point\"\n" +" },\n" +" \"pic\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"all\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\"\n" +" }\n" +" }\n" +" }\n" +"}";
}
在hotel-demo中的HotelIndexTest测试类中,编写单元测试,实现创建索引:
@Test
void createHotelIndex() throws IOException {// 1.创建Request对象CreateIndexRequest request = new CreateIndexRequest("hotel");// 2.准备请求的参数:DSL语句request.source(MAPPING_TEMPLATE, XContentType.JSON);// 3.发送请求client.indices().create(request, RequestOptions.DEFAULT);
}
4.2.删除索引库
删除索引库的DSL语句非常简单:
DELETE /hotel
与创建索引库相比:
- 请求方式从PUT变为DELTE
- 请求路径不变
- 无请求参数
所以代码的差异,注意体现在Request对象上。依然是三步走:
- 1)创建Request对象。这次是DeleteIndexRequest对象
- 2)准备参数。这里是无参
- 3)发送请求。改用delete方法
在hotel-demo中的HotelIndexTest测试类中,编写单元测试,实现删除索引:
@Test
void testDeleteHotelIndex() throws IOException {// 1.创建Request对象DeleteIndexRequest request = new DeleteIndexRequest("hotel");// 2.发送请求client.indices().delete(request, RequestOptions.DEFAULT);
}
4.3.判断索引库是否存在
判断索引库是否存在,本质就是查询,对应的DSL是:
GET /hotel
因此与删除的Java代码流程是类似的。依然是三步走:
- 1)创建Request对象。这次是GetIndexRequest对象
- 2)准备参数。这里是无参
- 3)发送请求。改用exists方法
@Test
void testExistsHotelIndex() throws IOException {// 1.创建Request对象GetIndexRequest request = new GetIndexRequest("hotel");// 2.发送请求boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);// 3.输出System.err.println(exists ? "索引库已经存在!" : "索引库不存在!");
}
4.4.总结
JavaRestClient操作elasticsearch的流程基本类似。核心是**client.indices()**方法来获取索引库的操作对象。
索引库操作的基本步骤:
- 初始化RestHighLevelClient
- 创建XxxIndexRequest。XXX是Create、Get、Delete
- 准备DSL( Create时需要,其它是无参)
- 发送请求。调用RestHighLevelClient#indices().xxx()方法,xxx是create、exists、delete
5.RestClient操作文档
为了与索引库操作分离,我们再次参加一个测试类,做两件事情:
- 初始化RestHighLevelClient
- 我们的酒店数据在数据库,需要利用IHotelService去查询,所以注入这个接口
package cn.itcast.hotel;import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.service.IHotelService;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import java.io.IOException;
import java.util.List;@SpringBootTest
public class HotelDocumentTest {@Autowiredprivate IHotelService hotelService;private RestHighLevelClient client;@BeforeEachvoid setUp() {this.client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.249.132:9200")));}@AfterEachvoid tearDown() throws IOException {this.client.close();}
}5.1.新增文档
我们要将数据库的酒店数据查询出来,写入elasticsearch中。
5.1.1.索引库实体类
数据库查询后的结果是一个Hotel类型的对象。结构如下:
@Data
@TableName("tb_hotel")
public class Hotel {@TableId(type = IdType.INPUT)private Long id;private String name;private String address;private Integer price;private Integer score;private String brand;private String city;private String starName;private String business;private String longitude;private String latitude;private String pic;
}
与我们的索引库结构存在差异:
- longitude和latitude需要合并为location
因此,我们需要定义一个新的类型,与索引库结构吻合:
package cn.itcast.hotel.pojo;import lombok.Data;
import lombok.NoArgsConstructor;@Data
@NoArgsConstructor
public class HotelDoc {private Long id;private String name;private String address;private Integer price;private Integer score;private String brand;private String city;private String starName;private String business;private String location;private String pic;public HotelDoc(Hotel hotel) {this.id = hotel.getId();this.name = hotel.getName();this.address = hotel.getAddress();this.price = hotel.getPrice();this.score = hotel.getScore();this.brand = hotel.getBrand();this.city = hotel.getCity();this.starName = hotel.getStarName();this.business = hotel.getBusiness();this.location = hotel.getLatitude() + ", " + hotel.getLongitude();this.pic = hotel.getPic();}
}5.1.2.语法说明
新增文档的DSL语句如下:
POST /{索引库名}/_doc/1
{"name": "Jack","age": 21
}
对应的java代码如图:
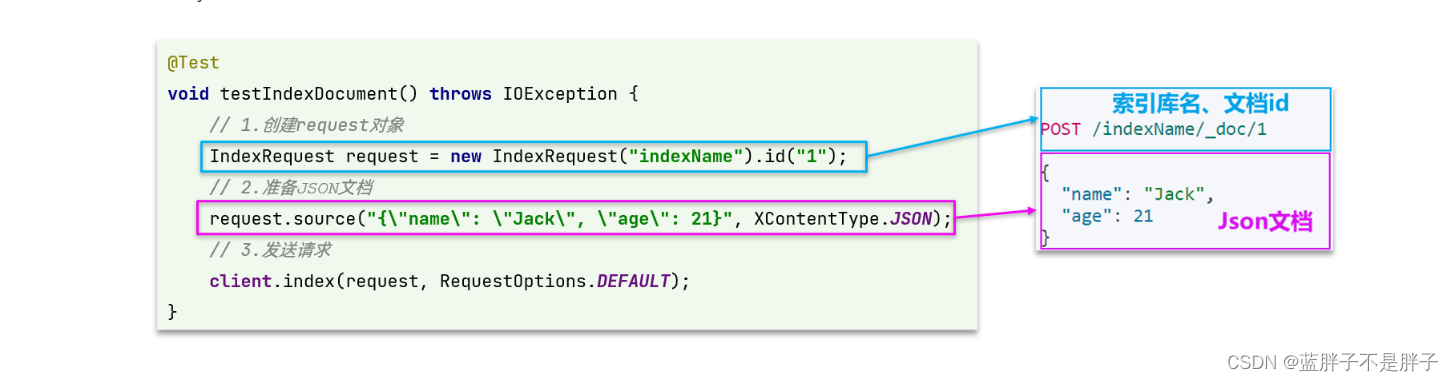
可以看到与创建索引库类似,同样是三步走:
- 1)创建Request对象
- 2)准备请求参数,也就是DSL中的JSON文档
- 3)发送请求
变化的地方在于,这里直接使用client.xxx()的API,不再需要client.indices()了。
5.1.3.完整代码
我们导入酒店数据,基本流程一致,但是需要考虑几点变化:
- 酒店数据来自于数据库,我们需要先查询出来,得到hotel对象
- hotel对象需要转为HotelDoc对象
- HotelDoc需要序列化为json格式
因此,代码整体步骤如下:
- 1)根据id查询酒店数据Hotel
- 2)将Hotel封装为HotelDoc
- 3)将HotelDoc序列化为JSON
- 4)创建IndexRequest,指定索引库名和id
- 5)准备请求参数,也就是JSON文档
- 6)发送请求
在hotel-demo的HotelDocumentTest测试类中,编写单元测试:
@Test
void testAddDocument() throws IOException {// 1.根据id查询酒店数据Hotel hotel = hotelService.getById(61083L);// 2.转换为文档类型HotelDoc hotelDoc = new HotelDoc(hotel);// 3.将HotelDoc转jsonString json = JSON.toJSONString(hotelDoc);// 1.准备Request对象IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());// 2.准备Json文档request.source(json, XContentType.JSON);// 3.发送请求client.index(request, RequestOptions.DEFAULT);
}
5.2.查询文档
5.2.1.语法说明
查询的DSL语句如下:
GET /hotel/_doc/{id}
非常简单,因此代码大概分两步:
- 准备Request对象
- 发送请求
不过查询的目的是得到结果,解析为HotelDoc,因此难点是结果的解析。完整代码如下:
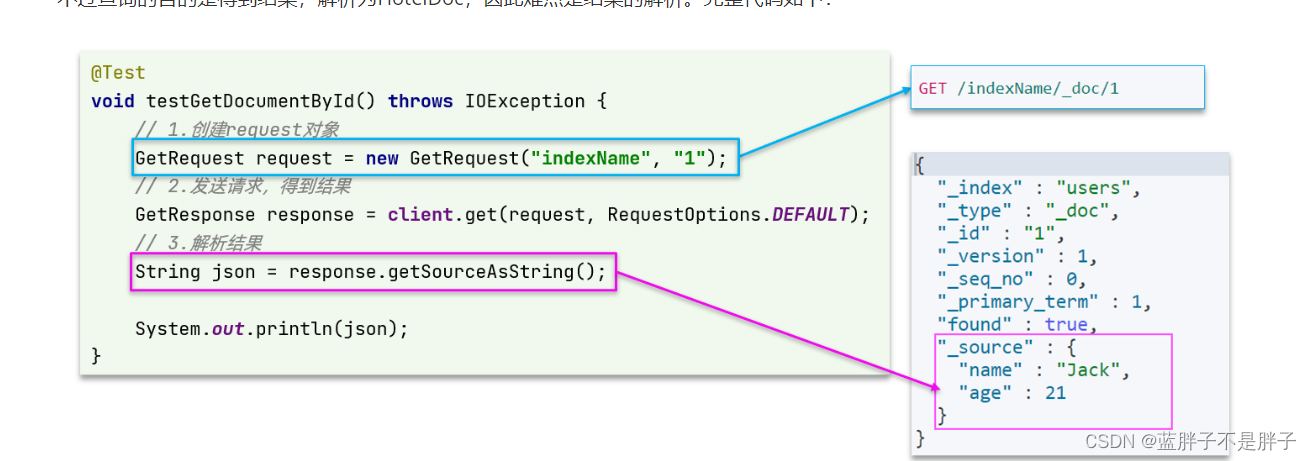
可以看到,结果是一个JSON,其中文档放在一个_source属性中,因此解析就是拿到_source,反序列化为Java对象即可。
与之前类似,也是三步走:
- 1)准备Request对象。这次是查询,所以是GetRequest
- 2)发送请求,得到结果。因为是查询,这里调用client.get()方法
- 3)解析结果,就是对JSON做反序列化
5.2.2.完整代码
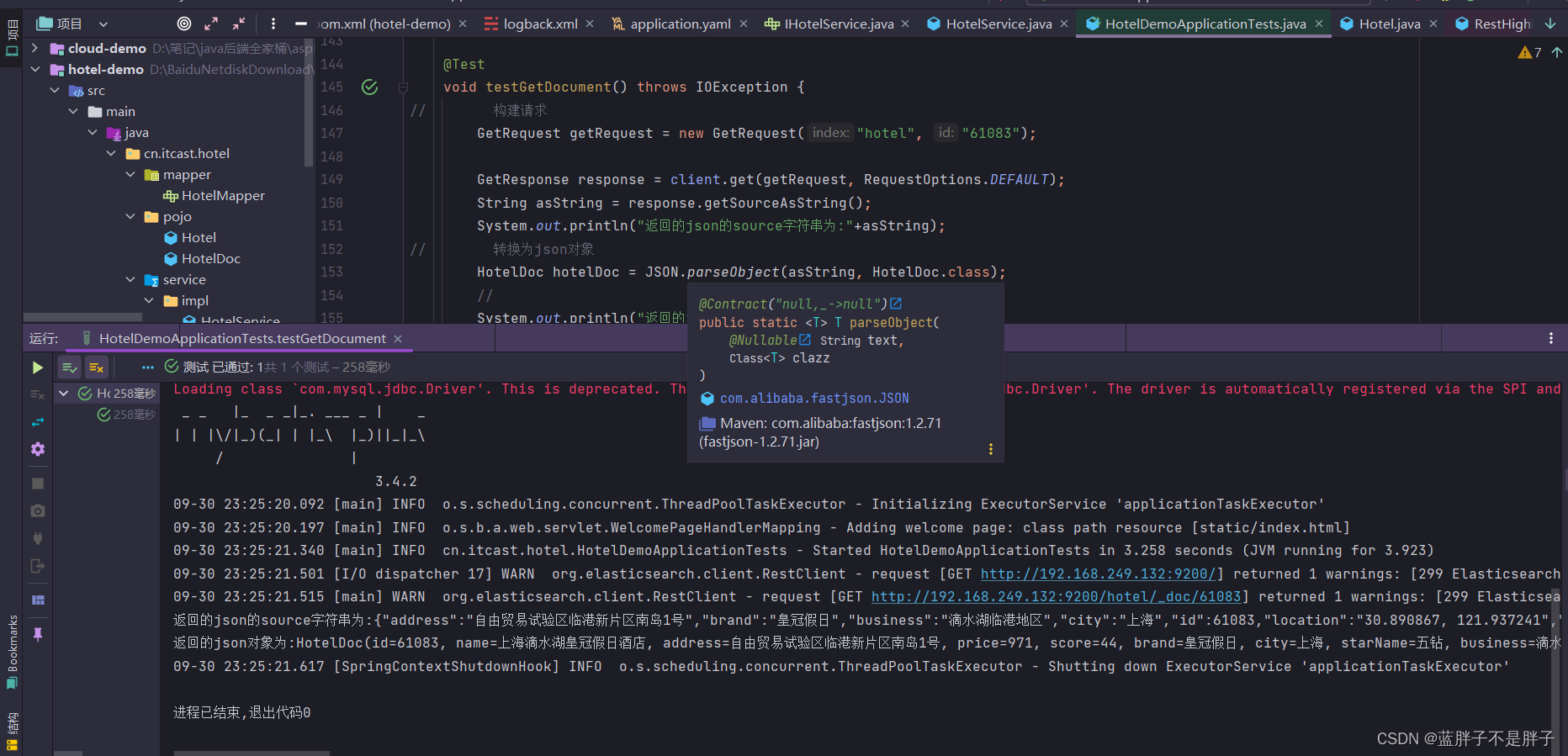
在hotel-demo的HotelDocumentTest测试类中,编写单元测试:
@Test
void testGetDocumentById() throws IOException {// 1.准备RequestGetRequest request = new GetRequest("hotel", "61082");// 2.发送请求,得到响应GetResponse response = client.get(request, RequestOptions.DEFAULT);// 3.解析响应结果String json = response.getSourceAsString();HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);System.out.println(hotelDoc);
}
测试结果
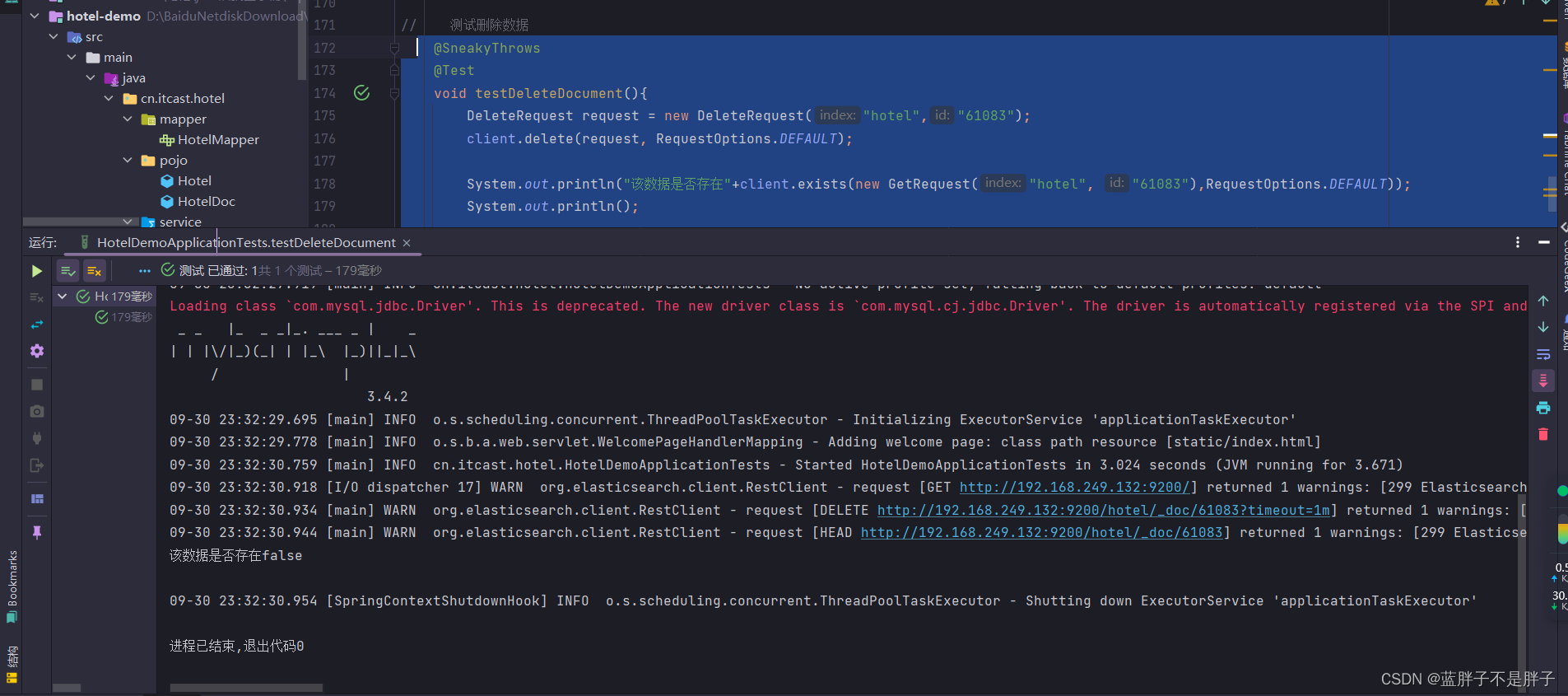
5.3.删除文档
删除的DSL为是这样的:
DELETE /hotel/_doc/{id}
与查询相比,仅仅是请求方式从DELETE变成GET,可以想象Java代码应该依然是三步走:
- 1)准备Request对象,因为是删除,这次是DeleteRequest对象。要指定索引库名和id
- 2)准备参数,无参
- 3)发送请求。因为是删除,所以是client.delete()方法
在hotel-demo的HotelDocumentTest测试类中,编写单元测试:
@SneakyThrows@Testvoid testDeleteDocument(){DeleteRequest request = new DeleteRequest("hotel","61083");client.delete(request, RequestOptions.DEFAULT);System.out.println("该数据是否存在"+client.exists(new GetRequest("hotel", "61083"),RequestOptions.DEFAULT));System.out.println();}
5.4.修改文档
5.4.1.语法说明
修改我们讲过两种方式:
- 全量修改:本质是先根据id删除,再新增
- 增量修改:修改文档中的指定字段值
在RestClient的API中,全量修改与新增的API完全一致,判断依据是ID:
- 如果新增时,ID已经存在,则修改
- 如果新增时,ID不存在,则新增
这里不再赘述,我们主要关注增量修改。
只演示局部更新
代码示例如图:
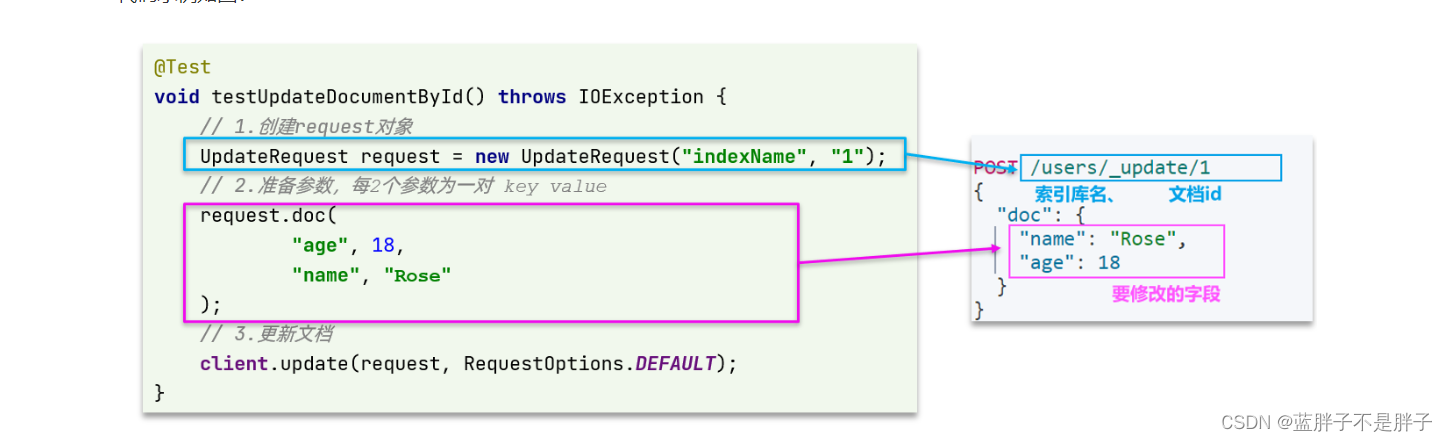
与之前类似,也是三步走:
- 1)准备Request对象。这次是修改,所以是UpdateRequest
- 2)准备参数。也就是JSON文档,里面包含要修改的字段
- 3)更新文档。这里调用client.update()方法
5.4.2.完整代码
在hotel-demo的HotelDocumentTest测试类中,编写单元测试:
@Testvoid testUpdateDocument() throws IOException {UpdateRequest request = new UpdateRequest("hotel", "61083");Map<String, Object> fieldmap = new HashMap<String, Object>();fieldmap.put("address", "自由贸易试验区临港新片区南岛133号");request.doc(fieldmap);client.update(request, RequestOptions.DEFAULT);}
5.5.批量导入文档
案例需求:利用批量将数据库数据导入到索引库中。
步骤如下:
-
利用mybatis-plus查询酒店数据
-
将查询到的酒店数据(Hotel)转换为文档类型数据(HotelDoc)
-
利用JavaRestClient中的BulkRequest批处理,实现批量新增文档
5.5.1.语法说明
批量处理BulkRequest,其本质就是将多个普通的CRUD请求组合在一起发送。
其中提供了一个add方法,用来添加其他请求:
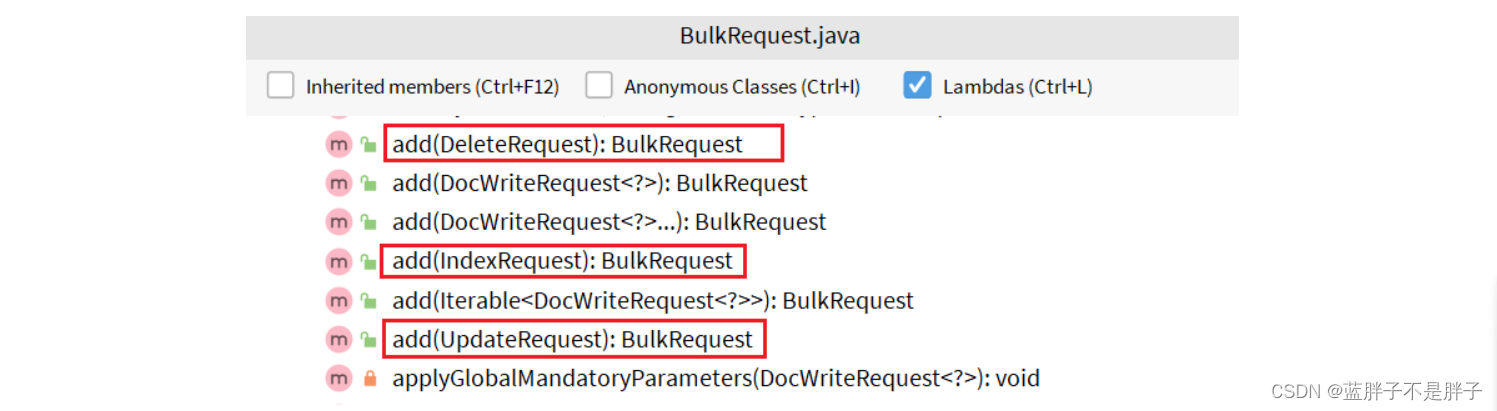
可以看到,能添加的请求包括:
- IndexRequest,也就是新增
- UpdateRequest,也就是修改
- DeleteRequest,也就是删除
因此Bulk中添加了多个IndexRequest,就是批量新增功能了。示例:
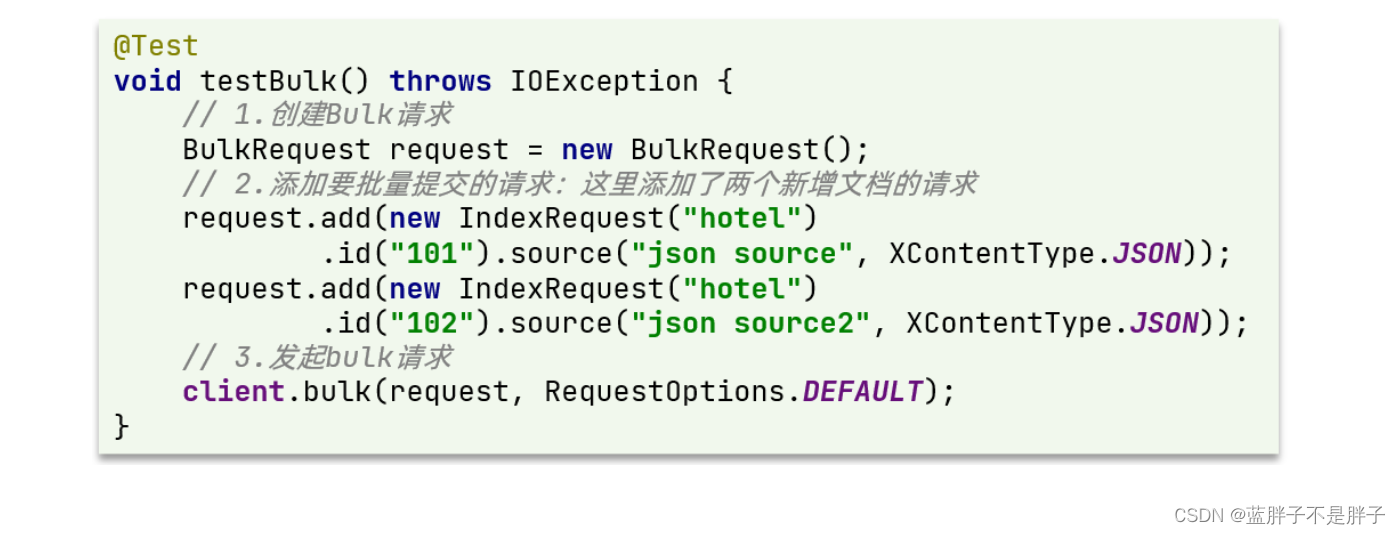
其实还是三步走:
- 1)创建Request对象。这里是BulkRequest
- 2)准备参数。批处理的参数,就是其它Request对象,这里就是多个IndexRequest
- 3)发起请求。这里是批处理,调用的方法为client.bulk()方法
我们在导入酒店数据时,将上述代码改造成for循环处理即可。
5.5.2.完整代码
在hotel-demo的HotelDocumentTest测试类中,编写单元测试:
// 批量新增加@Testvoid testAddbenchDocument() throws IOException {BulkRequest bulkRequest = new BulkRequest();List<Hotel> list = service.list();list.stream().forEach(hotelItem->bulkRequest.add(new IndexRequest("hotel").id(hotelItem.getId().toString()).source(JSON.toJSONString(new HotelDoc(hotelItem)),XContentType.JSON)));client.bulk(bulkRequest, RequestOptions.DEFAULT);}
使用countapi查看批量操作是否成功
@Testvoid testTotalDocument() throws IOException {CountRequest countRequest = new CountRequest("hotel");CountResponse response = client.count(countRequest, RequestOptions.DEFAULT);System.out.println(response.getCount());}
运行成功

5.6.小结
文档操作的基本步骤:
- 初始化RestHighLevelClient
- 创建XxxRequest。XXX是Index、Get、Update、Delete、Bulk
- 准备参数(Index、Update、Bulk时需要)
- 发送请求。调用RestHighLevelClient#.xxx()方法,xxx是index、get、update、delete、bulk
- 解析结果(Get时需要)
分布式搜索引擎02
在昨天的学习中,我们已经导入了大量数据到elasticsearch中,实现了elasticsearch的数据存储功能。但elasticsearch最擅长的还是搜索和数据分析。
所以今天,我们研究下elasticsearch的数据搜索功能。我们会分别使用DSL和RestClient实现搜索。
0.学习目标
1.DSL查询文档
elasticsearch的查询依然是基于JSON风格的DSL来实现的。
1.1.DSL查询分类
Elasticsearch提供了基于JSON的DSL(Domain Specific Language)来定义查询。常见的查询类型包括:
-
查询所有:查询出所有数据,一般测试用。例如:match_all
-
全文检索(full text)查询:利用分词器对用户输入内容分词,然后去倒排索引库中匹配。例如:
- match_query
- multi_match_query
-
精确查询:根据精确词条值查找数据,一般是查找keyword、数值、日期、boolean等类型字段。例如:
- ids
- range 范围
- term 数据值
-
地理(geo)查询:根据经纬度查询。例如:
- geo_distance
- geo_bounding_box
-
复合(compound)查询:复合查询可以将上述各种查询条件组合起来,合并查询条件。例如:
- bool
- function_score
查询的语法基本一致:
GET /indexName/_search
{"query": {"查询类型": {"查询条件": "条件值"}}
}
我们以查询所有为例,其中:
- 查询类型为match_all
- 没有查询条件
// 查询所有
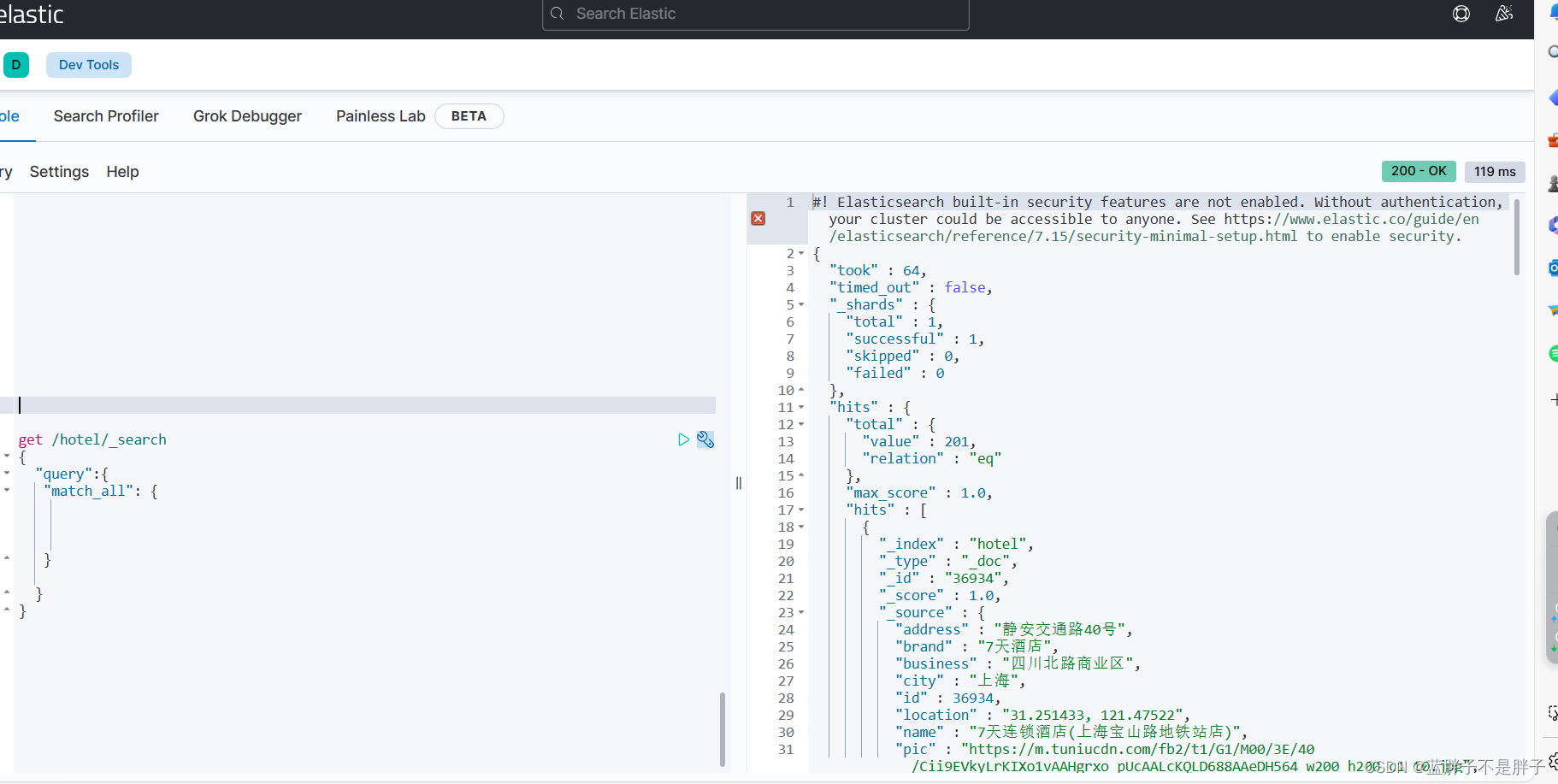
GET /indexName/_search
{"query": {"match_all": {}}
}
查询结果,默认只显示10条数据
hits :表示查询命中事件
max_score:查询得分
其它查询无非就是查询类型、查询条件的变化。
1.2.全文检索查询
1.2.1.使用场景
全文检索查询的基本流程如下:
- 对用户搜索的内容做分词,得到词条
- 根据词条去倒排索引库中匹配,得到文档id
- 根据文档id找到文档,返回给用户
比较常用的场景包括:
- 商城的输入框搜索
- 百度输入框搜索
例如京东:

因为是拿着词条去匹配,因此参与搜索的字段也必须是可分词的text类型的字段。
1.2.2.基本语法
常见的全文检索查询包括:
- match查询:单字段查询
- multi_match查询:多字段查询,任意一个字段符合条件就算符合查询条件
match查询语法如下:
GET /indexName/_search
{"query": {"match": {"FIELD": "TEXT"}}
}
mulit_match语法如下:
GET /indexName/_search
{"query": {"multi_match": {"query": "TEXT","fields": ["FIELD1", " FIELD12"]}}
}
1.2.3.示例
match查询示例:
查询索引库,创建索引的时候是创建了一个all字段,并且把city,brand,name等字段的值复制给all字段,这样进行字段匹配查找的时候,直接匹配all字段,就可以做多个字段的查询了
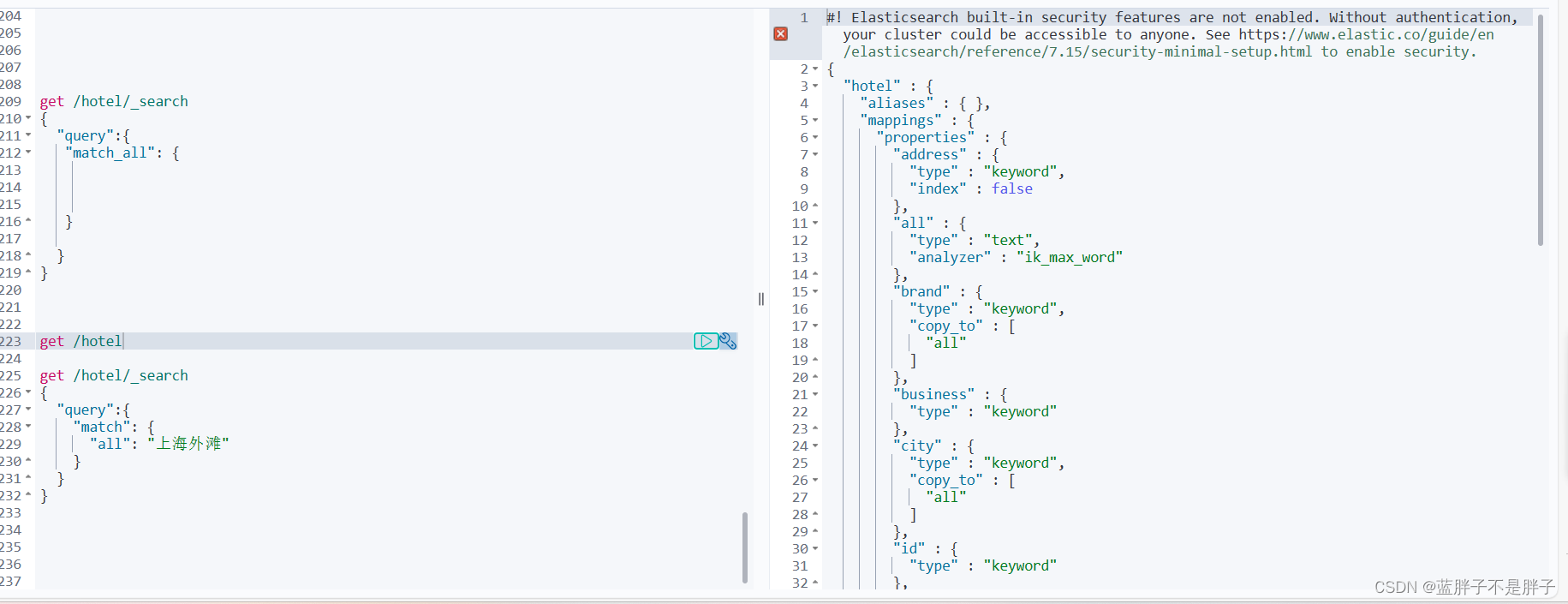
get /hotel/_search
{"query":{"match": {"all": "上海外滩"}}
}
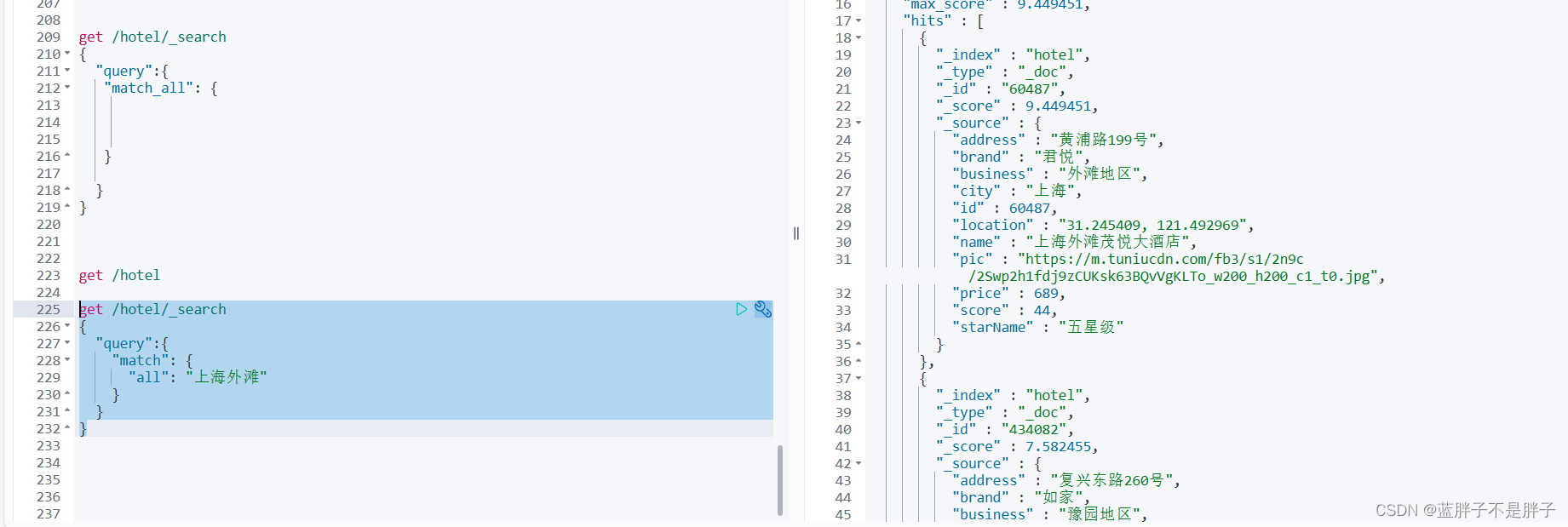
此时all分词查询到的数据 也就是city和name的文档
- _score:表示相关度得分
multi_match查询示例:
get /hotel/_search
{"query":{"multi_match": {"query": "如家","fields": ["brand","name", "business"]}}
}
多条件匹配
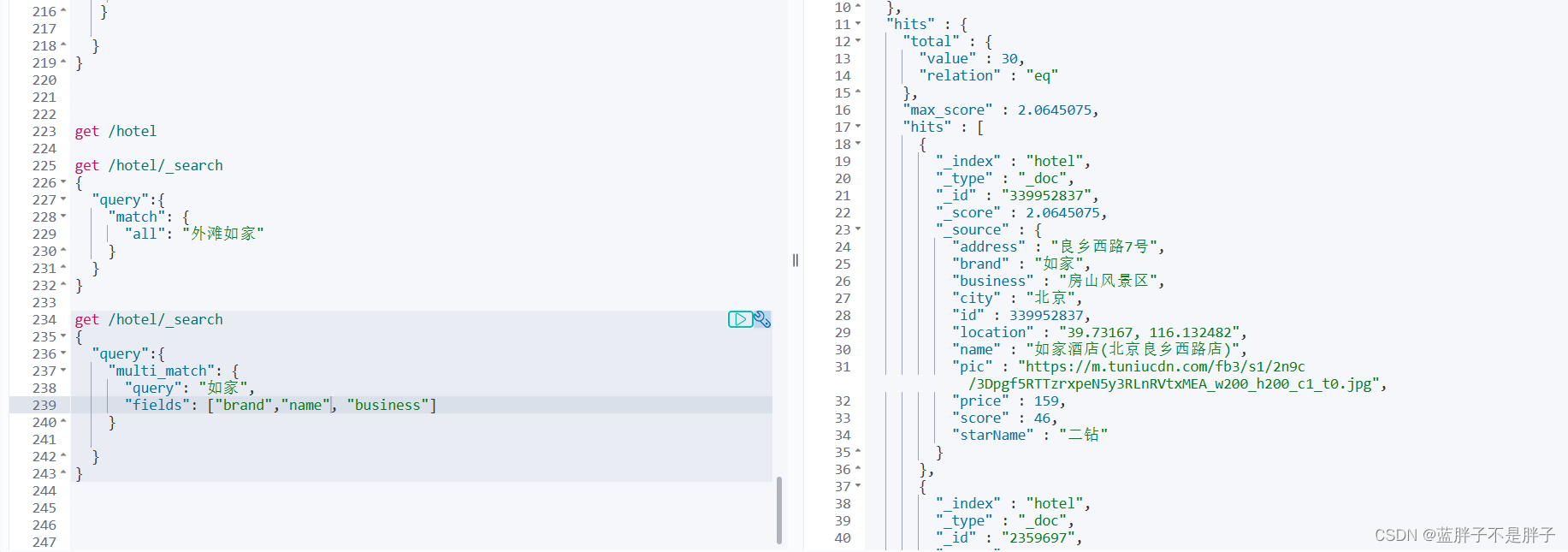
这样多字段的效果和建立索引时专门专门创建一个查询字段,把查询的内容copy进去,方便条件匹配的时候进行分词检索的效果是一样的,但是多字段查询对检索效率有影响,涉及到链接操作,而通过把插叙字段全部复制在一起,进行分词检索不需要条件链接,效率快一些
可以看到,两种查询结果是一样的,为什么?
因为我们将brand、name、business值都利用copy_to复制到了all字段中。因此你根据三个字段搜索,和根据all字段搜索效果当然一样了。
但是,搜索字段越多,对查询性能影响越大,因此建议采用copy_to,然后单字段查询的方式。
1.2.4.总结
match和multi_match的区别是什么?
- match:根据一个字段查询
- multi_match:根据多个字段查询,参与查询字段越多,查询性能越差
1.3.精准查询
精确查询一般是查找keyword、数值、日期、boolean等类型字段。所以不会对搜索条件分词。常见的有:
- term:根据词条精确值查询
- range:根据值的范围查询
1.3.1.term查询
因为精确查询的字段搜是不分词的字段,因此查询的条件也必须是不分词的词条。查询时,用户输入的内容跟自动值完全匹配时才认为符合条件。如果用户输入的内容过多,反而搜索不到数据。
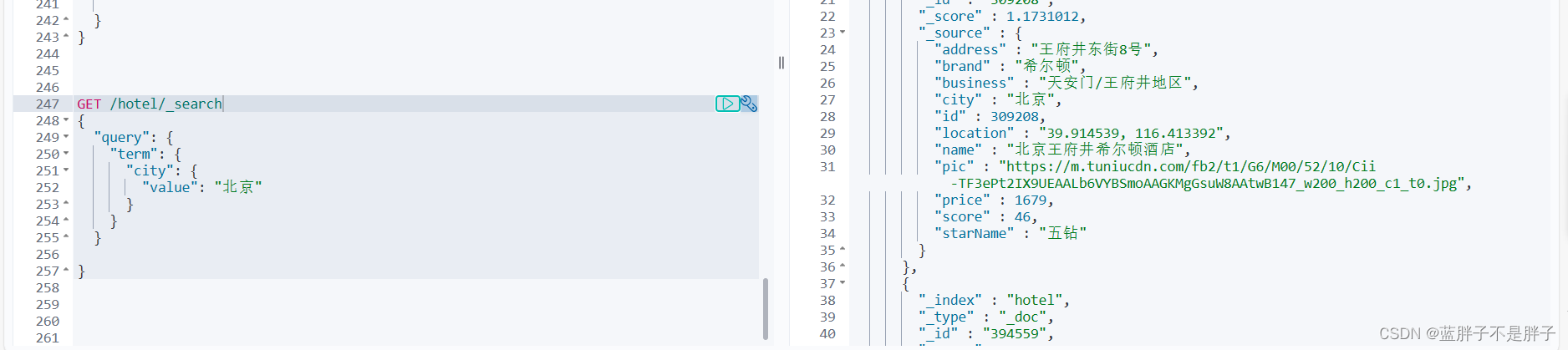
语法说明:
// term查询
GET /indexName/_search
{"query": {"term": {"FIELD": {"value": "VALUE"}}}
}
示例:
当我搜索的是精确词条时,能正确查询出结果:
但是,当我搜索的内容不是词条,而是多个词语形成的短语时,反而搜索不到:
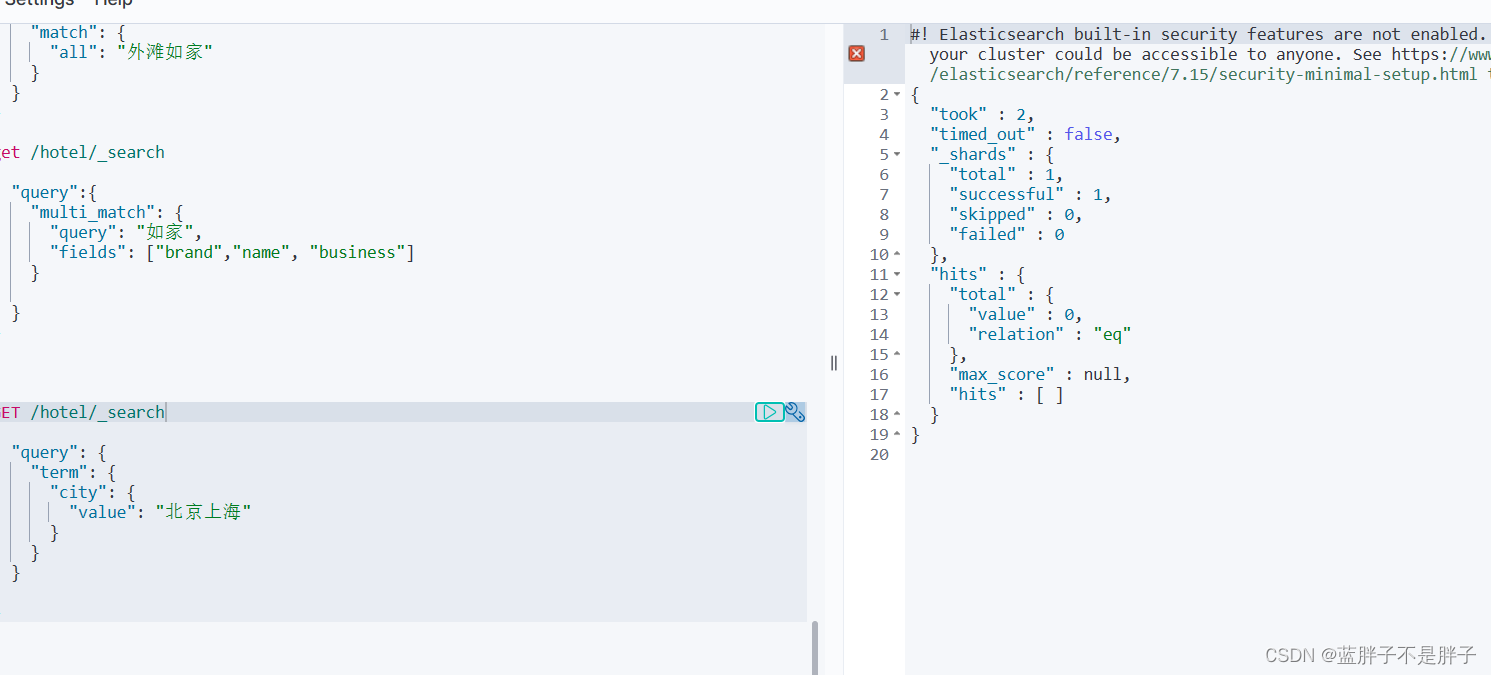
1.3.2.range查询
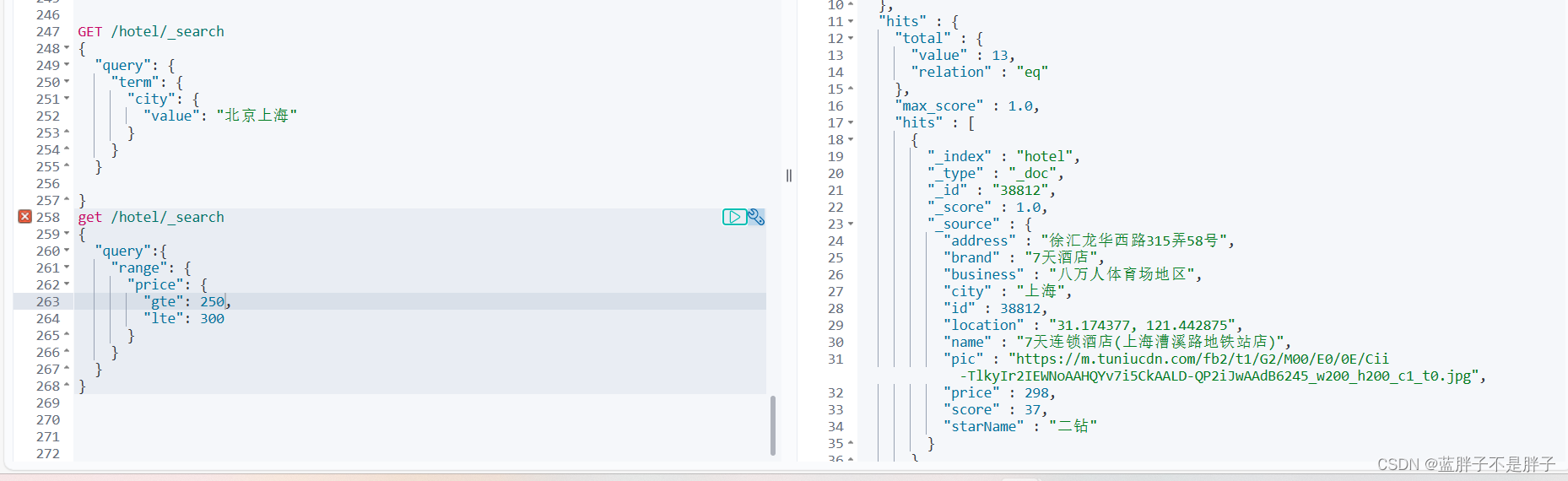
范围查询,一般应用在对数值类型做范围过滤的时候。比如做价格范围过滤。
基本语法:
// range查询
GET /indexName/_search
{"query": {"range": {"FIELD": {"gte": 10, // 这里的gte代表大于等于,gt则代表大于"lte": 20 // lte代表小于等于,lt则代表小于}}}
}
示例:
1.3.3.总结
精确查询常见的有哪些?
- term查询:根据词条精确匹配,一般搜索keyword类型、数值类型、布尔类型、日期类型字段
- range查询:根据数值范围查询,可以是数值、日期的范围
1.4.地理坐标查询
所谓的地理坐标查询,其实就是根据经纬度查询,官方文档:
常见的使用场景包括:
- 携程:搜索我附近的酒店
- 滴滴:搜索我附近的出租车
- 微信:搜索我附近的人
附近的酒店:
1.4.1.矩形范围查询
矩形范围查询,也就是geo_bounding_box查询,查询坐标落在某个矩形范围的所有文档:
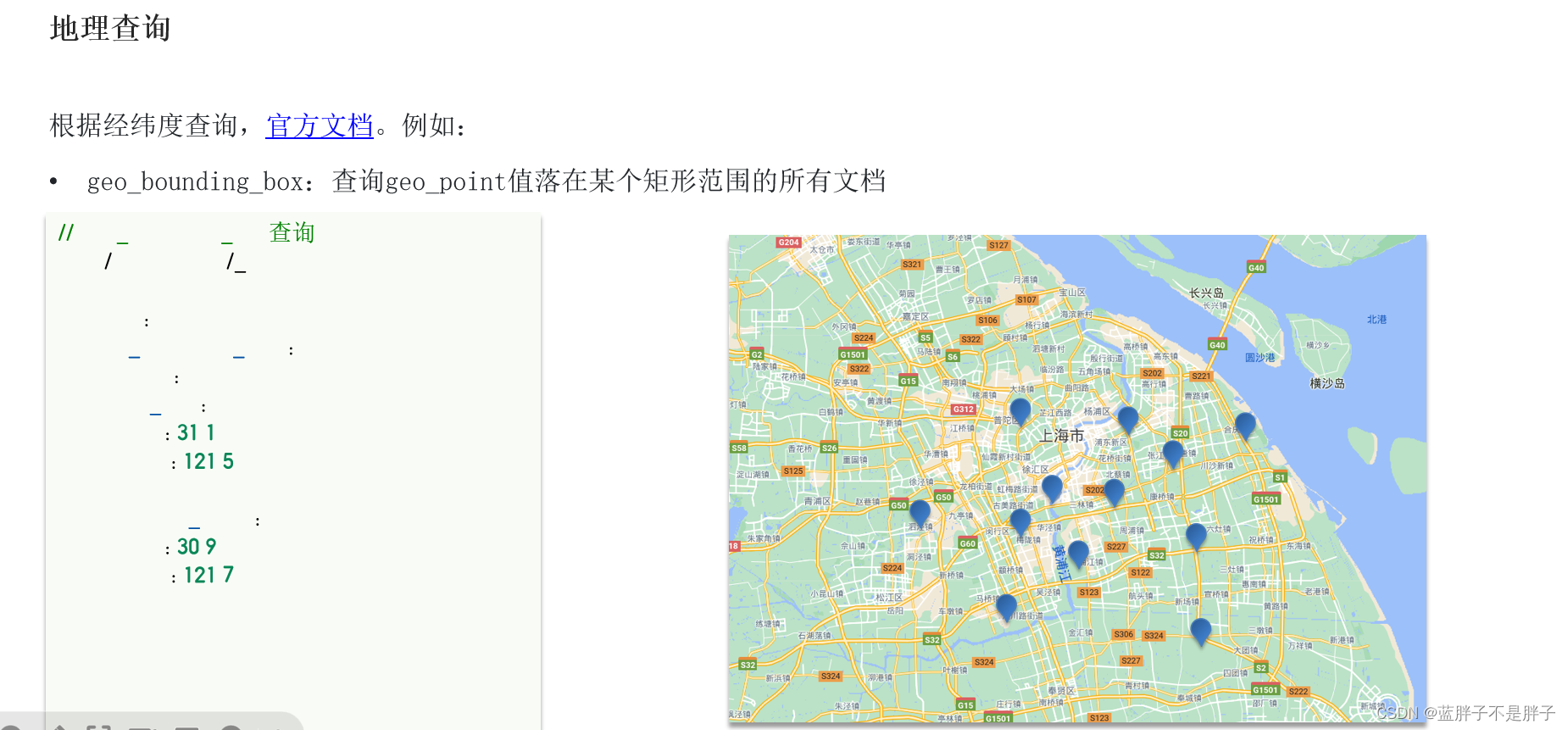
查询时,需要指定矩形的左上、右下两个点的坐标,然后画出一个矩形,落在该矩形内的都是符合条件的点。
语法如下:
// geo_bounding_box查询
GET /indexName/_search
{"query": {"geo_bounding_box": {"FIELD": {"top_left": { // 左上点"lat": 31.1,"lon": 121.5},"bottom_right": { // 右下点"lat": 30.9,"lon": 121.7}}}}
}
这种并不符合“附近的人”这样的需求,所以我们就不做了。一般都是根据自身半径内多少距离来进行开发的
1.4.2.附近查询
附近查询,也叫做距离查询(geo_distance):查询到指定中心点小于某个距离值的所有文档。
换句话来说,在地图上找一个点作为圆心,以指定距离为半径,画一个圆,落在圆内的坐标都算符合条件:
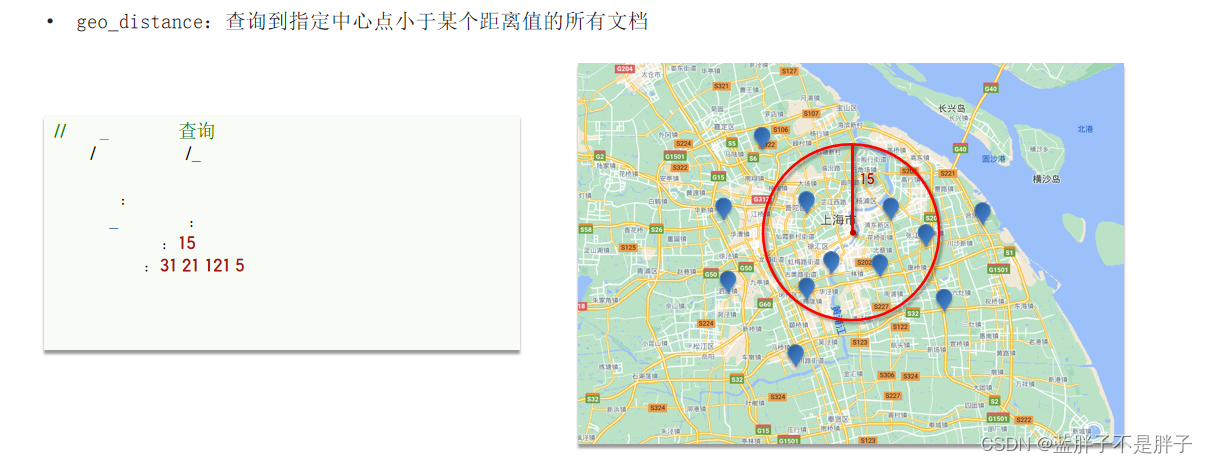
语法说明:
// geo_distance 查询
GET /indexName/_search
{"query": {"geo_distance": {"distance": "15km", // 半径"FIELD": "31.21,121.5" // 圆心}}
}
示例:
我们先搜索陆家嘴附近15km的酒店:
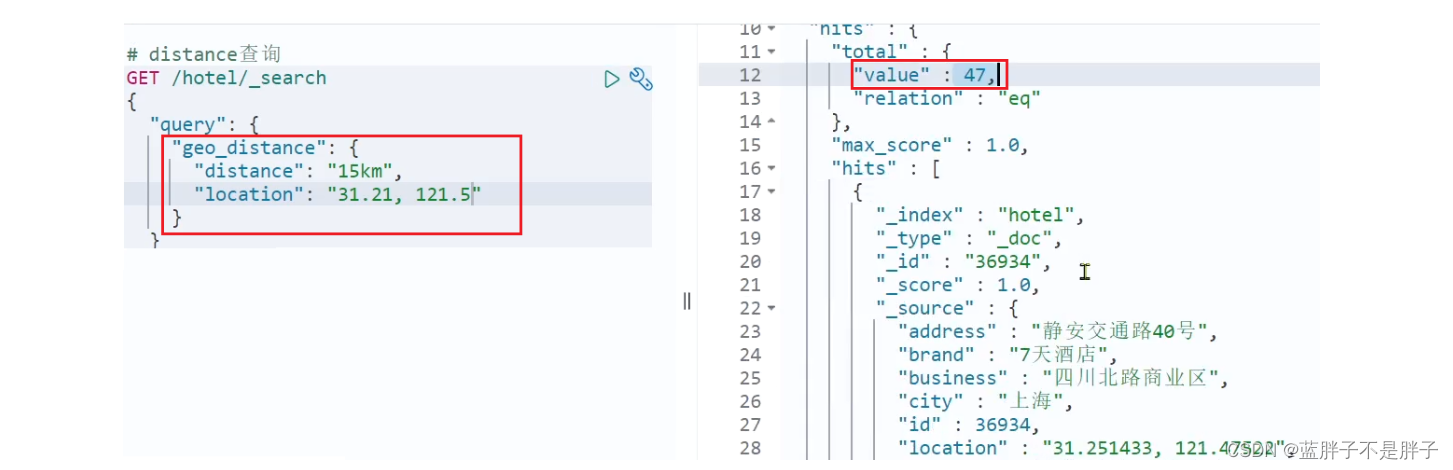
发现共有47家酒店。
然后把半径缩短到5公里:

可以发现,搜索到的酒店数量减少到了13家。
1.5.复合查询
复合(compound)查询:复合查询可以将其它简单查询组合起来,实现更复杂的搜索逻辑。常见的有两种:
- fuction score:算分函数查询,可以控制文档相关性算分,控制文档排名
- bool query:布尔查询,利用逻辑关系组合多个其它的查询,实现复杂搜索
1.5.1.相关性算分
当我们利用match查询时,文档结果会根据与搜索词条的关联度打分(_score),返回结果时按照分值降序排列。
例如,我们搜索 “虹桥如家”,结果如下:
[{"_score" : 17.850193,"_source" : {"name" : "虹桥如家酒店真不错",}},{"_score" : 12.259849,"_source" : {"name" : "外滩如家酒店真不错",}},{"_score" : 11.91091,"_source" : {"name" : "迪士尼如家酒店真不错",}}
]
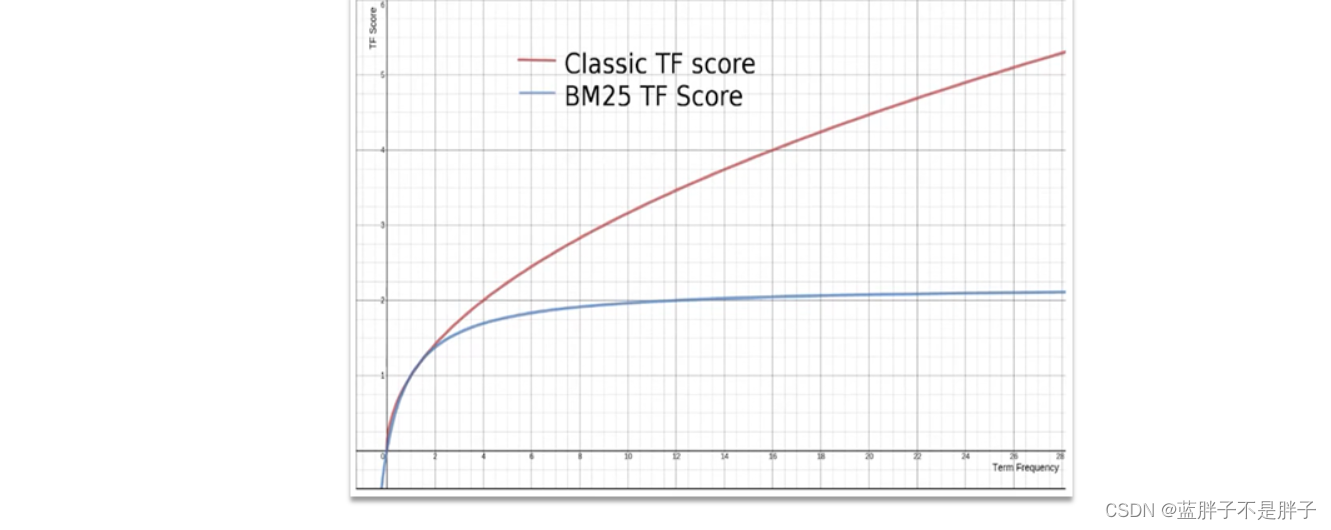
在elasticsearch中,早期使用的打分算法是TF-IDF算法,公式如下:

在后来的5.1版本升级中,elasticsearch将算法改进为BM25算法,公式如下:

TF-IDF算法有一各缺陷,就是词条频率越高,文档得分也会越高,单个词条对文档影响较大。而BM25则会让单个词条的算分有一个上限,曲线更加平滑:
小结:elasticsearch会根据词条和文档的相关度做打分,算法由两种:
- TF-IDF算法
- BM25算法,elasticsearch5.1版本后采用的算法
1.5.2.算分函数查询
根据相关度打分是比较合理的需求,但合理的不一定是产品经理需要的。
以百度为例,你搜索的结果中,并不是相关度越高排名越靠前,而是谁掏的钱多排名就越靠前。如图:
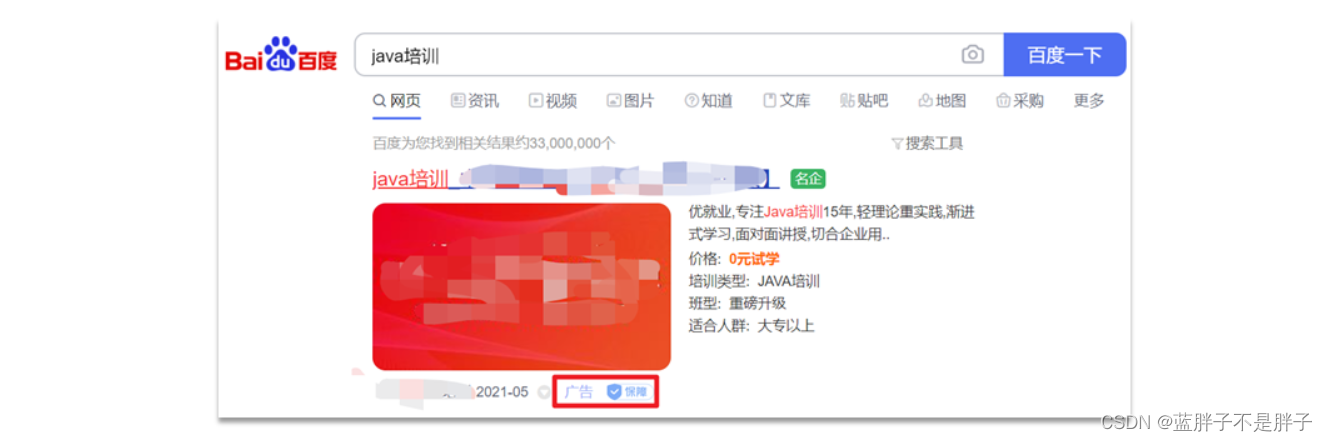
要想认为控制相关性算分,就需要利用elasticsearch中的function score 查询了。
1)语法说明
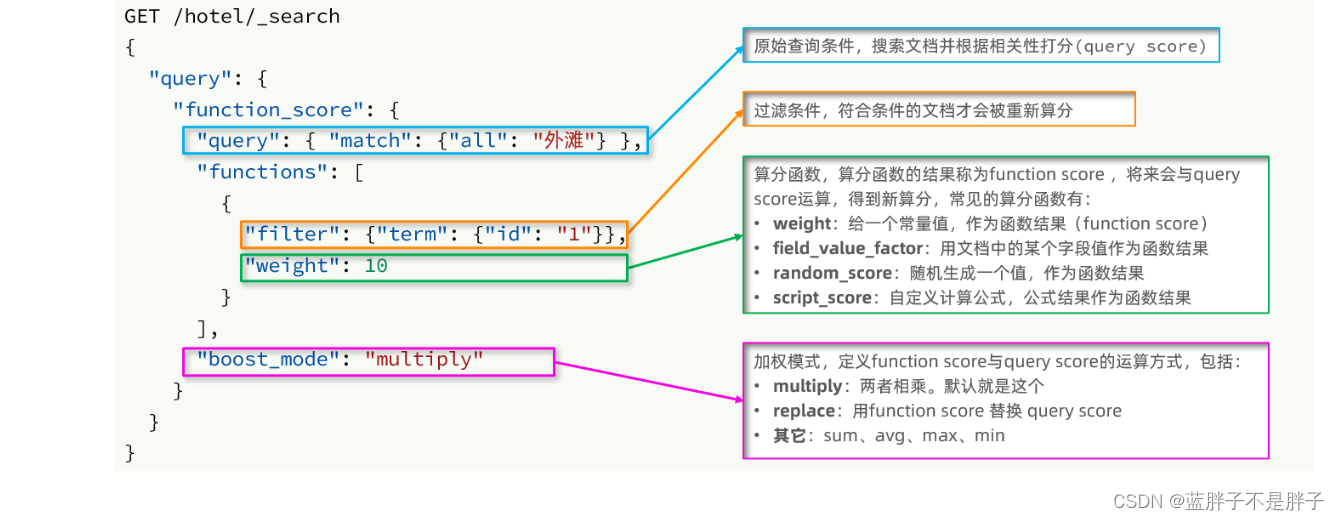
function score 查询中包含四部分内容:
- 原始查询条件:query部分,基于这个条件搜索文档,并且基于BM25算法给文档打分,原始算分(query score)
- 过滤条件:filter部分,符合该条件的文档才会重新算分
- 算分函数:符合filter条件的文档要根据这个函数做运算,得到的函数算分(function score),有四种函数
- weight:函数结果是常量
- field_value_factor:以文档中的某个字段值作为函数结果
- random_score:以随机数作为函数结果
- script_score:自定义算分函数算法
- 运算模式:算分函数的结果、原始查询的相关性算分,两者之间的运算方式,包括:
- multiply:相乘
- replace:用function score替换query score
- 其它,例如:sum、avg、max、min
(重点)function score的运行流程如下:
- 1)根据原始条件查询搜索文档,并且计算相关性算分,称为原始算分(query score)
- 2)根据过滤条件,过滤文档
- 3)符合过滤条件的文档,基于算分函数运算,得到函数算分(function score)
- 4)将原始算分(query score)和函数算分(function score)基于运算模式做运算,得到最终结果,作为相关性算分。
因此,其中的关键点是:
- 过滤条件:决定哪些文档的算分被修改
- 算分函数:决定函数算分的算法
- 运算模式:决定最终算分结果
2)示例
需求:给“如家”这个品牌的酒店排名靠前一些
实际应用也可以给某些字段写名等级,得分来进行排名操作
翻译一下这个需求,转换为之前说的四个要点:
- 原始条件:不确定,可以任意变化
- 过滤条件:brand = “如家”
- 算分函数:可以简单粗暴,直接给固定的算分结果,weight
- 运算模式:比如求和
因此最终的DSL语句如下:
GET /hotel/_search
{"query": {"function_score": {"query": { .... }, // 原始查询,可以是任意条件"functions": [ // 算分函数{"filter": { // 满足的条件,品牌必须是如家"term": {"brand": "如家"}},"weight": 2 // 算分权重为2}],"boost_mode": "sum" // 加权模式,求和}}
}
测试,在未添加算分函数时,如家得分如下:
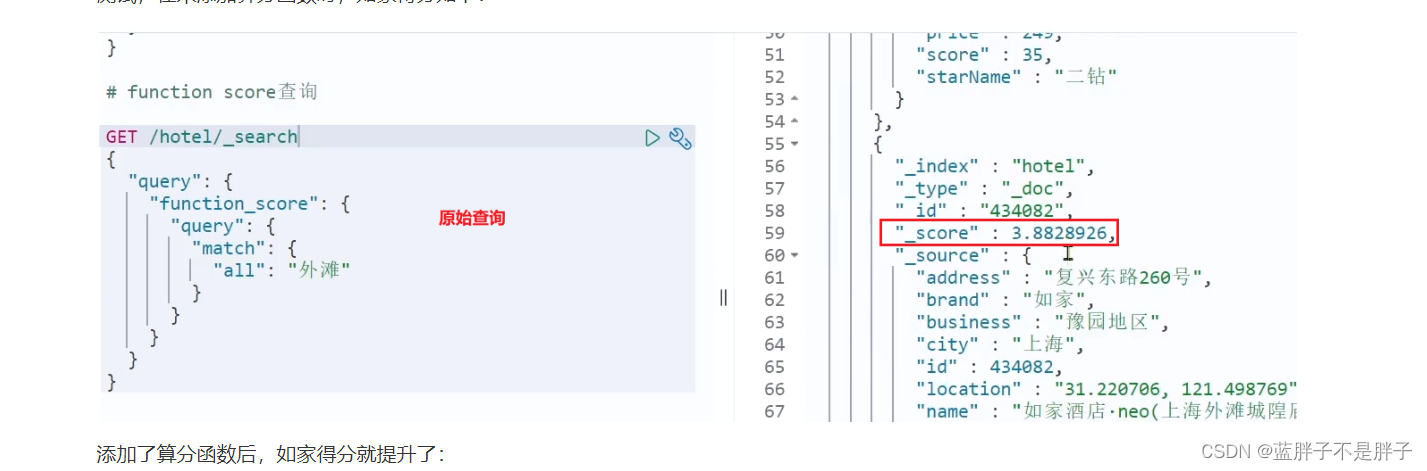
添加了算分函数后,如家得分就提升了:

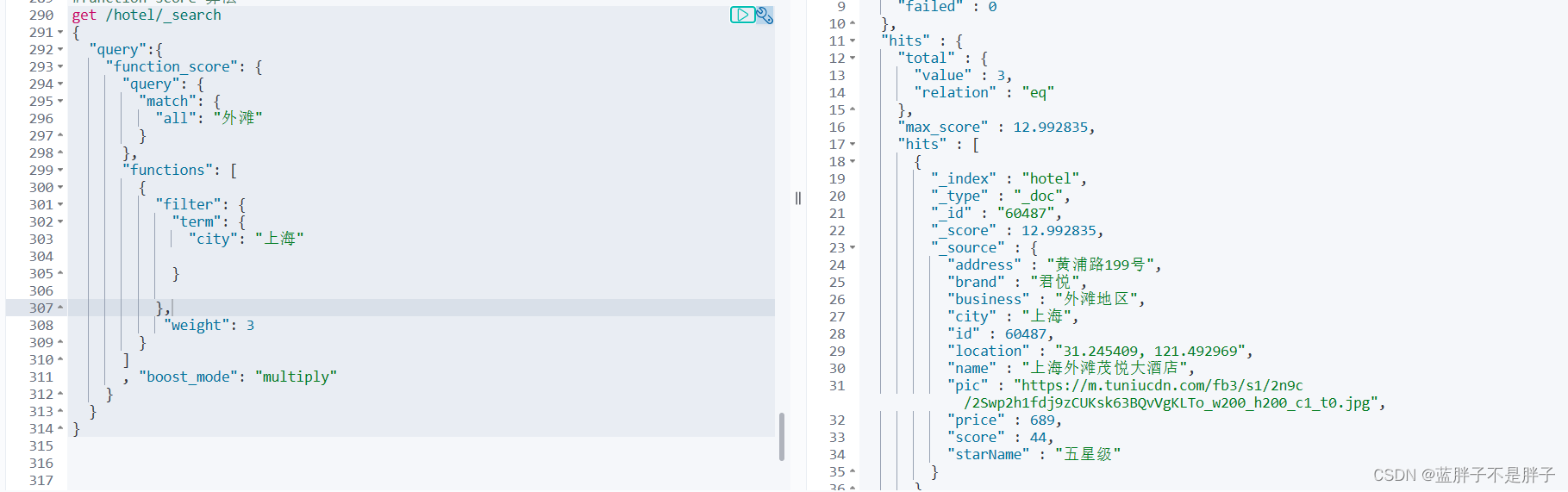
同理 我这里给city字段值在"上海"的文档加分
get /hotel/_search
{"query":{"function_score": {"query": {"match": {"all": "外滩"}},"functions": [{"filter": {"term": {"city": "上海"}},"weight": 3}], "boost_mode": "multiply"}}
}
得到评分最高
3)小结
function score query定义的三要素是什么?
- 过滤条件:哪些文档要加分
- 算分函数:如何计算function score
- 加权方式:function score 与 query score如何运算
1.5.3.布尔查询
布尔查询是一个或多个查询子句的组合,每一个子句就是一个子查询。子查询的组合方式有:
- must:必须匹配每个子查询,类似“与”
- should:选择性匹配子查询,类似“或”
- must_not:必须不匹配,不参与算分,类似“非”
- filter:必须匹配,不参与算分
比如在搜索酒店时,除了关键字搜索外,我们还可能根据品牌、价格、城市等字段做过滤:
每一个不同的字段,其查询的条件、方式都不一样,必须是多个不同的查询,而要组合这些查询,就必须用bool查询了。
需要注意的是,搜索时,参与打分的字段越多,查询的性能也越差。因此这种多条件查询时,建议这样做:
- 搜索框的关键字搜索,是全文检索查询,使用must查询,参与算分
- 其它过滤条件,采用filter查询。不参与算分
1)语法示例:
GET /hotel/_search
{"query": {"bool": {"must": [{"term": {"city": "上海" }}],"should": [{"term": {"brand": "皇冠假日" }},{"term": {"brand": "华美达" }}],"must_not": [{ "range": { "price": { "lte": 500 } }}],"filter": [{ "range": {"score": { "gte": 45 } }}]}}
}
要求返回的结果一定在上海,并且brand字段一定是这俩个之一,价格一定不小于500,并且必须得分在大于45的文档
2)示例
需求:搜索名字包含“如家”,价格不高于400,在坐标31.21,121.5周围10km范围内的酒店。
分析:
- 名称搜索,属于全文检索查询,应该参与算分。放到must中
- 价格不高于400,用range查询,属于过滤条件,不参与算分。放到must_not中
- 周围10km范围内,用geo_distance查询,属于过滤条件,不参与算分。放到filter中

filter是不参与算分的,所以这里的算分是根据es的算法来的,所以这里再次添加一个match匹配条件
GET /hotel/_search
{"query": {"bool": {"must": [{"geo_distance": {"distance": "10km","location": {"lat": 31.21,"lon": 121.5}}},{"match": {"name": "如家"}}], "must_not": [{"range": {"price": {"gt": 400}}}],"filter": [{"range": {"score": {"gte": 44}}}]}}
}
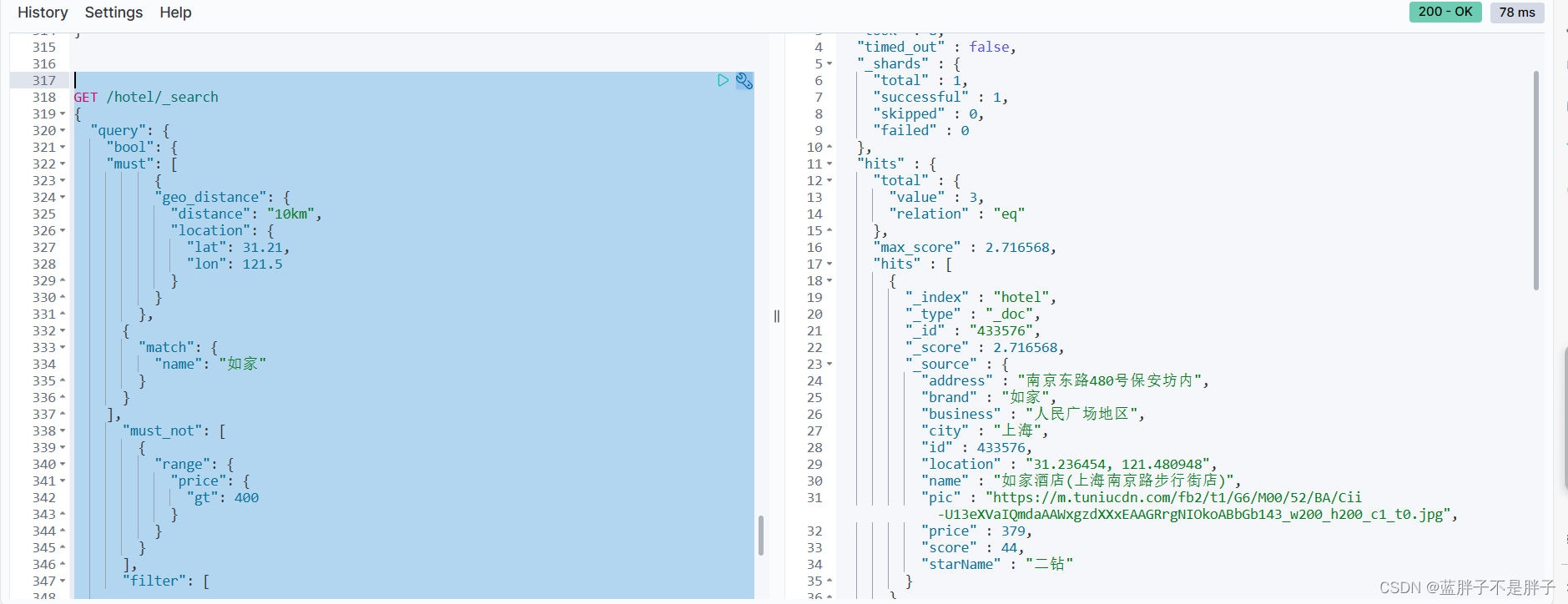
此时,满足俩个检索条件的文档分数更高
3)小结
bool查询有几种逻辑关系?
- must:必须匹配的条件,可以理解为“与”
- should:选择性匹配的条件,可以理解为“或”
- must_not:必须不匹配的条件,不参与打分
- filter:必须匹配的条件,不参与打分
2.搜索结果处理
搜索的结果可以按照用户指定的方式去处理或展示。
2.1.排序
elasticsearch默认是根据相关度算分(_score)来排序,但是也支持自定义方式对搜索结果排序。可以排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等,当自定义排序过后es不会在对文档进行打分。
2.1.1.普通字段排序
keyword、数值、日期类型排序的语法基本一致。
语法:
GET /indexName/_search
{"query": {"match_all": {}},"sort": [{"FIELD": "desc" // 排序字段、排序方式ASC、DESC}]
}
排序和条件检索的等级一样的,所以json格式中的所处等级一样
排序条件是一个数组,也就是可以写多个排序条件。按照声明的顺序,当第一个条件相等时,再按照第二个条件排序,以此类推
示例:
需求描述:酒店数据按照用户评价(score)降序排序,评价相同的按照价格(price)升序排序
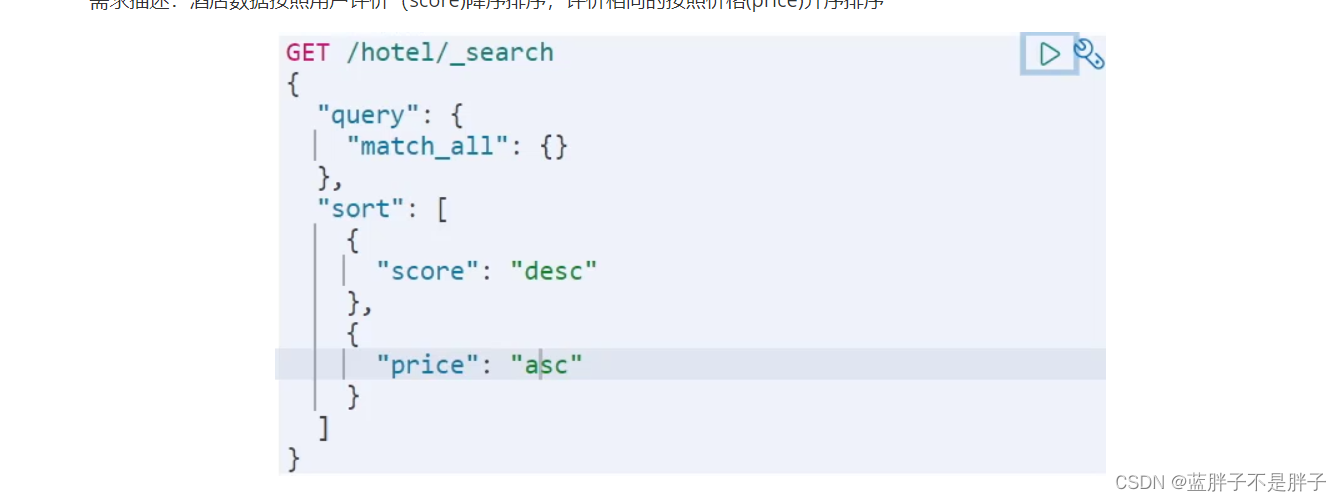
2.1.2.地理坐标排序
地理坐标排序略有不同。
语法说明:
GET /indexName/_search
{"query": {"match_all": {}},"sort": [{"_geo_distance" : {"FIELD" : "纬度,经度", // 文档中geo_point类型的字段名、目标坐标点"order" : "asc", // 排序方式"unit" : "km" // 排序的距离单位}}]
}
这个查询的含义是:
- 指定一个坐标,作为目标点
- 计算每一个文档中,指定字段(必须是geo_point类型)的坐标 到目标点的距离是多少
- 根据距离排序
示例:
需求描述:实现对酒店数据按照到你的位置坐标的距离升序排序
提示:获取你的位置的经纬度的方式:https://lbs.amap.com/demo/jsapi-v2/example/map/click-to-get-lnglat/
假设我的位置是:31.034661,121.612282,寻找我周围距离最近的酒店。
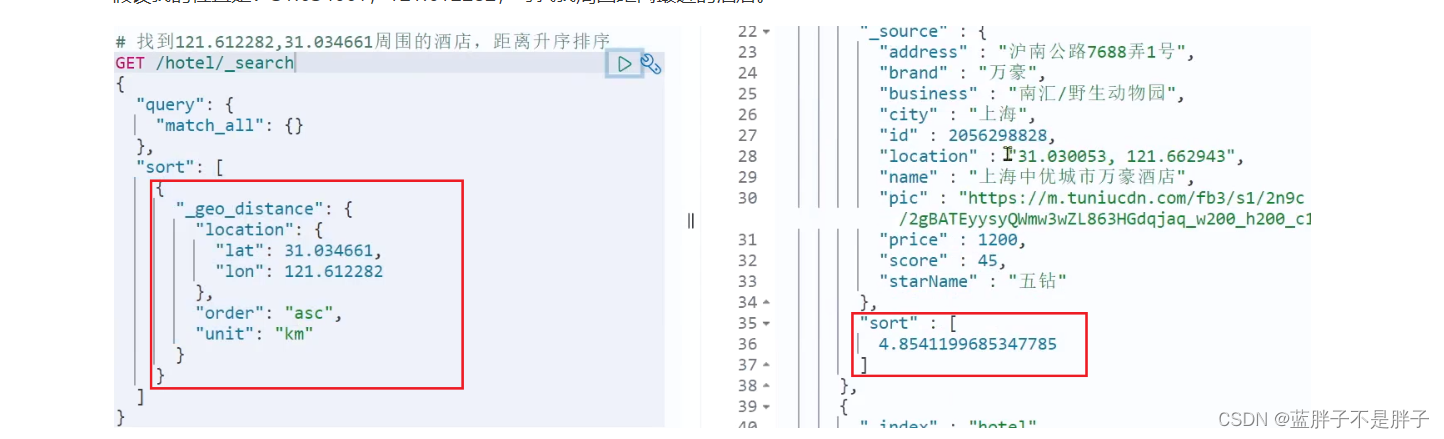
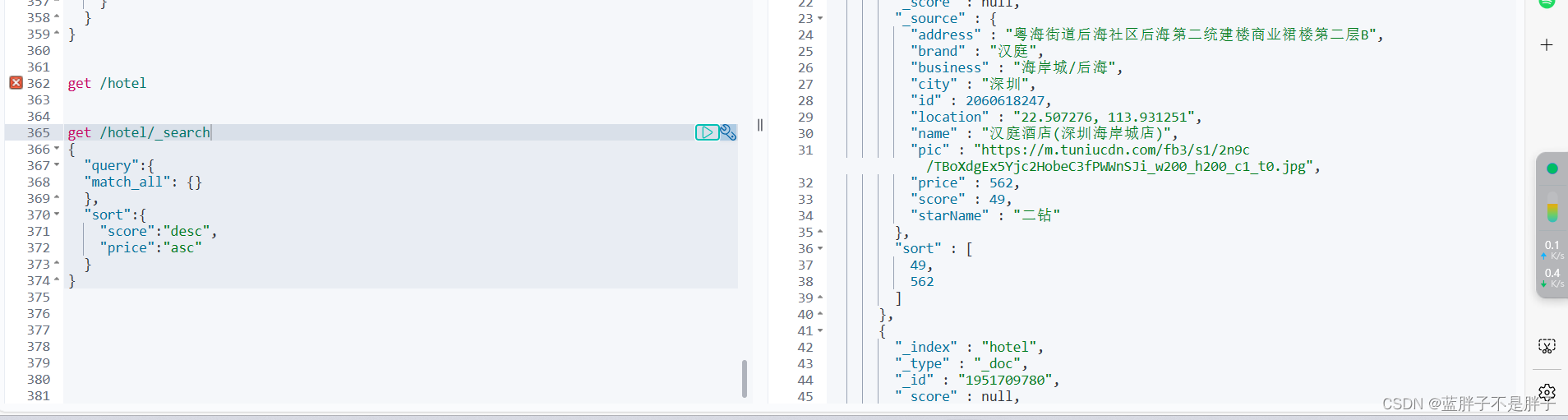
比如,对所有酒店进行排序,按照价格升序,评分降序的顺序检索文档
get /hotel/_search
{"query":{"match_all": {}},"sort":{"score":"desc","price":"asc"}
}
2.2.分页
elasticsearch 默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。elasticsearch中通过修改from、size参数来控制要返回的分页结果:
- from:从第几个文档开始
- size:总共查询几个文档
类似于mysql中的limit ?, ?
2.2.1.基本的分页
分页的基本语法如下:
GET /hotel/_search
{"query": {"match_all": {}},"from": 0, // 分页开始的位置,默认为0"size": 10, // 期望获取的文档总数"sort": [{"price": "asc"}]
}
2.2.2.深度分页问题
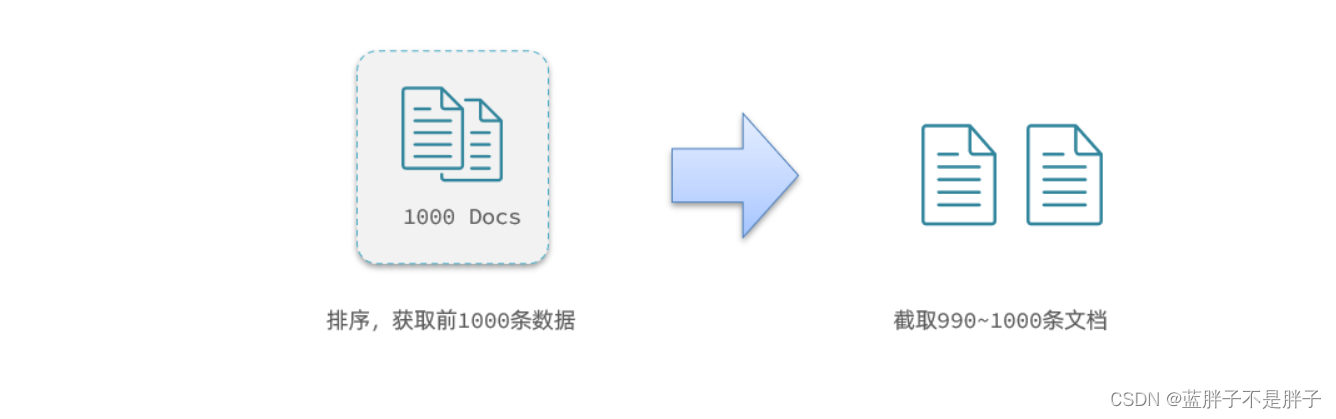
现在,我要查询990~1000的数据,查询逻辑要这么写:
GET /hotel/_search
{"query": {"match_all": {}},"from": 990, // 分页开始的位置,默认为0"size": 10, // 期望获取的文档总数"sort": [{"price": "asc"}]
}
这里是查询990开始的数据,也就是 第990~第1000条 数据。
不过,elasticsearch内部分页时,因为es底层是倒排索引,只能必须先查询 0~1000条,然后截取其中的990 ~ 1000的这10条:
查询TOP1000,如果es是单点模式,这并无太大影响。
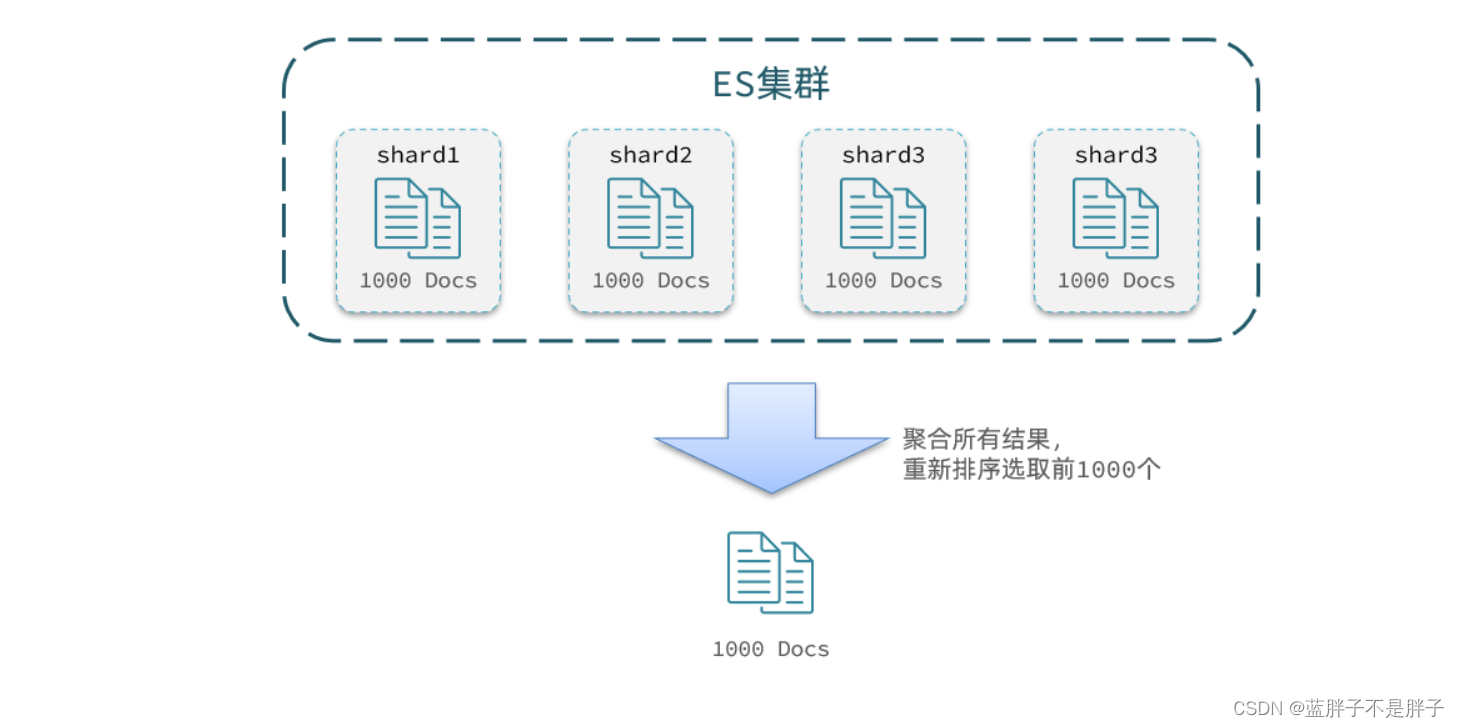
但是elasticsearch将来一定是集群,例如我集群有5个节点,我要查询TOP1000的数据,并不是每个节点查询200条就可以了。
因为节点A的TOP200,在另一个节点可能排到10000名以外了。
因此要想获取整个集群的TOP1000,必须先查询出每个节点的TOP1000,汇总结果后,重新排名,重新截取TOP1000。
那如果我要查询9900~10000的数据呢?是不是要先查询TOP10000呢?那每个节点都要查询10000条?汇总到内存中?
当查询分页深度较大时,汇总数据过多,对内存和CPU会产生非常大的压力,因此elasticsearch会禁止from+ size 超过10000的请求。
针对深度分页,ES提供了两种解决方案,官方文档:
- search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。
- scroll:原理将排序后的文档id形成快照,保存在内存。官方已经不推荐使用。
当使用 Elasticsearch 的 search_after 参数时,按照以下步骤进行详细演示:
GET /hotel/_search
{"size": 10, "sort": [{ "price": "asc" } ],"search_after": [ 20 ]
}
搜索查询的含义如下:
- “size”: 10:每页返回的文档数量,这里设置为 10。
- “sort”: [{ “price”: “asc” }]:按价格字段升序排序。
- “search_after”: [20]:假如上一页的最后一个文档的价格值为 20,将其用作 search_after 值来比较排序获取下一页的数据。
执行这个搜索请求后,Elasticsearch 将会返回下一页的文档数据,按照价格字段的升序排列。结果将包含最接近上一页最后一个文档的价格值大于 20 的文档。
您可以重复这个过程,提取响应结果中最后一条文档的价格值,并将其用作下一页搜索请求的 search_after 值,以获取下一页的数据。这样,您可以通过不断更新 search_after 值来获取所需的所有分页数据。
2.2.3.小结
分页查询的常见实现方案以及优缺点:
-
from + size:- 优点:支持随机翻页
- 缺点:深度分页问题,默认查询上限(from + size)是10000
- 场景:百度、京东、谷歌、淘宝这样的随机翻页搜索
-
after search:- 优点:没有查询上限(单次查询的size不超过10000)
- 缺点:只能向后逐页查询,不支持随机翻页
- 场景:没有随机翻页需求的搜索,例如手机向下滚动翻页
-
scroll:- 优点:没有查询上限(单次查询的size不超过10000)
- 缺点:会有额外内存消耗,并且搜索结果是非实时的
- 场景:海量数据的获取和迁移。从ES7.1开始不推荐,建议用 after search方案。
2.3.高亮
2.3.1.高亮原理
什么是高亮显示呢?
我们在百度,京东搜索时,关键字会变成红色,比较醒目,这叫高亮显示:
高亮显示的实现分为两步:
- 1)给文档中的所有关键字都添加一个标签,例如
<em>标签 - 2)页面给
<em>标签编写CSS样式 - 3)然后和前端约定好这个特殊标签修改样式即可
2.3.2.实现高亮
高亮的语法:
GET /hotel/_search
{"query": {"match": {"FIELD": "TEXT" // 查询条件,高亮一定要使用全文检索查询 分词到哪个部分高亮}},"highlight": {"fields": { // 指定要高亮的字段"FIELD": {"pre_tags": "<em>", // 用来标记高亮字段的前置标签"post_tags": "</em>" // 用来标记高亮字段的后置标签}}}
}
注意:
- 高亮是对关键字高亮,因此搜索条件必须带有关键字,而不能是范围这样的查询。
- 默认情况下,高亮的字段,必须与搜索指定的字段一致,否则无法高亮
- 如果要对非搜索字段高亮,则需要添加一个属性:required_field_match=false
示例:
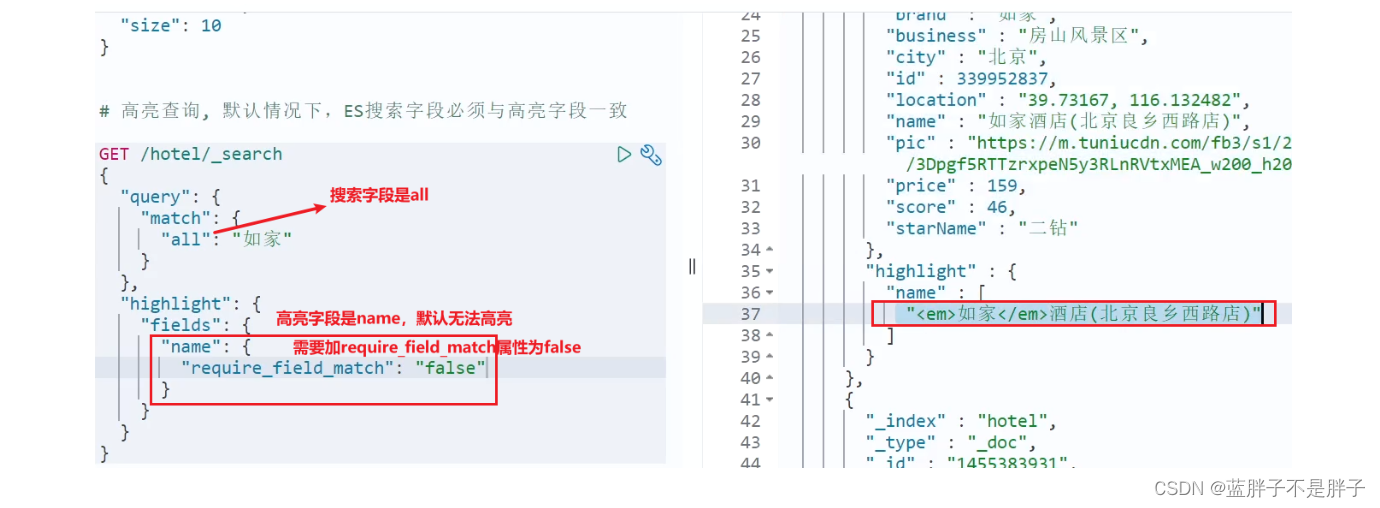
代码演示:
GET /hotel/_search
{"query": {"match": {"all": "如家"}},"highlight": {"fields": {"name": {"require_field_match": "false"}}}
}
- require_field_match 需求字段匹配,因为建立索引的时候将为了避免同时检索多个条件,而创建检索字段all,高亮默认配置是字段检索字段和高亮字段一至,所以
"require_field_match": "false"
是为了取消字段匹配,让满足分词检索的结果想哪个字段高亮就高亮- 如果不喜欢默认添加的env标签 ,可以通过以下配置修改自定义标签
"highlight": {"fields": {"your_field": {}},"pre_tags": ["<gaoliang>"], // 自定义前置标签"post_tags": ["</gaoliang>"] // 自定义后置标签}
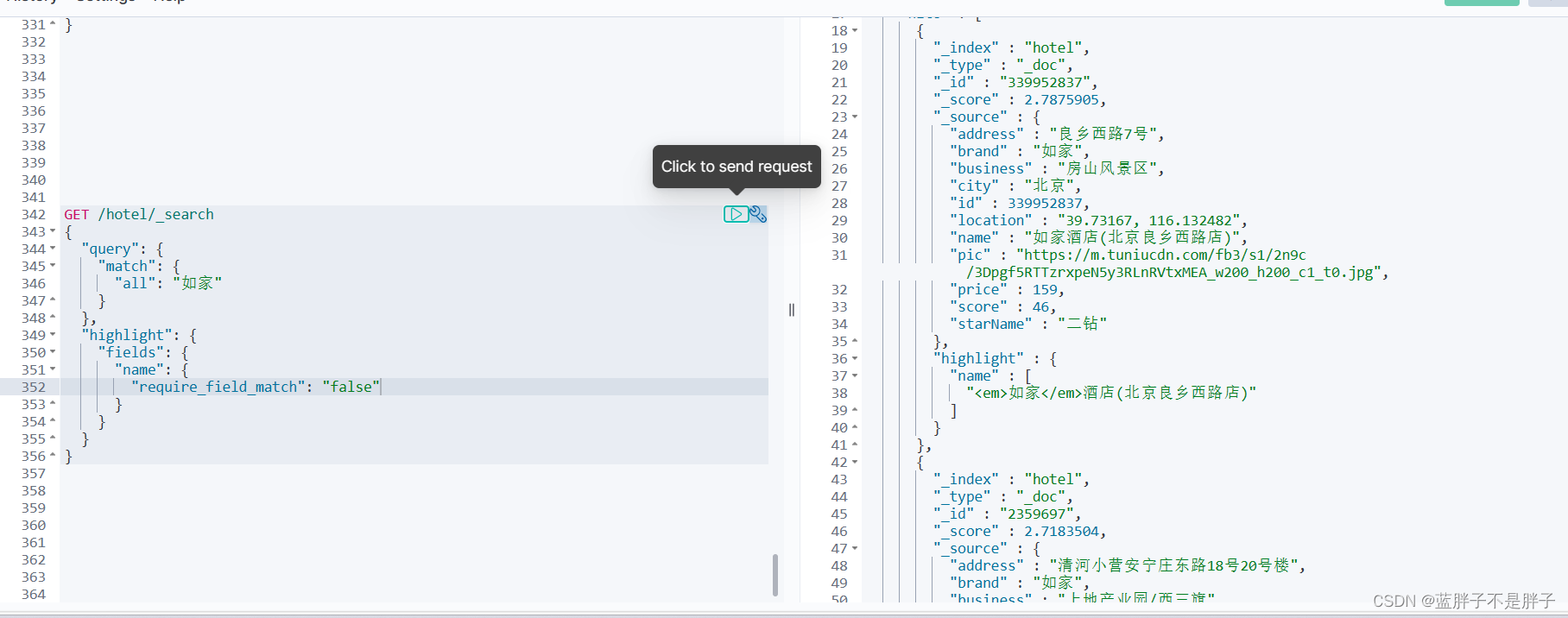
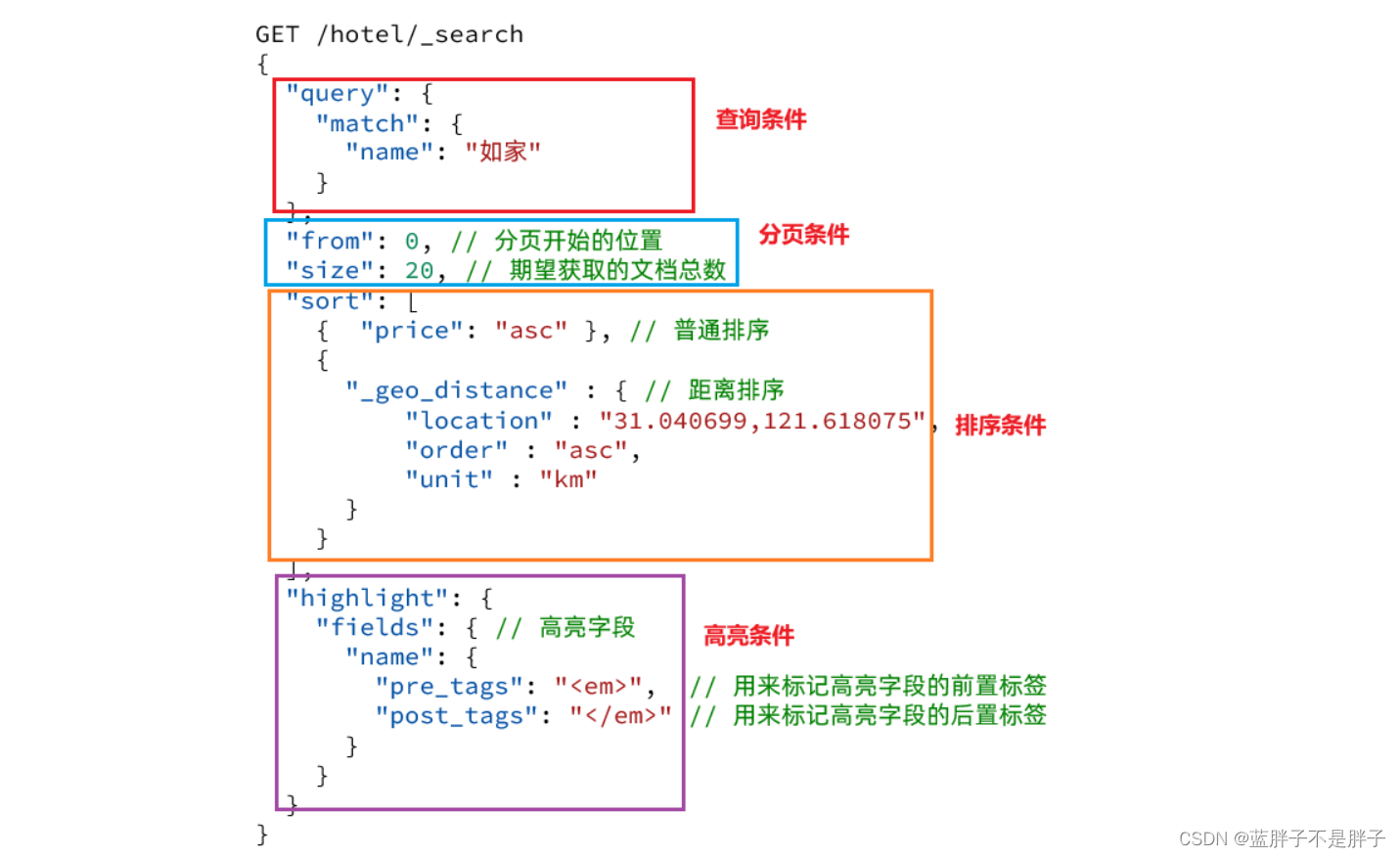
2.4.总结
查询的DSL是一个大的JSON对象,包含下列属性:
- query:查询条件
- from和size:分页条件
- sort:排序条件
- highlight:高亮条件
示例:
第二部分使用java客户端工具操作es
3.RestClient查询文档
文档的查询同样适用昨天学习的 RestHighLevelClient对象,基本步骤包括:
- 1)准备Request对象
- 2)准备请求参数
- 3)发起请求
- 4)解析响应
3.1.快速入门
我们以match_all查询为例
3.1.1.发起查询请求
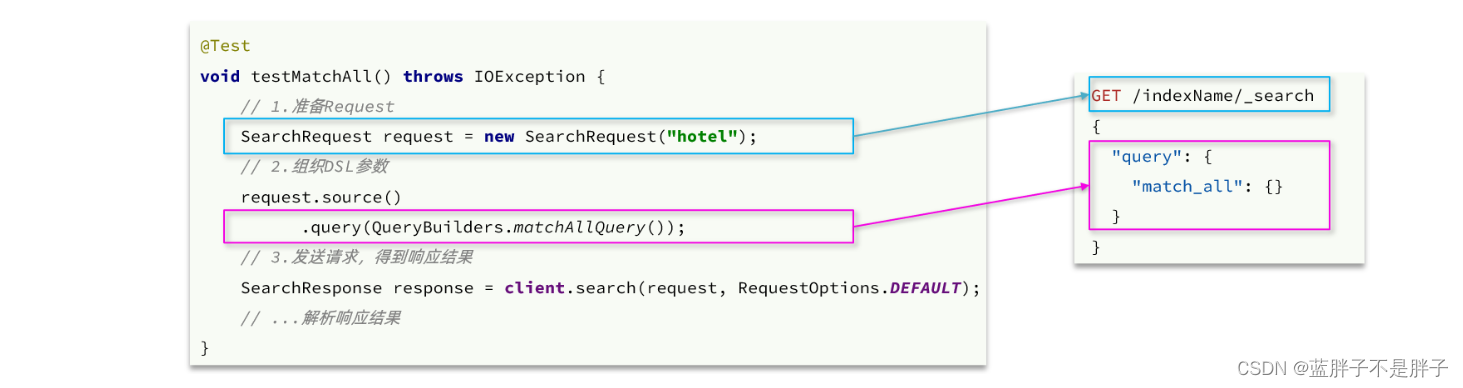
代码解读:
-
第一步,创建
SearchRequest对象,指定索引库名 -
第二步,利用
request.source()构建DSL,DSL中可以包含查询、分页、排序、高亮等query():代表查询条件,利用QueryBuilders.matchAllQuery()构建一个match_all查询的DSL
-
第三步,利用client.search()发送请求,得到响应
这里关键的API有两个,一个是request.source(),其中包含了查询、排序、分页、高亮等所有功能:
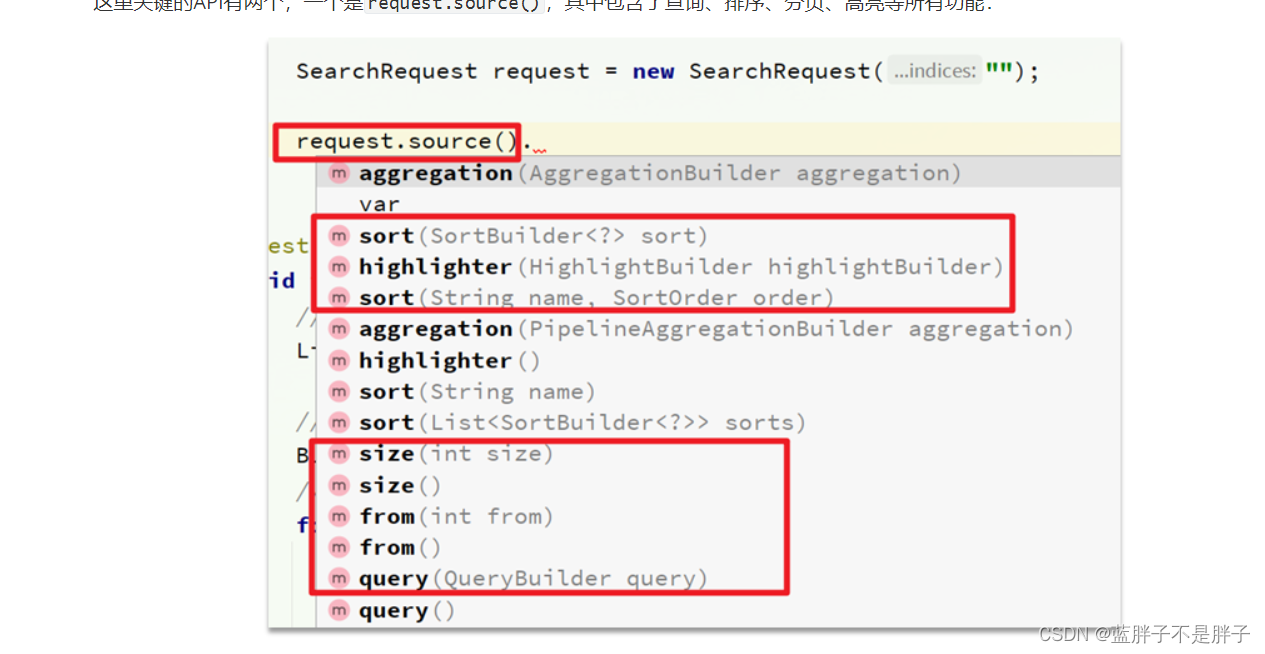
另一个是QueryBuilders,其中包含match、term、function_score、bool等各种查询:
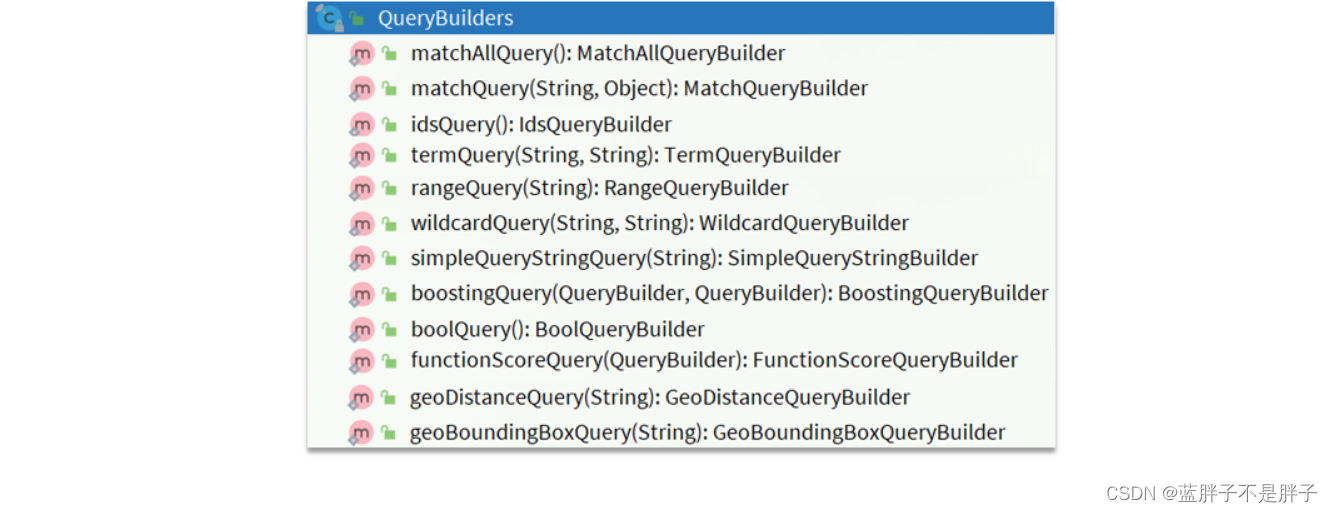
3.1.2.解析响应
响应结果的解析:
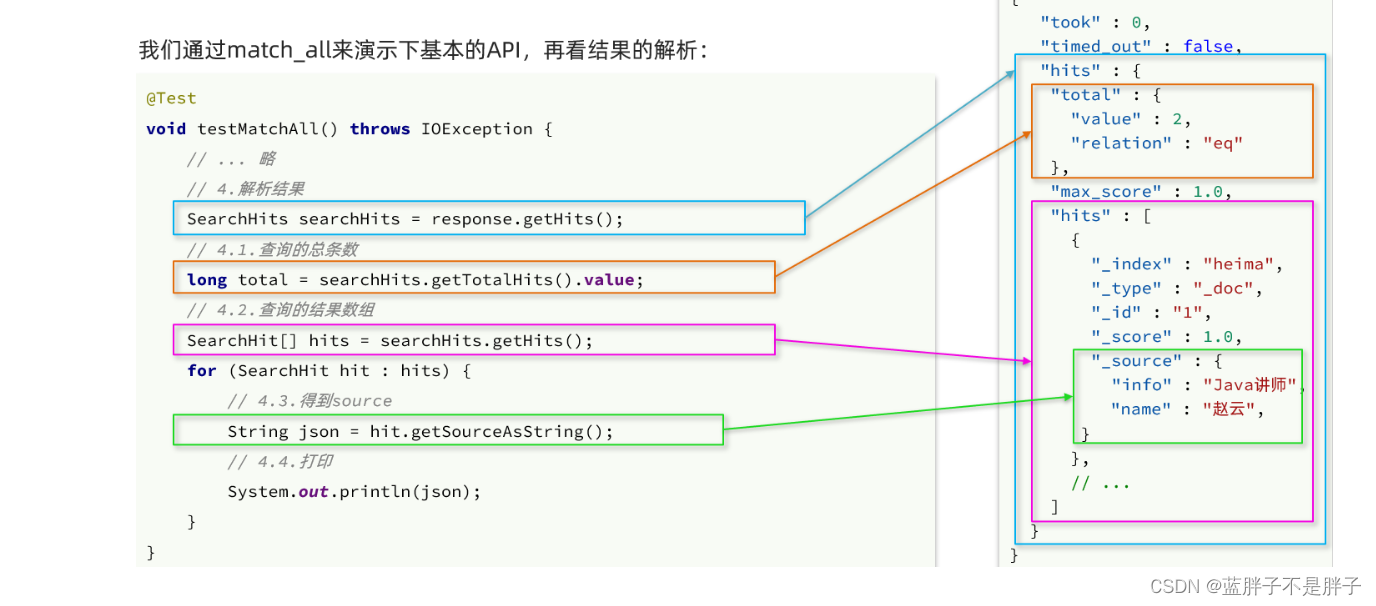
elasticsearch返回的结果是一个JSON字符串,结构包含:
hits:命中的结果total:总条数,其中的value是具体的总条数值max_score:所有结果中得分最高的文档的相关性算分hits:搜索结果的文档数组,其中的每个文档都是一个json对象_source:文档中的原始数据,也是json对象
因此,我们解析响应结果,就是逐层解析JSON字符串,流程如下:
SearchHits:通过response.getHits()获取,就是JSON中的最外层的hits,代表命中的结果SearchHits#getTotalHits().value:获取总条数信息SearchHits#getHits():获取SearchHit数组,也就是文档数组SearchHit#getSourceAsString():获取文档结果中的_source,也就是原始的json文档数据
所以解析要做的就是把命中的文档读取出来
@Testvoid testSearchDocument() throws IOException {SearchRequest request = new SearchRequest("hotel");request.source().query(QueryBuilders.matchAllQuery());SearchResponse response = client.search(request, RequestOptions.DEFAULT);SearchHits hits = response.getHits();System.out.println("返回的查询结果:");Arrays.stream(hits.getHits()).forEach(hit -> System.out.println("" +hit));}
3.1.3.完整代码
也可以把解析的部分封装为一个api
完整代码如下:
@Test
void testMatchAll() throws IOException {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备DSLrequest.source().query(QueryBuilders.matchAllQuery());// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);
}private void handleResponse(SearchResponse response) {// 4.解析响应SearchHits searchHits = response.getHits();// 4.1.获取总条数long total = searchHits.getTotalHits().value;System.out.println("共搜索到" + total + "条数据");// 4.2.文档数组SearchHit[] hits = searchHits.getHits();// 4.3.遍历for (SearchHit hit : hits) {// 获取文档sourceString json = hit.getSourceAsString();// 反序列化HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);System.out.println("hotelDoc = " + hotelDoc);}
}
3.1.4.小结
查询的基本步骤是:
-
创建SearchRequest对象
-
准备Request.source(),也就是DSL。
① QueryBuilders来构建查询条件
② 传入Request.source() 的 query() 方法
-
发送请求,得到结果
-
解析结果(参考JSON结果,从外到内,逐层解析)
3.2.match查询
全文检索的match和multi_match查询与match_all的API基本一致。差别是查询条件,也就是query的部分。match是检索内容匹配单一字段,multi_match则是检索的内容对应多个字段

