✅作者简介:大家好,我是 Meteors., 向往着更加简洁高效的代码写法与编程方式,持续分享Java技术内容。
🍎个人主页:Meteors.的博客
💞当前专栏: 神经网络(随缘更新)
✨特色专栏: 知识分享
🥭本文内容:【1.2】神经网络:神经元与激活函数
📚 ** ps ** : 阅读这篇文章如果有问题或者疑惑,欢迎各位在评论区提问或指出!

----------------------------------------------------- 目录 ---------------------------------------------------------
目录
一、介绍
1. 简介
神经元
激活函数
2. 作用
神经元
激活函数
二、常见激活函数分类及特点
阶跃函数
恒等函数
Sigmoid 函数
ReLU函数
Softmax函数
ELU函数
Swish函数
反正切函数
三、激活函数选择
非线性变换能力
梯度消失问题
计算效率
稀疏激活性
任务特性
实验和经验
四、激活函数改进
参数化激活函数
自适应激活函数
门控激活函数
带参数的激活函数
多阶段激活函数
五、 神经元和激活函数的组合
全连接层
卷积层
池化层
六、神经元和激活函数的优化
正则化
批归一化
残差连接
激活函数的选择
---------------------------------------------------------------------------------------------------------------------------------
一、介绍
1. 简介
神经元
人工神经网络是模拟人脑系统工作原理进行设计的计算模型。它包含很多(模拟)神经元,每个神经元接收来自其它神经元的输入,并通过激活函数处理这些输入,然后产生输出。
神经元通常由三部分组成:
- 输入层:接受来自其它神经元或外部输入的信号。
- 权重:每个输入信号都有一个权重与之对应,用于调节该信号对神经网络输出的影响程度。
- 激活函数:接收加权输入信号的总和,并将其映射到一个特定的输出范围内。
激活函数
神经元中,输入的的inputs通过加权,求和后,还会被作用一个函数,这个函数就是激活函数,它决定了神经元输出形式和范围。

2. 作用
神经元
每个神经元都有一个权重参数,用于调整输入数据的权重。神经元对输入数据进行加权求和,并将结果传递给激活函数。可以将它看作是神经网络中的基本单位。
激活函数
激活函数对于人工神经网络的学习,理解非常复杂和非线性函数来说具有重要的作用。它让神经元不会止步于线性的数学运算(没有激活函数的每层相当于矩阵相乘,就算增加若干层,无非也还是简单的矩阵相乘法罢了),而是让输入输出之间通过非线性形成更加复杂的关系,有效提高学习效率,使神经网络更加强大。

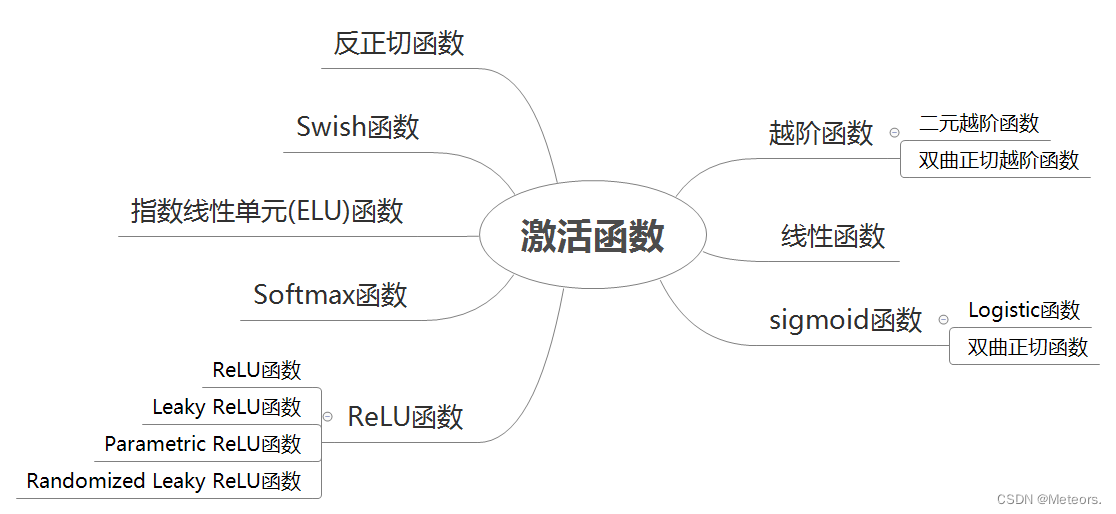
二、常见激活函数分类及特点
神经网络的激活函数通常是一种非线性函数,用于引入非线性特征,提高神经网络的表达能力,常见的神经网络激活函数分类:
阶跃函数
- 二元阶跃函数:将输入值映射为两个离散的输出值,通常是0和1。它在输入大于等于某个阈值时输出1,否则输出0。
- 双曲正切阶跃函数:一个连续的版本,将输入值映射到[-1, 1]的范围内。它在输入大于等于某个阈值时输出1,小于该阈值时输出-1。
恒等函数
- 一种简单的线性函数,它将输入值原样输出。在神经网络中,恒等函数常用于回归问题。
Sigmoid 函数
- Logistic 函数:一种常用的Sigmoid函数,将输入值映射到[0, 1]的范围内。它具有平滑的S形曲线,常用于二分类问题和概率估计。
