问题:现存的方法经常忽略面部的情感或者不能将它们从语音内容中分离出来。
方法:本文提出了一种端到端神经网络来分解语音中的不同情绪,从而生成丰富的 3D 面部表情。
1.我们引入了情感分离编码器(EDE),通过交叉重构具有不同情感标签的语音信号来分离语音中的情感和内容。
2.采用情感引导特征融合解码器来生成具有增强的情感的3D说话面部。
3.由于3D情感说话人脸的数据较少,我们借助面部混合形状的监督,从2D情感数据中重建出可信的3D人脸,并提供了一个大规模的3D情感说话人脸数据集(3D-ETF)来训练网络。
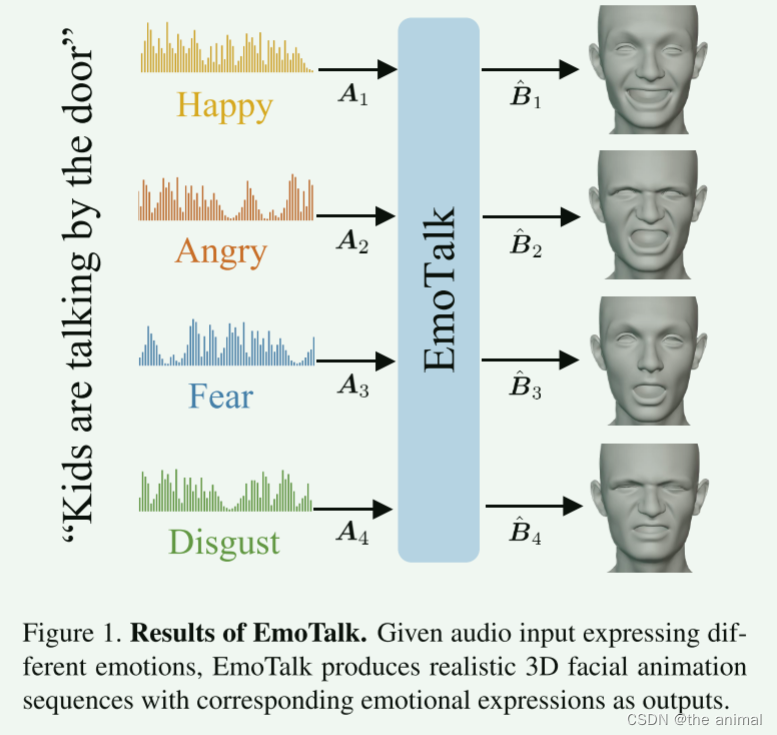
给定表达不同情绪的音频输入,EmoTalk产生具有相应情绪表达的逼真3D面部序列作为输出。
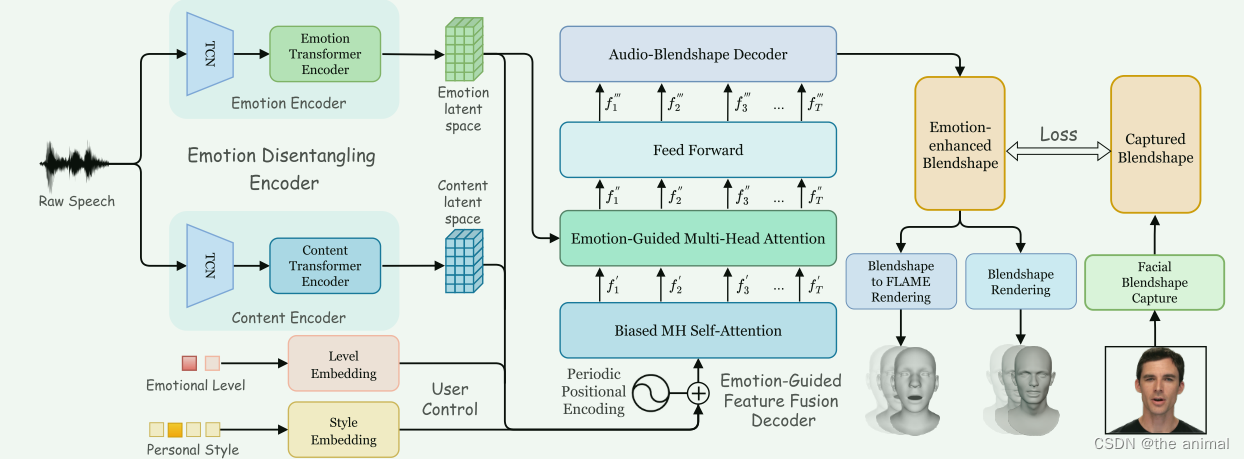
对于情感分离编码器,引入了两个不同的音频特征提取器,并分别用于为内容和情感提取两个单独的潜在空间,用于解耦情感和内容。使用交叉重建损失来约束学习过程,以更好地从语音中分离情感和内容。
方法:我们提出了一种 3D 面部动画模型,可以从语音信号中重建具有丰富情感的面部表情,使用户能够控制情绪水平和个人风格。用户可控的emotional level l ∈ R2 作为输入,允许用户调节最终面部动画中表达情绪的强度。Personal style p ∈ R24 输入也可以被用户操纵以具有不同的说话习惯。作者使用wav2vec 2.0来提取音频特征。
Aci,ej 表示样本数据,这些数据