因此,Java代码上的差异主要是request.source().query()中的参数了。同样是利用QueryBuilders提供的方法:

而结果解析代码则完全一致,可以抽取并共享。
完整代码如下:
@Testvoid testSearchName() throws IOException {
// 演示用户查找的是酒店名字 ,并且实际情况是酒店名字中带有品牌名 所以一般是检索内容匹配多个字段String nameByuser = "如家";SearchRequest request = new SearchRequest("hotel");
// 构造查询条件request.source().query(QueryBuilders.matchQuery("all",nameByuser));//这里用专门的匹配字段进行匹配
// 也可以多个字段匹配但是性能会下降
// request.source().query(QueryBuilders.multiMatchQuery(nameByuser,"name","brand"));SearchResponse response = client.search(request, RequestOptions.DEFAULT);handleResponse(response);}
3.3.精确查询
精确查询主要是两者:
- term:词条精确匹配
- range:范围查询
与之前的查询相比,差异同样在查询条件,其它都一样。
查询条件构造的API如下:

3.4.布尔查询
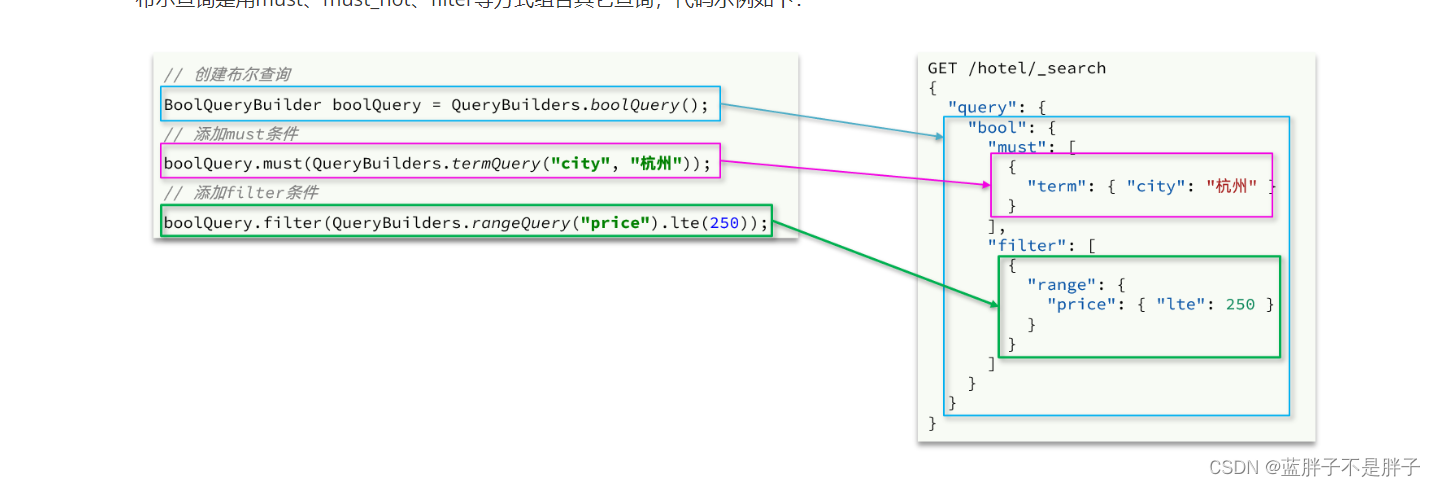
布尔查询是用must、must_not、filter等方式组合其它查询,代码示例如下:
可以看到,API与其它查询的差别同样是在查询条件的构建,QueryBuilders,结果解析等其他代码完全不变。
完整代码如下:
查询在杭州的价格低于250的数据
@Test
void testBool() throws IOException {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备DSL// 2.1.准备BooleanQueryBoolQueryBuilder boolQuery = QueryBuilders.boolQuery();// 2.2.添加termboolQuery.must(QueryBuilders.termQuery("city", "杭州"));// 2.3.添加rangeboolQuery.filter(QueryBuilders.rangeQuery("price").lte(250));request.source().query(boolQuery);// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应handleResponse(response);}
演示的是查询价格在200~500 评分高于30的如家品牌数据
// 演示复合查询 bool@Testvoid testBoolSearch()throws IOException{SearchRequest searchRequest = new SearchRequest("hotel");
// 因为boolquery要设置多个匹配,所以不直接放在queryapi中BoolQueryBuilder boolQuery= QueryBuilders.boolQuery();//boolquery的查询匹配条件和过滤条件boolQuery.must(QueryBuilders.termQuery("brand","如家"));//如家的品牌
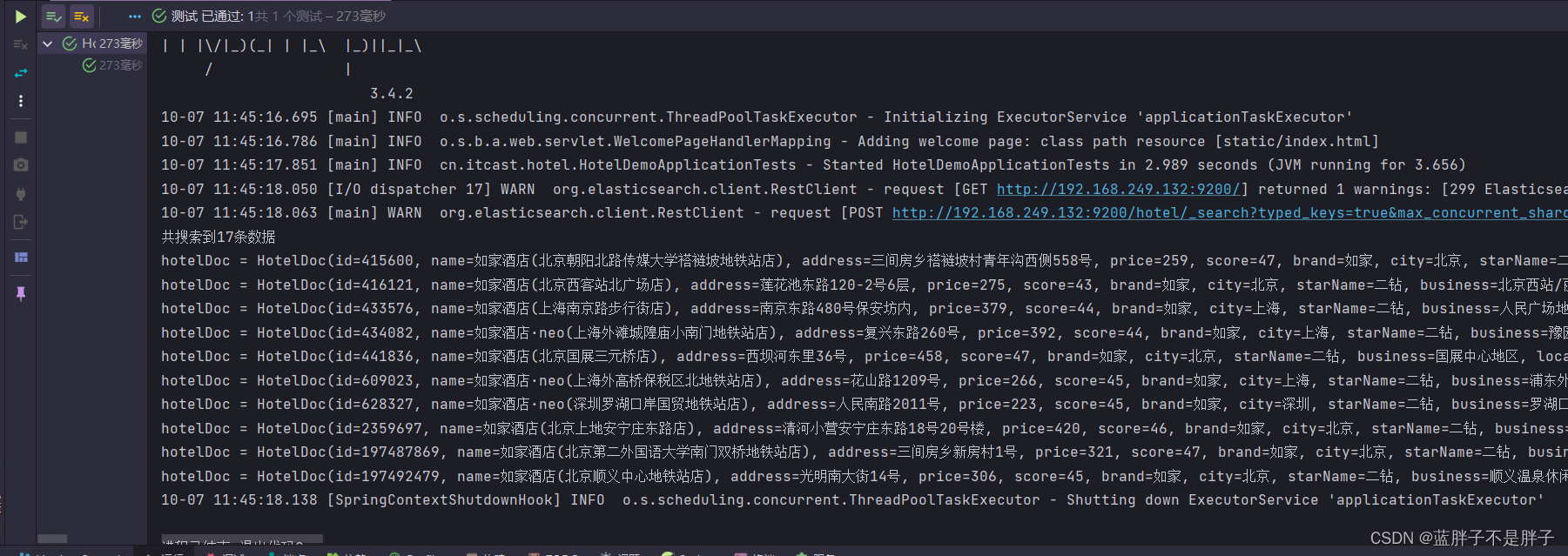
// 大于200小于500boolQuery.must(QueryBuilders.rangeQuery("price").lte(500).gt(200));//上描述的条件 必须都是评分大于30的数据boolQuery.filter(QueryBuilders.rangeQuery("score").gt(30));searchRequest.source().query(boolQuery);SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);handleResponse(response);}
查询结果 满足条件
3.5.排序、分页
搜索结果的排序和分页是与query同级的参数,因此同样是使用request.source()来设置。
对应的API如下:

完整代码示例:
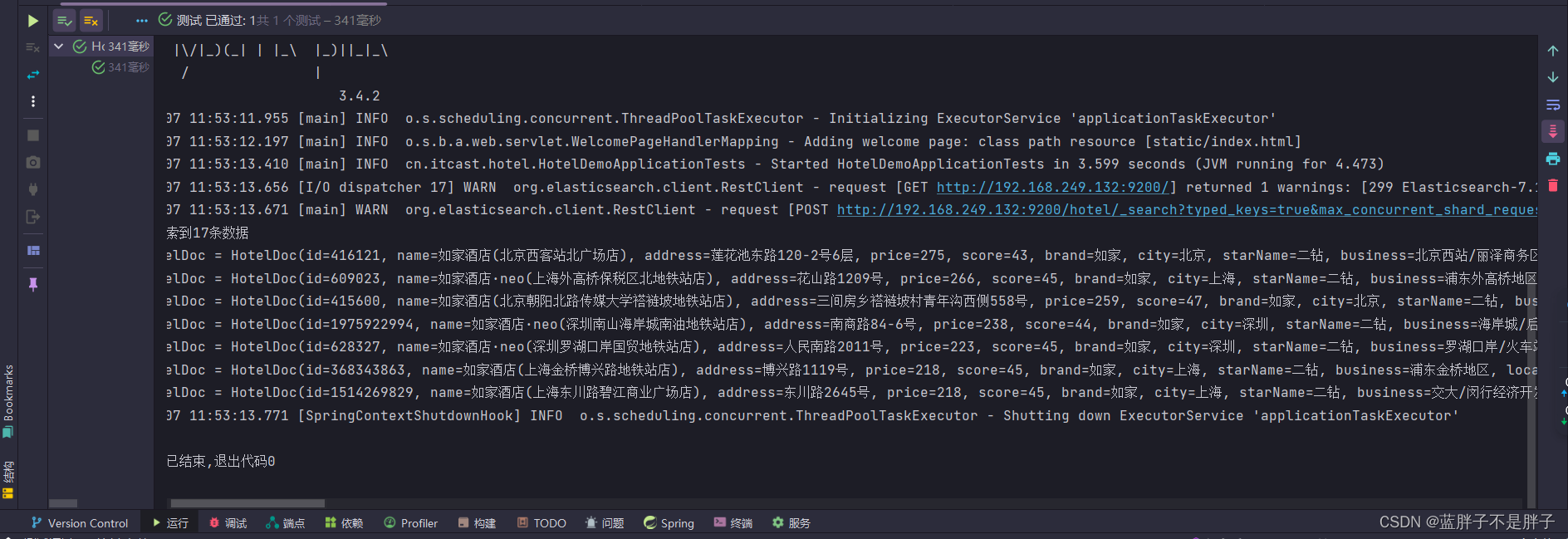
// 演示复合查询 bool@Testvoid testBoolSearch()throws IOException{SearchRequest searchRequest = new SearchRequest("hotel");
// 因为boolquery要设置多个匹配,所以不直接放在queryapi中BoolQueryBuilder boolQuery= QueryBuilders.boolQuery();//boolquery的查询匹配条件和过滤条件boolQuery.must(QueryBuilders.termQuery("brand","如家"));//如家的品牌
// 大于200小于500boolQuery.must(QueryBuilders.rangeQuery("price").lte(500).gt(200));//上描述的条件 必须都是评分大于30的数据boolQuery.filter(QueryBuilders.rangeQuery("score").gt(30));searchRequest.source().query(boolQuery);//模拟前端传递过来的页面和排序需求searchRequest.source().from(10).size(20);searchRequest.source().sort("price", SortOrder.DESC);SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);handleResponse(response);}值得注意的是虽然这些api是链式编程,在query方法后还可以调用size和sorte等,但是不是我们所需要的api,分页,排序和query是同级别的,所以api都是写在source()加载dsl语句的方法后的
运行结果
3.6.高亮
高亮的代码与之前代码差异较大,有两点:
- 查询的DSL:其中除了查询条件,还需要添加高亮条件,同样是与query同级。
- 结果解析:结果除了要解析_source文档数据,还要解析高亮结果
3.6.1.高亮请求构建
高亮请求的构建API如下:

上述代码省略了查询条件部分,但是大家不要忘了:高亮查询必须使用全文检索查询,并且要有搜索关键字,将来才可以对关键字高亮。
3.6.2.高亮结果解析
高亮的结果与查询的文档结果默认是分离的,并不在一起。
发情请求和解析高亮的完整代码:
@Testvoid testHighLight()throws IOException{SearchRequest searchRequest = new SearchRequest("hotel");
// 对检索出来的分词做高亮处理searchRequest.source().query(QueryBuilders.matchQuery("all","如家"));
// 指定哪个字段高亮searchRequest.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));//不进行字段匹配SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);Arrays.stream(response.getHits().getHits()).forEach(hit ->hit.getHighlightFields().entrySet().forEach(entry ->System.out.println("命中数据的高亮的字段是:"+entry.getKey()+" 高亮的结果是:"+Arrays.toString(entry.getValue().getFragments()))));}
因此解析高亮的代码需要额外处理:
运行结果
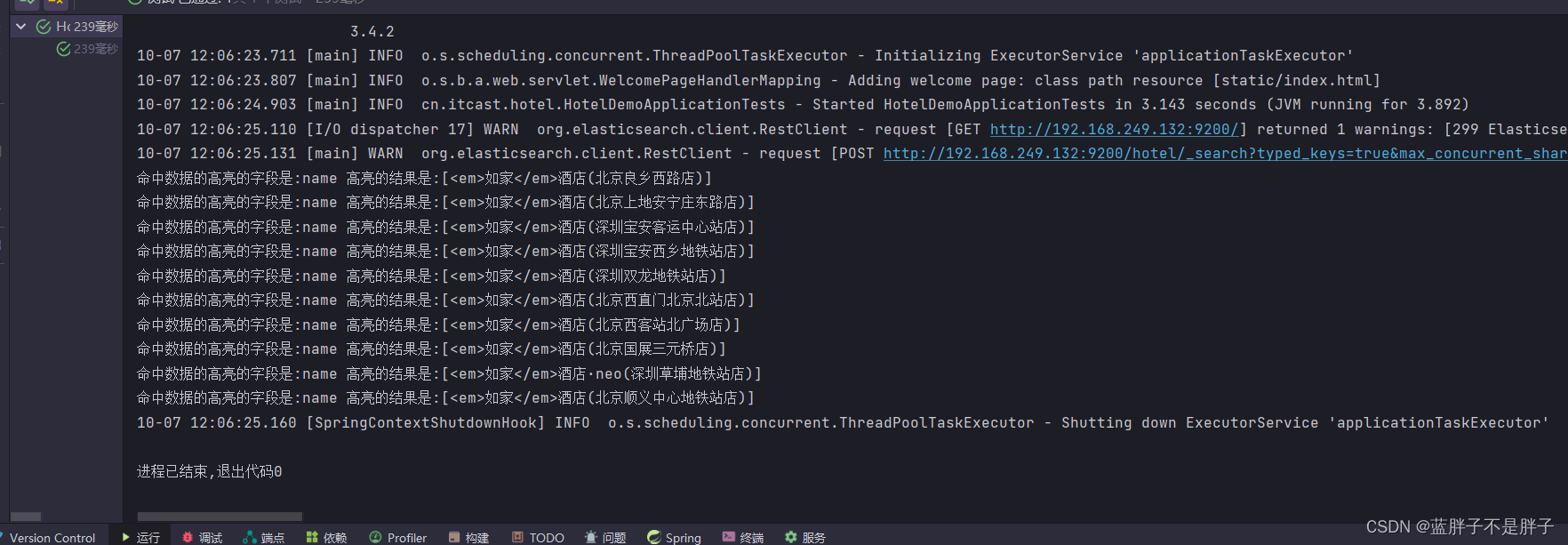
我这里进行了stream流的便利,出现了俩个gethits,原因无他控制台输出返回的search请求的返回值response
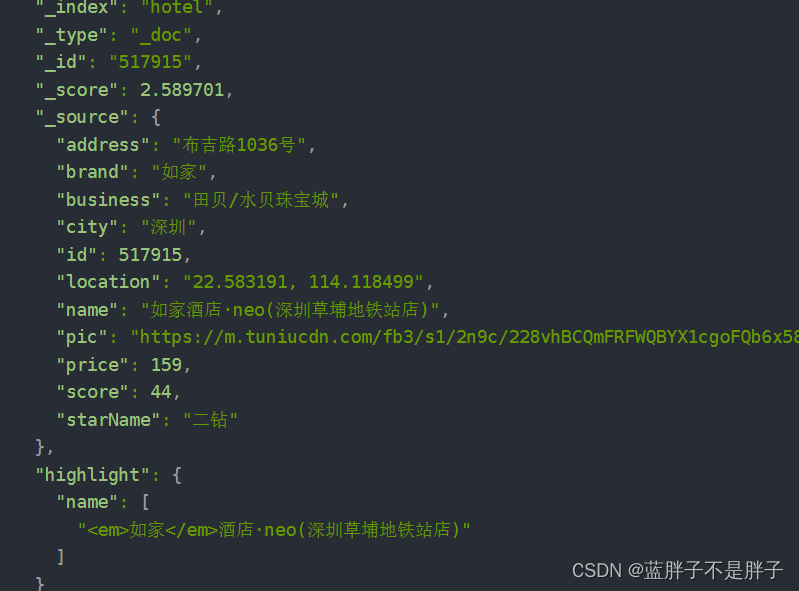
{"took": 5,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 30,"relation": "eq"},"max_score": 2.7875905,"hits": [{"_index": "hotel","_type": "_doc","_id": "339952837","_score": 2.7875905,"_source": {"address": "良乡西路7号","brand": "如家","business": "房山风景区","city": "北京","id": 339952837,"location": "39.73167, 116.132482","name": "如家酒店(北京良乡西路店)","pic": "https://m.tuniucdn.com/fb3/s1/2n9c/3Dpgf5RTTzrxpeN5y3RLnRVtxMEA_w200_h200_c1_t0.jpg","price": 159,"score": 46,"starName": "二钻"},"highlight": {"name": ["<em>如家</em>酒店(北京良乡西路店)"]}},{"_index": "hotel","_type": "_doc","_id": "2359697","_score": 2.7183504,"_source": {"address": "清河小营安宁庄东路18号20号楼","brand": "如家","business": "上地产业园/西三旗","city": "北京","id": 2359697,"location": "40.041322, 116.333316","name": "如家酒店(北京上地安宁庄东路店)","pic": "https://m.tuniucdn.com/fb3/s1/2n9c/2wj2f8mo9WZQCmzm51cwkZ9zvyp8_w200_h200_c1_t0.jpg","price": 420,"score": 46,"starName": "二钻"},"highlight": {"name": ["<em>如家</em>酒店(北京上地安宁庄东路店)"]}},{"_index": "hotel","_type": "_doc","_id": "1455383931","_score": 2.7183504,"_source": {"address": "西乡河西金雅新苑34栋","brand": "如家","business": "宝安商业区","city": "深圳","id": 1455383931,"location": "22.590272, 113.881933","name": "如家酒店(深圳宝安客运中心站店)","pic": "https://m.tuniucdn.com/fb3/s1/2n9c/2w9cbbpzjjsyd2wRhFrnUpBMT8b4_w200_h200_c1_t0.jpg","price": 169,"score": 45,"starName": "二钻"},"highlight": {"name": ["<em>如家</em>酒店(深圳宝安客运中心站店)"]}},{"_index": "hotel","_type": "_doc","_id": "728180","_score": 2.6524668,"_source": {"address": "西乡大道298-7号(富通城二期公交站旁)","brand": "如家","business": "宝安体育中心商圈","city": "深圳","id": 728180,"location": "22.569693, 113.860186","name": "如家酒店(深圳宝安西乡地铁站店)","pic": "https://m.tuniucdn.com/fb3/s1/2n9c/FHdugqgUgYLPMoC4u4rdTbAPrVF_w200_h200_c1_t0.jpg","price": 184,"score": 43,"starName": "二钻"},"highlight": {"name": ["<em>如家</em>酒店(深圳宝安西乡地铁站店)"]}},{"_index": "hotel","_type": "_doc","_id": "2316304","_score": 2.6524668,"_source": {"address": "龙岗街道龙岗墟社区龙平东路62号","brand": "如家","business": "龙岗中心区/大运新城","city": "深圳","id": 2316304,"location": "22.730828, 114.278337","name": "如家酒店(深圳双龙地铁站店)","pic": "https://m.tuniucdn.com/fb3/s1/2n9c/4AzEoQ44awd1D2g95a6XDtJf3dkw_w200_h200_c1_t0.jpg","price": 135,"score": 45,"starName": "二钻"},"highlight": {"name": ["<em>如家</em>酒店(深圳双龙地铁站店)"]}},{"_index": "hotel","_type": "_doc","_id": "1765008760","_score": 2.6524668,"_source": {"address": "西直门北大街49号","brand": "如家","business": "西直门/北京展览馆地区","city": "北京","id": 1765008760,"location": "39.945106, 116.353827","name": "如家酒店(北京西直门北京北站店)","pic": "https://m.tuniucdn.com/fb3/s1/2n9c/4CLwbCE9346jYn7nFsJTQXuBExTJ_w200_h200_c1_t0.jpg","price": 356,"score": 44,"starName": "二钻"},"highlight": {"name": ["<em>如家</em>酒店(北京西直门北京北站店)"]}},{"_index": "hotel","_type": "_doc","_id": "416121","_score": 2.589701,"_source": {"address": "莲花池东路120-2号6层","brand": "如家","business": "北京西站/丽泽商务区","city": "北京","id": 416121,"location": "39.896449, 116.317382","name": "如家酒店(北京西客站北广场店)","pic": "https://m.tuniucdn.com/fb3/s1/2n9c/42DTRnKbiYoiGFVzrV9ZJUxNbvRo_w200_h200_c1_t0.jpg","price": 275,"score": 43,"starName": "二钻"},"highlight": {"name": ["<em>如家</em>酒店(北京西客站北广场店)"]}},{"_index": "hotel","_type": "_doc","_id": "441836","_score": 2.589701,"_source": {"address": "西坝河东里36号","brand": "如家","business": "国展中心地区","city": "北京","id": 441836,"location": "39.966238, 116.450142","name": "如家酒店(北京国展三元桥店)","pic": "https://m.tuniucdn.com/fb2/t1/G6/M00/52/39/Cii-TF3eRTGITp1UAAYIilRD7skAAGLngIuAnQABgii479_w200_h200_c1_t0.png","price": 458,"score": 47,"starName": "二钻"},"highlight": {"name": ["<em>如家</em>酒店(北京国展三元桥店)"]}},{"_index": "hotel","_type": "_doc","_id": "517915","_score": 2.589701,"_source": {"address": "布吉路1036号","brand": "如家","business": "田贝/水贝珠宝城","city": "深圳","id": 517915,"location": "22.583191, 114.118499","name": "如家酒店·neo(深圳草埔地铁站店)","pic": "https://m.tuniucdn.com/fb3/s1/2n9c/228vhBCQmFRFWQBYX1cgoFQb6x58_w200_h200_c1_t0.jpg","price": 159,"score": 44,"starName": "二钻"},"highlight": {"name": ["<em>如家</em>酒店·neo(深圳草埔地铁站店)"]}},........}}
代码解读:
gethits得到命中的数据体里面包含总条数等信息,然后从searchhits中获取详细的hit数组

数组的每一个元素是一个hit对象,而高亮处理的字段就在其中,并且java封装其为很多和键值对在map中
读出
hit.getHighlightFields().entrySet().forEach(entry ->System.out.println("命中数据的高亮的字段是:"+entry.getKey()+" 高亮的结果是:"+Arrays.toString(entry.getValue().getFragments()))
- 第一步:从结果中获取source。hit.getSourceAsString(),这部分是非高亮结果,json字符串。还需要反序列为HotelDoc对象
- 第二步:获取高亮结果。hit.getHighlightFields(),返回值是一个Map,key是高亮字段名称,值是HighlightField对象,代表高亮值
- 第三步:从map中根据高亮字段名称,获取高亮字段值对象HighlightField
- 第四步:从HighlightField中获取Fragments,并且转为字符串。这部分就是真正的高亮字符串了
- 第五步:用高亮的结果替换HotelDoc中的非高亮结果
完整代码如下:
private void handleResponse(SearchResponse response) {// 4.解析响应SearchHits searchHits = response.getHits();// 4.1.获取总条数long total = searchHits.getTotalHits().value;System.out.println("共搜索到" + total + "条数据");// 4.2.文档数组SearchHit[] hits = searchHits.getHits();// 4.3.遍历for (SearchHit hit : hits) {// 获取文档sourceString json = hit.getSourceAsString();// 反序列化HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);// 获取高亮结果Map<String, HighlightField> highlightFields = hit.getHighlightFields();if (!CollectionUtils.isEmpty(highlightFields)) {// 根据字段名获取高亮结果HighlightField highlightField = highlightFields.get("name");if (highlightField != null) {// 获取高亮值String name = highlightField.getFragments()[0].string();// 覆盖非高亮结果hotelDoc.setName(name);}}System.out.println("hotelDoc = " + hotelDoc);}
}
4.黑马旅游案例
bilibili 有对应的视频教材和练习项目可以下载来自己实践
我们实现四部分功能:
- 酒店搜索和分页
- 酒店结果过滤
- 我周边的酒店
- 酒店竞价排名
启动我们提供的hotel-demo项目,其默认端口是8089,访问http://localhost:8090,就能看到项目页面了:
4.1.酒店搜索和分页
案例需求:实现黑马旅游的酒店搜索功能,完成关键字搜索和分页
4.1.1.需求分析
在项目的首页,有一个大大的搜索框,还有分页按钮:
请求参数如下:
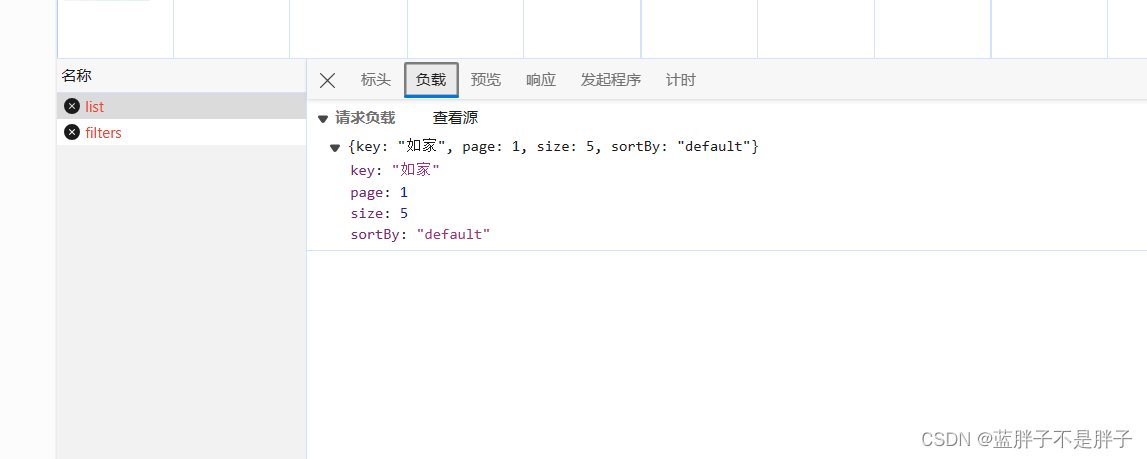
由此可以知道,我们这个请求的信息如下:
- 请求方式:POST
- 请求路径:/hotel/list
- 请求参数:JSON对象,包含4个字段:
- key:搜索关键字
- page:页码
- size:每页大小
- sortBy:排序,目前暂不实现
- 返回值:分页查询,需要返回分页结果PageResult,包含两个属性:
total:总条数List<HotelDoc>:当前页的数据
因此,我们实现业务的流程如下:
- 步骤一:定义实体类,接收请求参数的JSON对象
- 步骤二:编写controller,接收页面的请求
- 步骤三:编写业务实现,利用RestHighLevelClient实现搜索、分页
4.1.2.定义实体类
实体类有两个,一个是前端的请求参数实体,一个是服务端应该返回的响应结果实体。
1)请求参数
前端请求的json结构如下:
{"key": "搜索关键字","page": 1,"size": 3,"sortBy": "default"
}
因此,我们在cn.itcast.hotel.pojo包下定义一个实体类:
package cn.itcast.hotel.pojo;import lombok.Data;@Data
public class RequestParams {private String key;private Integer page;private Integer size;private String sortBy;
}
2)返回值
分页查询,需要返回分页结果PageResult,包含两个属性:
total:总条数List<HotelDoc>:当前页的数据
因此,我们在cn.itcast.hotel.pojo中定义返回结果:
package cn.itcast.hotel.pojo;import lombok.Data;import java.util.List;@Data
public class PageResult {private Long total;private List<HotelDoc> hotels;public PageResult() {}public PageResult(Long total, List<HotelDoc> hotels) {this.total = total;this.hotels = hotels;}
}
4.1.3.定义controller
定义一个HotelController,声明查询接口,满足下列要求:
- 请求方式:Post
- 请求路径:/hotel/list
- 请求参数:对象,类型为RequestParam
- 返回值:PageResult,包含两个属性
Long total:总条数List<HotelDoc> hotels:酒店数据
因此,我们在cn.itcast.hotel.web中定义HotelController:
@RestController
@RequestMapping("/hotel")
public class HotelController {@Autowiredprivate IHotelService hotelService;// 搜索酒店数据@PostMapping("/list")public PageResult search(@RequestBody RequestParams params){return hotelService.search(params);}
}
4.1.4.实现搜索业务
我们在controller调用了IHotelService,并没有实现该方法,因此下面我们就在IHotelService中定义方法,并且去实现业务逻辑。
1)在cn.itcast.hotel.service中的IHotelService接口中定义一个方法:
/*** 根据关键字搜索酒店信息* @param params 请求参数对象,包含用户输入的关键字 * @return 酒店文档列表*/
PageResult search(RequestParams params);
2)实现搜索业务,肯定离不开RestHighLevelClient,我们需要把它注册到Spring中作为一个Bean。在cn.itcast.hotel中的HotelDemoApplication中声明这个Bean:
@Bean
public RestHighLevelClient client(){return new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.150.101:9200")));
}
3)在cn.itcast.hotel.service.impl中的HotelService中实现search方法:
@Override@Overridepublic PageResult search(RequestParam requestParam) throws IOException {
// 普通的全文检索SearchRequest searchRequest = new SearchRequest("hotel");if (requestParam.getKey() == null){
// 没有条件 返回为空或者查询全部searchRequest.source().query(QueryBuilders.matchAllQuery());}searchRequest.source().query(QueryBuilders.matchQuery("all", requestParam.getKey().toString()));searchRequest.source().from((requestParam.getPage()-1)*requestParam.getSize()).size(requestParam.getSize());SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);List<HotelDoc> list = Arrays.stream(response.getHits().getHits()).map(item ->JSON.parseObject(item.getSourceAsString(), HotelDoc.class)).collect(Collectors.toList());return new PageResult(response.getHits().getTotalHits().value,list);}也可以优化,结果解析专门做一个方法
// 结果解析
private PageResult handleResponse(SearchResponse response) {// 4.解析响应SearchHits searchHits = response.getHits();// 4.1.获取总条数long total = searchHits.getTotalHits().value;// 4.2.文档数组SearchHit[] hits = searchHits.getHits();// 4.3.遍历List<HotelDoc> hotels = new ArrayList<>();for (SearchHit hit : hits) {// 获取文档sourceString json = hit.getSourceAsString();// 反序列化HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);// 放入集合hotels.add(hotelDoc);}// 4.4.封装返回return new PageResult(total, hotels);
}
得到返回数据
4.2.酒店结果过滤
需求:添加品牌、城市、星级、价格等过滤功能
4.2.1.需求分析
在页面搜索框下面,会有一些过滤项:

