安装JDK1.8
这里最好是安装1.8版本的jdk
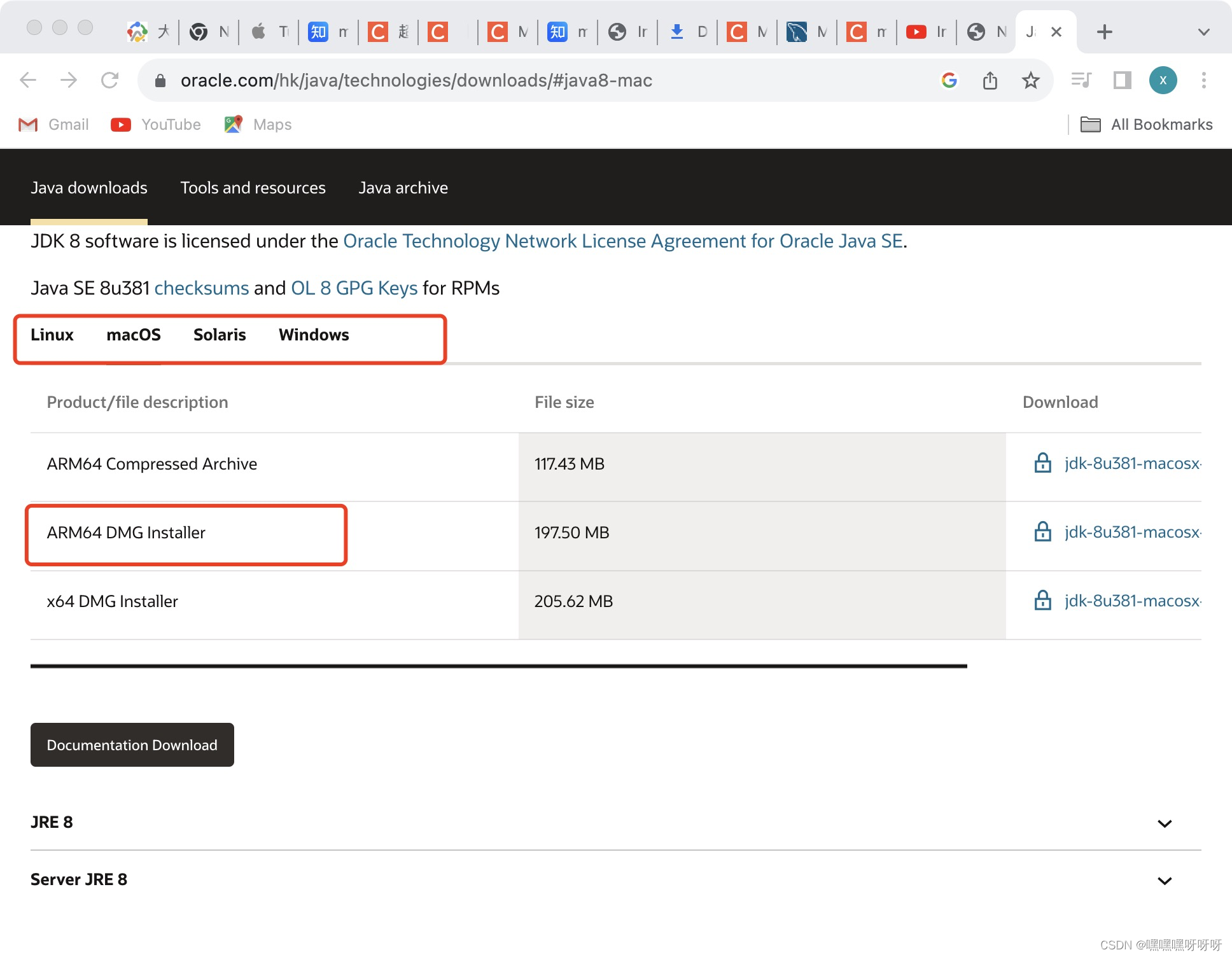
1. 进入官网Java Downloads | Oracle Hong Kong SAR, PRC,下滑到中间区域找到JDK8
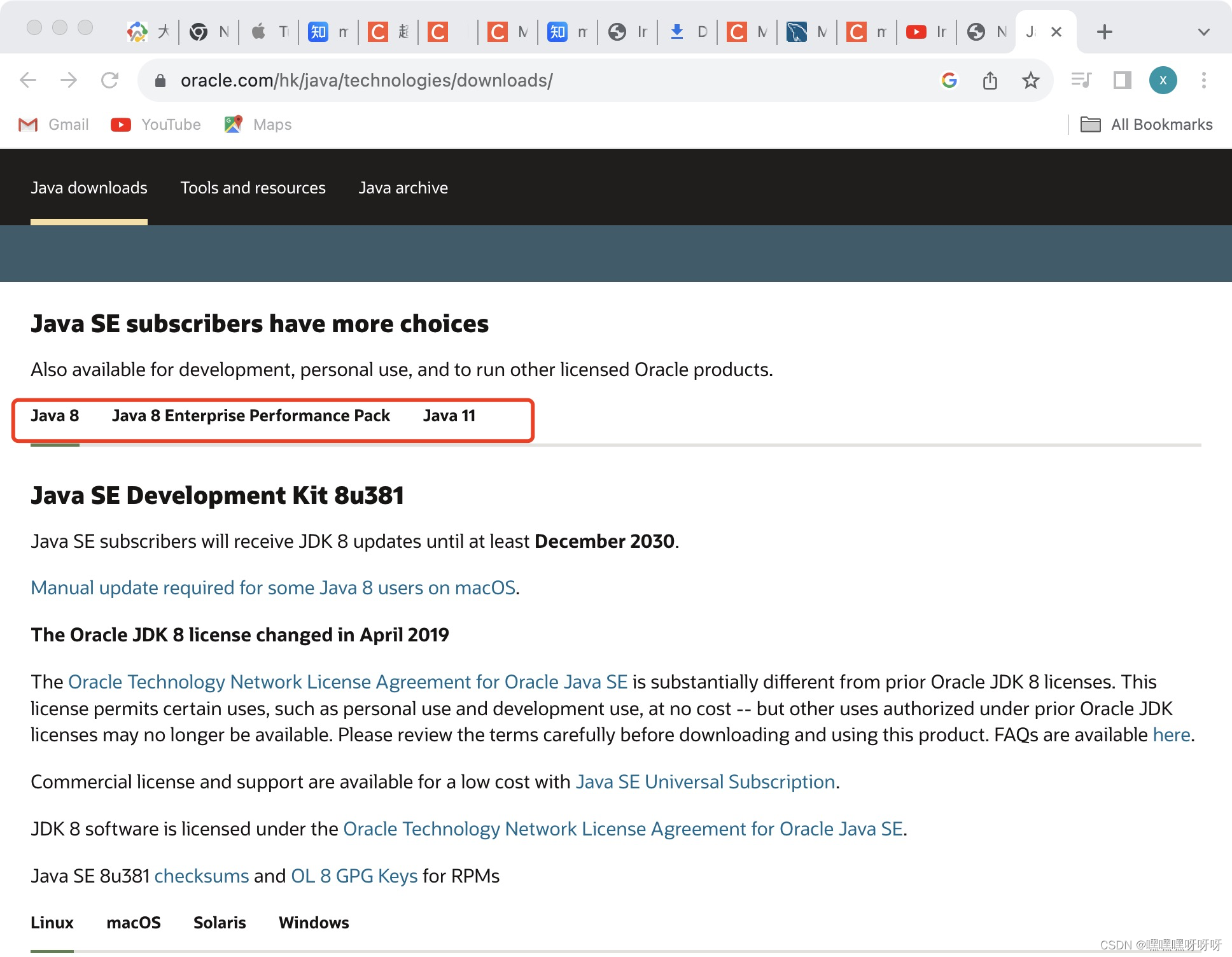
2.选择mac os,下载ARM64 DMG Installer对应版本
注:这里下载需要注册oracle账号,不过很简单,只需要提供邮箱即可,什么邮箱都可以

3.下载完成后,双击.pkg文件,安装步骤安装即可。
4.输入命令:java -version 验证

配置JAVA_HOME环境
1. 查看JDK所在位置,将路径录制下来后续会用到。
/usr/libexec/java_home -V
2.直接在终端输入vim ~/.bash_profile打开文件,没有文件则使用【touch .bash_profile】创建文件,在最后添加下方内容,Java_home 中的参数就是JDK所在路径
JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk-11.jdk/Contents/Home
PATH=$JAVA_HOME/bin:$PATH:.
