(注:本文为小报童精选文章,已订阅小报童或加入知识星球「玉树芝兰」用户请勿重复付费)
想采集网页数据却不会写 Python 爬虫?不会就不会吧,ChatGPT 会就可以了 😂

问题描述
朋友最近遇到了一点儿技术障碍,找我帮忙。起因是他想获取一个网站上面的信息。
一般网站的信息,获取起来并不麻烦。怕就怕这种网站 —— 活动通知。

要知道,过期的活动,是没有什么「通知」的意义的。所以网站对于过期活动的态度比较明确 —— 直接删掉。所以主页面的内容,是每天甚至每个小时都会改变的。
刚才的图片,是今天早上网站的内容,而下面这个是前几天他保存的页面存档内容。
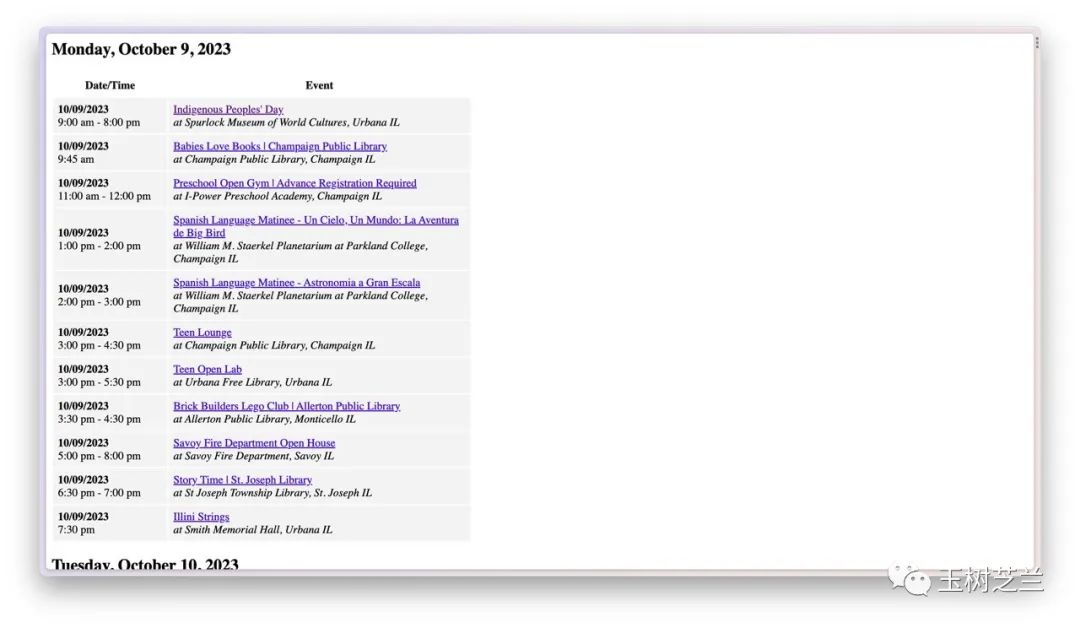
他发现不仅主页上面活动列表里过期活动信息找不到了,就连存档里过期活动的链接也全都点不开了。
痛定思痛,他决心干脆每天把当日的活动信息都弄下来。可是他又不懂 Python 爬虫技术。每天分别手动摘取活动的名称、日期、时间、地点、URL,以及还得打开对应 URL ,拷贝其中的活动描述正文内容,实在是太麻烦了。
一天两天还好说,如果要坚持一年,那可就是愚公移山的精神了……
所以,他找我求助。
这种事儿吧,「会者不难难者不会」。我虽然曾经写过简单的爬虫教程,但是也已经很久没有摸索了。现在不仅手生,也没有时间去对要提取的各项信息一一定位、抽取,觉得太过繁琐。
好在,咱们不是有 ChatGPT 吗?
