前言
课上的实验
由于不想被抄袭,所以暂时不放完整代码
Adult数据集可以在Azure官网上找到
Azure 开放数据集中的数据集 - Azure Open Datasets | Microsoft Learn
数据集预处理
- 删除难以处理的权重属性fnlwgt与意义重复属性educationNum
- 去除重复行与空行
- 删除包含异常值的数据
处理连续值属性
- 年龄数据分箱(使得各个年龄段中高收入人群占比的差异尽量大):
- 资本收益数据分箱
- 资本支出数据分箱
- 某周工作时长数据分箱
处理离散值属性
- workclass工作部门,可以把相同的工作部门归为一类避免决策树分叉过多
- education学历,可以把学历相近的分为一块,以减少决策树分叉
- maritalStatus婚姻状况,将离异、丧偶、分居等归为一类,未婚归为一类,已婚与配偶暂时不在归为一类,再婚归为一类,分四类。
- occupation职业,由于不同职业的薪水状况不同,所以只能每个职业都单独作为一类
- relationship家庭关系,每种单独分为一类
- race种族,每种单独归类
- sex性别,分两类
- nativeCountry国籍,由于美国人居多,所以分为美国与其他国家两类
- income收入,这是我们需要预测的结果,分为 >50K 和 <=50K,由于测试集中的标签多了一个‘.’所以需要单独处理一下
C4.5决策树
其实决策树并没什么太难的地方,主要是使用的python,pandas库在划分数据集时如果使用单行遍历会很慢,此时需要找到符合功能需求的批处理函数
决策树主要分为以下几个模块
1、计算信息熵(D表示数据集,|D|表示数据集大小,Di表示分类结果为i的数据集)
信息熵:
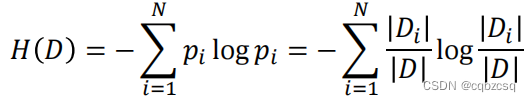
条件信息熵:(按照属性A划分之后的信息熵加权平均数,D(j)表示属性A为j的数据集)
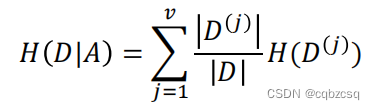
2、获取数据集中的众数。作为叶节点的信息
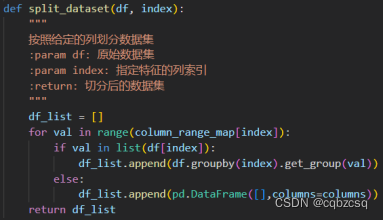
3、将数据集按照某个关键字划分。这里很坑,如果单行遍历划分回巨慢无比,但是pandas有专门的批处理函数groupby用于划分(划分时间直接从30+s优化到0.0s),但是如果当前值不存在会发生报错,所以要单独加入一个占位的DataFrame
4、决策树划分策略
按照C4.5决策树的划分规则,需要计算信息增益比
信息增益:
![]()
信息增益比
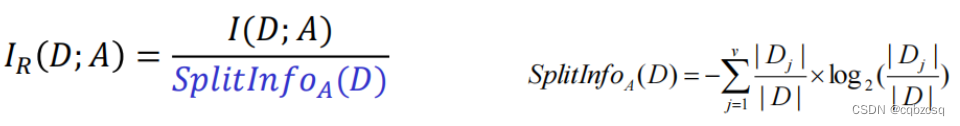
所以,在寻找最优划分策略的时候需要枚举每一个未划分的属性,计算划分后的数据集的信息增益比,选择信息增益比最高的属性进行划分即可
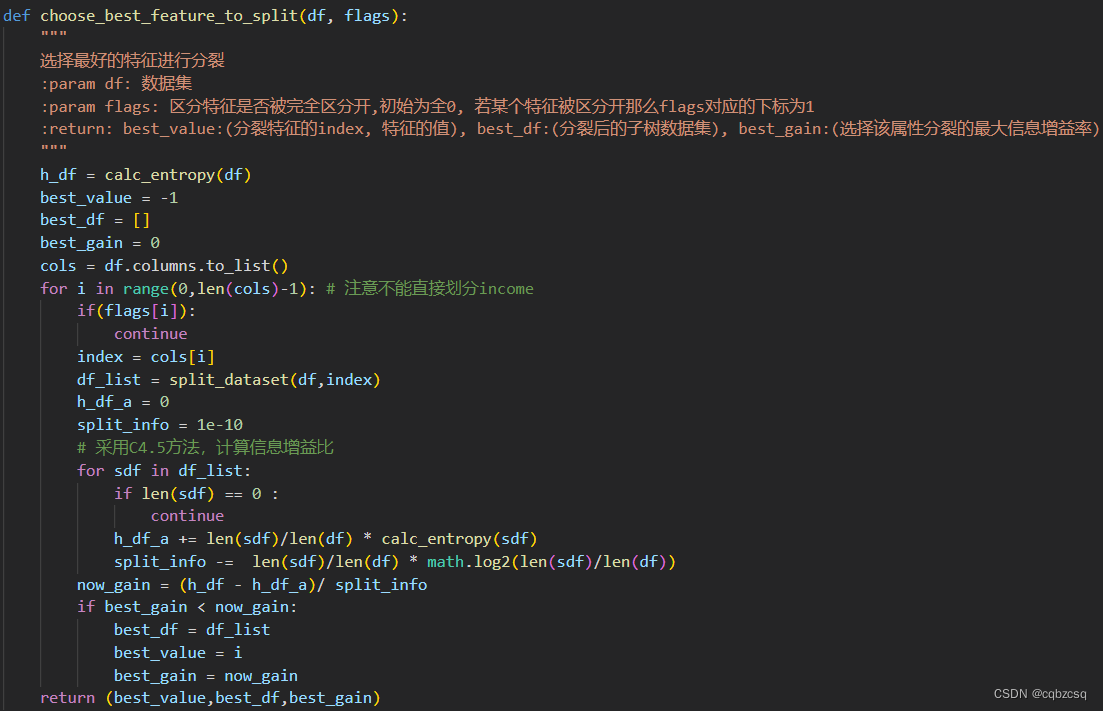
5、决策树构建
由于决策树很容易过拟合,所以这里使用了两种剪枝方法,首先设置节点纯度阈值,当递归时节点纯度高于阈值时可以直接选用当前数据集的众数作为节点值,停止递归。然后设置深度阈值,当超过该深度时就取当前数据集的众数作为节点值,停止递归。

