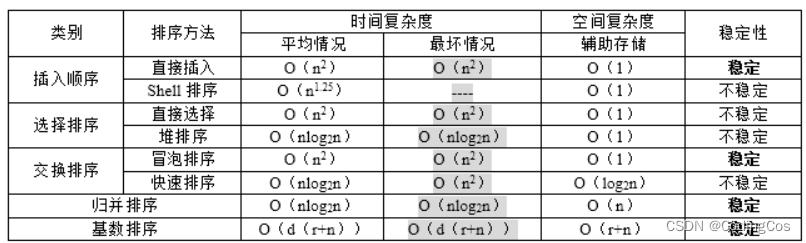
1.HTTP
当我们浏览网页时,地址栏中使用最多的多是https://开头的url,它与我们所学的http协议有什么区别?
http协议又叫超文本传输协议,它是应用层中使用最多的协议,
http与我们常说的socket有什么区别吗?
我们使用的网络可以分为(会话层和表示层可以忽略),每一层使用下一层的功能,并为上一层提供接口,我们经常听说的http协议就是应用层的协议,其中应用层协议包括ftp等等,而应用层还需要使用传输层的协议,http使用的就是tcp协议,http3计划使用udp协议。不过不管是tcp还是udp都是使用网络层的ip协议。不过传输层及以下层都是在操作系统内核中的,不利于我们使用,所以在用户态设计了socket接口来帮助我们使用tcp或者udp的网络协议。而http协议则是已经定义好解析标准的能让我们直接使用的协议。
1.1 http1.0
http1.0是个短连接,即每发一次请求,就建立一次连接,一次响应后就释放连接,这种方式简化了http的请求响应,但是却造成了重大的浪费:不能并行请求,每次请求都需要建立连接和释放连接,导致每次请求都需要三次握手和四次挥手。
1.2 http1.1
http1.1为了优化http1.0加入了很多东西。
①keep-alive(长连接):长连接,每个连接完成一次请求后先不关闭,在一定时间内可以发送多次请求。通过设置请求头Connection: keep-alive来实现
http1.1的长连接减少了三次握手和四次挥手的次数,不过需要前一次请求的响应返回后才能发送下一次请求,但是有个问题,在不释放连接的情况下如何才能判断请求已经结束,例如浏览器怎么知道数据传输完毕了?
- 通过 Content-Length 的长度信息,判断响应数据传输完毕。但是如果是大文件或者动态生成的数据呢?这些数据一开始可能不知道它们的长度,这时候就需要用到Transfer-Encoding: chunked请求头,这个请求头标识需要响应使用数据分块传输,并且每个块会有长度和数据,如果接收到长度为0的块标识数据接收完毕。http长连接 – http请求与连接的关系
②pipelining(管道化技术):虽然长连接减少了握手消耗,但是每次都要前一次请求完成之后才能发送下一次请求,管道化技术允许在一个请求没有响应之前发送多次请求。不过管道话技术要求响应必须按照请求发送的顺序返回,否则无法解析。存在队头阻塞。实际使用不多。
③增加并发连接数量与多域名:http1为了实现多并发,增加http连接的数量。
2.HTTPS
上面所说的http协议都是明文传输的,而且不会对应用数据和主机进行验证,这样即使数据被窃取和篡改我们也不得而知,所以为了保证http的安全,在它的基础上加了TSL/SSL安全协议。形成了我们所说的https协议。
先盗一张https验证的过程图

信息的安全传输解决三个问题,保密性,完整性与端点鉴别。
(a,b为传输方,c为攻击方)
1.保密性
http之所以不安全最大的原因就是使用明文传输,所以加密成了最大的问题,目前分为两大类加密算法(md5由于不能解密,不能算作加密算法)
①对称加密:DES(分组加密算法),AES(可以看作是DES的升级版)
②非对称加密:RSA、DSA
由于目前公钥加密算法的开销比较大,所以一般采用对称加密来保密信息。但是对称加密过程,密钥如何传输?这时可以使用公私钥来进行传输,因为公私钥使用公钥加密,私钥解密,所以只要是对方公钥加密的数据只有对方的私钥才能解密(私钥不公开,保证了传输过程中,即使数据泄露也没办法解密)对应图中④的过程:
note:不过又出现了一个问题,如何保证a得到的是b的公钥,而不是别人伪造的,这就需要下面的端点鉴别。

2.完整性
为了防止http数据在传输的过程中被篡改,完整性也是必须要考虑的问题,如何保证信息的完整性。
①发送方使用自己的私钥加密信息,接收方接收到后只能使用发送方的公钥解密
②使用信息摘要算法md5,sha生成散列加在正文数据的后面
第一种方法由于中间人没有发送方的私钥所以只能解密发送传输的数据,但是不能修改数据,因为一旦中间人修改数据,接收方利用发送方的公钥解密得到的数据就是错误的(信息中有专门的比特位用于验证信息的正确性),但是向前面说的公私钥加密开销比较大,所以不建议采用。
