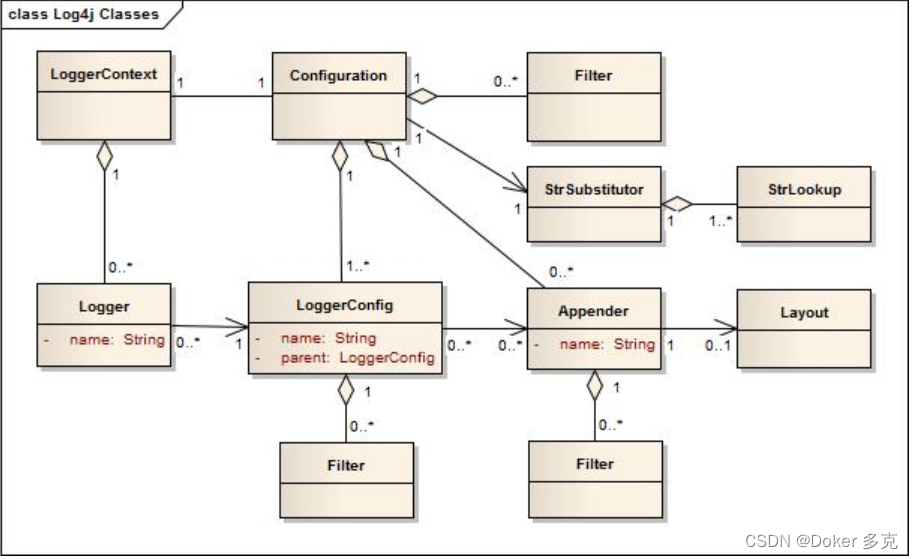
星系中的异常现象是我们了解宇宙的关键。然而,随着天文观测技术的发展,天文数据正以指数级别增长,超出了天文工作者的分析能力。
尽管志愿者可以在线上参与对天文数据的处理,但他们只能进行一些简单的分类,还可能会遗漏一些关键数据。
为此,研究者基于卷积神经网络和无监督学习开发了 Astronomaly 算法。近日,西开普大学的研究人员首次将 Astronomaly
用于大规模的数据分析,尝试从 400 万张星系照片中探寻宇宙的异常。
作者 | 雪菜
编辑 | 三羊、铁塔
星系中的异常现象 (Anomaly) 是我们了解宇宙的关键。通过对巡天望远镜 (Survey Telescope) 记录到的图像进行分析,研究人员能够找出星系中的异常现象,进而对宇宙的起源和演化做出推断。
然而,这一过程正面临着严峻的挑战,因为天文观测数据量正以指数级别在增长。以即将投入使用的薇拉·鲁宾天文台为例,这一天文台有着世界上最大的数码相机,预计每晚将记录 20 TB 的数据,十年间记录 60 PB 的数据,对约 200 亿个星系进行 32 万亿次观察,远超研究人员人力所能分析的极限。

2007 年 7 月,一些研究者启动了 Galaxy Zoo 项目,通过线上招募志愿者的方式推进天文观测图像分类。这一项目吸引了约 15 万名志愿者,共对斯隆数字巡天项目 (SDSS) 记录到的 100 万个星系图像进行了超过 4,000 万次分类。

但志愿者只能做一些基础的工作,而且很容易忽视掉图像中的细节。而机器学习长于图像分析和数据归类,在天文分析中大有可为。监督学习已被广泛用于天文数据分析,但这些算法需要大量的训练数据和预定义,在寻找异常现象中表现不佳。
为此,2021 年研究人员基于卷积神经网络 (CNN) 开发了无监督机器学习算法 Astronomaly,并在不同任务中有着优异的表现。近日,西开普大学的研究者利用 Astronomaly 对约 400 万张星系图像进行分析,首次将这一算法应用于大规模的数据分析,并找到了之前为人忽视的异常现象。这一成果已在 arXiv 发表预印版。

