大型语言模型(llm)在今年发展迅速,随着新一代模型不断地被开发,研究人员和工程师了解最新进展变得非常重要。本文总结9-10月期间发布了一些重要的LLM论文。
这些论文涵盖了一系列语言模型的主题,从模型优化和缩放到推理、基准测试和增强性能。最后部分讨论了有关安全训练并确保其行为保持有益的论文。
优化与扩展
Large Language Model Cascades with Mixture of Thoughts Representations for Cost-efficient Reasoning
https://arxiv.org/abs/2310.03094
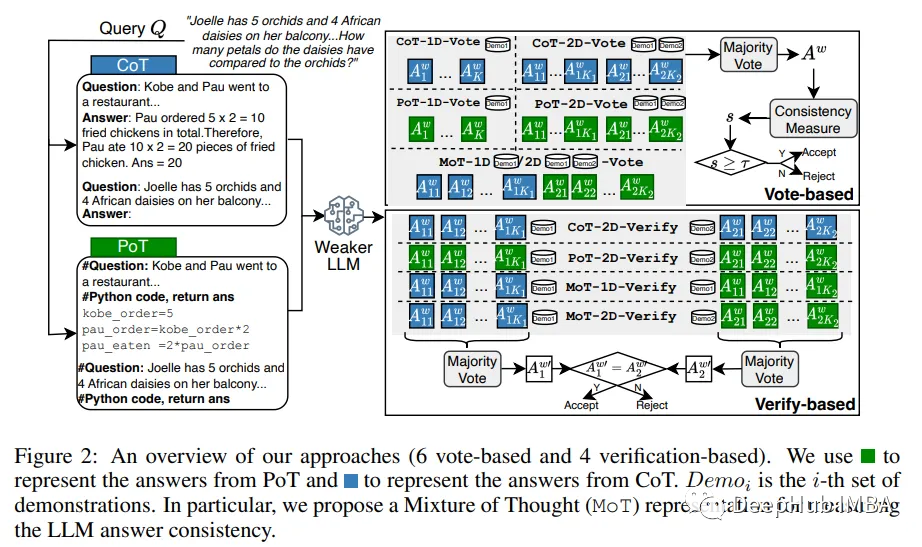
像GPT-4这样的大型语言模型(llm)在各种任务中表现出了卓越的性能,但是这种强大的性能通常伴随着使用付费API服务的高昂费用。
在本文中,作者研究了构建LLM级联以节省使用LLM的成本,特别是用于执行推理(例如,数学,因果关系)任务。
级联管道遵循的理论是,简单的问题可以通过较弱但更实惠的LLM来解决,而只有具有挑战性的问题才需要更强大且更昂贵的LLM。
为了实现这一决策,他们将较弱LLM的“答案一致性”视为问题难度的信号,并提出了几种答案抽样和一致性检查方法,包括一种利用两种思维表示(即Chain-of-Thought 和 Program-of-Thought)的混合方法。
通过在六个推理基准数据集上的实验,分别使用gpt -3.5 turbo和GPT-4作为较弱和较强的LLM,证明提出的LLM级联可以达到与单独使用较强LLM相当的性能,而成本仅为其40%。
EcoAssistant: Using LLM Assistant More Affordably and Accurately
https://arxiv.org/abs/2310.03046

用户要求大型语言模型(llm)作为助手来回答需要外部知识的查询;他们会询问某个城市的天气、股票价格,甚至是他们所在社区的具体位置。
这些查询需要LLM生成调用外部api代码来回答用户的问题,但是LLM很少在第一次尝试时生成正确的代码,需要在执行结果上进行迭代的优化。这导致高查询量可能会很昂贵。
在这项工作中,作者贡献了一个框架,EcoAssistant,使LLM能够更经济、更准确地回答代码驱动的查询。EcoAssistant包含三个组件:
首先,它允许LLM助手与自动代码执行器对话,以迭代地改进代码或根据执行结果生成答案。
其次,我们使用LLM助手的层次结构,它试图用更弱、更便宜的LLM来回答查询。
第三,从过去成功的查询中检索解决方案,作为上下文演示,以帮助后续查询。
EcoAssistant在可负担性和准确性方面具有明显的优势,其成功率超过GPT-4 10个百分点,成本不到GPT-4的50%。
AnyMAL: An Efficient and Scalable Any-Modality Augmented Language Model
https://arxiv.org/abs/2309.16058

作者提出了任意模态增强语言模型(AnyMAL),这是一个可以对多种输入模态信号(即文本、图像、视频、音频、IMU运动传感器)进行推理,并生成文本响应的统一模型。
AnyMAL继承了包括LLaMA-2 (70B)在内的最先进llm的强大的基于文本的推理能力,并通过预训练的对齐器模块将特定于模态的信号转换为联合文本空间。
为了进一步加强多模态LLM的能力,他们使用手动收集的多模态指令集对模型进行了微调,涵盖简单问答之外的各种主题和任务。他们进行了全面的实证分析,包括人工和自动评估,并在各种多模式任务中展示了最先进的表现。
基于人类反馈的强化学习(RLHF)
A Long Way to Go: Investigating Length Correlations in RLHF
https://arxiv.org/abs/2310.03716