信息摘要算法是利用散列函数将信息映射成一段固定长的数据,由于该算法具有不可逆性而且不同的数据散列得到的数据基本不会相同。所以接收方得到数据后,将正文数据散列得到的数据于散列值比对,如果不同,则正文数据遭篡改。

3.端点鉴别
保证了数据的完整性和保密性后,最终的问题就是如何确定发送方的问题。如何不进行端点鉴别,就可能会出现中间人攻击的风险,如图
端点A和端点B通信,但是中间人C拦截了请求并冒充B和A通信(中间人C将自己的公钥发给A,让A误以为这是B的公钥),然后C作为客户端向端点B发请求(将A发送的报文解密后,用BC之间的共享密钥加密),这样A误以为是在和B进行https加密通信,但是其实中间人已经知晓所有的报文。那么如何知晓这是公钥是不是B的?
这就需要用到证书,证书是CA机构用自己的私钥加密后的得到的东西,用来证明公钥持有者的身份,证书包括以下东西:
- 持有者信息;
- 证书认证机构(CA)的信息;
- CA 对这份文件的数字签名及使用的算法;
- 证书有效期以及一些额外信息;
CA是权威的受信任的证书颁发机构,CA的公钥会内嵌在浏览器中。由于CA使用自己的私钥加密证书,所以可以保证证书不可以伪造。服务器在发送公钥的时候还要发送自己的证书,客户端解密该证书的时候将证书中的公钥与服务器发来的公钥比较,如果两者相同,则直接说明服务器发来的公钥是可靠的;如果不相同说明服务器端身份有问题。例如上图,中间人C将自己的公钥和证书发给端点A,A解密证书,发现证书中的网站信息与B不同,说明访问的端点不是B。
证书分为根证书和中间证书,我们我大部分的证书都是由中间CA机构颁发的,中间CA机构是受根CA机构信任的能够颁发CA证书的机构,这样就形成了一个证书链:客户端信任操作系统浏览器->浏览器信任根CA机构->根CA机构信任中间CA机构->中间CA机构信任中间证书。所以浏览器对于收到的多级证书,需要从站点证书开始逐级验证,直至出现操作系统或浏览器内置的受信任 CA 根证书。

2.1TLS的流程
https是在http的基础上添加tls协议保证安全性的,那么tls的过程又是如何呢?SSL/TLS工作原理以及几幅图,拿下 HTTPS
tls握手的过程:这里以比较熟知的RSA密钥交换算法为例说明,下面会说明DHE密钥交换算法,RSA算法主要分为以下几步:
①Client Hello:握手第一步是客户端向服务端发送 Client Hello 消息,这个消息里包含了一个客户端生成的随机数 Random1、客户端支持的加密套件(Support Ciphers)和 SSL Version 等信息。
②Server Hello:第二步是服务端向客户端发送 Server Hello 消息,这个消息会从 Client Hello 传过来的 Support Ciphers 里确定一份加密套件,这个套件决定了后续加密和生成摘要时具体使用哪些算法,另外还会生成一份随机数 Random2。注意,至此客户端和服务端都拥有了两个随机数(Random1+ Random2),这两个随机数会在后续生成对称秘钥时用到。
③Certificate:这一步是服务端将自己的证书下发给客户端,让客户端验证自己的身份,客户端验证通过后取出证书中的公钥。Server Key Exchange:如果是DH算法,这里发送服务器使用的DH参数。RSA算法不需要这一步。Server Hello Done:通知客户端 Server Hello 过程结束。
④Certificate Verify:客户端收到服务端传来的证书后,先从 CA 验证该证书的合法性,验证通过后取出证书中的服务端公钥,再生成一个随机数 Random3,再用服务端公钥非对称加密 Random3生成 PreMaster Key。
⑤Client Key Exchange:上面客户端根据服务器传来的公钥生成了 PreMaster Key,Client Key Exchange 就是将这个 key 传给服务端,服务端再用自己的私钥解出这个 PreMaster Key得到客户端生成的 Random3。至此,客户端和服务端都拥有 Random1+ Random2+ Random3,两边再根据同样的算法就可以生成一份秘钥,握手结束后的应用层数据都是使用这个秘钥进行对称加密。为什么要使用三个随机数呢?这是因为 SSL/TLS 握手过程的数据都是明文传输的,并且多个随机数种子来生成秘钥不容易被暴力破解出来。
