文章目录
- 前言
- Dataworks API 文档解读
- GetMetaDBTableList 接口文档
- API 调试
- 在线调试
- 本地调试
- 运行环境
- 账密问题
- 请求数据
- 进一步处理
- 小结
前言
最近,我需要对公司的数据资产进行梳理,这其中便包括了Dataworks各个项目下的表单。这些表单,作为公司的重要数据资产之一,也需要进行整理和规范。幸运的是,官方提供了API接口,可以辅助我更高效地获取各个项目下的所有表单。
Dataworks API 提供了很多项目及表单的信息,比如表单列表、表单的名称、创建时间、所属项目、调度信息等等。
本文以一个比较简单的例子(获取表单列表)展开详细讲解下整个流程。
Dataworks API 文档解读
DataWorks OpenAPI 概述文档:https://help.aliyun.com/zh/dataworks/developer-reference/api
调取 Dataworks API 之前,需要留一下 API 的调取是有限额的。
基础版每日API总调用次数≤100次,标准版每日API总调用次数≤1000次,专业版每日API总调用次数≤10000次,而且不支持额外付费调用。而企业版几乎可以忽略调用限制,调用次数多且支持额外付费调用。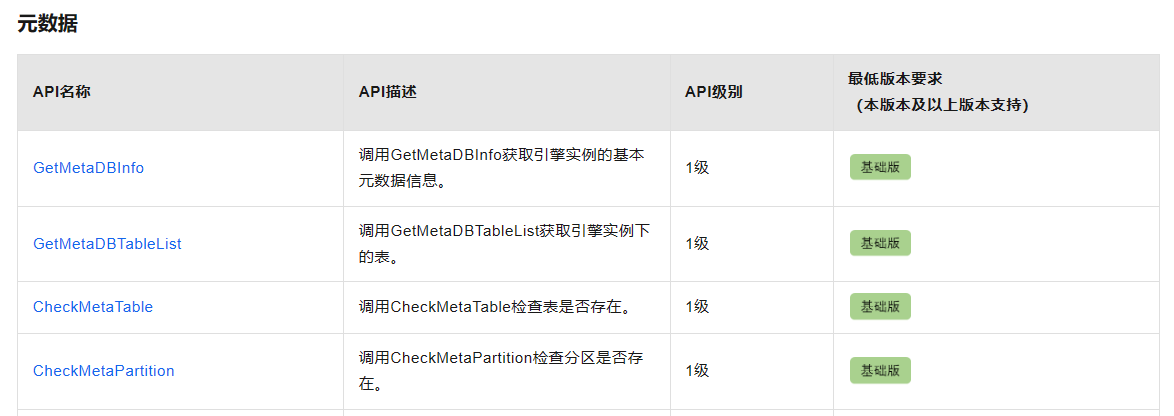
为规范 DataWorks OpenAPI 的调用,官方将 OpenAPI 分为1级、2级和3级,具体分类方式没有介绍,不过每一个 API 都有对应的级别说明,详见文档介绍。
GetMetaDBTableList 接口文档
本次要获取的是某项目下的表单名称,所以查看 GetMetaDBTableList 接口。
注意,文档中说的【引擎实例】其实就是 MaxCompute 的项目,所以这个相当于是在 DataWorks 中获取 MaxCompute 的项目的表。这个在工作空间中可以看到相关的配置信息。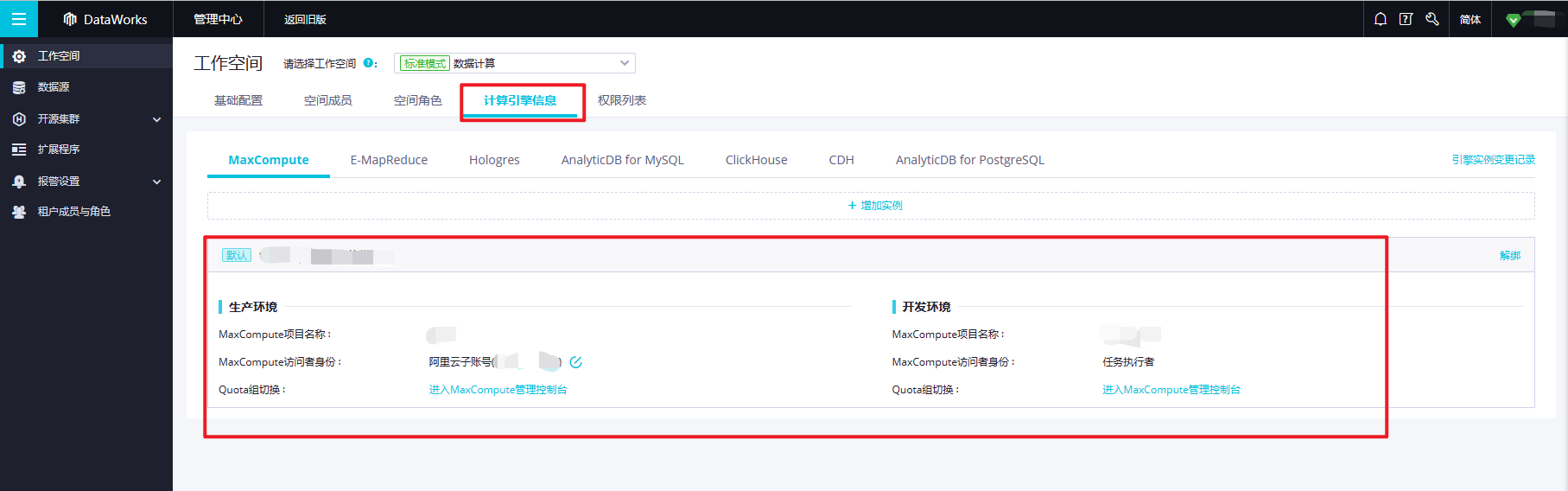
