作者:刘佳旭(花名:佳旭),阿里云容器服务技术专家
引言
随着云原生技术的快速发展以及在企业 IT 领域的深入应用,云原生场景下的高可用架构,对于企业服务的可用性、稳定性、安全性越发重要。通过合理的架构设计和云平台的技术支持,云原生高可用架构可以提供高可用性、弹性扩展性、简化运维管理、提升可靠性和安全性等方面的优势,为企业提供了更加可靠和高效的应用运行环境。
Kubernetes 是云原生的核心技术之一,提供了容器编排和管理的能力,包括基础设施自动化、弹性扩展性、微服务架构和自动化运维等,所以 Kubernetes 的应用高可用架构是云原生高可用的基石。本文会以阿里云容器服务 ACK(Alibaba Cloud Container Service for Kubernetes)为例,介绍基于 ACK 的应用高可用架构和治理的最佳实践。
应用高可用架构设计
云原生应用的高可用架构设计,是应用高可用开发、部署和治理的重要前提,可以从如下方面考虑:
1. 集群设计: 集群控制面和数据面的组件和节点,使用多节点、多副本高可用部署,保证 K8s 集群的高可用性。以 ACK 为例,提供了覆盖控制面和数据面的集群高可用能力。在控制面,ACK Pro 托管版集群的控制面组件使用多副本跨可用区部署,并基于对控制面的负载压力自动弹性;ACK 专有版可以配置 3 个或者 5 个 master 节点。在数据面,ACK 支持用户自行选择跨可用区以及 ECS 部署集来部署、添加节点的能力。
2. 容器设计: 应用在集群中多副本部署,基于 Deployment、Statefulset 以及 OpenKruise CRD 等来管理应用的副本,实现应用的高可用性;为应用配置自动弹性策略,以应对负载的动态变化。在多副本 Pod 的场景下,根据是否有主备角色的副本,可以分为主备形态高可用和多活形态高可用。
3. 资源调度: 使用 K8s 的调度器来实现应用的负载均衡和故障转移。使用标签和选择器来指定应用的部署节点范围,并使用亲和性、反亲和性、拓扑调度约束规则来控制应用的调度策略,实现 Pod 的按节点、可用区、部署集、拓扑域等不同类别的高可用。
4. 存储设计: 使用持久化存储来保存应用的数据,例如 K8s 的持久化卷来挂载存储等,以避免数据丢失。对于有状态应用,使用 StatefulSet 来管理有状态应用的副本和存储卷。
5. 故障恢复: 使用 K8s 的自动恢复机制来处理应用的故障。可以使用健康检查和自动重启来监测应用的健康状态,并在应用故障时自动重启或迁移应用。
6. 网络设计: 使用 K8s 的服务发现和负载均衡功能来实现应用的网络访问,可以使用 Service 和 Ingress 来暴露应用的服务。
7. 监控告警: 使用 K8s 的监控和告警系统(例如 Prometheus、Thanos、AlertManager 等)来监控应用的运行状态,并及时发现和处理故障。
8. 全链路高可用设计: 全链路高可用是指云原生应用的系统和服务中,所有涉及到的组件、模块、服务和网络等环节都具备高可用性。全链路高可用是一个综合性的考虑,需要从整个系统的架构设计、组件的选择和配置、服务的部署和运维等方面进行综合考虑和实施。同时,需要根据具体的业务需求和技术要求,进行适度的折中和权衡。
总之,设计 K8s 应用的高可用架构需要综合考虑集群、容器、资源调度、存储、故障恢复、网络以及监控告警等方面的因素,实现可靠稳定的应用高可用性架构和功能。对于已有系统的高可用改造也可以参考如上原则实施。
下面会介绍一下,基于如上设计原则,Kubernetes 提供的多种高可用技术,以及基于 ACK 的相关产品化实现。
K8s 高可用技术和在 ACK 的运用
Kubernetes 提供了多种高可用技术和机制,以确保集群和应用的高可用性。包括拓扑分布约束、PodAntiAffinity、容器健康检查和自动重启、存储冗余和持久化、服务发现和负载均衡等。这些技术和机制可以帮助构建高可用的 Kubernetes 集群和应用,提供稳定、可靠的服务,下面会展开介绍。
3.1 控制面/数据面按多可用区高可用
集群通过在不同的可用区部署控制面和数据面节点/组件来实现高可用性,是一种重要的高可用架构设计方法。可用区是指云提供商在一个地理区域内提供的逻辑独立数据中心。通过在不同的可用区部署节点,可以确保即使在一个可用区出现故障或不可用的情况下,集群仍然可以继续提供服务。
以下是 K8s 集群节点按可用区高可用设计的关键点,可用于在 Kubernetes 中实现控制面/数据面节点按可用区高可用的配置:
-
多可用区的选择
为集群选择云厂商支持的多个可用区,以减少单点故障的风险。
-
部署控制面节点/组件
将控制面节点和组件(如 etcd、kube-apiserver、kube-controller-manager、kube-scheduler)部署在不同的可用区中,使用云厂商的负载均衡器或 DNS 解析来将流量分发到后端。使用多个 etcd 节点配置一个高可用的 etcd 集群,将其分布在不同的可用区内。这样可以确保即使其中一个 etcd 节点失效,集群仍然可以继续工作。
-
部署数据面节点
将数据面节点分布在多个可用区,以确保 Pod 可以调度到不同可用区实现跨可用区高可用。
-
监控和自动恢复配置监控系统来监测集群的健康状态,并设置自动恢复机制,以便在节点或可用区故障时自动进行故障转移和恢复。
