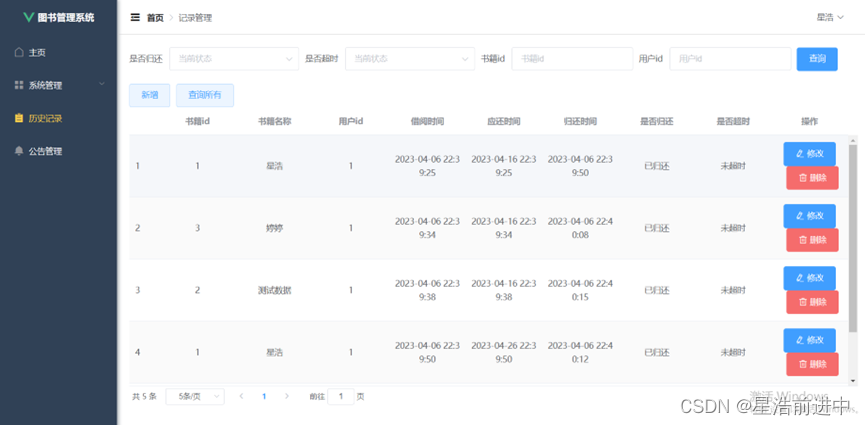
使用LLM在KG上进行复杂的逻辑推理
- 摘要
- 介绍
- 相关工作

摘要
在知识图谱上进行推理是一项具有挑战性的任务,这需要深度理解实体之间复杂的关系和它们关系的逻辑。而当前的方法通常依赖于学习 几何形状 以将实体嵌入到向量空间中进行逻辑查询操作,但在复杂查询和特定数据集表示方面表现不佳。
几何形状通常指的是将实体或关系映射到向量空间时所使用的几何结构或形状。几何形状嵌入方法通过学习实体和关系之间的几何关系,将它们映射到向量空间中的几何形状。这些几何形状可以是点、线、曲线等,它们在向量空间中的位置和距离可以反映实体和关系在知识图谱中的语义关系。
本文提出了一种新的 解耦(decoupled) 方法,即LARK,将复杂的KG推理定义为上下文KG搜索和逻辑查询推理的组合,以利用 图抽取算法(Graph extraction algorithms) 和大型语言模型(LLM)的优势。
“解耦方法”(Decoupling Method)通常指的是将复杂系统或问题分解为更简单、相互独立的组件或子问题的方法。
"Graph extraction algorithms"图抽取算法
用于从非结构化的文本数据中提取出图结构信息。这些算法将文本中的实体、关系和属性识别出来,并将它们表示为图的形式,其中实体作为节点,关系作为边连接节点。
Graph extraction算法的目标是将文本数据转化为结构化的图数据,以便进行图分析、图挖掘和知识图谱构建等任务。
实验证明,所提出的方法在多个逻辑查询构造上优于现有的KG推理方法,并在更复杂的查询中取得了显著的性能提升。此外,该方法的性能与底层LLM的规模增加成正比,从而使得最新的LLM在逻辑推理上能够得到整合。该方法为解决复杂KG推理的挑战提供了新的方向,并为未来在这一领域的研究铺平了道路。
介绍
知识图谱(KG)使用灵活的三元组模式来编码知识,其中两个实体节点通过关系边连接。然而,一些现实世界中的知识图谱,如Freebase、Yago和NELL等,通常是大规模的、噪声干扰和不完整的。因此,在这样的知识图谱上进行推理是人工智能研究中的一个基本且具有挑战性的问题。
逻辑推理的总体目标是利用存在量词(∃)、合取(∧)、析取(∨)和否定(¬)等一阶逻辑(FOL)查询的运算符,为知识图谱上的FOL查询开发回答机制。为了有效地捕捉知识图谱实体的语义位置和逻辑覆盖范围,当前研究主要集中在创建多样的潜在空间几何结构上,例如向量、盒子、双曲面和概率分布等。
尽管这些方法取得了成功,但它们在性能上存在以下限制:
- 复杂查询: 它们依赖于对 FOL查询 的限制形式,这导致丢失需要链式推理和涉及知识图谱中多个实体之间多个关系的复杂查询的信息;
- 泛化能力: 针对特定知识图谱的优化可能无法推广到其他知识图谱,这限制了这些方法在真实场景中的适用性,因为知识图谱在结构和内容上可以有很大的变化;
- 可扩展性: 繁重的训练时间限制了这些方法在更大的知识图谱上的可扩展性和将新数据纳入现有知识图谱的能力。
FOL查询是指一阶逻辑(First-Order Logic)中的查询操作。一阶逻辑是一种形式化的逻辑系统,用于描述和推理关于对象、关系和性质的命题。
在一阶逻辑中,FOL查询是对知识库或知识图谱中的事实和关系进行询问的方式。FOL查询使用一阶逻辑的语法和语义规则,结合存在量词 (∃)、合取 (∧)、析取 (∨) 和否定 (¬) 等逻辑运算符,以及变量和常量,来构造查询语句。查询语句由一个或多个谓词(表示关系)和变量组成,用于询问知识库中是否存在满足某些条件的事实或关系。
例如,假设有一个知识库包含关于人员的信息,其中包括实体 “John” 和 “Mary”,以及关系 “父亲” 和 “母亲”。我们可以构建一个FOL查询,如 “∃x 父亲(x, John)”,它询问是否存在一个实体 x,使得 x 是 John 的父亲。查询的回答可能是 “是” 或 “否”,表示是否存在满足查询条件的事实。
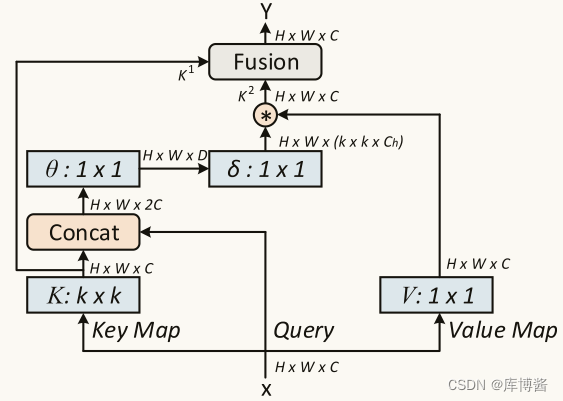
为了解决这些限制,本文旨在利用大型语言模型(LLM)的推理能力,在一种名为Language-guided Abstract Reasoning over Knowledge graphs(LARK)的新框架中进行推理,如图1所示。

在LARK中,利用逻辑查询在知识图谱上搜索相关的子图上下文,并使用逻辑分解的LLM提示进行链式推理。