另外,DataWorks 和 MaxCompute 的关系:
DataWorks 是阿里云提供的一站式大数据开发治理平台,可以在 DataWorks 上进行 MaxCompute 作业开发、周期性调度、作业运维、数据治理等一站式数据开发治理操作。可在 DataWorks 控制台创建 DataWorks 工作空间,并在这过程中直接创建并绑定 MaxCompute 项目,后续即可在 DataWorks 工作空间中开发 MaxCompute 作业。
MaxCompute通过 DataWorks 采用可视化方式,进行任务工作流的配置、周期性调度执行及元数据管理,保障数据生产及管理的高效稳定。
回到文档上,可以看到需要的参数有很多,但是并不是所有都需要,具体可以在调试部分点击【调试】按钮,到调试页面进行测试,或者直接点击该链接直达:https://next.api.aliyun.com/api/dataworks-public/2020-05-18/GetMetaDBTableList
调试入口
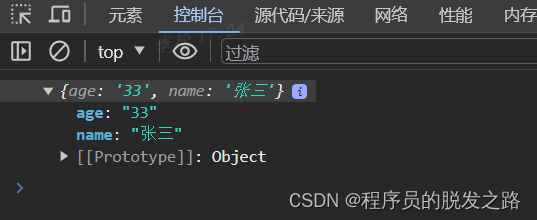
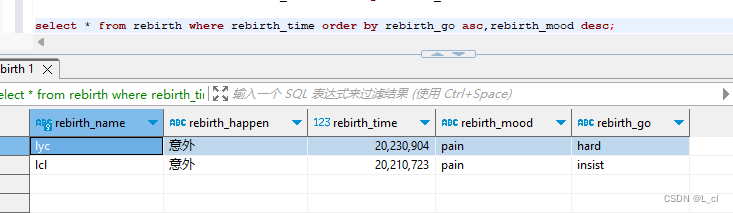
再往下,看看返回的数据,返回的数据结构如下。RequestId 和 Data 是同级的,我需要的 TableName 的路径是 Data -> TableEntityList -> TableName。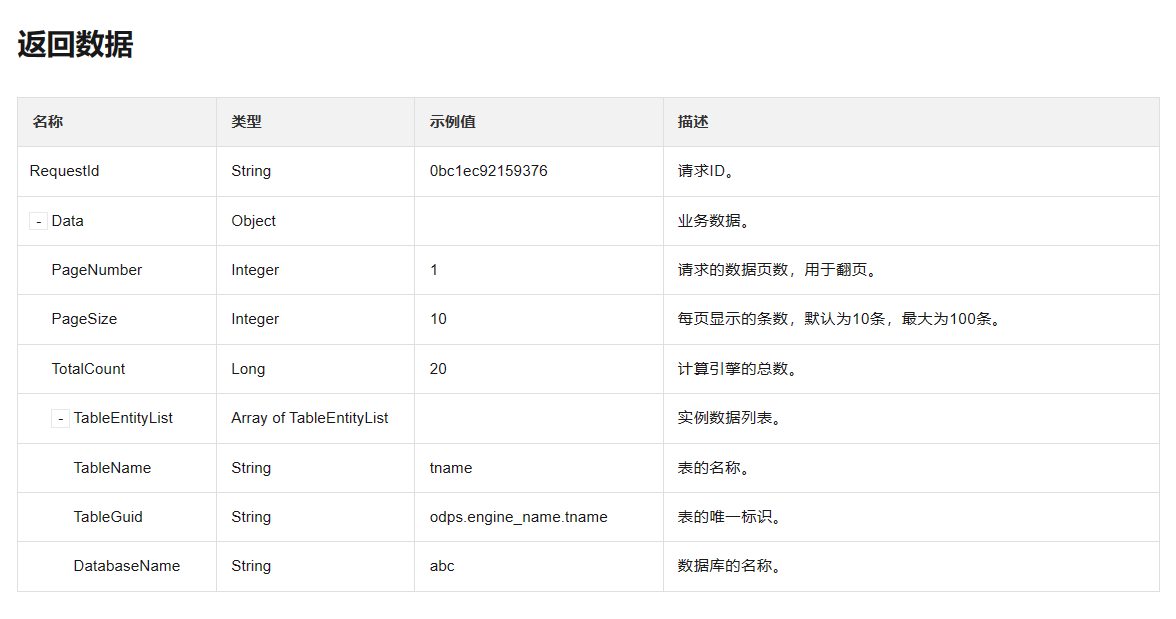
“剧透”下,这些数据都是 body 的值,后续调用可以看到对应的结构,处理值的时候,也需要从 body 层级开始取。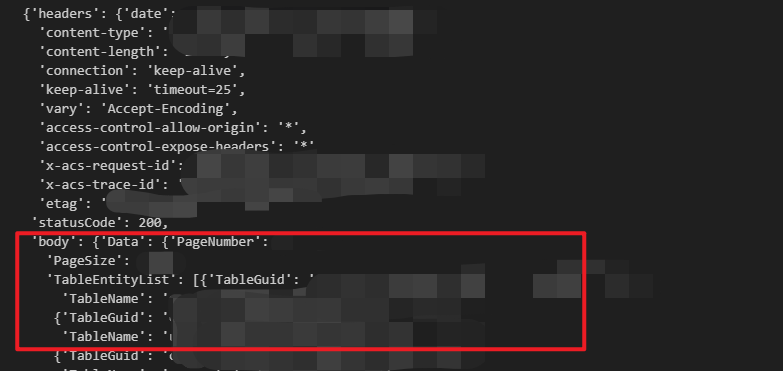
文档下面是一些示例和错误码,自行查看即可。
可能你看完后跟我一样,一脸懵逼!这就能取数了?不,取数的逻辑不在这里,具体的代码逻辑,可以在调试界面获取相关的参考代码,而且支持多种编程语言调取接口。
API 调试
在线调试
了解了基本的信息,接下来调试下。
