目录
Celery介绍
相关环境
相关配置
1、在proj/proj/目录下创建一个新的celery.py模块
定义 Celery 实例:
2、在proj/proj/__init__.py 模块中导入这个应用程序。
3、在各自模块中定义任务文件tasks.py
4、settings.py配置
服务启动
异步调用
Celery介绍
Celery 是一个简单,灵活且可靠的分布式系统,可以处理大量消息。它是一个任务队列,着重于实时处理,同时还支持任务调度。
Celery 可以做队列、异步调用、解耦、高并发、流量削峰、定时任务等等
一个 Celery 系统可以由多个 worker 和 broker 组成,从而实现高可用性和横向扩展。
Celery既可以独立使用,也可以结合Django使用
原理:celery将待处理任务扔进消息队列,然后由worker进程进行消费
相关环境
Python 3.8 django-celery-beat==2.5.0 django-celery-results==2.5.1 celery==5.2.7 redis==4.6.0
此文中用redis做消息队列,用Mysql5.7保存执行结果
相关配置
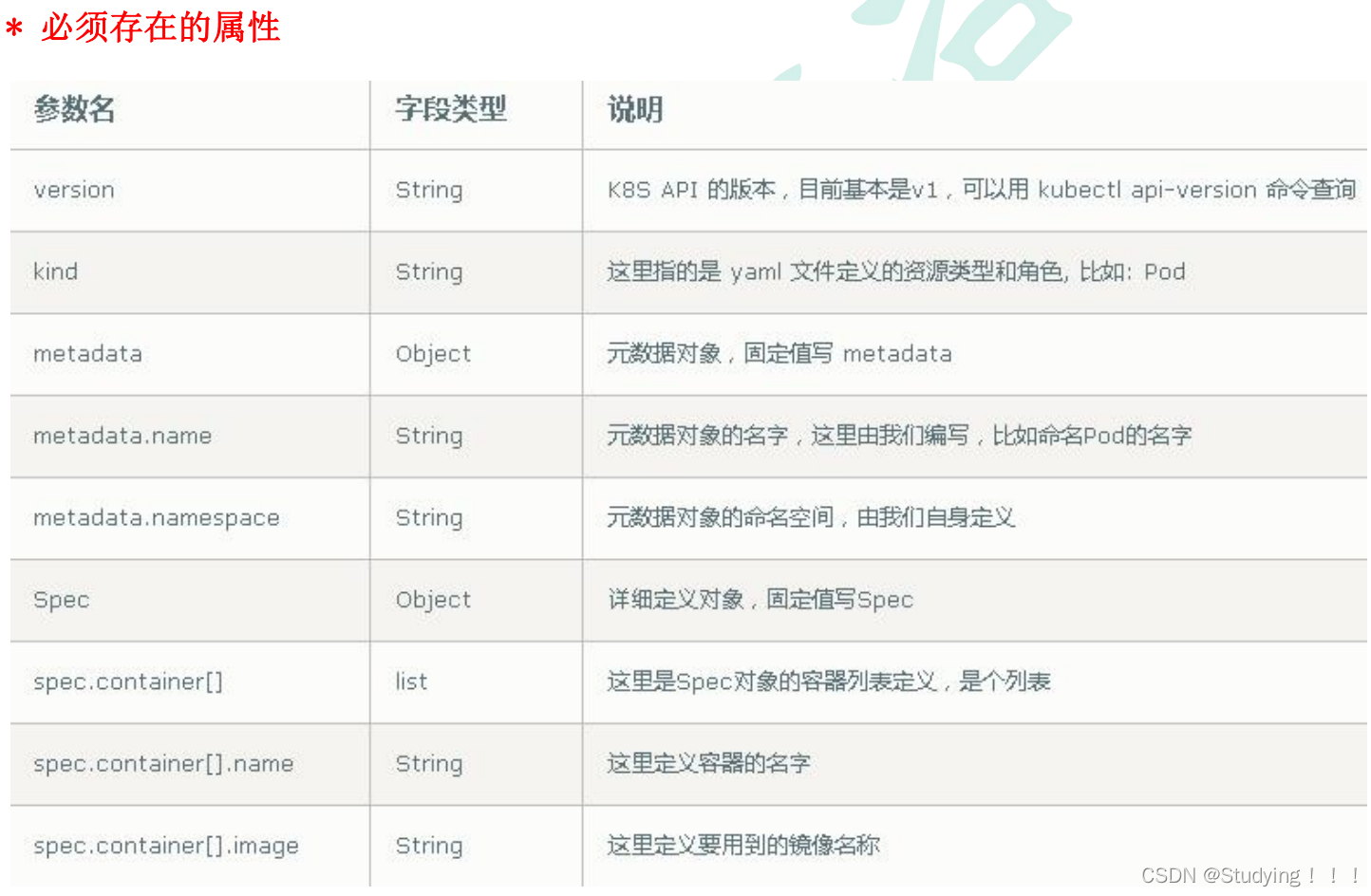
Django 项目布局如下:
- proj/- manage.py- proj/- __init__.py- settings.py- urls.py1、在proj/proj/目录下创建一个新的celery.py模块
定义 Celery 实例:
import osfrom celery import Celery# Set the default Django settings module for the 'celery' program.