⑥Change Cipher Spec(Client):这一步是客户端通知服务端后面再发送的消息都会使用前面协商出来的秘钥加密了,是一条事件消息。Encrypted Handshake Message(Client Finish):客户端将前面的握手消息生成摘要再用协商好的秘钥加密,这是客户端发出的第一条加密消息。服务端接收后会用秘钥解密,能解出来说明前面协商出来的秘钥是一致的。
⑦Change Cipher Spec(Server)和Encrypted Handshake Message(Server)与客户端的意思基本相同,使用前面的加密数据和加密之前的握手消息。
2.2https的优化
①会话复用tls
https为了安全引入了tls,但是一次连接无形中又增加了tls握手的部分,而且要命的是每次都需要将这个过程走一遍。为了复用TLS过程,我们引入了session id与sesson ticket机制 Session会话恢复SessionID&SessionTicket
session id是指一次tls握手完成后(第一次握手携带空的session id,服务器端就知道首次连接),服务器端生成session id返回,客户端存下,而且客户端会将生成的密钥存放在tls层中,接着下次连接时客户端携带此session id发起请求,服务器端收到后与内存中的session id比较,如果相同则使用上次的密钥。发送一个Change Cipher Spec报文后,就发送加密后的验证信息Finished。
session ticket与session id的过程差不多,但是session ticket为了解决有多台服务器的问题(服务器负载均衡导致两次请求到不同机器),所以session ticket是首次tls握手完成后服务端将加密协议,算法,参数等加密生成会话票据,服务器不存储,传给客户端存储,等客户端下次tls握手时,服务器验证票据并根据票据生成加密密钥,同时生成新的NewSessionTicket防止过期。


②前向安全算法
普通的密钥交换算法(rsa)需要使用公私钥传输加密密钥,如果私钥一旦泄露,那么中间人就可以通过私钥解密出加密密钥当前会话以及后续会话就不安全了。为了安全性,设计出了ECDHE(DHE)算法TLS/SSL 协议中的RSA、ECDHE、ECDH流程与区别。
上面那张图是RSA算法交换加密密钥的过程,下面的图则是ECDHE算法交换密钥的过程,ECDHE与DHE的过程相同,只是加密算法不同而已,下面以DHE算法流程为例说明:
(1):客户端发送client hello申请DHE加密。
(2):服务器允许DHE算法并生成加密使用的参数p,q,然后服务器生成随机数Xb作为自己的临时私钥,接着计算Pb = q^Xb mod p,最后发送sever hello,和server key exchange(包括Pb,p, q等加密参数)至客户端,Xb仅自己保存。
(3):客户端收到Pb后,生成自己的临时私钥Xa,接着计算Pa = q^Xa mod p,然后将Pa发送给服务器端,客户端发送client key exchange (包括Pa)至服务器,
(4):客户端计算Sa=Pb ^Xa mod p;服务器收到Pa后计算Sb= Pa^Xb mod p,DHE与ECDHE算法使用离散对数的概念保证了Sa与Sb的相同和高度保密性,所以密钥交换成功,最后双方通过S加解密数据。算法的加密过程可以查看DH密钥交换算法,DHE与DH不同的是DHE使用临时的私钥,这样可以保证即使一次通信密钥被破解,但是其他的通信仍是安全的。


③TFO(tcp fast open)TFO详解
传统的http通信需要先进性3次握手后才能发送数据,但是为了提高速度,一般在第三次握手时会携带应用数据,即使服务器没有收到,客户端也可以在超时后重发,但是每次http通信还是需要浪费1RTT的时间?
