文章目录
- MySQL8窗口函数
- 前言
- 窗口函数相关概念介绍
- 窗口函数
- 分区介绍
- 窗口函数的使用
- 语法介绍
- 实战演练
- 示例一:聚合函数
- 示例二:排名函数
- 示例三:偏移函数
- 示例四:分布函数
- 示例五:首尾函数
- 示例六:其它函数
- 总结
MySQL8窗口函数

前言
花费30分钟的时间阅读本文,你将快速了解了解窗口函数的相关概念,以及如何使用,了解传统的聚合函数和窗口函数的区别。文中内容是博主阅读其它博主的博客、MySQL官方文档进行整理总结了,如果你觉得本文对你有所帮助,还请你不吝惜赐赞,你的支持将是我持续更新的动力
- MySQL8英文文档
- MySQL8中文文档
PS:如果文中存在侵权、错误、描述不当的地方,还请及时告知作者,博主将及时更正
窗口函数相关概念介绍
窗口函数
-
窗口函数是什么?
窗口函数(Window Function)是MySQL8新增的,是一种在查询结果中执行聚合、排序和分析操作的特殊函数。它可以结合分组、排序和窗口框架来计算行级别的结果,而不会改变查询结果的行数。
-
窗口框架是什么?
窗口框架(Window Frame)是用于定义窗口函数计算所需的数据范围的一种机制,它决定了在执行窗口函数时应该考虑哪些行为
窗口函数的计算通常是基于一个窗口框架来进行的,这个窗口框架可以通过以下方式指定:
- 不指定窗口框架:如果不显式指定窗口框架,则默认使用整个分区(partition)作为窗口框架。这意味着窗口函数将考虑分区内的所有行,相当于范围从分区的第一行到当前行的结束。
- 使用
ROWS关键字指定行数:可以通过使用ROWS关键字配合前后偏移量来指定窗口框架的行数范围。例如,ROWS 3PRECEDING表示窗口框架包括当前行及其之前的前三行,ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW表示窗口框架从分区的第一行到当前行的结束。 - 使用
RANGE关键字指定值的范围:有些窗口函数可以使用RANGE关键字来指定特定列值的范围,而不是行数。具体的范围将取决于数据的排序顺序和窗口函数的要求。
-
窗口函数的作用?
相较于之前本版提供的函数,窗口函数具有更强大和灵活的数据分析和处理能力。
- 分组计算:窗口函数可以对查询结果按照指定的分组方式进行计算。通过使用
PARTITION BY子句,可以将数据划分为多个分组,然后在每个分组内对数据进行聚合、排序或统计等操作。这样可以方便地对每个分组内的数据进行分析和比较。 - 排序和排名:窗口函数提供了对查询结果集中的行进行排序和排名的功能。使用
ORDER BY子句,可以指定窗口函数的排序规则,从而按照指定的顺序对数据进行排序。通过使用窗口函数如ROW_NUMBER()、RANK()和DENSE_RANK(),可以为每一行分配一个唯一的编号或排名,以便进行进一步的分析和筛选。 - 窗口框架计算:窗口函数可以基于指定的窗口框架来计算结果。窗口框架定义了用于计算窗口函数的数据范围,可以包括当前行及其前后若干行。通过使用窗口函数如
LAG()和LEAD(),可以获取当前行之前或之后的特定行的值,方便进行与前后行相关的计算和分析。 - 数据处理与分析:窗口函数可以实现复杂的数据处理和分析逻辑。例如,使用窗口函数如
