文章目录
- 前言
- 完成效果
- 一、下载数据集
- 手动下载
- 代码下载MNIST数据集:
- 二、 展示图片
- 三、DataLoader数据加载器
- 四、搭建神经网络
- 五、 训练和测试
- 第一次运行:
- 六、优化模型
- 第二次优化后运行:
- 七、完整代码
- 八、手写板实现输入识别功能
前言
注意:本代码需要安装PyTorch未安装请看之前的文章https://blog.csdn.net/qq_39583774/article/details/132070870
MNIST(Modified National Institute of Standards and Technology)是一个常用于机器学习和计算机视觉领域的数据集,用于手写数字识别。它包含了一系列28x28像素大小的灰度图像,每个图像都表示了一个手写的数字(0到9之间)。MNIST数据集共有60,000个训练样本和10,000个测试样本,可用于训练和测试各种图像分类算法。
通过使用MNIST数据集,研究人员和开发者可以测试和验证各种机器学习模型和算法的性能,特别是在图像分类领域。这个数据集成为了计算机视觉领域中的基准,许多研究论文和教程都使用它来演示各种图像处理和机器学习技术的效果。
完成效果
准确率有待提高,可能是因为测试数据集和训练数据集的数据是国外,写法有点不一样,如果你能提高这个模型的成功率可以分享给我,感谢。
一、下载数据集
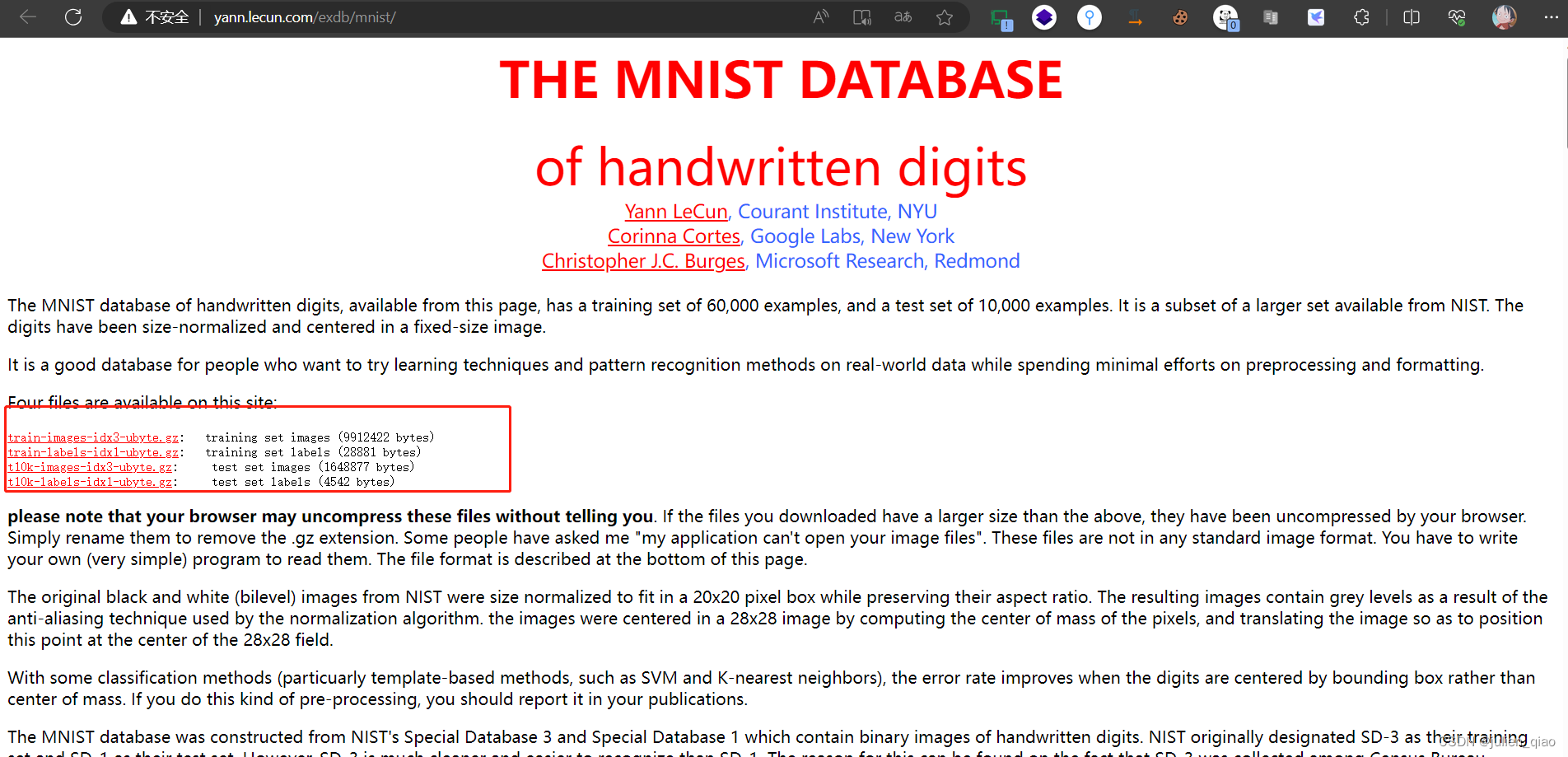
下载可以使用代码也可以使用手动方式下载:
数据集网站:http://yann.lecun.com/exdb/mnist/
手动下载
代码下载MNIST数据集:
#MNIST--手写字识别
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor#创建一个MNIST数据集的实例,其中包括训练图像和标签
training_data = datasets.MNIST(root="data", #下载的跟目录train=True, #加载训练数据集download=True,#如果数据集不存在,将自动下载transform=ToTensor(), #将图像数据转换为Tensor格式的数据(张量),pytorch使用tensor数据流所以这里要转换
)
print(len(training_data))
运行:
打印训练数量:

读取测试数据集:
代码下载工作原理:按住ctrl建跳转源代码
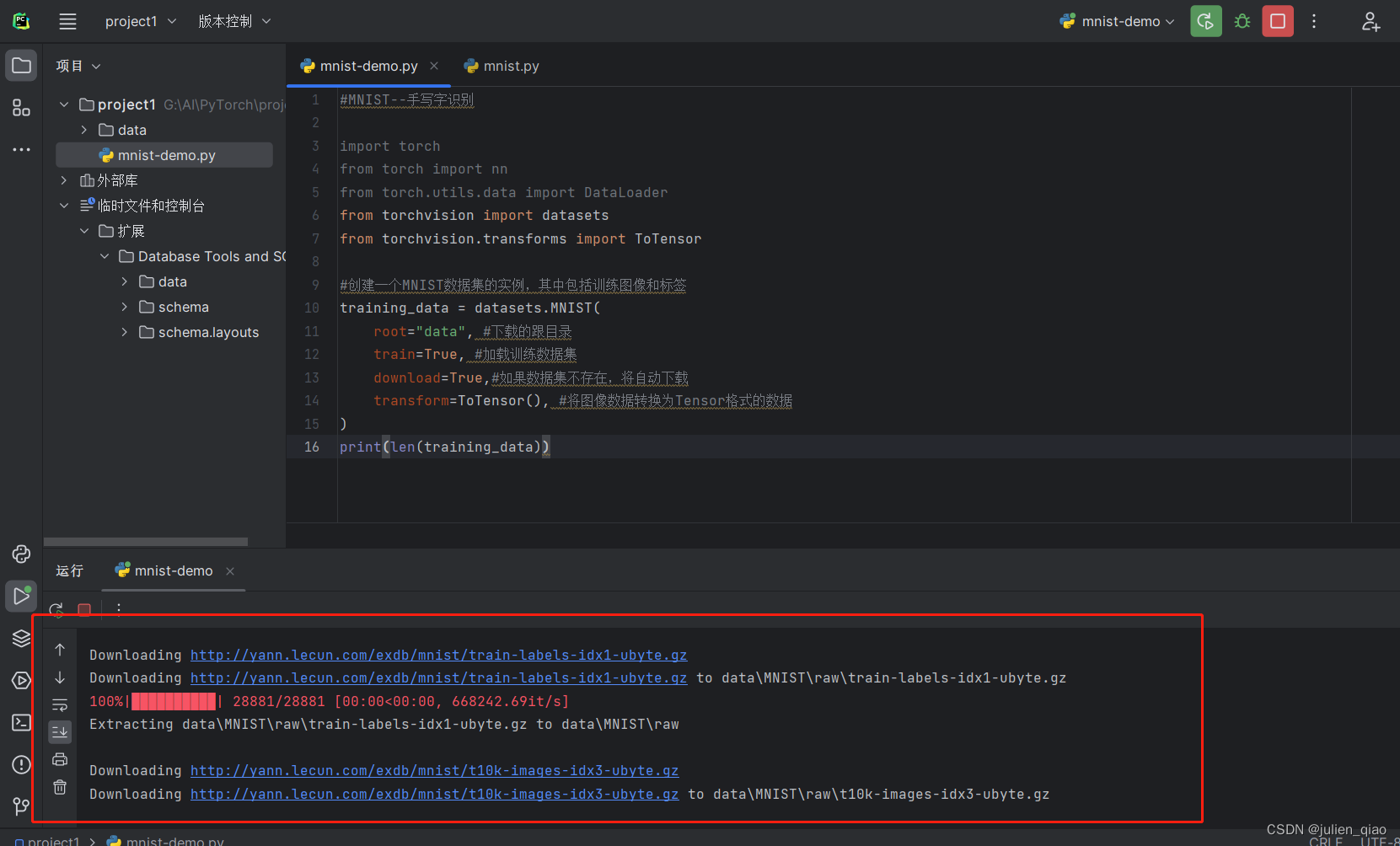
从上面看是通过爬虫方式下载,和我们的手动下载方式差不多

可以看到我们下载好的数据集:
前言中我们有训练数据和测试数据上面是读取训练数据下面我们读取测试数据集:
test_data = datasets.MNIST(root="data", #下载的跟目录train=False, #加载测试数据集download=True,#如果数据集不存在,将自动下载transform=ToTensor(), #将图像数据转换为Tensor格式的数据(张量),pytorch使用tensor数据流所以这里要转换
)
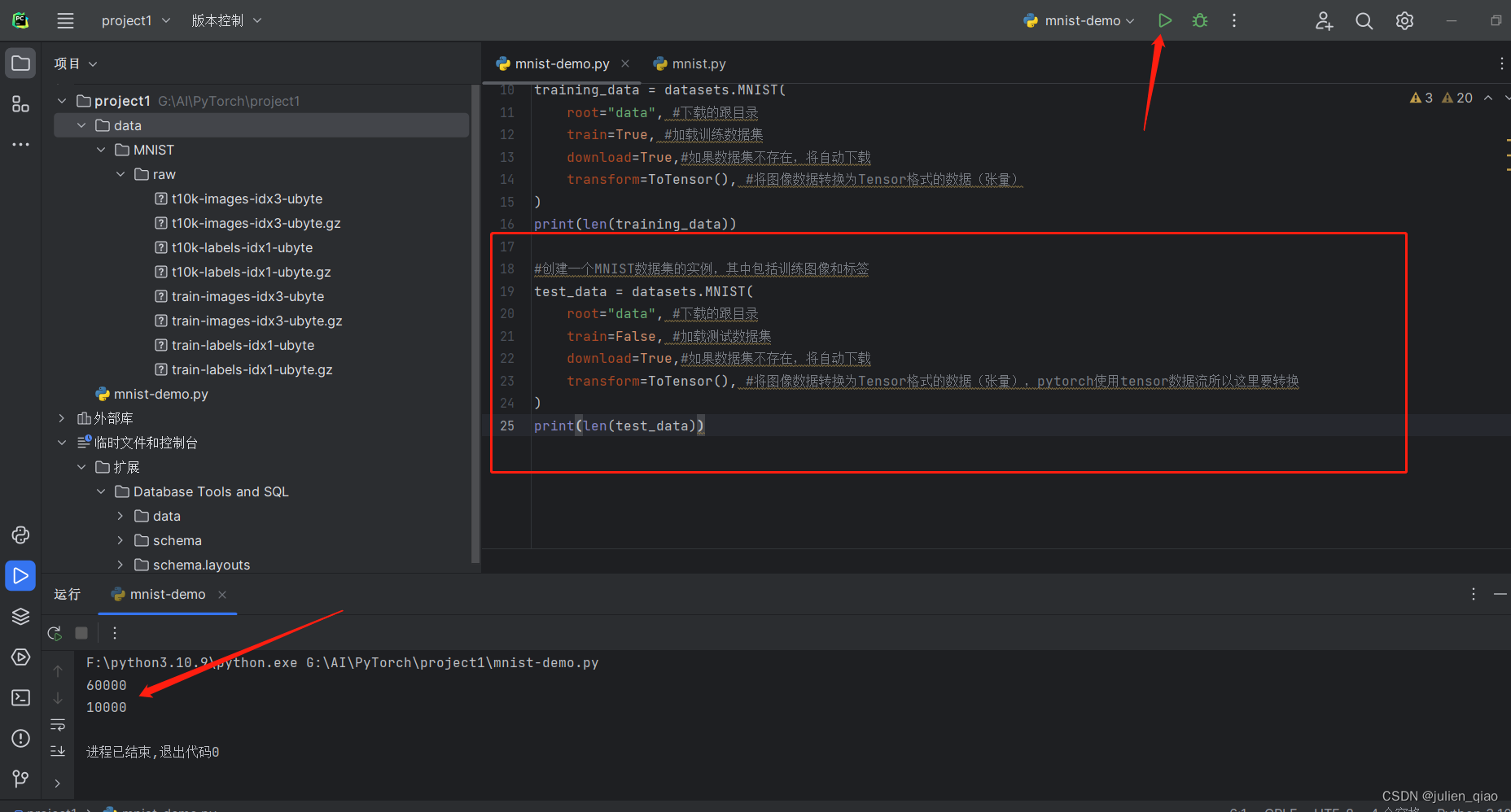
print(len(test_data))
运行一下:
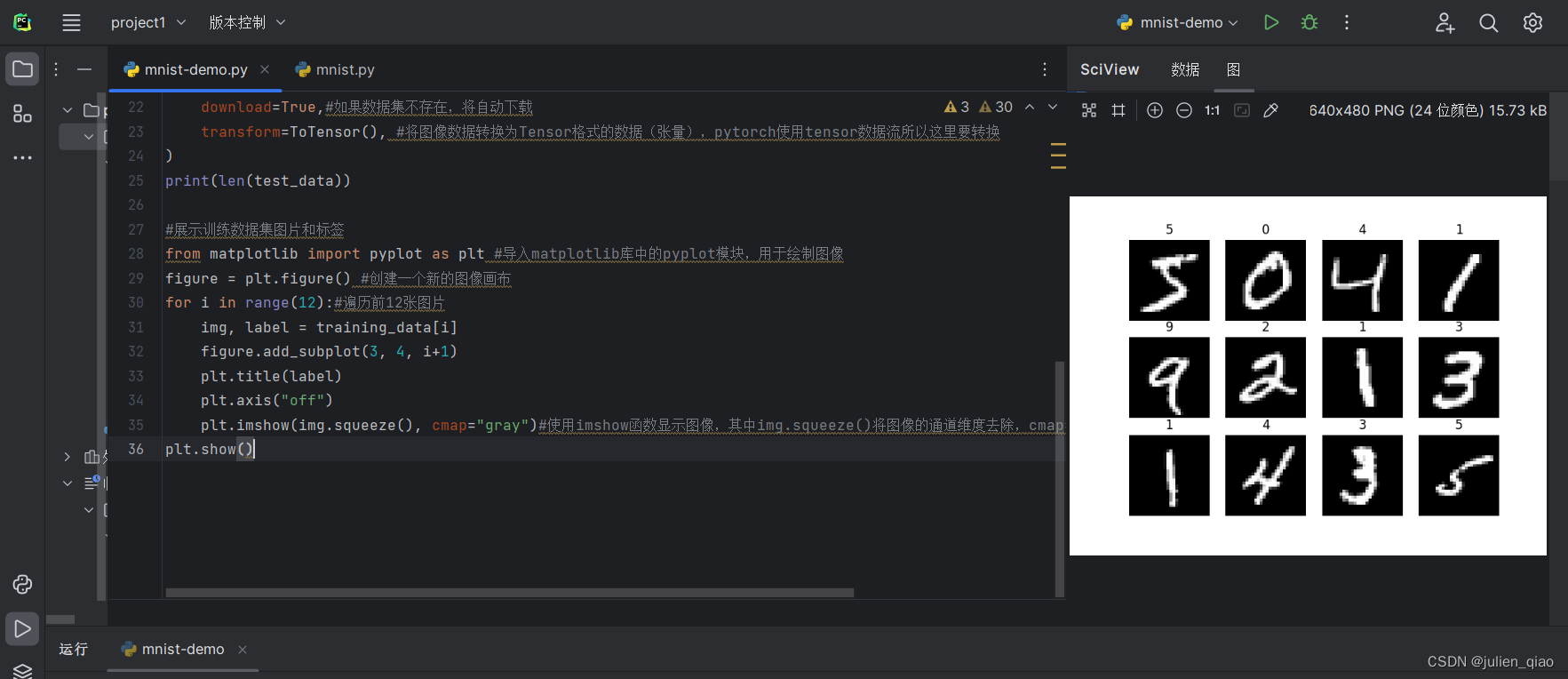
二、 展示图片
#展示训练数据集图片和标签
from matplotlib import pyplot as plt #导入matplotlib库中的pyplot模块,用于绘制图像
figure = plt.figure() #创建一个新的图像画布