CLASSPATH=$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:.
export JAVA_HOME
export PATH
export CLASSPATH3.保存文件后退出
4.输入命令【source ~/.bash_profile】 使配置文件生效。
5.输入 【echo $JAVA_HOME】 显示刚才配置的路径

设置SSH免密
1. 打开系统偏好设置,在输入框输入sharing
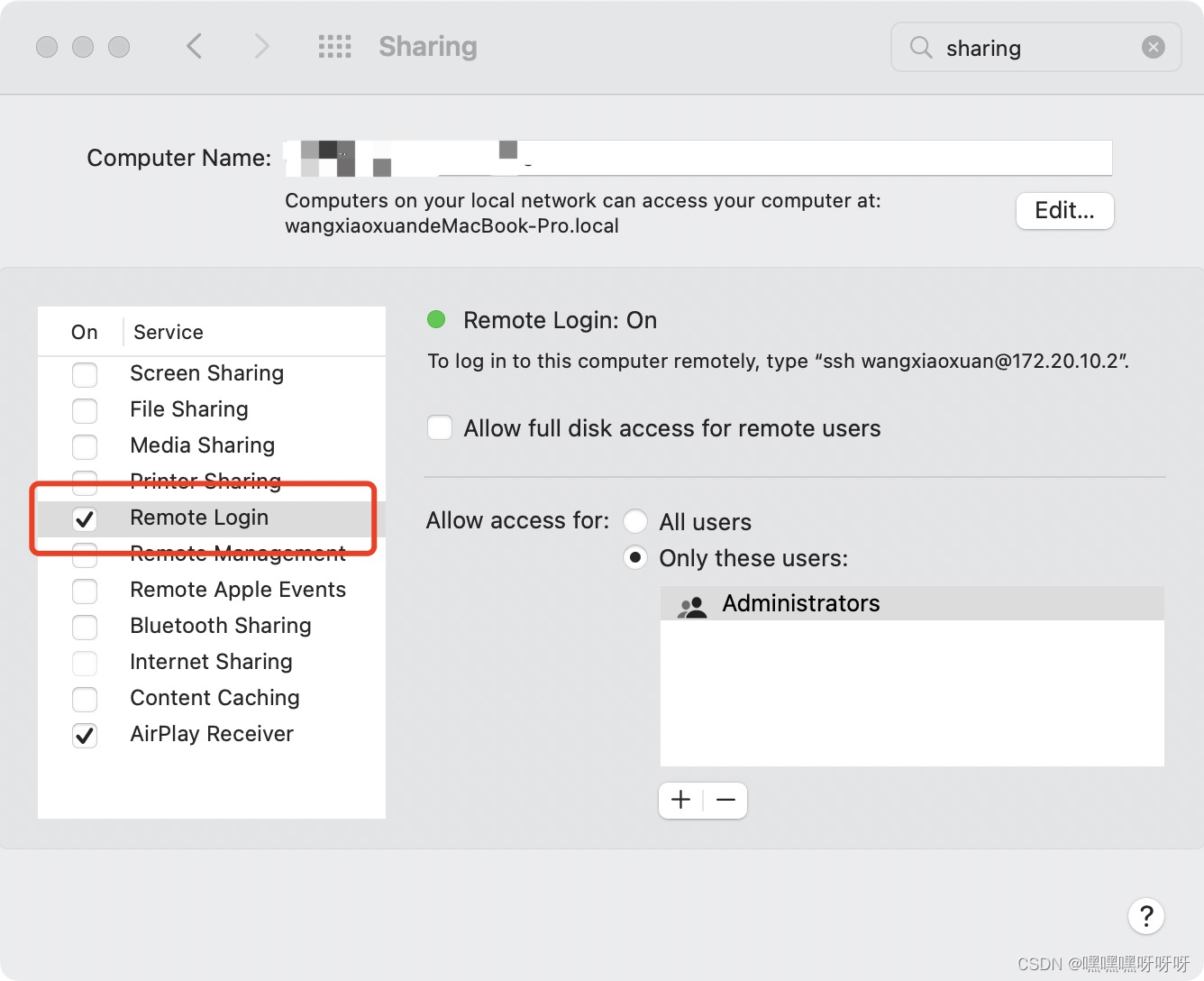
2.勾选远程登录选项
3.打开终端,依次输入如下命令
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/id_rsa.pub4.输入【ssh localhost】验证

下载Hadoop
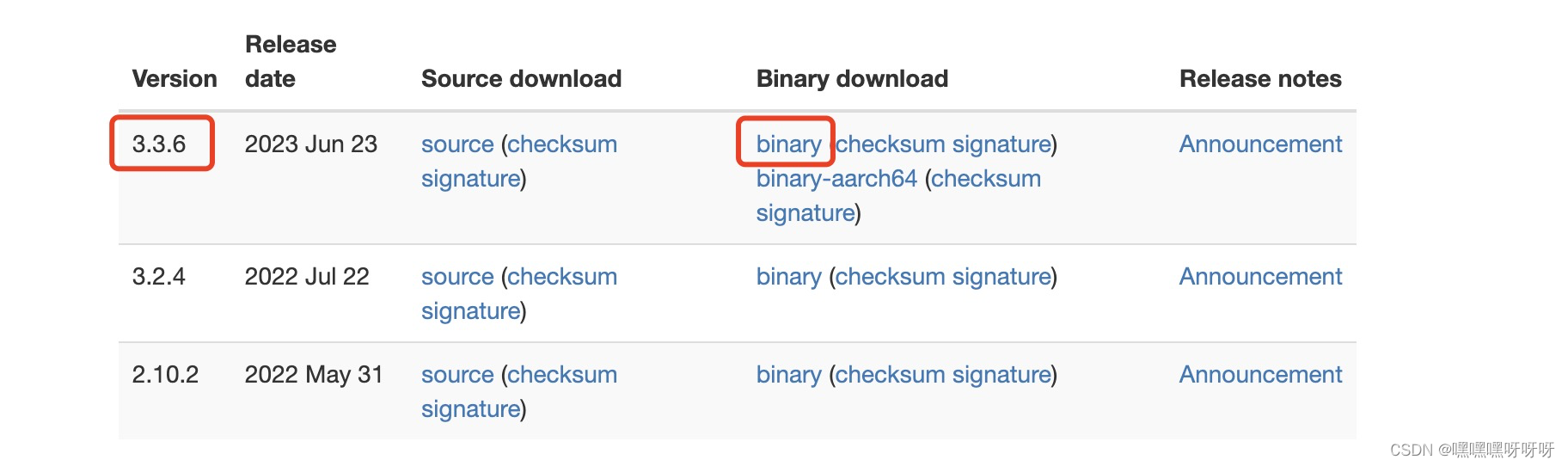
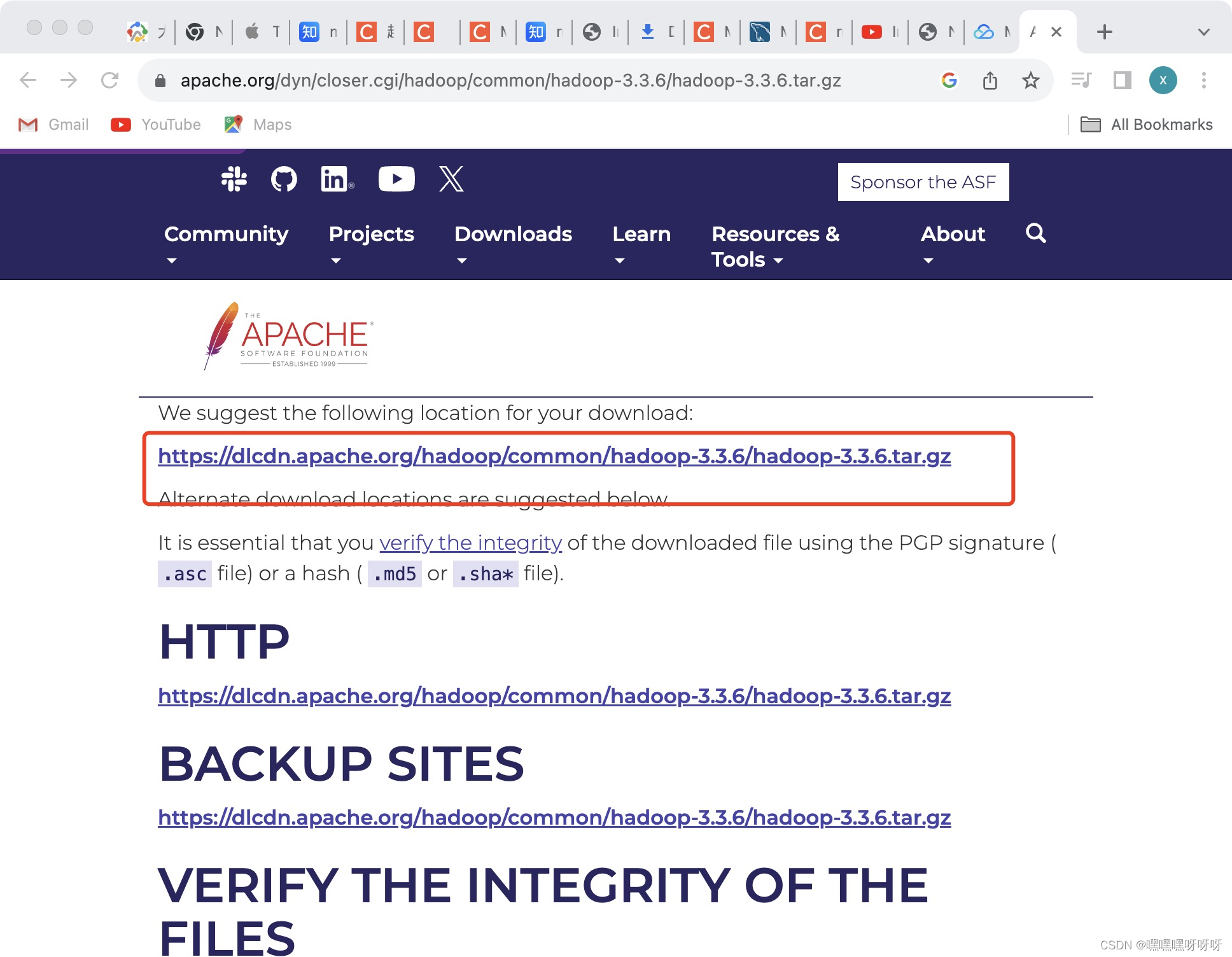
