我们使用 Spring Data JPA 的时候,一般都会用到 Spring MVC,Spring Data 对 Spring MVC 做了很好的支持,体现在以下几个方面:
- 支持在 Controller 层直接返回实体,而不使用其显式的调用方法;
- 对 MVC 层支持标准的分页和排序功能;
- 扩展的插件支持 Querydsl,可以实现一些通用的查询逻辑。
正常情况下,我们开启 Spring Data 对 Spring Web MVC 支持的时候需要在 @Configuration 的配置文件里面添加 @EnableSpringDataWebSupport 这一注解,如下面这种形式:
复制代码
@Configuration
@EnableWebMvc
//开启支持Spring Data Web的支持
@EnableSpringDataWebSupport
public class WebConfiguration { }
由于我们用了 Spring Boot,其有自动加载机制,会自动加载 SpringDataWebAutoConfiguration 类,发生如下变化:
复制代码
@EnableSpringDataWebSupport
@ConditionalOnWebApplication(type = Type.SERVLET)
@ConditionalOnClass({ PageableHandlerMethodArgumentResolver.class, WebMvcConfigurer.class })
@ConditionalOnMissingBean(PageableHandlerMethodArgumentResolver.class)
@EnableConfigurationProperties(SpringDataWebProperties.class)
@AutoConfigureAfter(RepositoryRestMvcAutoConfiguration.class)
public class SpringDataWebAutoConfiguration {
从类上面可以看出来,@EnableSpringDataWebSupport 会自动开启,所以当我们用 Spring Boot + JPA + MVC 的时候,什么都不需要做,因为 Spring Boot 利用 Spring Data 对 Spring MVC 做了很多 Web 开发的天然支持。支持的组件有 DomainConverter、Page、Sort、Databinding、Dynamic Param 等。
那么我们先来看一下它对 DomainClassConverter 组件的支持。
DomainClassConverter 组件
这个组件的主要作用是帮我们把 Path 中 ID 的变量,或 Request 参数中的变量 ID 的参数值,直接转化成实体对象注册到 Controller 方法的参数里面。怎么理解呢?我们看个例子,就很好懂了。
一个例子
首先,写一个 MVC 的 Controller,分别从 Path 和 Param 变量里面,根据 ID 转化成实体,代码如下:
复制代码
@RestController
public class UserInfoController {/*** 从path变量里面获得参数ID的值,然后直接转化成UserInfo实体* @param userInfo* @return*/@GetMapping("/user/{id}")public UserInfo getUserInfoFromPath(@PathVariable("id") UserInfo userInfo) {return userInfo;}/*** 将request的param中的ID变量值,转化成UserInfo实体* @param userInfo* @return*/@GetMapping("/user")public UserInfo getUserInfoFromRequestParam(@RequestParam("id") UserInfo userInfo) {return userInfo;}
}
然后,我们运行起来,看一下结果:
复制代码
GET http://127.0.0.1:8089/user/1
HTTP/1.1 200
Content-Type: application/json
{"id": 1,"version": 0,"ages": 10,"telephone": "123456789"
}
GET http://127.0.0.1:8089/user?id=1
{"id": 1,"version": 0,"ages": 10,"telephone": "123456789"
}
从结果来看,Controller 里面的 getUserInfoFromRequestParam 方法会自动根据 ID 查询实体对象 UserInfo,然后注入方法的参数里面。那它是怎么实现的呢?我们看一下源码。
源码分析
我们打开 DomainClassConverter 类,里面有个 ToEntityConverter 的内部转化类的 Matches 方法,它会判断参数的类型是不是实体,并且有没有对应的实体 Repositorie 存在。如果不存在,就会直接报错说找不到合适的参数转化器。
DomainClassConverter 里面的关键代码如下:
复制代码