论文链接:
https://arxiv.org/abs/2309.08660
实验过程
数据集:暗能量巡天相机
本研究的数据集主要为暗能量巡天相机 (DECaLS) 的第八批公开数据 (DR8) 中 g、r、z 波段中记录的图像。
随后,对数据集中的图像进行筛选。去除被伪迹和恒星遮盖的图像,同时排除与标准星系模型不符的图像,最后留下了 3,884,404 张星系图像。
特征提取:CNN + PCA
为了提高 Astronomaly 的计算效率,需要对高维的图像进行特征提取,将其转变为低维向量。
本研究通过预训练的 CNN 对图像进行特征提取。CNN 的每一层会对输入图像进行不同变换,生成一个可以代表图像特征的向量。
CNN 最终输出了包含 1,280 个图像特征的向量。随后,研究人员利用主成分分析 (PCA) 进一步降低数据维度。PCA 是一种常用的统计方法,能够基于数据的方差将一组相关的变量转换为不相关的主成分。通过 PCA,图像的维度进一步降低至 26,提高了 Astronomaly 的处理效率。
异常监测:iForest + 主动学习
Astronomaly 结合孤立森林 (iForest) 和局部离群因子 (LOF) 算法进行异常监测。在数据测试中,LOF 算法很难应用于大规模的数据,而 iForest 算法能够通过决策树迅速找到图像中的异常。因此,在后续分析中均使用 iForest 算法。
随后, Astronomaly 通过 K-近邻算法 (NS) 和直接回归算法 (DR) 进行主动学习,不断更新数据集中图像的异常评分。
NS 算法可以基于少量人工标注的评分,通过随机森林回归算法预测用户对所有图像的评分。而 DR 算法会直接尝试「模拟」用户对图像的评分。
最终,两种算法的评分结果将与人工标注的数据进行结果对比,进行评估。

Label 5 结果自左向右分别对应星系融合、引力透镜和尚未归类。
引力透镜是指强引力天体使得附近的光不再沿直线传播的效应,与透镜对光线的折射作用类似。
对比验证:Recall 曲线 + UMAP
研究人员利用 iForest、NS 和 DR 算法对验证集中的数据进行了预测。评价集包含 184 个异常现象。iForest 算法在 500 个异常评分最高的图像中仅发现了 15 处异常,而 DR 和 NS 算法均找到了 84 处异常。

进一步,研究人员将 iForest 和 NS 算法的预测结果按照伪迹、引力透镜和星系融合进行了分类,发现了 iForest 算法表现不佳的原因。

如图所示,iForest 算法发现的异常大多是伪迹。这些技术异常虽然也是异常,但没有什么科学价值。上述结果说明,NS 和 DR 算法可以帮助 Astronomaly 迅速排除伪迹的干扰,找到宇宙中的异常现象。
同时,研究人员利用统一流形逼近投影法 (UMAP, Uniform Manifold Approximation and Projection) 对验证集中的图像进行了分类。

可以看到,0 分的伪迹和 5 分的异常现象在图中被分为紧密的团簇,说明两类图像都有很明显的特征。但同时,两类图像的分布很近,很容易让 iForest 算法产生误判。
大规模应用:标注与探索
在对不同算法的性能进行评估后,研究人员将 NS 算法用于整个数据集中。
图中可以看到,当不对数据进行任何标注时,即无主动学习的 iForest 算法,结果中几乎看不到曲线,因为 iForest 算法在 2,000 个异常评分最高数据中只找到了一处异常。

然而,对数据集中 2,000 个数据进行标注后,Astronomaly 能够通过主动学习迅速找到图像中的异常。当标注数为 4,000 时,Astronomaly 新找到的异常现象最多,随后开始下降,说明此时不需要额外的标注,可以增大数据集。
后续调查:1635/2000
在对数据集中所有图像进行分析后, Astronomaly 从异常评分最高的 2,000 张图像中找到了 1,635 处异常,其中 8 处引力透镜、18 处未被归类的现象、1609 处星系融合。



同时,被称为「中国天眼」的 500 米口径球面射电望远镜 (FAST) 也面临着数据量过大的问题,而 AI 为他们提供了解决方案。2021 年,FAST 与腾讯优图实验室合作,对 FAST 数据进行分析,很快就找到了 5 颗脉冲星。
AI 在其他方面也发挥着自己的作用。2019 年,视界面望远镜 (ETH) 团队发布了世界上第一张黑洞照片。四年后,美国的研究人员利用 AI 对这张照片进行了图像处理,得到了更高清的黑洞照片,为黑洞「美颜」。

参考链接:
[1]https://zoo4.galaxyzoo.org/?lang=zh_cn#/classify
[2]https://www.cas.cn/kj/202009/t20200901_4757754.shtml
[3]https://www.thepaper.cn/newsDetail_