如图为了弥补这种浪费,人们设计出了TFO通信方式,在第一次通信时按照正常的3次握手来完成,同时第一次通信完成后服务器端会发送cookie给客户端,接下来的tcp通信客户端会发送cookie与应用数据,这个过程就和上面的tsl复用的思路一样。
- 如果cookie验证成功,则将应用数据上传给应用程序,并且服务器端会发送客户端syn和应用数据确认的ack;
- 如果cookie验证不成功,则服务器会将数据丢弃,然后只发送syn确认的ack,客户端通过服务器端的ack就可以知道cookie是否验证成功,如果不成功,则客户端第三次握手的时候再发送一遍应用数据,这就又回到了没有TFO的过程。

④hsts(HTTP Strict-Transport-Security)HSTS详解-CSDN博客
在访问网站的时候我们经常会直接敲域名www.baidu.com,而不会添加http://或者https://,而浏览器为了兼容http会先使用http询问是否能够进行https请求,如果浏览器只支持https会返回3XX状态码表示路径已经改变。然后浏览器才会使用新的https://开头的域名访问server,但是这样每次都会多发一次请求,而且还会造成中间人攻击
hsts就是为了解决一个问题,当访问过一次server之后,server会返回
Strict-Transport-Security: max-age=31536000; includeSubDomains,这个响应行表示如果浏览器接收到使用 HTTP 加载资源的请求,则必须尝试使用 HTTPS 请求替代。 如果 HTTPS 不可用,则必须直接终止连接;max-age是强制执行的时间,这里是一年,只要一年时间内浏览器再次访问这个域名,就可以再次强制执行一年;includeSubDomains表示当前域名及其子域名均开启HSTS保护;而且对于tls握手过程中有问题的证书也会禁止访问,hsts不仅提升了访问速度,而且增强了安全性。
TLS1.3
TLS1.3相对于之前的版本有了更加安全和高效的密钥交换流程,以下是截取tls1.3相比之前协议的改变
接下来具体说一下tls的哪些改变,详细的过程可以参考tls详解:
①1RTT的tls连接时间tls1.3还废除了rsa算法,因为它不支持前向安全,所以这里使用DHE算法作为讲解。
- 客户端发送client hello,支持的加密套件,(该作用和之前一样)、supproted_versions 拓展(包含自己支持的TLS协议版本号)、supproted_groups 拓展(表示自己支持的椭圆曲线类型)、key_share拓展(包含客户端利用supprot_groups中各椭圆曲线算法生成的public key)
- server 发送Server Hello,携带如下几个重要信息supproted_versions 拓展(包含自己从client的supproted_versions中选择的TLS协议版本号)、key_share拓展(包含自己选中的椭圆曲线,以及自己计算出来的公钥,接着发送Change Ciper Spec和Finished(与tls1.2相同)
tls1.3相比1.2的DHE算法减少了一个RTT,原因在于tls再client hello阶段就计算出了所有椭圆曲线算法的公钥供server选择。
②0RTT的会话复用
与上图tls1.2的会话复用相同,tls1.3的会话复用使用了相同的sessionid和ticket机制,也是1RTT的时间。但是tls1.3的会话复用还可以实现0RTT的连接,具体做法是:
- client hello中除发送上面的信息外还需要额外发送:psk_key_exchange_modes(psk的交换模式)、pre_shared_key拓展(将之前握手后发送的ticket处理之后形成的预共享密钥,简称psk,由于server可能会发送多次,所以可能会出现多个),early_data拓展(server是否支持0RTT的连接)以及应用数据。
- server hello会有多种情况,如果server验证ticket成功并且愿意0RTT连接,那么sever hello会发送Encrypted Extensions,里面携带了early data拓展表示自己会读取early data,说明0RTT成功;如果 server没有配置读取early data的选项,但是ticket验证成功,那么server就会忽略client发送的Application data,这样只表示会话复用成功,但不立刻接收数据,需要1RTT;如果ticket验证失败,则回到了上面tls1.3 1RTT建立连接的过程。