for i in range(12):#遍历前12张图片0-12img, label = training_data[i]figure.add_subplot(3, 4, i+1)plt.title(label)plt.axis("off")plt.imshow(img.squeeze(), cmap="gray")#使用imshow函数显示图像,其中img.squeeze()将图像的通道维度去除,cmap="gray"表示使用灰度颜色映射
plt.show()
三、DataLoader数据加载器
为什么要做这一步:因为数据集有6万个数据集,通过打包方式将64个为一组,打包起来一起传入,内存这样可以大大加快处理的速度,不然就是6万多个数据集一个一个传入导致速度变慢。
train_dataloader = DataLoader(training_data, batch_size=64)#创建一个训练数据加载器,将training_data(训练数据集)分成64张图像一组的批次
test_dataloader = DataLoader(test_data, batch_size=64)#创建一个测试数据加载器,将test_data(测试数据集)分成64张图像一组的批次。
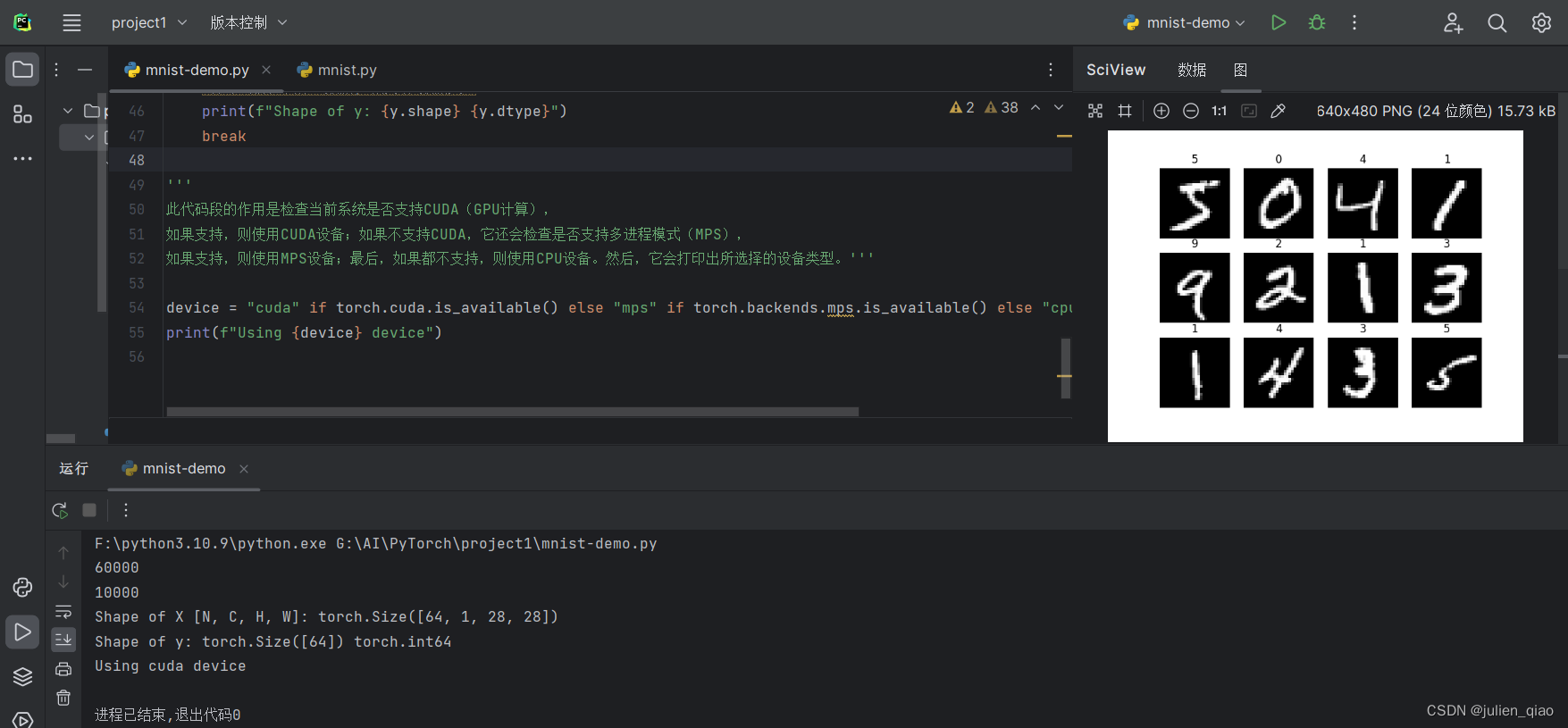
for X, y in test_dataloader:#X是表示打包好的每一个数据包#打印当前批次图像数据X的形状,其中N表示批次大小,C表示通道数,H和W表示图像的高度和宽度print(f"Shape of X [N, C, H, W]: {X.shape}")#打印当前批次标签数据y的形状和数据类型print(f"Shape of y: {y.shape} {y.dtype}")break#这里测试一下第一个组中的形状
'''
此代码段的作用是检查当前系统是否支持CUDA(GPU计算),
如果支持,则使用CUDA设备;如果不支持CUDA,它还会检查是否支持多进程模式(MPS),
如果支持,则使用MPS设备;最后,如果都不支持,则使用CPU设备。然后,它会打印出所选择的设备类型。'''device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device")
第一组中中有64张图像,大小为28*28,使用GPU计算
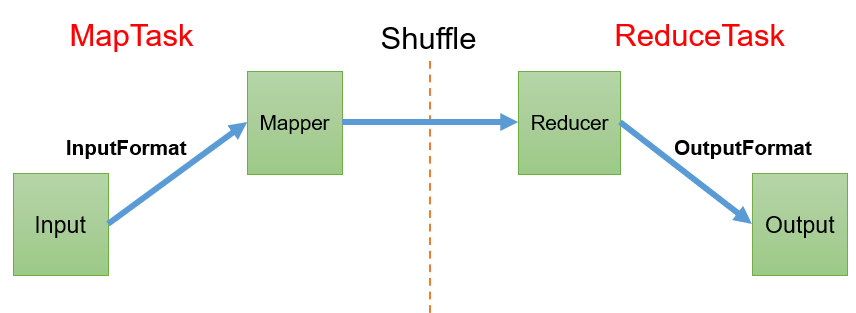
四、搭建神经网络
构造示意图:输出层为固定参数十个,因为数字数字0-9一共就十个
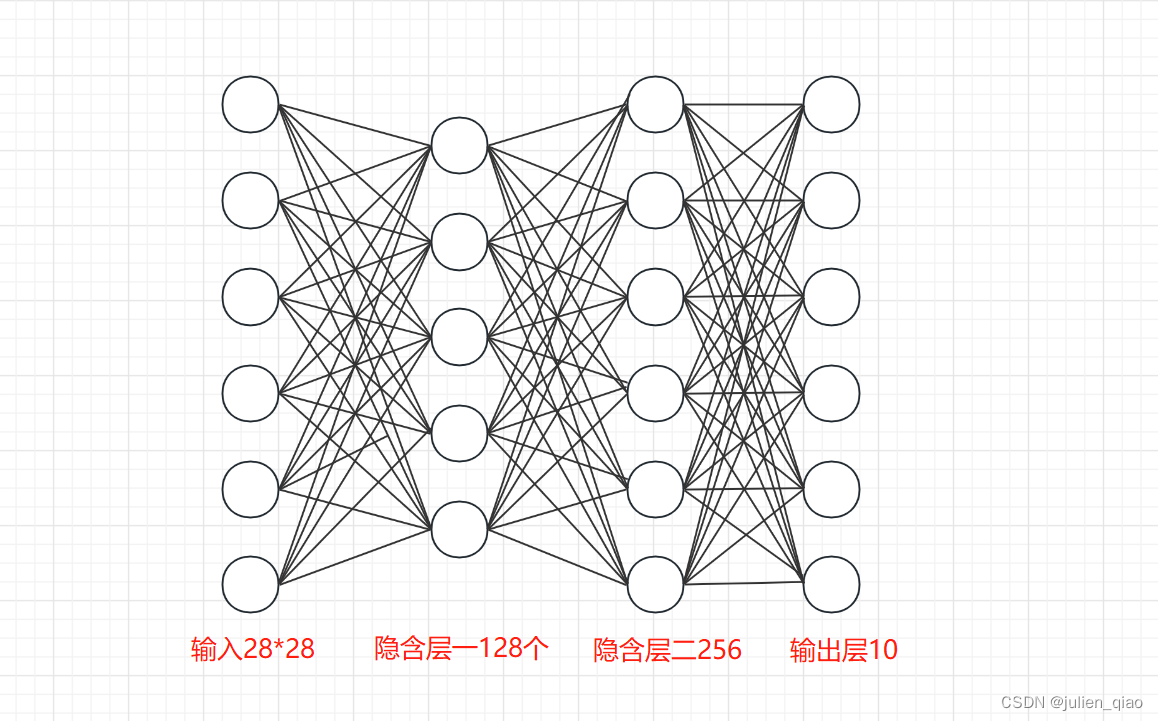
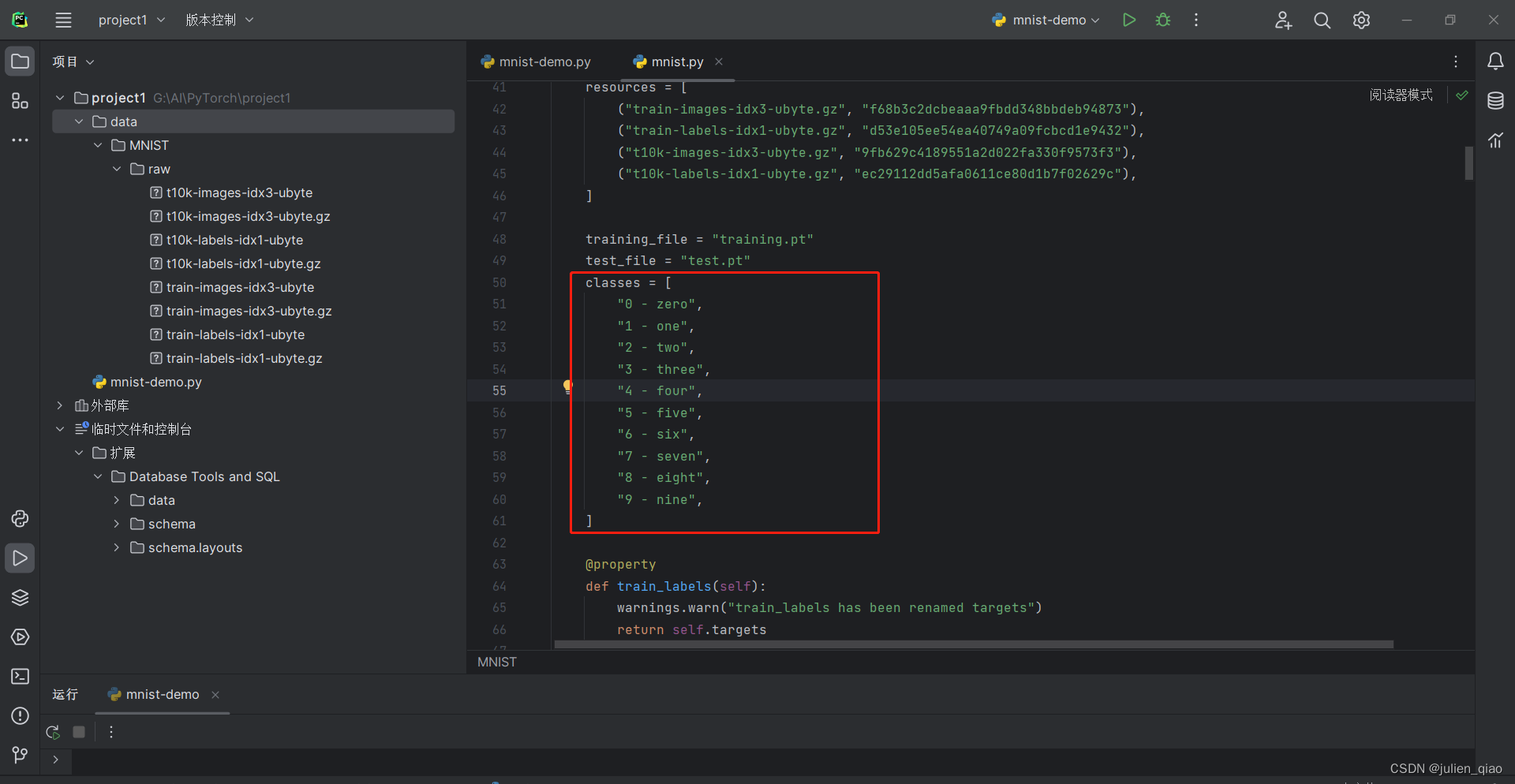
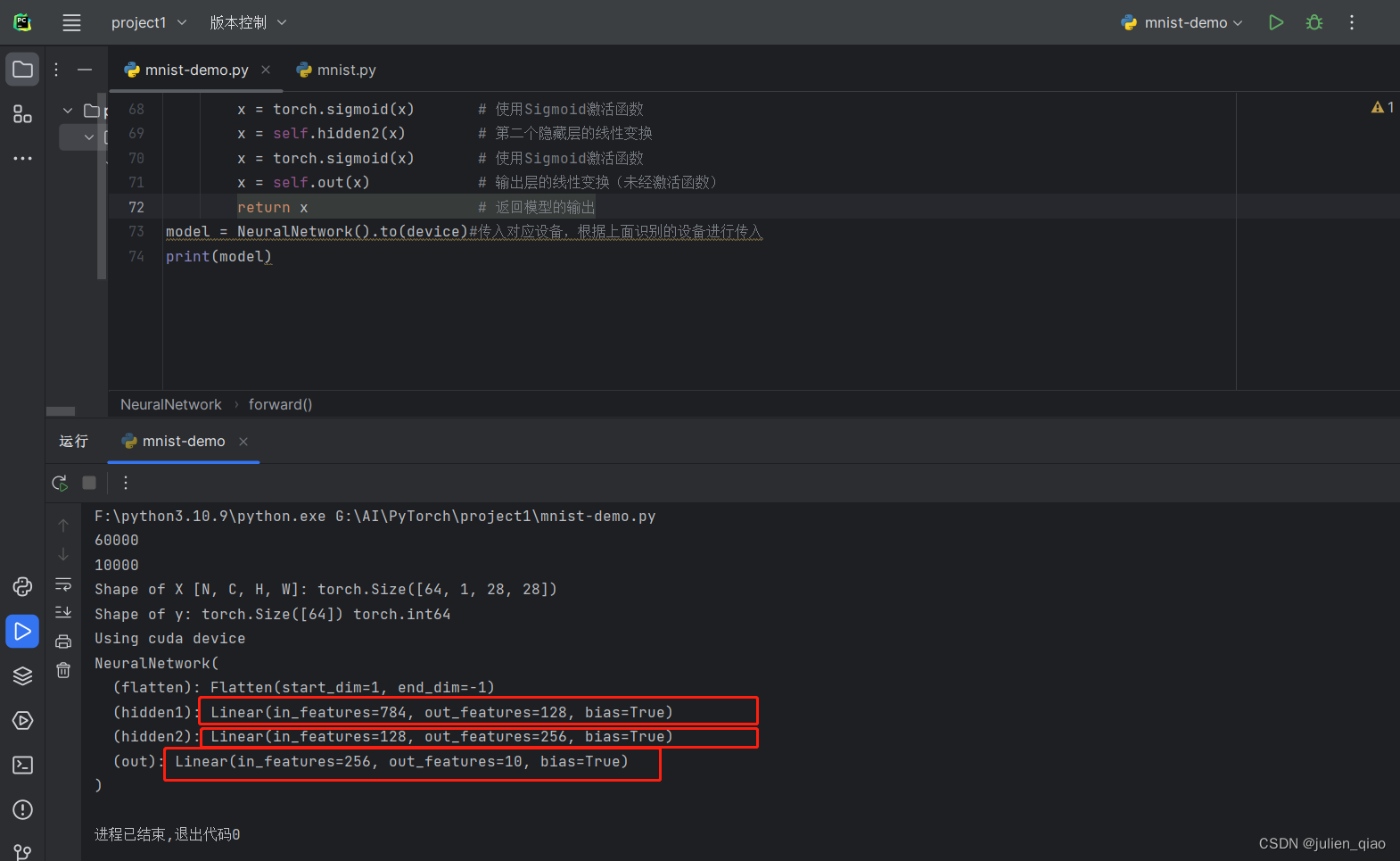
class NeuralNetwork(nn.Module):def __init__(self):super().__init__()self.flatten = nn.Flatten() # 将图像展平self.hidden1 = nn.Linear(28*28, 128) # 第一个隐藏层,输入维度为28*28,输出维度为128self.hidden2 = nn.Linear(128, 256) # 第二个隐藏层,输入维度为128,输出维度为256self.out = nn.Linear(256, 10) # 输出层,输入维度为256,输出维度为10(对应10个数字类别)def forward(self, x):x = self.flatten(x) # 将输入图像展平x = self.hidden1(x) # 第一个隐藏层的线性变换x = torch.sigmoid(x) # 使用Sigmoid激活函数x = self.hidden2(x) # 第二个隐藏层的线性变换x = torch.sigmoid(x) # 使用Sigmoid激活函数x = self.out(x) # 输出层的线性变换(未经激活函数)return x # 返回模型的输出
model = NeuralNetwork().to(device)#传入对应设备,根据上面识别的设备进行传入,这里传入GPU
print(model)