传递的参数如图:
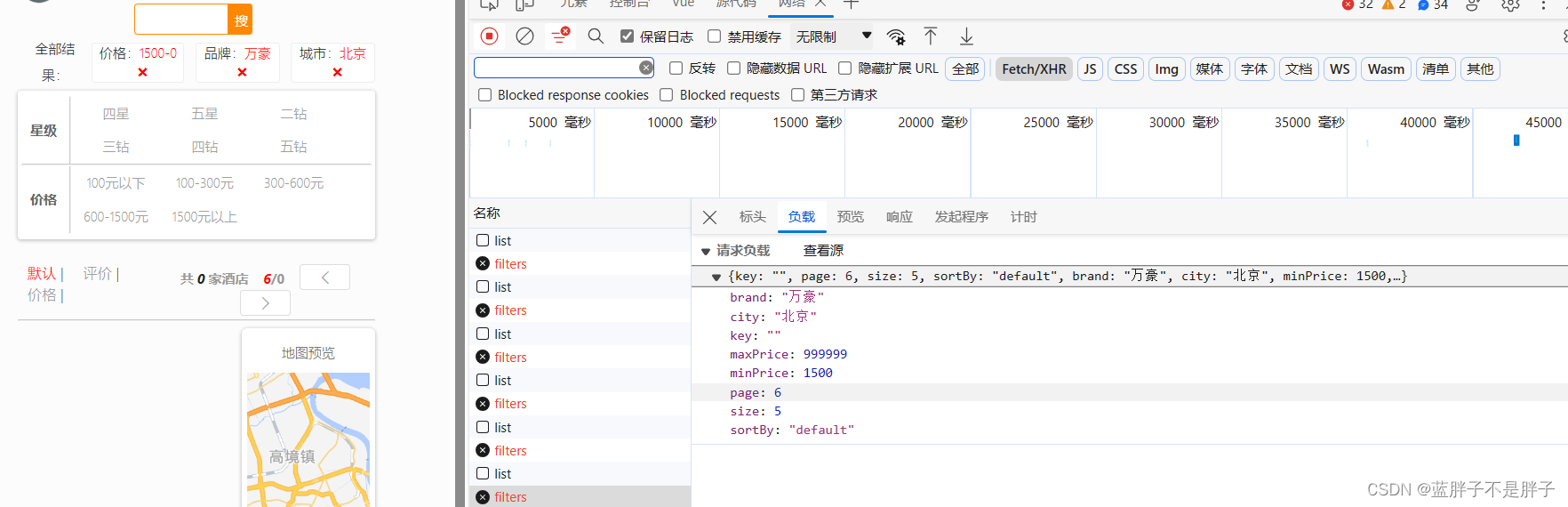
包含的过滤条件有:
- brand:品牌值
- city:城市
- minPrice~maxPrice:价格范围
- starName:星级
我们需要做两件事情:
- 修改请求参数的对象RequestParams,接收上述参数
- 修改业务逻辑,在搜索条件之外,添加一些过滤条件
4.2.2.修改实体类
修改在cn.itcast.hotel.pojo包下的实体类RequestParams:
@Data
public class RequestParams {private String key;private Integer page;private Integer size;private String sortBy;// 下面是新增的过滤条件参数private String city;private String brand;private String starName;private Integer minPrice;private Integer maxPrice;
}
4.2.3.修改搜索业务
在HotelService的search方法中,只有一个地方需要修改:requet.source().query( … )其中的查询条件。
在之前的业务中,只有match查询,根据关键字搜索,现在要添加条件过滤,包括:
- 品牌过滤:是keyword类型,用term查询
- 星级过滤:是keyword类型,用term查询
- 价格过滤:是数值类型,用range查询
- 城市过滤:是keyword类型,用term查询
多个查询条件组合,肯定是复合查询中的boolean查询来组合:
- 关键字搜索放到must中,参与算分
- 其它过滤条件放到filter中,不参与算分
因为条件构建的逻辑比较复杂,这里先封装为一个函数:
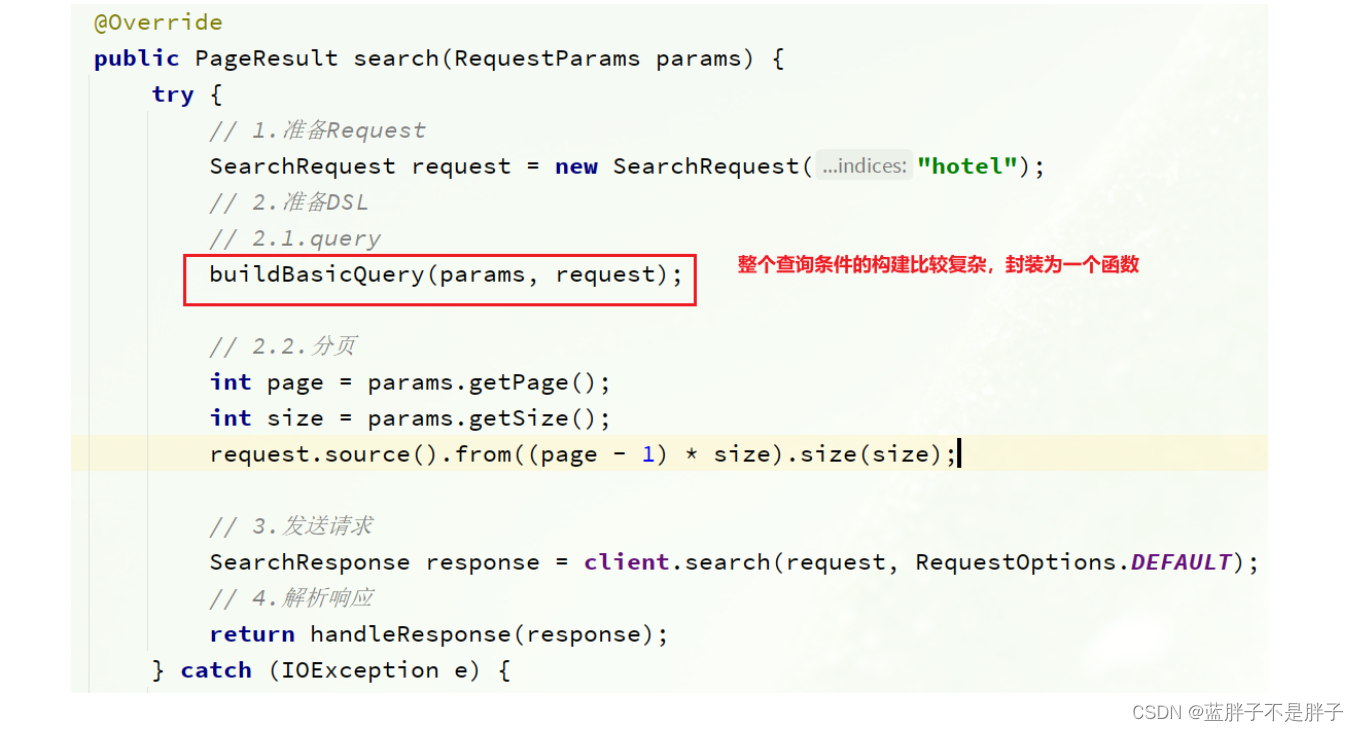
buildBasicQuery的代码如下:
private void buildBasicQuery(RequestParams params, SearchRequest request) {// 1.构建BooleanQueryBoolQueryBuilder boolQuery = QueryBuilders.boolQuery();// 2.关键字搜索String key = params.getKey();if (key == null || "".equals(key)) {boolQuery.must(QueryBuilders.matchAllQuery());} else {boolQuery.must(QueryBuilders.matchQuery("all", key));}// 3.城市条件if (params.getCity() != null && !params.getCity().equals("")) {boolQuery.filter(QueryBuilders.termQuery("city", params.getCity()));}// 4.品牌条件if (params.getBrand() != null && !params.getBrand().equals("")) {boolQuery.filter(QueryBuilders.termQuery("brand", params.getBrand()));}// 5.星级条件if (params.getStarName() != null && !params.getStarName().equals("")) {boolQuery.filter(QueryBuilders.termQuery("starName", params.getStarName()));}// 6.价格if (params.getMinPrice() != null && params.getMaxPrice() != null) {boolQuery.filter(QueryBuilders.rangeQuery("price").gte(params.getMinPrice()).lte(params.getMaxPrice()));}// 7.放入sourcerequest.source().query(boolQuery);
}
4.3.我周边的酒店
需求:我附近的酒店
4.3.1.需求分析
在酒店列表页的右侧,有一个小地图,点击地图的定位按钮,地图会找到你所在的位置:
并且,在前端会发起查询请求,将你的坐标发送到服务端:
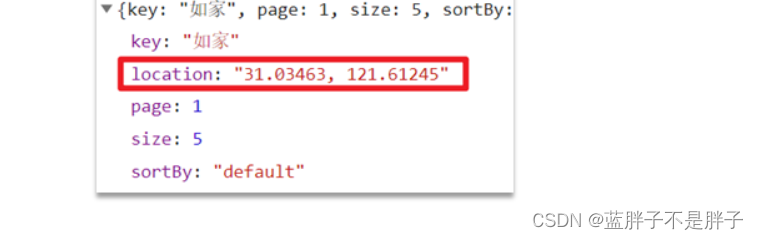
我们要做的事情就是基于这个location坐标,然后按照距离对周围酒店排序。实现思路如下:
- 修改RequestParams参数,接收location字段
- 修改search方法业务逻辑,如果location有值,添加根据geo_distance排序的功能
4.3.2.修改实体类
修改在cn.itcast.hotel.pojo包下的实体类RequestParams:
package cn.itcast.hotel.pojo;import lombok.Data;@Data
public class RequestParams {private String key;private Integer page;private Integer size;private String sortBy;private String city;private String brand;private String starName;private Integer minPrice;private Integer maxPrice;// 我当前的地理坐标private String location;
}4.3.3.距离排序API
我们以前学习过排序功能,包括两种:
- 普通字段排序
- 地理坐标排序
我们只讲了普通字段排序对应的java写法。地理坐标排序只学过DSL语法,如下:
GET /indexName/_search
{"query": {"match_all": {}},"sort": [{"price": "asc" },{"_geo_distance" : {"FIELD" : "纬度,经度","order" : "asc","unit" : "km"}}]
}
4.3.4.添加距离排序
在cn.itcast.hotel.service.impl的HotelService的search方法中,添加一个排序功能:
完整代码:
@Override
public PageResult search(RequestParams params) {try {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备DSL// 2.1.querybuildBasicQuery(params, request);// 2.2.分页int page = params.getPage();int size = params.getSize();request.source().from((page - 1) * size).size(size);// 2.3.排序String location = params.getLocation();if (location != null && !location.equals("")) {request.source().sort(SortBuilders.geoDistanceSort("location", new GeoPoint(location)).order(SortOrder.ASC).unit(DistanceUnit.KILOMETERS));}// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应return handleResponse(response);} catch (IOException e) {throw new RuntimeException(e);}
}
4.3.5.排序距离显示
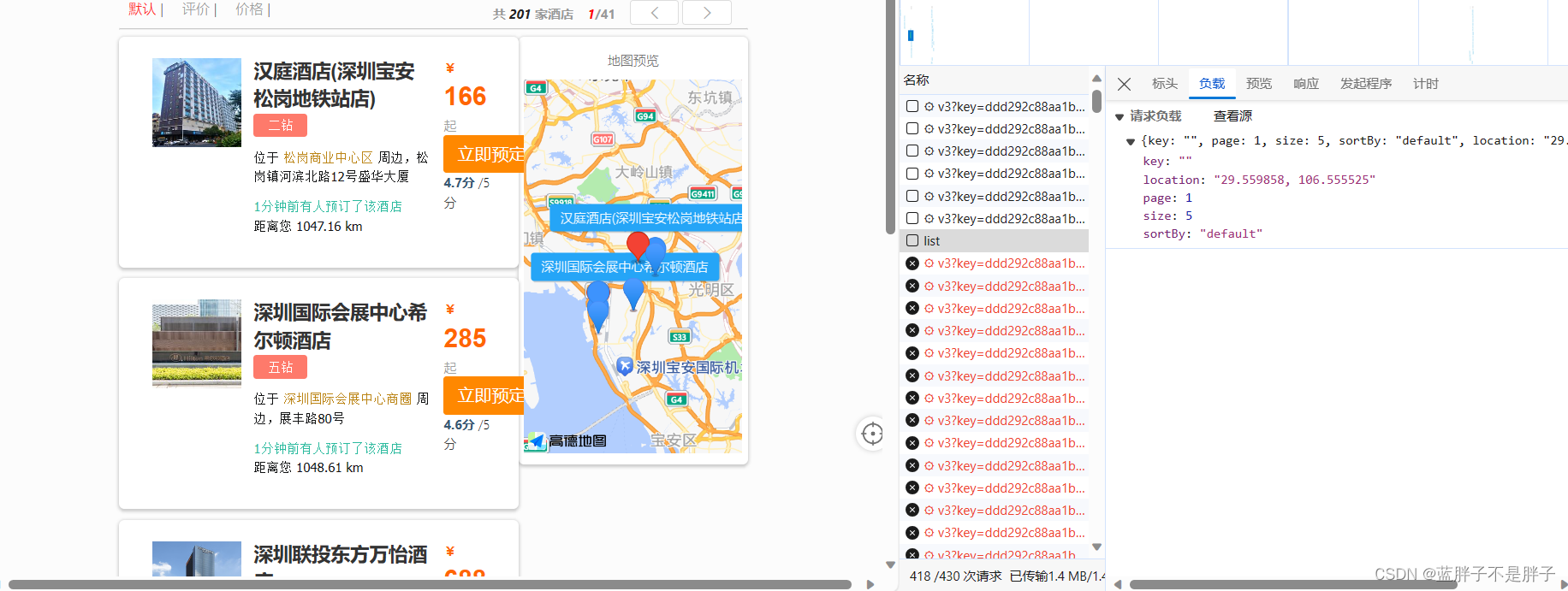
重启服务后,测试我的酒店功能:
发现确实可以实现对我附近酒店的排序,不过并没有看到酒店到底距离我多远,这该怎么办?
排序完成后,页面还要获取我附近每个酒店的具体距离值,这个值在响应结果中是独立的:
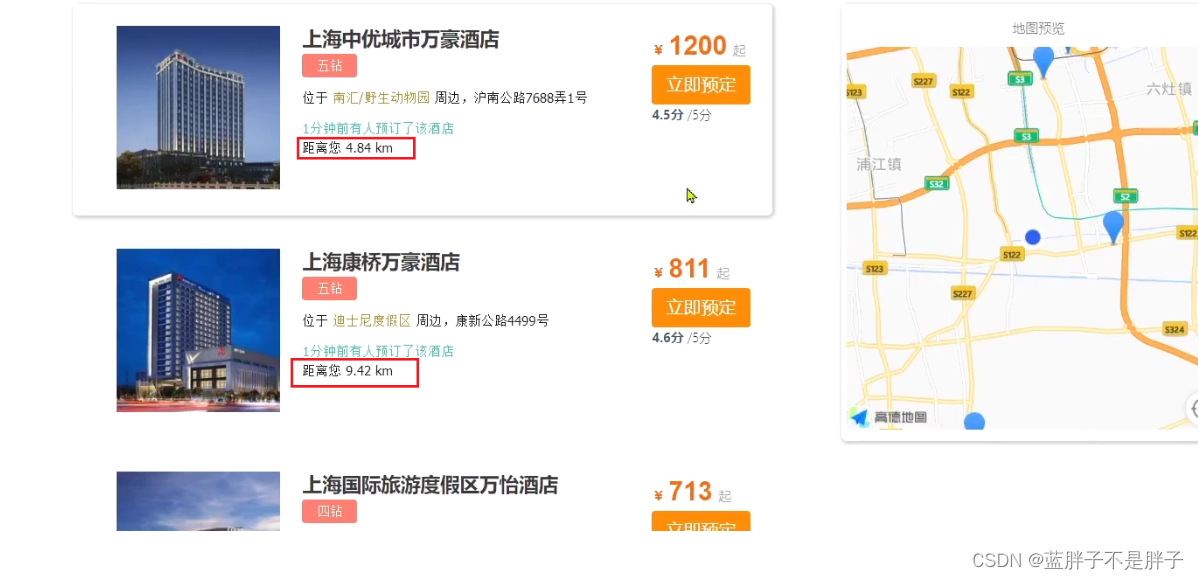
因此,我们在结果解析阶段,除了解析source部分以外,还要得到sort部分,也就是排序的距离,然后放到响应结果中。
我们要做两件事:
- 修改HotelDoc,添加排序距离字段,用于页面显示
- 修改HotelService类中的handleResponse方法,添加对sort值的获取
1)修改HotelDoc类,添加距离字段
package cn.itcast.hotel.pojo;import lombok.Data;
import lombok.NoArgsConstructor;@Data
@NoArgsConstructor
public class HotelDoc {private Long id;private String name;private String address;private Integer price;private Integer score;private String brand;private String city;private String starName;private String business;private String location;private String pic;// 排序时的 距离值private Object distance;public HotelDoc(Hotel hotel) {this.id = hotel.getId();this.name = hotel.getName();this.address = hotel.getAddress();this.price = hotel.getPrice();this.score = hotel.getScore();this.brand = hotel.getBrand();this.city = hotel.getCity();this.starName = hotel.getStarName();this.business = hotel.getBusiness();this.location = hotel.getLatitude() + ", " + hotel.getLongitude();this.pic = hotel.getPic();}
}2)修改HotelService中的handleResponse方法
private PageResult handleResponse(SearchResponse response) {// 4.解析响应SearchHits searchHits = response.getHits();// 4.1.获取总条数long total = searchHits.getTotalHits().value;// 4.2.文档数组SearchHit[] hits = searchHits.getHits();// 4.3.遍历List<HotelDoc> list = Arrays.stream(hits).map(i -> {HotelDoc doc = JSON.parseObject(i.getSourceAsString(), HotelDoc.class);if (i.getSortValues().length!=0) {doc.setDistance(i.getSortValues()[0]); }return doc;}).collect(Collectors.toList());// 4.4.封装返回return new PageResult(total, list);
}
因为排序可能是多个字段排序,所以排序返回的对象是个数组、
这个sort值对应dsl中的sort
重启后测试,发现页面能成功显示距离了:
4.4.酒店竞价排名
需求:让指定的酒店在搜索结果中排名置顶
4.4.1.需求分析
要让指定酒店在搜索结果中排名置顶,效果如图:
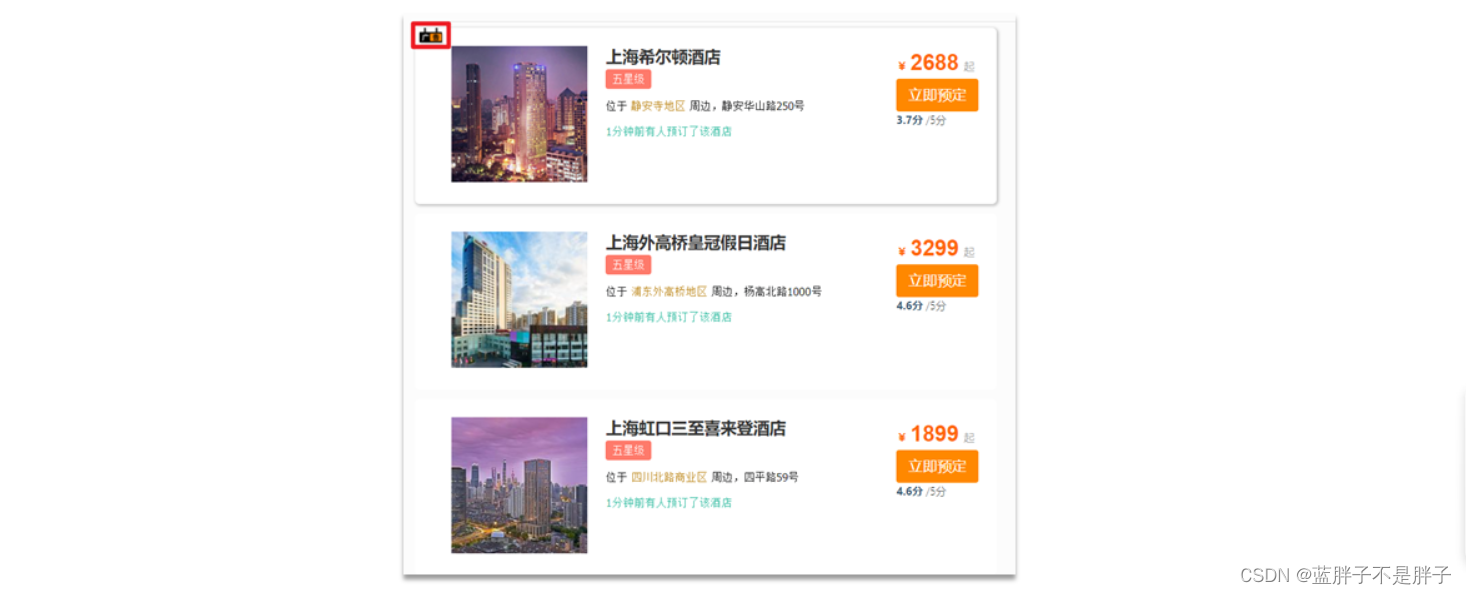
页面会给指定的酒店添加广告标记。
那怎样才能让指定的酒店排名置顶呢?
之前学习过的function_score查询可以影响算分,算分高了,自然排名也就高了。而function_score包含3个要素:
- 过滤条件:哪些文档要加分
- 算分函数:如何计算function score
- 加权方式:function score 与 query score如何运算
这里的需求是:让指定酒店(比如付费加盟)排名靠前。因此我们需要给这些酒店添加一个标记,这样在过滤条件中就可以根据这个标记来判断,是否要提高算分。
比如,我们给酒店添加一个字段:isAD,Boolean类型:
- true:是广告
- false:不是广告
这样function_score包含3个要素就很好确定了:
- 过滤条件:判断isAD 是否为true
- 算分函数:我们可以用最简单暴力的weight,固定加权值
- 加权方式:可以用默认的相乘,大大提高算分
因此,业务的实现步骤包括:
-
给HotelDoc类添加isAD字段,Boolean类型
-
挑选几个你喜欢的酒店,给它的文档数据添加isAD字段,值为true
-
修改search方法,添加function score功能,给isAD值为true的酒店增加权重
4.4.2.修改HotelDoc实体
给cn.itcast.hotel.pojo包下的HotelDoc类添加isAD字段:
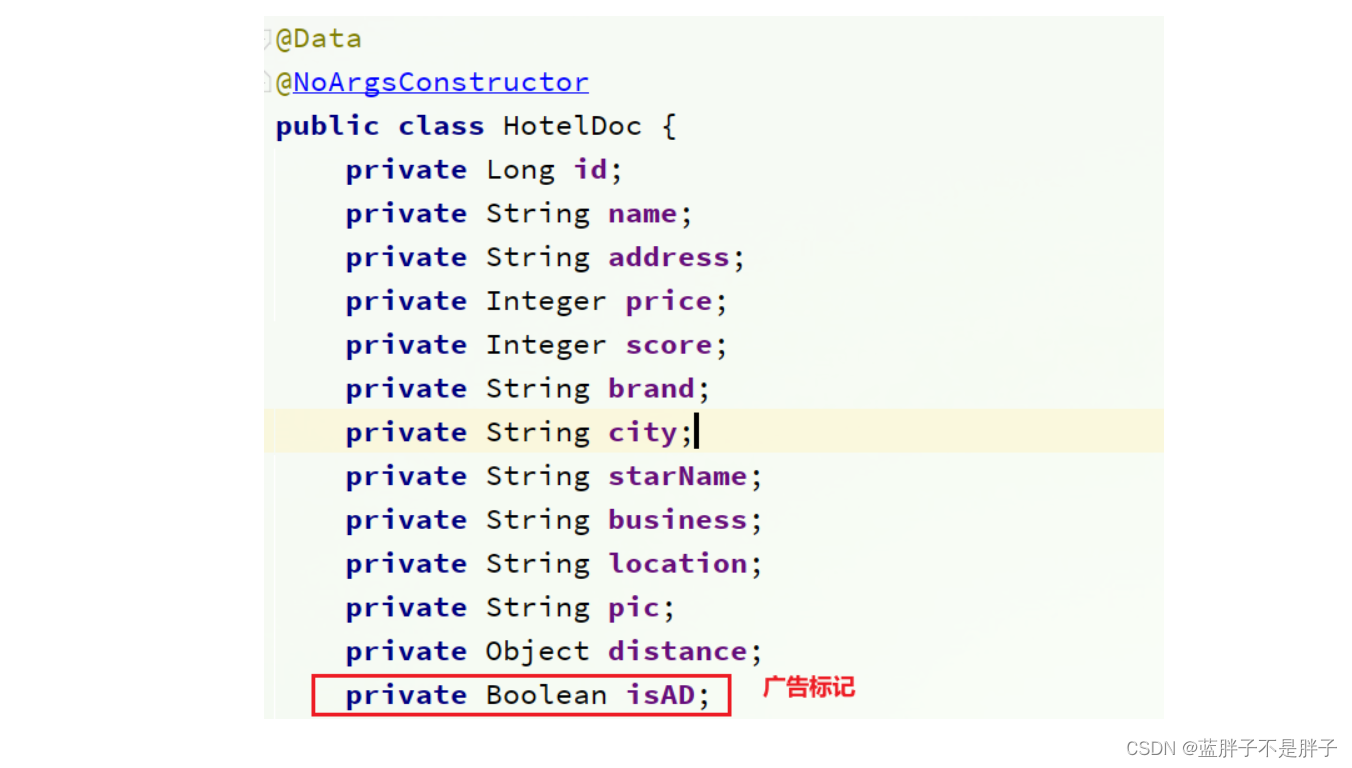
4.4.3.添加广告标记
接下来,我们挑几个酒店,添加isAD字段,设置为true:
POST /hotel/_update/1902197537
{"doc": {"isAD": true}
}
POST /hotel/_update/2056126831
{"doc": {"isAD": true}
}
POST /hotel/_update/1989806195
{"doc": {"isAD": true}
}
POST /hotel/_update/2056105938
{"doc": {"isAD": true}
}
结果
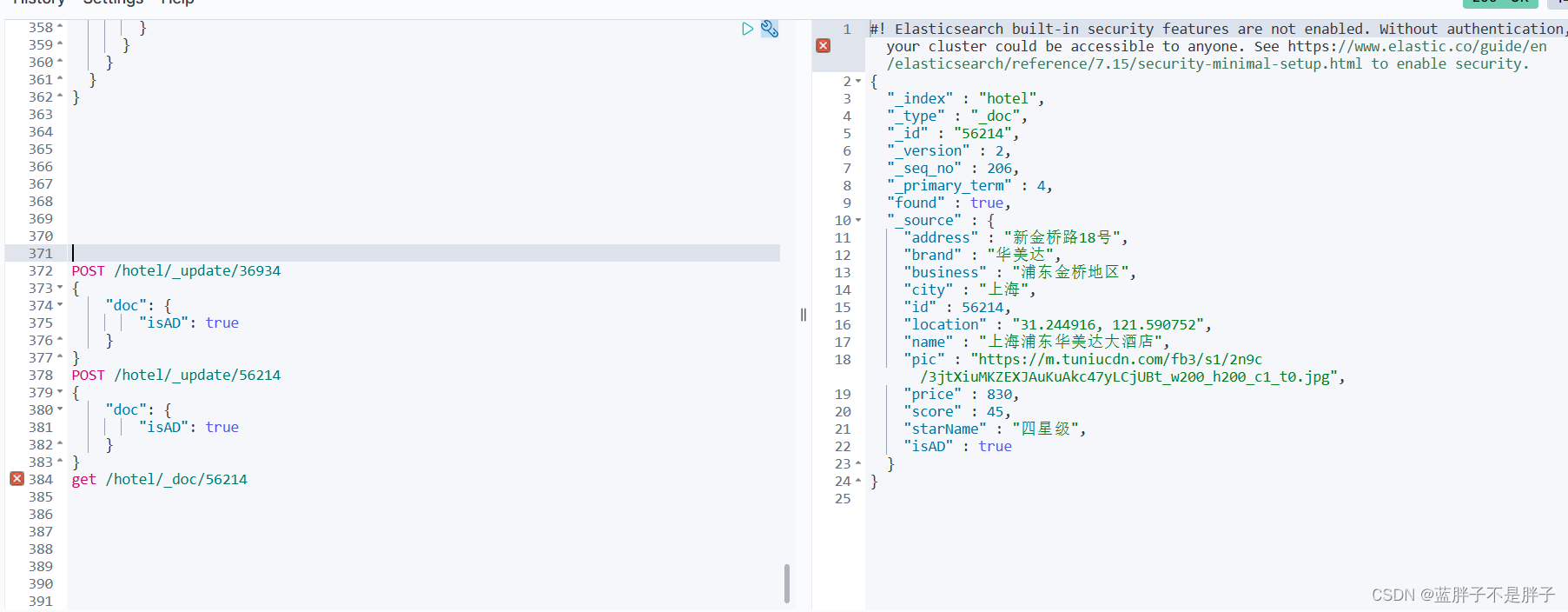
添加成功
4.4.4.添加算分函数查询
接下来我们就要修改查询条件了。之前是用的boolean 查询,现在要改成function_socre查询。
function_score查询结构如下:
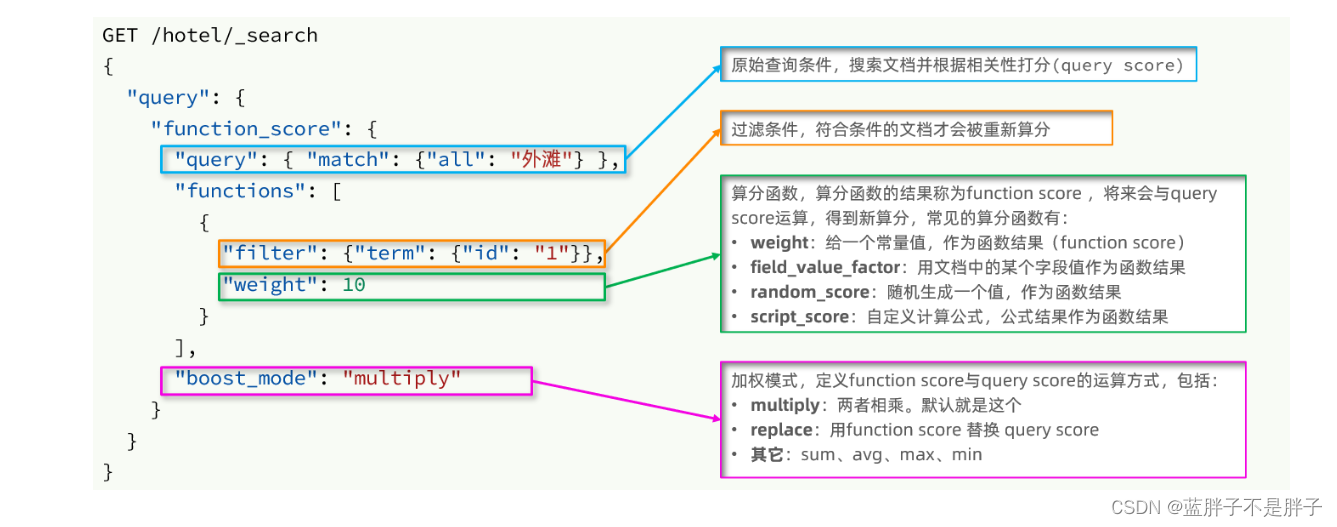
对应的JavaAPI如下:

我们可以将之前写的boolean查询作为原始查询条件放到query中,接下来就是添加过滤条件、算分函数、加权模式了。所以原来的代码依然可以沿用。
修改cn.itcast.hotel.service.impl包下的HotelService类中的buildBasicQuery方法,添加算分函数查询:
private void buildBasicQuery(RequestParams params, SearchRequest request) {// 1.构建BooleanQueryBoolQueryBuilder boolQuery = QueryBuilders.boolQuery();// 关键字搜索String key = params.getKey();if (key == null || "".equals(key)) {boolQuery.must(QueryBuilders.matchAllQuery());} else {boolQuery.must(QueryBuilders.matchQuery("all", key));}// 城市条件if (params.getCity() != null && !params.getCity().equals("")) {boolQuery.filter(QueryBuilders.termQuery("city", params.getCity()));}// 品牌条件if (params.getBrand() != null && !params.getBrand().equals("")) {boolQuery.filter(QueryBuilders.termQuery("brand", params.getBrand()));}// 星级条件if (params.getStarName() != null && !params.getStarName().equals("")) {boolQuery.filter(QueryBuilders.termQuery("starName", params.getStarName()));}// 价格if (params.getMinPrice() != null && params.getMaxPrice() != null) {boolQuery.filter(QueryBuilders.rangeQuery("price").gte(params.getMinPrice()).lte(params.getMaxPrice()));}// 2.算分控制FunctionScoreQueryBuilder functionScoreQuery =QueryBuilders.functionScoreQuery(// 原始查询,相关性算分的查询boolQuery,// function score的数组new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{// 其中的一个function score 元素new FunctionScoreQueryBuilder.FilterFunctionBuilder(// 过滤条件QueryBuilders.termQuery("isAD", true),// 算分函数ScoreFunctionBuilders.weightFactorFunction(10))});request.source().query(functionScoreQuery);
}
分布式搜索引擎03
1.数据聚合
**聚合(aggregations)**可以让我们极其方便的实现对数据的统计、分析、运算。例如:
- 什么品牌的手机最受欢迎?
- 这些手机的平均价格、最高价格、最低价格?
- 这些手机每月的销售情况如何?
这些需求就像msql中的max,average,等只是mysql是根据分组实现,而es根据数据桶,实现这些统计功能的比数据库的sql要方便的多,而且查询速度非常快,可以实现近实时搜索效果。
1.1.聚合的种类
聚合常见的有三类:
-
**桶(Bucket)**聚合:用来对文档做分组
- TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组
- Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
-
**度量(Metric)**聚合:用以计算一些值,比如:最大值、最小值、平均值等
- Avg:求平均值
- Max:求最大值
- Min:求最小值
- Stats:同时求max、min、avg、sum等
-
**管道(pipeline)**聚合:其它聚合的结果为基础做聚合
**注意:**参加聚合的字段必须是keyword、日期、数值、布尔类型 不能进行分词的数据,可以分词的文本数据无法聚合

