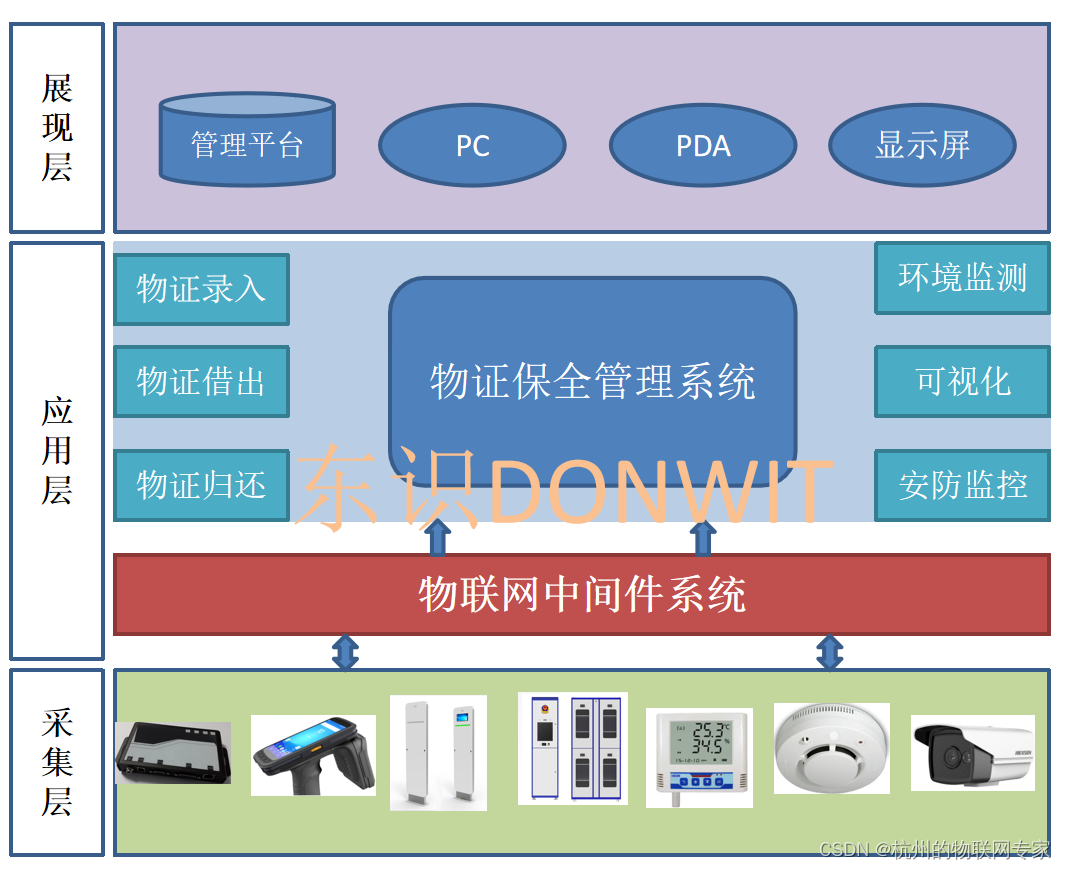
索引
定义
索引:为了提高查找效率而使用的一种数据结构把数据组织起来,可以把索引理解在书的目录或字典的检索表(拼音检索)
索引是一种特殊的文件,可以包含着对数据表里的所有记录的引用指针,对表中的一列或多列创建索引,并指定索引类型,各类索引有各自的数据结构实现
为什么要用索引
使用索引的主要目的是提高数据检索性能和查询效率。以下是一些使用索引的重要原因:
1. 快速数据访问:索引允许数据库系统快速定位和访问表中的数据行,而无需扫描整个表。这对于大型数据集和复杂查询尤为重要,可以显著减少查询的执行时间。
2. 加速搜索操作:当执行搜索、过滤和排序操作时,索引可将数据库系统的工作量大大降低,因为它们提供了一种有效的方式来查找匹配特定条件的数据(使用B+树)。
3. 提高性能:通过减少查询的时间复杂度,索引可以显著提高数据库的性能和响应时间。这对于需要快速响应用户请求的应用程序尤为重要。
4. 减少磁盘I/O:索引通常存储在内存中,这可以减少磁盘I/O的需求。磁盘I/O通常是数据库查询中的性能瓶颈之一,因此索引可以显著降低I/O操作的次数。
5. 支持唯一性约束:索引可以用于确保数据库表中的数据列具有唯一值,这是通过唯一性约束来实现的。唯一索引可防止重复的数据。
6. 支持外键约束:索引可以用于支持外键约束,确保在不同表之间的引用完整性。外键通常涉及到索引的创建,以提高引用表的查询性能。
7. 支持复杂查询:索引可帮助优化复杂查询,包括联接操作、聚合函数和多个筛选条件的查询。它们可以加速这些查询的执行。
尽管索引提供了这些重要的性能优势,但也需要权衡。索引的创建和维护会占用额外的存储空间和计算资源,并且可能会导致写入操作的性能开销。因此,索引的设计和维护需要仔细考虑,以满足特定应用程序的需求,并确保不会引入不必要的复杂性。
索引使用的数据结构
索引使用的数据结构是B+树,在了解B+树前,我们先了解一下B树
B树
我们学习B树之前一定学过二叉搜索树与二叉平衡树这两种数据结构,这里简单提及一下
二叉平衡树(Balanced Binary Tree)和二叉搜索树(Binary Search Tree)是两种不同的二叉树数据结构,它们具有一些相似之处,但也有重要的区别。
二叉搜索树 (Binary Search Tree,BST):
-
特性: 二叉搜索树是一种二叉树,其中每个节点的左子树包含的所有节点的值都小于该节点的值,而右子树包含的所有节点的值都大于该节点的值。这个特性使得在BST中进行快速的查找、插入和删除操作成为可能。
-
性能: 在平均情况下,BST的查找、插入和删除操作的时间复杂度为O(log N),其中N是树中节点的数量。但如果树失衡,最坏情况下时间复杂度可达O(N),这是因为BST没有保证平衡。