SUM()、AVG()、MAX()和MIN(),可以对某个分组内的数据进行求和、平均值、最大值和最小值等聚合操作。通过结合其他SQL语句,如WHERE子句和HAVING子句,可以进一步筛选和条件过滤窗口函数的结果。
- 分组计算:窗口函数可以对查询结果按照指定的分组方式进行计算。通过使用
-
窗口函数的分类
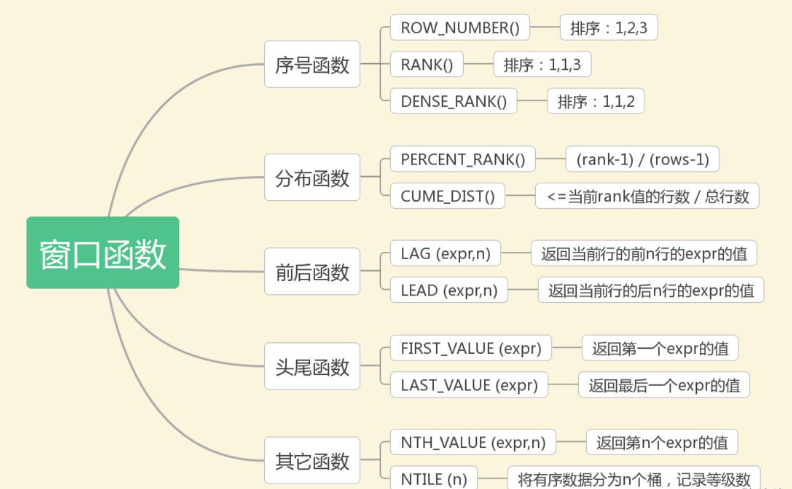
分类 描述 聚合函数 对每个分组中的行进行计算,并返回单个结果。例如,SUM、AVG、MIN、MAX等。 排名函数 基于指定的排序规则为每一行分配一个排名值。例如,ROW_NUMBER、RANK、DENSE_RANK等。 偏移函数 计算当前行与指定偏移量的行之间的值。例如,Lag、Lead等。 分布函数 将某一列的值划分成多个区间,并计算每个区间内的统计结果。例如,NTILE、PERCENT_RANK等。 首尾函数 First_Value和Last_Value、返回指定列在窗口范围内的第一个和最后一个非空值。 其他函数 NTILE(n)和NTH_VALUE(expr, n),将查询结果划分为n个分组,返回第n个expr的值 -
窗口函数与聚合函数的区别
- 计算范围不同:窗口函数计算范围是行级别的,聚合函数是结果集级别的
- 窗口函数是行级别的。窗口函数在每一行上进行计算,并可以根据定义的窗口框架来确定计算的范围。因此,窗口函数的计算范围是相对于每一行的,不改变行数。
- 聚合函数是结果集级别的。聚合函数将多行数据汇总为一个单一的值,计算的范围是整个结果集。
- 结果展示方式:窗口函数不会减少查询结果的行数,聚合函数可能会减少查询结果的行数
- 窗口函数的结果则可以与原始数据一起显示,不会减少查询结果的行数。
- 聚合函数的结果通常作为结果集的一部分返回,或者在
GROUP BY子句中使用,可能会减少查询结果的行数。
- 分组方式不同:窗口函数支持分组,聚合函数不支持分组
- 窗口函数本身支持分组,窗口函数可以通过
OVER子句的PARTITION BY子句来实现分组,不同的是窗口函数并不改变行的分组。 - 聚合函数本身不支持分组,聚合函数通常需要与
GROUP BY子句一起使用,以指定分组的列,对每个组进行聚合计算
- 窗口函数本身支持分组,窗口函数可以通过
- 排序方式不同:窗口函数支持排序,聚合函数不支持排序
- 窗口函数支持排序。窗口函数可以使用
ORDER BY子句对结果进行排序,通过指定排序的列,我们可以按照特定的顺序来计算窗口函数的结果。 - 聚合函数不支持排序。聚合函数是对一组行进行计算,并返回一个单一的结果,它们并没有内置的排序功能。如果需要对聚合函数的结果进行排序,通常需要将聚合函数的结果作为子查询的一部分,并在外部查询中使用 order by 子句来完成排序操作。
- 窗口函数支持排序。窗口函数可以使用
- 数据处理能力不同:窗口函数对于数据的处理能力更强
- 窗口函数可以在查询结果的基础上进行更复杂的数据处理和分析操作,例如在特定分组内获取前后行的值、计算累计和等
- 聚合函数主要用于简单的汇总计算,不具备类似的数据处理能力。
总体而言,聚合函数用于对整个结果集进行汇总计算,返回单一值或少量行;而窗口函数则在每一行上进行计算,并可以根据定义的窗口框架来控制计算的范围和排序规则。窗口函数提供了更灵活和强大的数据分析和处理功能,适用于复杂的数据分析需求。
- 计算范围不同:窗口函数计算范围是行级别的,聚合函数是结果集级别的
分区介绍
-
分区是什么?
