问题
- redis 怎么解决的hash冲突问题 ?
- redis 对于扩容rehash有什么优秀的设计?
hash
目标是解决hash冲突,那什么是hash冲突呢?
实际上,一个最简单的 Hash 表就是一个数组,数组里的每个元素是一个哈希桶(也叫做 Bucket),第一个数组元素被编为哈希桶 0,以此类推。当一个键值对的键经过 Hash 函数计算后,再对数组元素个数取模,就能得到该键值对对应的数组元素位置,也就是第几个哈希桶。下面画几个图来说明下:

上图所示,写入16个键,那么对应的桶只有8个(想一下如果一个桶只能保存一个元素,那么势必会存在数据覆盖),如果写入的key值过多,我们的hash表要怎么处理呢? 事先声明一个很大的hash表嘛,这种肯定是不现实的,不说大小怎么确定,资源也会存在浪费。
那么回过来,我们看下hash冲突,key1 和 key9 都被映射到了 Hash 表的桶 1 中,这样,当桶 5 只能保存一个 key 时,key1 和 key3 就会有一个 key 无法保存到哈希表中了。

看下redis怎么解决hash冲突:总体来说一个是链式hash和渐进式rehash。
链式哈希如何设计与实现?
所谓的链式哈希,就是用一个链表把映射到 Hash 表同一桶中的键给连接起来。下面我们就来看看 Redis 是如何实现链式哈希的,以及为何链式哈希能够帮助解决哈希冲突。
在 dict.h 文件中,Hash 表被定义为一个二维数组(dictEntry **table),这个数组的每个元素是一个指向哈希项(dictEntry)的指针。下面的代码展示的就是在 dict.h 文件中对 Hash 表的定义,你可以看下:
typedef struct dictht {dictEntry **table; //二维数组unsigned long size; //Hash表大小unsigned long sizemask;unsigned long used;
} dictht;再看dictEntry,一定是会一个当前自己的指针,一个next指针
typedef struct dictEntry {void *key;union {void *val;uint64_t u64;int64_t s64;double d;} v;struct dictEntry *next;
} dictEntry;下面还是拿key1 和 key9 来举例,还是相同的映射流程,采用链式hash的方式画个图就都清楚了

