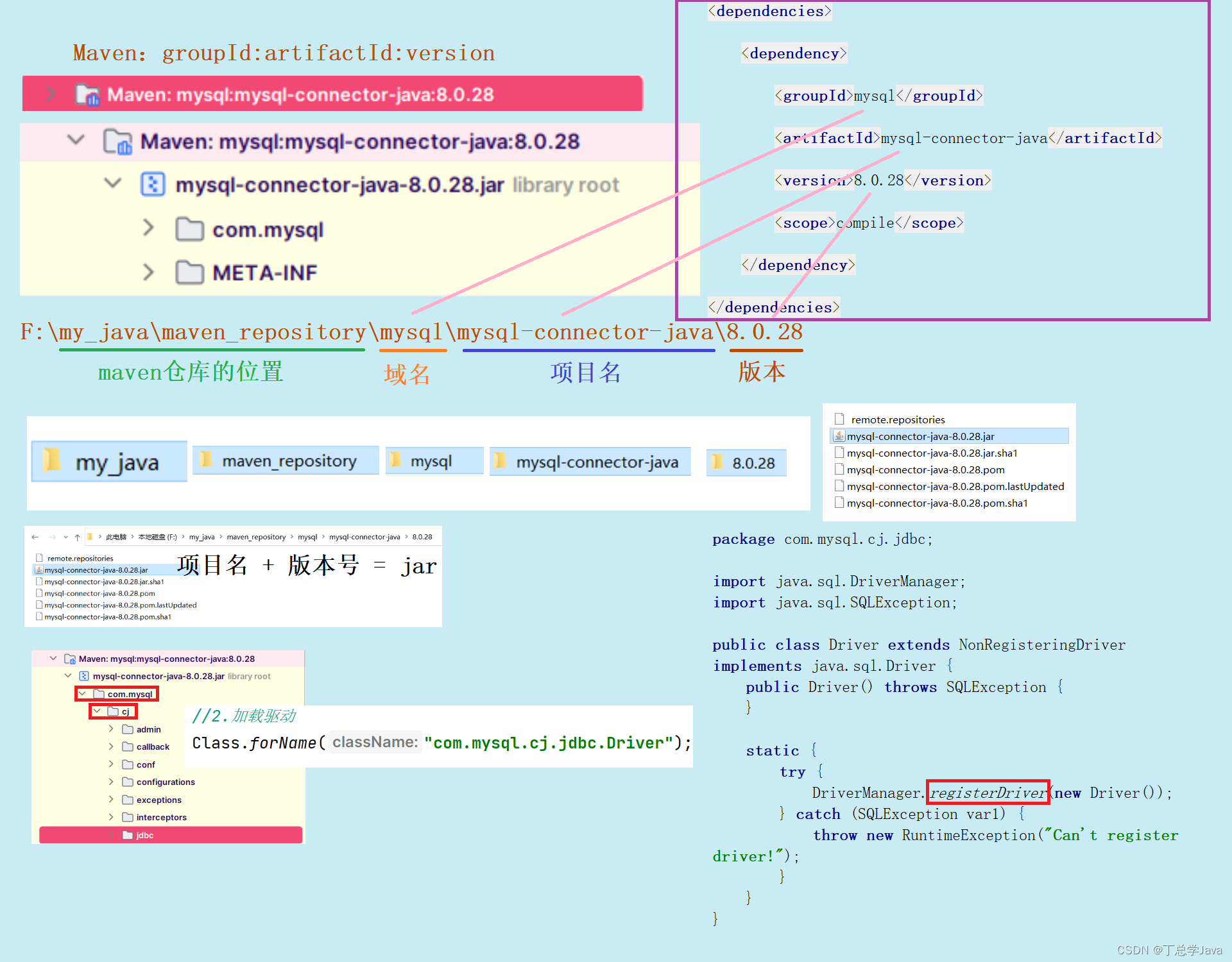
一、数据写出
(1)SparkSQL统一API写出DataFrame数据
统一API写法:

常见源写出:

# cording:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, IntegerType, StringType
import pyspark.sql.functions as F
if __name__ == '__main__':spark = SparkSession.builder.\appName('write').\master('local[*]').\getOrCreate()sc = spark.sparkContext# 1.读取文件schema = StructType().add('user_id', StringType(), nullable=True).\add('movie_id', IntegerType(), nullable=True).\add('rank', IntegerType(), nullable=True).\add('ts', StringType(), nullable=True)df = spark.read.format('csv').\option('sep', '\t').\option('header', False).\option('encoding', 'utf-8').\schema(schema=schema).\load('../input/u.data')# write text 写出,只能写出一个列的数据,需要将df转换为单列dfdf.select(F.concat_ws('---', 'user_id', 'movie_id', 'rank', 'ts')).\write.\mode('overwrite').\format('text').\save('../output/sql/text')# write csvdf.write.mode('overwrite').\format('csv').\option('sep',';').\option('header', True).\save('../output/sql/csv')# write jsondf.write.mode('overwrite').\format('json').\save('../output/sql/json')# write parquetdf.write.mode('overwrite').\format('parquet').\save('../output/sql/parquet')
二、写出MySQL数据库
API写法:

注意:
①jdbc连接字符串中,建议使用useSSL=false 确保连接可以正常连接( 不使用SSL安全协议进行连接)
②jdbc连接字符串中,建议使用useUnicode=true 来确保传输中不出现乱码
③save()不要填参数,没有路径,是写出数据库
④dbtable属性:指定写出的表名
# cording:utf8from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, IntegerType, StringType
import pyspark.sql.functions as F
if __name__ == '__main__':spark = SparkSession.builder.\appName('write').\master('local[*]').\getOrCreate()sc = spark.sparkContext# 1.读取文件schema = StructType().add('user_id', StringType(), nullable=True).\add('movie_id', IntegerType(), nullable=True).\add('rank', IntegerType(), nullable=True).\add('ts', StringType(), nullable=True)df = spark.read.format('csv').\option('sep', '\t').\option('header', False).\option('encoding', 'utf-8').\schema(schema=schema).\load('../input/u.data')# 2.写出df到MySQL数据库df.write.mode('overwrite').\format('jdbc').\option('url', 'jdbc:mysql://pyspark01:3306/bigdata?useSSL=false&useUnicode=true&serverTimezone=GMT%2B8').\option('dbtable', 'movie_data').\option('user', 'root').\option('password', '123456').\save()# 读取df.read.mode('overwrite'). \format('jdbc'). \option('url', 'jdbc:mysql://pyspark01:3306/bigdata?useSSL=false&useUnicode=true&serverTimezone=GMT%2B8'). \option('dbtable', 'movie_data'). \option('user', 'root'). \option('password', '123456'). \load()'''JDBC写出,会自动创建表的因为DataFrame中的有表结构信息,StructType记录的 各个字段的名称 类型 和是否运行为空'''








![[SQL开发笔记]AND OR运算符复杂表达式开发实例](https://img-blog.csdnimg.cn/133fc7ee58b846c681889ab35fe9e682.png)