1.进入网址Apache Hadoop,选择最新版本Hadoop,选择binary download
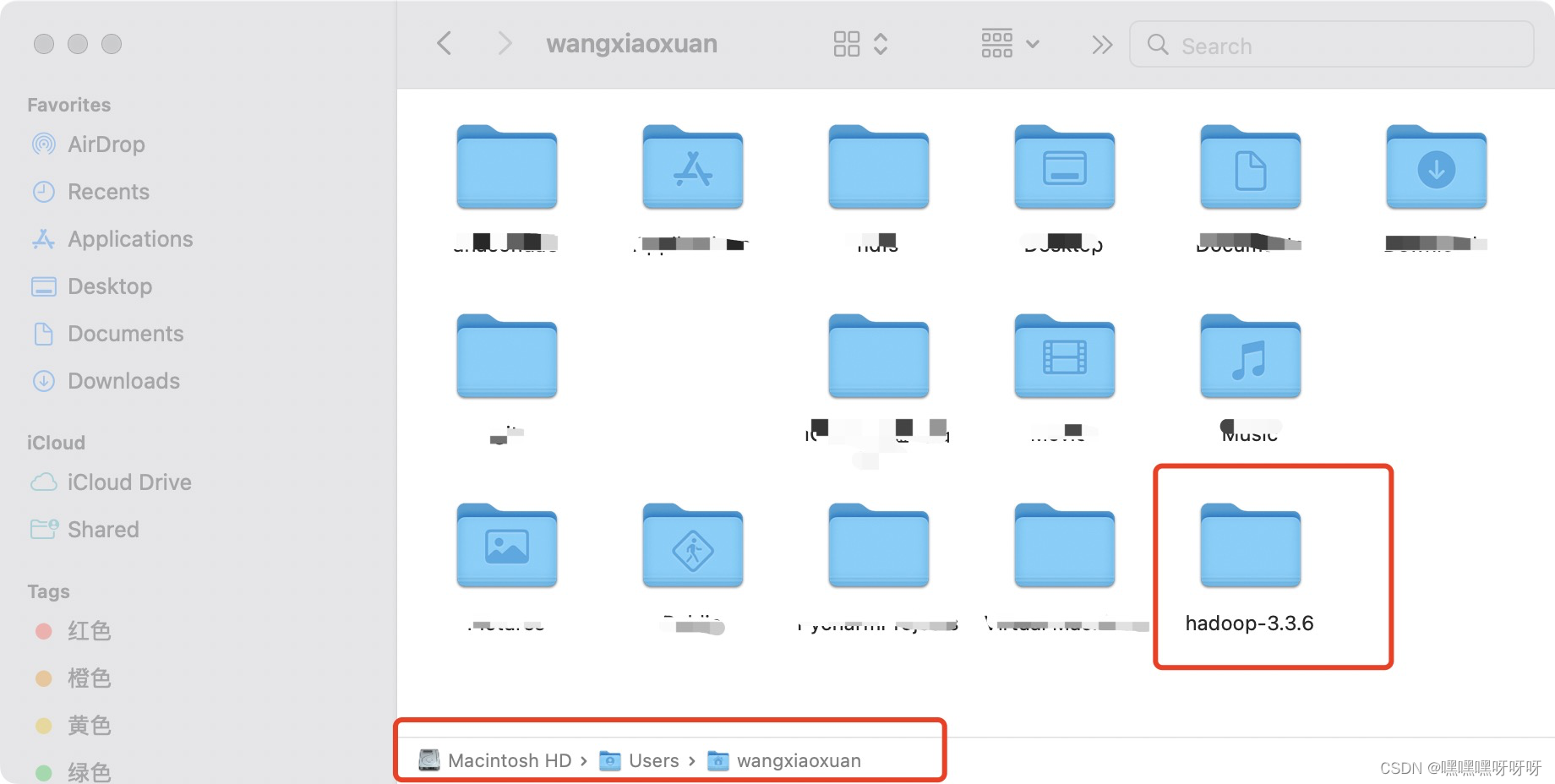
2.获取.gz文件后双击解压该文件,获取到hadoop-3.3.6文件夹,将此文件放入根目录下(USER/[你的名字])
3.修改配置文件
(1)vim ~/.zprofile
打开 zprofile,添加以下内容,HADOOP_HOME=/Users/wangxiaoxuan/Documents/download/hadoop-3.3.6/ 修改为你自己的路径
# Hadoop
export HADOOP_HOME=/Users/wangxiaoxuan/hadoop-3.3.6/
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/nativ"输入【source ~/.zprofile】是内容生效
(2)进入/Users/wangxiaoxuan/hadoop-3.3.6/etc/hadoop 目录