通过按多可用区部署控制面节点/组件和数据面节点,可以提高 Kubernetes 集群的可用性和容错能力,确保即使在单个可用区或节点发生故障时,集群仍然能够继续提供服务。
ACK 提供了覆盖控制面和数据面的集群高可用能力。ACK 容器服务采用 Kubernetes on Kubernetes 架构来托管用户 Kubernetes 集群控制面组件,包括 etcd,API Server,Scheduler 等等,每种控制面组件的多实例均采用高可用架构部署和管理。如果 ACK Pro 集群所在区域的可用区数量为 3 个及以上,ACK Pro 托管集群控制面的 SLA 是 99.95%;如果 ACK Pro 集群所在区域的可用区数量为 2 个及以下,ACK Pro 托管集群控制面的 SLA 是 99.50%。
ACK 容器服务负责托管面组件的高可用性,安全性以及弹性扩缩容。ACK Pro 集群对托管组件提供了完备的可观测能力,帮助用户对集群状态进行监控、告警。
下面介绍常见的控制按可用区高可用打散的技术以及 ACK 场景下的使用,在数据面高可用场景广泛使用。
3.1.1 拓扑分布约束 Topology Spread Constraints
拓扑分布约束(Topology Spread Constraints)是一种在 Kubernetes 集群中管理 Pod 分布的功能。它可以确保 Pod 在不同的节点和可用区之间均匀分布,以提高应用程序的高可用性和稳定性。该技术适用于工作负载 Deployment、StatefulSet、DaemonSet 和 Job/CronJob。
通过使用拓扑分布约束,可以设置以下配置来控制Pod的分布:
-
MaxSkew
指定每个拓扑域内 Pod 的最大偏差值。拓扑域可以是节点、可用区或其他自定义拓扑域。最大偏差值是一个整数,表示 Pod 在集群的任意两个拓扑域内 Pod 的最大差值。例如,如果 MaxSkew 设置为 2,则在任意两个拓扑域内的 Pod 数量差值不得超过 2 个。
-
TopologyKey
指定用于标识拓扑域的标签或注释的键。可以使用节点标签(例如 node.kubernetes.io/zone),或者自定义的标签或注释。
-
WhenUnsatisfiable
指定当无法满足拓扑分布约束时采取的操作。可以选择的操作有 DoNotSchedule(不调度 Pod)、ScheduleAnyway(强制调度 Pod)和RequireDuringSchedulingIgnoredDuringExecution(要求拓扑分布约束,但不强制执行)。
通过使用这些配置,可以创建拓扑分布约束的策略,以确保 Pod 在集群中按照期望的拓扑分布进行部署。这对于需要在不同的可用区或节点之间均匀分布负载的应用程序非常有用,以提高可靠性和可用性。
apiVersion: apps/v1
kind: Deployment
metadata:name: app-run-per-zone
spec:replicas: 3selector:matchLabels:app: app-run-per-zonetemplate:metadata:labels:app: app-run-per-zonespec:containers:- name: app-containerimage: app-imagetopologySpreadConstraints:- maxSkew: 1topologyKey: "topology.kubernetes.io/zone"whenUnsatisfiable: DoNotSchedule
在上述示例中,创建了一个拓扑分布约束,其中 maxSkew 设置为 1,topologyKey 设置为 “topology.kubernetes.io/zone”,whenUnsatisfiable 设置为 DoNotSchedule。这意味着 Pod 按由节点的 label “topology.kubernetes.io/zone”(对应到云厂商的可用区)定义的拓扑域进行按可用区强制打散,且拓扑域之间 Pod 数量最大差值为 1。通过这种方式,可以将 Workload 的 Pod 尽量按可用区打散调度。
ACK K8s 集群控制面默认采用了多可用区的高可用架构,进一步我们需要实现数据面的多可用区架构。ACK 集群的数据面由节点池和虚拟节点组成。每个节点池是一组 ECS 实例,通过节点池,用户可以对节点进行管理、扩缩容与日常运维。虚拟节点可以通过弹性容器实例 ECI 来提供 Serverless 化的容器运行环境。
每个节点池背后是一个弹性伸缩组(ESS),支持节点的手动扩缩容与自动化弹性伸缩。ACK 节点池支持部署集,可以将同一部署集中的 ECS 实例打散部署在不同的物理服务器上,从而避免由于一台物理机失效导致多台 ECS 实例宕机。ACK 也支持多 AZ 节点池:在创建和运行过程中,可以为节点池选择多个跨不同 AZ 的 vSwitch。并选择均衡分布策略,这样可以在伸缩组指定的多可用区(即指定多个专有网络交换机)之间均匀分配 ECS 实例。如果由于库存不足等原因可用区之间变得不平衡,您可以再进行均衡操作来平衡资源的可用区分布。