public class DomainClassConverter<T extends ConversionService & ConverterRegistry>implements ConditionalGenericConverter, ApplicationContextAware {@Overridepublic boolean matches(TypeDescriptor sourceType, TypeDescriptor targetType) {//判断参数的类型是不是实体if (sourceType.isAssignableTo(targetType)) {return false;}Class<?> domainType = targetType.getType();//有没有对应的实体的Repositorie 存在if (!repositories.hasRepositoryFor(domainType)) {return false;}Optional<RepositoryInformation> repositoryInformation = repositories.getRepositoryInformationFor(domainType);return repositoryInformation.map(it -> {Class<?> rawIdType = it.getIdType();return sourceType.equals(TypeDescriptor.valueOf(rawIdType))|| conversionService.canConvert(sourceType.getType(), rawIdType);}).orElseThrow(() -> new IllegalStateException(String.format("Couldn't find RepositoryInformation for %s!", domainType)));}
}
......}
所以,我们上面的例子其实是需要有 UserInfoRepository 的,否则会失败。通过源码我们也可以看到,如果 matches=true,那么就会执行下面的 convert 方法,最终调用 findById 的方法帮我们执行查询动作,如下图所示:
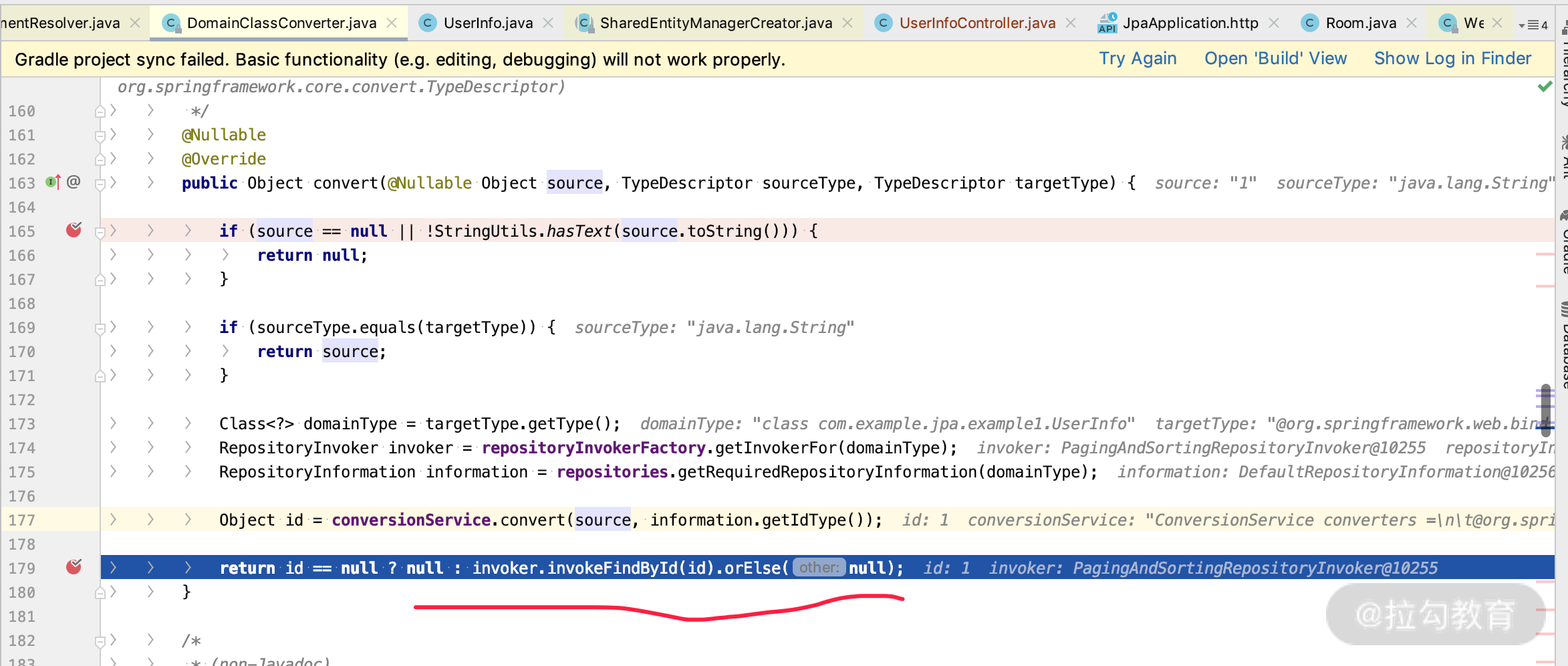
而 DomainClassConverter 是 Spring MVC 自定义 Formatter 的一直种机制,加载进去,可以看到如下界面:
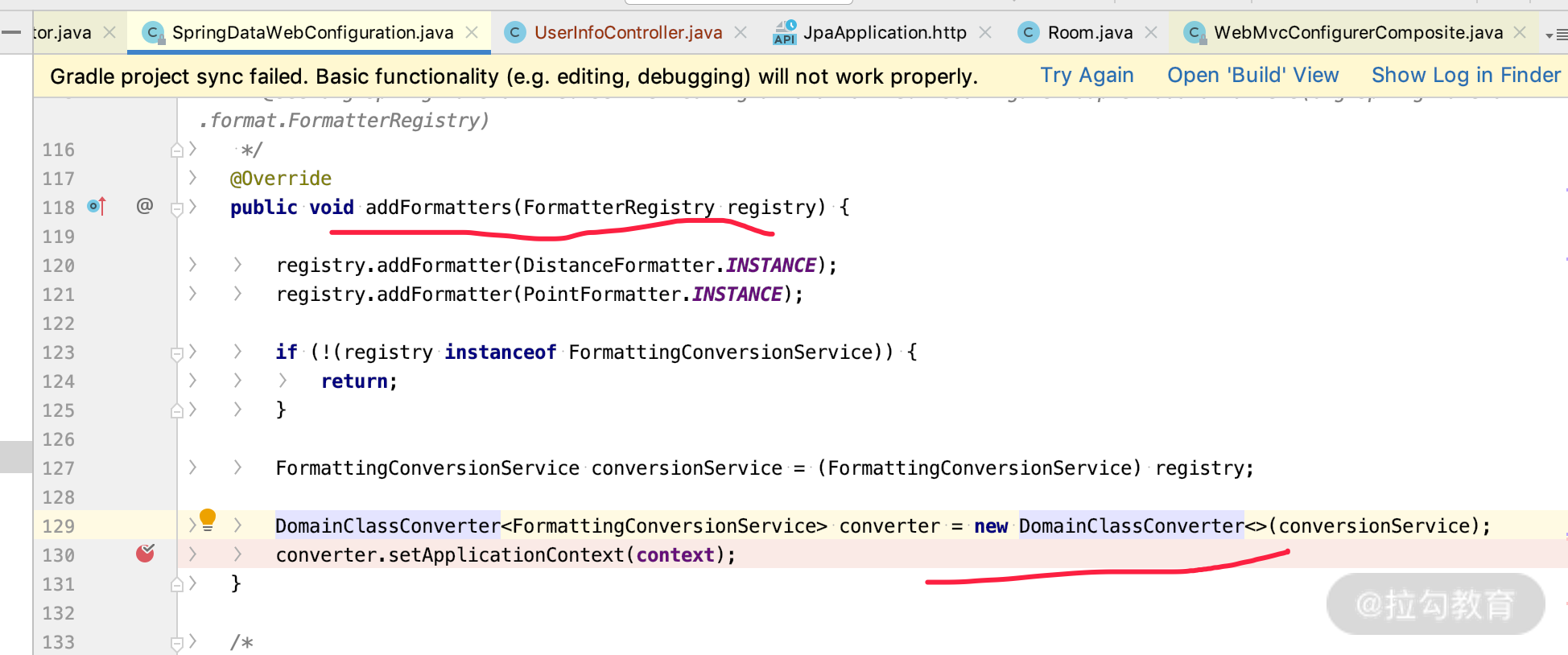
而 SpringDataWebConfiguration 是因为实现了 WebMvcConfigurer 的 addFormatters 所有加载了自定义参数转化器的功能,所以才有了 DomainClassConverter 组件的支持。关键代码如下:
复制代码
@Configuration
public class SpringDataWebConfiguration implements WebMvcConfigurer, BeanClassLoaderAware {
......}
从源码上我们也可以看到,DomainClassConverter 只会根据 ID 来查询实体,很有局限性,没有更加灵活的参数转化功能,不过你也可以根据源码自己进行扩展,我在这就不展示更多了。
下面来看一下JPA 对 Web MVC 分页和排序是如何支持的。
Page 和 Sort 的参数支持
我们还是先通过一个例子来说明。
一个实例
这是一个通过分页和排序参数查询 UserInfo 的实例。
首先,我们新建一个 UserInfoController,里面添加如下两个方法,分别测试分页和排序。
复制代码
@GetMapping("/users")
public Page<UserInfo> queryByPage(Pageable pageable, UserInfo userInfo) {return userInfoRepository.findAll(Example.of(userInfo),pageable);
}
@GetMapping("/users/sort")
public HttpEntity<List<UserInfo>> queryBySort(Sort sort) {return new HttpEntity<>(userInfoRepository.findAll(sort));
}
其中,queryByPage 方法中,两个参数可以分别接收分页参数和查询条件,我们请求一下,看看效果:
复制代码
GET http://127.0.0.1:8089/users?size=2&page=0&ages=10&sort=id,desc
参数里面可以支持分页大小为 2、页码 0、排序(按照 ID 倒序)、参数 ages=10 的所有结果,如下所示:
复制代码
{"content": [{"id": 4,"version": 0,"ages": 10,"telephone": "123456789"},{"id": 3,"version": 0,"ages": 10,"telephone": "123456789"}],"pageable": {"sort": {"sorted": true,"unsorted": false,"empty": false},"offset": 0,"pageNumber": 0,"pageSize": 2,"unpaged": false,"paged": true},"totalPages": 2,"totalElements": 4,"last": false,"size": 2,"number": 0,"numberOfElements": 2,"sort": {"sorted": true,"unsorted": false,"empty": false},"first": true,"empty": false
}
上面的字段我就不一一介绍了,在第 4 课时(如何利用 Repository 中的方法返回值解决实际问题)我们已经讲过了,只不过现在应用到了 MVC 的 View 层。
因此,我们可以得出结论:Pageable 既支持分页参数,也支持排序参数。并且从下面这行代码可以看出其也可以单独调用 Sort 参数。
复制代码
GET http://127.0.0.1:8089/users/sort?ages=10&sort=id,desc
那么它的实现原理是什么呢?