cd /Users/wangxiaoxuan/hadoop-3.3.6/etc/hadoop (3)打开hadoop-env.sh 【vim hadoop-env.sh】,添加如下内容,路径为jdk所在路径,上文有提到如何获取
export JAVA_HOME="/Library/Java/JavaVirtualMachines/jdk-1.8.jdk/Contents/Home"(4)打开core-site.sh文件【vim core-site.xml】,将标签<configuration></configuration>中内容替换如下,路径需换成自己的路径
<configuration><property><name>hadoop.tmp.dir</name><value>/Users/wangxiaoxuan/hdfs/tmp/</value></property><property><name>fs.default.name</name><value>hdfs://127.0.0.1:9000</value></property>
</configuration>(5)打开hdfs-site.xml文件【vim hdfs-site.xml】,将标签<configuration></configuration>中内容替换如下,路径需换成自己的路径
<property><name>dfs.data.dir</name><value>/Users/wangxiaoxuan/hdfs/namenode</value></property><property><name>dfs.data.dir</name><value>/Users/wangxiaoxuan/hdfs/datanode</value></property><property><name>dfs.replication</name><value>1</value></property>
</configuration>(6)打开mapred-site.xml文件【vim mapred-site.xml】,将标签<configuration></configuration>中内容替换如下,无需更改路径