基于节点、部署集、AZ,这样不同故障域的元信息,结合 K8s 调度中的拓扑分布约束(Topology Spread Constraints),我们可以实现不同级别的故障域隔离能力。首先 ACK 节点池上所有节点会自动添加拓扑相关的 label,比如“kubernetes.io/hostname”, “topology.kubernetes.io/zone”,“topology.kubernetes.io/region” 等。开发者可以使用拓扑分布约束来控制 Pod 在不同故障域间的分布,提升对底层基础设施故障的容忍能力。

3.1.2 拓扑分布约束与 NodeAffinity/NodeSelector 的关系
拓扑分布约束与 NodeAffinity/NodeSelector 的关系是,Node Affinity 和 Node Selectors 主要用于控制 Pod 调度到特定范围的节点上,而拓扑分布约束则更专注于控制 Pod 在不同拓扑域之间的分布。可以通过结合使用这些机制,来更精细地控制 Pod 的调度和分布。
NodeAffinity 和 NodeSelector 可以与拓扑分布约束一起使用。可以先使用 NodeAffinity 和 NodeSelector 来选择满足特定条件的节点,然后使用拓扑分布约束来确保 Pod 在这些节点上的分布符合预期的拓扑分布要求。
具体可以参考 [1]。
关于混合使用 Node Affinity 和 Node Selectors 可以与拓扑分布约束,可以参考 [2]。
3.1.3 拓扑分布约束的不足
拓扑分布约束存在一些限制和不足,需要注意:
-
可用区数量限制:如果可用区的数量非常有限,或者只有一个可用区可用,那么使用拓扑分布约束可能无法发挥其优势。在这种情况下,无法实现真正的可用区故障隔离和高可用性。
-
当 Pod 被移除时,并不能保证约束条件仍然得到满足。例如,缩减一个 Deployment 可能会导致 Pods 分布不均衡。
-
调度器并没有对集群中的所有区域或其他拓扑域有先前的了解。它们是根据集群中现有的节点确定的。这可能会导致在自动扩展集群中出现问题,当一个节点池(或节点组)被缩减到零个节点时,而用户期望集群能够扩展时,此时这些拓扑域将不被考虑,直到至少有一个节点在其中。
更多详细内容参考 [3]。
3.1.4 多可用区实现同时快速弹性扩容
ACK 节点自动伸缩组件可通过预调度判断服务能否部署在某个伸缩组上,然后将扩容实例个数的请求发给指定伸缩组,最终由 ESS 伸缩组生成实例。但这种在一个伸缩组上配置多个可用区 vSwtich 的模型特点,会导致以下问题:
当多可用区业务 Pod 出现由于集群资源不足无法调度时,节点自动伸缩服务会触发该伸缩组扩容,但是无法将需要扩容的可用区与实例的关系传递到 ESS 弹性伸缩组,因此可能会连续弹出某一个地域的多个实例,而非在多个 vSwtich 同时弹出,这样无法满足在多可用区同时扩容的需求。
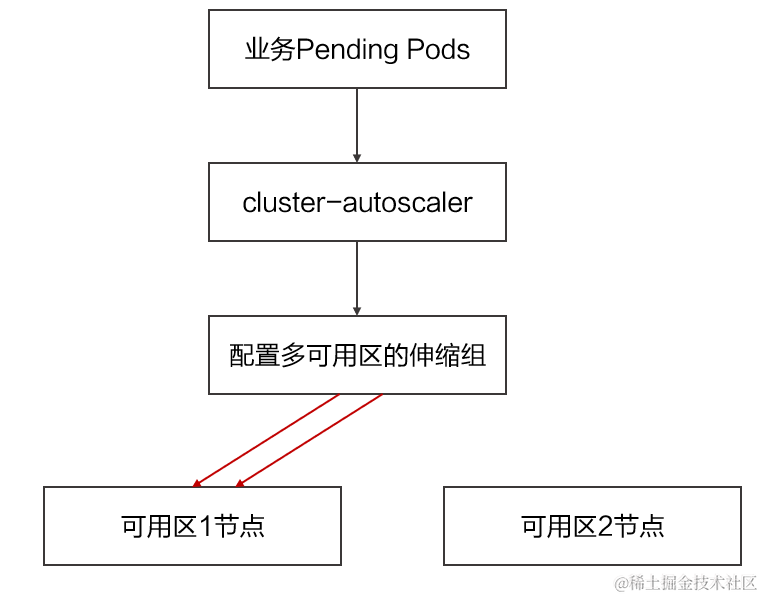
多可用区均衡是数据类型业务高可用场景下常用的部署方式。当业务压力增大时,有多可用区均衡调度策略的应用希望可以自动扩容出多个可用区的实例来满足集群的调度水位。
为了解决同时扩容多可用区节点的问题,容器服务 ACK 引入了 ack-autoscaling-placeholder 组件,通过少量的资源冗余方式,将多可用区的弹性伸缩问题转变为并发节点池的定向伸缩问题。
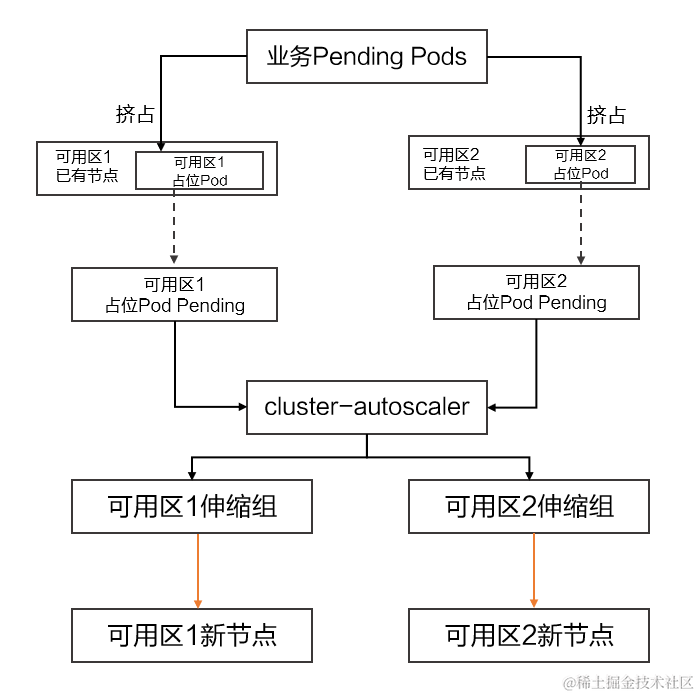
具体原理如下:
-
首先为每个可用区创建一个节点池,并分别在各个节点池打上可用区的标签。
-
通过配置可用区标签 nodeSelector 的方式,使用 ack-autoscaling-placeholder 为每个可用区创建占位 Pod,默认的占位 Pod 具有比较低权重的 PriorityClass,应用 Pod 的优先级高于占位 Pod。
-
这样业务应用 Pod Pending 后,会抢占各个可用区占位 Pod,带有可用区 nodeSelector 的多可用区占位 Pod 处于 Pending 后,节点自动伸缩组件感知到的调度策略就从多个可用区的 anti-affinity 变成了可用区的 nodeSelector,从而可以轻松处理发出扩容区域的节点的请求。
以下图两个可用区为例,介绍利用现有架构上能满足多可用区同时扩容的方法。
详细内容请参考 [4]。
3.1.5 可用区容量受损后的自动恢复
多可用区高可用集群,当面临着 AZ 失效时,往往意味着应用容量受损,K8s 会根据应用的副本数或者 HPA(水平 Pod 伸缩)配置进行自动化的扩容。这里面需要集群配置 Cluster AutoScaler 或者虚拟节点实现集群资源的自动扩容。当使用 Cluster AutoScaler 时,可以通过对资源的超额分配进行预留,这样可以实现容器应用的快速拉起,并且避免因为底层扩容缓慢或者失败导致的业务中断。详细内容请参考 [5]。
3.2 应用 Pod 按节点反亲和(PodAntiAffinity)
Pod 反亲和(PodAntiAffinity)是一种 Kubernetes 中的调度策略,用于在调度 Pod 时确保它们不会被调度到同一个节点上。这可以用于实现对 Pod 的节点打散,以提高应用程序的高可用性和故障隔离能力。
通过使用 Pod 反亲和策略,您可以配置以下方式来控制 Pod 的节点打散:
1.RequiredDuringSchedulingIgnoredDuringExecution
