1 索引
索引是帮助数据库高效查询的一种数据结构:
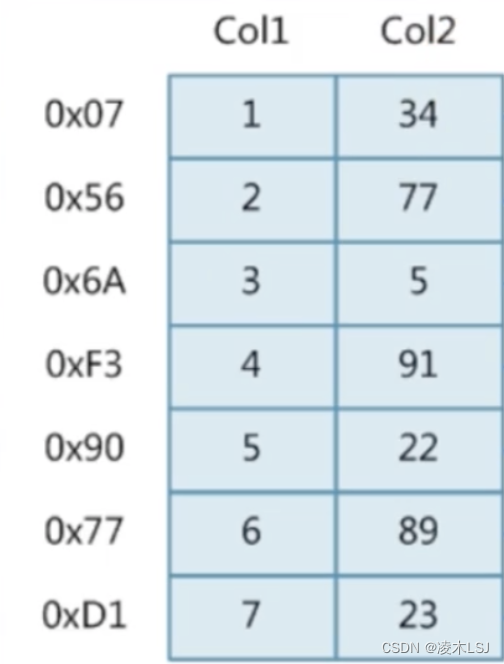
查询语句:select * from t where t.Col2 =89;
不加索引进行数据库查询时,每次都需要将所有数据遍历一次,直到找到符合目标的数据。
加上索引之后,可以根据数据结构不同,减少查询的次数,进而优化。
例如,以下语句创建一个新表,其索引由两列c2和c3组成。
CREATE TABLE t(c1 INT PRIMARY KEY,c2 INT NOT NULL,c3 INT NOT NULL,c4 VARCHAR(10),INDEX (c2,c3)
); 要为列或一组列添加索引,请使用以下CREATE INDEX语句:
CREATE INDEX index_name ON table_name (column_list) 要从表中删除现有索引,请使用以下DROP INDEX语句:
DROP INDEX index_name ON table_name二叉树
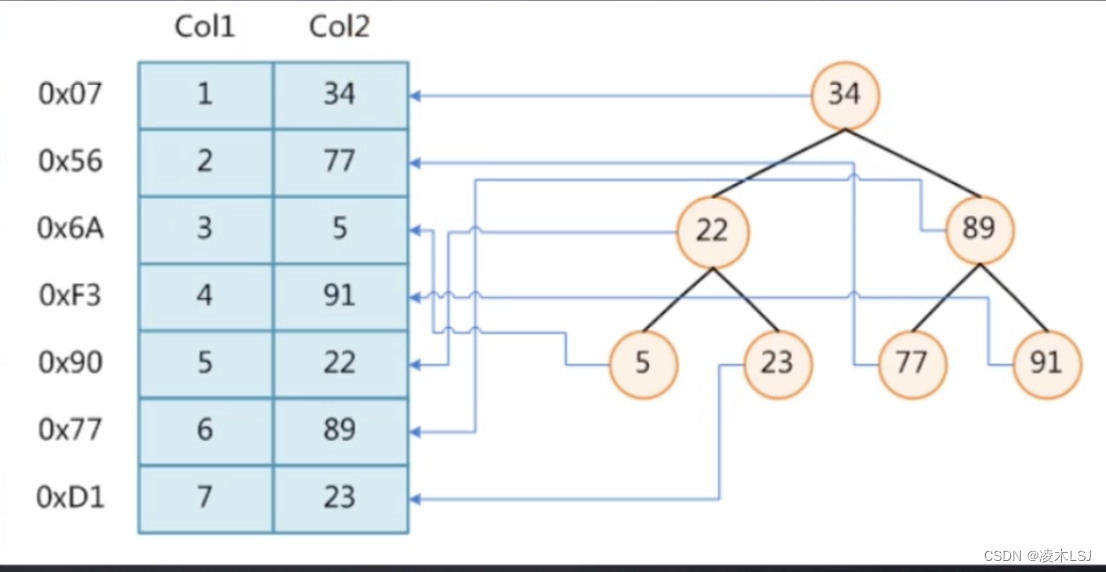