1.2.DSL实现聚合
现在,我们要统计所有数据中的酒店品牌有几种,其实就是按照品牌对数据分组。此时可以根据酒店品牌的名称做聚合,也就是Bucket聚合。
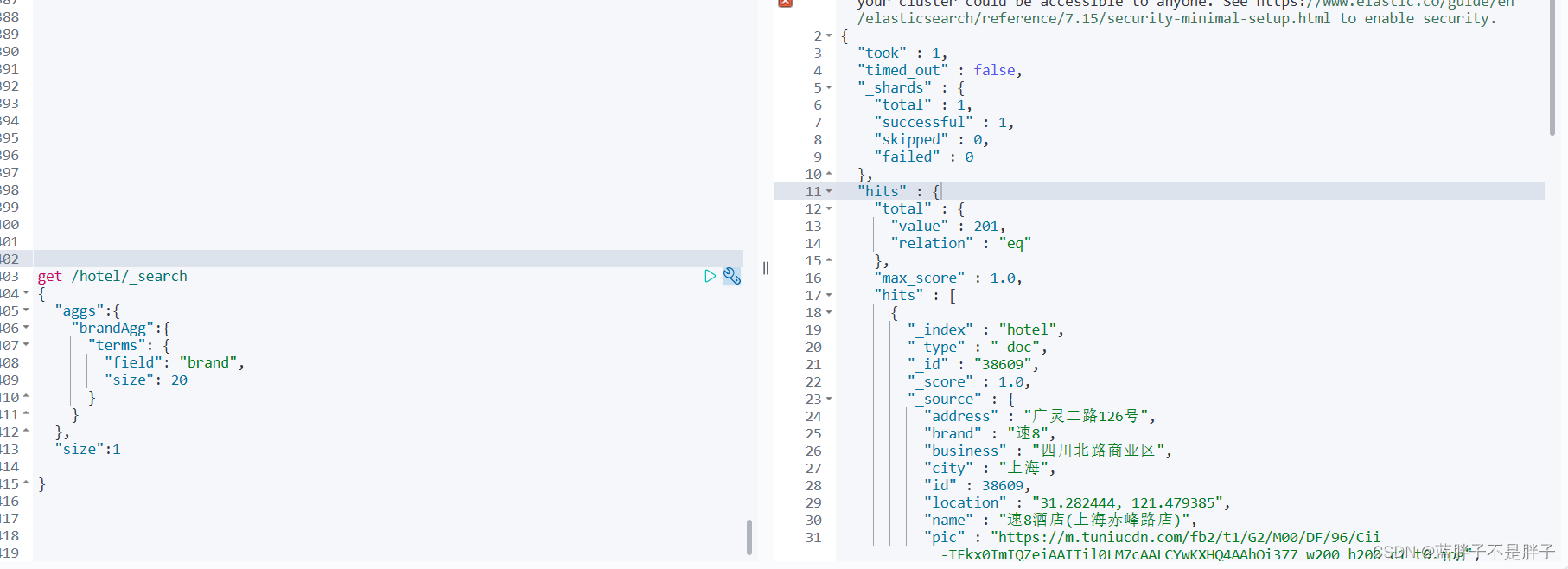
1.2.1.Bucket聚合语法
聚合和query同级别,dsl卸载dsl的第一层和query,size,sort等同一深度
语法如下:
GET /hotel/_search
{"size": 0, // 设置size为0,结果中不包含命中的文档,只包含聚合结果"aggs": { // 定义聚合"brandAgg": { //给聚合起个名字"terms": { // 聚合的类型,按照品牌值聚合,所以选择term"field": "brand", // 参与聚合的字段"size": 20 // 希望获取的聚合结果数量}}}
}
结果如图:
1.2.2.聚合结果排序
默认情况下,Bucket聚合会统计Bucket内的文档数量,记为_count,并且按照_count降序排序。
我们可以指定order属性,自定义聚合的排序方式:
GET /hotel/_search
{"size": 0, "aggs": {"brandAgg": {"terms": {"field": "brand","order": {"_count": "asc" // 按照_count升序排列},"size": 20}}}
}
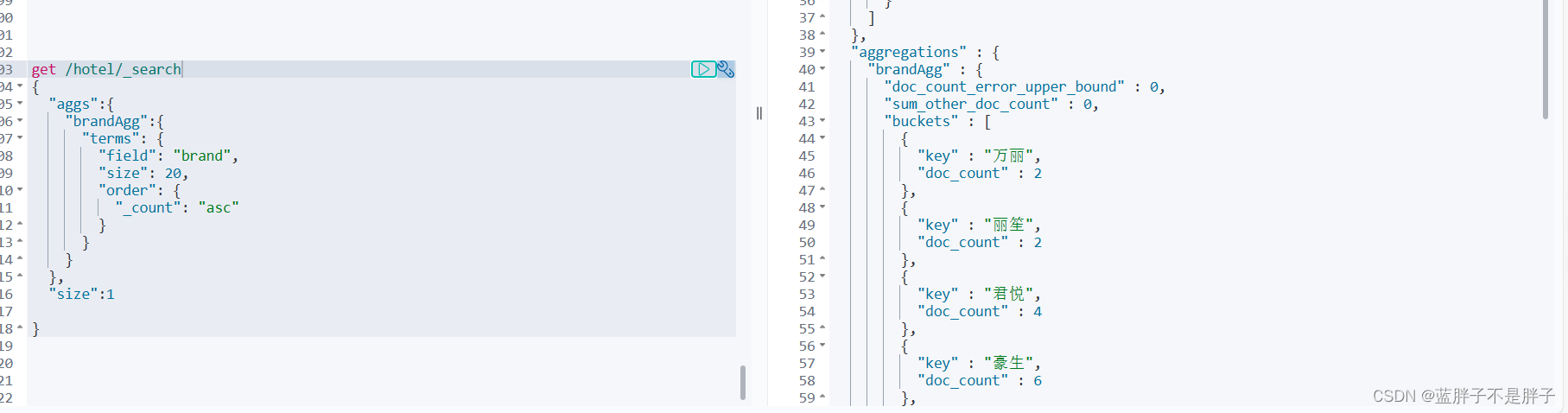
这里因为聚合的字段中的key是文本,无法排序,只能对count排序
1.2.3.限定聚合范围
默认情况下,Bucket聚合是对索引库的所有文档做聚合,但真实场景下,用户会输入搜索条件,因此聚合必须是对搜索结果聚合。那么聚合必须添加限定条件。
我们可以限定要聚合的文档范围,只要添加query条件即可:
GET /hotel/_search
{"query": {"range": {"price": {"lte": 200 // 只对200元以下的文档聚合}}}, "size": 0, "aggs": {"brandAgg": {"terms": {"field": "brand","size": 20}}}
}
这次,聚合得到的品牌明显变少了:
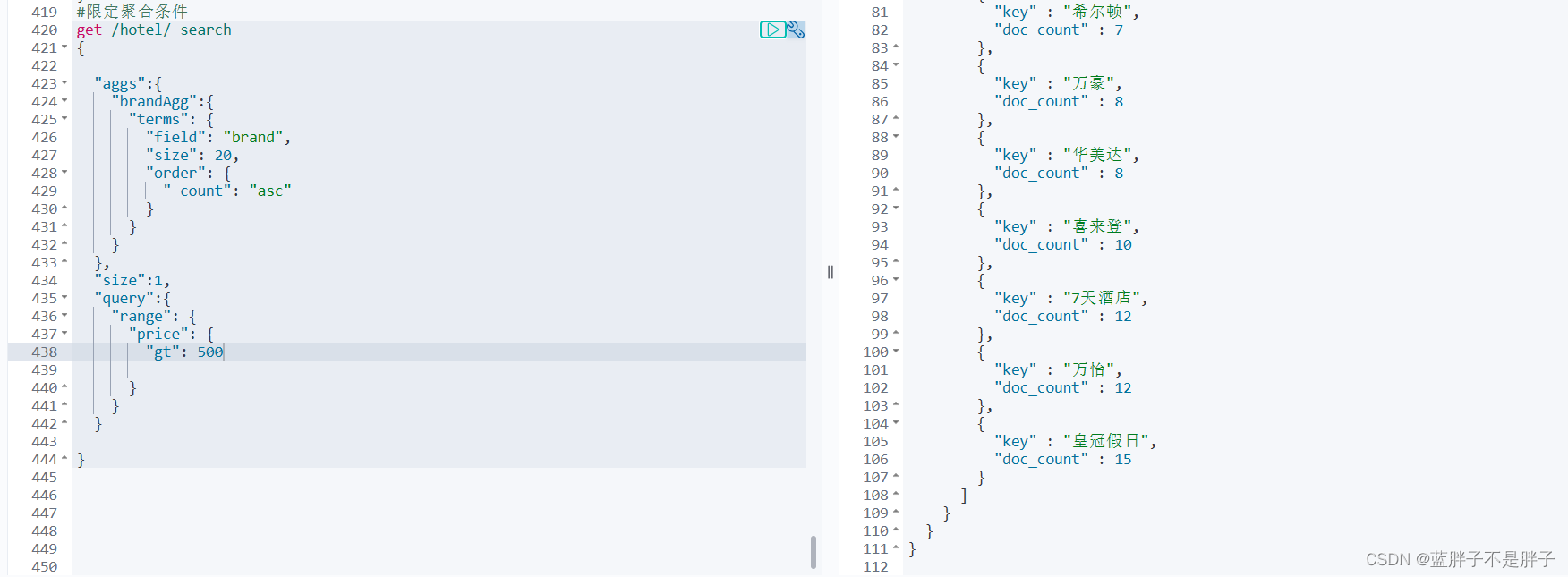
1.2.4.Metric聚合语法
之前我们对酒店按照品牌分组,形成了一个个桶。现在我们需要对桶内的酒店做运算,获取每个品牌的用户评分的min、max、avg等值。
这就要用到Metric聚合了,例如stat聚合:就可以获取min、max、avg等结果。
语法如下:
GET /hotel/_search
{"size": 0, "aggs": {//对品牌做聚合"brandAgg": { "terms": { "field": "brand", "size": 20},"aggs": { // 是brands聚合的子聚合,也就是分组后对每组分别计算"score_stats": { // 聚合名称"stats": { // 聚合类型,这里stats可以计算min、max、avg等"field": "score" // 聚合字段,这里是score}}}}}
}
这次的score_stats聚合是在brandAgg的聚合内部嵌套的子聚合。因为我们需要在每个桶分别计算。
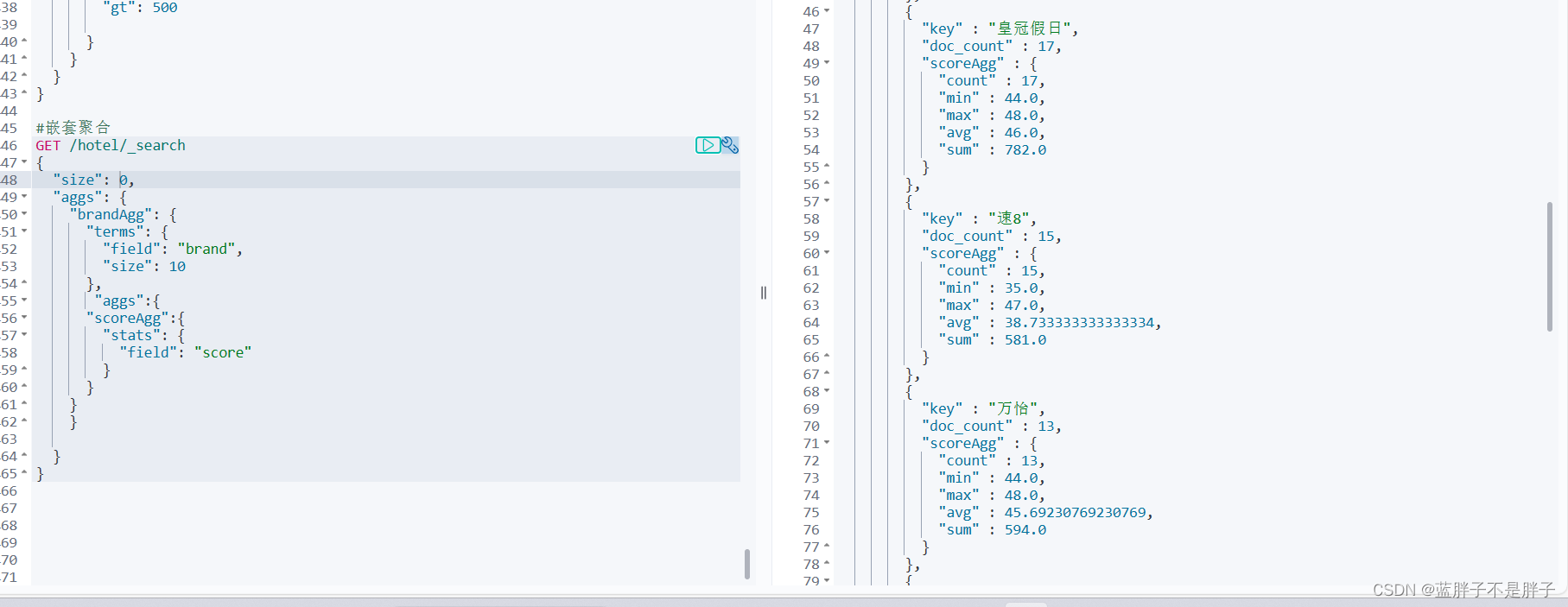
返回的桶和dsl语句中写的一样,
brandagg中包含了socreAgge,此时可以指定除了_count数量字段来排序了

另外,我们还可以给聚合结果做个排序,例如按照每个桶的酒店平均分做排序:
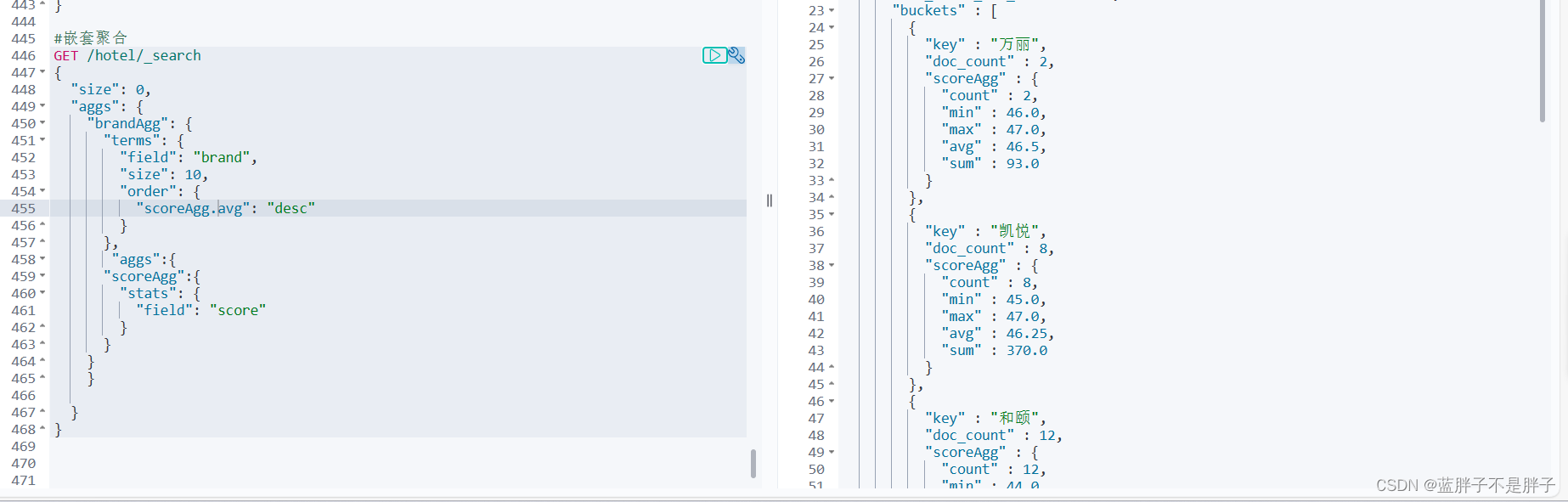
1.2.5.小结
aggs代表聚合,与query同级,此时query的作用是?
在 Elasticsearch 的 DSL 查询语言中,query 和 aggs(或者叫做 aggregations)是两个主要的组成部分,它们在很多查询场景下都会一起使用。它们的作用分别是:
1.query:
2.这部分定义了如何筛选文档。它指明了哪些文档应被认为是满足查询条件的,因此会被包括在结果集中。
3.query 定义的条件决定了哪些文档应当进入后续的聚合操作。
4.这部分不仅决定了哪些文档会被返回,而且对那些文档进行了评分。评分通常基于文档与查询的匹配程度,以及其他因素。
5.aggs or aggregations:
6.这部分定义了聚合操作。聚合操作可以理解为对一组文档进行一定的统计操作,比如计数、求和、求平均值等。
7.聚合操作通常用于生成桶(buckets)
总结聚合操作中,query作用类似于过滤,只对query检索出来的聚合
- 限定聚合的的文档范围
聚合必须的三要素:
- 聚合名称
- 聚合类型
- 聚合字段
聚合可配置属性有:
- size:指定聚合结果数量
- order:指定聚合结果排序方式
- field:指定聚合字段
1.3.RestAPI实现聚合
1.3.1.API语法
聚合条件与query条件同级别,因此需要使用request.source()来指定聚合条件。
聚合条件的语法:
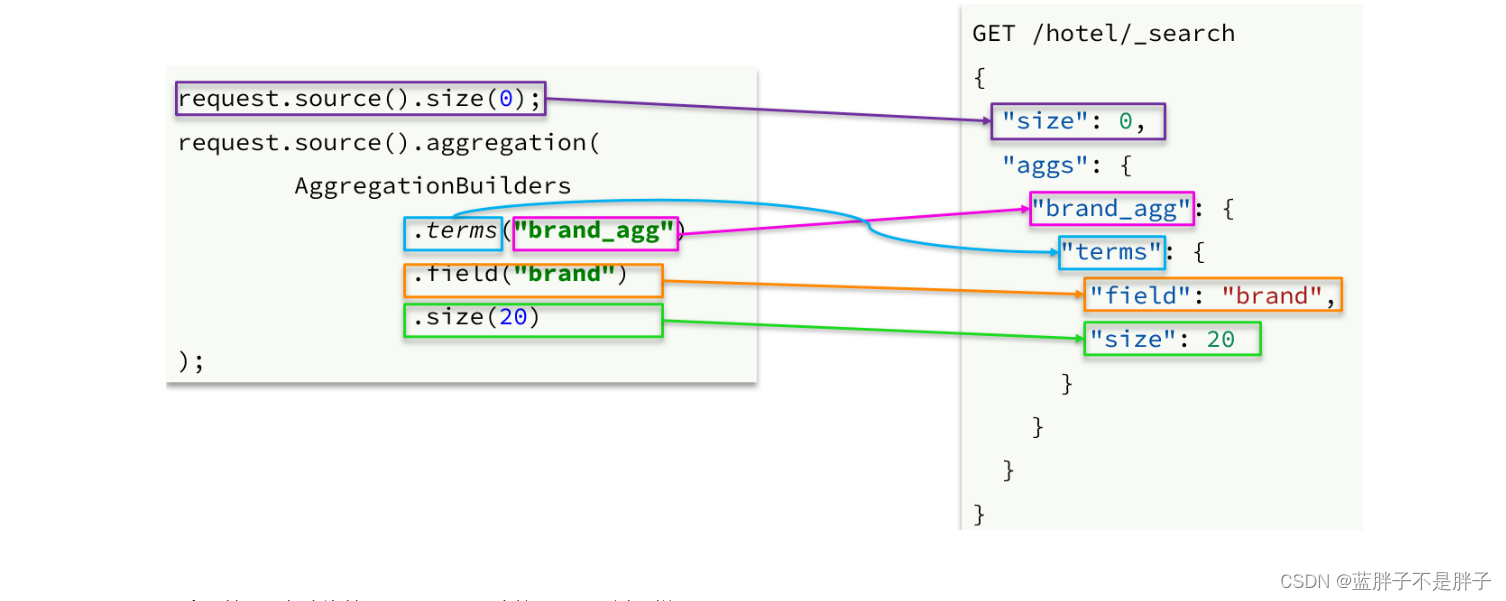
聚合的java客户端的区别只不同在于java客户端是链式编程来设置对象体的内容
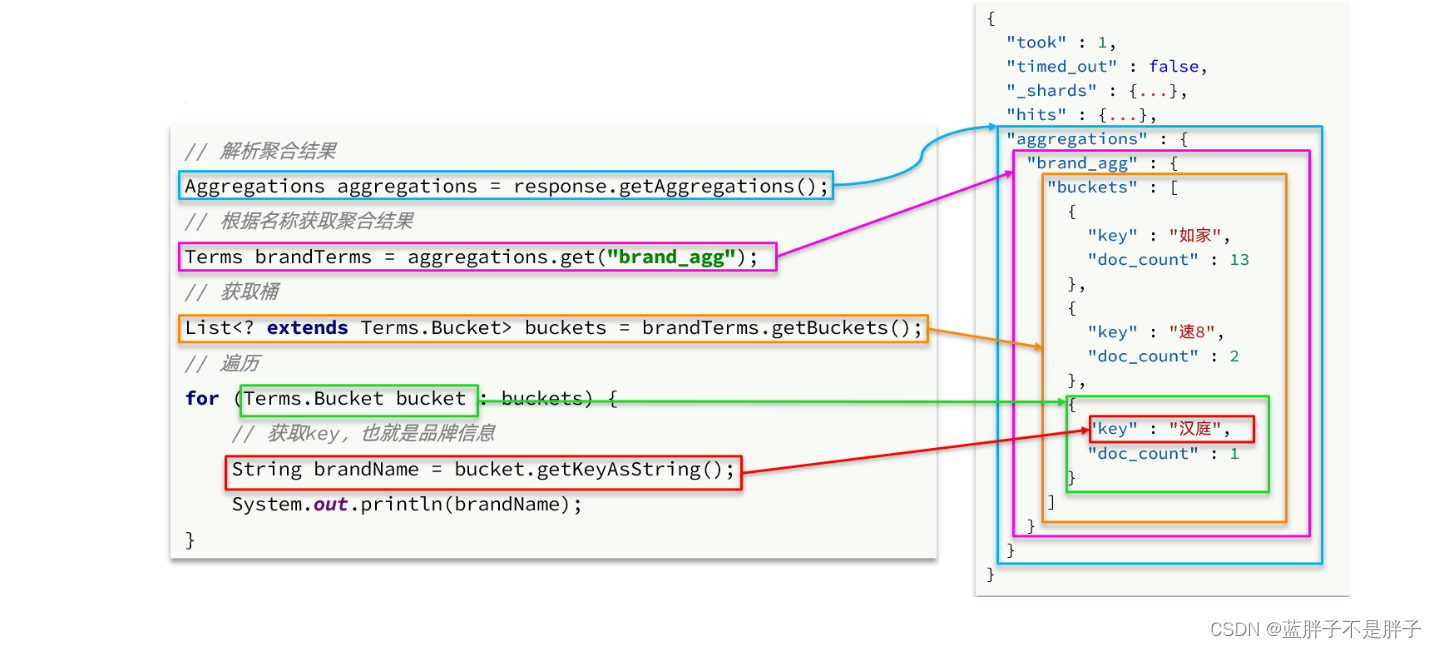
聚合的结果也与查询结果不同,API也比较特殊。不过同样是JSON逐层解析:
完整代码
@Test@DisplayName("测试聚合处理")void testAggQuery() throws IOException {SearchRequest request = new SearchRequest("hotel");//聚合的名字是自己取得这里我取名交品牌桶request.source().aggregation(AggregationBuilders.terms("brandBuckt").field("brand").size(10).order(BucketOrder.aggregation("_count",false)) //不采用升序 使用默认降序//聚合10条);
// 不返回命中数据request.source().size(0);SearchResponse response = client.search(request, RequestOptions.DEFAULT);Aggregations responseAggregations = response.getAggregations();//获取对应什么类型的聚合Terms buckt = responseAggregations.get("brandBuckt");List<? extends Terms.Bucket> buckets = buckt.getBuckets();buckets.stream().forEach(i-> System.out.println("品牌:"+i.getKey()+" 数量:"+i.getDocCount()));}
结果如下
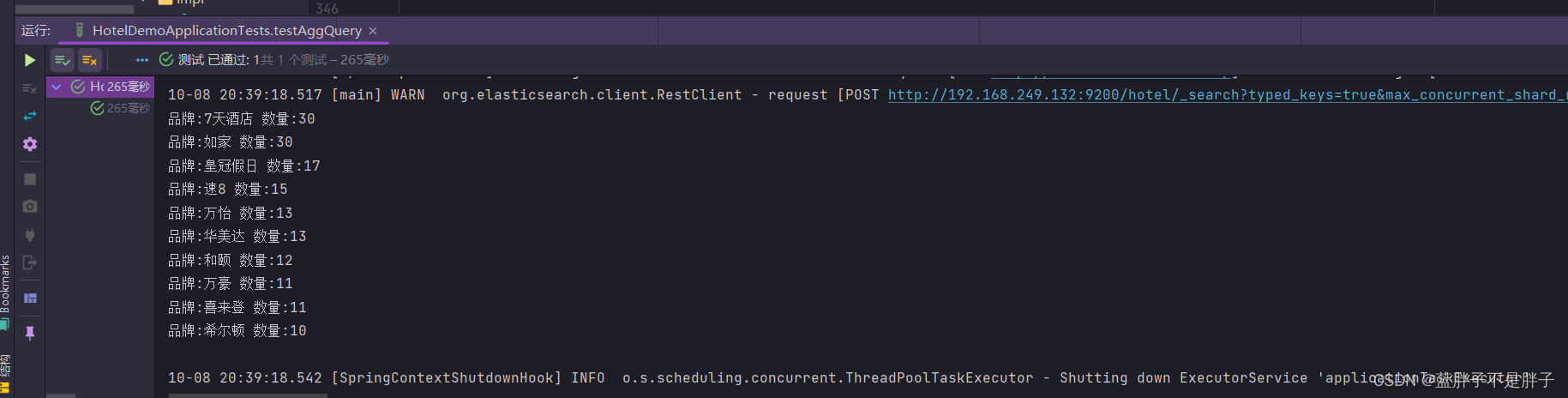
能和web页面返回的数据对应上 说明测试成功
1.3.2.业务需求
在实际开发中,检索的条件的都是动态赋予的,如果写死了,数据库数据发生改变那么检索条件就会失效
搜索页面的品牌、城市等信息不应该是在页面写死,而是通过聚合索引库中的酒店数据得来的:
分析:
目前,页面的城市列表、星级列表、品牌列表都是写死的,并不会随着搜索结果的变化而变化。但是用户搜索条件改变时,搜索结果会跟着变化。
例如:用户搜索“东方明珠”,那搜索的酒店肯定是在上海东方明珠附近,因此,城市只能是上海,此时城市列表中就不应该显示北京、深圳、杭州这些信息了。
也就是说,搜索结果中包含哪些城市,页面就应该列出哪些城市;搜索结果中包含哪些品牌,页面就应该列出哪些品牌。
如何得知搜索结果中包含哪些品牌?如何得知搜索结果中包含哪些城市?
使用聚合功能,利用Bucket聚合,对搜索结果中的文档基于品牌分组、基于城市分组,就能得知包含哪些品牌、哪些城市了。
因为是对搜索结果聚合,因此聚合是限定范围的聚合,也就是说聚合的限定条件跟搜索文档的条件一致。
查看浏览器可以发现,前端其实已经发出了这样的一个请求:
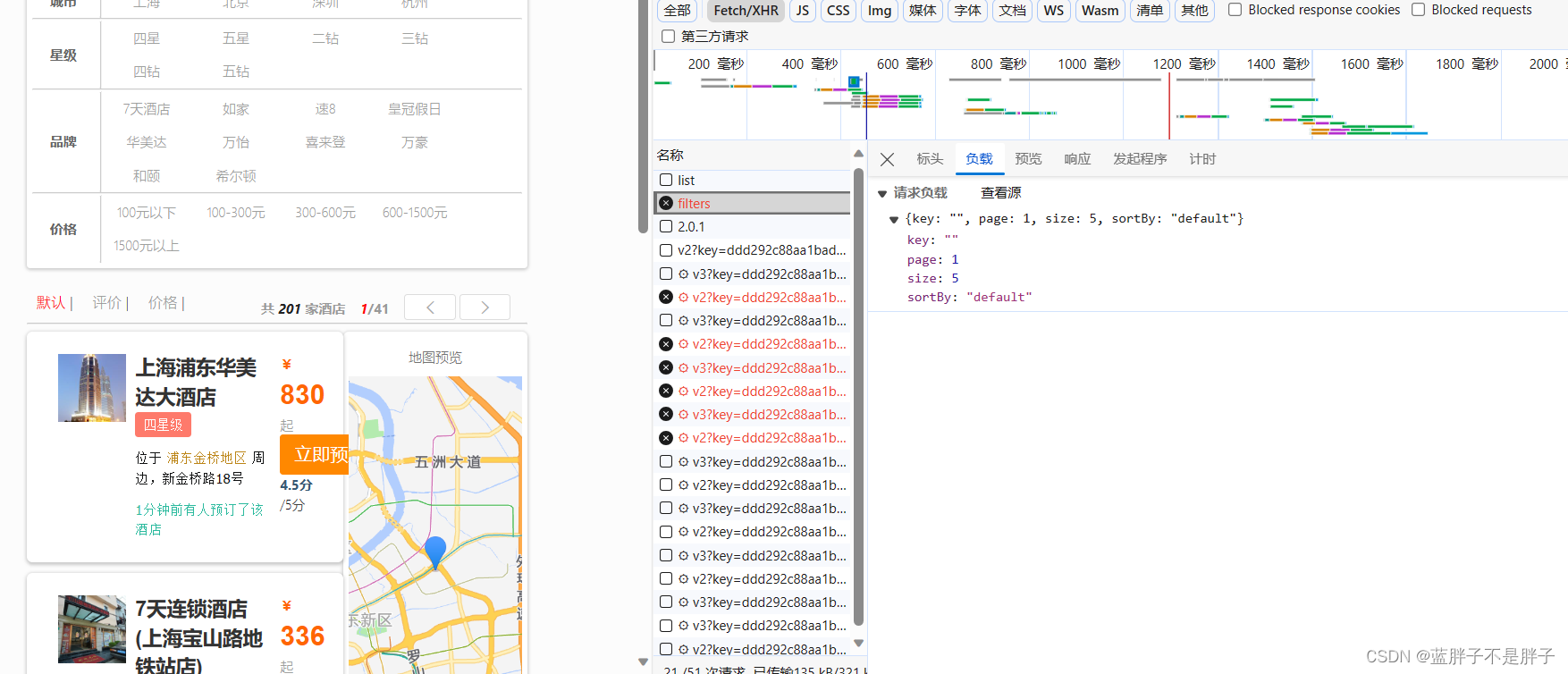
请求参数与搜索文档的参数完全一致。
返回值类型就是页面要展示的最终结果,这样也便于前端页面的读取渲染:
结果是一个Map结构:
- key是字符串,城市、星级、品牌、价格
- value是集合,例如多个城市的名称
1.3.3.业务实现
在cn.itcast.hotel.web包的HotelController中添加一个方法,遵循下面的要求:
- 请求方式:
POST - 请求路径:
/hotel/filters - 请求参数:
RequestParams,与搜索文档的参数一致 - 返回值类型:
Map<String, List<String>>
代码:
@PostMapping("filters")public Map<String, List<String>> getFilters(@RequestBody RequestParams params){return hotelService.getFilters(params);}
这里调用了IHotelService中的getFilters方法,尚未实现。
在cn.itcast.hotel.service.IHotelService中定义新方法:
Map<String, List<String>> filters(RequestParams params);
在cn.itcast.hotel.service.impl.HotelService中实现该方法:
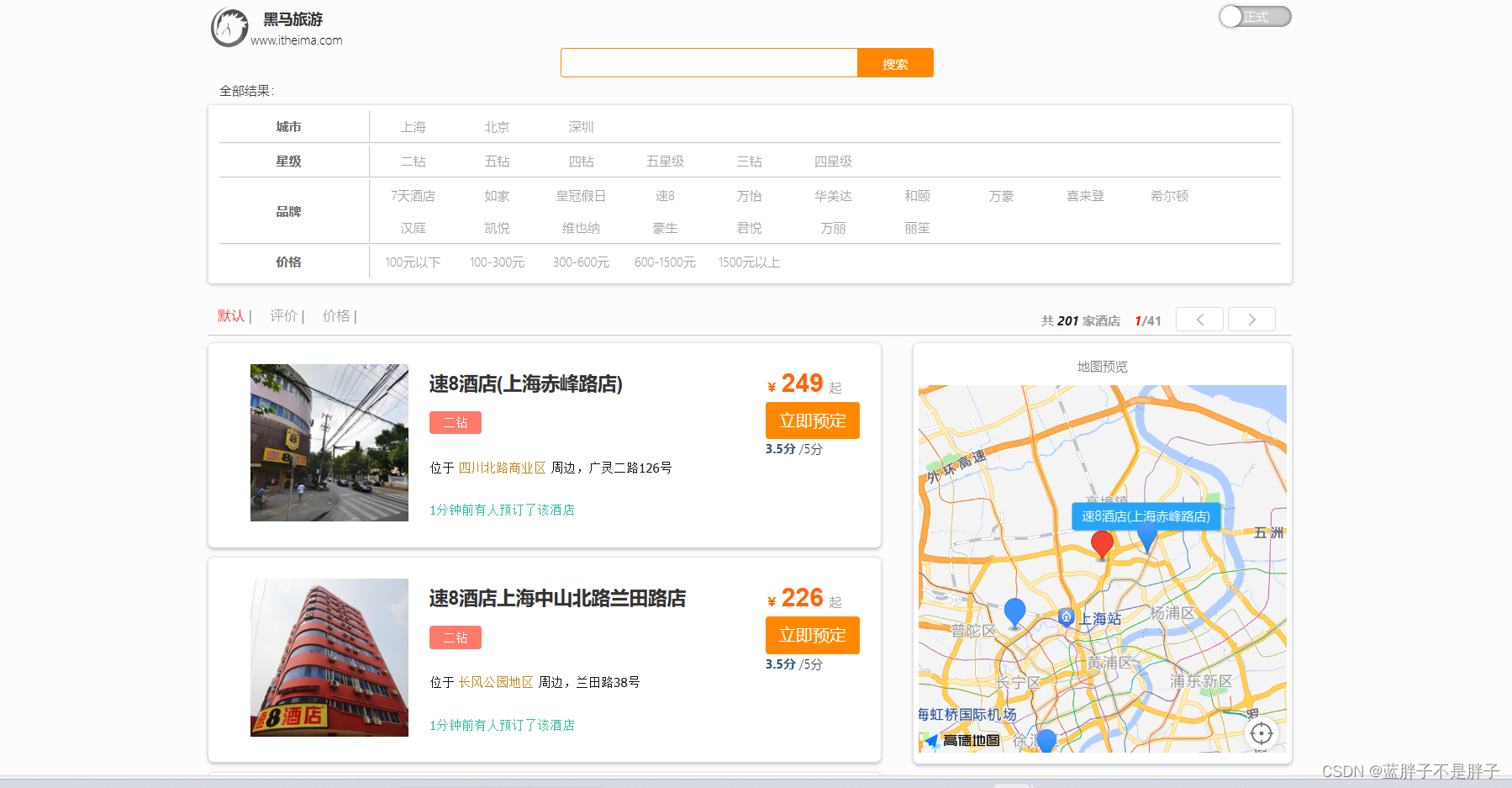
@Overridepublic Map<String, List<String>> filters(RequestParams requestParam) {SearchRequest request = new SearchRequest("hotel");try {
// 开始聚合 品牌request.source().aggregation(AggregationBuilders.terms("brandAggr").field("brand").size(30));request.source().aggregation(AggregationBuilders.terms("starNameAggr").field("starName").size(30));request.source().aggregation(AggregationBuilders.terms("CityAggr").field("city").size(30));SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 获取聚合对象Aggregations aggregations = response.getAggregations();// 从聚合对象中读取对应聚合数据Terms brandAggr = aggregations.get("brandAggr");Terms starNameAggr = aggregations.get("starNameAggr");Terms CityAggr = aggregations.get("CityAggr");List<String> Brandlist = brandAggr.getBuckets().stream().map(i -> i.getKeyAsString()).collect(Collectors.toList());List<String> starNamelist = starNameAggr.getBuckets().stream().map(i -> i.getKeyAsString()).collect(Collectors.toList());List<String> citylist = CityAggr.getBuckets().stream().map(i -> i.getKeyAsString()).collect(Collectors.toList());Map<String,List<String>> map=new HashMap<String,List<String>>();map.put("starName",starNamelist);map.put("city",citylist);map.put("brand",Brandlist);
return map;} catch (IOException e) {throw new RuntimeException(e);}}值得注意的是,这里初始化页面时候做聚合是为了能动态展示分类条件,所以在做聚合的时候不需要对数据过滤(query),而是所有数据来聚合出brand,city等检索条件返回给前端,效果如图
当我们动态搜索时候,输入检索需要分词的文本后,我们的过滤检索词条都应该查找的内容变化,所以这个时候需要对聚合过滤
在之前的代码块基础上添加条件即可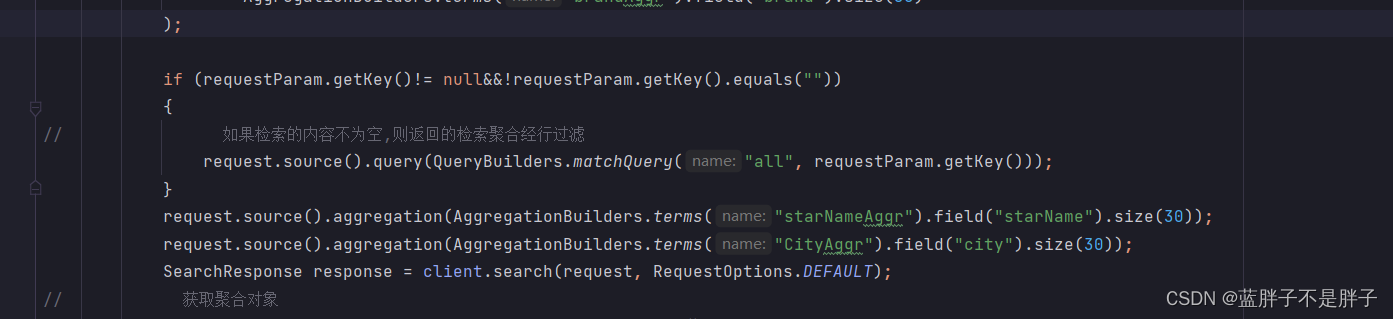
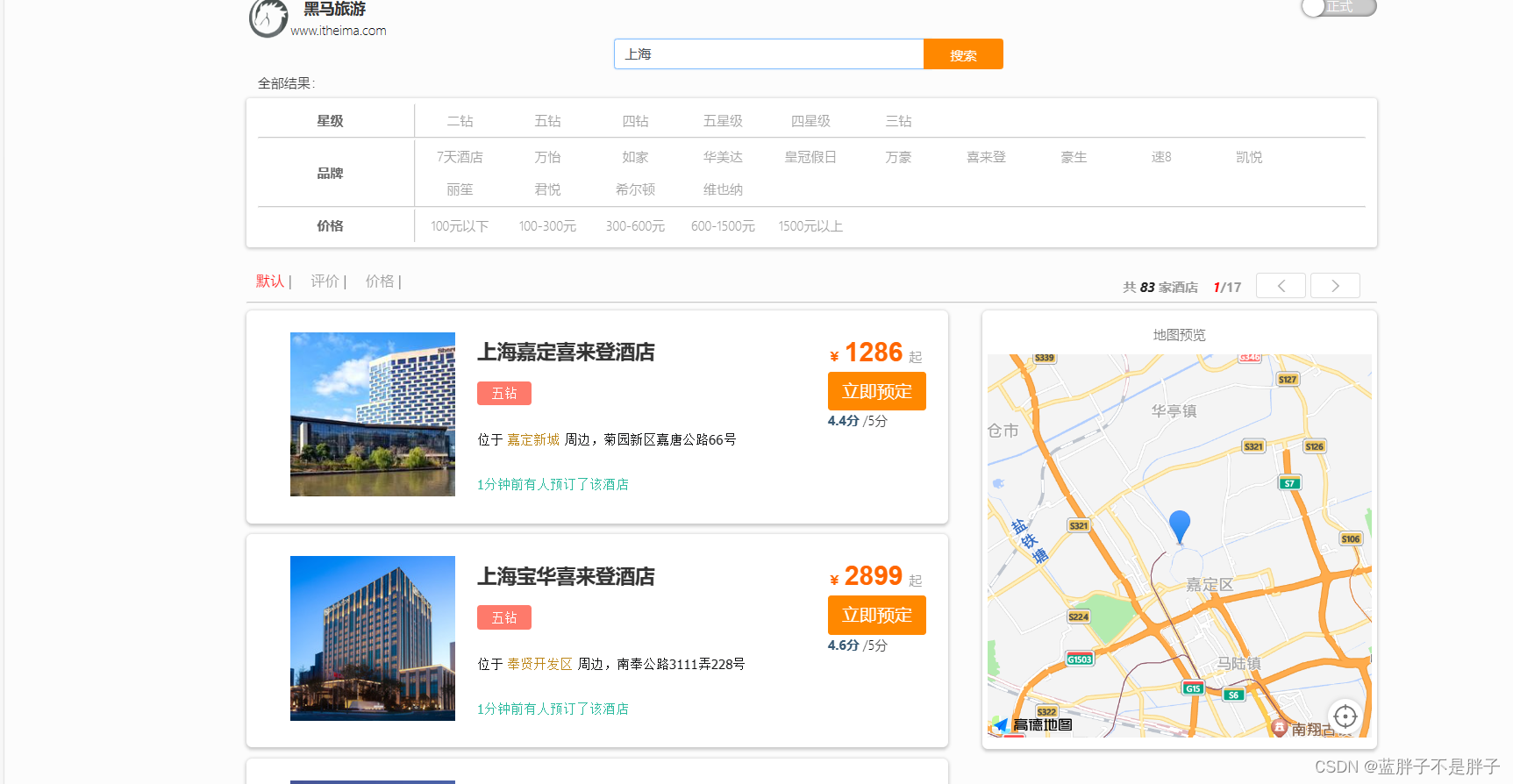
效果如下
检索"上海",那么 此时的聚合出来的查找条件也只能是基于地址在上海的数据
2.自动补全
当用户在搜索框输入字符时,我们应该提示出与该字符有关的搜索项,如图:
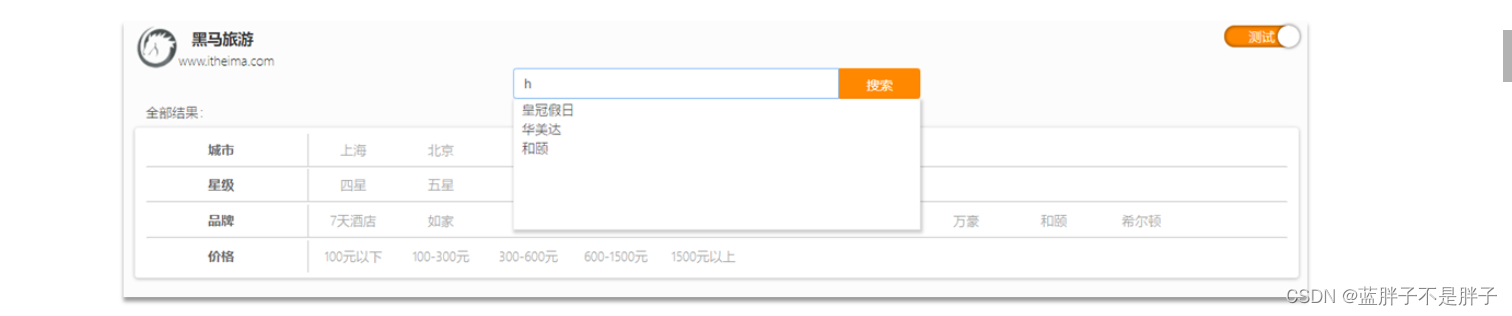
这种根据用户输入的字母,提示完整词条的功能,就是自动补全了。
因为需要根据拼音字母来推断,因此要用到拼音分词功能。
2.1.拼音分词器
要实现根据字母做补全,就必须对文档按照拼音分词。在GitHub上恰好有elasticsearch的拼音分词插件。地址:https://github.com/medcl/elasticsearch-analysis-pinyin
不是使用官方的最新版的,可以找以前的老旧版本
https://github.com/medcl/elasticsearch-analysis-pinyin/releases?
根据官网下载既可
安装方式与IK分词器一样,分三步:
①解压
②上传到虚拟机中,elasticsearch的plugin目录
③重启elasticsearch
④测试