使用基于人类反馈的强化学习(RLHF)来校准大型语言模型取得了巨大的成功。开源好数据集和奖励模型使得在普通聊天设置之外的更广泛的实验成为可能,特别是使系统对网络问答、摘要和多回合对话等任务更“有用”。在优化有用性时,RLHF一直被观察到驱动模型产生更长的输出。
论文表明,优化响应长度是RLHF在这些设置中报告的改进背后的重要因素。他们研究了在三个开源的数据集上训练的奖励模型的奖励和长度之间的关系。发现长度与奖励密切相关,奖励分数的提高主要是通过改变输出长度的分布来驱动的。
然后探索在RL和奖励模式学习期间的干预措施,是否能在不增加长度的情况下实现与RLHF相同的下游改善。虽然干预措施减轻了长度的增加,但它们并不是在不同的环境下都有效。
论文还发现即使运行RLHF时仅基于长度的奖励也能再现初始策略模型的大部分下游改进,这表明在这些设置下的奖励模型还有很长的路要走。
推理
MathCoder: Seamless Code Integration in LLMs for Enhanced Mathematical Reasoning
https://arxiv.org/abs/2310.03731

最近发布的GPT-4代码解释器在解决具有挑战性的数学问题方面表现出了非凡的熟练程度,这主要归功于它能够无缝地使用自然语言进行推理,生成代码,执行代码,并根据执行输出继续进行推理。
论文提出了一种方法来微调开源语言模型,使他们能够使用代码来建模和推导数学方程,从而提高他们的数学推理能力。
其中包含一种生成新颖的高质量数学问题及其基于代码的解决方案数据集的方法,称为mathcodedirective。每个解决方案都交织着自然语言、代码和执行结果。我们还介绍了一种定制的监督微调和推理方法。
这种方法产生了MathCoder模型,这是一组能够生成基于代码的解决方案的模型,用于解决具有挑战性的数学问题。MathCoder模型在MATH(45.2%)和GSM8K(83.9%)数据集上获得了最先进的分数,大大优于其他开源替代方案。MathCoder模型不仅在GSM8K和MATH上超过ChatGPT-3.5和PaLM-2,而且在竞赛级别的MATH数据集上也优于GPT-4。
Large Language Models Cannot Self-Correct Reasoning Yet
https://arxiv.org/abs/2310.01798
大型语言模型(llm)已经成为一项突破性的技术,在各种应用程序中具有无与伦比的文本生成能力。然而对其生成内容的准确性和适当性的关注仍然存在。
论文提出了一种自我纠正的方法,作为这些问题的补救。研究的核心是内在自我纠正的概念,即LLM试图仅根据其固有能力纠正其初始反应,而不依赖外部反馈。
在推理的情况下,研究表明,LLM很难在没有外部反馈的情况下自我纠正他们的反应,有时他们的表现在自我纠正后的指标下降。根据这些见解,作者对该领域的未来研究和实际应用提出了建议。
Large Language Models as Analogical Reasoners
https://arxiv.org/abs/2310.01714

语言模型的思维链(CoT)提示在推理任务中展示了令人印象深刻的性能,但通常需要标记为推理过程的范例。
论文引入了一种新的提示方法,类比提示,它可以自动引导大型语言模型的推理过程。类比推理是一种认知过程,在这种认知过程中,人类从相关的过去经验中汲取知识来解决新问题。我们的方法受到类比推理的启发,促使语言模型在继续解决给定问题之前,在上下文中自我生成相关的范例或知识。
这种方法有几个优点:它避免了标记或检索样本的需要,提供了通用性和方便性;它还可以为每个问题定制生成的示例和知识,提供适应性。实验结果表明,论文的方法在各种推理任务中都优于0-shot CoT和手动较少-shot CoT,包括GSM8K和math中的数学问题解决,Codeforces中的代码生成以及BIG-Bench中的其他推理任务。
LLM进展与基准
How FaR Are Large Language Models From Agents with Theory-of-Mind?