二叉平衡树 (Balanced Binary Tree):
-
特性: 二叉平衡树是一种二叉树,它在BST的基础上添加了一个重要的性质,即树的高度保持平衡。这意味着树的左子树和右子树的高度差不会太大,通常不超过1。
-
性能: 由于保持平衡的性质,二叉平衡树的查找、插入和删除操作在最坏情况下也能保持O(log N)的时间复杂度。这使得它在数据结构中的性能更加稳定,而不容易出现极端情况。
二叉搜索树和二叉平衡树是一种很优秀的排序算法,但是这里也是存在一种问题,我们在实际应用的时候,面对的数据是海量的,那么树的深度会大大提升,花费的时间也会变得很大,所以我们就引入了多叉搜索树来解决问题。
特点
1.每个节点可以有多个子树,M 阶 B 树表示该树每个节点最多有 M 个子树
2.每个中间节点有 k-1 个关键字(可以理解为数据)和 k 个子树 (k 介于阶数 M 和 M/2 之间,M/2 向上取整)
3.所有叶子节点都在同一层,并且叶子节点只有关键字,指向孩子的指针为 null
4.若根结点不是终端结点,则至少有2棵子树
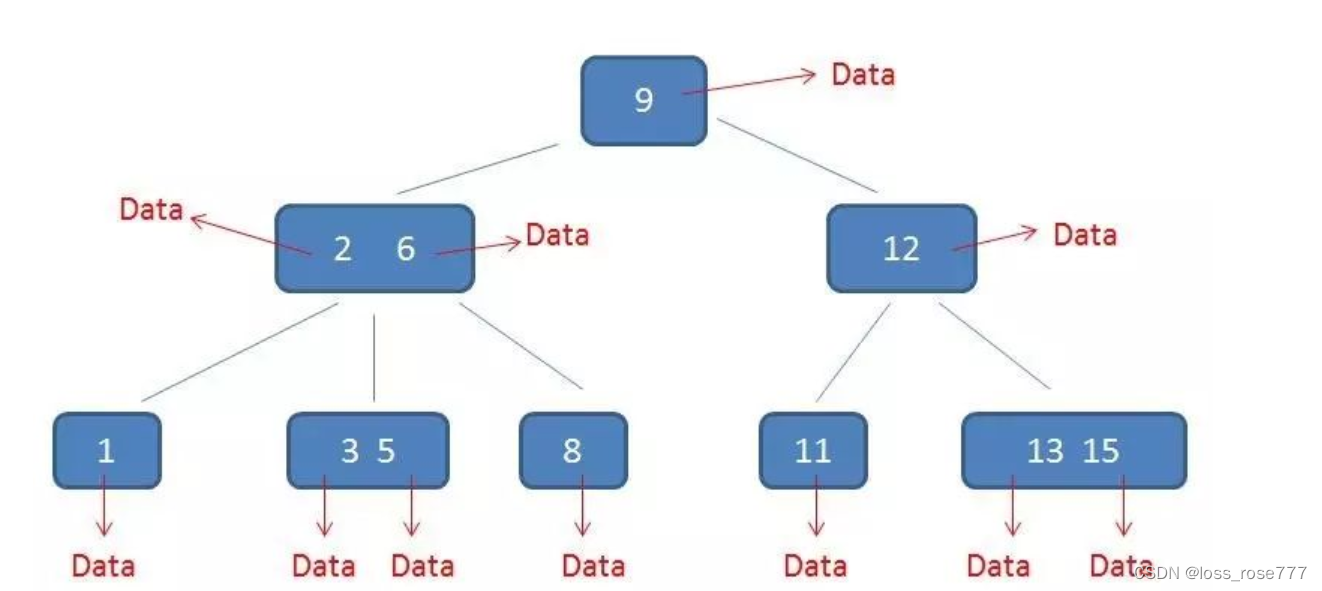
B+树
B+树叶子节点包含所有数据,并且0是一个循环双向链表,这样组织数据更有利范围查找。
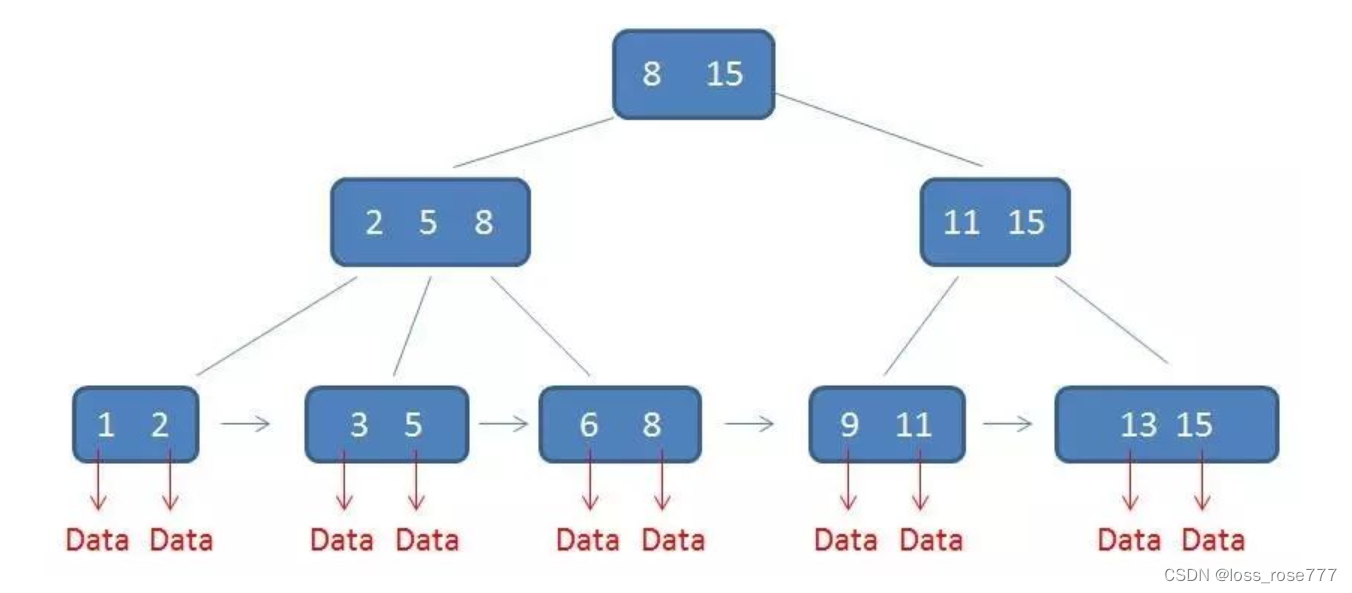
特点:
1.关键字数和子树相同
2.非叶子节点仅用作索引,它的关键字和子节点有重复元素
3.叶子节点用指针连在一起
优点:
1.B+树非叶节点不存储数据,同样大小的磁盘页可以容纳更多的节点,io次数会减少
2.B+树每次查询都要到叶节点,所以查询性能稳定
3.B+树由于所有数据都在叶子节点上,并且有序相连,范围查询非常友好
事务
事务(Transaction)是数据库管理系统(DBMS)中的一个重要概念,用于管理对数据库的一系列操作,以确保数据库的一致性、隔离性、持久性和原子性,通常用于处理数据库中的数据更改
特点
-
原子性(Atomicity): 事务是一个不可分割的操作单元,要么全部执行,要么全部回滚。如果在事务执行中发生故障,数据库会自动回滚事务,确保数据的一致性,防止不完整的操作。
-
一致性(Consistency): 事务在执行前后,必须将数据库从一个一致状态转变为另一个一致状态。这意味着事务的执行不会违反数据库的完整性约束,如唯一性、参照完整性等。
-
隔离性(Isolation): 多个事务可以并行执行,但它们应该互不干扰,互相隔离。隔离性确保了每个事务在查看和修改数据时不会看到其他事务未提交的中间状态,以防止数据不一致和竞态条件。
-