原理分析
和 DomainClassConverter 组件的支持是一样的,由于 SpringDataWebConfiguration 实现了 WebMvcConfigurer 接口,通过 addArgumentResolvers 方法,扩展了 Controller 方法的参数 HandlerMethodArgumentResolver
的解决者,从下面图片中你就可以看出来。
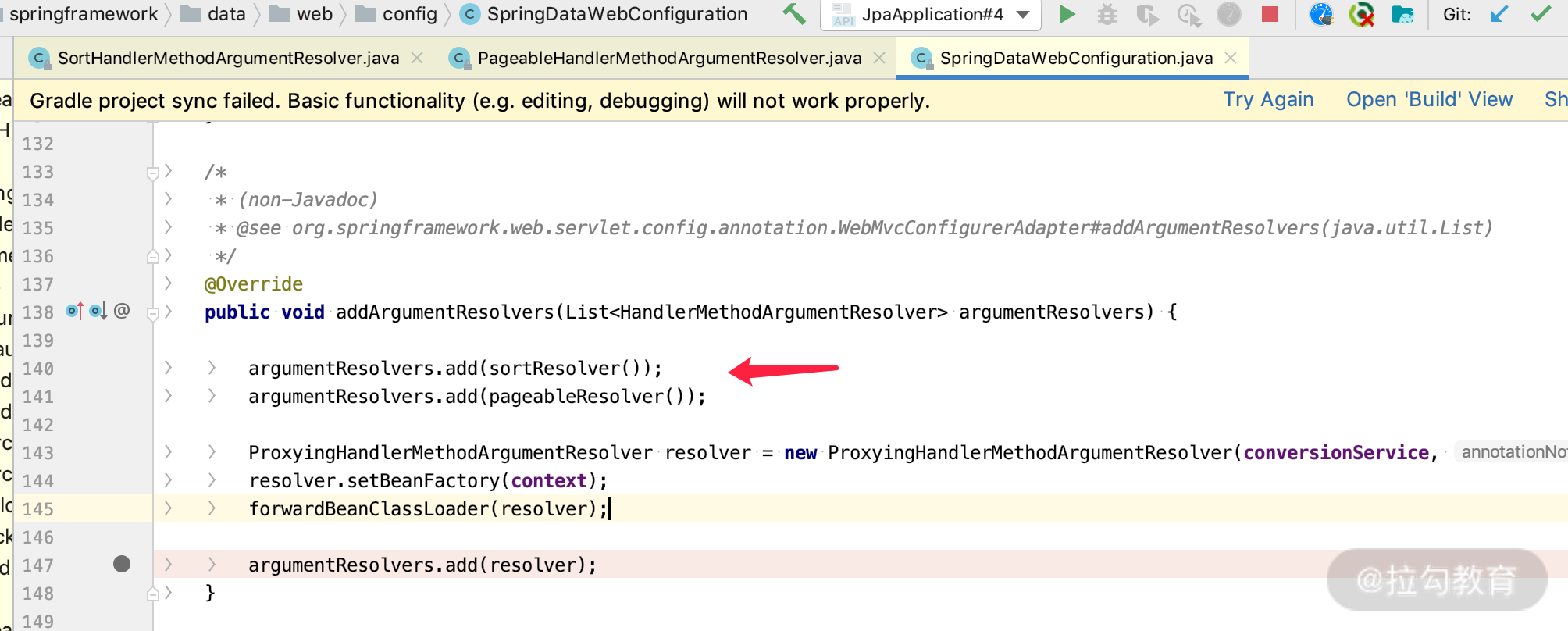
我们通过箭头的地方分析一下 SortHandlerMethodArgumentResolver 的类,会看到如下界面:
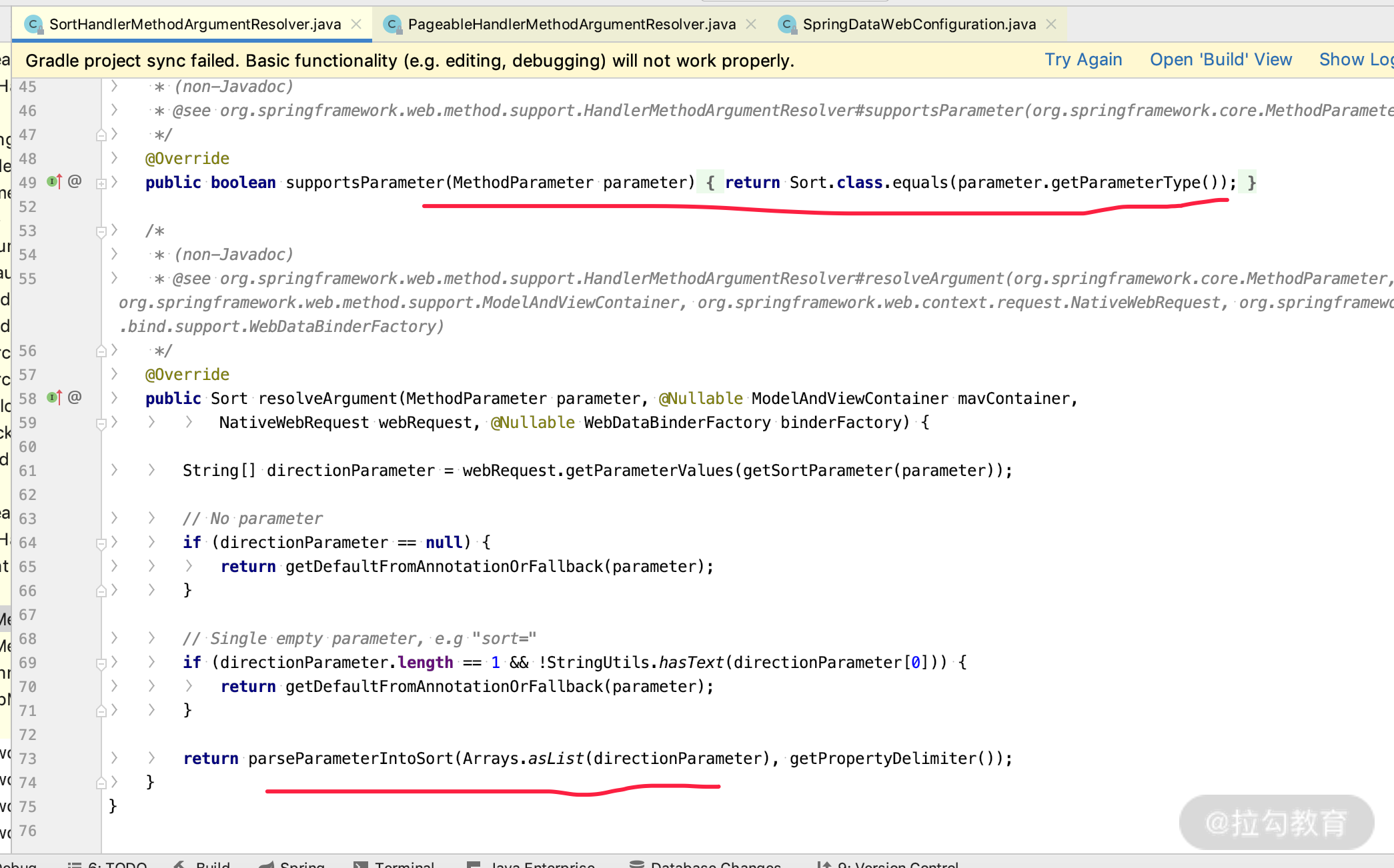
这个类里面最关键的就是下面两个方法:
- supportsParameter,表示只处理类型为 Sort.class 的参数;
- resolveArgument,可以把请求里面参数的值,转换成该方法里面的参数 Sort 对象。
这里还要提到的是另外一个类:PageHandlerMethodArgumentResolver 类。
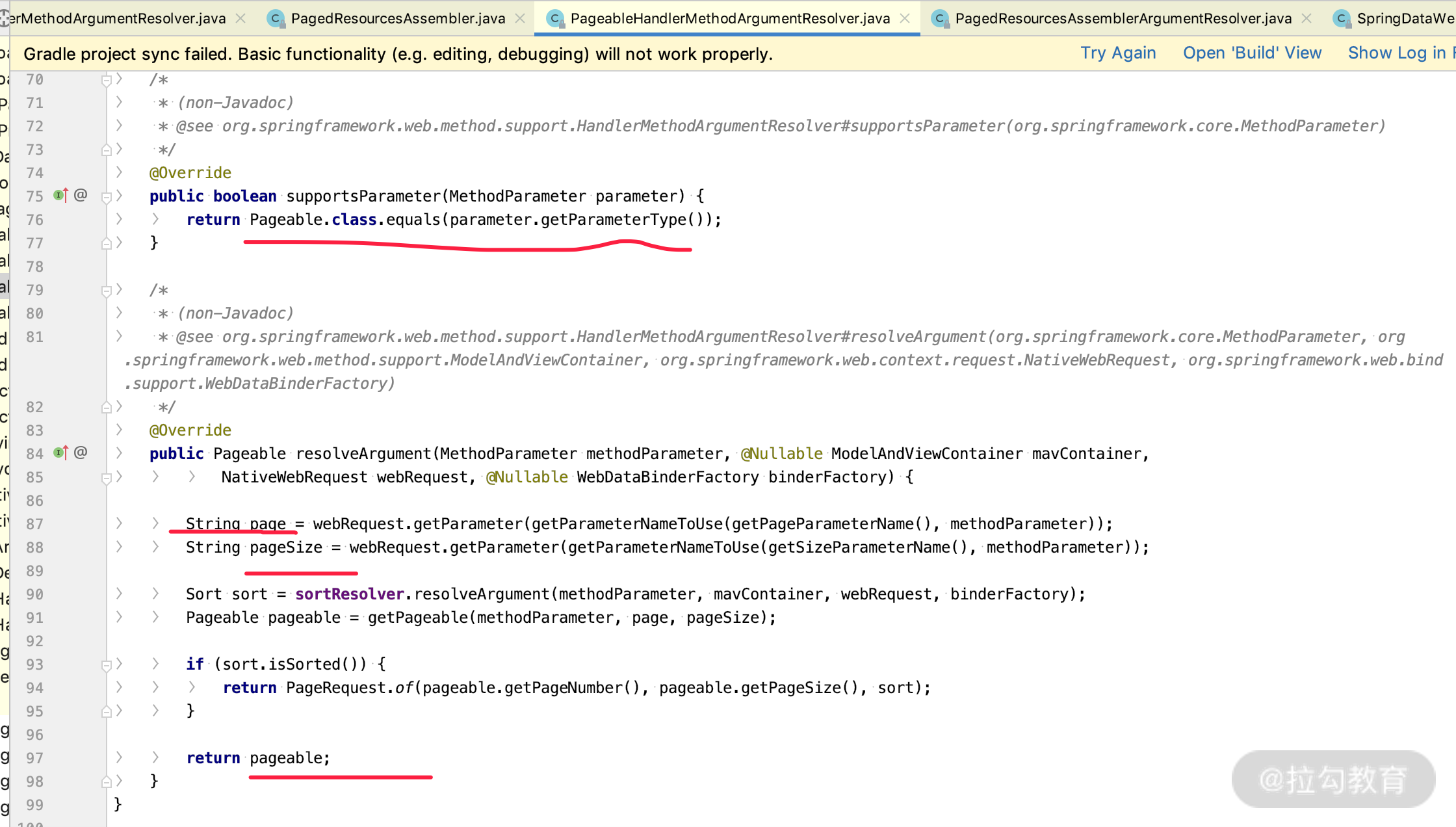
这个类里面也有两个最关键的方法:
- supportsParameter,表示我只处理类型是 Pageable.class 的参数;
- resolveArgument,把请求里面参数的值,转换成该方法里面的参数 Pageable 的实现类 PageRequest。
关于 Web 请求的分页和排序的支持就介绍到这里,那么如果返回的是一个 Projection 的接口,Spring 是怎么处理的呢?我们接着看。
Web Databinding Support
之前我们在 08 课时,讲 Projection 的时候提到过接口,Spring Data JPA 里面,也可以通过 @ProjectedPayload 和 @JsonPath 对接口进行注解支持,不过要注意这与前面所讲的 Jackson 注解的区别在于,此时我们讲的是接口。
一个实例
这里我依然结合一个实例来对这个接口进行讲解,请看下面的步骤。
第一步:如果要支持 Projection,必须要在 gradle 里面引入 jsonpath 依赖才可以:
复制代码
implementation 'com.jayway.jsonpath:json-path'
第二步:新建一个 UserInfoInterface 接口类,用来接收接口传递的 json 对象。
复制代码
package com.example.jpa.example1;
import org.springframework.data.web.JsonPath;
import org.springframework.data.web.ProjectedPayload;
@ProjectedPayload
public interface UserInfoInterface {@JsonPath("$.ages") // 第一级参数/JSON里面找ages字段
// @JsonPath("$..ages") $..代表任意层级找ages字段Integer getAges();@JsonPath("$.telephone") //第一级找参数/JSON里面的telephone字段
// @JsonPath({ "$.telephone", "$.user.telephone" }) //第一级或者user下面的telephone都可以String getTelephone();
}
第三步:在 Controller 里面新建一个 post 方法,通过接口获得 RequestBody 参数对象里面的值。
复制代码
@PostMapping("/users/projected")
public UserInfoInterface saveUserInfo(@RequestBody UserInfoInterface userInfoInterface) {return userInfoInterface;
}
第四步:我们发送一个 get 请求,代码如下:
复制代码
POST /users HTTP/1.1
{"ages":10,"telephone":"123456789"}