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
(7)打开yarn-site.xml文件【vim yarn-site.xml】,将标签<configuration></configuration>中内容替换如下,无需更改路径。
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property><property><name>yarn.resourcemanager.hostname</name><value>127.0.0.1</value></property><property><name>yarn.acl.enable</name><value>0</value></property><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PERPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property>
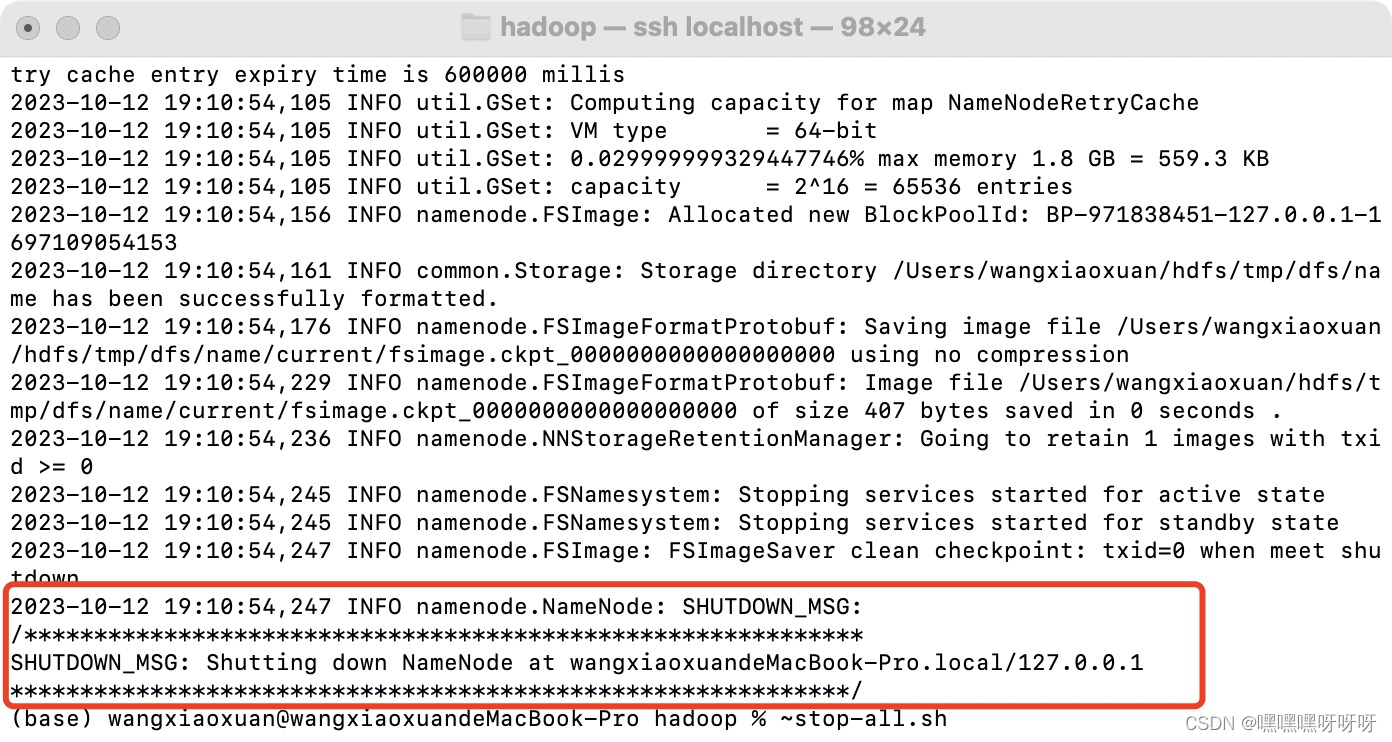
</configuration>8.执行【hdfs namenode -format】 如果报错,需要先执行【stop-all.sh】
正常应显示如下:
9.执行【start-all.sh】,查看resourcemanager 和nodemanagers是否启动成功

10.执行【jps】可查看进程

验证
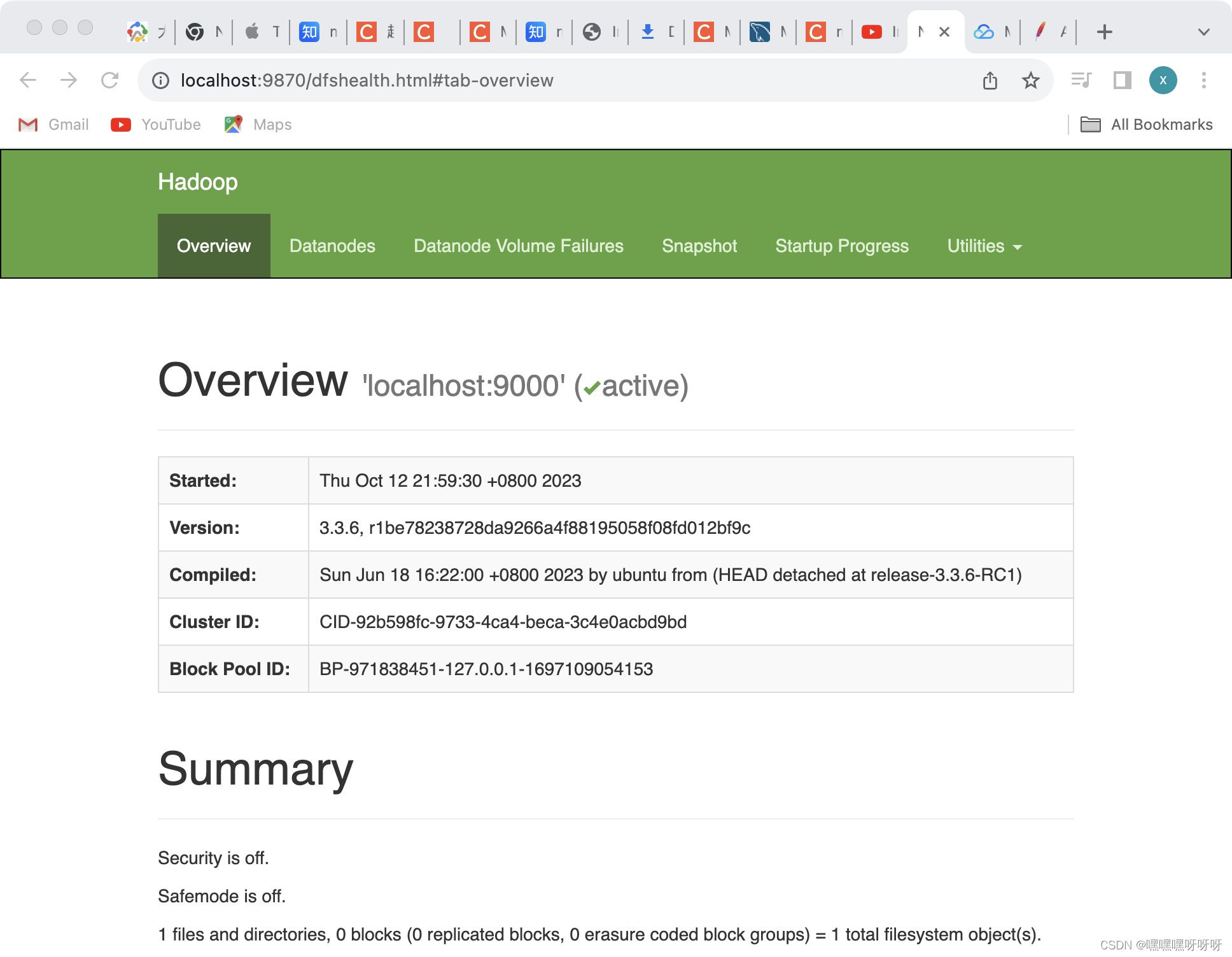
在浏览器中输入http://localhost:9870/
显示如下:
此安装教程参考:
https://www.youtube.com/watch?v=inDC9jgwpWY
https://codewitharjun.medium.com/install-hadoop-on-macos-m1-m2-6f6a01820cc9
在安装过程中如遇设置免密登陆错误可参考:
networking - How to ssh to localhost without password? - Stack Overflow