持久性(Durability): 一旦事务成功提交,其结果应该永久保存在数据库中,即使系统崩溃或重启,也不应该丢失。
下面 我们举例说明事务特点:
原子性:
假设有一个银行应用,一个用户要进行银行转账操作,将100元从账户A转账到账户B。这个操作可以分为以下几步:
- 从账户A中减少100元。
- 向账户B中增加100元。
现在,考虑以下情况:
-
如果第一步(减少账户A的金额)成功,但第二步(增加账户B的金额)失败,会出现什么情况?账户A会减少100元,但账户B不会增加相应的金额。这会导致数据不一致。
-
反之,如果第一步失败(例如,由于余额不足),但第二步成功,也会导致数据不一致。
原子性的目标是避免这种中间状态。如果在一个事务中的任何一步失败,整个事务都应该被回滚,以恢复到操作之前的状态。这确保了数据的完整性和一致性。在上述示例中,如果第一步或第二步失败,整个转账操作应该被回滚,以确保不会发生不一致的情况。
原子性在事务中的应用是确保事务的完整性,即要么全部执行,要么不执行。这是数据库管理系统和应用程序在处理事务时的重要特性,以防止不完整的操作或数据不一致。
一致性:
考虑一个存储银行账户信息的数据库。在该数据库中,有一个账户余额(balance)字段,以及一个存款限制(deposit limit)字段。存款限制规定每个账户的存款不能超过1000元。
现在,考虑以下两个并发执行的事务:
事务1: 要求将1000元存入账户A。
事务2: 要求将2000元存入账户A。
如果没有一致性的保证,事务1和事务2可以同时执行,导致以下问题:
- 事务1存入1000元后,账户A的余额变为1000元。
- 事务2存入2000元后,账户A的余额变为3000元。
这违反了存款限制的规则,因为存款不能超过1000元。这会导致数据不一致。
为了确保一致性,数据库管理系统应该在事务执行前检查存款限制的规则,并在事务2尝试存入2000元时拒绝操作。这样,数据库保持一致性,不会违反规则,账户A的余额仍然为1000元。
一致性要求事务操作遵守数据库中定义的规则和约束,以确保数据的完整性和一致性。它确保数据库在事务执行前后保持合法性和规则的完整性,不会违反数据库中的定义规则。这有助于防止数据不一致或不合法的状态。
隔离性:
假设有两个并发执行的事务,事务A和事务B。两者都要执行以下操作:
事务A:
- 读取账户A的余额。
- 将100元从账户A转账到账户B。
- 更新账户A的余额。
- 提交事务A。
事务B:
- 读取账户A的余额。
- 向账户A存入50元。
- 更新账户A的余额。
- 提交事务B。
如果没有隔离性,可能会出现以下问题:
- 事务A在步骤1之后读取了账户A的余额,然后在步骤3之前将100元转账给账户B。