此时可以正常得到如下结果:
复制代码
{"ages": 10,"telephone": "123456789"
}
这个响应结果说明了接口可以正常映射。现在你知道用法了,我们再通过源码分析一下其原理。
原理分析
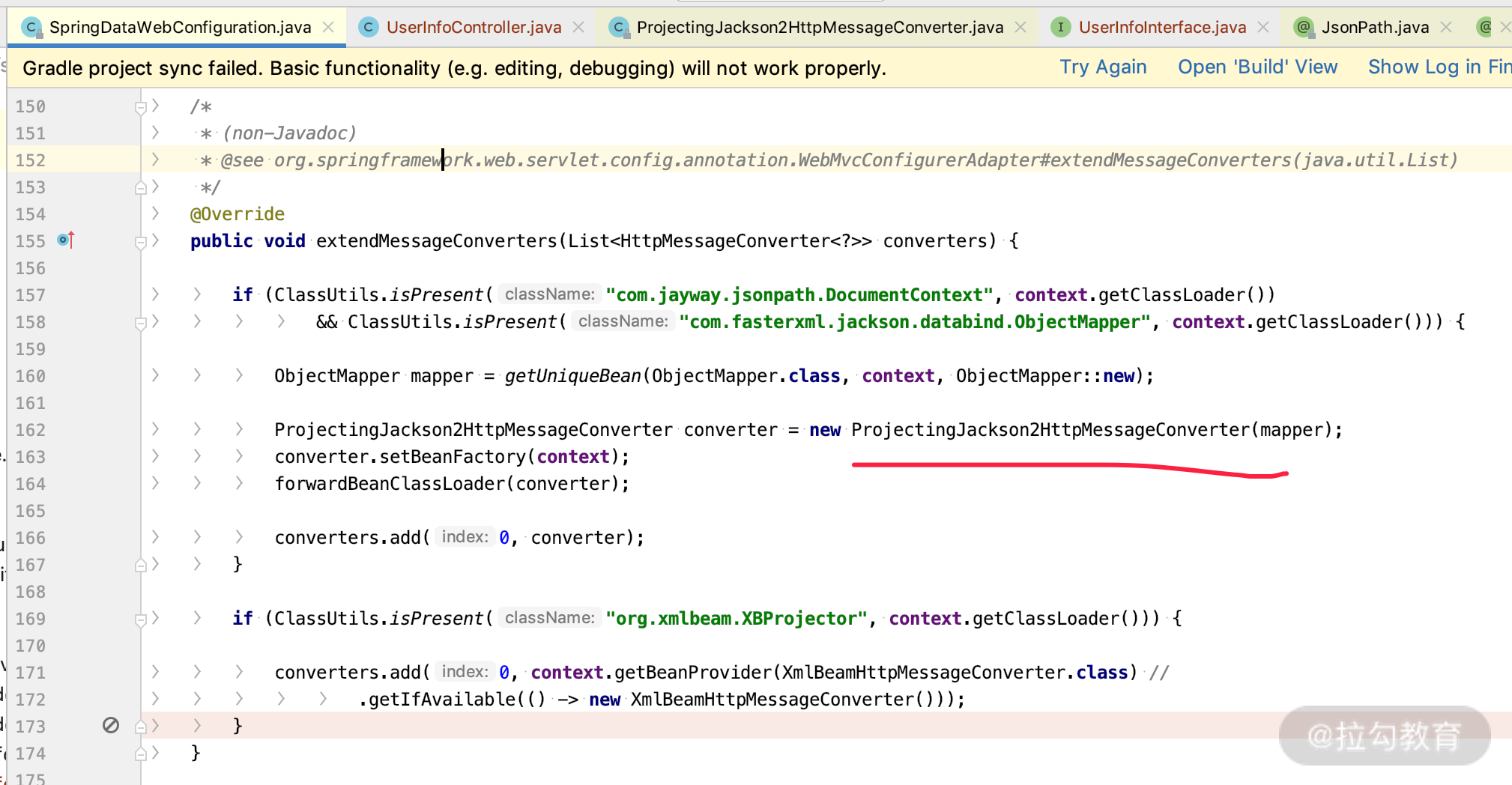
很简单,我们还是直接看 SpringDataWebConfiguration,其中实现的 WebMvcConfigurer 接口里面有个 extendMessageConverters 方法,方法中加了一个 ProjectingJackson2HttpMessageConverter 的类,这个类会把带 ProjectedPayload.class 注解的接口进行 Converter。
我们看一下其中主要的两个方法:
1.加载 ProjectingJackson2HttpMessageConverter,用来做 Projecting 的接口转化。我们通过源码看一下是在哪里被加载进去的,如下:
2.而 ProjectingJackson2HttpMessageConverter 主要是继承了 MappingJackson2HttpMessageConverter,并且实现了 HttpMessageConverter 的接口里面的两个重要方法,如下图所示:
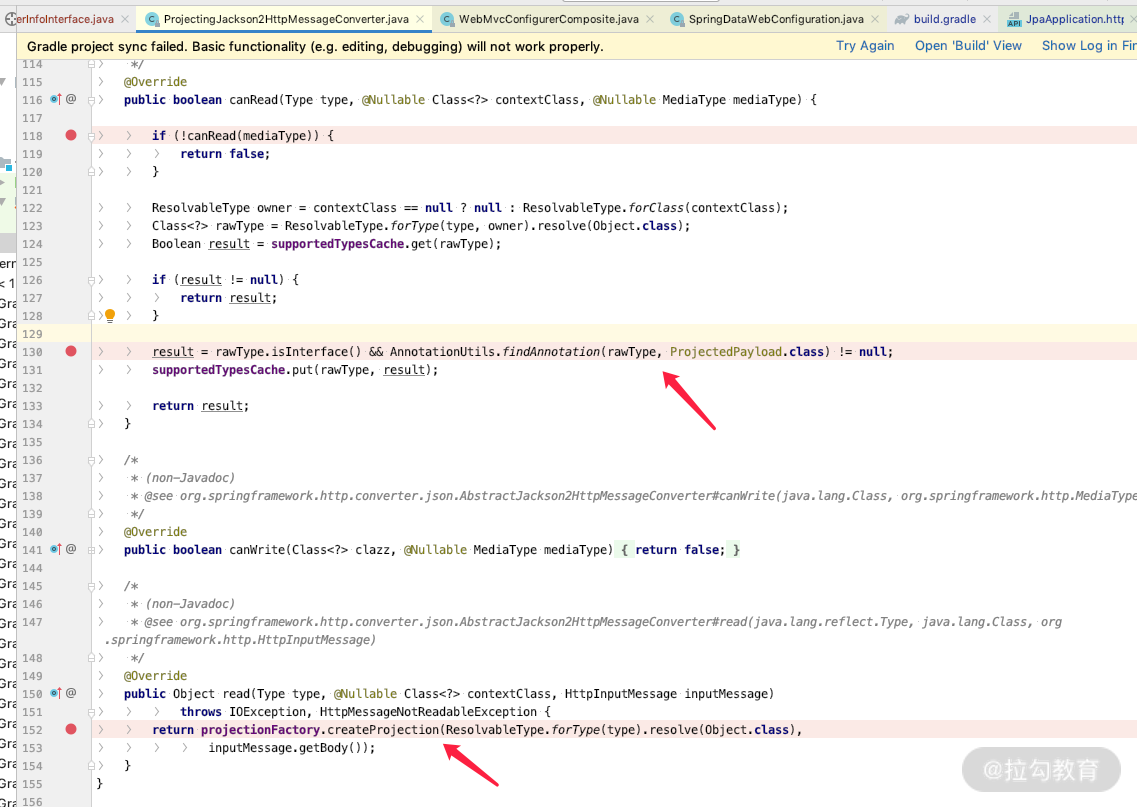
其中,
- canRead 通过判断参数的实体类型里面是否有接口,以及是否有 ProjectedPayload.class 注解后,才进行解析;
- read 方法负责把 HttpInputMessage 转化成 Projected 的映射代理对象。
现在你知道了 Spring 里面是如何通过 HttpMessageConverter 对 Projected 进行的支持,在使用过程中,希望你针对实际情况多去 Debug。不过这个不常用,你知道一下就可以了。
下面介绍一个通过 QueryDSL 对 Web 请求进行动态参数查询的方法。
QueryDSL Web Support
实际工作中,经常有人会用 Querydsl 做一些复杂查询,方便生成 Rest 的 API 接口,那么这种方法有什么好处,又会暴露什么缺点呢?我们先看一个实例。
一个实例
这是一个通过 QueryDSL 作为请求参数的使用案例,通过它你就可以体验一下 QueryDSL 的用法和使用场景,我们一步一步来看一下。
第一步:需要 grandle 引入 querydsl 的依赖。
复制代码
implementation 'com.querydsl:querydsl-apt'
implementation 'com.querydsl:querydsl-jpa'
annotationProcessor("com.querydsl:querydsl-apt:4.3.1:jpa","org.hibernate.javax.persistence:hibernate-jpa-2.1-api:1.0.2.Final","javax.annotation:javax.annotation-api:1.3.2","org.projectlombok:lombok")
annotationProcessor("org.springframework.boot:spring-boot-starter-data-jpa")
annotationProcessor 'org.projectlombok:lombok'
第二步:UserInfoRepository 继承 QuerydslPredicateExecutor 接口,就可以实现 QueryDSL 的查询方法了,代码如下:
复制代码
public interface UserInfoRepository extends JpaRepository<UserInfo, Long>, QuerydslPredicateExecutor<UserInfo> {}
第三步:Controller 里面直接利用 @QuerydslPredicate 注解接收 Predicate predicate 参数。
复制代码
@GetMapping(value = "user/dsl")
