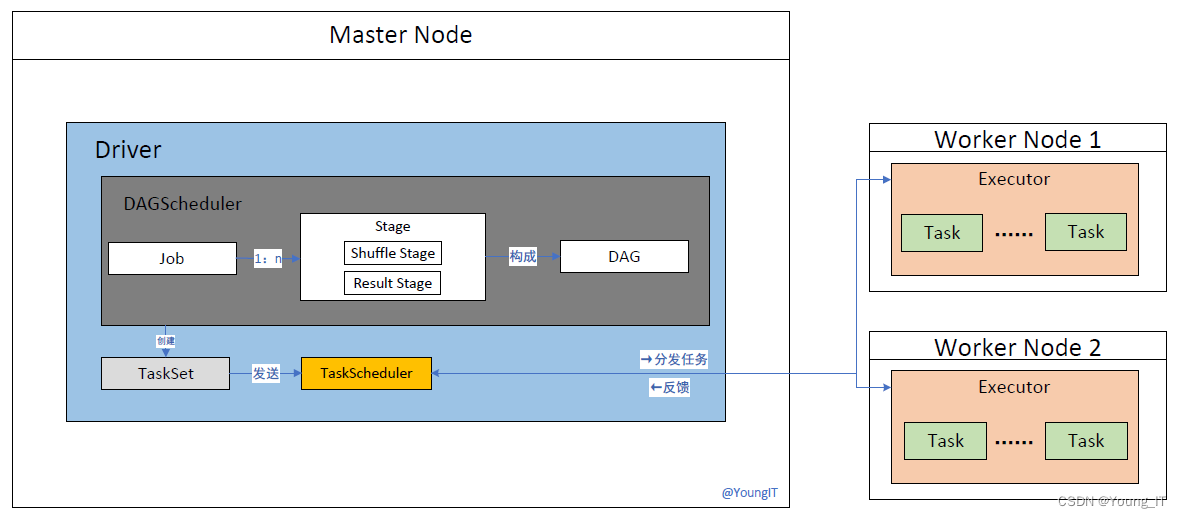
工作流程:
- Driver 创建 SparkSession 并将应用程序转化为执行计划,将作业划分为多个 Stage,并创建相应的 TaskSet。
- Driver 将 TaskSet 发送给 TaskScheduler 进行调度和执行。
- TaskScheduler 根据资源情况将任务分发给可用的 Executor 进程执行。
- Executor 加载数据并执行任务的操作,将计算结果保存在内存中。
- Executor 将任务的执行结果返回给 Driver。
- DAGScheduler 监控任务的执行状态和依赖关系,并根据需要调整任务的执行顺序和依赖关系。
- TaskScheduler 监控任务的执行状态和资源分配情况,负责任务的调度和重新执行。
在 Spark 中,有多个概念和组件相互协作,以实现分布式数据处理。下面是这些概念和组件的详细说明及它们之间的工作关系:
-
Driver(驱动器):
- Driver 是 Spark 应用程序的主要组件,负责整个应用程序的执行和协调。
- 它包含了应用程序的主函数,并将用户程序转化为执行计划。
- Driver 与集群管理器通信,请求资源,并监控应用程序的执行状态。
- 它还与 Executor 进程进行通信,发送任务并接收任务执行结果。
-
Executor(执行器):
- Executor 是运行在集群的工作节点上的进程,负责执行任务和计算。
- 它由集群管理器分配给应用程序,用于并行处理数据和执行操作。
- Executor 加载数据到内存中,并根据分配的任务执行相应的操作。
- 它将计算结果保存在内存中,并将结果返回给 Driver。
-
Application(应用程序):
- 应用程序是用户编写的 Spark 代码,用于数据处理和分析。
- 应用程序由 Driver 执行,将用户定义的操作转化为执行计划。
- 应用程序可以包含多个 Job,并且可以跨多个阶段进行分布式计算。
-
Job(作业):
- Job 是应用程序中的一个独立任务单元,由用户定义的操作组成。
- Job 定义了数据的转换和操作,可以包含多个 Stage。
-
Stage(阶段):
- Stage 是 Job 的子任务单位,有两种类型:Shuffle Stage 和 Result Stage。
- Shuffle Stage 包含需要进行数据洗牌的操作,如 groupByKey、reduceByKey 等。
- Result Stage 包含没有数据洗牌的操作,如 map、filter 等。
- Stage 通过依赖关系构成有向无环图(DAG),描述了数据的转换和操作流程。
-
TaskSet(任务集合):
- TaskSet 是一个 Stage 中所有任务的集合。
- TaskSet 中的任务是并行执行的,每个任务对应一部分数据的处理。
- TaskSet 由 Driver 创建,并发送给 TaskScheduler 进行调度和执行。
-
Task(任务):
- Task 是 Spark 中最小的执行单元,对应于一个数据分区的处理。
- 一个 Stage 中的任务数等于分区数,每个任务负责处理一个数据分区。
- 任务在 Executor 上执行,加载数据并执行用户定义的操作。
-
DAGScheduler(有向无环图调度器):
- DAGScheduler 负责将应用程序转化为有向无环图(DAG)的形式。
- 它根据任务之间的依赖关系,将 Job 划分为多个 Stage,并确定它们的执行顺序。
- DAGScheduler 将任务发送给 TaskScheduler 进行调度和执行。
-
TaskScheduler(任务调度器):
- TaskScheduler 是 Spark 中的任务调度器,负责将任务分发给 Executor 进程执行。
- 它根据资源需求和可用资源,将任务分配给合适的 Executor 进程。
- TaskScheduler 还负责监控任务的执行状态,处理任务失败和重试等情况。
关系:一个Driver可以产生多个Application;一个Application可以产生多个Job;一个Job对应多个Stage;一个Stage对应一个TaskSet(TaskSet是Stage内部调度的基本单位);一个Stage对应多个Task(一个TaskSet为一组Task集合);一个Task对应一个分区;
每个Application都有自己独立的执行环境和资源分配,它们之间相互独立,互不干扰。每个Application都会有自己的SparkContext,用于与集群进行通信和资源管理。
如有错误,欢迎指出!!!
如有错误,欢迎指出!!!
如有错误,欢迎指出!!!
扩展文章推荐:
1500字带你读懂 Spark任务的角色分工! - 知乎
一篇文章搞清spark任务如何执行 - 掘金
Spark[二]——Spark的组件们[Application、Job、Stage、TaskSet、Task] - 掘金