- 与此同时,事务B在步骤1之后也读取了账户A的余额,然后在步骤3之前向账户A存入50元。
这会导致问题,因为两个事务都在不同时间读取了相同的数据,然后进行了操作。这可能导致数据不一致或金额错误。
隔离性的作用是确保这种情况不会发生。通过使用事务隔离级别(例如,读未提交、读提交、可重复读和串行化),数据库管理系统可以控制事务之间的可见性,以确保它们不会相互干扰。这意味着在一个事务中所做的更改在另一个事务看来要么是不可见的,要么在第一个事务完成后才可见。
在上述示例中,如果事务A和事务B采用合适的隔离级别,它们的操作不会互相干扰,从而避免了潜在的数据一致性问题。隔离性确保了多个事务可以并发执行,而不会破坏数据的完整性和一致性。不同的隔离级别提供不同程度的隔离,以满足不同应用场景的需求。
持久性:
假设一个在线购物网站的数据库记录了用户的订单信息。当用户下订单时,系统将创建一个订单并将其存储在数据库中。一旦用户的订单被确认并提交,数据库应该确保这个订单数据是持久的,即使在订单提交后发生了以下情况:
-
系统崩溃: 如果数据库系统在订单提交后崩溃,订单数据不应该丢失。当系统重新启动时,订单数据应该继续存在。
-
断电: 如果数据库服务器突然断电,订单数据应该在重新上电后仍然存在。
-
硬件故障: 即使数据库服务器的硬件组件(如硬盘)发生故障,数据库系统应该有适当的冗余和备份机制,以确保数据可以从备份中恢复。
-
人为错误: 即使管理员或数据库操作人员犯了错误,删除了订单或执行了不正确的操作,数据库应该有记录或备份,以便数据可以恢复。
持久性确保了一旦事务成功提交,数据库不会失去已提交的数据。这对于关键业务数据的安全性和可靠性至关重要,尤其是在需要可靠性和持久性的应用程序中,如金融、医疗保健和电子商务系统。持久性通常通过数据的备份、日志记录和冗余存储等手段来实现。
事务操作
事务通常包括以下操作:
-
开始事务(BEGIN): 标志事务的开始点,通常表示事务的操作要开始执行。
-
执行操作: 在事务中执行数据库操作,如插入、更新、删除数据等。
-
提交事务(COMMIT): 事务成功执行完成后,提交事务,将操作结果永久保存到数据库中。
-
回滚事务(ROLLBACK): 如果事务执行中发生错误或违反了某些规则,可以回滚事务,取消所有操作,使数据库恢复到事务开始之前的状态。
事务隔离级别
脏读
脏读是指一个事务读取了另一个正在进行的事务中尚未提交的数据。这种情况可能导致问题,因为未提交的数据可能会在后续操作中被撤销或更改,从而使读取的数据无效。
举例说明:
- 有两个并发执行的事务,事务A和事务B。
- 在事务A中,用户从账户A中查询余额,得到1000元。
- 在事务B中,用户尝试从账户A中取出200元,但该操作尚未提交。
