二叉树和平衡二叉树
二叉树,每个节点支持两个分支的树结构,相比于单向链表,多了一个分支。 二叉查找树,在二叉树的基础上增加了一个规则,左子树的所有节点的值都小于它的根 节点,右子树的所有子节点都大于它的根节点。
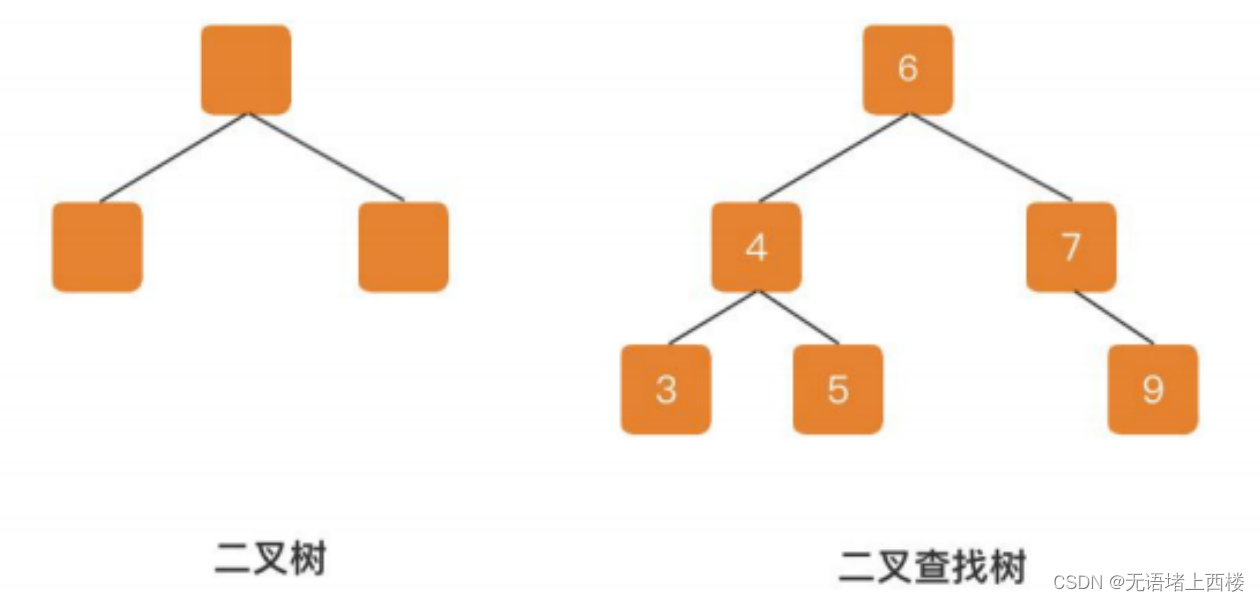
二叉查找树会出现斜树问题,导致时间复杂度增加,因此又引入了一种平衡二叉树,它具有二叉查找树的所有特点,同时增加了一个规则:”它的左右两个子树的高度差的绝对值不超过 1“。平衡二叉树会采用左旋、右旋的方式来实现平衡。

b树和b+树
而 B 树是一种多路平衡查找树,它满足平衡二叉树的规则,但是它可以有多个子树,子树的数量取决于关键字的数量,比如这个图中根节点有两个关键字 3 和 5,那么它能够拥有的子路数量=关键字数+1。因此从这个特征来看,在存储同样数据量的情况下,平衡二叉树的高度要大于 B 树。
 B+树,其实是在 B 树的基础上做的增强,最大的区别有两个:
B+树,其实是在 B 树的基础上做的增强,最大的区别有两个:
- B 树的数据存储在每个节点上,而 B+树中的数据是存储在叶子节点,并且通过链表的方式把叶子节点中的数据进行连接。
- B+树的子路数量等于关键字数
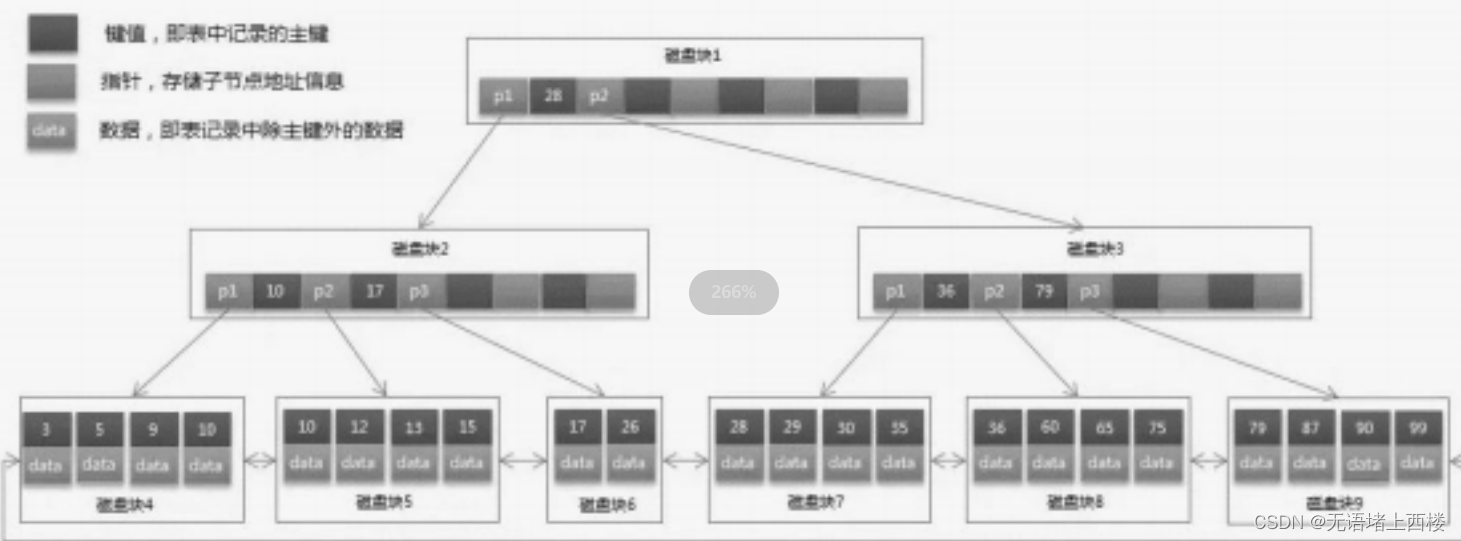
这个是 B 树的存储结构,从 B 树上可以看到每个节点会存储数据。
 这个是 B+树,B+树的所有数据是存储在叶子节点,并且叶子节点的数据是用双向链表关联的。
这个是 B+树,B+树的所有数据是存储在叶子节点,并且叶子节点的数据是用双向链表关联的。
磁盘IO