这是一种强制执行的策略,它要求 Pod 之间的反亲和关系在调度时得到满足。这意味着 Kubernetes 调度器会尽力确保在调度 Pod 时,它们不会被调度到同一个节点上。然而,在调度后,如果节点资源不足或其他原因导致在同一节点上运行这些 Pod 成为必要,Kubernetes 会忽略这个反亲和策略。
2.PreferredDuringSchedulingIgnoredDuringExecution
这是一种偏好性的策略,它建议 Pod 之间保持反亲和关系,但不是强制要求。当调度器有多个选择时,它会尽量避免在同一个节点上调度这些 Pod。然而,如果没有其他可行的选择,调度器仍然可以在同一节点上调度这些 Pod。
通过使用 Pod 反亲和策略,您可以控制集群中 Pod 的分布,避免将它们调度到同一节点上,从而实现节点的打散。这对于需要在不同的节点上运行 Pod 的应用程序非常有用,以提高可用性和故障隔离能力。
以下是一个 Pod 反亲和的示例:
apiVersion: apps/v1
kind: Deployment
metadata:name: app-run-per-node
spec:replicas: 3selector:matchLabels:app: app-run-per-nodetemplate:metadata:labels:app: app-run-per-nodespec:containers:- name: app-containerimage: app-imageaffinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- app-run-per-nodetopologyKey: "kubernetes.io/hostname"
在上述示例中,对 Pod 进行了反亲和设置,要求调度器在调度时确保这些 Pod 不会被调度到同一个节点上。拓扑键设置为 “kubernetes.io/hostname”,使得调度器能够在不同的节点之间进行打散。
请注意,Pod 反亲和和节点亲和性(Node Affinity)是不同的概念。节点亲和性用于指定 Pod 偏好于调度到具有特定标签的节点上,而 Pod 反亲和则用于确保 Pod 不会调度到同一个节点上。结合使用这两个调度策略可以实现更灵活和具有容错能力的调度和节点分布。
基于 TopologySpreadConstraints 也可以实现 Pod 按节点高可用的调度效果,指定 topologyKey: “kubernetes.io/hostname” 相当于每个节点就是一个拓扑域,实现节点之间 skew 的比较。以下是一个拓扑分布约束的示例:
apiVersion: apps/v1
kind: Deployment
metadata:name: my-app
spec:replicas: 3selector:matchLabels:app: my-apptemplate:metadata:labels:app: my-appspec:containers:- name: my-app-containerimage: my-app-imagetopologySpreadConstraints:- maxSkew: 1topologyKey: "kubernetes.io/hostname"whenUnsatisfiable: DoNotSchedule
在上述示例中,创建了一个拓扑分布约束,其中 maxSkew 设置为 1,topologyKey 设置为 “kubernetes.io/hostname”,whenUnsatisfiable 设置为 DoNotSchedule。这意味着在每个节点上最多只能运行 1 个 Pod 实现强制 Pod 按节点高可用打散。
3.3 应用多副本高可用
在 Kubernetes 中可以基于多种工作负载实现应用多副本高可用,比如 Deployment、Statefulset 以及 OpenKruise 等 CRD 高级资源。以 Deployment 为例,Deployment 资源是一种用于定义 Pod 副本数量的控制器,它负责确保指定数量的副本一直在运行,并在副本失败时自动创建新的副本。
3.3.1 应用多活高可用
应用的多活高可用,是应用的多个副本均可以接收流量并独立处理业务,可以通过 HPA 方式配置副本数根据负载压力触发的自动弹性实现对动态流量的自适应,例如 API Server、Nginx Ingress Controller。这种形态的高可用设计,需要考虑多副本的数据一致性和性能等问题。
3.3.2 应用主备高可用
应用的主备高可用,是应用多副本中存在主副本和备副本,最常见的是一主一备,也存在一主多从等更复杂的形态,基于抢锁等方式来选主,适用于控制器等形态的组件。比如 Etcd,KubeControllerManager,KubeScheduler 都是主备形态的高可用应用。
用户可以根据自己的业务形态和场景,来设计控制器使用多活或者主备。
3.3.3 PDB 提升应用高可用
为了进一步提高应用的可用性,在 Kubernetes 中还可以使用 Pod Disruption Budget(PDB)配置。PDB 允许使用者定义一个最小可用副本数,当进行节点维护或故障时,Kubernetes 将确保至少有指定数量的副本保持运行。PDB 可以防止过多的副本同时终止,尤其适合多活副本处理流量型的场景,例如 MessageQueue 产品,从而避免服务中断。