问题在于,事务A在查询账户A的余额时读取了未提交的数据,也就是1000元。在这个时刻,事务B的操作(尝试从账户A中取出200元)尚未完成,因此账户A的余额尚未减少。
现在,考虑以下两种可能的情况:
- 如果事务B的操作最终成功,账户A的余额会减少200元,变为800元。这是因为200元已被取出。
- 如果事务B的操作在后续的操作中被回滚(例如,由于余额不足),账户A的余额会恢复到原始状态,也就是1000元。
这就是问题所在。事务A读取的数据(1000元)在后续操作中可能会变得无效,因为它取决于事务B的操作是否成功或失败。这导致了不一致性,因为事务A最初的查询结果不再反映实际的账户余额。
与从账户A中取200元的关系在于,事务B的操作(取款)可能会更改账户A的余额,因此与事务A的查询操作相关,可能导致事务A读取了不再准确的数据。这就是脏读的本质:读取了未提交或可能被回滚的数据,从而导致数据不一致。
解决脏读问题:
1、给⼀个写操作的事务加上⼀把锁,在写这个事务从开始时加锁,事务提交或加滚的时候释放锁,被加锁的事务不能与其他事务共存,写锁也叫排他锁
2、可以把当前数据库的隔离级别设置成READ-COMMITTED读已提交,就避免了脏读问题
不可重复读
不可重复读(Non-Repeatable Read)是数据库中的一个并发问题,它发生在一个事务在两次读取同一数据时,得到了不一致的结果。这可能是因为另一个并发事务在两次读取之间修改了数据。
让我用一个示例来说明不可重复读:
-
假设有两个并发执行的事务,事务A和事务B。
-
在事务A中,用户从数据库中读取账户A的余额,得到1000元。
-
在事务B中,用户执行以下操作:
- 增加账户A的余额100元。
- 提交事务B。
-
然后,在事务A中,用户再次读取账户A的余额,得到1100元。
在这个示例中,事务A两次读取了同一个数据,即账户A的余额,但结果不一致。第一次读取是1000元,而第二次读取是1100元。这是因为在两次读取之间,事务B修改了数据,增加了100元。
不可重复读的问题在于,事务A在两次读取之间看到了不一致的数据状态。这可能会导致数据分析或决策出现问题,因为数据在短时间内发生了变化,而事务A并没有意识到这一点。
为了解决不可重复读的问题,数据库管理系统提供了不同的隔离级别,如"读未提交"、"读提交"、"可重复读"和"串行化"。在较高的隔离级别下,不可重复读问题通常是不允许的,数据库会保证事务之间的数据一致性。不同的隔离级别提供不同程度的隔离,以满足应用程序的需求。
幻读
幻读(Phantom Read)是数据库中的另一个并发问题,类似于不可重复读,但它发生在一个事务在两次查询同一个范围的数据时,得到了不一致的结果。幻读通常与插入或删除操作有关,即使在两次查询之间没有其他事务修改数据,也会导致数据不一致。