如果以二叉树的形式存储:key存储地址,value存储值。查询从跟节点开始的话,很快便能查找到。
二叉树的缺点是弱存储Col1数据,最终相当于存了一个链表。
红黑树
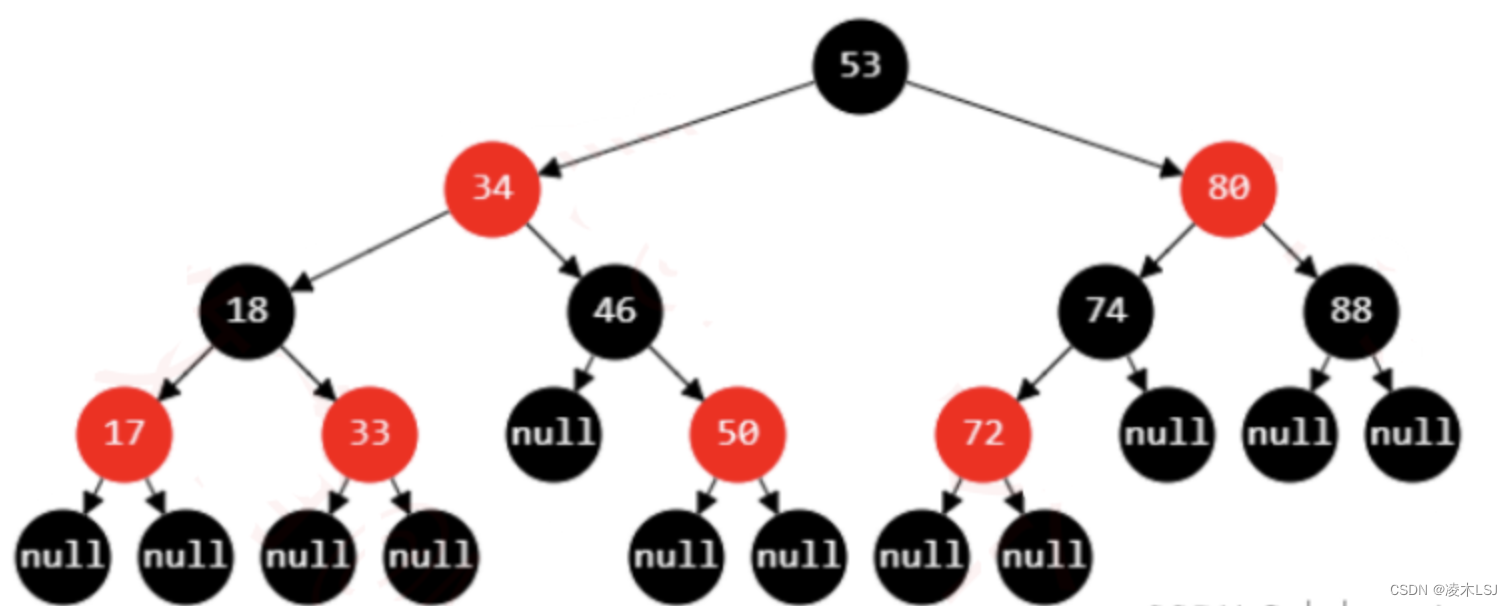
要求:
节点是红色或黑色,根是黑色。
所有叶子都是黑色。
从每个叶子到根的所有路径上不能有两个连续的红色节点。从任一节点到叶子节点的所有路径都包含相同数目的黑色节点。(黑高相同,叶子节点其实是哪些null节点)
也称为二叉平衡树,他会平衡左右分支的高度。(插入时都做为红色节点插入,出现不符合红黑树要求时就进行调整。)
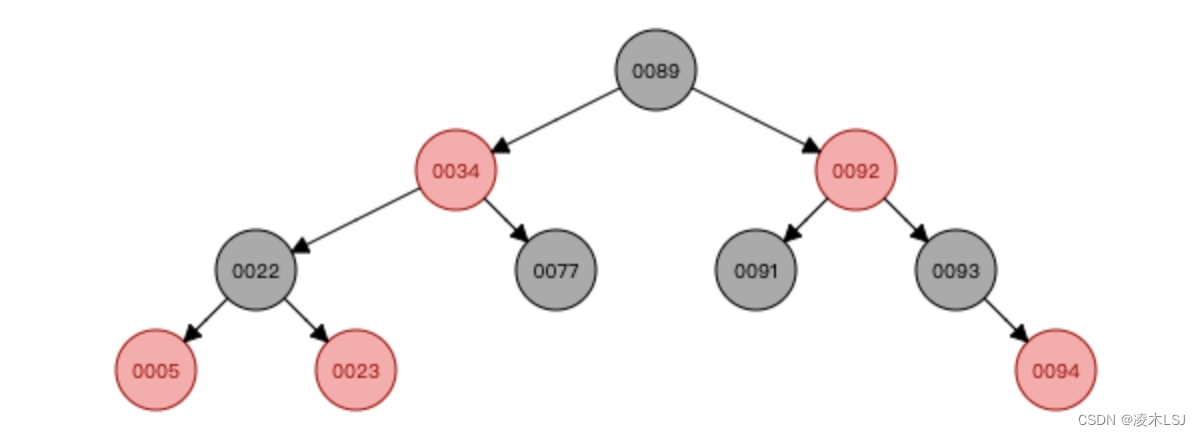
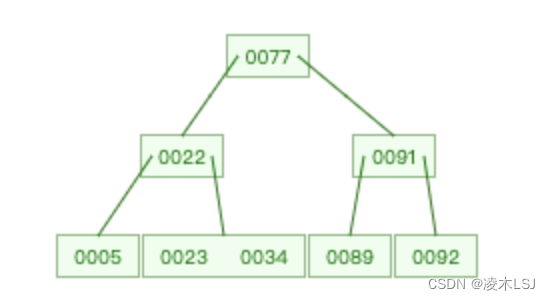
B-Tree
一颗m阶的B树定义如下:
1)每个结点最多有m-1个关键字。
2)根结点最少可以只有1个关键字。
3)非根结点至少有Math.ceil(m/2)-1个关键字。
4)每个结点中的关键字都按照从小到大的顺序排列,每个关键字的左子树中的所有关键字都小于它,而右子树中的所有关键字都大于它。