从分类中也可以看出分类:
运行代码:
五、 训练和测试
#训练数据
def train(dataloader, model, loss_fn, optimizer):model.train()
#pytorch提供2种方式来切换训练和测试的模式,分别是:model.train() 和 model.eval()。
# 一般用法是:在训练开始之前写上model.trian(),在测试时写上 model.eval() 。batch_size_num = 1for X, y in dataloader: #其中batch为每一个数据的编号X, y = X.to(device), y.to(device) #把训练数据集和标签传入cpu或GPUpred = model.forward(X) #自动初始化 w权值loss = loss_fn(pred, y) #通过交叉熵损失函数计算损失值loss# Backpropagation 进来一个batch的数据,计算一次梯度,更新一次网络optimizer.zero_grad() #梯度值清零loss.backward() #反向传播计算得到每个参数的梯度值optimizer.step() #根据梯度更新网络参数loss = loss.item() #获取损失值print(f"loss: {loss:>7f} [number:{batch_size_num}]")batch_size_num += 1
#测试数据
def test(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)model.eval() #梯度管理test_loss, correct = 0, 0with torch.no_grad(): #一个上下文管理器,关闭梯度计算。当你确认不会调用Tensor.backward()的时候。这可以减少计算所用内存消耗。for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model.forward(X)test_loss += loss_fn(pred, y).item() #correct += (pred.argmax(1) == y).type(torch.float).sum().item()a = (pred.argmax(1) == y) #dim=1表示每一行中的最大值对应的索引号,dim=0表示每一列中的最大值对应的索引号b = (pred.argmax(1) == y).type(torch.float)test_loss /= num_batches#计算正确率correct /= size#计算损失print(f"Test result: \n Accuracy: {(100*correct)}%, Avg loss: {test_loss}")
# 多分类使用交叉熵损失函数
loss_fn = nn.CrossEntropyLoss() #创建交叉熵损失函数对象,因为手写字识别中一共有10个数字,输出会有10个结果
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)#创建一个优化器,SGD为随机梯度下降算法??
#params:要训练的参数,一般我们传入的都是model.parameters()。
#lr:learning_rate学习率,也就是步长。
调用函数训练:
#训练模型
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn)
多次训练:
epochs = 5 #
for t in range(epochs):print(f"Epoch {t+1}\n-------------------------------")train(train_dataloader, model, loss_fn, optimizer)# test(test_dataloader, model, loss_fn)