Page<UserInfo> queryByDsl(@QuerydslPredicate(root = UserInfo.class) com.querydsl.core.types.Predicate predicate, Pageable pageable) {
//这里面我用的userInfoRepository里面的QuerydslPredicateExecutor里面的方法return userInfoRepository.findAll(predicate, pageable);
}
第四步:直接请求我们的 user / dsl 即可,这里利用 queryDsl 的语法 ,使 &ages=10 作为我们的请求参数。
复制代码
GET http://127.0.0.1:8089/user/dsl?size=2&page=0&ages=10&sort=id%2Cdesc&ages=10
Content-Type: application/json
{"content": [{"id": 2,"version": 0,"ages": 10,"telephone": "123456789"},{"id": 1,"version": 0,"ages": 10,"telephone": "123456789"}],"pageable": {"sort": {"sorted": true,"unsorted": false,"empty": false},"offset": 0,"pageNumber": 0,"pageSize": 2,"unpaged": false,"paged": true},"totalPages": 1,"totalElements": 2,"last": true,"size": 2,"number": 0,"sort": {"sorted": true,"unsorted": false,"empty": false},"numberOfElements": 2,"first": true,"empty": false
}
Response code: 200; Time: 721ms; Content length: 425 bytes
现在我们可以得出结论:QuerysDSL 可以帮我们省去创建 Predicate 的过程,简化了操作流程。但是它依然存在一些局限性,比如多了一些模糊查询、范围查询、大小查询,它对这些方面的支持不是特别友好。可能未来会更新、优化,不过在这里你只要关注一下就可以了。
此外,你还要注意这里讲解的 QuerysDSL 的参数处理方式与第 10 课时“JpaSpecificationExecutor 实战应用场景”讲的参数处理方式的区别,你可以自己感受一下,看看哪个使用起来更加方便。
原理分析
QueryDSL 也是主要利用自定义 Spring MVC 的 HandlerMethodArgumentResolver 实现类,根据请求的参数字段,转化成 Controller 里面所需要的参数,请看一下源码。
复制代码
public class QuerydslPredicateArgumentResolver implements HandlerMethodArgumentResolver {
....
public Object resolveArgument(MethodParameter parameter, @Nullable ModelAndViewContainer mavContainer,NativeWebRequest webRequest, @Nullable WebDataBinderFactory binderFactory) throws Exception {.....//你有兴趣的话可以在下图关键节点打个断点看看效果,我就不多说了
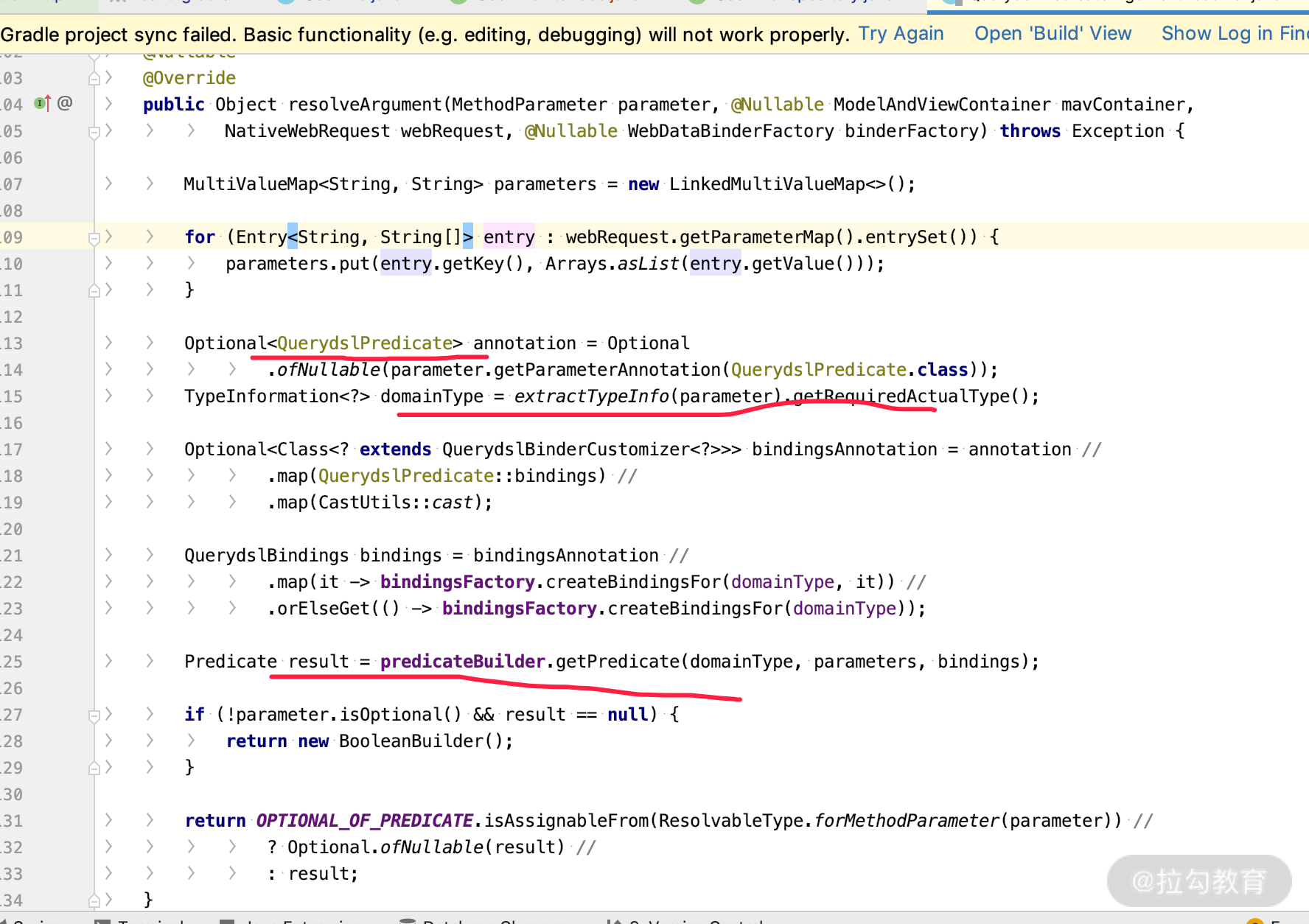
在实际开发中,关于 insert 和 update 的接口我们是“逃不掉”的,但不是每次的字段都会全部传递过来,那这个时候我们应该怎么做呢?这就涉及了上述实例里面的两个注解 @DynamicUpdate 和 @DynamicInsert,下面来详细介绍一下。
@DynamicUpdate & @DynamicInsert 详解
通过语法快速了解