- 双曲正切函数:将输入值映射到[-1, 1]的范围内。与Logistic函数相比,它的输出范围更广,适用于更广泛的问题。
ReLU函数
- 一种非常简单且广泛使用的激活函数,它将负值映射为0,并保持正值不变。这使得ReLU函数在处理大规模数据和深层网络时非常高效。
- Leaky ReLU函数:对ReLU函数的改进,当输入为负值时,它引入一个小的斜率,以避免出现“神经元死亡”问题。
- Parametric ReLU函数:Leaky ReLU的扩展版本,它允许斜率成为可学习的参数。
- Randomized Leaky ReLU函数:在Parametric ReLU的基础上引入了随机性,以增加模型的鲁棒性。
Softmax函数
- Softmax函数用于多分类问题,将一组实数映射到[0, 1]的范围内,并且所有输出值的总和等于1。它常用于输出层,将神经网络的原始输出转换为概率分布。
ELU函数
- 在负值区域引入了指数增长的特性,以解决ReLU函数在负值部分的限制。相比于ReLU,ELU函数在某些情况下可以提供更好的训练性能。
Swish函数
- 一种近似于ReLU的激活函数,它在正值区域具有ReLU的性质,在负值区域引入了平滑的曲线。Swish函数在一些情况下可以提供更好的性能。
反正切函数
- 将输入值映射到[-π/2, π/2]的范围内。它是一个平滑的、具有对称性的函数,常用于某些特定的问题领域。
三、激活函数选择
没有一种激活函数可以用于所有情况,通常情况下,激活函数的选择可以考虑下面几个方面:
非线性变换能力
激活函数应该具有一定的非线性变换能力,以便神经网络可以学习非线性模式和复杂关系。常见的非线性激活函数如sigmoid、tanh、ReLU等。梯度消失问题
某些激活函数(如sigmoid和tanh)在输入较大或较小时,梯度会接近于零,导致梯度消失的问题。为了避免这个问题,可以选择具有更好梯度传播性质的激活函数,如ReLU、Leaky ReLU、ELU等。计算效率
激活函数的计算效率也是一个考虑因素。一些激活函数(如sigmoid和tanh)在计算上相对较慢,尤其是在大规模神经网络中。相比之下,ReLU和其变种计算速度更快。稀疏激活性
某些激活函数具有稀疏激活性,即只有部分神经元被激活,这有助于减少网络的参数数量和计算复杂度。例如,稀疏自编码器常使用稀疏激活函数如稀疏ReLU。任务特性
不同的任务可能对激活函数有不同的要求。例如,对于二分类问题,sigmoid函数在输出层上常被使用,而对于多分类问题,softmax函数更为常见。实验和经验
激活函数的选择也可以基于实验和经验。根据具体的任务、数据集和网络结构,通过尝试不同的激活函数并进行实验评估,找到最适合的激活函数。
四、激活函数改进
改进激活函数主要是为了提高网络性能和效率,常见的激活函数改进方法有下面这些:
参数化激活函数
传统的激活函数是非参数化的,即没有可学习的参数。而参数化激活函数则引入了可学习的参数,使得激活函数可以根据数据进行自适应调整。例如,PReLU(Parametric ReLU)通过引入一个可学习的负斜率参数来改进ReLU,可以在一定程度上缓解ReLU的负数部分输出为零的问题。自适应激活函数
自适应激活函数是指根据输入数据动态调整激活函数的形状和参数。例如,AdaReLU(Adaptive ReLU)通过引入一个可学习的阈值参数,根据输入数据动态调整ReLU的形状,可以提高ReLU在不同数据分布下的表现。门控激活函数
门控激活函数是指通过引入门控机制来控制激活函数的输出。例如,GELU(Gaussian Error Linear Units)通过引入门控机制,可以在一定程度上缓解ReLU的负数部分输出为零的问题,并提高网络的性能。带参数的激活函数