让我用一个示例来说明幻读:
-
假设有两个并发执行的事务,事务A和事务B。
-
在事务A中,用户从数据库中查询了所有账户余额大于1000元的记录,得到3个账户。
-
在事务B中,用户执行以下操作:
- 插入了一个新的账户,余额为1500元。
- 提交事务B。
-
然后,在事务A中,用户再次查询了所有账户余额大于1000元的记录,得到4个账户。
在这个示例中,事务A两次查询了相同的范围,即账户余额大于1000元的记录,但结果不一致。第一次查询得到3个账户,而第二次查询得到4个账户。这是因为在两次查询之间,事务B插入了一个新的记录,导致第二次查询结果发生了变化。
幻读的问题在于,它可能会导致查询结果不稳定,即使没有其他事务修改了数据。这对需要准确的查询结果的应用程序可能是一个问题,因为结果可能会在短时间内发生变化,而事务A并不知道。
为了解决幻读问题,数据库管理系统通常提供不同的隔离级别,如"读未提交"、"读提交"、"可重复读"和"串行化"。在较高的隔离级别下,幻读通常是不允许的,数据库会保证事务之间的数据一致性。不同的隔离级别提供不同程度的隔离,以满足应用程序的需求。
隔离级别
隔离级别(Isolation Level)是数据库管理系统提供的一种设置,用于控制多个并发事务之间的可见性和互操作方式。隔离级别规定了事务之间的隔离程度,以确保数据库操作的一致性和可靠性。不同的隔离级别提供了不同程度的隔离,以满足不同应用程序的需求。
常见的数据库隔离级别包括以下四个:
-
读未提交(Read Uncommitted): 这是最低的隔离级别,允许一个事务读取另一个事务尚未提交的数据。这意味着脏读、不可重复读和幻读都是可能的。这个级别提供了最高的并发性,但牺牲了数据一致性。
-
读提交(Read Committed): 在这个级别下,一个事务只能读取已经提交的数据。这消除了脏读,但仍然允许不可重复读和幻读。这是许多数据库系统的默认隔离级别。
-
可重复读(Repeatable Read): 在这个级别下,事务可以读取已经提交的数据,并且在事务的生命周期内,其他事务不能修改或插入新的数据,以确保不可重复读和幻读不会发生。这提供了更高的数据一致性,但可能会导致一些并发性降低。
-
串行化(Serializable): 这是最高的隔离级别,它确保事务彼此之间完全隔离,不允许并发操作。在串行化级别下,事务将一个接一个地执行,消除了所有并发问题,但牺牲了并发性能。
选择适当的隔离级别取决于应用程序的需求和性能要求。更高的隔离级别提供了更高的数据一致性,但通常会导致更低的并发性能。较低的隔离级别提供了更高的并发性能,但可能会导致一些并发问题。开发人员需要根据应用程序的要求权衡这些因素,并选择适当的隔离级别来确保数据的完整性和一致性。