目录
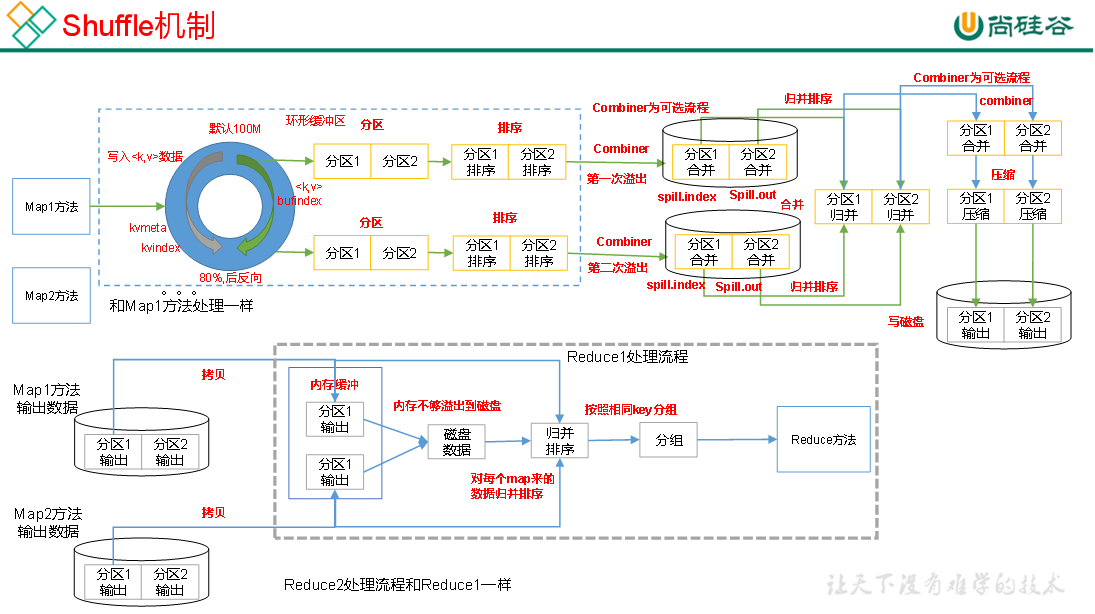
1,主要步骤
1.1 导入需要的包和模块,并读取两张待拼接的图片,这里我们假设它们为 left.jpg 和 right.jpg。
1.2 创建SIFT检测器
1.3 创建一个基于 FLANN 的匹配器
1.4 筛选过程删除掉一些不合适的匹配点,只保留最好的匹配点
1.5透视变换
1.6 消除重叠的效果,对两张图片进行加权处理
2,代码展示
3,效果展示
应用场景主要有两个方面:
- 风景或建筑物的拍摄
对于一些风景或建筑物的拍摄,有时候需要的画面宽度超出了单张图片所能提供的视野范围。这时可以通过拍摄多张图片并将它们拼接成一张更加宽阔的全景图来达到所需的效果。
- 科学研究
在一些科学研究中,需要对一定的区域进行高精度测量,例如地形测量、海洋测量等。这时候就需要一些宽视野相机来实现拍摄。但是,由于一张图片所能覆盖的区域有限,因此通常还需要将多张图片拼接成一张更大的全景图像,方便科学家们进行研究和分析。
1,主要步骤
- 读入待拼接的图片并调整大小;
- 使用 SIFT 或 SURF 算法提取图片的关键点和描述符;
- 使用基于 FLANN 的匹配器进行关键点匹配,并筛选出较好的匹配点;
- 计算视角变换矩阵,并使用透视变换对右边的图片进行变换;
- 消除重叠的效果,对两张图片进行加权处理;
- 输出拼接后的结果。
1.1 导入需要的包和模块,并读取两张待拼接的图片,这里我们假设它们为 left.jpg 和 right.jpg。
左视图:

右视图:

1.2 创建SIFT检测器
cv2.xfeatures2d.SIFT_create()创建一个 SIFT 检测器。也可以选择使用
cv2.SIFT_create()不过前者是更新的版本,可能会更好一些
然后,在两张图片上分别使用这个检测器进行关键点检测和特征提取,获得关键点集合和描述符集合。
surf=cv2.xfeatures2d.SIFT_create()#可以改为SIFT
#sift = cv2.SIFT_create()
sift = cv2.xfeatures2d.SIFT_create()kp1,descrip1 = sift.detectAndCompute(imageA,None)
kp2,descrip2 = sift.detectAndCompute(imageB,None)1.3 创建一个基于 FLANN 的匹配器
调用
cv2.FlannBasedMatcher()创建一个基于 FLANN 的匹配器,并使用knnMatch()处理两张图片的特征描述符,得到最佳匹配。
indexParams = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
searchParams = dict(checks=50)
flann=cv2.FlannBasedMatcher(indexParams,searchParams)
match=flann.knnMatch(descrip1,descrip2,k=2)
good=[]1.4 筛选过程删除掉一些不合适的匹配点,只保留最好的匹配点
for i,(m,n) in enumerate(match):if(m.distance<0.75*n.distance):good.append(m)1.5透视变换
判断满足条件的匹配点数量是否大于阈值
MIN,如果大于,则进行视角变换矩阵的计算,将右边的图片imageB对其进行透视变换,得到warpImg。
if len(good) > MIN:src_pts = np.float32([kp1[m.queryIdx].pt for m in good]).reshape(-1,1,2)ano_pts = np.float32([kp2[m.trainIdx].pt for m in good]).reshape(-1,1,2)M,mask = cv2.findHomography(src_pts,ano_pts,cv2.RANSAC,5.0)warpImg = cv2.warpPerspective(imageB, np.linalg.inv(M), (imageA.shape[1]+imageB.shape[1], imageB.shape[0]))direct=warpImg.copy()direct[0:imageA.shape[0], 0:imageB.shape[1]] =imageAsimple=time.time()show('res',warpImg)同时,将左边的图片覆盖在变换后的图片上,得到 direct。最后,显示结果。
print(rows)
print(cols)
for col in range(0,cols):# 开始重叠的最左端if imageA[:, col].any() and warpImg[:, col].any():left = colprint(left)breakfor col in range(cols-1, 0, -1):#重叠的最右一列if imageA[:, col].any() and warpImg[:, col].any():right = colprint(right)break1.6 消除重叠的效果,对两张图片进行加权处理
根据图片相对位置的不同,左边的图片和右边的图片有可能会在某些列出现重叠部分,为了消除这种不自然的效果,需要实现像素级的混合。首先找到左右图片开始重叠的位置和结束的位置,然后对两张图片进行加权处理,最后将加权后的图片输出。
#加权处理
res = np.zeros([rows, cols, 3], np.uint8)