带参数的激活函数是指在激活函数中引入额外的参数,以提高激活函数的表达能力和灵活性。例如,Swish激活函数通过引入一个可学习的参数,可以在一定程度上提高网络的性能。多阶段激活函数
多阶段激活函数是指将激活函数分为多个阶段,每个阶段使用不同的激活函数。例如,SELU(Scaled Exponential Linear Units)通过引入多个阶段的激活函数,可以提高网络的性能和稳定性。
五、 神经元和激活函数的组合
神经元是构成神经网络的基本单元,激活函数则是神经元中的一个重要组成部分。将神经元和激活函数组合起来,可以构建出不同类型的神经网络,包括全连接层、卷积层和池化层等。
下面简单介绍一下不同类型的层是如何组合的:
全连接层
在全连接层中,每个神经元都与上一层的所有神经元相连接。每个连接都有一个权重,用于调整输入的重要性。神经元的输入是上一层神经元的输出乘以对应的权重之和。然后,这个加权和会经过激活函数的处理,得到神经元的输出。卷积层
在卷积层中,神经元只与输入数据的局部区域相连接。每个神经元有一个局部感受野(receptive field),它会与输入数据的对应区域进行卷积操作。卷积操作将局部感受野的输入与权重进行乘积求和,并通过激活函数进行处理,得到神经元的输出。池化层
在池化层中,神经元的作用是对输入数据进行降采样,减少数据的维度和计算量。常见的池化操作包括最大池化和平均池化。神经元在池化层中没有可学习的参数,它的作用仅仅是对输入数据进行池化操作,并将池化后的结果作为输出。
六、神经元和激活函数的优化
实际中如果需要提高神经网络的性能和训练效果。通常会优化神经元和激活函数,常见方式包括正则化、批归一化和残差连接。下面是一些对它们的一些简单介绍:
正则化
通过在损失函数中添加正则项来控制模型的复杂度,避免过拟合。常见的正则化方法有L1正则化和L2正则化。
- L1正则化:将L1范数乘以一个正则化参数λ加到损失函数中,强制使得一些权重变为0,从而实现特征选择和稀疏性。
- L2正则化:将L2范数乘以一个正则化参数λ加到损失函数中,惩罚权重的平方和,使得权重值趋向于较小的值,防止过拟合。
批归一化
一种在深度神经网络中广泛使用的技术,通过对每一层的输入进行归一化来加速网络的收敛和提高泛化能力。
- 批归一化的操作是在每一层的输入上进行的,将输入减去均值后再除以标准差,使得输入的均值为0,方差为1。
- 批归一化不仅可以加速网络的收敛,还有正则化的效果,能够一定程度上避免过拟合。
残差连接
一种用于解决梯度消失和网络退化问题的技术,通过直接将某一层的输出与之前某一层的输入相加,使得信息能够更容易地传递。
- 残差连接可以有效地减少梯度消失的问题,使得网络能够更深更容易训练。
- 残差连接也有助于提高网络的表达能力,使得网络可以学习到更复杂的特征。
激活函数的选择
通过引入非线性,增加网络的表达能力。常见的激活函数包括Sigmoid、ReLU、Leaky ReLU、ELU等。
- Sigmoid函数:将输入映射到一个介于0和1之间的值,但它存在梯度饱和和输出不以0为中心的问题,不适合在深度神经网络中使用。
- ReLU函数:ReLU函数在正区间上输出输入值,而在负区间上输出0,解决了梯度饱和问题,但存在神经元死亡的问题。
- Leaky ReLU函数:在负区间上不是输出0,而是输出一个小的负数,解决了神经元死亡问题。
- ELU函数:在负区间上输出一个接近于0的值,解决了ReLU函数在负区间上不平滑的问题。
最后,
后续内容会陆续更新,希望文章对你有所帮助!