在SQL中,分区(Partition)是将表或索引数据划分为逻辑上相互独立的部分的过程。通过分区,可以将大型表或索引拆分为更小、更可管理的单元,从而提高查询性能、简化维护和管理,并满足特定的数据处理需求。
具体来说,分区是将数据按照某个指定的规则进行划分,并将每个划分后的数据存储到不同的物理存储位置上。这个划分规则可以基于列值范围、列值列表、哈希函数、日期范围等多种方式进行定义。
注意:分区功能在不同的数据库管理系统中可能有所差异,包括支持的分区类型、划分规则和分区操作等。因此,在具体使用分区功能时,需要根据所使用的数据库系统来了解和应用相应的分区机制。
-
为什么需要分区?(分区的作用)
- 提高查询性能:将大型表分成小块,可以使查询仅针对特定分区进行,减少扫描和过滤的数据量,提高查询效率。
- 简化维护和管理:通过分区可以更方便地进行备份、恢复、数据加载和数据清理等操作,减轻了整个表的操作负担。
- 实现数据生命周期管理:可以根据数据的使用频率和重要性,将数据划分到不同的分区中,并灵活地控制数据的存储周期和访问权限。
- 支持并行处理:分区可以让多个查询同时处理不同的分区,从而实现并行执行,提高整体系统的处理能力。
窗口函数的使用
语法介绍
window_function_name(expression)OVER ([PARTITION BY <列1>, <列2> ...][ORDER BY <列1>, <列2> ...][frame_definition])
-
window_function_name:用于指定窗口函数,用于对特定的窗口框架内的数据进行计算和处理
常见的窗口函数如下所示:
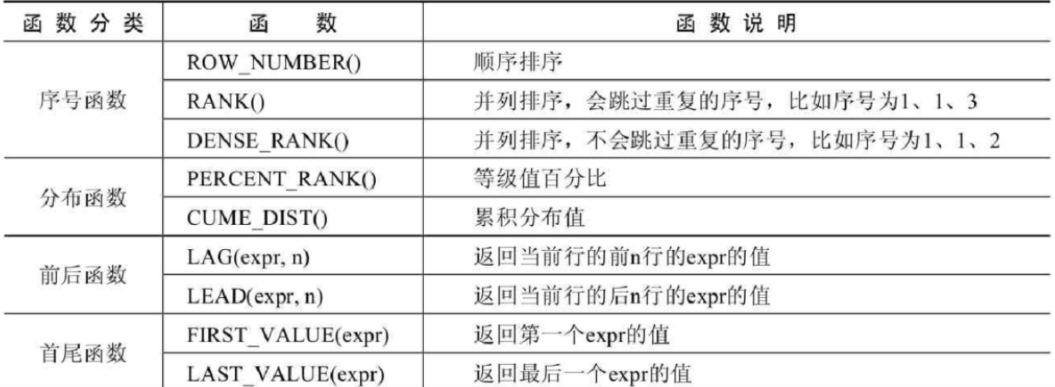
ROW_NUMBER():为每一行分配一个唯一的序号,按照指定的排序顺序进行编号。RANK():对查询结果集中的行进行排名,相同值将获得相同的排名,下一个排名将会跳过相应数量的序号。DENSE_RANK():对查询结果集中的行进行连续排名,相同值将获得相同的排名,没有间隔。CUME_DIST(): 返回当前行与结果集中所有行的累积分布比值,计算方式 r o w _ n u m b e r / r o w s row\_number/rows row_number/rows。PERCENT_RANK(): 返回当前行的排名与结果集中所有行的百分比排名,计算方式 ( r o w − 1 ) / ( r o w s − 1 ) (row-1) / (rows-1) (row−1)/(rows−1)。LAG():获取当前行之前指定偏移量的行的值。LEAD():获取当前行之后指定偏移量的行的值。FIRST_VALUE():获取分组内的第一个值。LAST_VALUE():获取分组内的最后一个值。SUM()、AVG()、MAX()、MIN()等窗口聚合函数:但与普通聚合函数不同的是,窗口聚合函数可以在不改变行数的情况下计算聚合结果。NTILE(n):将查询结果划分为n个分组,并为每个分组分配一个标识值。NTH_VALUE(expr, n): 返回窗口中第n个 expr 的值(expr可以是表达式,也可以是列名)
-
OVER:关键字,表示接下来的是一个窗口函数的定义。VOER后面括号种的内容可以 -
PARTITION BY:子句,用于将查询结果集划分为多个分区。可以根据指定的列或表达式对数据进行分组,每个分区内的数据将作为窗口函数的独立计算单元。可以不填,如果不填表示不进行分区常见的取值有以下几种:
- 列名:可以指定一个或多个列名作为分区键。根据这些列的值将数据行分组到不同的分区中。
- 表达式:可以使用任意有效的表达式作为分区键。这可以是一个简单的算术表达式、函数调用或条件语句。
- 列编号:可以使用列的位置编号作为分区键。例如,1表示第一个列,2表示第二个列,以此类推。
- 列别名:如果在查询中使用了AS关键字来为列指定别名,那么该别名也可以在PARTITION BY子句中使用。
-
ORDER BY:子句,用于指定分区内行的排序方式。可以根据指定的列或表达式对分区内的数据进行排序,以便在窗口函数中基于排序顺序进行计算。常见的取值有以下几种:
- 列名:可以使用查询结果集中存在的列名作为排序键。例如,ORDER BY column_name。
- 表达式:可以使用任意有效的表达式作为排序键。这可以是一个简单的算术表达式、函数调用或条件语句。例如,ORDER BY expression。
- 列编号:可以使用列的位置编号作为排序键。例如,1表示第一个列,2表示第二个列,以此类推。例如,ORDER BY 1。
- 别名:如果在查询中使用了AS关键字为列指定别名,那么该别名也可以在ORDER BY子句中使用。例如,ORDER BY alias_name。
- 多列排序:可以按照多个列进行排序。在ORDER BY子句中,可以同时指定多个列名,并按照它们的顺序进行排序。例如,ORDER BY column1, column2。
-
frame_definition(可选):指定窗口函数操作的行范围常见的取值有以下几种:
-
ROWS:使用ROWS关键字来指定基于行的窗口范围。可以使用以下语法来定义行范围:frame_definition = {ROWS | ROWS BETWEEN start_expr AND end_expr}ROWS:表示窗口的行范围是从开始到结束的行数。- start_expr和end_expr:用于指定行范围的起始和结束位置,可以使用以下表达式:
UNBOUNDED PRECEDING:表示从窗口的第一行开始。CURRENT ROW:表示当前行。{integer} PRECEDING:表示当前行的前{integer}行。{integer} FOLLOWING:表示当前行的后{integer}行。