https://arxiv.org/abs/2310.03051

“思考是为了行动。”人类可以通过观察推断他人的心理状态——一种被称为心理理论(ToM)的能力——然后根据这些推断采取实际行动。现有的问答基准(如ToMi)会向模型提问,以推断故事中人物的信念,但不会测试模型是否可以使用这些推断来指导它们的行动。
我们为大型语言模型(llm)提出了一种新的评估范式:Thinking for Doing (T4D),它要求模型将对他人心理状态的推断与社会场景中的行动联系起来。在T4D上的实验表明,像GPT-4和PaLM 2这样的llm似乎擅长追踪故事中人物的信念,但它们很难将这种能力转化为战略行动。
论文引入了一个零样本提示框架,预见和反映(FaR),它提供了一个推理结构,鼓励LLM预测未来的挑战,并对潜在的行动进行推理。
FaR将GPT-4在T4D中的表现从50%提高到71%,优于其他提示方法。此外FaR推广到不同的分布外的故事结构和场景,也需要ToM推理来选择一个动作,始终优于其他方法(包括少量的上下文学习)。
SmartPlay: A Benchmark for LLMs as Intelligent Agents
https://arxiv.org/abs/2310.01557

最近的大型语言模型(llm)已经证明了智能代理和下一代自动化的巨大潜力,但目前还没有一个系统的基准来评估llm作为代理的能力。
论文提出的SmartPlay:既是一个具有挑战性的基准,也是一种评估LLM作为代理的方法。SmartPlay由6款不同的游戏组成,包括石头剪刀布、河内塔和我的世界。
每个游戏都有一个独特的设置,提供多达20个评估设置和无限的环境变化。SmartPlay中的每个游戏都独特地挑战了智能LLM代理的9个重要功能的子集,包括对象依赖性推理,提前计划,空间推理,从历史中学习和理解随机性。每个游戏测试的能力集之间的区别使我们能够分别分析每个能力。
SmartPlay不仅可以作为评估LLM代理整体性能的严格测试场地,还可以作为识别当前方法差距的路线图。
提高LLM的表现
FreshLLMs: Refreshing Large Language Models with Search Engine Augmentation
https://arxiv.org/abs/2310.03214
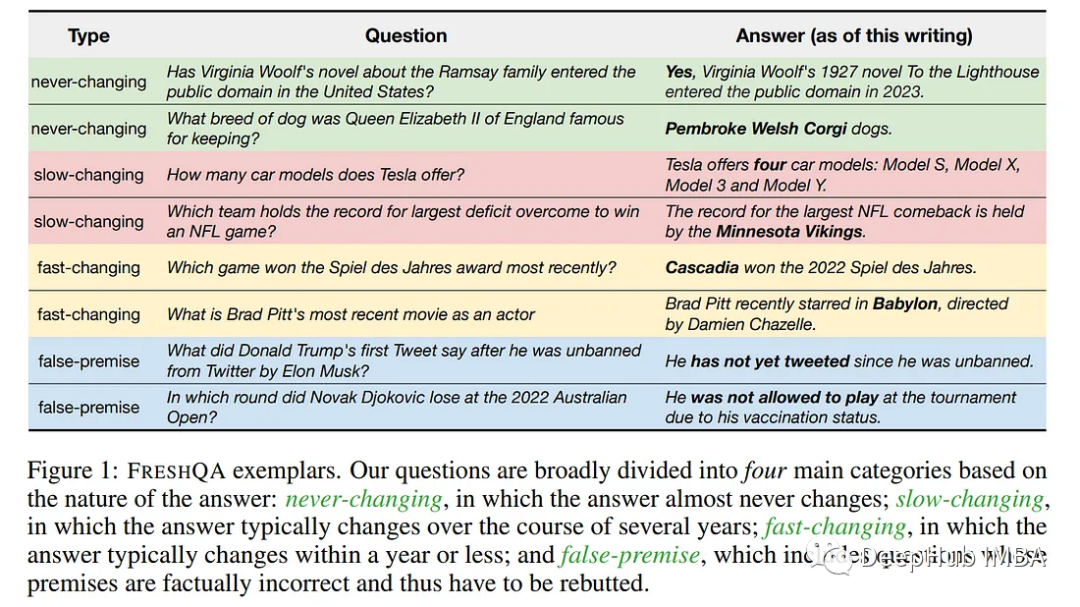
