MQ
MQ解决了什么问题?
-
异步处理
-
解耦合
-
削峰填谷
-
大规模数据处理
解耦
A系统发送数据到BCD三个系统,通过接口调用发送。如果 E 系统也要这个数据呢?那如果C系统现在不需要了呢?A系统负责人几乎崩溃…
A系统跟其它各种乱七八糟的系统严重耦合,A系统产生一条比较关键的数据,很多系统都需要A系统将这个数据发送过来。
如果使用MQ,A系统产生一条数据,发送到MQ里面去,哪个系统需要数据自己去MQ里面消费。如果新系统需要数据,直接从MQ里消费即可;如果某个系统不需要这条数据了,就取消对MQ消息的消费即可。
这样下来,A系统压根儿不需要去考虑要给谁发送数据,不需要维护这个代码,也不需要考虑人家是否调用成功、失败超时等情况。就是一个系统或者一个模块,调用了多个系统或者模块,互相之间的调用很复杂,维护起来很麻烦。但是其实这个调用是不需要直接同步调用接口的,如果用MQ给它异步化解耦。
异步
A系统接收一个请求,需要在自己本地写库,还需要在BCD三个系统写库,自己本地写库要 3ms,BCD三个系统分别写库要300ms、450ms、200ms。最终请求总延时是3 + 300 +450 + 200 = 953ms,接近1s,用户感觉搞个什么东西,慢死了慢死了。
用户通过浏览器发起请求。如果使用MQ,那么 A 系统连续发送 3 条消息到MQ队列中,假如耗时5ms,A系统从接受一个请求到返回响应给用户,总时长是3 + 5 = 8ms。
削峰
减少高峰时期对服务器压力。
MQ的缺点
-
系统可用性降低:系统引入的外部依赖越多,越容易挂掉。万一 MQ 挂了,MQ 一挂,整套系统崩溃,你不就完了?
-
系统复杂度提高: 硬生生加个 MQ 进来,你怎么保证消息没有重复消费?怎么处理消息丢失的情况?怎么保证消息传递的顺序性?问题一大堆。
-
一致性问题: A 系统处理完了直接返回成功了,人都以为你这个请求就成功了;但是问题是,要是BCD 三个系统那里,BD 两个系统写库成功了,结果 C 系统写库失败了,咋整?你这数据就不一致了。
如何保证幂等性
- 消息的唯一标识
- 数据库插入数据时,设置主键,避免重复插入
- 事务机制
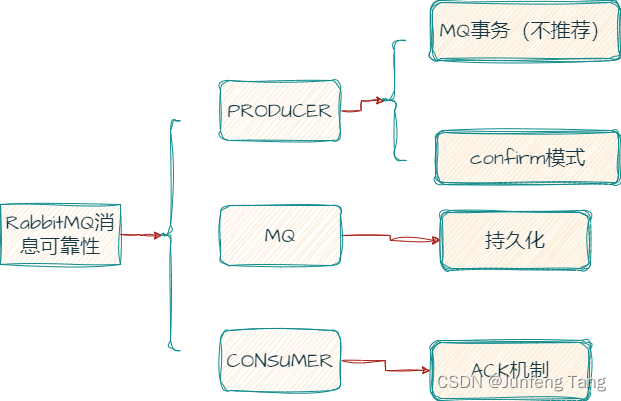
如何保证消息的可靠性
- 消息的确认机制
- 消息的持久化
- 重试机制
- 容错设计
MQ消息堆积怎么处理
- 增加消费者。
- 批处理
- 分析堆积原因,优化消费代码。