-
RANGE:使用RANGE关键字来指定基于值的窗口范围。可以使用以下语法来定义值范围:
frame_definition = RANGE | RANGE BETWEEN start_expr AND end_expr }RANGE:表示窗口的值范围是从开始到结束的数据的值范围。start_expr和end_expr:用于指定值范围的起始和结束位置。
注意:起始和结束位置通常是基于排序字段的值,而不是行数
-
INTERVAL:INTERVAL关键字用于指定基于值的范围时的间隔大小。它可以与RANGE关键字一起使用。常见取值:
YEAR或YEARS:年MONTH或MONTHS:月DAY或DAYS:日HOUR或HOURS:小时MINUTE或MINUTES:分钟SECOND或SECONDS:秒
下面是演示查询近七天产品的销售总额(可以看到十分简单,如果使用原始的聚合函数将十分复杂)
下面两条SQL是查询近七天(天数的连续的)销售总额
SUM(amount) OVER (ORDER BY sales_date RANGE INTERVAL 6 DAY PRECEDING)备注:注意是连续的七天,从前六天开始到当前这一天所有销售额的总和
-
实战演练
温馨提示:由于文章篇幅优先,这里也只是列举了部分窗口函数的基础用法,关于窗口函数更加详细完整的用法大家可以去参考MySQL8官方使用手册:
- MySQL8英文文档
- MySQL8中文文档
建立如下一张 employee表:
-- 员工表
drop table if exists `employee`;
create table if not exists `employee`
(`eid` int not null auto_increment comment '员工id' primary key,`emp_name` varchar(20) not null comment '员工名称',`dep_name` varchar(50) not null comment '部门名称',`hiredate` date not null comment '入职日期',`salary` double null comment '薪资'
) comment '员工表';-- 插入数据
insert into `employee` (`emp_name`, `dep_name`, `hiredate`, `salary`) values ('傅嘉熙', '开发部', '2022-08-20 12:00:04', 9000);
insert into `employee` (`emp_name`, `dep_name`, `hiredate`, `salary`) values ('武晟睿', '开发部', '2022-06-12 13:54:12', 9500);
insert into `employee` (`emp_name`, `dep_name`, `hiredate`, `salary`) values ('孙弘文', '开发部', '2022-10-16 08:27:06', 9400);
insert into `employee` (`emp_name`, `dep_name`, `hiredate`, `salary`) values ('潘乐驹', '开发部', '2022-04-22 03:56:11', 9500);
insert into `employee` (`emp_name`, `dep_name`, `hiredate`, `salary`) values ('潘昊焱', '人事部', '2022-02-24 03:40:02', 5000);
insert into `employee` (`emp_name`, `dep_name`, `hiredate`, `salary`) values ('沈涛', '人事部', '2022-12-14 09:16:37', 6000);
insert into `employee` (`emp_name`, `dep_name`, `hiredate`, `salary`) values ('江峻熙', '人事部', '2022-05-12 01:17:48', 5000);
insert into `employee` (`emp_name`, `dep_name`, `hiredate`, `salary`) values ('陆远航', '人事部', '2022-04-14 03:35:57', 5500);
insert into `employee` (`emp_name`, `dep_name`, `hiredate`, `salary`) values ('姜煜祺', '销售部', '2022-03-23 03:21:05', 6000);
insert into `employee` (`emp_name`, `dep_name`, `hiredate`, `salary`) values ('邹明', '销售部', '2022-11-23 23:10:06', 6800);
insert into `employee` (`emp_name`, `dep_name`, `hiredate`, `salary`) values ('董擎苍', '销售部', '2022-02-12 07:54:32', 6500);
insert into `employee` (`emp_name`, `dep_name`, `hiredate`, `salary`) values ('钟俊驰', '销售部', '2022-04-10 12:17:06', 6000);-- 查询数据
select * from employee;