print("Done!")
test(test_dataloader, model, loss_fn)
第一次运行:
成功率只有可怜的16,loss高达2.2

六、优化模型
使用Adam(自适应矩估计):
修改代码118行:
# 多分类使用交叉熵损失函数
loss_fn = nn.CrossEntropyLoss() #创建交叉熵损失函数对象,因为手写字识别中一共有10个数字,输出会有10个结果
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)#创建一个优化器
防止梯度爆炸和梯度消失使用relu函数替换:
class NeuralNetwork(nn.Module):def __init__(self):super().__init__()self.flatten = nn.Flatten() # 将图像展平self.hidden1 = nn.Linear(28*28, 128) # 第一个隐藏层,输入维度为28*28,输出维度为128self.hidden2 = nn.Linear(128, 256) # 第二个隐藏层,输入维度为128,输出维度为256self.out = nn.Linear(256, 10) # 输出层,输入维度为256,输出维度为10(对应10个数字类别)def forward(self, x):x = self.flatten(x) # 将输入图像展平x = self.hidden1(x) # 第一个隐藏层的线性变换x = torch.relu(x) # 使用Sigmoid激活函数/修改为relux = self.hidden2(x) # 第二个隐藏层的线性变换x = torch.relu(x) # 使用Sigmoid激活函数/修改为relux = self.out(x) # 输出层的线性变换(未经激活函数)return x # 返回模型的输出#传入GPU
model = NeuralNetwork().to(device)#传入对应设备,根据上面识别的设备进行传入
print(model)增加训练次数:
epochs = 15 #
for t in range(epochs):print(f"Epoch {t+1}\n-------------------------------")train(train_dataloader, model, loss_fn, optimizer)# test(test_dataloader, model, loss_fn)
print("Done!")
test(test_dataloader, model, loss_fn)
第二次优化后运行:
成功率大大提高:
Accuracy: 97.67%, Avg loss: 0.12269500801303047

七、完整代码
#MNIST--手写字识别import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor#创建一个MNIST数据集的实例,其中包括训练图像和标签
training_data = datasets.MNIST(root="data", #下载的跟目录train=True, #加载训练数据集download=True,#如果数据集不存在,将自动下载transform=ToTensor(), #将图像数据转换为Tensor格式的数据(张量)
)
print(len(training_data))#创建一个MNIST数据集的实例,其中包括训练图像和标签
test_data = datasets.MNIST(root="data", #下载的跟目录train=False, #加载测试数据集download=True,#如果数据集不存在,将自动下载transform=ToTensor(), #将图像数据转换为Tensor格式的数据(张量),pytorch使用tensor数据流所以这里要转换
)
print(len(test_data))#展示训练数据集图片和标签