要使用 PDB,可以在 Deployment 或 StatefulSet 的配置中添加一个 PDB 资源,并指定最小可用副本数。例如,以下是一个使用 PDB 的 Deployment 配置示例:
apiVersion: apps/v1
kind: Deployment
metadata:name: app-with-pdb
spec:replicas: 3selector:matchLabels:app: app-with-pdbtemplate:metadata:labels:app: app-with-pdbspec:containers:- name: app-containerimage: app-container-imageports:- containerPort: 80---apiVersion: policy/v1beta1kind: PodDisruptionBudgetmetadata:name: pdb-for-appspec:minAvailable: 2selector:matchLabels:app: app-with-pdb
在上述示例中,Deployment 配置定义了 3 个副本,PDB 配置指定了至少要保持 2 个副本可用。这意味着,即使在节点维护或故障时,Kubernetes 也会确保至少有 2 个副本一直在运行,提高应用程序在 Kubernetes 集群中的可用性,并减少可能的服务中断。
3.4 健康检测与自愈
在 Kubernetes 中,可以通过配置不同类型的探针来监测和管理容器的状态和可用性。以下是 Kubernetes 中常用的探针配置和策略:
-
存活探针(Liveness Probes) 存活探针用于监测容器是否仍然运行正常。如果存活探针失败(返回非 200 状态码),Kubernetes 将会重启容器。通过配置存活探针,可以确保容器在出现问题时能够自动重启。存活探针可以使用 HTTP 请求、TCP 套接字或命令执行来进行检测。
-
就绪探针(Readiness Probes) 就绪探针用于监测容器是否已经准备好接收流量。只有在就绪探针成功(返回 200 状态码)时,Kubernetes 才会将流量转发给容器。通过配置就绪探针,可以确保只有当容器完全启动并准备好接收请求时,才将它们加入服务的负载均衡。
-
启动探针(Startup Probes) 启动探针用于监测容器是否正在启动过程中。与存活探针和就绪探针不同,启动探针在容器启动期间执行,并且只有在探针成功后,才会将容器标记为就绪状态。如果启动探针失败,Kubernetes 会将容器标记为失败状态,并重新启动容器。
-
重启策略(Restart Policy) 重启策略定义了在容器退出时应采取的操作。Kubernetes 支持以下三种重启策略:
-
- Always:无论容器以任何方式退出,Kubernetes 都会自动重启容器。
- OnFailure:只有当容器以非零状态退出时,Kubernetes 才会自动重启容器。
- Never:无论容器以任何方式退出,Kubernetes 都不会自动重启容器。
可以通过在 Pod 或 Deployment 的配置中添加相应的探针和重启策略来进行配置,例如:
apiVersion: v1
kind: Pod
metadata:name: app-with-probe
spec:containers:- name: app-containerimage: app-imagelivenessProbe:httpGet:path: /healthport: 80initialDelaySeconds: 10periodSeconds: 5readinessProbe:tcpSocket:port: 8080initialDelaySeconds: 15periodSeconds: 10startupProbe:exec:command:- cat- /tmp/readyinitialDelaySeconds: 20periodSeconds: 15restartPolicy: Always
在上述示例中,配置了一个存活探针(通过 HTTP GET 请求检测路径为 /health 的端口 80)、一个就绪探针(通过 TCP 套接字检测端口 8080)、一个启动探针(通过执行命令 cat /tmp/ready 来检测容器是否启动完成)和重启策略为 Always。根据实际需求,可以根据容器的特性和健康检查的要求进行适当的配置。
3.5 应用与数据解耦
在 Kubernetes 中,实现应用与数据解耦可以通过使用 Persistent Volumes(PV)和 Persistent Volume Claims(PVC)来实现,也可以选择合适的后端数据库服务存储。
PV 和 PVC 提供了一种抽象层,使应用程序可以独立于底层存储技术使用。Persistent Volumes 是集群中的存储资源,它们独立于 Pod 和节点。Persistent Volume Claims 是对 Persistent Volumes 的请求,用于将存储资源绑定到应用程序的 Pod 中。
要选择合适的 Persistent Volume Claims 和 Persistent Volumes,需要考虑以下几个因素:
-
存储类型