5)所有叶子结点都位于同一层,或者说根结点到每个叶子结点的长度都相同。
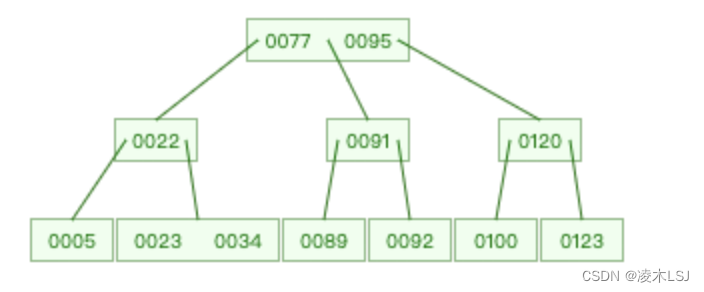
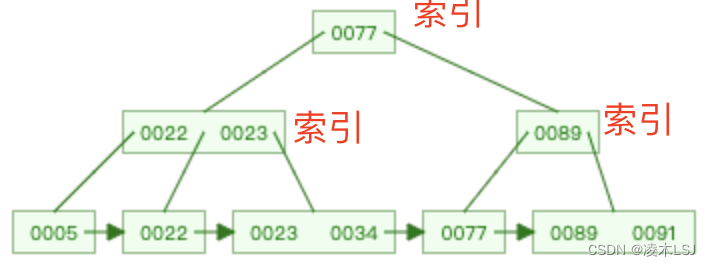
B+ Tree
MySQL索引底层:B+树
- 非叶子节点不存储data,只存储索引,可以放更多的索引
- 叶子节点包含所有索引字段
- 叶子节点用指针连接,提高区间访问的性能

B+树与B树的区别:
B+树在内部节点上不包含数据信息,因此在内存页中能够存放更多的key。
B+树的叶子结点都是相链的,因此对整棵树的便利只需要一次线性遍历叶子结点即可。
HASH

HASH查找的效率很高,但不支持范围查找(age > 10)。
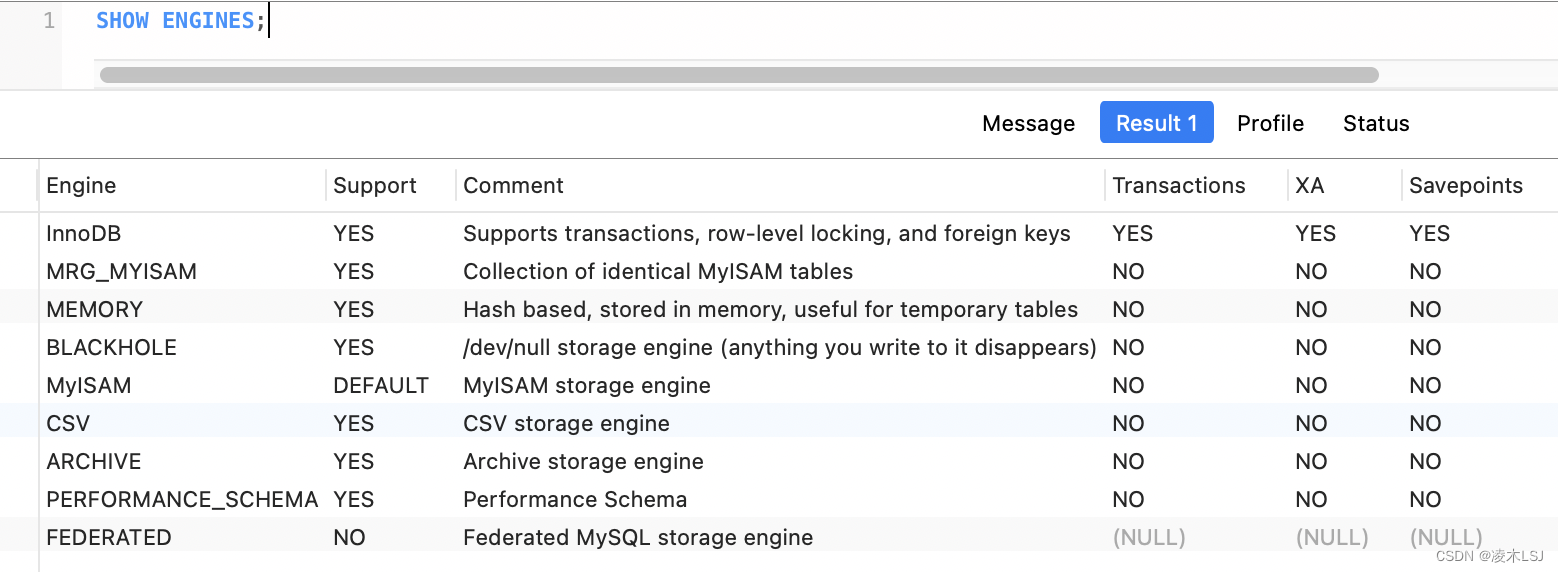
2 存储引擎
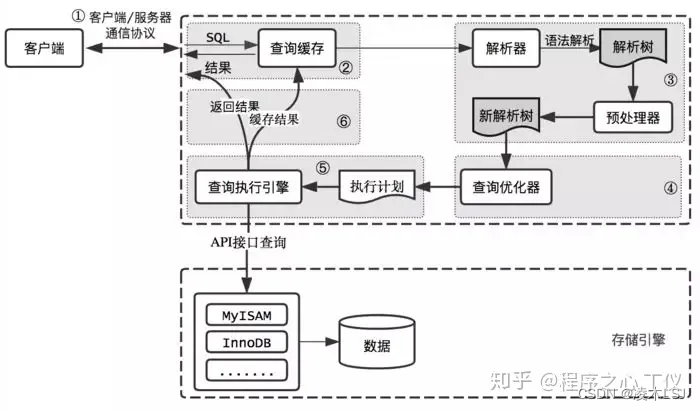
查询当前数据库支持的引擎,默认是MyISAM
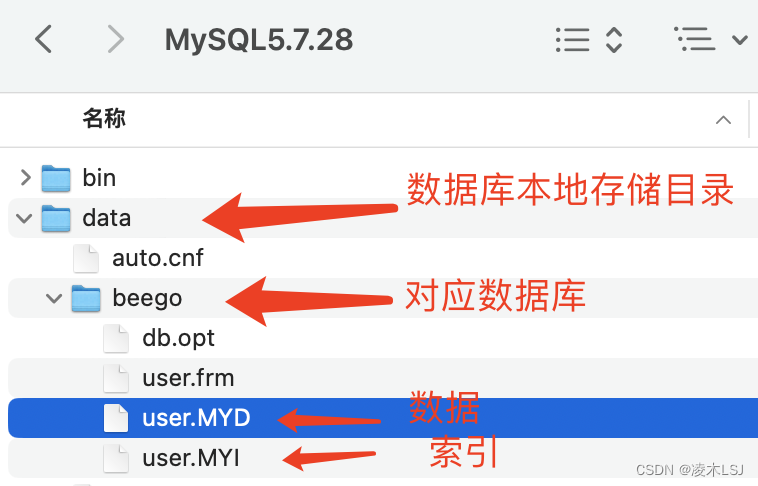
MyISAM存储引擎