在调试界面,可以看到,必填的参数其实只有一个,经过测试,填上该参数即可获取到相关的表单列表数据。
默认情况下,一页展示 10 条记录,最大可以展示 100 条,可以将分页参数的 PageSize 调到最大,使用最少的次数将表单数据都拉取下来。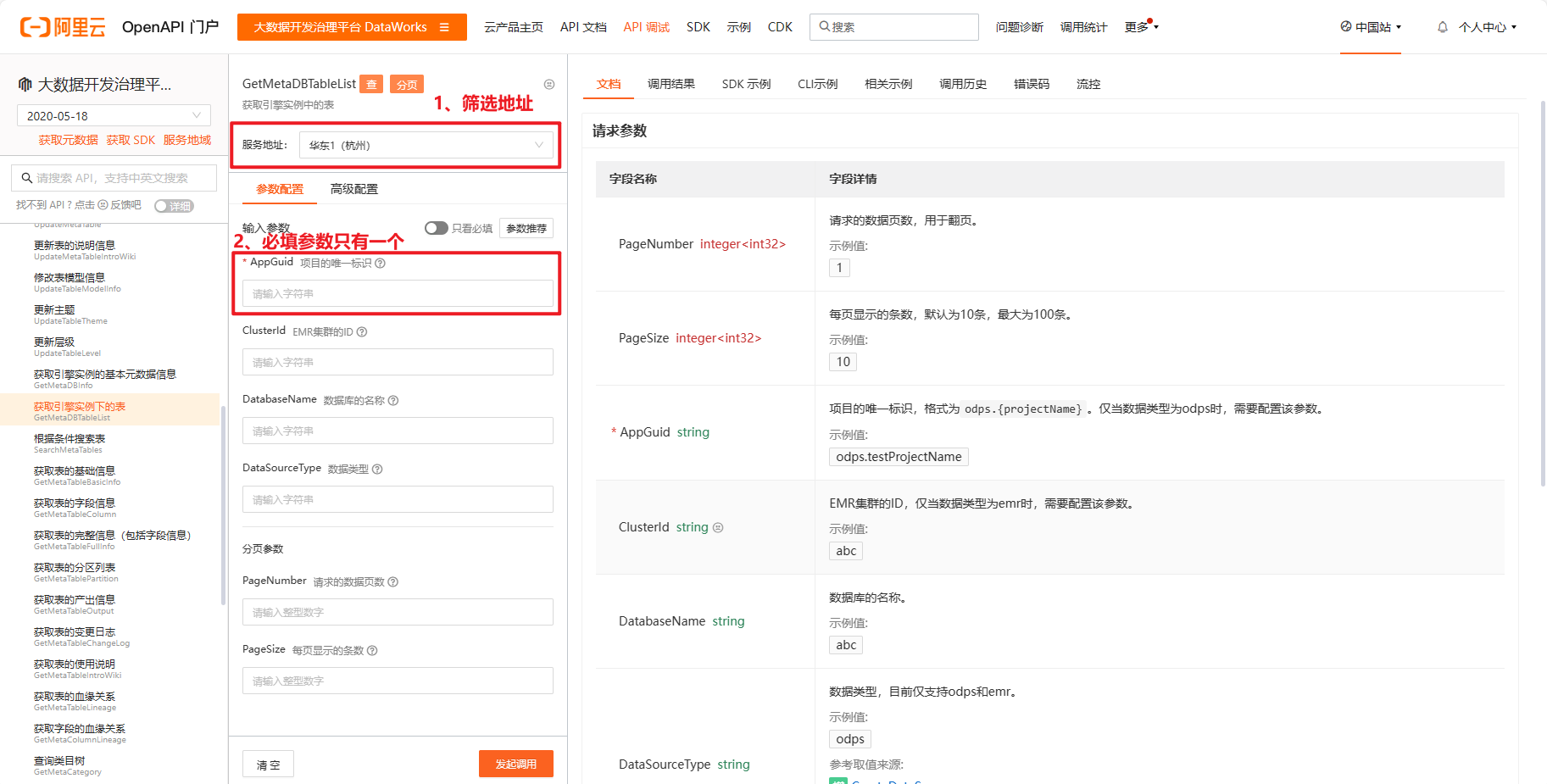
发起调用之后,可以看到调用的结果信息,里面有一个返回值:TotalCount,官方介绍是计算引擎的总数,其实就是表单数量,可以结合该值调整页数和每页的记录数。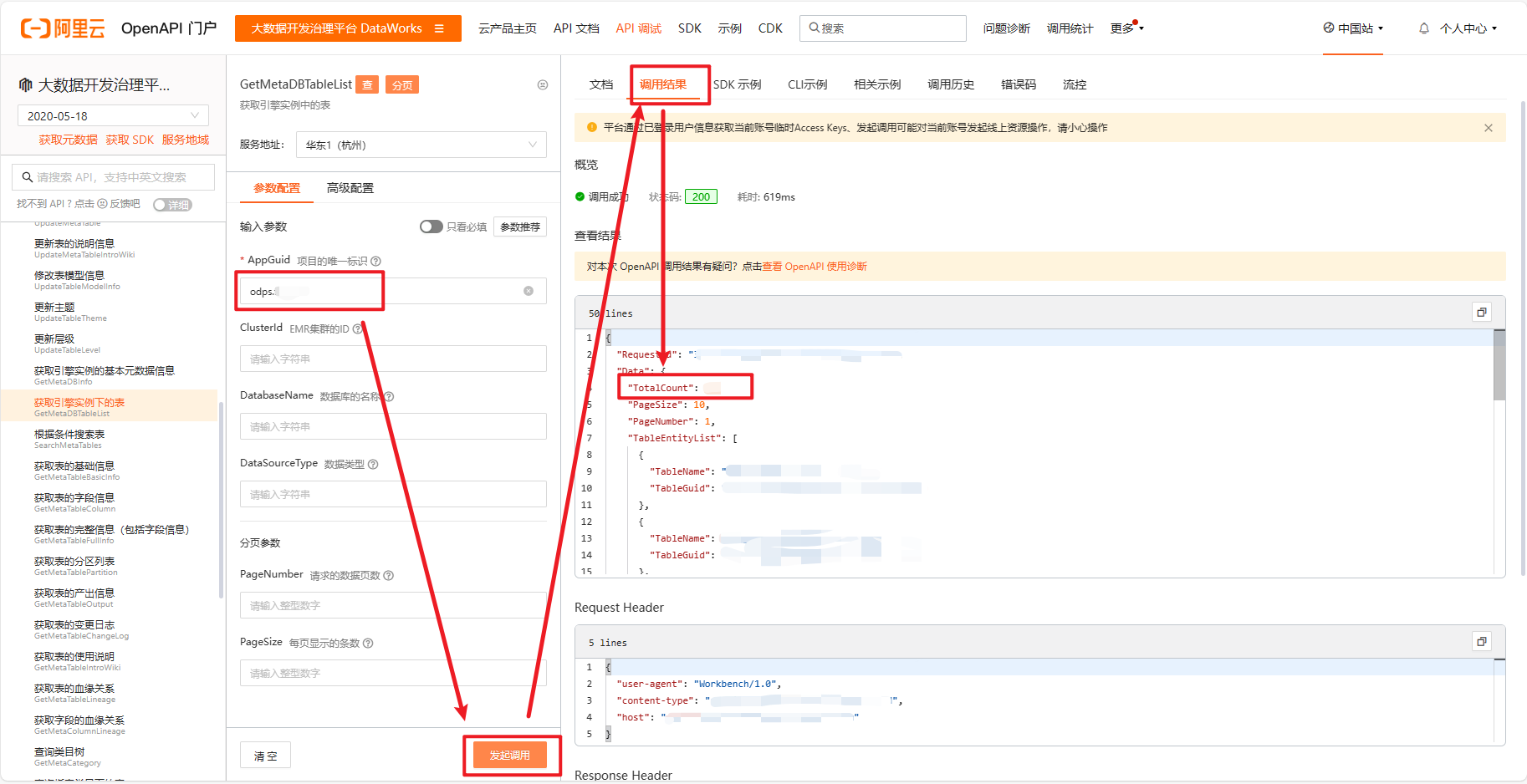
本地调试
调试没问题,那就进入下一步,在本地敲代码调 API 接口获取数据。
还是在调试页面,点击【SDK 示例】,这里以 Python 为例,点击 Python。可以看到一段完整的 Python 源码。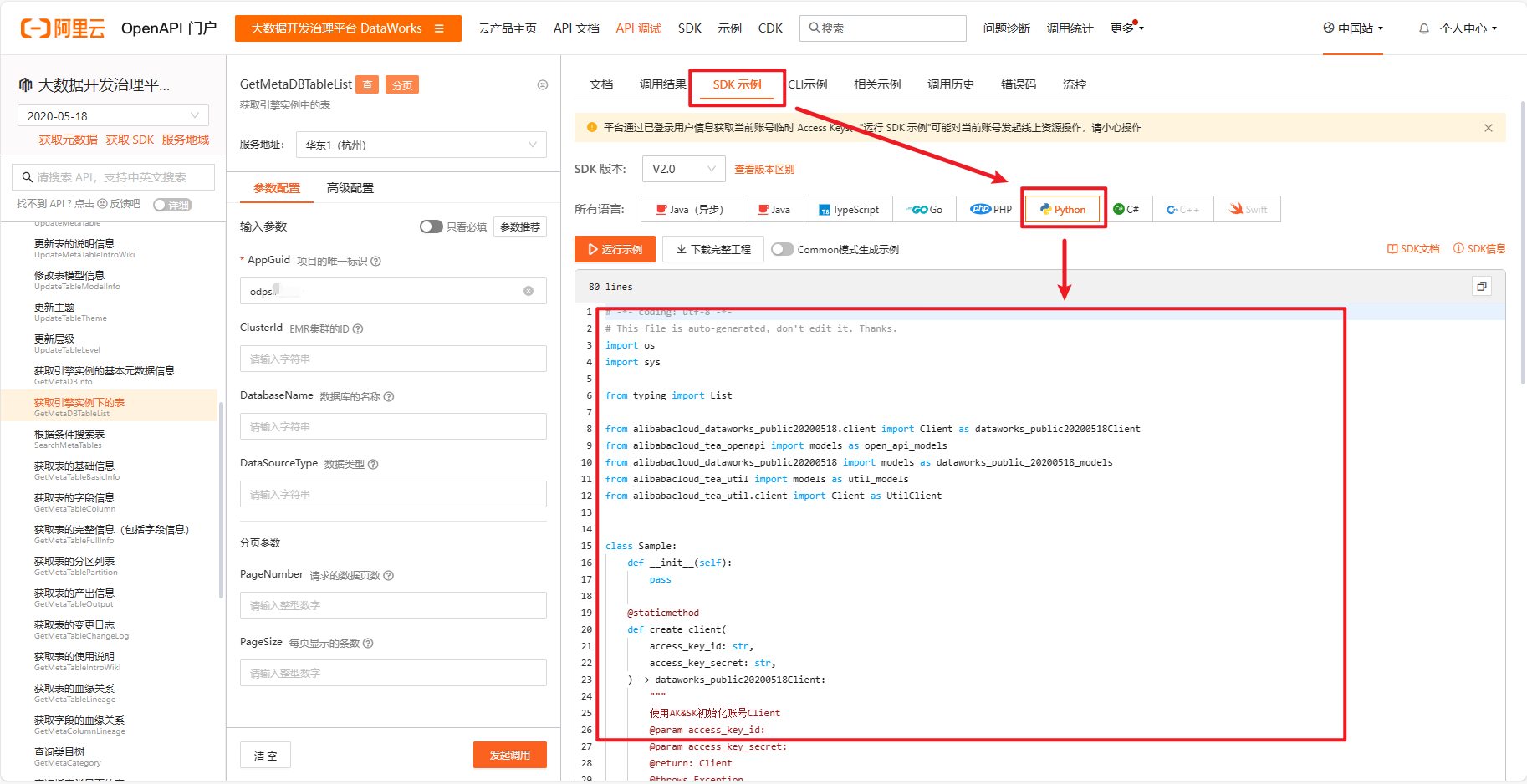
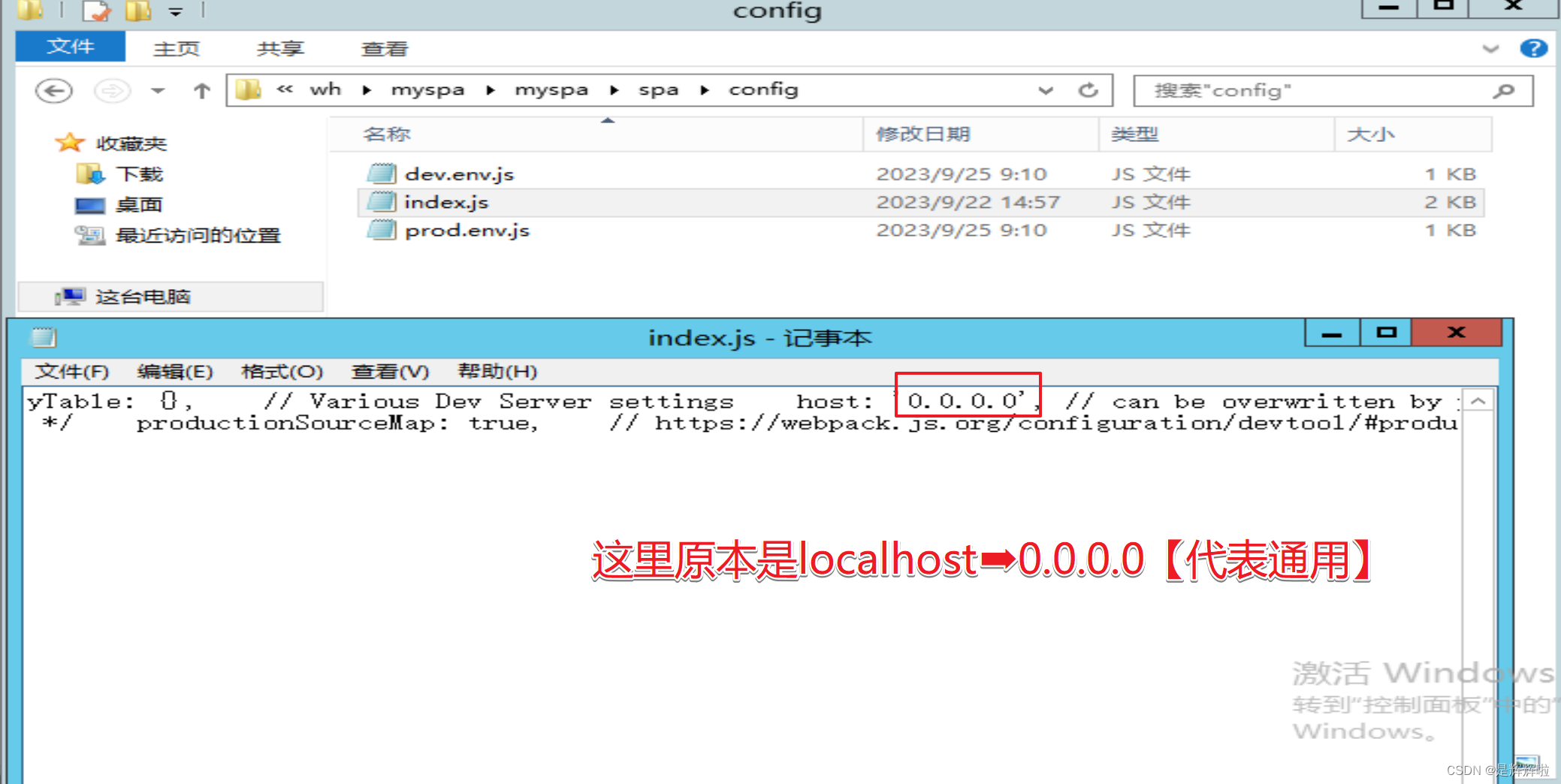
将其复制放到本地的 Python 编辑器中,此时还不能运行,还需要配置两个核心东西:运行环境 和 账户及密码(ACCESS_KEY_ID和ACCESS_KEY_SECRET)。
运行环境
点击右侧的【SDK 信息】,可以看到安装的命令:
pip install alibabacloud_dataworks_public20200518==4.7.2

打开终端/命令提示符,先安装上alibabacloud_dataworks_public20200518==4.7.2环境(大前提:已经安装了 Python,此处不展开)。
可能会由于网络问题出现超时的报错,多试几次,或者分不同的时间段试试。
WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'ReadTimeoutError("HTTPSConnectionPool(host=‘files.pythonhosted.org’, port=443): Read timed out.

