假设大语言模型需要 10 秒钟才能生成一条结果,即需要存储的单条新记忆。那么我们获得 10 万条记忆的时间周期将为:100000 x 10 秒 = 1000000 秒——约等于 11.57 天。而即使我们用最简单的暴力算法(Numpy 的点查询),整个过程也只需要几秒钟时间,完全不值得进行优化!也就是说,我们就连近似最近邻搜索都不需要,更不用说向量数据库了。

那么我们应该如何为自己的项目选型?吴英骏老师认为,对于任何大模型应用,是否需要选用矢量数据库,完全取决于该应用对于矢量存储与查询的依赖程度。
“对于需要存储大量矢量的场景,如海量图像检索、音视频检索等,很显然使用矢量数据库可以获得更加强大、专业的功能,而对于数据量并没有那么大的场景来说,还不如使用 Numpy 等 Python 库计算来的高效、便捷。实际上,在矢量数据库这个赛道上,也分为轻量级矢量数据库以及重量级矢量数据库等,到底是选择 PostgreSQL 上的 pgvector 插件还是选择一个专用的分布式矢量数据库,也是需要对于特定应用做出具体分析之后再做出决策。”
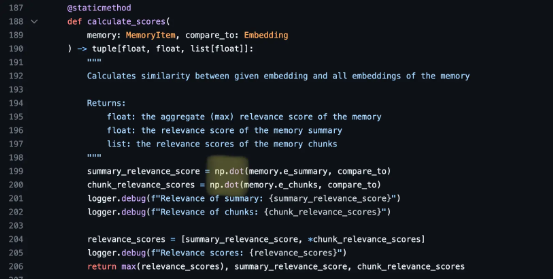
这个说法也符合如今 AutoGPT 项目的真实选择,使用 np.dot 进行嵌入比较:
And