可以看出,当我们查询key9的时候,会先hash(key9)/8 的结果确定桶的位置,再根据链表中的next指针遍历要得到的结果。
想一下,这样会有什么不足?(链表过长的时候,查询复杂度上升)
rehash
hash表的缺点是链表过长,查询效果会下降,那么就要想办法让它的链表存储变短一些。在Redis 中准备了两个哈希表,用于 rehash 时交替保存数据。如图定义:
typedef struct dict {...dictht ht[2]; //两个Hash表,交替使用,用于rehash操作long rehashidx; //Hash表是否在进行rehash的标识,-1表示没有进行rehash...
} dict;- 其次,在正常服务请求阶段,所有的键值对写入哈希表 ht[0]。
- 接着,当进行 rehash 时,键值对被迁移到哈希表 ht[1]中。
- 最后,当迁移完成后,ht[0]的空间会被释放,并把 ht[1]的地址赋值给 ht[0],ht[1]的表大小设置为 0。这样一来,又回到了正常服务请求的阶段,ht[0]接收和服务请求,ht[1]作为下一次 rehash 时的迁移表。
 到这里应该了解怎么进行rehash,保证我们使用的空间足够了,那么有两个问题: 什么时候触发 rehash? rehash 扩容扩多大? rehash 如何执行?
到这里应该了解怎么进行rehash,保证我们使用的空间足够了,那么有两个问题: 什么时候触发 rehash? rehash 扩容扩多大? rehash 如何执行?
什么时候触发 rehash?
判断是否触发的函数:dictExpandIfNeeded,在里面找一下触发条件
变量值是在 dictEnableResize 和 dictDisableResize作用分别是启用和禁止哈希表执行 rehash 功能
//如果Hash表为空,将Hash表扩为初始大小
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);//如果Hash表承载的元素个数超过其当前大小,并且可以进行扩容,或者Hash表承载的元素个数已是当前大小的5倍
if (d->ht[0].used >= d->ht[0].size &&(dict_can_resize ||d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{return dictExpand(d, d->ht[0].used*2);
}实际上,_dictExpandIfNeeded 函数中定义了三个扩容条件。
- 条件一:ht[0]的大小为 0。
- 条件二:ht[0]承载的元素个数已经超过了 ht[0]的大小,同时 Hash 表可以进行扩容。
- 条件三:ht[0]承载的元素个数,是 ht[0]的大小的 dict_force_resize_ratio 倍,其中,dict_force_resize_ratio 的默认值是 5。
剩下的就是看下这个dictExpandIfNeeded方法是谁在使用了 ,dictAdd:用来往 Hash 表中添加一个键值对。 dictRelace:用来往 Hash 表中添加一个键值对,或者键值对存在时,修改键值对。 dictAddorFind:直接调用 dictAddRaw。
rehash 扩容扩多大?
int dictExpand(dict *d, unsigned long size);// 当前表的已用空间大小为 size,那么就将表扩容到 size2 的大小。
dictExpand(d, d->ht[0].used*2);
在 Redis 中,rehash 对 Hash 表空间的扩容是通过调用 dictExpand 函数 来完成的。dictExpand 函数的参数有两个,一个是要扩容的 Hash 表,另一个是要扩到的容量
在 dictExpand 函数中,具体执行是由 _dictNextPower 函数完成的,以下代码显示的 Hash 表扩容的操作,就是从 Hash 表的初始大小(DICT_HT_INITIAL_SIZE),不停地乘以 2,直到达到目标大小。
static unsigned long _dictNextPower(unsigned long size)
{//哈希表的初始大小unsigned long i = DICT_HT_INITIAL_SIZE;//如果要扩容的大小已经超过最大值,则返回最大值加1if (size >= LONG_MAX) return LONG_MAX + 1LU;//扩容大小没有超过最大值while(1) {//如果扩容大小大于等于最大值,就返回截至当前扩到的大小if (i >= size)return i;//每一步扩容都在现有大小基础上乘以2i *= 2;}
}为什么要实现渐进式 rehash?
Hash 表在执行 rehash 时,由于 Hash 表空间扩大,原本映射到某一位置的键可能会被映射到一个新的位置上,因此,很多键就需要从原来的位置拷贝到新的位置。而在键拷贝时,由于 Redis 主线程无法执行其他请求,所以键拷贝会阻塞主线程,这样就会产生 rehash 开销。Redis为了降低这方面的开销,采用了渐进式 rehash 的方法。
简单的说,就是分批来迁移桶内数据,并不会一次性把当前 Hash 表中的所有键,都拷贝到新位置,而是会分批拷贝,每次的键拷贝只拷贝 Hash 表中一个 bucket 中的哈希项。
dictRehash 的主要执行流程:
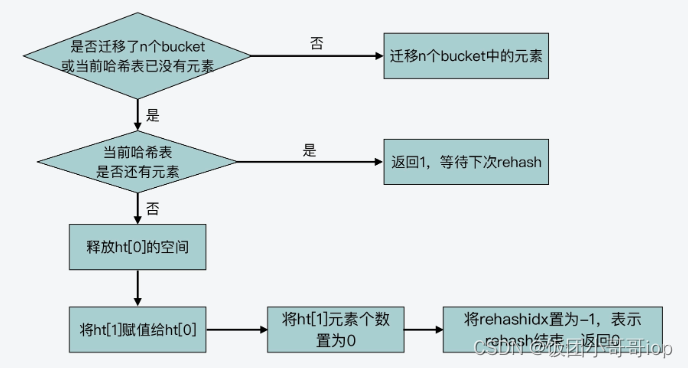
整理了dictRehash函数的逻辑的核心执行流程:
int dictRehash(dict *d, int n) {int empty_visits = n*10;...//主循环,根据要拷贝的bucket数量n,循环n次后停止或ht[0]中的数据迁移完停止while(n-- && d->ht[0].used != 0) {...}//判断ht[0]的数据是否迁移完成if (d->ht[0].used == 0) {//ht[0]迁移完后,释放ht[0]内存空间zfree(d->ht[0].table);//让ht[0]指向ht[1],以便接受正常的请求d->ht[0] = d->ht[1];//重置ht[1]的大小为0_dictReset(&d->ht[1]);//设置全局哈希表的rehashidx标识为-1,表示rehash结束d->rehashidx = -1;//返回0,表示ht[0]中所有元素都迁移完return 0;}//返回1,表示ht[0]中仍然有元素没有迁移完return 1;
}需要关注个核心参数:全局哈希表 dict 结构中的 rehashidx 变量相关了。 rehashidx 变量表示的是当前 rehash 在对哪个 bucket 做数据迁移。比如,当 rehashidx 等于 0 时,表示对 ht[0]中的第一个 bucket 进行数据迁移;当 rehashidx 等于 1 时,表示对 ht[0]中的第二个 bucket 进行数据迁移,以此类推。