详细安装步骤可以参考IK分词器的安装过程,我这里使用的是docker 容器 安装在对应的插件数据卷即可
测试用法如下:
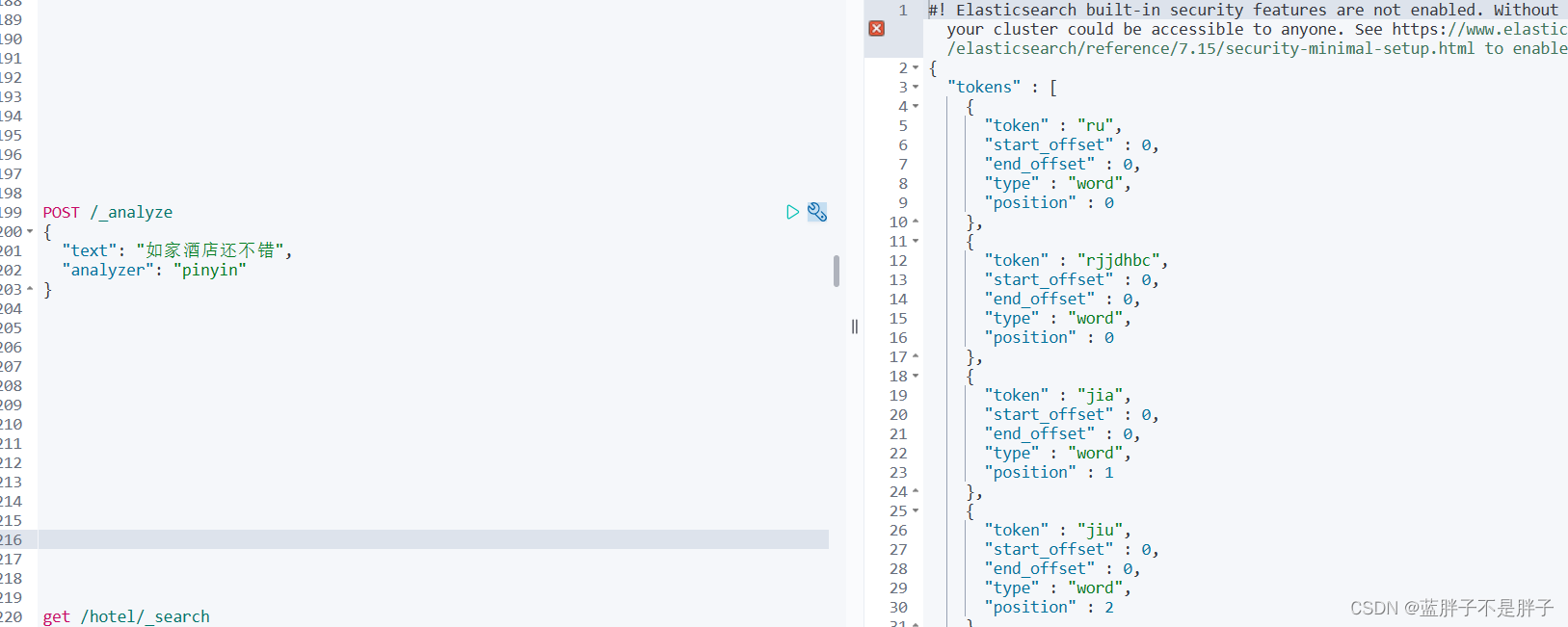
POST /_analyze
{"text": "如家酒店还不错","analyzer": "pinyin"
}
结果:
测试拼英分词成功
2.2.自定义分词器
默认的拼音分词器会将每个汉字单独分为拼音,而我们希望的是每个词条形成一组拼音,需要对拼音分词器做个性化定制,形成自定义分词器。
elasticsearch中分词器(analyzer)的组成包含三部分:
- character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
- tokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart
- tokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等
文档分词时会依次由这三部分来处理文档:

声明自定义分词器的语法如下:
PUT /test
{"settings": {"analysis": {"analyzer": { // 自定义分词器"my_analyzer": { // 分词器名称"tokenizer": "ik_max_word","filter": "py"}},"filter": { // 自定义tokenizer filter"py": { // 过滤器名称"type": "pinyin", // 过滤器类型,这里是pinyin"keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"name": {"type": "text","analyzer": "my_analyzer","search_analyzer": "ik_smart"}}}
}
以下是它各部分的详细解释:
- PUT /test: 此语句标识了这个动作是对名为 “test” 的索引进行操作,即创建/更新了名为 “test” 的索引。
- settings: 在索引设置对象中,关于分词的两个主要部分是“analysis”和“filter”。这里是分词器(analyzer)、分词过滤器(filter)相关的设置。
- analyzer: 在"analysis"部分下,我们定义了名为 “myanalyzer” 的自定义分词器。这个分词器使用了IK分词器的“ikmax_word”模式进行分词。
- filter: 在"analysis"部分下的“filter”部分,我们定义了一个名为 “py” 的过滤器。这个过滤器的类型是 “pinyin”,即转化为拼音。它设置了对拼音的一些处理方式,如是否保留全拼、首字母、原始词组等。
- mappings: 映射定义了索引中字段的存储和搜索方式。在"properties"属性中,你定义了一个名为 “name” 的字段。该字段的类型为 “text”,我们指定该字段在索引文档时使用 “myanalyzer” 分词器,在查询时使用 "iksmart"分词器。
这是因为避免搜索同音字时候,出现俩个不同的词,但是由于拼音一样,所以查找的时候会出现俩个同音的词,所以创建索引时,使用自定义包含拼英的自定义分词器,查找还是用原文分词器
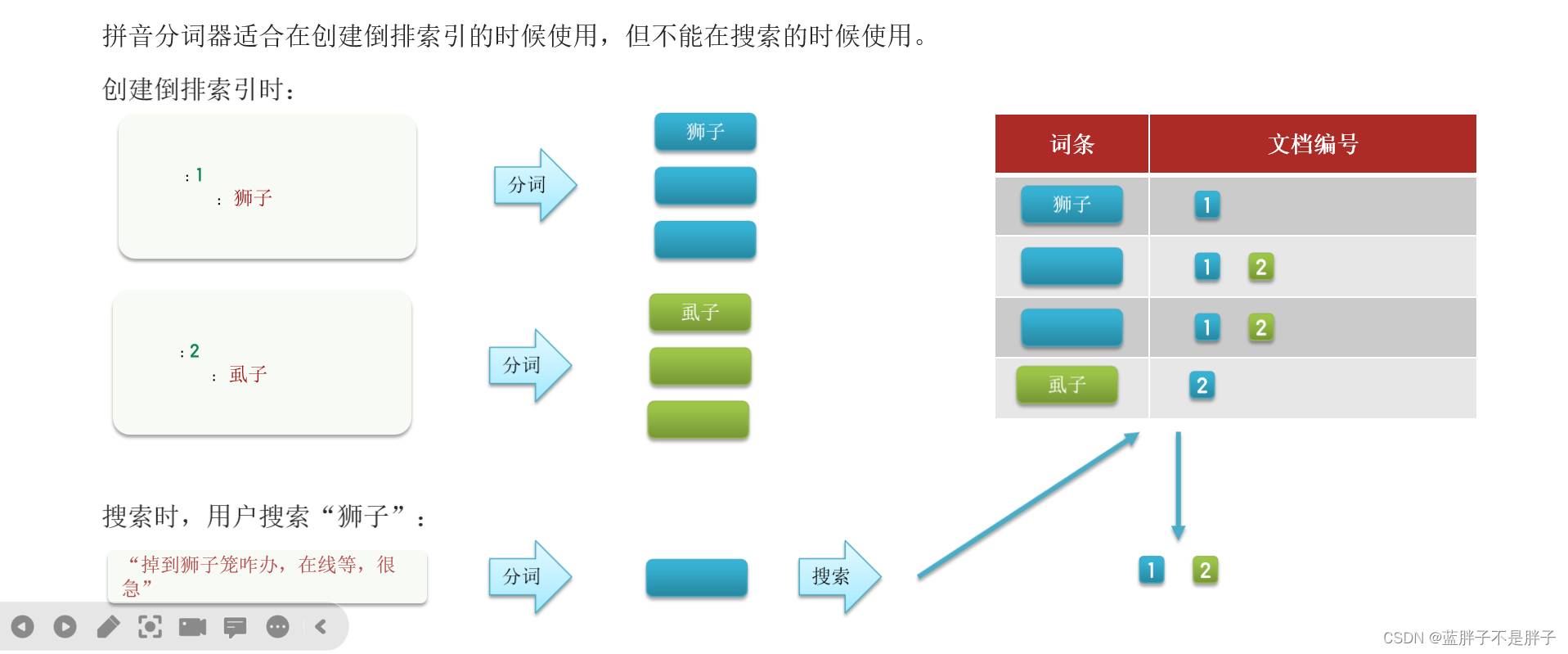
pinyin分词器的每个选项:
- tokenizer: “ikmaxword”, 用于设定为IK分词其的ikmaxword模式进行分词。
- keepfullpinyin: false, 不保留全拼。
- keepjoinedfull_pinyin: true, 保留连在一起的全拼。
- keep_original: true, 保留原始词组。
- limitfirstletter_length: 16, 限制首字母的长度为16。
- removeduplicatedterm: true, 移除重复词。
- nonechinesepinyin_tokenize: false, 非中文拼音不进行分词。
因此,这段DSL主要是创建了一个索引,自定义了其分词器和过滤器,用于处理中文及拼音的存储和搜索。
测试:
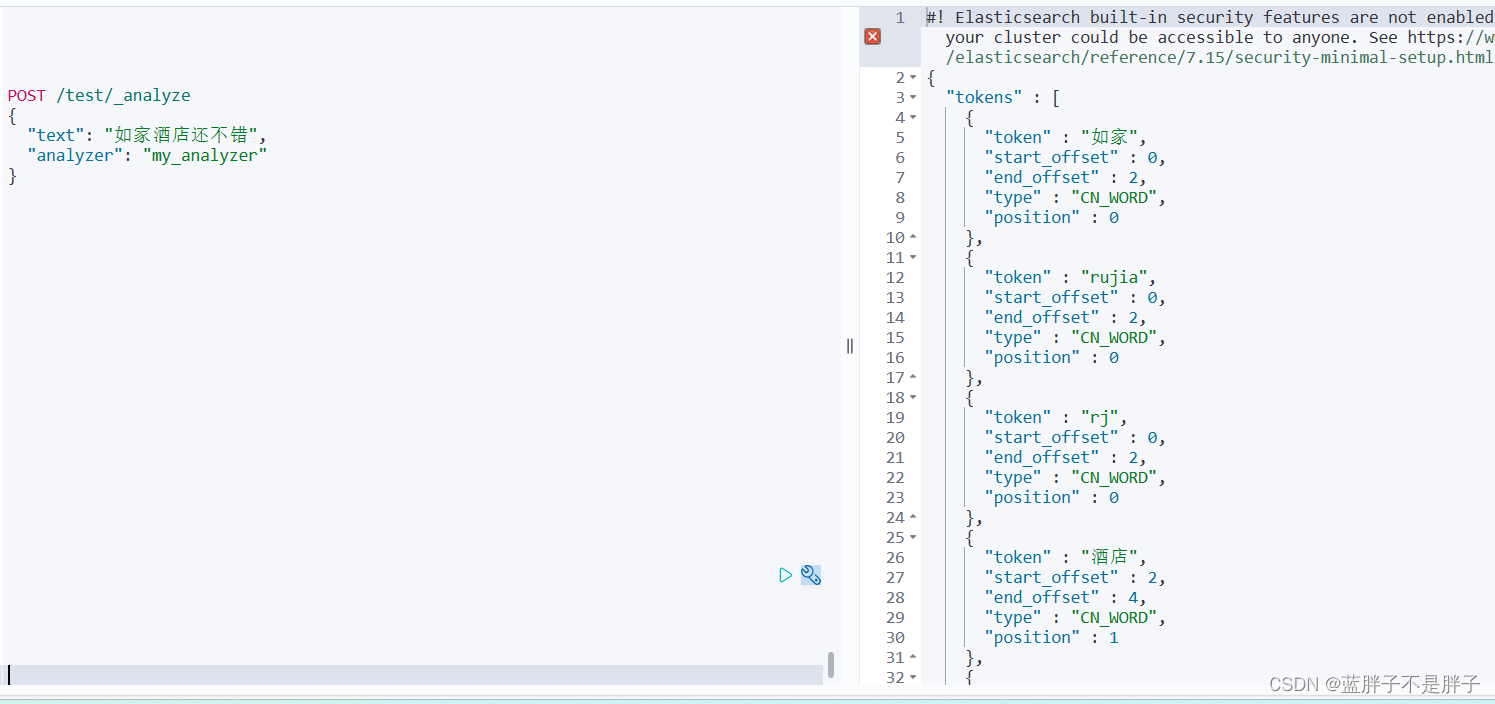
添加俩条文档作为测试
POST /test/_doc/1
{"id": 1,"name": "狮子"
}
POST /test/_doc/2
{"id": 2,"name": "虱子"
}
搜索拼英可以查询到数据
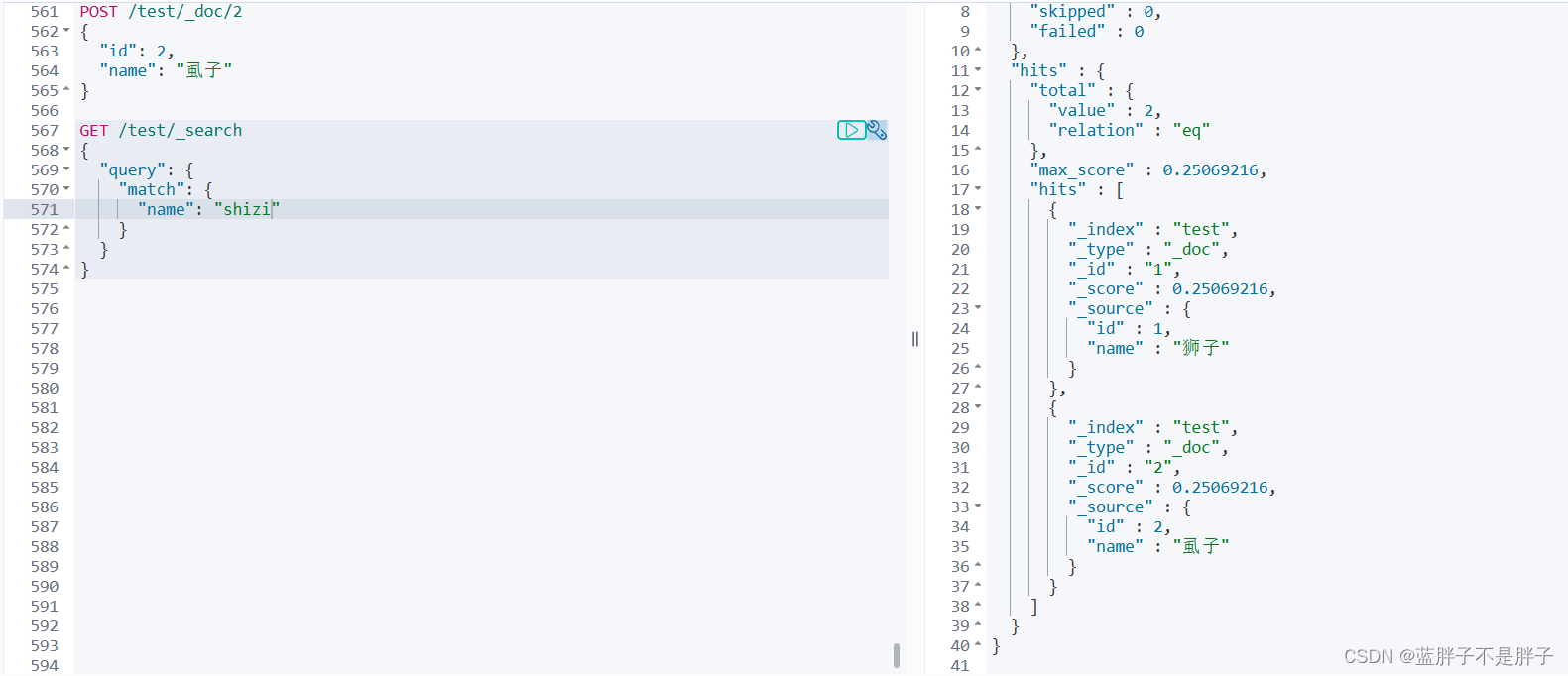
这样不会返回同音词条
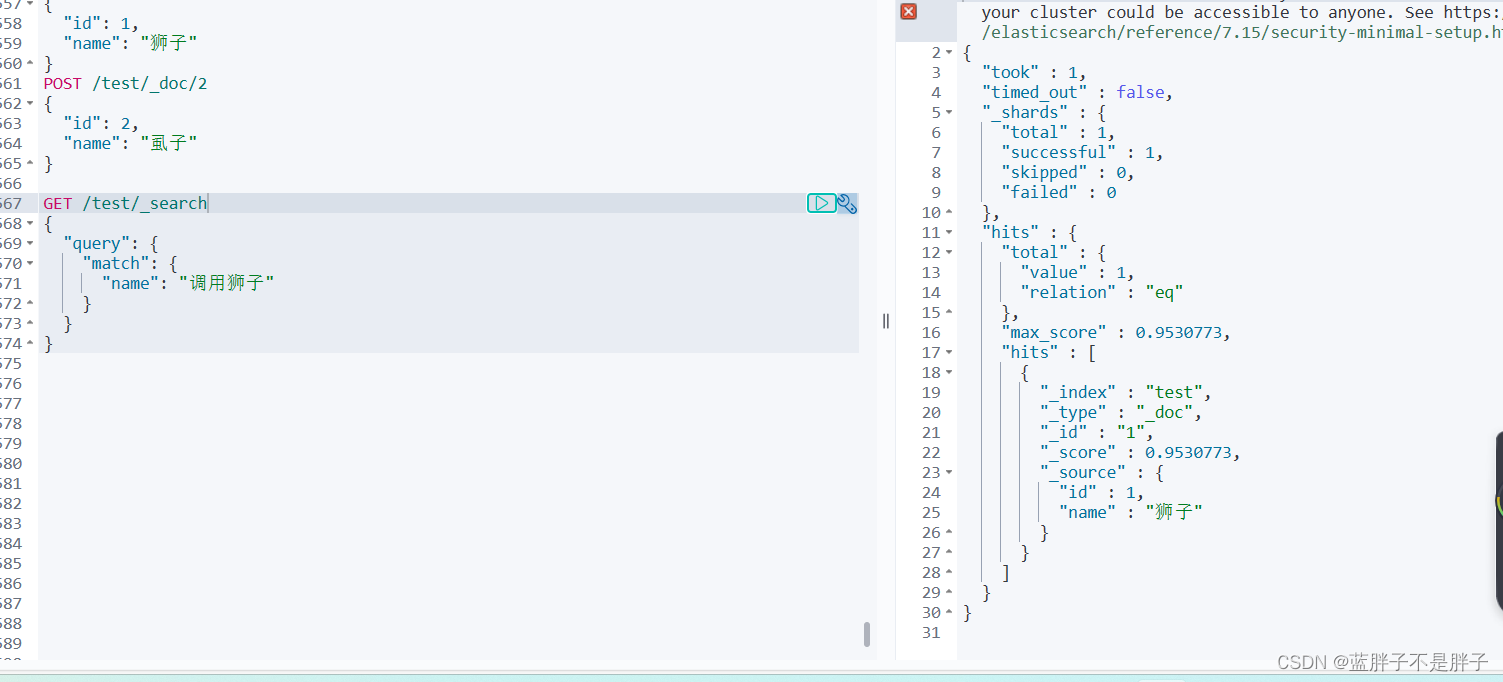
总结:
如何使用拼音分词器?
-
①下载pinyin分词器
-
②解压并放到elasticsearch的plugin目录
-
③重启即可
如何自定义分词器?
-
①创建索引库时,在settings中配置,可以包含三部分
-
②character filter
-
③tokenizer
-
④filter
拼音分词器注意事项?
- 为了避免搜索到同音字,搜索时不要使用拼音分词器
2.3.自动补全查询
elasticsearch提供了Completion Suggester查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全查询的效率,对于文档中字段的类型有一些约束:
-
参与补全查询的字段必须是completion类型。
-
字段的内容一般是用来补全的多个词条形成的数组。
因为是根据词条做的自动补全
比如,一个这样的索引库:
// 创建索引库
PUT test
{"mappings": {"properties": {"title":{"type": "completion"}}}
}
然后插入下面的数据:
// 示例数据 不写id 由es自动生成
POST test/_doc
{"title": ["Sony", "WH-1000XM3"]
}
POST test/_doc
{"title": ["SK-II", "PITERA"]
}
POST test/_doc
{"title": ["Nintendo", "switch"]
}
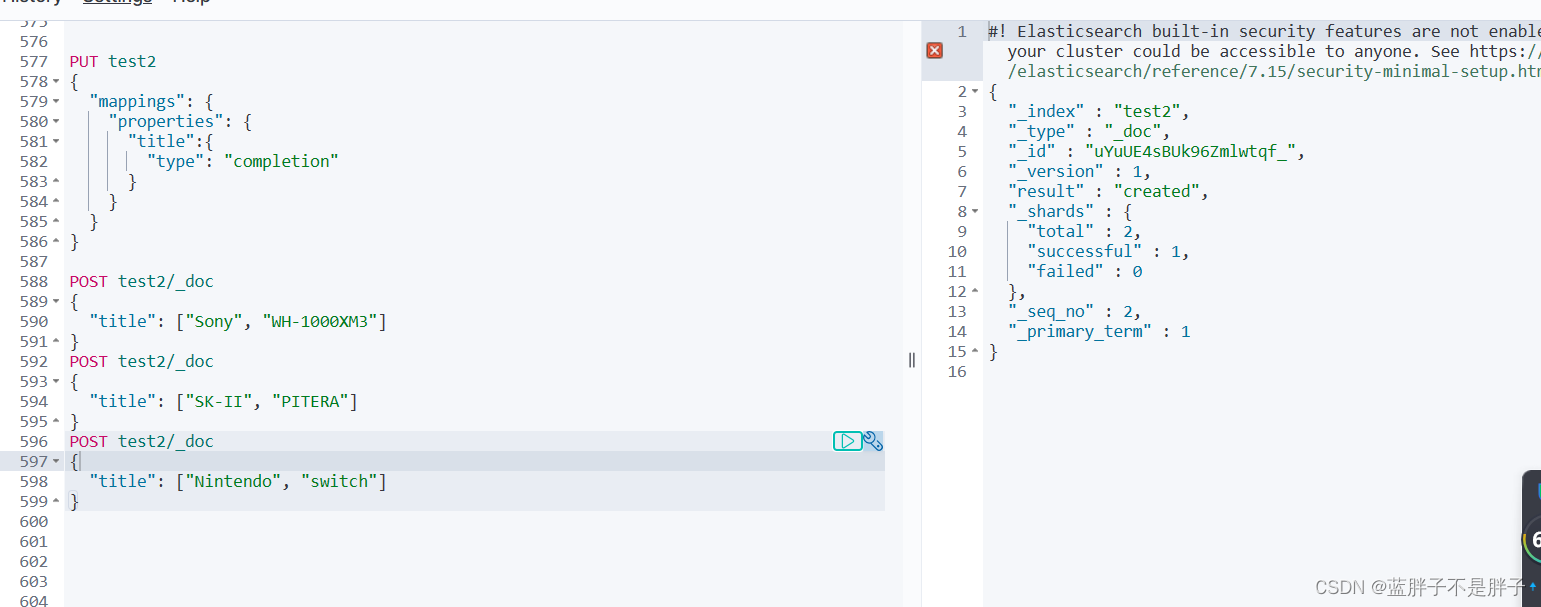
查询的DSL语句如下:
// 自动补全查询
GET /test/_search
{"suggest": {//自动补全不算检索 是给字段做补全操作"title_suggest": {//给自动补全起名"text": "s", // 关键字也就是自动补全的前缀"completion": {"field": "title", // 补全查询的字段"skip_duplicates": true, // 跳过重复的"size": 10 // 获取前10条结果}}}
}
补全结果:
不但返回了补全的结果,还返回了改补全结果所在的文档
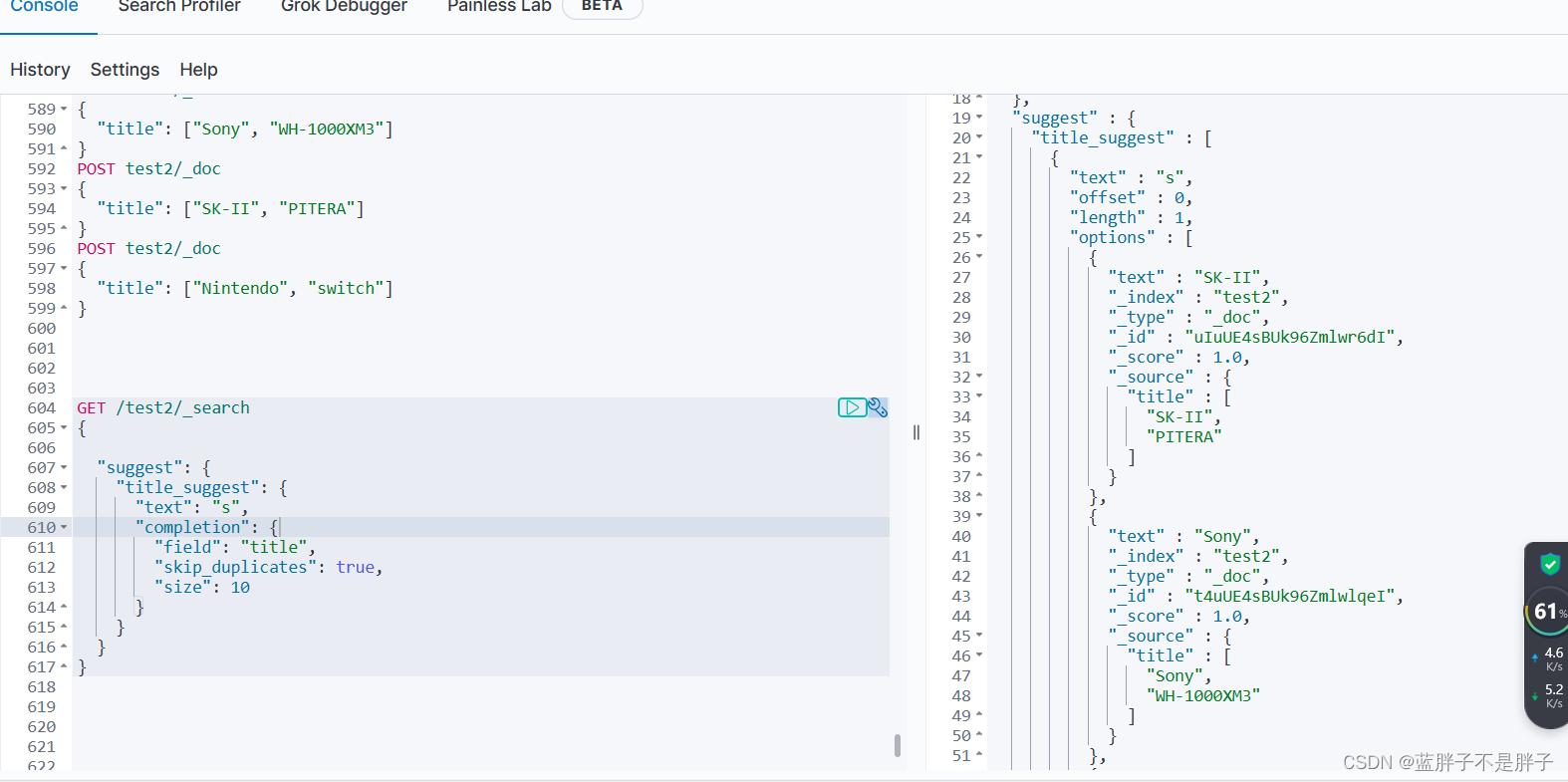
2.4.实现酒店搜索框自动补全
现在,我们的hotel索引库还没有设置拼音分词器,需要修改索引库中的配置。但是我们知道索引库是无法修改的,只能删除然后重新创建。
另外,我们需要添加一个字段,用来做自动补全,将brand、suggestion、city等都放进去,作为自动补全的提示。
因此,总结一下,我们需要做的事情包括:
-
修改hotel索引库结构,设置自定义拼音分词器
-
修改索引库的name、all字段,使用自定义分词器
-
索引库添加一个新字段suggestion,类型为completion类型,使用自定义的分词器
-
给HotelDoc类添加suggestion字段,内容包含brand、business
-
重新导入数据到hotel库
2.4.1.修改酒店映射结构
代码如下:
// 酒店数据索引库
PUT /hotel
{"settings": {"analysis": {"analyzer": {"text_anlyzer": {"tokenizer": "ik_max_word","filter": "py"},"completion_analyzer": {"tokenizer": "keyword","filter": "py"}},"filter": {"py": {"type": "pinyin","keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"id":{"type": "keyword"},"name":{"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart","copy_to": "all"},"address":{"type": "keyword","index": false},"price":{"type": "integer"},"score":{"type": "integer"},"brand":{"type": "keyword","copy_to": "all"},"city":{"type": "keyword"},"starName":{"type": "keyword"},"business":{"type": "keyword","copy_to": "all"},"location":{"type": "geo_point"},"pic":{"type": "keyword","index": false},"all":{"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart"},"suggestion":{"type": "completion","analyzer": "completion_analyzer"}}}
}
-
Settings:
-
text_anlyzer:这个分析器结合了 ik_max_word 分词器和拼音过滤器。ik_max_word 是一个中文分词器,它提供了细粒度的分词能力。加入拼音过滤器后,它会将文本转换为拼音,并保留原始文本。
-
completion_analyzer:这是为 completion 类型字段设计的分析器。它使用 keyword 分词器,这意味着整个输入都会被当作一个单一的 token(分词的独立单元)。但是,它也使用了拼音过滤器,这样可以帮助实现基于拼音的自动完成。
-
py 拼音过滤器:这个过滤器的目的是为中文文本提供拼音支持。设置如下:
-
keep_joined_full_pinyin:保留完整的拼音。
-
keep_original:原始文本也被保留,这样既可以基于原始中文搜索,也可以基于拼音搜索。
-
其他设置用于优化拼音的处理方式。
-
Mappings:
-
name 字段:使用 text_anlyzer 进行索引,这样名称既可以基于中文词条进行搜索,也可以基于拼音进行搜索。查询时,使用 ik_smart 进行搜索,提供更为粗糙的分词,以获得更好的搜索匹配度。
-
all 字段:是一个复合字段,其他字段如 name、brand、business 使用 copy_to 指令复制内容到这里。这样做可以实现一个多字段的全文搜索。
-
suggestion 字段:为自动完成字段。它使用 completion_analyzer,支持基于拼音的自动完成功能。
这样指定分词器的目的是:
2.4.2.修改HotelDoc实体
HotelDoc中要添加一个字段,用来做自动补全,内容可以是酒店品牌、城市、商圈等信息。按照自动补全字段的要求,最好是这些字段的数组。
因此我们在HotelDoc中添加一个suggestion字段,类型为List<String> (因为数组会限制大小,list是是动态的),然后将brand、city、business等信息放到里面。
代码如下:
package cn.itcast.hotel.pojo;import lombok.Data;
import lombok.NoArgsConstructor;import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;@Data
@NoArgsConstructor
public class HotelDoc {private Long id;private String name;private String address;private Integer price;private Integer score;private String brand;private String city;private String starName;private String business;private String location;private String pic;private Object distance;private Boolean isAD;private List<String> suggestion;public HotelDoc(Hotel hotel) {this.id = hotel.getId();this.name = hotel.getName();this.address = hotel.getAddress();this.price = hotel.getPrice();this.score = hotel.getScore();this.brand = hotel.getBrand();this.city = hotel.getCity();this.starName = hotel.getStarName();this.business = hotel.getBusiness();this.location = hotel.getLatitude() + ", " + hotel.getLongitude();this.pic = hotel.getPic();// 组装suggestionif(this.business.contains("/")){// business有多个值,需要切割String[] arr = this.business.split("/");// 添加元素this.suggestion = new ArrayList<>();this.suggestion.add(this.brand);Collections.addAll(this.suggestion, arr);}else {this.suggestion = Arrays.asList(this.brand, this.business);}}
}
2.4.3.重新导入
@Test
void TestBulk(){BulkRequest bulkRequest = new BulkRequest();service.list().stream().forEach(i->bulkRequest.add(new IndexRequest("hotel").id(i.getId().toString()).source(JSON.toJSONString(new HotelDoc(i)),XContentType.JSON)));try {client.bulk(bulkRequest,RequestOptions.DEFAULT);} catch (IOException e) {throw new RuntimeException(e);}
}
重新执行之前编写的导入数据功能,可以看到新的酒店数据中包含了suggestion:
测试查询
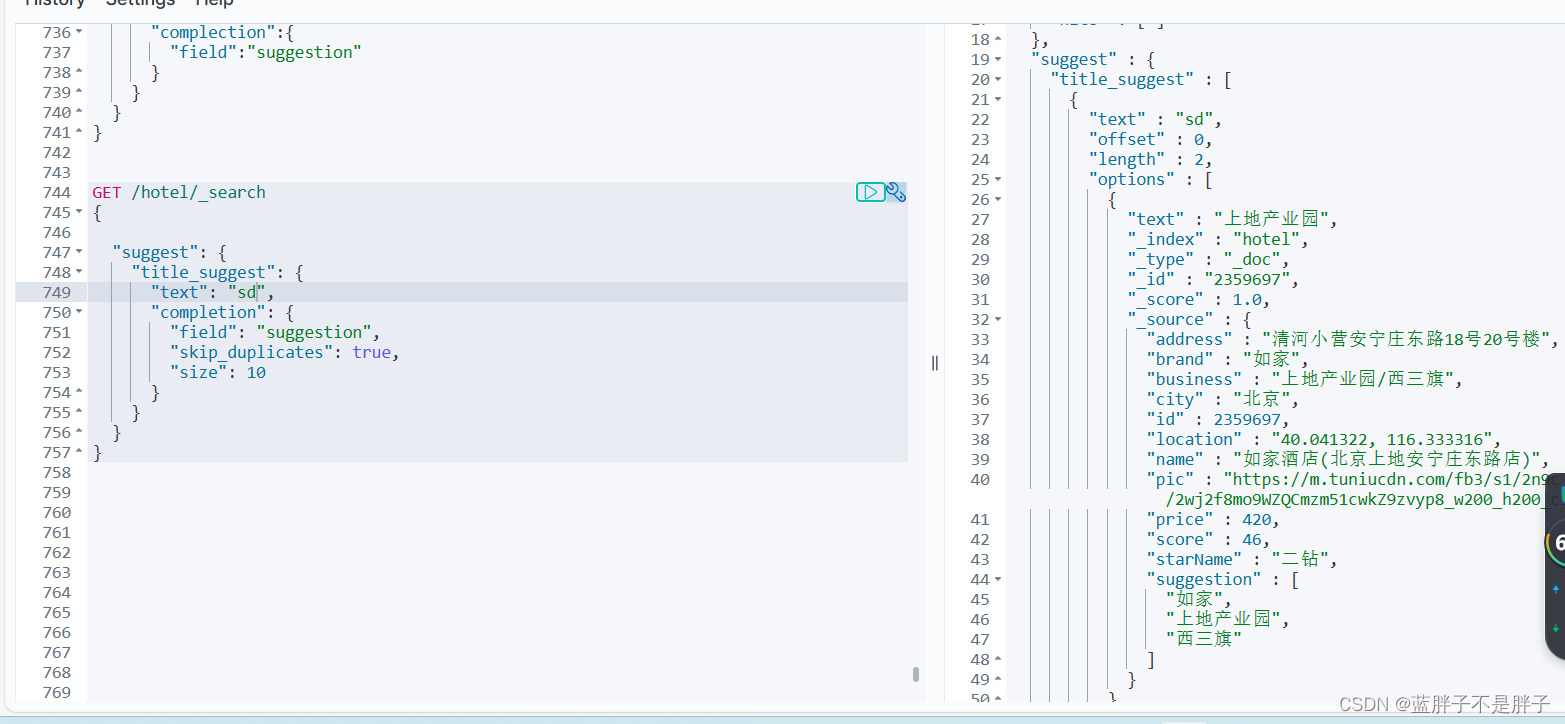
2.4.4.自动补全查询的JavaAPI
之前我们学习了自动补全查询的DSL,而没有学习对应的JavaAPI,这里给出一个示例:
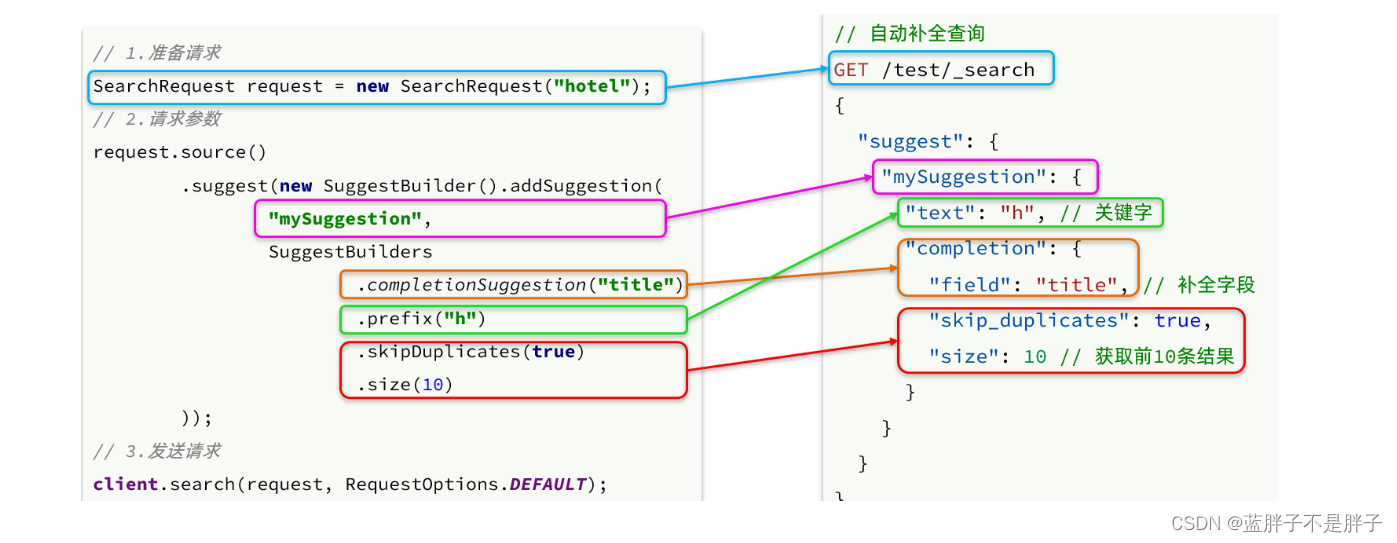
完整代码
@Testvoid testAggestion(){SearchRequest request = new SearchRequest("hotel");try {request.source().suggest(new SuggestBuilder().addSuggestion("suggestions",SuggestBuilders.completionSuggestion("suggestion").prefix("s").size(10)));//prefx前缀就是查找内容client.search(request, RequestOptions.DEFAULT);} catch (IOException e) {throw new RuntimeException(e);}}
}
和之前的检索api方式差不多,也就是链式编程,参数一是聚合builder来实现
而自动补全的结果也比较特殊,解析的代码如下:
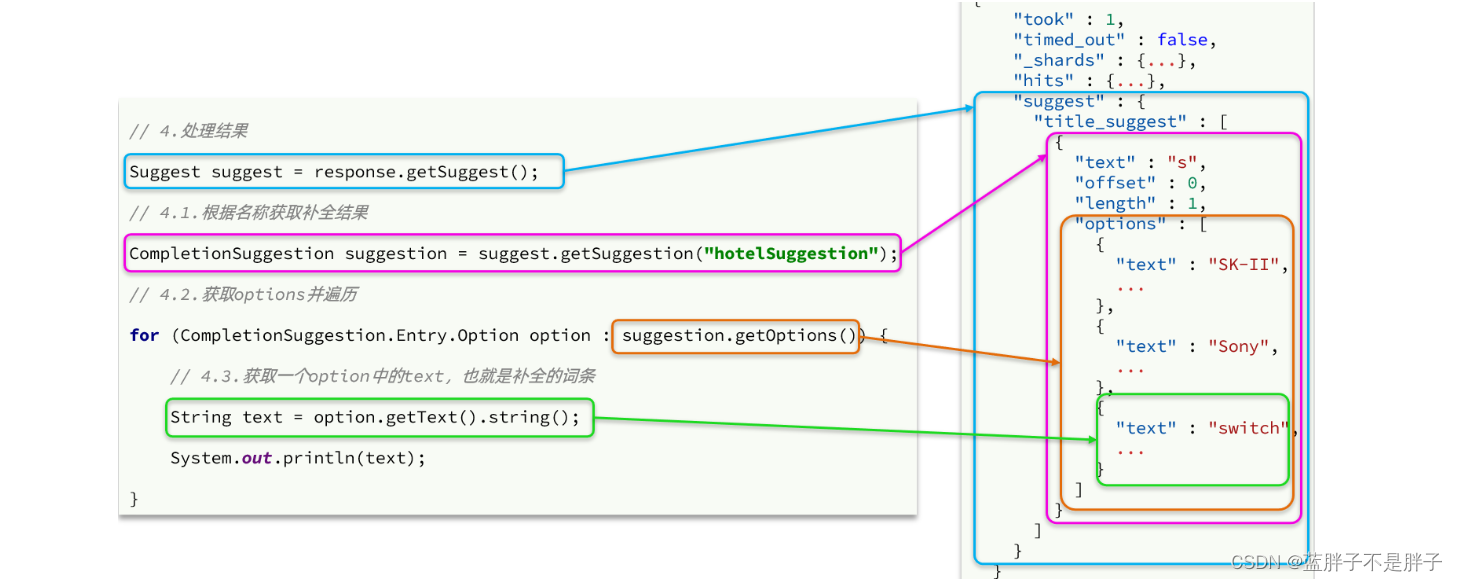
解析代码
Suggest suggest = response.getSuggest();//根据实际名字取自动补全的返回值CompletionSuggestion suggestions = suggest.getSuggestion("suggestions"); //什么类型的补全,就什么类型Suggestion接收
suggestions.getOptions().stream().forEach(i-> System.out.println(i.getText().toString()));
和聚合一样发送请求采用什么方式聚合,解析就采用什么方式接收