3.HTTP/2
HTTP/2是对之前HTTP协议的扩展,而非替代,HTTP 方法、状态代码、URI 和标头字段等这些核心概念不变,只是传输过程做了优化。http1为了实现请求的多并发,只能创建多个连接和域名分片上下手,但是六个浏览器都有自己的最大连接数,这种策略不能从根本上解决问题;而且创建多个连接也会增加握手消耗。
①ALPN协议:http2设计的时候为了考虑兼容性的问题,需要客户端对服务器发起一次询问,但是这样浪费一次RTT,为了减少浪费,客户端会在client hello时加上http询问请求,这样做不仅减少了浪费,还达到了h2强制使用tls的目的,确保通信安全,这种机制叫做ALPN(Application Layer Protocol Negotiation)
②二进制分帧:h2为了应对http1中的队头阻塞问题什么是http队头阻塞和tcp队头阻塞以及如何解决,设计出了二进制分帧技术,http1中的数据都是通过文本文本传输的,但是二进制结构更有利于数据处理,因为计算机只认识二进制,所以传输时不需要文本与二进制之间的转换;http1中的管道技术虽然支持反多次请求,但是响应必须按照FIFO的顺序返回,不能实现真正的并发,所以存在队头阻塞问题。
针对这个问题,h2将每个响应分成若干个帧序列,而每个帧序列都有流号,标记属于哪个响应,这样即使每个帧序列乱序到客户端,还是能够根据流id重新组装,解决了http方面的队头阻塞,真正实现多路复用。
例如下图,客户端请求first函数和second函数,响应便将每个函数分割成若干个帧序列,然后填写流id和长度(方便客户端组装)。其中响应头会生成headers frame,请求行会生成data frame(除此之外还有其他种类的帧负责标记帧的用途)+-----------------------------------------------+ | Length (24) | +---------------+---------------+---------------+ | Type (8) | Flags (8) | +-+-------------+---------------+-------------------------------+ |R| Stream Identifier (31) | +=+======================================================>=======+ | Frame Payload (0...) ... +---------------------------------------------------------------+
Length代表整个 frame 的长度,用一个 24 位无符号整数表示,头部的 9 字节不算在这个长度里。Type定义 frame 的类型,用 8 bits 表示。帧类型决定了帧主体的格式和语义,如果 type 为 unknown 应该忽略或抛弃。Flags是为帧类型相关而预留的布尔标识。标识对于不同的帧类型赋予了不同的语义。如果该标识对于某种帧类型没有定义语义,则它必须被忽略且发送的时候应该赋值为 (0x0)R是一个保留的比特位。这个比特的语义没有定义,发送时它必须被设置为 (0x0), 接收时需要忽略- Stream Identifier 用作流控制,用 31 位无符号整数表示。客户端建立的 sid 必须为奇数,服务端建立的 sid 必须为偶数,值 (0x0) 保留给与整个连接相关联的帧 (连接控制消息),而不是单个流
-Frame Payload是主体内容,由帧类型决定。帧类型主要有以下几种:
HEADERS: 报头帧 (type=0x1),用来打开一个流或者携带一个首部块片段DATA: 数据帧 (type=0x0),装填主体信息,可以用一个或多个 DATA 帧来返回一个请求的响应主体PRIORITY: 优先级帧 (type=0x2),指定发送者建议的流优先级,可以在任何流状态下发送 PRIORITY 帧,包括空闲 (idle) 和关闭 (closed) 的流PUSH_PROMISE: 推送帧 (type=0x5),服务端推送,客户端可以返回一个 RST_STREAM 帧来选择拒绝推送的流RST_STREAM: 流终止帧 (type=0x3),用来请求取消一个流,或者表示发生了一个错误,payload 带有一个 32 位无符号整数的错误码 (Error Codes),不能在处于空闲 (idle) 状态的流上发送 RST_STREAM 帧SETTINGS: 设置帧 (type=0x4),设置此连接的参数,作用于整个连接,设置流量控制窗口的大小PING: PING 帧 (type=0x6),判断一个空闲的连接是否仍然可用,也可以测量最小往返时间 (RTT)GOAWAY: GOWAY 帧 (type=0x7),用于发起关闭连接的请求,或者警示严重错误。