本文我就给你演示一下,如何用 ChatGPT 来帮助咱们从网页上把想要的信息抽取出来。
脾性
ChatGPT 的每一个模式,都有自己的「脾性」。其中 Advanced Data Analysis 的脾性,重要的是以下两点:
无法联网。所以你不要指望它能够获得最新的 API ,也不要希望它能够帮你下载任何东西。这里「任何东西」当然包括网页,也包括 ChatGPT 的 Advanced Data Analysis 模式虚拟机中未安装的软件包。很多读者反馈给我,说是 scikit-learn 机器学习框架在 Advanced Data Analysis 里面能用,但是 Tensorflow 不能用,也装不上。就是这个原因;
能上传数据。你可以把数据直接喂给它。这样它在进行分析的时候,可以有非常强烈的上下文。
这里我们着重说说第二点。假设我们让 ChatGPT 「去,帮我把一个网页中的日期、时间、地点、活动名称、URL 爬取下来」,它因为啥都看不到,多半会根据经验,给你胡写一个根本不能用的结果。而对于一个输入数据文件作为样例,情况就会好很多。
只不过,网页里面一般也有很多内容。与其让 ChatGPT 帮你在文件里面瞎猜乱试,然后需要你参与进来不断纠错,还不如一上来你就把真正需要查找的内容以样例方式精确清楚传递给ChatGPT。而且是越清楚越好。
下面,我就来给你演示,怎么把内容样例的精确定位获取到,并且传递给 Advanced Data Analysis 。
你看,这是我下载的活动日程通知主页面的例子。
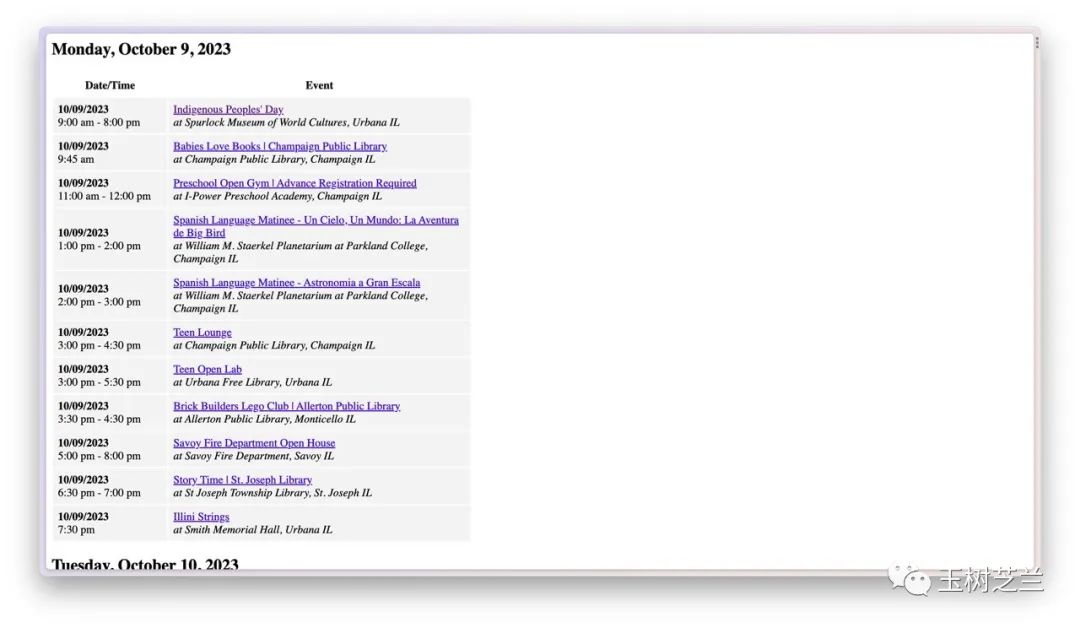
你可以在浏览器里面 Inspect (检视)页面的源码。