根据应用程序的需求选择合适的存储类型。Kubernetes 支持多种存储类型,包括本地存储、网络存储(如 NFS、iSCSI 等)、云提供商的持久化存储(如阿里云 OSS 等)以及外部存储插件(如 Ceph、GlusterFS 等)。根据应用程序的读写性能、数据保护和可用性要求选择适当的存储类型。
-
存储容量
根据应用程序的存储需求选择合适的存储容量。在创建 Persistent Volume 时,可以指定存储容量的大小范围。在创建 Persistent Volume Claim 时,可以指定所需的存储容量。确保为应用程序提供足够的存储空间,以满足其数据存储需求。
-
访问模式
根据应用程序的访问模式选择适当的访问模式。Kubernetes 支持多种访问模式,包括读写一致(ReadWriteOnce)、读写多次(ReadWriteMany)和只读(ReadOnlyMany)。根据应用程序的多节点访问需求选择适当的访问模式。
选择合适的后端数据服务,如 RDS 等,需要考虑以下因素:
-
数据库类型和功能
根据应用程序的需求选择合适的数据库类型。不同的数据库类型如关系型数据库(如 MySQL、PostgreSQL)、NoSQ L数据库(如 MongoDB、Cassandra)等提供不同的功能和适应性。根据应用程序的数据模型和查询需求选择适当的数据库类型。
-
性能和扩展性
根据应用程序的性能要求选择后端数据服务。考虑数据库的性能指标(如吞吐量、延迟)以及其扩展性能。
-
可用性和可靠性
选择后端数据服务时要考虑其可用性和可靠性。云提供商的托管数据库服务通常提供高可用性和自动备份功能。确保选择一个能够满足应用程序的可用性和数据保护需求的后端数据服务。
3.6 负载均衡高可用配置
传统型负载均衡 CLB 已在大部分地域部署了多可用区以实现同地域下的跨机房容灾。可以通过 Service Annoation 来指定 SLB/CLB 的主备可用区,主备可用区应该与节点池中 ECS 可用区保持一致,可以减少跨可用区数据转发,提升网络访问性能。
apiVersion: v1
kind: Service
metadata:annotations:service.beta.kubernetes.io/alibaba-cloud-loadbalancer-master-zoneid: "cn-hangzhou-a"service.beta.kubernetes.io/alibaba-cloud-loadbalancer-slave-zoneid: "cn-hangzhou-b"name: nginxnamespace: default
spec:ports:- port: 80protocol: TCPtargetPort: 80selector:run: nginxtype: LoadBalancer
为了减少跨可用区网络流量,提升网络性能。我们可以使用在 Kubernetes 1.23 中引入拓扑感知提示 (Topology Aware Hints) 实现了拓扑感知的就近路由功能。
3.7 云盘高可用配置
目前阿里云云盘只能在单可用区进行创建和挂载,在多可用区集群中使用云盘作为持久化应用的数据存储,需要选择 ACK 提供的拓扑感知的云盘存储类型 alicloud-disk-topology [6] 来创建 PersistentVolumeClaim,此存储类 Volume Binding Mode 默认是 WaitForFirstConsumer 支持延迟绑定直至 PersistentVolumeClaim 被在对应的可用区创建出来。可以创建更精细化的指定多可用区拓扑感知的 ESSD 云盘存储类来生成存储卷,存储声明和持久化应用如下示例,更多内容详见文档 [7]。
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: alicloud-disk-topology-essd
provisioner: diskplugin.csi.alibabacloud.com
parameters:type: cloud_essdfstype: ext4diskTags: "a:b,b:c"zoneId: “cn-hangzhou-a,cn-hangzhou-b,cn-hangzhou-c” #指定可用区范围来生成云盘encrypted: "false"performanceLevel: PL1 #指定性能类型volumeExpandAutoSnapshot: "forced" #指定扩容编配的自动备份开关,该设置仅在type为"cloud_essd"时生效。
volumeBindingMode: WaitForFirstConsumer
reclaimPolicy: Retain
allowVolumeExpansion: true
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: topology-disk-pvc
spec:accessModes:- ReadWriteOncevolumeMode: Filesystemresources:requests:storage: 100GistorageClassName: alicloud-disk-topology-essd
---
apiVersion: apps/v1
kind: StatefulSet
metadata:name: mysql