构建过程:
由于是进行的递归构建,相当于在对最优决策树做一个先根遍历,首先对于当前节点,在决策树存储矩阵上添加一行,存储当前节点的决策信息;然后将每个儿子返回的矩阵依次append到这个矩阵下方,利用当前的矩阵行数计算儿子行标相对于当前节点行标的增量。完成构建之后,为了后续方便查询,对每个节点的用当前的行数加上儿子节点的增量,就可以算出儿子节点对应的行数。
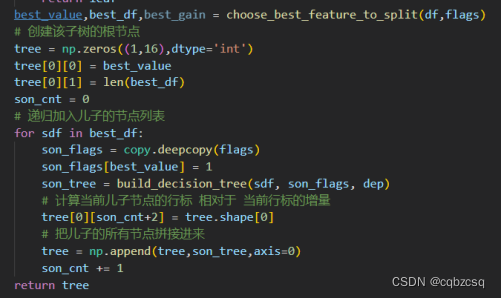

6、决策树分类过程
对于每个数据组,从决策树根节点开始,选择决策树节点划分的属性,将当前节点id跳转到数据该属性对应值的儿子节点即可,直到跳转到叶子节点停止

运行结果
训练集分类结果(准确率0.833)

测试集分类结果(准确率0.836)
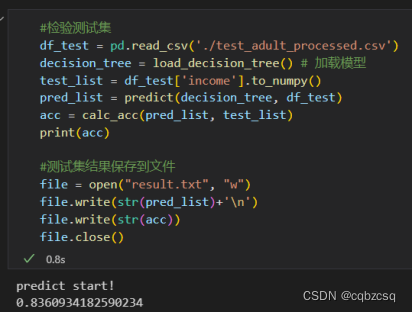
效果还是不错,堪比神经网络?
反思总结
这次实验花费了很长时间在数据集的分析和处理上
包括年龄和资本收支的分箱、离散值归并,并且发现了测试集数据中income标签与训练集不同的问题。
决策树构建过程中花费了许多时间去查询pandas的批处理函数,如果之前有pandas库调用的基础会好很多。
决策树存储结构选用numpy是不太合适的,因为每一个节点的结构儿子个数是不定的,如果按照最多分支数来设置矩阵的列数会有很多空间是浪费的。使用list+dict保存每个节点的数据,用json文件存储读取应该会方便一些。