B 树和 B+树,一般都是应用在文件系统和数据库系统中,用来减少磁盘 IO 带来的性能损耗。 以 Mysql 中的 InnoDB 为例,当我们通过 select 语句去查询一条数据时,InnoDB 需要从磁盘上去读取数据,这个过程会涉及到磁盘 IO 以及磁盘的随机 IO, 我们知道磁盘 IO 的性能是特别低的,特别是随机磁盘 IO。 因为,磁盘 IO 的工作原理是,首先系统会把数据逻辑地址传给磁盘,磁盘控制电路按 照寻址逻辑把逻辑地址翻译成物理地址,也就是确定要读取的数据在哪个磁道,哪个扇区。 为了读取这个扇区的数据,需要把磁头放在这个扇区的上面,为了实现这一个点,磁盘 会不断旋转,把目标扇区旋转到磁头下面,使得磁头找到对应的磁道,这里涉及到寻道 事件以及旋转时间。
 很明显,磁盘 IO 这个过程的性能开销是非常大的,特别是查询的数据量比较多的情况下。所以在 InnoDB 中,干脆对存储在磁盘块上的数据建立一个索引,然后把索引数据以及索引列对应的磁盘地址,以 B+树的方式来存储。如图所示,当我们需要查询目标数据的时候,根据索引从 B+树中查找目标数据即可,由于 B+树分路较多,所以只需要较少次数的磁盘 IO 就能查找到。
很明显,磁盘 IO 这个过程的性能开销是非常大的,特别是查询的数据量比较多的情况下。所以在 InnoDB 中,干脆对存储在磁盘块上的数据建立一个索引,然后把索引数据以及索引列对应的磁盘地址,以 B+树的方式来存储。如图所示,当我们需要查询目标数据的时候,根据索引从 B+树中查找目标数据即可,由于 B+树分路较多,所以只需要较少次数的磁盘 IO 就能查找到。
总结
为什么用 B 树或者 B+树来做索引结构:
原因是 AVL 树的高度要比 B 树的高度要高,而高度就意味着磁盘 IO 的数量。所以为了减少磁盘 IO 的次数,文件系统或者数据库才会采用 B 树或者 B+树