+-----+----------+----------+------------+--------+
| eid | emp_name | dep_name | hiredate | salary |
+-----+----------+----------+------------+--------+
| 1 | 傅嘉熙 | 开发部 | 2022-08-20 | 9000 |
| 2 | 武晟睿 | 开发部 | 2022-06-12 | 9500 |
| 3 | 孙弘文 | 开发部 | 2022-10-16 | 9400 |
| 4 | 潘乐驹 | 开发部 | 2022-04-22 | 9500 |
| 5 | 潘昊焱 | 人事部 | 2022-02-24 | 5000 |
| 6 | 沈涛 | 人事部 | 2022-12-14 | 6000 |
| 7 | 江峻熙 | 人事部 | 2022-05-12 | 5000 |
| 8 | 陆远航 | 人事部 | 2022-04-14 | 5500 |
| 9 | 姜煜祺 | 销售部 | 2022-03-23 | 6000 |
| 10 | 邹明 | 销售部 | 2022-11-23 | 6800 |
| 11 | 董擎苍 | 销售部 | 2022-02-12 | 6500 |
| 12 | 钟俊驰 | 销售部 | 2022-04-10 | 6000 |
+-----+----------+----------+------------+--------+
示例一:聚合函数
需求:查询每个部门员工的平均薪资
1)使用聚合函数
select dep_name, avg(salary) avg from employee group by dep_name;
+----------+------+
| dep_name | avg |
+----------+------+
| 开发部 | 9350 |
| 人事部 | 5375 |
| 销售部 | 6325 |
+----------+------+
2)使用窗口函数
select dep_name, avg(salary) over(partition by dep_name) avg from employee;
+----------+------+
| dep_name | avg |
+----------+------+
| 人事部 | 5375 |
| 人事部 | 5375 |
| 人事部 | 5375 |
| 人事部 | 5375 |
| 开发部 | 9350 |
| 开发部 | 9350 |
| 开发部 | 9350 |
| 开发部 | 9350 |
| 销售部 | 6325 |
| 销售部 | 6325 |
| 销售部 | 6325 |
| 销售部 | 6325 |
+----------+------+
如果添加员工order by子句
+----------+-------------------+
| dep_name | avg |
+----------+-------------------+
| 人事部 | 5000 |
| 人事部 | 5000 |
| 人事部 | 5166.666666666667 |
| 人事部 | 5375 |
| 开发部 | 9000 |
| 开发部 | 9200 |
| 开发部 | 9350 |
| 开发部 | 9350 |
| 销售部 | 6000 |
| 销售部 | 6000 |
| 销售部 | 6166.666666666667 |
| 销售部 | 6325 |
+----------+-------------------+
通过order by改变了窗口的范围,也就是自上而下累加求平均,而对于没有order by是直接平均所有的值

需求2:查询每一个部门所有员工的薪资总和
1)使用聚合函数查询
select dep_name, sum(salary) sum
from employee
group by dep_name;
+----------+-------+
| dep_name | sum |
+----------+-------+
| 开发部 | 37400 |
| 人事部 | 21500 |
| 销售部 | 25300 |
+----------+-------+
2)使用窗口函数查询
select dep_name, salary, sum(salary) over(partition by dep_name) sum
from employee;
+----------+--------+-------+
| dep_name | salary | sum |
+----------+--------+-------+
| 人事部 | 5000 | 21500 |
| 人事部 | 6000 | 21500 |
| 人事部 | 5000 | 21500 |
| 人事部 | 5500 | 21500 |
| 开发部 | 9000 | 37400 |
| 开发部 | 9500 | 37400 |
| 开发部 | 9400 | 37400 |
| 开发部 | 9500 | 37400 |
| 销售部 | 6000 | 25300 |
| 销售部 | 6800 | 25300 |
| 销售部 | 6500 | 25300 |
| 销售部 | 6000 | 25300 |
+----------+--------+-------+
如果我们添加一个 order by 字句,结果将会是累加展示的:
select dep_name, salary, sum(salary) over(partition by dep_name order by salary) sum
from employee;
