在《0基础学习PyFlink——Map和Reduce函数处理单词统计》和《0基础学习PyFlink——模拟Hadoop流程》这两篇文章中,我们使用了Python基础函数实现了字(符)统计的功能。这篇我们将切入PyFlink,使用这个框架实现字数统计功能。
PyFlink安装
安装Python
sudo apt install python3.10
sudo ln -s /usr/bin/python3.10 /usr/bin/python
安装虚拟环境
sudo apt install python3.10-venv
创建工程所在文件夹,并创建虚拟环境
mkdir pyflink-test
cd pyflink-test
python -m venv .env
进入虚拟环境,并安装PyFlink
source .env/bin/activate
pip3.10 install apache-flink
统计代码
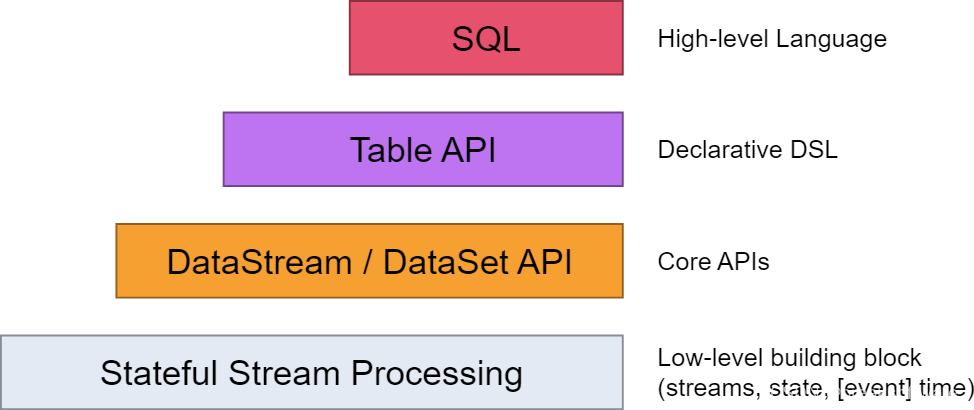
Flink为开发者提供了如下不同层级的抽象。本篇我们将尽量使用SQL来实现功能。
创建环境
执行环境用于设置任务的属性(batch还是stream),以及一些运行时参数(parallelism.default等)。
和Hadoop不同的是,Flink是流批一体(既可以处理流,也可以处理批处理)的引擎,而前者是批处理引擎。
批处理很好理解,即给一批数据,我们一次性、成批处理完成。
而流处理则是指,数据源源不断进入引擎,没有尽头。
本文不对此做过多展开,只要记得本例使用的是批处理模式(in_batch_mode)即可。
import argparse
import logging
import sysfrom pyflink.common import Configuration
from pyflink.table import (EnvironmentSettings, TableEnvironment)def word_count(input_path):config = Configuration()# write all the data to one fileconfig.set_string('parallelism.default', '1')env_settings = EnvironmentSettings \.new_instance() \.in_batch_mode() \.with_configuration(config) \.build()t_env = TableEnvironment.create(env_settings)
Source
在前两篇文章中,我们使用内存中的常规结构体,如dict等来保存Map过后的数据。而本文介绍的SQL方式,则是通过Table(表)的形式来存储,即输入的数据会Map到一张表中
# define the sourcemy_source_ddl = """create table source (word STRING) with ('connector' = 'filesystem','format' = 'csv','path' = '{}')""".format(input_path)t_env.execute_sql(my_source_ddl).print()tab = t_env.from_path('source')
这张表只有一个字段——String类型的word。它用于记录被切分后的一个个字符串。
这儿有个关键字with。它可以用于描述数据读写相关信息,即完成数据读写相关的设置。
connector用于指定连接方式,比如filesystem是指文件系统,即数据读写目标是一个文件;jdbc则是指一个数据库,比如mysql;kafka则是指一个Kafka服务。
format用于指定如何把二进制数据映射到表的列上。比如CSV,则是用“,”进行列的切割。
Execute
# execute insertmy_select_ddl = """select word, count(1) as `count`from sourcegroup by word"""t_env.execute_sql(my_select_ddl).wait()
上述SQL我们按source表中的word字段聚类,统计每个字符出现的个数。
完整输出如下
Using Any for unsupported type: typing.Sequence[~T]
No module named google.cloud.bigquery_storage_v1. As a result, the ReadFromBigQuery transform *CANNOT* be used with `method=DIRECT_READ`.
OK
+--------------------------------+----------------------+
| word | count |
+--------------------------------+----------------------+
| A | 3 |
| B | 1 |
| C | 2 |
| D | 2 |
| E | 1 |
+--------------------------------+----------------------+
5 rows in set
完整代码
# sql_print.py
import argparse
import logging
import sysfrom pyflink.common import Configuration
from pyflink.table import (EnvironmentSettings, TableEnvironment)def word_count(input_path):config = Configuration()# write all the data to one fileconfig.set_string('parallelism.default', '1')env_settings = EnvironmentSettings \.new_instance() \.in_batch_mode() \.with_configuration(config) \.build()t_env = TableEnvironment.create(env_settings)# define the sourcemy_source_ddl = """create table source (word STRING) with ('connector' = 'filesystem','format' = 'csv','path' = '{}')""".format(input_path)t_env.execute_sql(my_source_ddl).print()tab = t_env.from_path('source')my_select_ddl = """select word, count(1) as `count`from sourcegroup by word"""t_env.execute_sql(my_select_ddl).print()if __name__ == '__main__':logging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(message)s")parser = argparse.ArgumentParser()parser.add_argument('--input',dest='input',required=False,help='Input file to process.')argv = sys.argv[1:]known_args, _ = parser.parse_known_args(argv)word_count(known_args.input)
测试的输入文件
“A”,
“B”,
“C”,
“D”,
“A”,
“E”,
“C”,
“D”,
“A”,
运行的指令是
python sql_print.py --input input1.csv
参考资料
- https://nightlies.apache.org/flink/flink-docs-master/zh/docs/concepts/overview/