@DynamicInsert:这个注解表示 insert 的时候,会动态生产 insert SQL 语句,其生成 SQL 的规则是:只有非空的字段才能生成 SQL。代码如下:
复制代码
@Target( TYPE )
@Retention( RUNTIME )
public @interface DynamicInsert {//默认是true,如果设置成false,就表示空的字段也会生成sql语句;boolean value() default true;
}
这个注解主要是用在 @Entity 的实体中,如果加上这个注解,就表示生成的 insert SQL 的 Columns 只包含非空的字段;如果实体中不加这个注解,默认的情况是空的,字段也会作为 insert 语句里面的 Columns。
@DynamicUpdate:和 insert 是一个意思,只不过这个注解指的是在 update 的时候,会动态产生 update SQL 语句,生成 SQL 的规则是:只有非空的字段才会生成到 update SQL 的 Columns 里面。请看代码:
复制代码
@Target( TYPE )
@Retention( RUNTIME )
public @interface DynamicUpdate {//和insert里面一个意思,默认true,如果设置成false和不添加这个注解的效果一样boolean value() default true;
}
和上一个注解的原理类似,这个注解也是用在 @Entity 的实体中,如果加上这个注解,就表示生成的 update SQL 的 Columns 只包含改变的字段;如果不加这个注解,默认的情况是所有的字段也会作为 update 语句里面的 Columns。
这样做的目的是提高 sql 的执行效率,默认更新所有字段,这样会导致一些到索引的字段也会更新,这样 sql 的执行效率就比较低了。需要注意的是:这种生效的前提是 select-before-update 的触发机制。
这是什么意思呢?我们看个案例感受一下。
案例
第一步:为了方便测试,我们修改一下 User 实体:加上 @DynamicInsert 和 @DynamicUpdate 注解。
复制代码
@DynamicInsert
@DynamicUpdate
public class User extends BaseEntity {private String name;private String email;@Enumerated(EnumType.STRING)private SexEnum sex;private Integer age;
......}//其他不变的信息省略
第二步:UserInfo 实体还保持不变,即没有加上 @DynamicInsert 和 @DynamicUpdate 注解。
复制代码
@Entity
@Data
@AllArgsConstructor
@NoArgsConstructor
public class UserInfo extends BaseEntity {@Id@GeneratedValue(strategy= GenerationType.AUTO)private Long id;private Integer ages;private String telephone;
}
第三步:我们在 UserController 里面添加如下方法,用来测试新增和更新 User。
复制代码
@PostMapping("/user")
public User saveUser(@RequestBody User user) {return userRepository.save(user);
}
第四步:在 UserInfoController 里面添加如下方法,用来测试新增和更新 UserInfo。
复制代码
@PostMapping("/user/info")
public UserInfo saveUserInfo(@RequestBody UserInfo userInfo) {return userInfoRepository.save(userInfo);
}
第五步:测试一下 UserController的post 的 user 情况,看一下 insert 的情况。
复制代码
#### 通过post测试insert
POST /user HTTP/1.1
Host: 127.0.0.1:8089
