ID3算法
假定当前样本集合D中第k类样本所占比例为pk,则样本集合D的信息熵定义为

信息增益

C4.5算法
ID3算法存在一个问题,就是偏向于取值数目较多的属性,因此C4.5算法使用了“增益率”(gain ratio)来选择划分属性

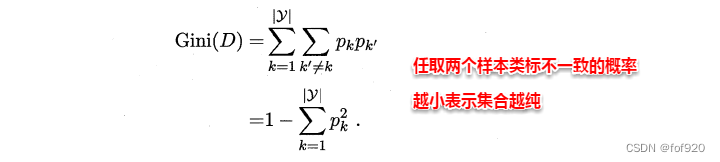
CART算法
使用属性α划分后的基尼指数为
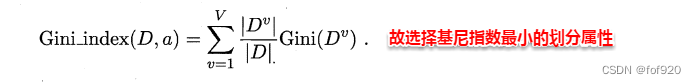
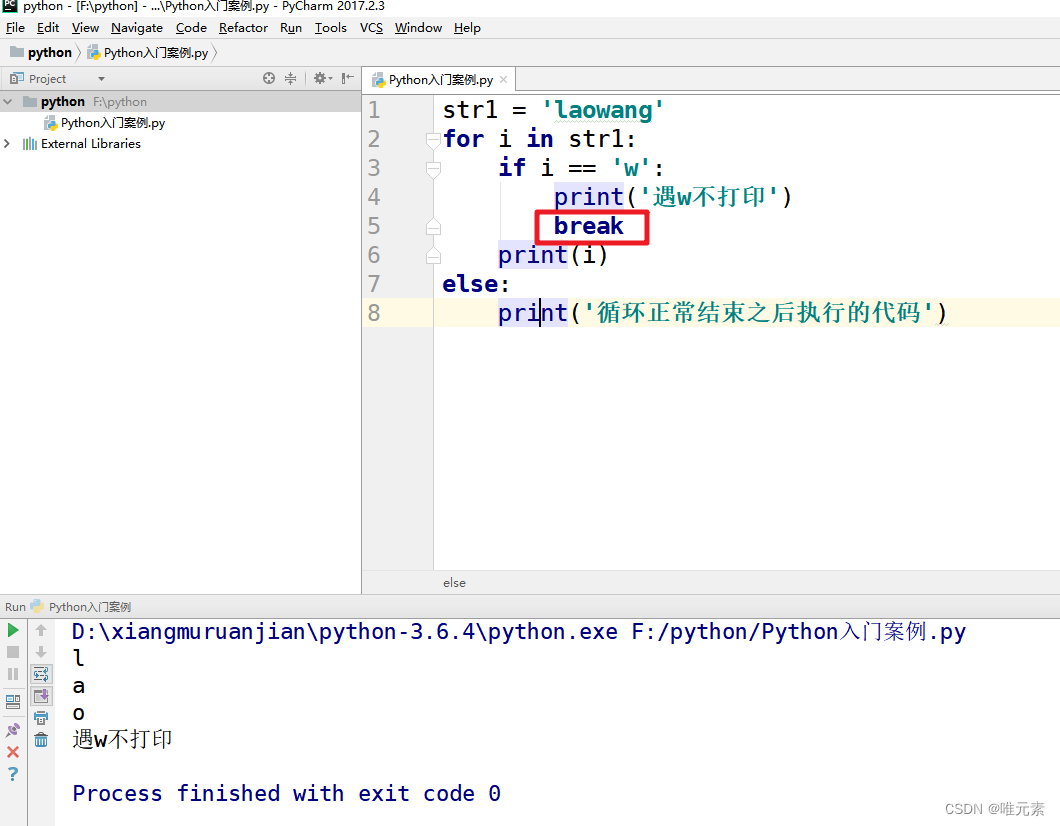
剪枝处理
* 预剪枝(prepruning):在构造的过程中先评估,再考虑是否分支。
* 后剪枝(post-pruning):在构造好一颗完整的决策树后,自底向上,评估分支的必要性。 评估指的是性能度量,即决策树的泛化性能。
连续值与缺失值处理
连续值
* 首先将α的所有取值按升序排列,所有相邻属性的均值作为候选划分点(n-1个,n为α所有的取值数目)。
* 计算每一个划分点划分集合D(即划分为两个分支)后的信息增益。
* 选择最大信息增益的划分点作为最优划分点。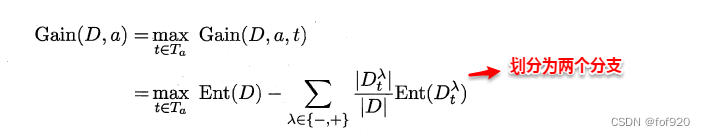
缺失值
假定为样本集中的每一个样本都赋予一个权重,根节点中的权重初始化为1,则定义:

通过在样本集D中选取在属性α上没有缺失值的样本子集,计算在该样本子集上的信息增益,最终的信息增益等于该样本子集划分后信息增益乘以样本子集占样本集的比重。即:

对于(2):若该样本子集在属性α上的值缺失,则将该样本以不同的权重(即每个分支所含样本比例)划入到所有分支节点中。该样本在分支节点中的权重变为:
![]()
多变量决策树
对于高维数据空间,决策树形成的分类边界有一个特点:轴平行,引入多变量决策树实现斜划分,分裂节点变为k1*x1+k2*x2+...








![[计算机提升] Windows系统各种开机启动方式介绍](https://img-blog.csdnimg.cn/5a0bcc425f87495383a6c5b8ecaacb26.png)