背景
本文基于Spark 3.1.1
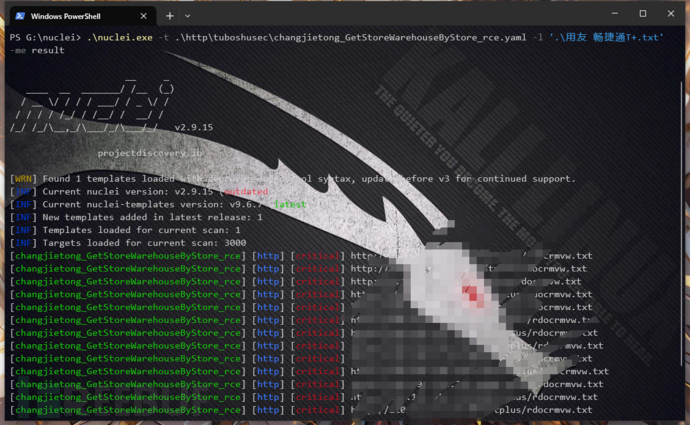
目前在做一些知识回顾的时候,发现了一些很有意思的事情,就是Spark UI中ShuffleExchangeExec 的dataSize和shuffle bytes written指标是不一样的,
那么在AQE阶段的时候,是以哪个指标来作为每个Task分区大小的参考呢
结论
先说结论 dataSzie指标是 是存在内存中的UnsafeRow 的大小的总和,AQE阶段(规则OptimizeSkewedJoin/CoalesceShufflePartitions)用到判断分区是否倾斜或者合并分区的依据是来自于这个值,
而shuffle bytes written指的是写入文件的字节数,会区分压缩和非压缩,如果在开启了压缩(也就是spark.shuffle.compress true)和未开启压缩的情况下,该值的大小是不一样的。
开启压缩如下:

未开启压缩如下:

先说杂谈
这两个指标的值都在 ShuffleExchangeExec中:
case class ShuffleExchangeExec(override val outputPartitioning: Partitioning,child: SparkPlan,shuffleOrigin: ShuffleOrigin = ENSURE_REQUIREMENTS)extends ShuffleExchangeLike {private lazy val writeMetrics =SQLShuffleWriteMetricsReporter.createShuffleWriteMetrics(sparkContext)private[sql] lazy val readMetrics =SQLShuffleReadMetricsReporter.createShuffleReadMetrics(sparkContext)override lazy val metrics = Map("dataSize" -> SQLMetrics.createSizeMetric(sparkContext, "data size")) ++ readMetrics ++ writeMetrics
dataSize指标来自于哪里
涉及到datasize的数据流是怎么样的如下,一切还是得从ShuffleMapTask这个shuffle的起始操作讲起:
ShuffleMapTask||\/
runTask||\/
dep.shuffleWriterProcessor.write //这里的shuffleWriterProcessor是来自于 ShuffleExchangeExec中的createShuffleWriteProcessor||\/
writer.write() //这里是writer 是 UnsafeShuffleWriter类型的实例||\/
insertRecordIntoSorter||\/
UnsafeRowSerializerInstance.writeValue||\/
dataSize.add(row.getSizeInBytes)这里的 row 是UnsafeRow的实例,这样就获取到了实际内存中的每个分区的大小,
而ShuffleMapTask runTask 方法最终返回的是MapStatus,而该MapStatus最终是在UnsafeShuffleWriter的closeAndWriteOutput方法中被赋值的:
void closeAndWriteOutput() throws IOException {assert(sorter != null);updatePeakMemoryUsed();serBuffer = null;serOutputStream = null;final SpillInfo[] spills = sorter.closeAndGetSpills();sorter = null;final long[] partitionLengths;try {partitionLengths = mergeSpills(spills);} finally {for (SpillInfo spill : spills) {if (spill.file.exists() && !spill.file.delete()) {logger.error("Error while deleting spill file {}", spill.file.getPath());}}}mapStatus = MapStatus$.MODULE$.apply(blockManager.shuffleServerId(), partitionLengths, mapId);}
shuffle bytes written指标来自哪里
基本流程和dataSize 一样,还是来自于ShuffleMapTask:
ShuffleMapTask||\/
runTask||\/
dep.shuffleWriterProcessor.write //这里的shuffleWriterProcessor是来自于 ShuffleExchangeExec中的createShuffleWriteProcessor||\/
writer.write() //这里是writer 是 UnsafeShuffleWriter类型的实例||\/
closeAndWriteOutput||\/
sorter.closeAndGetSpills() -> writeSortedFile -> writer.commitAndGet -> writeMetrics.incBytesWritten(committedPosition - reportedPosition) -> serializerManager.wrapStream(blockId, mcs) // 这里进行了压缩||\/
mergeSpills||\/
mergeSpillsUsingStandardWriter||\/
mergeSpillsWithFileStream -> writeMetrics.incBytesWritten(numBytesWritten)||\/
writeMetrics.decBytesWritten(spills[spills.length - 1].file.length())