from matplotlib import pyplot as plt #导入matplotlib库中的pyplot模块,用于绘制图像
figure = plt.figure() #创建一个新的图像画布
for i in range(12):#遍历前12张图片img, label = training_data[i]figure.add_subplot(3, 4, i+1)plt.title(label)plt.axis("off")plt.imshow(img.squeeze(), cmap="gray")#使用imshow函数显示图像,其中img.squeeze()将图像的通道维度去除,cmap="gray"表示使用灰度颜色映射
plt.show()#DataLoader数据加载器
train_dataloader = DataLoader(training_data, batch_size=64)#创建一个训练数据加载器,将training_data(训练数据集)分成64张图像一组的批次
test_dataloader = DataLoader(test_data, batch_size=64)#创建一个测试数据加载器,将test_data(测试数据集)分成64张图像一组的批次。
for X, y in test_dataloader:#X是表示打包好的每一个数据包#打印当前批次图像数据X的形状,其中N表示批次大小,C表示通道数,H和W表示图像的高度和宽度print(f"Shape of X [N, C, H, W]: {X.shape}")#打印当前批次标签数据y的形状和数据类型print(f"Shape of y: {y.shape} {y.dtype}")break'''
此代码段的作用是检查当前系统是否支持CUDA(GPU计算),
如果支持,则使用CUDA设备;如果不支持CUDA,它还会检查是否支持多进程模式(MPS),
如果支持,则使用MPS设备;最后,如果都不支持,则使用CPU设备。然后,它会打印出所选择的设备类型。'''device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device")class NeuralNetwork(nn.Module):def __init__(self):super().__init__()self.flatten = nn.Flatten() # 将图像展平self.hidden1 = nn.Linear(28*28, 128) # 第一个隐藏层,输入维度为28*28,输出维度为128self.hidden2 = nn.Linear(128, 256) # 第二个隐藏层,输入维度为128,输出维度为256self.out = nn.Linear(256, 10) # 输出层,输入维度为256,输出维度为10(对应10个数字类别)def forward(self, x):x = self.flatten(x) # 将输入图像展平x = self.hidden1(x) # 第一个隐藏层的线性变换x = torch.relu(x) # 使用Sigmoid激活函数/修改为relux = self.hidden2(x) # 第二个隐藏层的线性变换x = torch.relu(x) # 使用Sigmoid激活函数/修改为relux = self.out(x) # 输出层的线性变换(未经激活函数)return x # 返回模型的输出#传入GPU
model = NeuralNetwork().to(device)#传入对应设备,根据上面识别的设备进行传入
print(model)#训练数据
def train(dataloader, model, loss_fn, optimizer):model.train()
#pytorch提供2种方式来切换训练和测试的模式,分别是:model.train() 和 model.eval()。