GOAWAY 会停止接收新流,并且关闭连接前会处理完先前建立的流WINDOW_UPDATE: 窗口更新帧 (type=0x8),用于执行流量控制功能,可以作用在单独某个流上 (指定具体 Stream Identifier) 也可以作用整个连接 (Stream Identifier 为 0x0),只有 DATA 帧受流量控制影响。初始化流量窗口后,发送多少负载,流量窗口就减少多少,如果流量窗口不足就无法发送,WINDOW_UPDATE 帧可以增加流量窗口大小。note:数据优先级:
http2可以进行帧的多路复用,但是某些文件可能需要尽快处理?为此http2设计了数据帧优先级:通过帧之间的依赖关系和权重值来分配资源带宽。例如上图示例Ⅰ,可知帧AB处于同一级别,但是权重不同,所以帧A将分配到3/4的带宽,而帧B只分配到1/4的带宽。
示例Ⅱ说明,D是C的父级,所以先分配D的带宽,再分配C的带宽。
示例Ⅲ说明,先D的带宽,再分配C的带宽,最后根据权重分配AB的带宽。
Note:但是数据流依赖关系和权重只表示传输优先级,而不是一种必要行为,因此不能保证特定的处理或传输顺序。因为我们不希望在优先级较高的资源受到阻止时,还阻止服务器处理优先级较低的资源。③头部压缩:h2的另一个优势便是头部压缩,在大多数时候,我们请求或者响应的数据可能很少(例如ajax请求),但是同样需要传输各种请求头,尤其是cookie。这无疑给http带来负担,而头部压缩就是解决重复请求头发送的问题。为了方便,所以直接使用链接中的图片 HTTP/2 头部压缩技术介绍
正如图中所示,左边是请求头,中间分为上下两部分,上面是静态表(将常见的请求头编码),下面是动态表(请求响应时动态添加的内容,如cookies)(两个表使用连续的空间,所以画在了一起)右边是根据头部压缩得到的编码。头部压缩每个字节都表示不同的含义,根据字节前面的标识就可以分辨是哪种请求头。下面讲解一下头部压缩的编解码大致原理:
- 请求头在静态索引表或者动态表中的,如method:get或者path:/或者动态表添加的内容等,可以直接使用索引表示。索引表中的内容以1开始,剩下的七位表示索引表中的条目,这样只用1个字节就可以表示原来很多字节的内容。
0 1 2 3 4 5 6 7 +---+---+---+---+---+---+---+---+ | 1 | Index (7+) | +---+---------------------------+
- 请求头不在字典表中,但是需要添加到动态表中的,使用“01”开头,后面如果是“000000”,说明请求头参数名不在字典中,否则可以根据索引值在静态或者动态表中找到条目。接着后跟的字节标识请求头参数值,H为1表示使用哈夫曼编码,否则表示使用字符串编码。如下图选中的字节“0110000”表示不在表中,但是请求头参数名在字典中,为32表示cookie;剩下的字节“10011100”表示参数值使用哈夫曼编码,长度是28,而开头字母u的哈夫曼编码表示为“101101”,正好与接下来的序列相符,这里我们看出头部压缩的好处。
字符串的哈夫曼编码可能不是以整八位比特位结束的,这就需要在哈夫曼编码的最后添加“EOS(填充1)”结束标记。(哈夫曼编码是根据各字符经常使用频率而创造的序列,可以减少编码量,如字符a需要使用1个字节,但哈夫曼编码“00011”即可表示它),一般我们也会看到十六进制表示的请求头,这是由二进制编码转换而来的。