使用这个存储引擎,每个MyISAM在磁盘上存储成三个文件。
(1)frm文件:存储表的定义数据
(2)MYD文件:存放表具体记录的数据
(3)MYI文件:存储索引
MyISAM拥有较高的插入、查询速度,但不支持事物。使用B+树进行存储,叶子节点存储地址。
支持数据的类型也有三种:
(1)静态固定长度表
(2)动态可变长表
(3)压缩表
InnoDB存储引擎

跟MyISAM一样也是B+树索引,不过InnoDB叶子节点存储的是完整列数据——聚集索引,所以InnoDB表创建需要创建主键,同时最好使用整型自动递增auto_increment。

InnoDB支持事务,存在着缓冲管理,通过缓冲池,将索引和数据全部缓存起来,加快查询的速度。
3 联合索引
MySQL可以在多个列上建立索引,这种索引叫做复合(联合)索引,是一种非聚簇索引。MySQL允许您创建一个最多包含16列的复合索引。
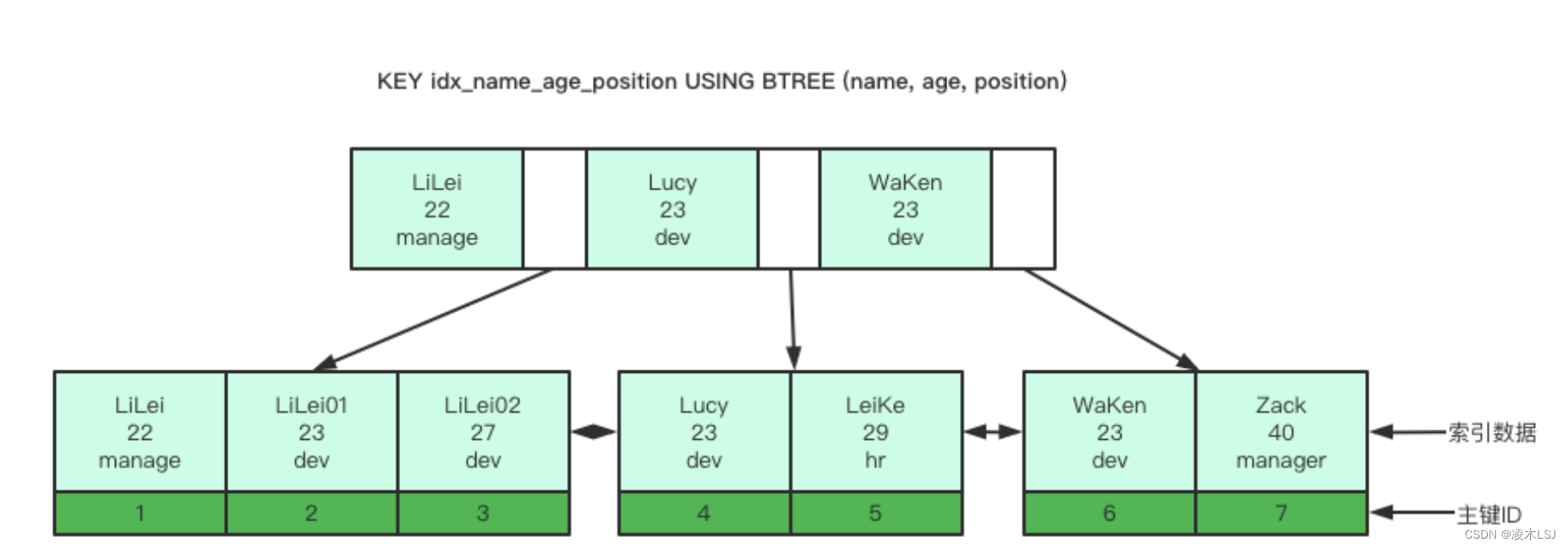
联合索引的特点
最左前缀原则: SQL 语句中用到了联合索引中的最左边的索引,那么这条 SQL 语句就可以利用这个联合索引去进行匹配,值得注意的是,当遇到范围查询(>、<、between、like)就会停止匹配。
最左匹配例子说明
create index table_name on test(a,b,c,d)
那么根据联合索引的最左匹配原则我们进行如下查询是会走索引的:
select * from table_name where a = '1';
select * from table_name where a = '1' and b = '2';
select * from table_name where a = '1' and b = '2' and c = '3';
select * from table_name where a = '1' and b = '2' and c = '3' and d = '4';
顺序可以随意,这种也是可以走联合索引的,Mysql有优化器会自动调整查询条件的顺讯跟索引顺序一致。比如:
select * from table_name where b = '1' and c = '2' and a = '3' and d = '4';
但是没有a,剩下的几个字段是都不会走索引!