+----------+--------+-------+
| dep_name | salary | sum |
+----------+--------+-------+
| 人事部 | 5000 | 10000 |
| 人事部 | 5000 | 10000 |
| 人事部 | 5500 | 15500 |
| 人事部 | 6000 | 21500 |
| 开发部 | 9000 | 9000 |
| 开发部 | 9400 | 18400 |
| 开发部 | 9500 | 37400 |
| 开发部 | 9500 | 37400 |
| 销售部 | 6000 | 12000 |
| 销售部 | 6000 | 12000 |
| 销售部 | 6500 | 18500 |
| 销售部 | 6800 | 25300 |
+----------+--------+-------+
总结:可以看到,如果使用聚合函数,需要通过分组才能计算出一个部门所有员工的总薪资,同时得到的结果是聚合后的结果,无法展示所有的记录,而使用窗口函数,不需要分组即可得到一整年的销售额,得到的结果可以展示全部记录
示例二:排名函数
需求:计算每个部门的薪资排行榜
1)聚合函数
select e2.dep_name,e2.salary,(select count(*) + 1from employee e1where e1.dep_name = e2.dep_name and e1.salary < e2.salary) `rank`
from employee e2
order by e2.dep_name, e2.salary;
+----------+--------+------+
| dep_name | salary | rank |
+----------+--------+------+
| 人事部 | 5000 | 1 |
| 人事部 | 5000 | 1 |
| 人事部 | 5500 | 3 |
| 人事部 | 6000 | 4 |
| 开发部 | 9000 | 1 |
| 开发部 | 9400 | 2 |
| 开发部 | 9500 | 3 |
| 开发部 | 9500 | 3 |
| 销售部 | 6000 | 1 |
| 销售部 | 6000 | 1 |
| 销售部 | 6500 | 3 |
| 销售部 | 6800 | 4 |
+----------+--------+------+
2)窗口函数
select dep_name, salary, row_number() over(partition by dep_name order by salary) `rank`from employee;
+----------+--------+------+
| dep_name | salary | rank |
+----------+--------+------+
| 人事部 | 5000 | 1 |
| 人事部 | 5000 | 2 |
| 人事部 | 5500 | 3 |
| 人事部 | 6000 | 4 |
| 开发部 | 9000 | 1 |
| 开发部 | 9400 | 2 |
| 开发部 | 9500 | 3 |
| 开发部 | 9500 | 4 |
| 销售部 | 6000 | 1 |
| 销售部 | 6000 | 2 |
| 销售部 | 6500 | 3 |
| 销售部 | 6800 | 4 |
+----------+--------+------+
示例三:偏移函数
需求:对各部门的员工按照薪资升序排序,然后计算每一个员工与前一个员工薪资的差值,如果前一个员工不存在则保留
select dep_name, emp_name, salary, lag(salary, 1) over(partition by dep_name order by salary) pre_salary
from employee;
+----------+----------+--------+------------+
| dep_name | emp_name | salary | pre_salary |
+----------+----------+--------+------------+
| 人事部 | 潘昊焱 | 5000 | NULL |
| 人事部 | 江峻熙 | 5000 | 5000 |
| 人事部 | 陆远航 | 5500 | 5000 |
| 人事部 | 沈涛 | 6000 | 5500 |
| 开发部 | 傅嘉熙 | 9000 | NULL |
| 开发部 | 孙弘文 | 9400 | 9000 |
| 开发部 | 武晟睿 | 9500 | 9400 |
| 开发部 | 潘乐驹 | 9500 | 9500 |
| 销售部 | 姜煜祺 | 6000 | NULL |
| 销售部 | 钟俊驰 | 6000 | 6000 |
| 销售部 | 董擎苍 | 6500 | 6000 |
| 销售部 | 邹明 | 6800 | 6500 |
+----------+----------+--------+------------+
select *, if(pre_salary is null, salary, pre_salary-salary) dif_salary
from(select dep_name, emp_name, salary, lag(salary, 1) over(partition by dep_name order by salary) pre_salary from employee
) t
+----------+----------+--------+------------+------------+