spec:serviceName: "mysql"selector:matchLabels:app: mysqltemplate:metadata:labels:app: mysqlspec:containers:- image: mysql:5.6name: mysqlenv:- name: MYSQL_ROOT_PASSWORDvalue: "mysql"volumeMounts:- name: datamountPath: /var/lib/mysqlvolumes:- name: datapersistentVolumeClaim:claimName: topology-disk-pvc
3.8 虚拟节点高可用配置
虚拟节点(Virtual Node)支持 Kubernetes 应用部署在弹性容器实例 ECI 之中,无需进行节点运维,按需创建,降低了预留资源浪费。为应对突发流量而进行业务的快速水平扩容,或者启动大量实例进行 Job 任务处理时,可能会遇到可用区对应规格实例库存不足或者指定的交换机 IP 耗尽等情况,从而导致 ECI 实例创建失败。使用 ACK Serverless 的多可用区特性可以提高 ECI 实例的创建成功率。
虚拟节点可以通过 ECI Profile 配置跨不同 AZ 的 vSwitch 实现跨多 AZ 应用部署。
- ECI 会把创建 Pod 的请求分散到所有的 vSwitch 中,从而达到分散压力的效果。
- 如果创建 Pod 请求在某一个 vSwitch 中遇到没有库存的情况,会自动切换到下一个 vSwitch 继续尝试创建。
根据实际需求修改 kube-system/eci-profile configmap 中的 vswitch 字段,修改后即时生效。
kubectl -n kube-system edit cm eci-profile
apiVersion: v1
data:kube-proxy: "true"privatezone: "true"quota-cpu: "192000"quota-memory: 640Tiquota-pods: "4000"regionId: cn-hangzhouresourcegroup: ""securitygroupId: sg-xxxvpcId: vpc-xxxvswitchIds: vsw-xxx,vsw-yyy,vsw-zzz
kind: ConfigMap
相关内容可以参考 [8]。
3.9 监控告警配置
通过 K8s 自身以及 kube-state-metrics 等组件透出的指标,可以有效监控 Pod、Node 等资源高可用性以及可用区分布情况,这对于快速发现、定位问题有积极重要的意义。在生产环境,监控告警系统是持续建并根据 K8s 版本、组件版本升级而迭代更新的,建议持续关注新指标并根据业务场景引入到监控告警系统中。下面列举两个资源高可用的告警配置做参考。
3.9.1 应用负载副本不可用的监控告警
K8s 的 kube-state-metrics 可以聚合分析应用负载 Deployment/Statefulset/Daemonset 的不可用副本数、副本总数等,基于该类指标可以发现应用是否存在不可用副本以及不可用副本占总副本数的百分比,实现服务部分受影响、全部影响的监控告警。
以 Deployment 为例,AlertManager/Thanos Ruler 的告警示例如下:
# kube-system或者monitoring中的Deployment存在不可用副本,持续1m,则触发告警,告警serverity配置为L1
- alert: SystemPodReplicasUnavailableexpr: kube_deployment_status_replicas_unavailable{namespace=~"kube-system|monitoring",deployment!~"ack-stub|kubernetes-kdm"} > 0labels:severity: L1annotations:summary: "namespace={{$labels.namespace}}, deployment={{$labels.deployment}}: Deployment存在不可用Replica"for: 1m
# kube-system或者monitoring中的Deployment副本总数>0,且全部副本不可用,持续1m,则触发告警,告警serverity配置为L1
- alert: SystemAllPodReplicasUnavailableexpr: kube_deployment_status_replicas_unavailable{namespace=~"kube-system|monitoring"} == kube_deployment_status_replicas{namespace=~"kube-system|monitoring"} and kube_deployment_status_replicas{namespace=~"kube-system|monitoring"} > 0labels:severity: L1annotations:summary: "namespace={{$labels.namespace}}, deployment={{$labels.deployment}}: Deployment全部Replicas不可用"for: 1m