但是,如果你在中间加入了模糊查询例如:
select * from table_name where a = '1' and b = '2' and c > '3' and d = '4';
那么就只有a,b,c会走索引,因为c用了模糊查询d是不会走联合索引的
实例演示
4个字段id name age sex,:
create table user(id int(2) primary key AUTO_INCREMENT,`name` char(8) not null,age int(2) not null,sex char(2) not null,index(`name`,age)
)ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8
给索引起个别名
create table user(id int(2) primary key AUTO_INCREMENT,`name` char(8) not null,age int(2) not null,sex char(2) not null,key name_index (`name`),key name_age_index (`name`,age)
)ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8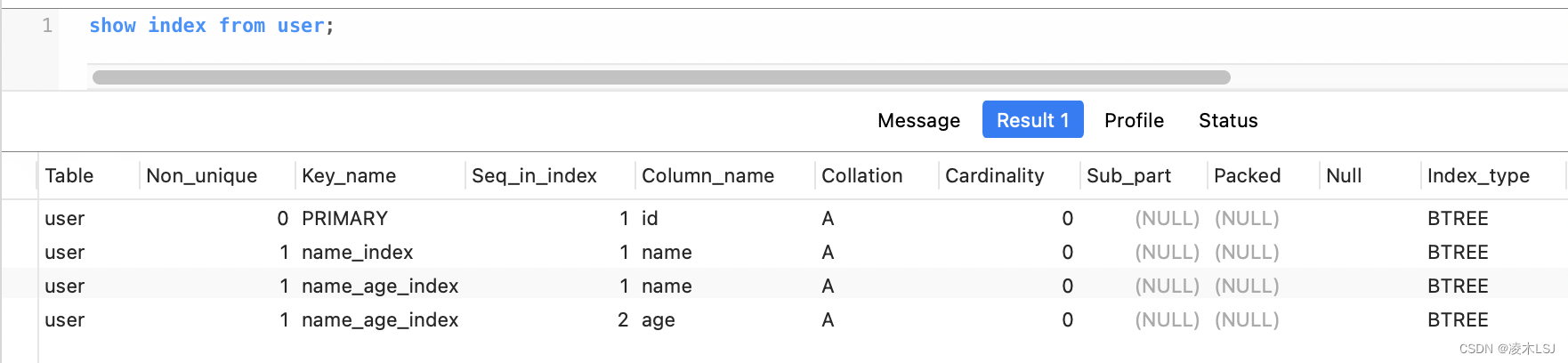
explain select * from user;
不使用索引,查询结果如下

explain select id from user where name = 'lihua' and age > 20;
依据mysql索引最左匹配原则,两个索引都匹配上,查询结果如下:

explain select * from user where id=4 and name = 'lihua';
查询结果如下:

explain select * from user where age = 22;
索引失效,最左匹配不生效,因为复合索引(name ,age)只有name确定时才会生效;

type列:

4 索引规约
注意:
mysql在使用不等于(!=或者<>)的时候无法使用索引会导致全表扫描
is null,is not null 也无法使用索引
like %在左边、在两边, mysql索引失效会变成全表扫描操作
查询条件导致类型转换会导致索引失效
【强制】业务上具有唯一特性的学段,即使是组合字段,也必须建唯一索引。
说明: 不要以为唯一索引影响了 insert 速度,这个速度损耗可以忽略,但提高查找速度是明显的。
【强制】超过三个表禁止 join。需要join 的字段,数据类型保持绝对一致;多表关联查询时保证被关联的字段需要有索引。
【强制】在varchar字段上建立索引时,必须指定索引长度,没必要对全字段建立索引,根据实际文本区分度决定索引长度。
说明: 索引的长度与区分度是一对矛盾体,一般对字符串类型数据,长度为 20 的索引,区分度会高达 90%以上,可以使用 count(distinct left(列名, 索引长度))/count(*)的区分度来确定。
【强制】页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。
说明: 索引文件具有 B+Tree 的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引,全模糊也会失效。
【推荐】如果有 order by 的场景,请注意利用索引的有序性。
order by 最后的字段是组合索引的一部分,并且放在索引组合顺序的最后。
【推荐】利用覆盖索引来进行查询操作, 避免回表。
覆盖索引(covering index ,或称为索引覆盖)即从非主键索引中就能查到的记录,而不需要查询主键索引中的记录,避免了回表的产生减少了树的搜索次数,显著提升性能。
【推荐】利用延迟关联或者子查询优化超多分页场景。
通过使用覆盖索引查询返回需要的主键,再根据主键关联原表获得需要的数据,尤其在大分页查询的场景下,可以提高查询效率。如下面第二条的执行速度要远远快于第一条SQL:
select * from table where xxx limit a,b;select * from table where id in (select id from table where xxx limit a,b);【推荐】 SQL 性能优化的目标:至少要达到 range 级别, 要求是 ref 级别, 如果可以是 consts最好。
说明:
- 全表扫描(All): 这是性能最低的级别。当查询没有使用索引或涉及大部分表数据时,通常会出现全表扫描。全表扫描意味着数据库系统需要遍历整个表来寻找匹配的行,这通常会导致性能问题。
- 范围扫描(Range): 范围扫描表示查询使用了索引,并且索引能够减少查询的数据量。这是性能提升的第一步,但仍需要扫描多个行来找到满足条件的数据。
- 索引引用(Ref): 当查询可以通过索引直接定位到唯一一行数据时,这被认为是性能更好的情况。通常,这需要在WHERE条件中使用主键或唯一索引,以便直接引用所需的数据行。
- 常数查找(Consts): 这是性能的最高级别。当查询可以直接定位到一个特定的数据行,而不需要进行任何扫描或比较时,性能最佳。这通常发生在使用主键或唯一索引来精确查找特定数据行的情况下。
【推荐】建组合索引的时候,区分度最高的在最左边。
【推荐】 防止因字段类型不同造成的隐式转换, 导致索引失效。
在执行SQL查询或操作时,MySQL会自动将数据类型转换为适当的类型,以便执行操作或比较。
- 比较操作符的隐式转换: 将一个整数和一个字符串进行比较时,MySQL可能会将字符串转换为整数以进行比较。
- 数据类型优先级: MySQL有一套规则来确定数据类型的优先级,用于隐式转换。通常,数值类型的优先级高于字符串类型。这意味着,如果涉及数值和字符串类型的比较,字符串类型通常会被转换为数值类型。
- 显式类型转换: 为避免隐式转换引发问题,应该尽量避免混合不同数据类型的比较。如果需要进行比较,可以使用显式的类型转换函数,如CAST()或CONVERT(),将数据类型显式转换为相同的类型。
SELECT id FROM sample WHERE id = CAST('1' AS SIGNED); -- 返回结果,显式将'1'转换为整数进行比较
SELECT id FROM sample WHERE name = CAST(5 AS CHAR); -- 返回结果,显式将5转换为字符串进行比较
5 事物
为了解决多事务并发问题,数据库设计了事务隔离机制、锁机制、MVCC多版本并发控制隔离机制、日志机制,用一整套机制来解决多事务并发问题。
5.1 事物特性
数据库中的事务(Transaction)是一组数据库操作,它被视为一个不可分割的工作单元,这些操作要么全部成功执行,要么全部失败,具有以下四个关键特性,通常被称为 ACID 特性:
- 原子性(Atomicity):事务是原子的,它要么全部执行成功,要么全部执行失败,没有部分执行的情况。如果事务的任何一部分失败,整个事务都将被回滚(撤销)到初始状态。
- 一致性(Consistency):事务将数据库从一个一致的状态转移到另一个一致的状态。这意味着事务执行后,数据库必须满足一组事先定义的规则和完整性约束,以保持数据的一致性。
- 隔离性(Isolation):隔离性确保并发执行的事务不会互相干扰。每个事务在看待数据时,就像它是唯一正在运行的事务一样,不会受到其他事务的影响。隔离性通常通过锁定或多版本控制等机制来实现。
- 持久性(Durability):一旦事务成功提交,其对数据库的更改是永久性的,即使系统崩溃或断电,数据库的状态也不会受到影响。持久性通过将事务更改写入持久存储介质(如磁盘)来实现。
数据库中的事物分为隐式事物(数据库自动提交)和显示事物(需要手动设置):
隐式事物(数据库自动提交):
- SELECT查询:一般情况下,SELECT查询语句通常是自动提交事务的,它们不会显式地启动或提交事务。
- INSERT、UPDATE和DELETE:这些写操作通常是自动提交事务的。
显示事物(需要手动设置):
需要确保一系列SQL操作要么全部成功,要么全部失败,你需要手动设置事务。例如多个INSERT、UPDATE、DELETE语句的组合,以及可能的其他操作。
- 可以使用BEGIN TRANSACTION或START TRANSACTION语句来明确开始一个事务。
- 在开始事务后,执行你需要在同一事务中执行的SQL操作。