大多数大型语言模型(llm)只训练一次,从不更新;因此,他们缺乏动态适应不断变化的世界的能力。在这项工作中,通过回答测试当前世界知识的问题的背景下,对LLM生成的文本的真实性进行了详细的研究。
引入了FreshQA,这是一种新的动态QA基准,包含各种各样的问答类型,包括需要快速变化的世界知识的问题,以及需要揭穿的错误前提的问题。
在一个双模式评估程序下对各种封闭和开源llm进行基准测试,通过涉及超过5万次判断的人类评估,揭示了这些模型的局限性,并展示了显著的改进空间:例如,所有模型(无论模型大小)都在与涉及快速变化的知识和错误前提的问题作斗争。
受这些结果的启发,论文提出了FreshPrompt,这是一种简单的少量提示方法,通过将从搜索引擎检索到的相关和最新信息整合到提示中,大大提高了LLM的性能。
实验表明,FreshPrompt优于竞争对手的搜索引擎增强提示方法,如Self-Ask (Press et al., 2022)以及商业系统,如Perplexity AI。对FreshPrompt的进一步分析表明,检索证据的数量及其顺序在影响llm生成答案的正确性方面起着关键作用。
此外,与鼓励冗长的答案相比,指导LLM生成简洁直接的答案有助于减少幻觉。
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
https://arxiv.org/abs/2310.03714
ML社区正在迅速探索提示语言模型(LMs)的技术,并将它们堆叠到解决复杂任务的管道中。但是现有的LM管道通常是使用硬编码的“提示模板”实现的,即通过反复试验发现的长字符串。
为了更系统地开发和优化LM管道,论文提出了DSPy,这是一个编程模型,它将LM管道抽象为文本转换图,即命令式计算图,其中通过声明性模块调用LM。DSPy模块是参数化的,这意味着它们可以学习(通过创建和收集演示)如何应用提示、调优、增强和推理技术的组合。
作者还设计了一个编译器,它将优化任何DSPy管道以最大化给定的度量。进行了两个案例研究,表明简洁的DSPy程序可以表达和优化复杂的LM管道,这些管道可以解释数学单词问题、处理多跳检索、回答复杂问题和控制代理循环。
在编译的几分钟内,几行DSPy允许GPT-3.5和llama2-13b-chat自引导管道,其性能优于标准的少样本提示(通常分别超过25%和65%)和专家创建的演示管道(分别高达5-46%和16-40%)。最重要的是,DSPy程序编译为开放和相对较小的lm,如770M-parameter T5和llama2-13b-chat,与依赖专家编写的专有GPT-3.5提示链的方法相比具有竞争力。