| dep_name | emp_name | salary | pre_salary | dif_salary |
+----------+----------+--------+------------+------------+
| 人事部 | 潘昊焱 | 5000 | NULL | 5000 |
| 人事部 | 江峻熙 | 5000 | 5000 | 0 |
| 人事部 | 陆远航 | 5500 | 5000 | -500 |
| 人事部 | 沈涛 | 6000 | 5500 | -500 |
| 开发部 | 傅嘉熙 | 9000 | NULL | 9000 |
| 开发部 | 孙弘文 | 9400 | 9000 | -400 |
| 开发部 | 武晟睿 | 9500 | 9400 | -100 |
| 开发部 | 潘乐驹 | 9500 | 9500 | 0 |
| 销售部 | 姜煜祺 | 6000 | NULL | 6000 |
| 销售部 | 钟俊驰 | 6000 | 6000 | 0 |
| 销售部 | 董擎苍 | 6500 | 6000 | -500 |
| 销售部 | 邹明 | 6800 | 6500 | -300 |
+----------+----------+--------+------------+------------+
示例四:分布函数
示例:查询每个部门,工资小于等于当前员工薪资的比例
select dep_name, emp_name, salary, cume_dist() over(partition by dep_name order by salary) lower
from employee
+----------+----------+--------+-------+
| dep_name | emp_name | salary | lower |
+----------+----------+--------+-------+
| 人事部 | 潘昊焱 | 5000 | 0.5 |
| 人事部 | 江峻熙 | 5000 | 0.5 |
| 人事部 | 陆远航 | 5500 | 0.75 |
| 人事部 | 沈涛 | 6000 | 1 |
| 开发部 | 傅嘉熙 | 9000 | 0.25 |
| 开发部 | 孙弘文 | 9400 | 0.5 |
| 开发部 | 武晟睿 | 9500 | 1 |
| 开发部 | 潘乐驹 | 9500 | 1 |
| 销售部 | 姜煜祺 | 6000 | 0.5 |
| 销售部 | 钟俊驰 | 6000 | 0.5 |
| 销售部 | 董擎苍 | 6500 | 0.75 |
| 销售部 | 邹明 | 6800 | 1 |
+----------+----------+--------+-------+
需求:查询每个部门,工资小于当前员工薪资的比例
备注:
- 如果是升序排列,前面比你小的还有多少
- 如果是降序排列,前面比你大的还有多少
select dep_name, emp_name, salary, percent_rank() over(partition by dep_name order by salary) lower
from employee
+----------+----------+--------+--------------------+
| dep_name | emp_name | salary | lower |
+----------+----------+--------+--------------------+
| 人事部 | 潘昊焱 | 5000 | 0 |
| 人事部 | 江峻熙 | 5000 | 0 |
| 人事部 | 陆远航 | 5500 | 0.6666666666666666 |
| 人事部 | 沈涛 | 6000 | 1 |
| 开发部 | 傅嘉熙 | 9000 | 0 |
| 开发部 | 孙弘文 | 9400 | 0.3333333333333333 |
| 开发部 | 武晟睿 | 9500 | 0.6666666666666666 |
| 开发部 | 潘乐驹 | 9500 | 0.6666666666666666 |
| 销售部 | 姜煜祺 | 6000 | 0 |
| 销售部 | 钟俊驰 | 6000 | 0 |
| 销售部 | 董擎苍 | 6500 | 0.6666666666666666 |
| 销售部 | 邹明 | 6800 | 1 |
+----------+----------+--------+--------------------+
示例五:首尾函数
需求:查询各部门薪资最高的员工信息
select *, first_value(salary) over(partition by dep_name order by salary desc) top
from employee;
+-----+----------+----------+------------+--------+------+
| eid | emp_name | dep_name | hiredate | salary | top |
+-----+----------+----------+------------+--------+------+
| 6 | 沈涛 | 人事部 | 2022-12-14 | 6000 | 6000 |
| 8 | 陆远航 | 人事部 | 2022-04-14 | 5500 | 6000 |
| 5 | 潘昊焱 | 人事部 | 2022-02-24 | 5000 | 6000 |
| 7 | 江峻熙 | 人事部 | 2022-05-12 | 5000 | 6000 |
| 2 | 武晟睿 | 开发部 | 2022-06-12 | 9500 | 9500 |