3.9.2 集群可用区内不健康节点百分比的监控告警
K8s 的 kube-controller-manager 组件有统计可用区内的不健康节点数、健康节点百分比和节点总数,可以配置相关告警。
# HELP node_collector_unhealthy_nodes_in_zone [ALPHA] Gauge measuring number of not Ready Nodes per zones.
# TYPE node_collector_unhealthy_nodes_in_zone gauge
node_collector_unhealthy_nodes_in_zone{zone="cn-shanghai::cn-shanghai-e"} 0
node_collector_unhealthy_nodes_in_zone{zone="cn-shanghai::cn-shanghai-g"} 0
node_collector_unhealthy_nodes_in_zone{zone="cn-shanghai::cn-shanghai-l"} 0
node_collector_unhealthy_nodes_in_zone{zone="cn-shanghai::cn-shanghai-m"} 0
node_collector_unhealthy_nodes_in_zone{zone="cn-shanghai::cn-shanghai-n"} 0
# HELP node_collector_zone_health [ALPHA] Gauge measuring percentage of healthy nodes per zone.
# TYPE node_collector_zone_health gauge
node_collector_zone_health{zone="cn-shanghai::cn-shanghai-e"} 100
node_collector_zone_health{zone="cn-shanghai::cn-shanghai-g"} 100
node_collector_zone_health{zone="cn-shanghai::cn-shanghai-l"} 100
node_collector_zone_health{zone="cn-shanghai::cn-shanghai-m"} 100
node_collector_zone_health{zone="cn-shanghai::cn-shanghai-n"} 100
# HELP node_collector_zone_size [ALPHA] Gauge measuring number of registered Nodes per zones.
# TYPE node_collector_zone_size gauge
node_collector_zone_size{zone="cn-shanghai::cn-shanghai-e"} 21
node_collector_zone_size{zone="cn-shanghai::cn-shanghai-g"} 21
node_collector_zone_size{zone="cn-shanghai::cn-shanghai-l"} 21
node_collector_zone_size{zone="cn-shanghai::cn-shanghai-m"} 21
node_collector_zone_size{zone="cn-shanghai::cn-shanghai-n"} 21
AlertManager/Thanos Ruler 的告警示例如下:
# node_collector_zone_health <= 80 如果可用区内健康节点比例小于80%,就触发告警。
- alert: HealthyNodePercentagePerZoneLessThan80expr: node_collector_zone_health <= 80labels:severity: L1annotations:summary: "zone={{$labels.zone}}: 可用区内健康节点与节点总数百分比 <= 80%"for: 5m
应用的单/多集群高可用架构
基于如上第三章介绍的高可用技术和阿里云产品能力提供的产品能力,可以全面实现单个集群范围内的高可用架构。多集群高可用架构是在单集群高可用架构上进步升级的高可用架构,提供了跨集群/地域的高可用服务能力。
通过多地域、多集群的部署和单元化应用架构,可以在保证高可用性的前提下,克服跨地域网络传输延迟、成本和故障率的挑战。这样可以为用户提供更好的使用体验,同时确保业务的稳定性和可靠性。
4.1 单地域多可用区高可用集群
基于如上第三章介绍的高可用技术和阿里云产品能力提供的能力,可以实现单个集群维度内的高可用架构,这里不再赘述。
4.2 单地域多集群高可用 + 多地域多集群高可用
首先每个 ACK 集群均采用多可用区高可用架构,业务应用采用多可用区部署模式,通过 SLB 对外提供服务。
多地域部署和多可用区部署在本质上是相似的,但由于地域间网络传输延迟、成本和故障率的差异,需要采用不同的部署和应用架构来适应。对于平台层来说,不建议实现跨地域的 Kubernetes 集群,而是推荐采用多地域多集群的方式,并结合单元化应用架构来实现多地域的高可用架构。在不同的地域部署多个独立的 Kubernetes 集群,每个集群管理自己的节点和应用。每个地域的集群都是独立的,具有自己的 Master 节点和工作节点。这样可以降低跨地域的网络延迟和故障率,提高应用的可用性和性能。
同时,采用单元化应用架构,将应用拆分为独立的单元,每个单元在多个地域的集群中部署副本。通过负载均衡和 DNS 解析技术,可以实现用户请求的就近路由,将流量分发到最近的地域,减少网络延迟,并提供高可用性和容灾能力。
跨地域 ACK 集群如果需要网络互联,可以通过云企业网 CEN 实现多地域 VPC 间的互联互通。地域间业务流量调度通过全局流量关了 GTM 与云解析服务实现。
如果希望对多地域多集群进行统一管理,比如可观测、安全策略,以及实现应用的跨集群统一交付。我们可以利用 ACK One 进行实现。分布式云容器平台 ACK One(Distributed Cloud Container Platform for Kubernetes)是阿里云面向混合云、多集群、分布式计算、容灾等场景推出的企业级云原生平台。ACK One 可以连接并管理用户在任何地域、任何基础设施上的 Kubernetes 集群,并提供一致的管理和社区兼容的 API,支持对计算、网络、存储、安全、监控、日志、作业、应用、流量等进行统一运维管控。如您想要了解更多关于 ACK One 的信息 ,欢迎钉钉搜索群号:35688562 进群交流。
ACK One 构建应用系统的两地三中心容灾方案,相关内容可以参考 [9]。
链接总结
云原生场景下的应用高可用架构和设计,对于企业服务的可用性、稳定性、安全性至关重要,可以有效提高应用可用性和用户体验,提供故障隔离和容错能力等。本文介绍了云原生应用高可用架构设计的关键原则、K8s 高可用技术以及在 ACK 场景下的使用和实现、单集群和多集群高可用架构的使用,希望为有相关需求的企业提供参考和帮助,ACK 会继续为客户提供安全、稳定、性能、成本持续优化升级的云原生产品和服务!
本文参考了阿里云容器服务负责人易立对于 ACK 高可用架构分析的精彩分享,在此表示诚挚感谢!
相关链接:
[1] https://kubernetes.io/docs/concepts/scheduling-eviction/topology-spread-constraints/#interaction-with-node-affinity-and-node-selectors
[2] https://kubernetes.io/blog/2020/05/introducing-podtopologyspread/
[3] https://kubernetes.io/docs/concepts/scheduling-eviction/topology-spread-constraints/#known-limitations
[4] https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/configure-auto-scaling-for-cross-zone-deployment
[5] https://help.aliyun.com/document_detail/184995.html
[6] https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/dynamically-provision-a-disk-volume-by-using-the-cli-1#section-dh5-bd8-x0q
[7] https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/use-dynamically-provisioned-disk-volumes
[8] https://help.aliyun.com/zh/ack/serverless-kubernetes/user-guide/create-ecis-across-zones
[9] https://developer.aliyun.com/article/913027