Enable Language Models to Implicitly Learn Self-Improvement From Data
https://arxiv.org/abs/2310.00898

大型语言模型(llm)在开放式文本生成任务中表现出了非凡的能力。但是这些任务固有的开放性意味着模型响应的质量总是有改进的空间。
为了应对这一挑战,人们提出了各种方法来LLM的性能。人们越来越关注使LLM能够自我提高其响应质量,从而减少对大量人工注释工作的依赖,以收集多样化和高质量的训练数据。基于提示的方法因其有效性、高效性和便捷性在自我完善方法中得到了广泛的探索。
但是这些方法通常需要明确而彻底地编写规则作为llm的输入。论文提出了一个隐式自我完善(PIT)框架,该框架从人类偏好数据中隐式学习改进目标。PIT只需要用于训练奖励模型的偏好数据,而无需额外的人力。
作者重新制定了基于人类反馈(RLHF)的强化学习的训练目标——不是对给定输入最大化响应质量,而是在参考响应的条件下最大化响应的质量差距。通过这种方式,PIT被隐式地训练,其改进目标是更好地与人类偏好保持一致。在两个真实数据集和一个合成数据集上的实验表明,该方法明显优于基于提示的方法。
法规与道德
HeaP: Hierarchical Policies for Web Actions using LLMs
https://arxiv.org/abs/2310.03720
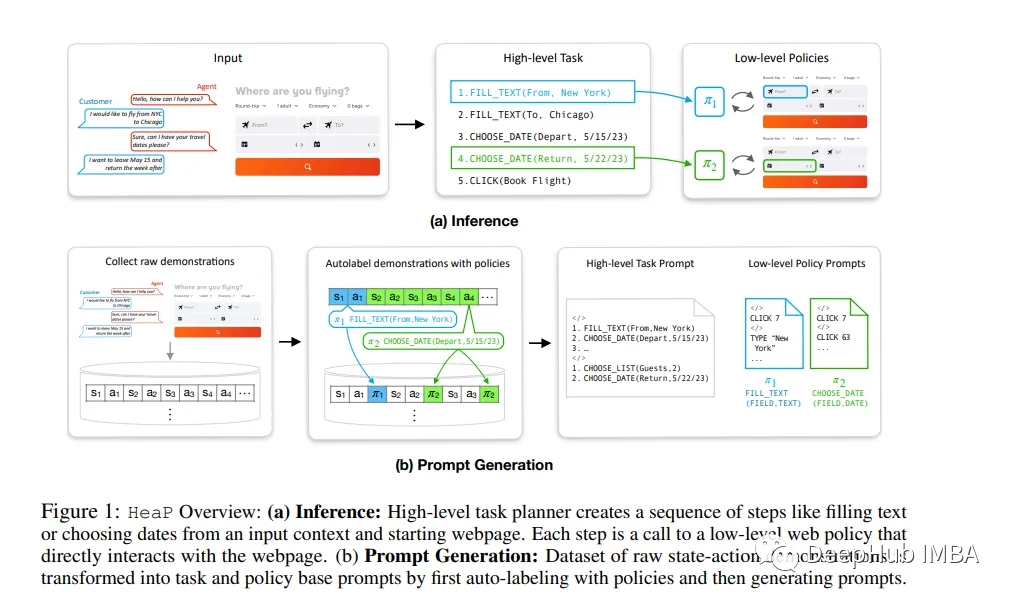
大型语言模型(llm)已经证明了在少量和零样本设置中执行一系列指令跟随任务的卓越能力。
但是组合大型开放世界任务和跨网络界面的变化对于模型有巨大的挑战。作者通过利用llm将web任务分解为一组子任务来解决这些挑战,每个子任务都可以通过低级闭环策略来解决。
这些策略构成了跨任务的共享语法,也就是说,新的web任务可以表示为这些策略的组合。论文提出了一个新的框架,使用LLM的Web操作的分层策略(HeaP),它从演示中学习一组分层LLM提示,用于规划高级任务并通过一系列低级策略执行它们。
根据一系列web任务(包括miniwob++、WebArena、模拟航空公司CRM以及实时网站交互)的基线对HeaP进行了评估,并表明它能够使用更少的数据来优于先前的工作。
https://avoid.overfit.cn/post/fe5635accd16437aa7b4b6d7f2eea43f
作者:Youssef Hosni