# 一般用法是:在训练开始之前写上model.trian(),在测试时写上 model.eval() 。batch_size_num = 1for X, y in dataloader: #其中batch为每一个数据的编号X, y = X.to(device), y.to(device) #把训练数据集和标签传入cpu或GPUpred = model.forward(X) #自动初始化 w权值loss = loss_fn(pred, y) #通过交叉熵损失函数计算损失值loss# Backpropagation 进来一个batch的数据,计算一次梯度,更新一次网络optimizer.zero_grad() #梯度值清零loss.backward() #反向传播计算得到每个参数的梯度值optimizer.step() #根据梯度更新网络参数loss = loss.item() #获取损失值print(f"loss: {loss:>7f} [number:{batch_size_num}]")batch_size_num += 1
#测试数据
def test(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)model.eval() #梯度管理test_loss, correct = 0, 0with torch.no_grad(): #一个上下文管理器,关闭梯度计算。当你确认不会调用Tensor.backward()的时候。这可以减少计算所用内存消耗。for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model.forward(X)test_loss += loss_fn(pred, y).item() #correct += (pred.argmax(1) == y).type(torch.float).sum().item()a = (pred.argmax(1) == y) #dim=1表示每一行中的最大值对应的索引号,dim=0表示每一列中的最大值对应的索引号b = (pred.argmax(1) == y).type(torch.float)test_loss /= num_batches#计算正确率correct /= size#计算损失print(f"Test result: \n Accuracy: {(100*correct)}%, Avg loss: {test_loss}")# 多分类使用交叉熵损失函数
loss_fn = nn.CrossEntropyLoss() #创建交叉熵损失函数对象,因为手写字识别中一共有10个数字,输出会有10个结果
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)#创建一个优化器
#params:要训练的参数,一般我们传入的都是model.parameters()。
#lr:learning_rate学习率,也就是步长。#训练模型
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn)epochs = 15 #
for t in range(epochs):print(f"Epoch {t+1}\n-------------------------------")train(train_dataloader, model, loss_fn, optimizer)# test(test_dataloader, model, loss_fn)
print("Done!")
test(test_dataloader, model, loss_fn)
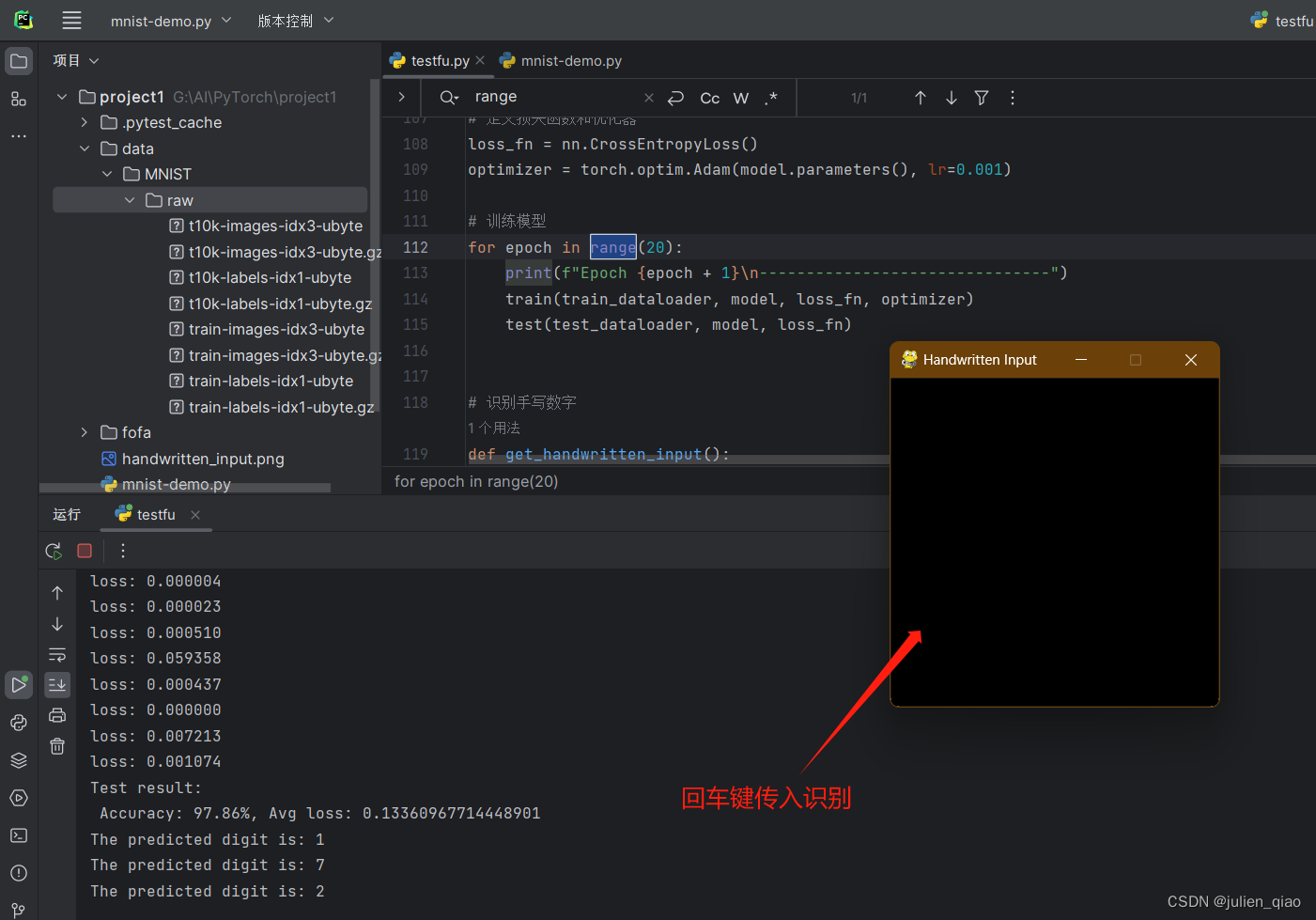
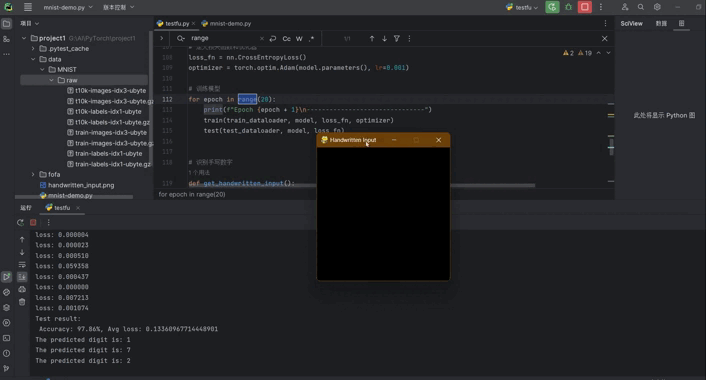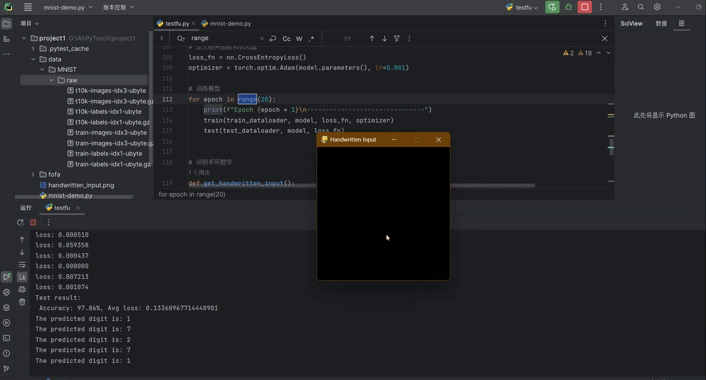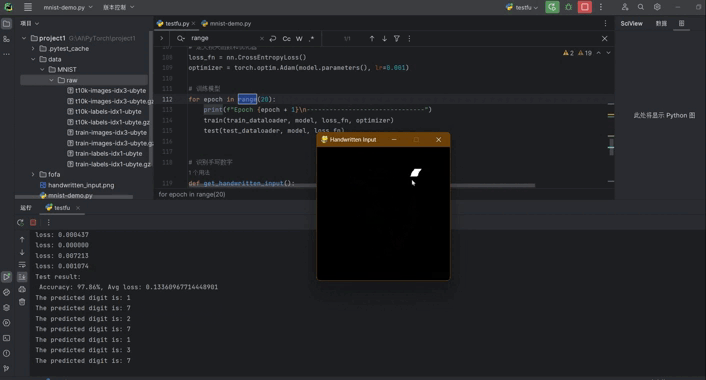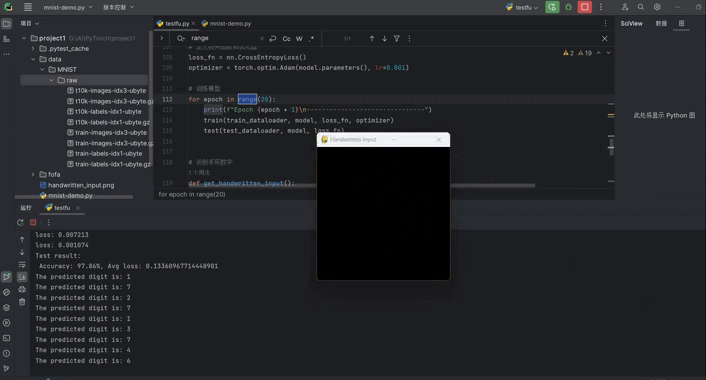