for row in range(0, rows):for col in range(0, cols):if not imageA[row, col].any(): # 如果没有原图,用旋转的填充res[row, col] = warpImg[row, col]elif not warpImg[row, col].any():res[row, col] = imageA[row, col]else:srcImgLen = float(abs(col - left))testImgLen = float(abs(col - right))alpha = srcImgLen / (srcImgLen + testImgLen)res[row, col] = np.clip(imageA[row, col] * (1 - alpha) + warpImg[row, col] * alpha, 0, 255)warpImg[0:imageA.shape[0], 0:imageA.shape[1]]=res
show('res',warpImg)
final=time.time()
print(final-starttime)2,代码展示
import cv2
import numpy as np
from matplotlib import pyplot as plt
import time
def show(name,img):cv2.imshow(name, img)cv2.waitKey(0)cv2.destroyAllWindows()
MIN = 10
FLANN_INDEX_KDTREE = 0
starttime = time.time()
img1 = cv2.imread('left.jpg') #query
img2 = cv2.imread('right.jpg') #train
imageA = cv2.resize(img1,(0,0),fx=0.2,fy=0.2)
imageB = cv2.resize(img2,(0,0),fx=0.2,fy=0.2)
surf=cv2.xfeatures2d.SIFT_create()#可以改为SIFT
#sift = cv2.SIFT_create()
sift = cv2.xfeatures2d.SIFT_create()kp1,descrip1 = sift.detectAndCompute(imageA,None)
kp2,descrip2 = sift.detectAndCompute(imageB,None)
#创建字典
indexParams = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
searchParams = dict(checks=50)
flann=cv2.FlannBasedMatcher(indexParams,searchParams)
match=flann.knnMatch(descrip1,descrip2,k=2)
good=[]
#过滤特征点
for i,(m,n) in enumerate(match):if(m.distance<0.75*n.distance):good.append(m)# 当筛选后的匹配对大于10时,计算视角变换矩阵
if len(good) > MIN:src_pts = np.float32([kp1[m.queryIdx].pt for m in good]).reshape(-1,1,2)ano_pts = np.float32([kp2[m.trainIdx].pt for m in good]).reshape(-1,1,2)M,mask = cv2.findHomography(src_pts,ano_pts,cv2.RANSAC,5.0)warpImg = cv2.warpPerspective(imageB, np.linalg.inv(M), (imageA.shape[1]+imageB.shape[1], imageB.shape[0]))direct=warpImg.copy()direct[0:imageA.shape[0], 0:imageB.shape[1]] =imageAsimple=time.time()show('res',warpImg)
rows,cols=imageA.shape[:2]
print(rows)
print(cols)
for col in range(0,cols):# 开始重叠的最左端if imageA[:, col].any() and warpImg[:, col].any():left = colprint(left)breakfor col in range(cols-1, 0, -1):#重叠的最右一列if imageA[:, col].any() and warpImg[:, col].any():right = colprint(right)break
#加权处理
res = np.zeros([rows, cols, 3], np.uint8)
for row in range(0, rows):for col in range(0, cols):if not imageA[row, col].any(): # 如果没有原图,用旋转的填充res[row, col] = warpImg[row, col]elif not warpImg[row, col].any():res[row, col] = imageA[row, col]else:srcImgLen = float(abs(col - left))testImgLen = float(abs(col - right))alpha = srcImgLen / (srcImgLen + testImgLen)res[row, col] = np.clip(imageA[row, col] * (1 - alpha) + warpImg[row, col] * alpha, 0, 255)warpImg[0:imageA.shape[0], 0:imageA.shape[1]]=res
show('res',warpImg)
final=time.time()
print(final-starttime)
3,效果展示