运行结果
完整代码
@Testvoid testAggestion(){SearchRequest request = new SearchRequest("hotel");try {request.source().suggest(new SuggestBuilder().addSuggestion("suggestions",SuggestBuilders.completionSuggestion("suggestion").prefix("s").size(10)));//prefx前缀就是查找内容SearchResponse response = client.search(request, RequestOptions.DEFAULT);Suggest suggest = response.getSuggest();//根据实际名字取自动补全的返回值CompletionSuggestion suggestions = suggest.getSuggestion("suggestions"); //什么类型的补全,就什么类型Suggestion接收
suggestions.getOptions().stream().forEach(i-> System.out.println(i.getText().toString()));} catch (IOException e) {throw new RuntimeException(e);}}
}
2.4.5.实现搜索框自动补全
查看前端页面,可以发现当我们在输入框键入时,前端会发起ajax请求:
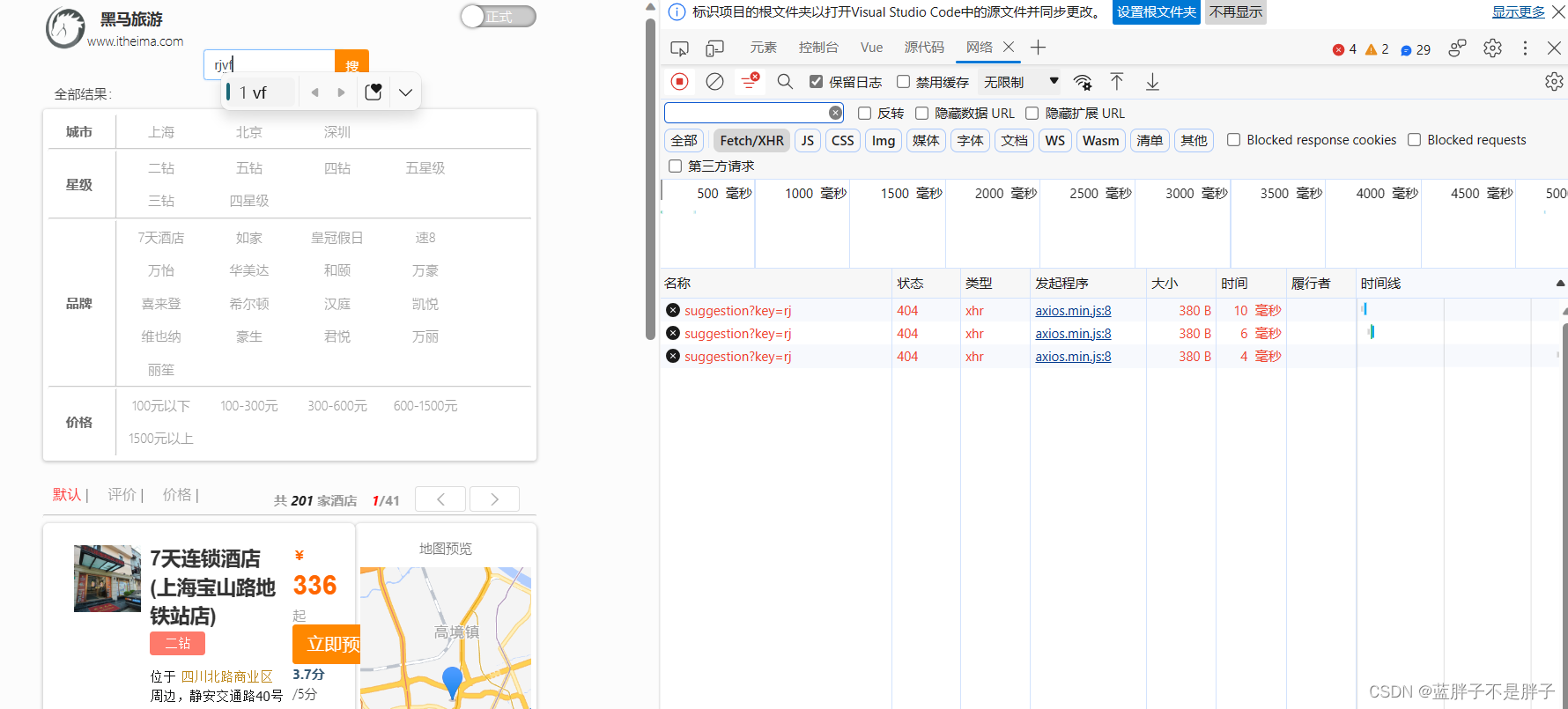
返回值是补全词条的集合,类型为List<String>,然后前端渲染出来
1)在cn.itcast.hotel.web包下的HotelController中添加新接口,接收新的请求:
@GetMapping("suggestion")
public List<String> getSuggestions(@RequestParam("key") String prefix) {return hotelService.getSuggestions(prefix);
}
2)在cn.itcast.hotel.service包下的IhotelService中添加方法:
List<String> getSuggestions(String prefix);
3)在cn.itcast.hotel.service.impl.HotelService中实现该方法:
public List<String> getSuggestions(String prefix) {SearchRequest request = new SearchRequest("hotel");try {request.source().suggest(new SuggestBuilder().addSuggestion("suggestion",SuggestBuilders.completionSuggestion("suggestion").size(10).prefix(prefix)));SearchResponse response = client.search(request, RequestOptions.DEFAULT);CompletionSuggestion suggestion= response.getSuggest().getSuggestion("suggestion");List<String> list = suggestion.getOptions().stream().map(i -> i.getText().toString()).collect(Collectors.toList());return list;} catch (IOException e) {throw new RuntimeException(e);}}
效果图
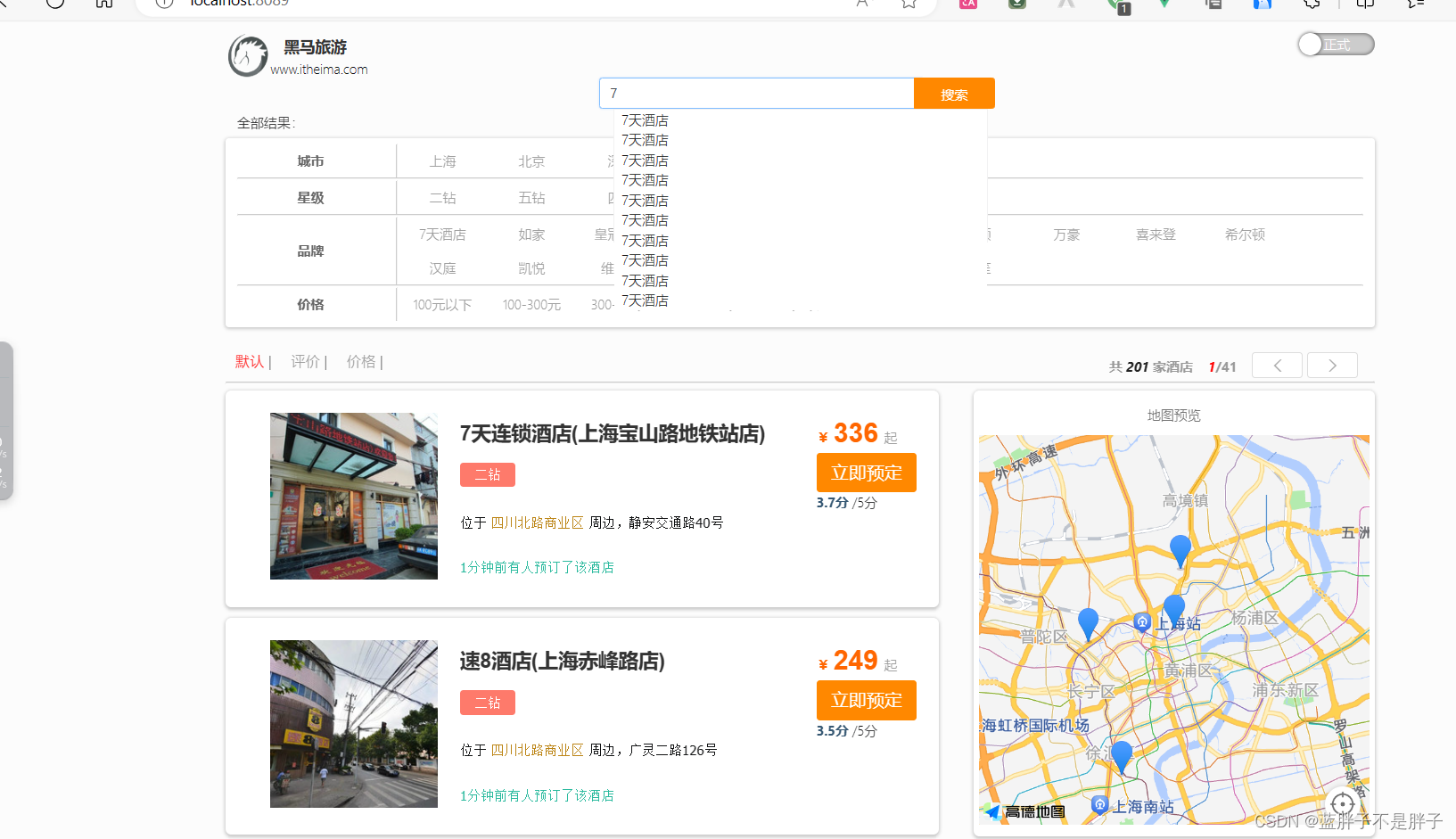
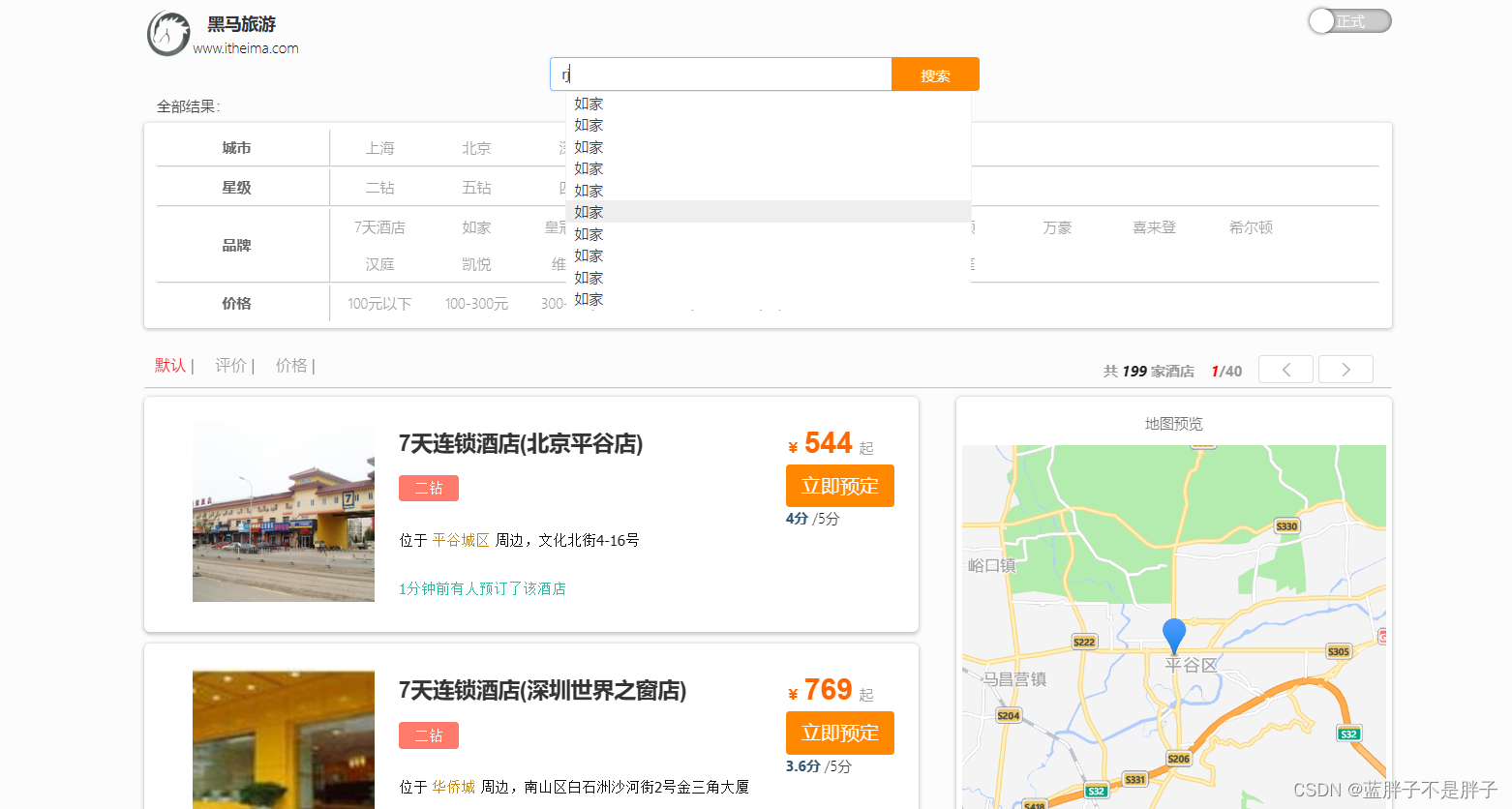
3.数据同步
和redis一样只要是根据持久化数据做得双写服务都会涉及到数据同步问题
elasticsearch中的酒店数据来自于mysql数据库,因此mysql数据发生改变时,elasticsearch也必须跟着改变,这个就是elasticsearch与mysql之间的数据同步。

3.1.思路分析
常见的数据同步方案有三种:
- 同步调用
- 异步通知
- 监听binlog
3.1.1.同步调用
方案一:同步调用

基本步骤如下:
- hotel-demo对外提供接口,用来修改elasticsearch中的数据
- 酒店管理服务在完成数据库操作后,直接调用hotel-demo提供的接口,
3.1.2.异步通知
方案二:异步通知
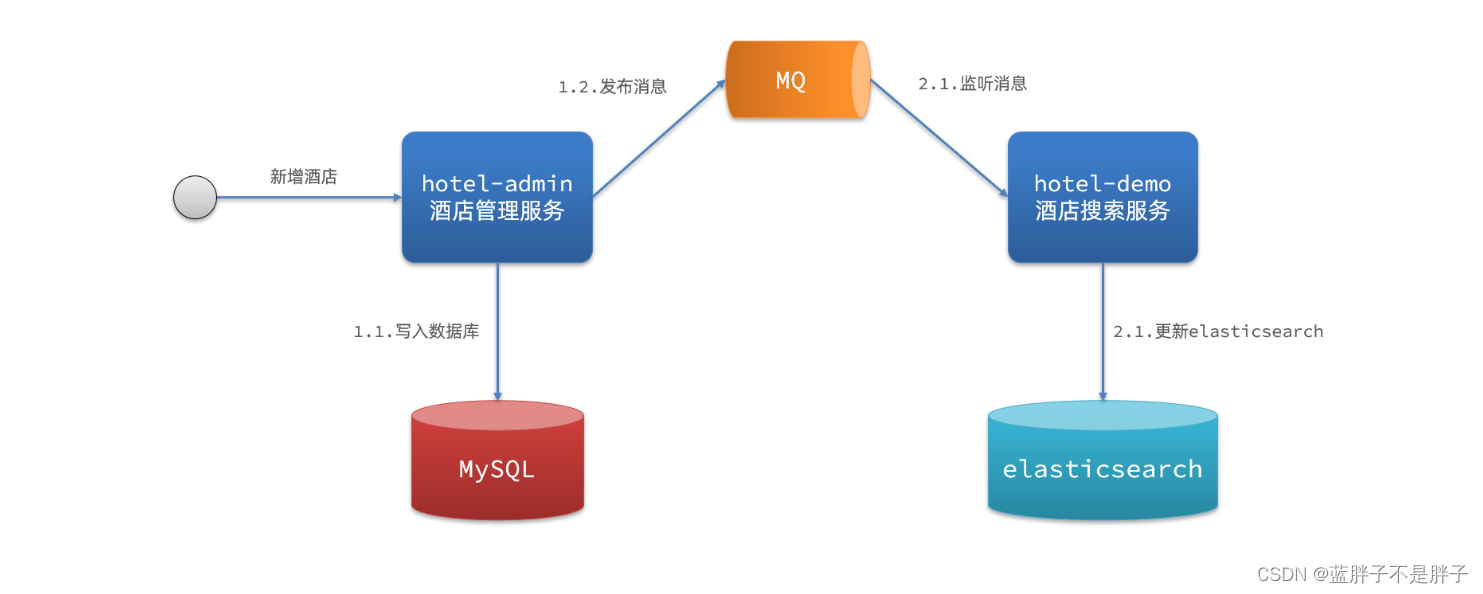
流程如下:
- hotel-admin对mysql数据库数据完成增、删、改后,发送MQ消息
- hotel-demo监听MQ,接收到消息后完成elasticsearch数据修改
3.1.3.监听binlog
方案三:监听binlog
流程如下:
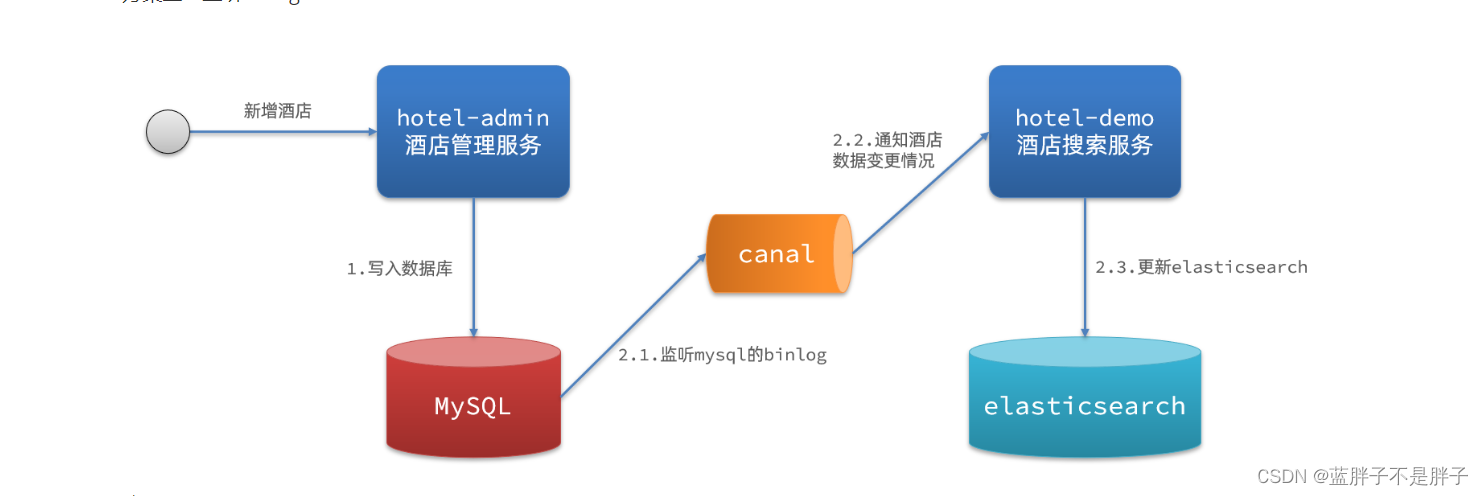
- 给mysql开启binlog功能
- mysql完成增、删、改操作都会记录在binlog中 (只要数据变化就会触发)
- hotel-demo基于canal监听binlog变化,实时更新elasticsearch中的内容
3.1.4.选择
方式一:同步调用
- 优点:实现简单,粗暴
- 缺点:业务耦合度高
方式二:异步通知
- 优点:低耦合,实现难度一般
- 缺点:依赖mq的可靠性
方式三:监听binlog
- 优点:完全解除服务间耦合
- 缺点:开启binlog增加数据库负担、实现复杂度高
一般是通过mq实现,并且处理方式和redis类似
- 实时同步(更新和删除):
这种方式确保 Elasticsearch 中的数据与 MySQL 中的数据保持实时同步。优点和缺点如下:
优点:
- 实时性较高,Elasticsearch 中的数据几乎与 MySQL 中的数据同步。
- 查询 Elasticsearch 时不需要访问 MySQL 数据库,因此可以提供更好的性能。
缺点: - 实时同步可能会对系统性能造成额外负担,特别是在高负载情况下。
- 需要处理同步期间的故障和一致性问题。
- 懒加载同步(查询并更新):
这种方式允许 Elasticsearch 和 MySQL 数据库之间存在一定的延迟,而不是实时同步。优点和缺点如下:
优点:
- 减少了实时同步的性能开销。
- 对于不需要实时数据的应用程序,可以提供更好的性能。
缺点: - 可能会导致一定的数据延迟,因为 Elasticsearch 中的数据不是立即更新的。
- 需要额外的逻辑来处理数据的查询和更新。
3.2.实现数据同步
3.2.1.思路
利用黑马得课前资料提供的hotel-admin项目作为酒店管理的微服务。当酒店数据发生增、删、改时,要求对elasticsearch中数据也要完成相同操作。
步骤:
-
导入课前资料提供的hotel-admin项目,启动并测试酒店数据的CRUD
-
声明exchange、queue、RoutingKey
-
在hotel-admin中的增、删、改业务中完成消息发送
-
在hotel-demo中完成消息监听,并更新elasticsearch中数据
-
启动并测试数据同步功能
3.2.2.导入demo
黑马课程
导入课前资料提供的hotel-admin项目:
运行后,访问 http://localhost:8099
其中包含了酒店的CRUD功能:
3.2.3.声明交换机、队列
MQ结构如图:
细节
- 修改数据使用全量修改这样可以和新增加通用一个队列
- Topic 交换机使用一组路由规则来确定如何将消息传递给订阅者。根据不同得路由key匹配发给哪个队列
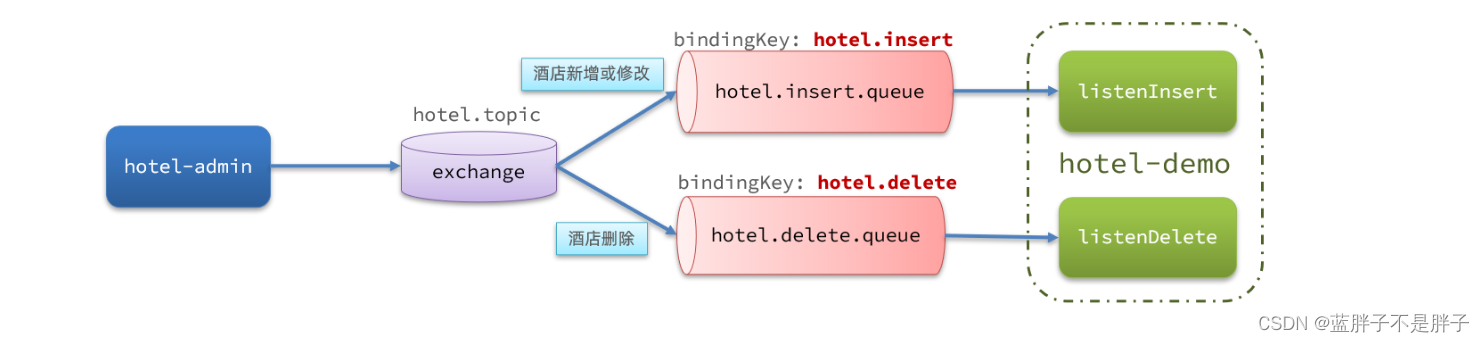
1)引入依赖
在hotel-admin、hotel-demo中引入rabbitmq的依赖:
<!--amqp-->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
并且配置mq服务地址
rabbitmq:addresses: 192.168.249.132port: 5672username: adminpassword: adminvirtual-host: /
2)声明队列交换机名称
在hotel-admin和hotel-demo中的cn.itcast.hotel.constatnts包下新建一个类MqConstants:
package cn.itcast.hotel.constatnts;public class MqConstants {/*** 交换机*/public final static String HOTEL_EXCHANGE = "hotel.topic";/*** 监听新增和修改的队列*/public final static String HOTEL_INSERT_QUEUE = "hotel.insert.queue";/*** 监听删除的队列*/public final static String HOTEL_DELETE_QUEUE = "hotel.delete.queue";/*** 新增或修改的RoutingKey*/public final static String HOTEL_INSERT_KEY = "hotel.insert";/*** 删除的RoutingKey*/public final static String HOTEL_DELETE_KEY = "hotel.delete";
}
3)声明队列交换机
在hotel-demo中,定义配置类,声明队列、交换机:
package cn.itcast.hotel.config;import cn.itcast.hotel.constants.MqConstants;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.core.TopicExchange;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/*** 对交换机和队列进行bingd定* 发送之前至少发送的地方应该存在*/
@Configuration
public class MqConfig {@Beanpublic TopicExchange topicExchange(){return new TopicExchange(MqConstants.HOTEL_EXCHANGE, true, false);}@Beanpublic Queue insertQueue(){return new Queue(MqConstants.HOTEL_INSERT_QUEUE, true);}@Beanpublic Queue deleteQueue(){return new Queue(MqConstants.HOTEL_DELETE_QUEUE, true);}@Beanpublic Binding insertQueueBinding(){return BindingBuilder.bind(insertQueue()).to(topicExchange()).with(MqConstants.HOTEL_INSERT_KEY);}@Beanpublic Binding deleteQueueBinding(){return BindingBuilder.bind(deleteQueue()).to(topicExchange()).with(MqConstants.HOTEL_DELETE_KEY);}
}
3.2.4.发送MQ消息
在hotel-admin中的增、删、改业务中分别发送MQ消息:
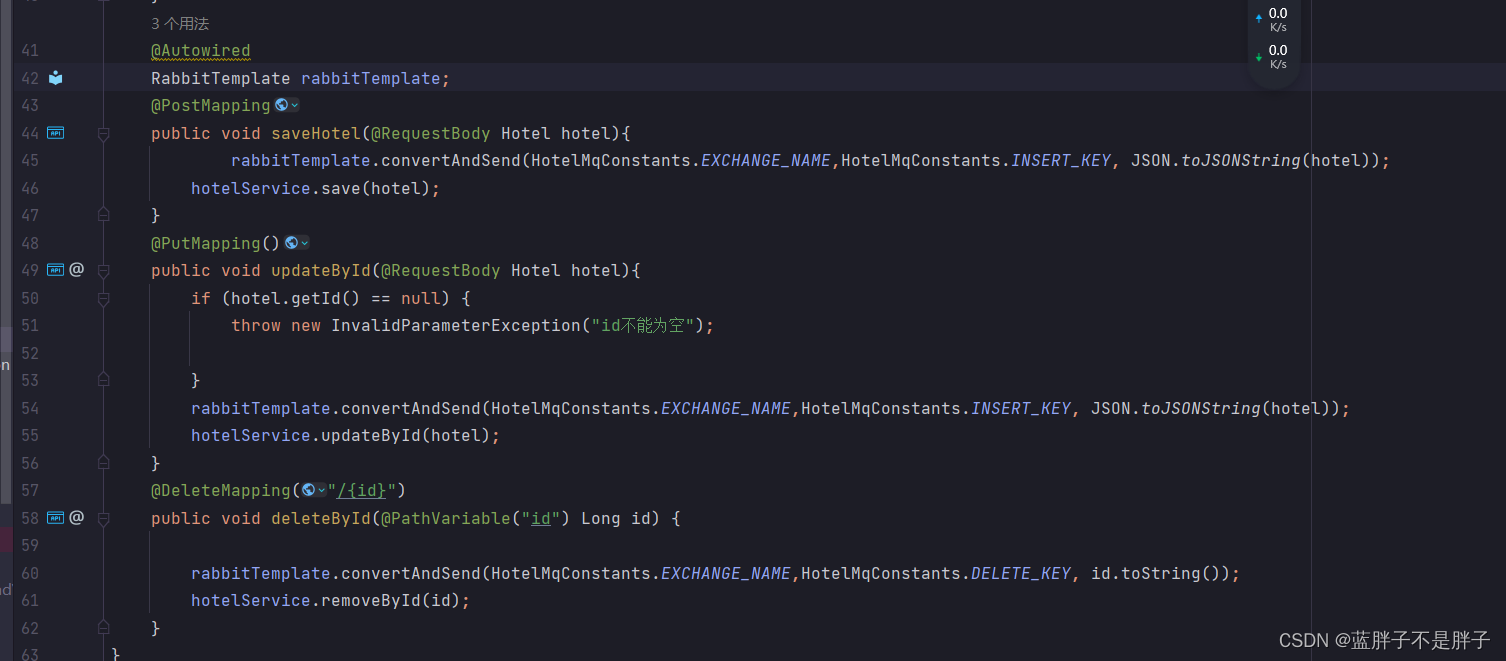
3.2.5.接收MQ消息
hotel-demo接收到MQ消息要做的事情包括:
- 新增消息:根据传递的hotel的id查询hotel信息,然后新增一条数据到索引库
- 删除消息:根据传递的hotel的id删除索引库中的一条数据
1)首先在hotel-demo的cn.itcast.hotel.service包下的IHotelService中新增新增、删除业务
void deleteById(Long id);void insertById(Long id);
2)给hotel-demo中的cn.itcast.hotel.service.impl包下的HotelService中实现业务:
@Override
public void deleteById(Long id) {try {// 1.准备RequestDeleteRequest request = new DeleteRequest("hotel", id.toString());// 2.发送请求client.delete(request, RequestOptions.DEFAULT);} catch (IOException e) {throw new RuntimeException(e);}
}@Override
public void insertById(Long id) {try {// 0.根据id查询酒店数据Hotel hotel = getById(id);// 转换为文档类型HotelDoc hotelDoc = new HotelDoc(hotel);// 1.准备Request对象IndexRequest request = new IndexRequest("hotel").id(hotel.getId().toString());// 2.准备Json文档request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);// 3.发送请求client.index(request, RequestOptions.DEFAULT);} catch (IOException e) {throw new RuntimeException(e);}
}
3)编写监听器
在hotel-demo中的cn.itcast.hotel.mq包新增一个类:
@Component
public class HotelLestener {@AutowiredRestHighLevelClient client;@RabbitListener(queues = HotelMqConstants.INSERT_QUEUE_NAME)public void InseetOrUpdateQueue(String message) {System.out.println("输出修改/增加得对象是" + message);if (message != null && !message.equals("")) {Hotel hotel = JSON.parseObject(message, Hotel.class);IndexRequest request = new IndexRequest("hotel");request.source(JSON.toJSONString(new HotelDoc(hotel)), XContentType.JSON).id(hotel.getId().toString());try {client.index(request, RequestOptions.DEFAULT);} catch (IOException e) {throw new RuntimeException(e);}} else return;}//一般开发中俩个服务@RabbitListener(queues = MqConstants.HOTEL_DELETE_QUEUE)public void listenHotelDelete(Long id){hotelService.deleteById(id);}
}
消息接收成功

es的单点实列实际开发的运用就到这里结束分布式场景的应用知识如下