八、手写板实现输入识别功能
在原来的基础上实现,手写数字然后识别,训练完成后使用pygame做一个手写版实现手写,保存图片,然后将图片的大小修改为模型可以识别的大小,然后传入模型识别:
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
from PIL import Image
import torchvision.transforms as transforms
import pygame
import sys ;sys.setrecursionlimit(sys.getrecursionlimit() * 5)
from pygame.locals import *# 创建一个MNIST数据集的实例
training_data = datasets.MNIST(root="data",train=True,download=True,transform=ToTensor(),
)test_data = datasets.MNIST(root="data",train=False,download=True,transform=ToTensor(),
)# 创建一个神经网络模型
class NeuralNetwork(nn.Module):def __init__(self):super().__init__()self.flatten = nn.Flatten()self.hidden1 = nn.Linear(28 * 28, 128)self.hidden2 = nn.Linear(128, 256)self.out = nn.Linear(256, 10)def forward(self, x):x = self.flatten(x)x = self.hidden1(x)x = torch.relu(x)x = self.hidden2(x)x = torch.relu(x)x = self.out(x)return x# 训练模型和测试模型的函数
def train(dataloader, model, loss_fn, optimizer):model.train()for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model.forward(X)loss = loss_fn(pred, y)optimizer.zero_grad()loss.backward()optimizer.step()loss = loss.item()print(f"loss: {loss:>7f}")def test(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)model.eval()test_loss, correct = 0, 0with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model.forward(X)test_loss += loss_fn(pred, y).item()correct += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss /= num_batchescorrect /= sizeprint(f"Test result: \n Accuracy: {(100 * correct)}%, Avg loss: {test_loss}")# 定义一个函数来识别手写数字