Content-Type: application/json
Cache-Control: no-cache
Postman-Token: 56d8dc02-7f3e-7b95-7ff1-572a4bb7d102
{"age":10,"name":"jack"}
这时,我们发送一个 post 请求,只带 ages 和 name 字段,而并没有带上 User 实体里面的其他字段,看一下生成的 sql 是什么样的。
复制代码
Hibernate: insert into user (create_time, last_modified_time, version, age, name, id) values (?, ?, ?, ?, ?, ?)
这时你会发现,除了 BaseEntity 里面的一些基础字段,而其他字段并没有生成到 insert 语句里面。
第六步:我们再测试一下 user 的 update 情况。
复制代码
#### 还是发生post请求,带上ID和version执行update操作
POST /user HTTP/1.1
Host: 127.0.0.1:8089
Content-Type: application/json
Cache-Control: no-cache
Postman-Token: 56d8dc02-7f3e-7b95-7ff1-572a4bb7d102{name":"jack1","id":1,"version":0}
此时你会看到,update 和 insert 的区别有两点:
- 去掉了 age 字段,修改了 name 字段的值;
- 当 Entity 里面有 version 字段的时候,我们再带上 version 和 id 就会显示为 update。
再看一下调用完之后的 sql:用一条 select 查询一下实体是否存在,代码如下:
复制代码
Hibernate: select user0_.id as id1_1_0_, user0_.create_time as create_t2_1_0_, user0_.create_user_id as create_u3_1_0_, user0_.last_modified_time as last_mod4_1_0_, user0_.last_modified_user_id as last_mod5_1_0_, user0_.version as version6_1_0_, user0_.age as age7_1_0_, user0_.deleted as deleted8_1_0_, user0_.email as email9_1_0_, user0_.name as name10_1_0_, user0_.sex as sex11_1_0_ from user user0_ where user0_.id=?
其中一条 update 动态更新了我们传递的那些值,只更新有变化的字段,而包括了 null 的字段也更新了,如 age 字段中我们传递的是 null,所以 update 的 sql 打印如下:
复制代码
Hibernate: update user set last_modified_time=?, version=?, name=?,age=? where id=? and version=?
第七步:那么我们再看一下 UserInfo 的 insert 方法。
复制代码
#### insert
POST /user/info HTTP/1.1
Host: 127.0.0.1:8089
Content-Type: application/json
Cache-Control: no-cache
Postman-Token: 56d8dc02-7f3e-7b95-7ff1-572a4bb7d102
{"ages":10}
发送一个 post 的 insert 操作,我们看一下 sql:
复制代码
Hibernate: insert into user_info (create_time, create_user_id, last_modified_time, last_modified_user_id, version, ages, telephone, id) values (?, ?, ?, ?, ?, ?, ?, ?)