账密问题
源码的第 45~47 行中介绍了怎么配置账密的方法:添加两个环境变量,一个命名为:ALIBABA_CLOUD_ACCESS_KEY_ID,对应的值是你的 ACCESS_KEY_ID,另外一个命名为:ALIBABA_CLOUD_ACCESS_KEY_SECRET,对应的值是你的 ACCESS_KEY_SECRET。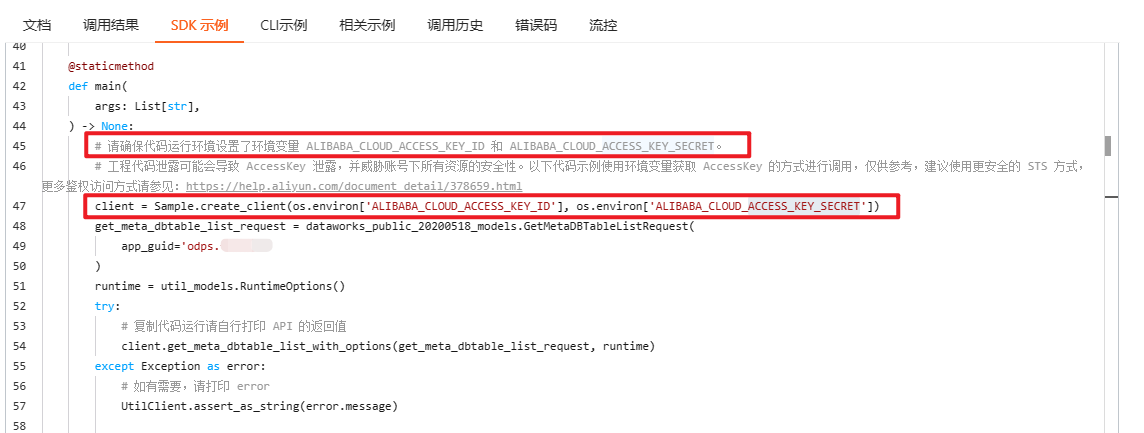
参考示例:
请求数据
两个准备工作做好之后,是不是就可以读取数据了呢?是的!不过可以读,但是读完没有保留下来。
直接运行源码,你会发现什么也没有……
这是因为源码没有打印(print())或者返回(return)API 返回的数据,官方给了提示,需要自行打印返回值。(见源码第 53 行)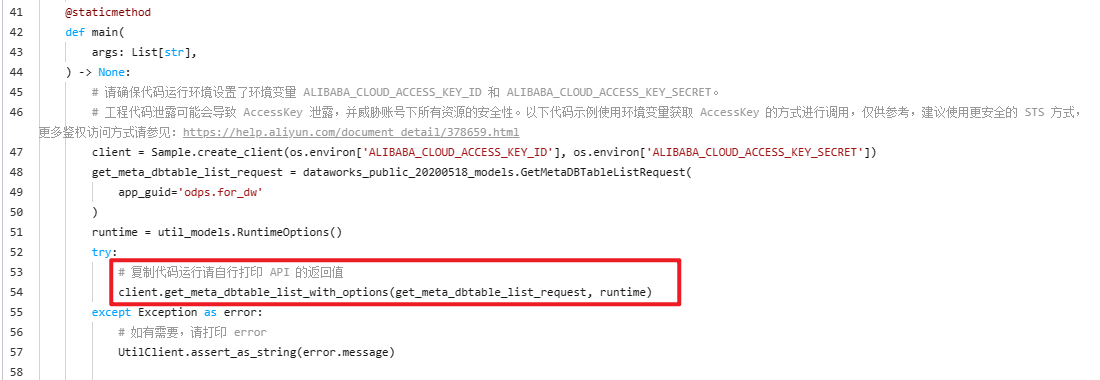
怎么改?print 一下,注意,由于返回的内容是一个对象,需要使用to_map()转换下对象,参考如下:
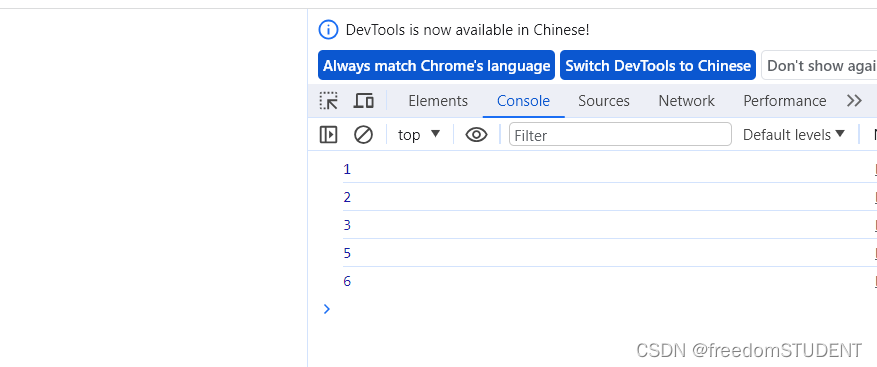
print(client.get_meta_dbtable_list_with_options(get_meta_dbtable_list_request, runtime).to_map())
再次运行就可以看到一个 字典结构的数据,和我前面“剧透”的那个截图的数据结构一致。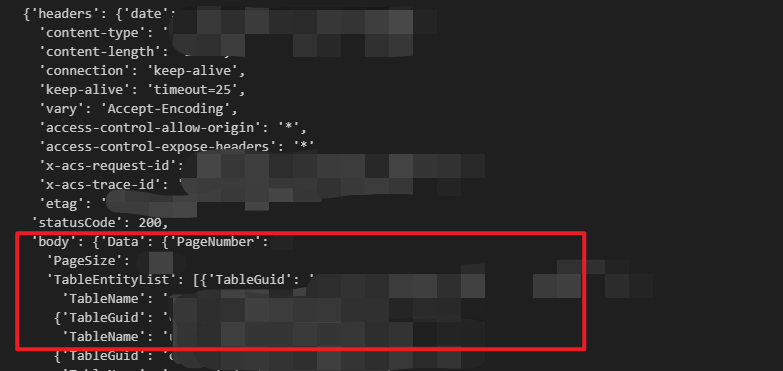
至此,恭喜你!已成功获取到你需要的数据。
进一步处理
尽管我们已经成功获取到数据,但目前仅获取了一页,最多只有100条记录。然而,在数据量比较大的情况下,我们需要进行多次调取。为提高效率,需要进一步完善代码,使程序能自动获取所有数据,同时保存每次调取的数据,以供后续分析和处理。
此处我加了一个for循环,并将数据临时存放在一个列表中,具体操作如下:
在class Sample中新增一个函数处理 body 的值,将 TableName 取出,然后返回。
@staticmethoddef gettable(response):TableInfos = response.to_map()['body']['Data']['TableEntityList']TableList = [table['TableGuid'] for table in TableInfos]return TableList
并修改main()方法,调用gettable()方法,将处理结果TableList返回。
@staticmethoddef main(args: List[str],) -> None:# 请确保代码运行环境设置了环境变量 ALIBABA_CLOUD_ACCESS_KEY_ID 和 ALIBABA_CLOUD_ACCESS_KEY_SECRET。# 工程代码泄露可能会导致 AccessKey 泄露,并威胁账号下所有资源的安全性。以下代码示例使用环境变量获取 AccessKey 的方式进行调用,仅供参考,建议使用更安全的 STS 方式,更多鉴权访问方式请参见:https://help.aliyun.com/document_detail/378659.htmlclient = Sample.create_client(os.environ['ALIBABA_CLOUD_ACCESS_KEY_ID'], os.environ['ALIBABA_CLOUD_ACCESS_KEY_SECRET'])get_meta_dbtable_list_request = dataworks_public_20200518_models.GetMetaDBTableListRequest(app_guid=args[0],page_size=args[1],page_number=args[2],)runtime = util_models.RuntimeOptions()try:# 复制代码运行请自行打印 API 的返回值# client.get_meta_dbtable_list_with_options(get_meta_dbtable_list_request, runtime)response = client.get_meta_dbtable_list_with_options(get_meta_dbtable_list_request, runtime)TableList = Sample.gettable(response)return TableListexcept Exception as error:# 如有需要,请打印 error# UtilClient.assert_as_string(error.message)response = UtilClient.assert_as_string(error.message)print(response)
最后在程序入库,修改传递的参数,并进行循环调用。
if __name__ == '__main__':# response = Sample.main(sys.argv[1:])TableList = []page_cnt = 10 #10*100,支持获取 1000 条记录for i in range(page_cnt):app_guid='odps.projectname';page_size=100;page_number=1+iresponse = Sample.main([app_guid,page_size,page_number])if response is None: #没有返回值,说明报错了。continueTableList.extend(response)print(TableList[:10])
到这里,所有的数据都获取到了,放在列表 TableList 中。
不过数据还没有保存下来,最后再通过 pandas 将数据写入 Excel 中(使用其他工具包也可以):
import pandas as pd
df = pd.DataFrame(TableList,columns=['tablename']);
df.to_excel('projectname_table.xlsx',index=False)
至此,数据获取大功告成!可以拿数据进行相关的分析了~~
小结
本文介绍了从 Dataworks 项目中获取所有表单字段的方法,基本步骤如下:
- 查看官方文档,了解约束和接口;
- 在线调试,并获取源码;
- 配置本地环境,安装 alibabacloud_dataworks_public20200518;
- 配置环境变量,新增两个环境变量ALIBABA_CLOUD_ACCESS_KEY_ID和 ALIBABA_CLOUD_ACCESS_KEY_SECRET,并将阿里云账号的 ACCESS_KEY_ID 和 ACCESS_KEY_SECRET 分别作为对应变量的值;
- 测试源码,打印数据,检验是否可行;
- 循环调用并保存数据。
整个流程比较繁琐,不过走一遍之后,便可以“一劳永逸”,因为其他的接口基本也是这个套路,改一些参数即可复用。