def recognize_handwritten_digit(image_path, model):image = Image.open(image_path).convert('L')preprocess = transforms.Compose([transforms.Resize((28, 28)),transforms.ToTensor(),])input_tensor = preprocess(image)input_batch = input_tensor.unsqueeze(0)input_batch = input_batch.to(device)with torch.no_grad():output = model(input_batch)_, predicted_class = torch.max(output, 1)return predicted_class.item()# 检查是否支持CUDA,然后选择设备
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device")# 创建数据加载器
train_dataloader = DataLoader(training_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)# 创建模型并传入设备
model = NeuralNetwork().to(device)# 定义损失函数和优化器
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)# 训练模型
for epoch in range(20):#训练次数print(f"Epoch {epoch + 1}\n-------------------------------")train(train_dataloader, model, loss_fn, optimizer)test(test_dataloader, model, loss_fn)# 识别手写数字
def get_handwritten_input():pygame.init()# 设置窗口window = pygame.display.set_mode((280, 280))pygame.display.set_caption('Handwritten Input')window.fill((0, 0, 0)) # 设置背景为黑色drawing = Falselast_pos = Nonewhile True:for event in pygame.event.get():if event.type == QUIT:pygame.quit()sys.exit()elif event.type == MOUSEBUTTONDOWN:drawing = Trueelif event.type == MOUSEMOTION:if drawing:mouse_x, mouse_y = pygame.mouse.get_pos()if last_pos:pygame.draw.line(window, (255, 255, 255), last_pos, (mouse_x, mouse_y), 15) # 设置绘画颜色为白色last_pos = (mouse_x, mouse_y)elif event.type == MOUSEBUTTONUP:drawing = Falselast_pos = Nonepygame.display.update()if event.type == KEYDOWN and event.key == K_RETURN:pygame.image.save(window, 'handwritten_input.png')return 'handwritten_input.png'def main():while True: # 死循环保证程序一直运行,直到关闭image_path = get_handwritten_input()predicted_digit = recognize_handwritten_digit(image_path, model)print(f"The predicted digit is: {predicted_digit}")if __name__ == "__main__":main()