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'proj.settings')app = Celery('proj')# Using a string here means the worker doesn't have to serialize
# the configuration object to child processes.
# - namespace='CELERY' means all celery-related configuration keys
# should have a `CELERY_` prefix.
app.config_from_object('django.conf:settings', namespace='CELERY')# Load task modules from all registered Django apps.
app.autodiscover_tasks()@app.task(bind=True, ignore_result=True)
def debug_task(self):print(f'Request: {self.request!r}')os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'proj.settings') 将设置模块传递给设置模块传递给celery程序
app.config_from_object('django.conf:settings', namespace='CELERY')从配置文件中获取以CELERY开头的配置
2、在proj/proj/__init__.py 模块中导入这个应用程序。
主要是为了应用程序在 Django 启动时加载,以便@shared_task装饰器:
proj/proj/__init__.py:
# This will make sure the app is always imported when
# Django starts so that shared_task will use this app.
from .celery import app as celery_app__all__ = ('celery_app',)3、在各自模块中定义任务文件tasks.py
Celery 会自动从tasks.py发现这些任务
#一个简单的tasks任务from celery import shared_task@shared_task
def add(x, y):return x + y
目录结构如下
- proj/- manage.py- proj1/- tasks.py- admin.py- models.py- views.py- tests.py- apps.py- proj/- __init__.py- settings.py- celery.py- urls.py4、settings.py配置
CELERY_BROKER_URL= xxxx.xxx.xxx.xxx
# 消息队列地址,可以是redis、mq、mysql等等
CELERY_ACCEPT_CONTENT = ['json']
CELERY_TASK_SERIALIZER = 'json'
CELERY_TIMEZONE = "Asia/Shanghai"
CELERY_TASK_TRACK_STARTED = True
CELERY_TASK_TIME_LIMIT = 30 * 60