| 4 | 潘乐驹 | 开发部 | 2022-04-22 | 9500 | 9500 |
| 3 | 孙弘文 | 开发部 | 2022-10-16 | 9400 | 9500 |
| 1 | 傅嘉熙 | 开发部 | 2022-08-20 | 9000 | 9500 |
| 10 | 邹明 | 销售部 | 2022-11-23 | 6800 | 6800 |
| 11 | 董擎苍 | 销售部 | 2022-02-12 | 6500 | 6800 |
| 9 | 姜煜祺 | 销售部 | 2022-03-23 | 6000 | 6800 |
| 12 | 钟俊驰 | 销售部 | 2022-04-10 | 6000 | 6800 |
+-----+----------+----------+------------+--------+------+
示例六:其它函数
需求:获取各部梦薪资排名第2的员工信息
select * ,
nth_value(salary, 2) over(partition by dep_name order by salary desc) second
from employee;
+-----+----------+----------+------------+--------+--------+
| eid | emp_name | dep_name | hiredate | salary | second |
+-----+----------+----------+------------+--------+--------+
| 6 | 沈涛 | 人事部 | 2022-12-14 | 6000 | NULL |
| 8 | 陆远航 | 人事部 | 2022-04-14 | 5500 | 5500 |
| 5 | 潘昊焱 | 人事部 | 2022-02-24 | 5000 | 5500 |
| 7 | 江峻熙 | 人事部 | 2022-05-12 | 5000 | 5500 |
| 2 | 武晟睿 | 开发部 | 2022-06-12 | 9500 | 9500 |
| 4 | 潘乐驹 | 开发部 | 2022-04-22 | 9500 | 9500 |
| 3 | 孙弘文 | 开发部 | 2022-10-16 | 9400 | 9500 |
| 1 | 傅嘉熙 | 开发部 | 2022-08-20 | 9000 | 9500 |
| 10 | 邹明 | 销售部 | 2022-11-23 | 6800 | NULL |
| 11 | 董擎苍 | 销售部 | 2022-02-12 | 6500 | 6500 |
| 9 | 姜煜祺 | 销售部 | 2022-03-23 | 6000 | 6500 |
| 12 | 钟俊驰 | 销售部 | 2022-04-10 | 6000 | 6500 |
+-----+----------+----------+------------+--------+--------+
备注:窗口大小是逐渐往下扩张的,所以有些窗口中的第一条记录是null,因为第一条记录是最大值的缘故
如果我要查询每个部门排名第三的工资,可以看到出现 null 的记录更多了,排名第一和排名第二的工资那行直接为null了
+-----+----------+----------+------------+--------+--------+
| eid | emp_name | dep_name | hiredate | salary | second |
+-----+----------+----------+------------+--------+--------+
| 6 | 沈涛 | 人事部 | 2022-12-14 | 6000 | NULL |
| 8 | 陆远航 | 人事部 | 2022-04-14 | 5500 | NULL |
| 5 | 潘昊焱 | 人事部 | 2022-02-24 | 5000 | 5000 |
| 7 | 江峻熙 | 人事部 | 2022-05-12 | 5000 | 5000 |
| 2 | 武晟睿 | 开发部 | 2022-06-12 | 9500 | NULL |
| 4 | 潘乐驹 | 开发部 | 2022-04-22 | 9500 | NULL |
| 3 | 孙弘文 | 开发部 | 2022-10-16 | 9400 | 9400 |
| 1 | 傅嘉熙 | 开发部 | 2022-08-20 | 9000 | 9400 |
| 10 | 邹明 | 销售部 | 2022-11-23 | 6800 | NULL |
| 11 | 董擎苍 | 销售部 | 2022-02-12 | 6500 | NULL |
| 9 | 姜煜祺 | 销售部 | 2022-03-23 | 6000 | 6000 |
| 12 | 钟俊驰 | 销售部 | 2022-04-10 | 6000 | 6000 |
+-----+----------+----------+------------+--------+--------+
总结
通过以上的介绍,我们了解了窗口函数的相关概念,什么是窗口函数?什么是窗口?什么是窗口框架?窗口函数的作用?什么是分区?分区的作用?以及窗口函数的基本语法,如何使用等等相关知识,总的来讲,窗口函数是MySQL8的一个十分重要且有用的特性,这一点可能我们现在还无法深刻的感知到,我们可以通过刷题来感受到窗口函数的强大,这里推荐一下我的SQL刷题专栏:LeetCode高频SQL100_知识汲取者的博客-CSDN博客,感兴趣的可以关注博主,一起参与每天的打卡
参考资料:
- MySQL 窗口函数 | 新手教程 (begtut.com)
- 【数据库高级】Mysql窗口函数的使用和练习