这里,你可以通过区域选择按钮,让浏览器帮忙定位到选定区域对应的源代码位置。
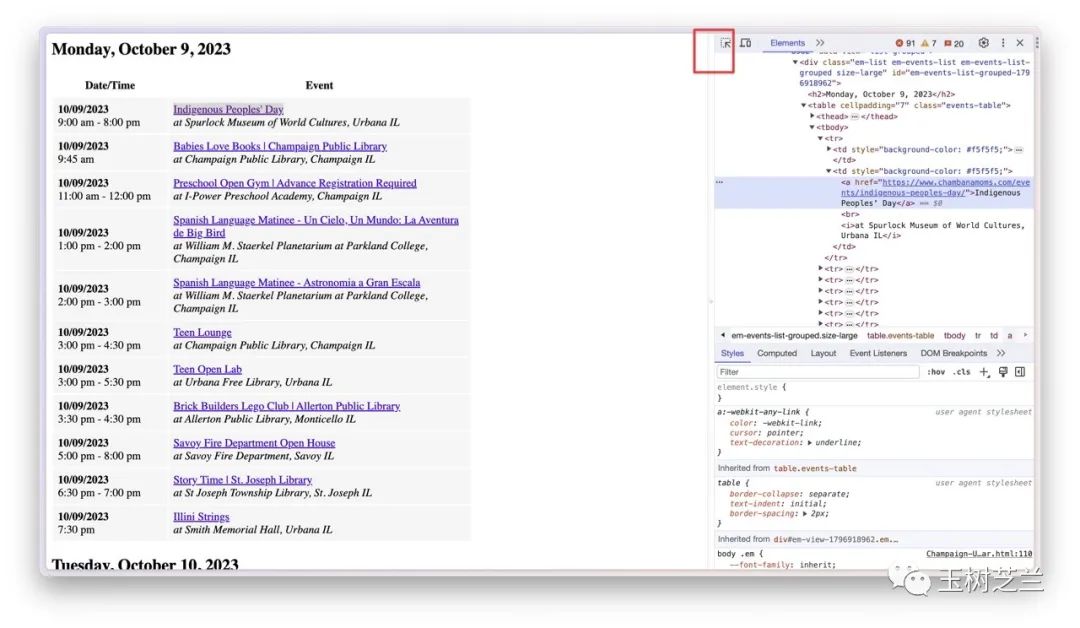
操作效果就像这样:
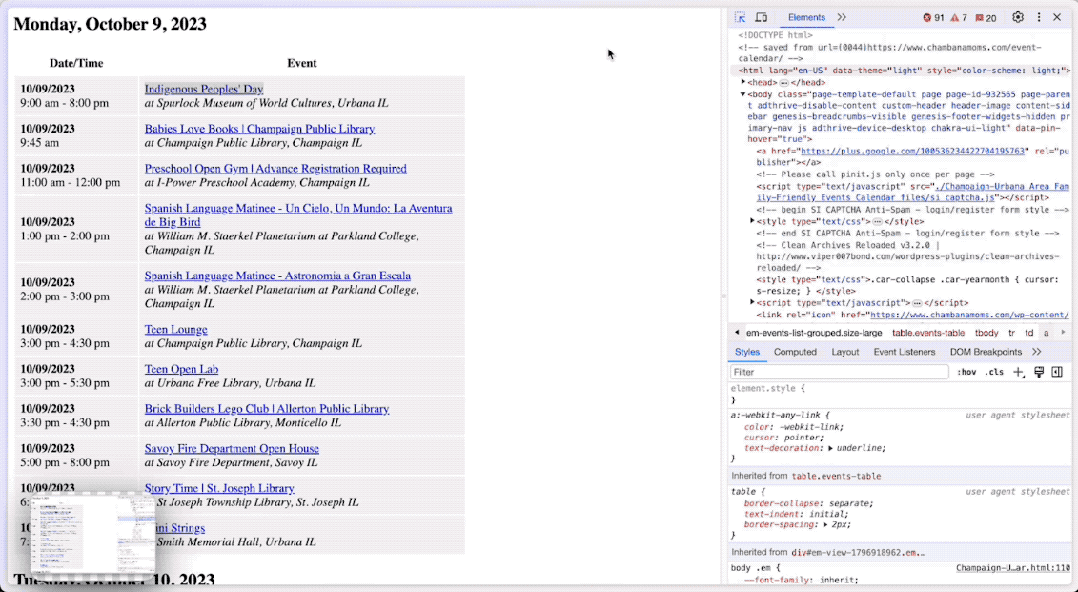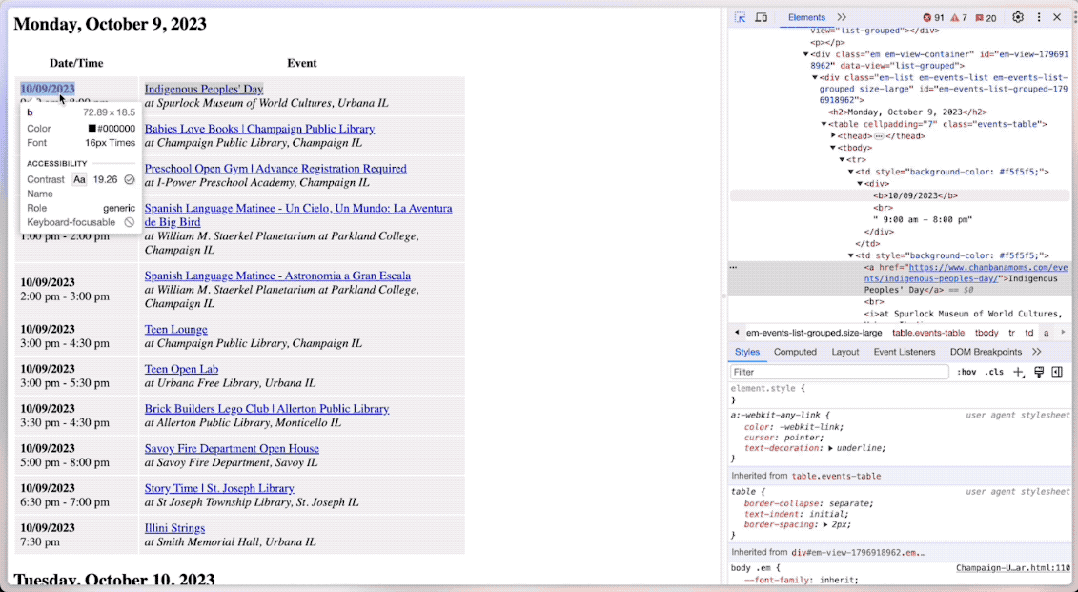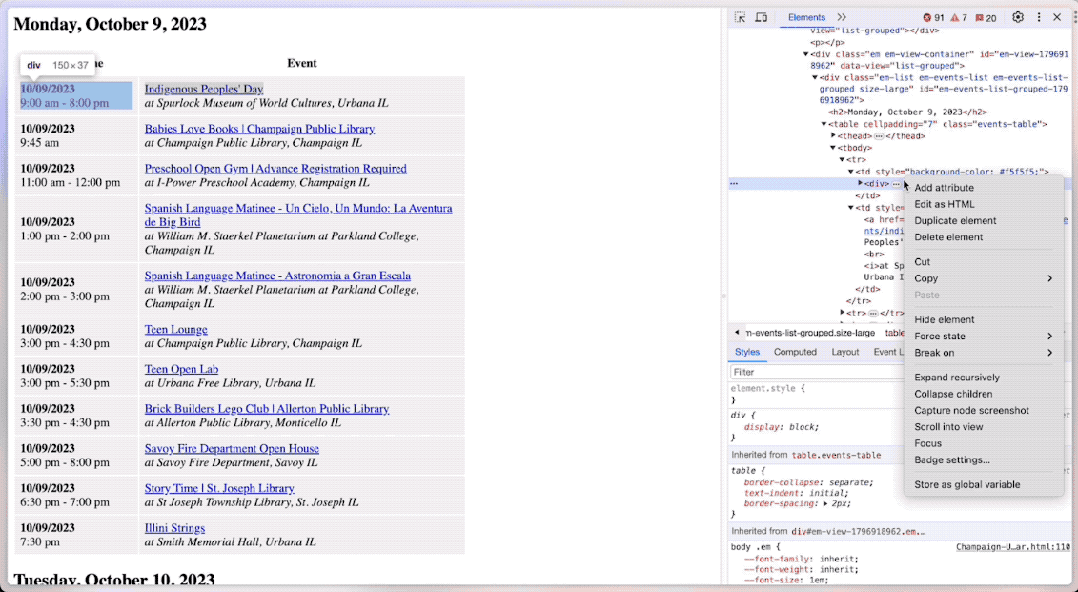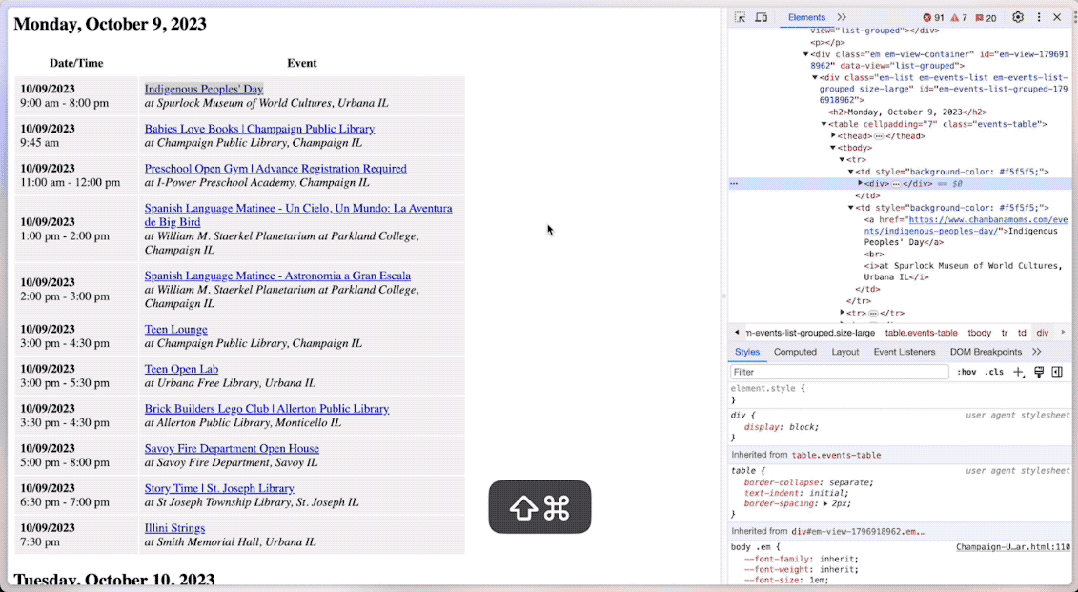
然后,你就可以用这种方式,拷贝具体文本段落的 xpath 。
我分别拷贝了某个活动对应的时间、地点、URL 等信息。然后连同这个 HTML 文件,一股脑扔给了 Advanced Data Analysis。