CELERY_ENABLE_UTC = False
DJANGO_CELERY_BEAT_TZ_AWARE = False
CELERY_BEAT_SCHEDULER = 'django_celery_beat.schedulers:DatabaseScheduler'
CELERY_RESULT_BACKEND = 'django-db'
# 任务执行结果保存方式
CELERY_RESULT_BACKEND_TRANSPORT_OPTIONS= {'global_keyprefix': '{}_celery_prefix_'.format(ENV_PROFILE)
}
CELERYD_CONCURRENCY = 5
# 执行任务的并发工作进程/线程/线程的数量。
CELERYD_MAX_TASKS_PER_CHILD = 100
# 任务池工作进程在被新进程替换之前可以执行的最大任务数。默认没有限制。
CELERYD_FORCE_EXECV = TrueCELERY_TASK_TRACK_STARTED:当True时,任务判断是否将其状态报告为“已启动”。默认值是False。任何长时间运行任务并且需要报告当前正在运行的任务。
CELERY_TASK_TIME_LIMIT:任务时间限制(以秒为单位)。当超过这个值时,处理任务进程将被杀死并被新的进程取代。
CELERY_ACCEPT_CONTENT:收到的消息进行序列化,默认情况下仅启用 json,但可以添加任何内容类型,包括 pickle 和 yaml;
注意:
1、celery从4.0引入了小写配置,但是从 Django 设置模块加载 Celery 配置,需要继续使用大写名称。而且还需要使用CELERY_前缀,以便 Celery 设置不会与其他应用程序使用的 Django 设置发生冲突。
2、用Mysql5.7作为任务结果存储,数据库设置为utf8,如果使用utf8mb4无法成功创建相关表
服务启动
celery -A proj worker -l INFO
#定时任务启动方式如下:
celery -A itmanager beat
异步调用
views.py代码如下
#一个简单的tasks任务from proj1.tasks import adddef add(request):x = int(request.POST.get('x', '0'))y = int(request.POST.get('y', '0'))addInfo.delay(x, y)
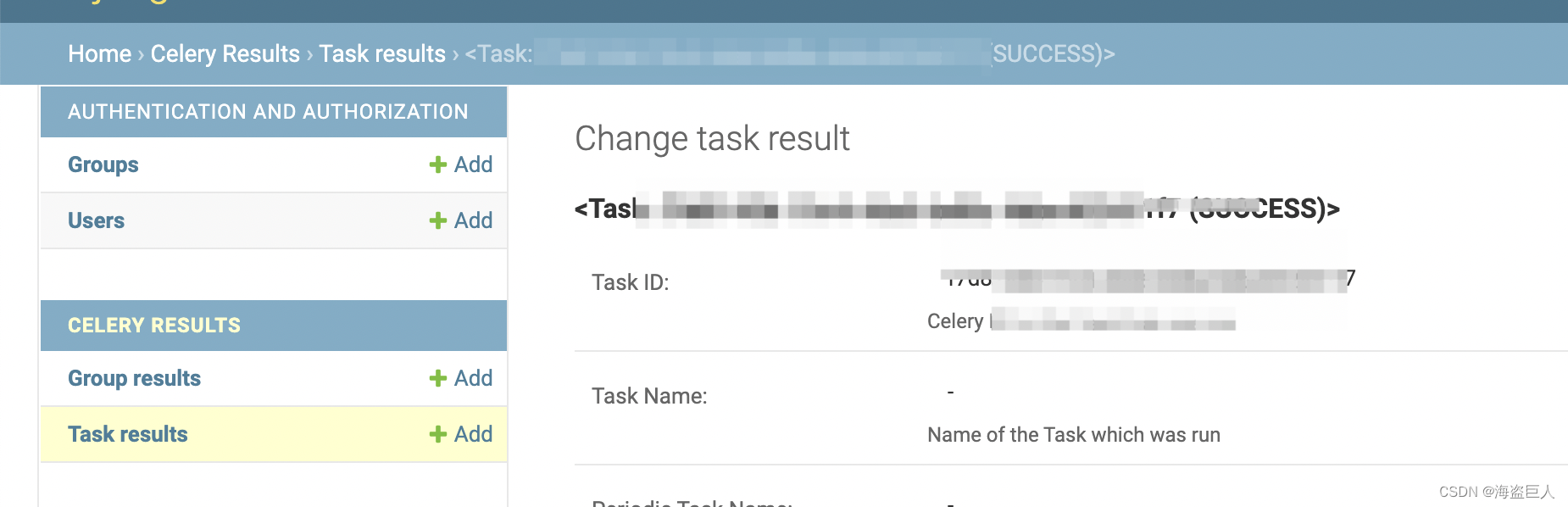
默认情况下不启用保存结果。本文我们已经Celery 结果后端。在admin管理后台可以看到任务运行情况
常见问题
1、结果未保存或任务始终处于PENDING状态
所有任务默认为PENDING,因此状态为“未知”。发送任务时,Celery 不会更新状态,并且任何没有历史记录的任务都被假定为待处理。
-
确保该任务
ignore_result未启用。启用此选项将强制工作人员跳过更新状态
-
确保没有任何旧线程在运行。
很容易意外启动多个工作线程,因此在启动新工作线程之前,请确保前一个工作线程已正确关闭。
未配置预期结果后端的旧工作人员可能正在运行并劫持任务。
可以将该参数--pidfile设置为绝对路径以确保不会发生这种情况。
-
确保客户端配置了正确的后端。
如果由于某种原因,客户端配置为使用与工作线程不同的后端,您将无法收到结果。确保后端配置正确:
>>> result = task.delay() >>> print(result.backend)