为了实现这一目标,首先从输入查询和知识图谱中抽象出逻辑信息。由于逻辑的不变性,这使得我们的方法可以专注于逻辑形式化,避免模型的产生幻觉,并在不同的知识图谱上进行泛化。从这个抽象的知识图谱中,使用逻辑查询中存在的实体和关系提取相关的子图。这些子图作为上下文提示输入到LLMs中。在下一个阶段,需要有效处理复杂的推理查询。根据之前的研究,发现与一系列简单提示相比,LLMs在处理复杂提示时效果显著较差。因此,为了简化查询,利用它们的逻辑性质,将多操作查询确定性地分解为逻辑顺序的基本查询(从图1b到图1c的转换中所示)。然后,将这些分解的逻辑查询转换为提示,并通过LLM进行处理,生成最终的答案集(图1d所示)。逻辑查询按顺序处理,如果查询y依赖于查询x,则x在y之前调度。操作按逻辑顺序进行调度,以便将不同的逻辑查询进行批处理,并将答案存储在缓存中以便于访问。
逻辑分解是将复杂的多操作查询分解为一系列逻辑顺序的基本查询的过程。每个基本查询只包含一个操作,例如投影、交集、并集或否定。
本文提出的方法有效地将逻辑推理与知识图谱的能力与LLM的能力相结合,这是首次尝试。与先前依赖受限的一阶逻辑(FOL)查询形式的方法不同,该方法利用逻辑分解的LLM提示,实现了对从知识图谱中检索到的子图的链式推理,从而能够高效地利用LLM的推理能力。知识图谱搜索模型受到 检索增强技术 的启发,但实现了知识图谱的确定性特性,以简化相关子图的检索。此外,与其他提示方法相比,链式分解技术通过利用复杂查询中的逻辑操作链和以逻辑顺序利用后续查询中的先前答案,增强了知识图谱中的推理能力。
检索增强技术是一类用于改进信息检索系统性能的方法和技术。传统的信息检索系统通常基于关键词匹配或统计模型来检索和排名文档,但这些方法可能存在一些局限性,例如无法准确理解查询意图、无法处理复杂的查询或无法提供个性化的结果。
检索增强技术旨在克服这些限制,提高信息检索系统的效果和用户体验。
总结一下,本文的主要贡献如下:
- 提出了一种名为Language-guided Abstract Reasoning over Knowledge graphs(LARK)的新模型,利用大型语言模型的推理能力,高效地回答知识图谱上的FOL查询。
- 该模型利用查询中的实体和关系在抽象的知识图谱中找到相关的子图上下文,然后使用逻辑分解的查询的LLM提示在这些上下文中进行链式推理。
- 在标准知识图谱数据集上进行的逻辑推理实验表明,相对于基于投影(p)、交集(∧)、并集(∨)和否定(¬)等操作的14种FOL查询类型,LARK的MRR性能提升了33%至64%。
- 通过比较复杂查询和分解的逻辑查询,证明了链式分解的优势,LARK在逻辑推理任务上的性能比复杂查询提升了9%至24%。此外,对LLMs的分析显示了增加规模和更好设计的底层LLMs对LARK性能的重要贡献。
相关工作
本文涉及两个主题的交叉,即知识图谱上的逻辑推理和LLM中的推理提示技术。
知识图谱上的逻辑推理:这个领域的一开始的方法主要关注捕捉实体的语义信息以及它们之间的投影所涉及的关系操作。然而,该领域的进一步研究揭示了对编码知识图谱中存在的空间和层次信息的新几何形式的需求。为了解决这个问题,模型如Query2Box 、HypE 、PERM和BetaE将实体和关系编码为盒子、双曲面、高斯分布和贝塔分布。此外,CQD等方法专注于通过简单中间查询的答案组合来改进复杂推理任务的性能。在另一条研究线路中,HamQA 和QA-GNN 开发了利用知识图谱邻域增强整体性能的问答技术。先前的方法主要关注增强逻辑推理的知识图谱表示。与这些现有方法相反,本文提供了一个系统的框架,利用LLM的推理能力,并将其定制为解决知识图谱上的逻辑推理问题。
LLM中的推理提示:最近的研究表明,LLM可以通过上下文提示学习各种NLP任务。此外,LLM通过提供中间推理步骤(也称为思维链)成功应用于多步推理任务,这些步骤是到达答案所需的。另外,某些研究组合了多个LLM或带有符号函数的LLM来执行多步推理,并具有预定义的分解结构。最近的研究如least-to-most、successive 和decomposed 的提示策略将复杂提示分解为子提示,并按顺序回答它们以实现有效性能。虽然这些研究与本文的方法接近,但它们没有利用先前的答案来指导后续查询。
LARK是独特的,因为它能够利用链式分解机制中的逻辑结构,增强检索到的知识图谱邻域,并在连续查询中将前面的LLM答案纳入其中的多阶段回答结构。