- 如果所有操作都成功,你可以使用COMMIT语句来提交事务,使更改永久生效。
- 如果任何操作失败或发生错误,你可以使用ROLLBACK语句来回滚事务,取消操作并恢复到事务开始前的状态。
5.2 事物隔离级别
并发事务处理往往会带来一些问题,如:
脏写或更新丢失(Lost Update)
当两个或多个事务选择同一行数据修改,有可能发生更新丢失问题,即最后的更新覆盖了由其他事务所做的更新。
脏读(Dirty Reads)
事务A读取到了事务B已经修改但尚未提交的数据。
不可重复读(Non_Repeatable Reads)
事务A内部的相同查询语句在不同时刻读出的结果不一致。
幻读(Phantom Reads)
事务A读取到了事务B提交的新增数据,在同一个事务中进行相同查询两次,但第二次查询返回的结果集比第一次查询时不一样。
解决并发事物带来的问题,可以使用隔离级别。数据库管理系统(DBMS)通常支持多个隔离级别,如读未提交(Read Uncommitted)、读已提交(Read Committed)、可重复读(Repeatable Read)、串行化(Serializable)等。

查看当前数据库的事务隔离级别:
show variables like 'tx_isolation';
设置事务隔离级别:set tx_isolation = 'REPEATABLE-READ';
6 存储过程
存储过程(Stored Procedure)是在大型数据库系统中,一组为了完成特定功能的SQL 语句集,存储在数据库中,经过第一次编译后再次调用不需要再次编译,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来调用存储过程。
-- 创建存储过程
create procedure mypro(in a int,in b int,out sum int)
begin set sum = a+b; select sum;
end;call mypro(1,2,@s);-- 调用存储过程
select @s;-- 显示过程输出结果显示存储过程
SHOW PROCEDURE STATUS;
SHOW PROCEDURE status where db = 'userdb';
显示名称中包含“my”的存储过程
SHOW PROCEDURE status where name like '%my%';
显示存储过程“mypro1”的源码
SHOW CREATE PROCEDURE mypro1;
删除存储过程“mypro1”
drop PROCEDURE mypro1;最后,数据库的优化建议:
数据库优化维度有四个:硬件、系统配置、数据库表结构、SQL及索引。优化选择:
1、优化成本: 硬件>系统配置>数据库表结构>SQL及索引
2、优化效果: 硬件<系统配置<数据库表结构<SQL及索引
检查问题常用工具:
mysql
msyqladmin mysql客户端,可进行管理操作
mysqlshow 功能强大的查看shell命令
show [SESSION | GLOBAL] variables 查看数据库参数信息
SHOW [SESSION | GLOBAL] STATUS 查看数据库的状态信息
information_schema 获取元数据的方法
SHOW ENGINE INNODB STATUS Innodb引擎的所有状态
SHOW PROCESSLIST 查看当前所有连接session状态
explain 获取查询语句的执行计划
show index 查看表的索引信息
slow-log 记录慢查询语句
mysqldumpslow 分析slowlog文件的不常用但好用的工具:
zabbix 监控主机、系统、数据库(部署zabbix监控平台)
pt-query-digest 分析慢日志
mysqlslap 分析慢日志
sysbench 压力测试工具
mysql profiling 统计数据库整体状态工具
Performance Schema mysql性能状态统计的数据
workbench 管理、备份、监控、分析、优化工具(比较费资源)




![[论文笔记]GTE](https://img-blog.csdnimg.cn/img_convert/edb6a3de10038c00dadaaf3b0ab008f0.png)