你会发现,无论你有没有传递值,每个字段都做了 insert,没有传递的话会用 null 代替。
第八步:我们再看一下 UserInfo 的 update 方法。
复制代码
#### update
POST /user/info HTTP/1.1
Host: 127.0.0.1:8089
Content-Type: application/json
Cache-Control: no-cache
Postman-Token: 56d8dc02-7f3e-7b95-7ff1-572a4bb7d102
{"ages":10,"id":1,"version":0}
还是发送一个 post 的 update 操作,原理一样,也是带上 ID 和 version 即可。我们看一下 SQL:
复制代码
Hibernate: update user_info set create_time=?, create_user_id=?, last_modified_time=?, last_modified_user_id=?, version=?, ages=?, telephone=? where id=? and version=?
通过 update 的 SQL 可以看出,即使我们传递了 ages 的值,虽然没有变化,它也会把我们所有字段进行更新,包括未传递的 telephone 会更新成 null。
通过上面的两个例子你应该能弄清楚 @DynamicInsert 和 @DynamicUpdate 注解是做什么的了,我们在写 API 的时候就要考虑一下是否需要对 null 的字段进行操作,因为 JPA 是不知道字段为 null 的时候,是想更新还是不想更新,所以默认 JPA 会比较实例对象里面的所有包括 null 的字段,发现有变化也会更新。
而当我们做 API 开发的时候,有些场景是不期望更新未传递的字段的,例如如果我们没有传递某些字段而不期望 server 更新,那么我们该怎么做呢?
只更新非 Null 的字段
第一步:新增一个 PropertyUtils 工具类,用来复制字段的属性值,代码如下:
复制代码
package com.example.jpa.example1.util;import com.google.common.collect.Sets;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.BeanWrapper;
import org.springframework.beans.BeanWrapperImpl;import java.util.Set;public class PropertyUtils {/*** 只copy非null字段** @param source* @param dest*/public static void copyNotNullProperty(Object source, Object dest) {//利用spring提供的工具类忽略为null的字段BeanUtils.copyProperties(source, dest, getNullPropertyNames(source));}/*** get property name that value is null** @param source* @return*/private static String[] getNullPropertyNames(Object source) {final BeanWrapper src = new BeanWrapperImpl(source);java.beans.PropertyDescriptor[] pds = src.getPropertyDescriptors();Set<String> emptyNames = Sets.newHashSet();for (java.beans.PropertyDescriptor pd : pds) {Object srcValue = src.getPropertyValue(pd.getName());if (srcValue == null) {emptyNames.add(pd.getName());}}String[] result = new String[emptyNames.size()];return emptyNames.toArray(result);}
}
第二步:我们的 User 实体保持不变,类里面还加上 @DynamicUpdate 注解,新增一个 Controller 方法,代码如下:
复制代码
/*** @param user* @return*/
@PostMapping("/user/notnull")
public User saveUserNotNullProperties(@RequestBody User user) {//数据库里面取出最新的数据,当然了这一步严谨一点可以根据id和version来取数据,如果没取到可以报乐观锁异常User userSrc = userRepository.findById(user.getId()).get();//将不是null的字段copy到userSrc里面,我们只更新传递了不是null的字段PropertyUtils.copyNotNullProperty(user,userSrc);return userRepository.save(userSrc);
}
第三步:调用 API,触发更新操作:
复制代码
POST http://127.0.0.1:8089/user HTTP/1.1
Host: 127.0.0.1:8089
Content-Type: application/json
Cache-Control: no-cache
Postman-Token: 56d8dc02-7f3e-7b95-7ff1-572a4bb7d102{"name": "jack1","version": 1,"id":"1"
}
发送一个更新请求,和上面的更新请求一样,还是 age 不传递,值传递改变了的 name 属性,我们再看一下 sql 的变化,代码如下:
复制代码
update user set last_modified_time=?, version=?, name=? where id=? and version=?
你会发现,这个时候未传递的 age 字段就不会更新了。实际工作中你也可以将 Controller 里面的逻辑放到 BaseService 里面,提供一个公共的 updateOnlyNotNull 的方法,以便和默认的 save 方法作区分。
我们既然做了 MVC,一定也免不了要对系统进行监控,那么怎么看监控指标呢?
Spring Data 对系统监控做了哪些支持?
对数据层面的系统进行监控,这里我主要为你介绍两个方法。
方法一:/actuator/health 的支持,里面会检查 DB 的状态。
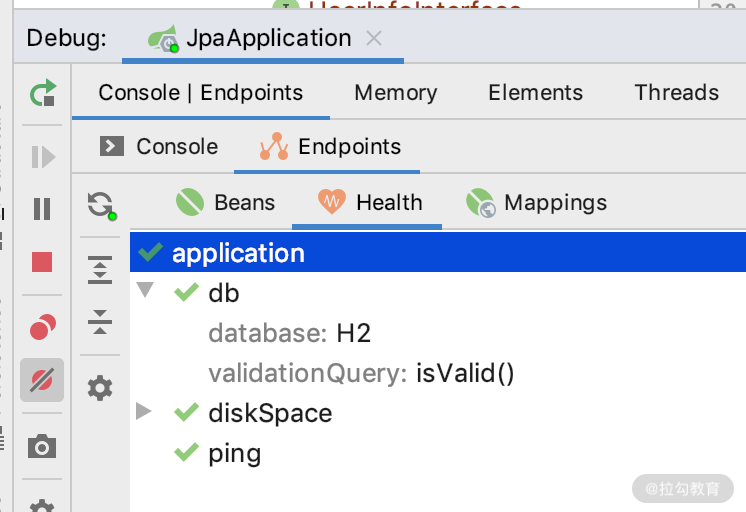
方法二:/actuator/prometheus 里面会包含一些 Hibernate 和 Datasource 的 metric。
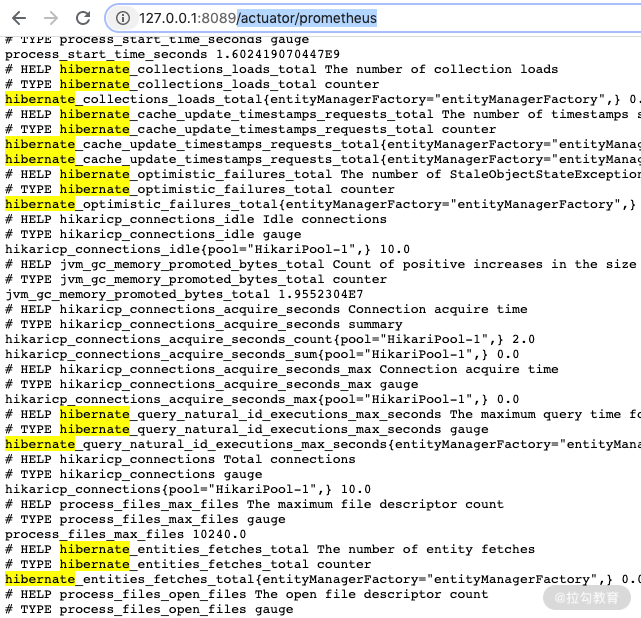
这个方法在我们做 granfan 图表的时候会很有用,不过需要注意的是:
1.开启 prometheus 需要 gradle 额外引入下面这个包:
复制代码
implementation 'io.micrometer:micrometer-registry-prometheus'
2.开启 Hibernate 的 statistics 需要配置如下操作:
复制代码
spring.jpa.properties.hibernate.generate_statistics=true
management.endpoint.prometheus.enabled=true
management.metrics.export.prometheus.enabled=true