哈夫曼编码表//请求头的参数名在字典中,但是参数值不在表中0 1 2 3 4 5 6 7 +---+---+---+---+---+---+---+---+ | 0 | 1 | Index (6+) | +---+---+-----------------------+ | H | Value Length (7+) | +---+---------------------------+ | Value String (Length octets) | +-------------------------------+ //请求头的参数名和参数值都不在表中0 1 2 3 4 5 6 7 +---+---+---+---+---+---+---+---+ | 0 | 1 | 0 | +---+---+-----------------------+ | H | Name Length (7+) | +---+---------------------------+ | Name String (Length octets) | +---+---------------------------+ | H | Value Length (7+) | +---+---------------------------+ | Value String (Length octets) | +-------------------------------+
- 请求头不在字典中,但是不添加到动态表中,使用“0001”开头,大致过程与第二种情况相同。
//请求头的参数名在字典中,但是参数值不在表中0 1 2 3 4 5 6 7 +---+---+---+---+---+---+---+---+ | 0 | 0 | 0 | 1 | Index (4+) | +---+---+-----------------------+ | H | Value Length (7+) | +---+---------------------------+ | Value String (Length octets) | +-------------------------------+ ///请求头的参数名和参数值都不在表中 0 1 2 3 4 5 6 7 +---+---+---+---+---+---+---+---+ | 0 | 0 | 0 | 1 | 0 | +---+---+-----------------------+ | H | Name Length (7+) | +---+---------------------------+ | Name String (Length octets) | +---+---------------------------+ | H | Value Length (7+) | +---+---------------------------+ | Value String (Length octets) | +-------------------------------+
但是需要说明的是,如果请求头参数名在字典中的索引很大,比如1234怎么办,我们这种结构只能存储最大值为15的索引?这就需要用到前缀编码,以第三种情况众多的四位前缀编码为例,存储x = 1234过程,这个过程与十进制转换二进制的过程有些相似:
- 首先将最大值1111,填入后四位;那么x = x-15 = 1219;
- 接着需要将剩余的部分填入接下来的字节中,计算x = x%128=67(为什么使用128而不是256,因为需要一位标识这个数据是否结束,因为数据可能需要填入多个字节中,为0则表示数据结束。)需要将67填到下个字节的剩下七位中。接着计算x = x/128=9;
- x = 9<128,数据计算结束,将下个字节的首位置零(标识这个数据一表示完成),剩下7位填入9;得到的序列就是 0001 1111,1100 0011,0000 1001。解码时可以将后两个字节去除首部颠倒顺序排列,再加上1111就可以得到1234。 计算代码如下。
//编码过程 if I < 2^N - 1, encode I on N bits elseencode (2^N - 1) on N bitsI = I - (2^N - 1)while I >= 128encode (I % 128 + 128) on 8 bitsI = I / 128encode I on 8 bits //解码过程 decode I from the next N bits if I < 2^N - 1, return I elseM = 0repeatB = next octetI = I + (B & 127) * 2^MM = M + 7while B & 128 == 128return I-还有一种请求头不在表中,但是绝对不添加索引的首部;这种和第三种情况相同,唯一不同的是,这种情况会作用于网络中的每一跳(每一个路由设备)如果中间通过代理,代理必须原样转发不能另行编码。而上一种首部只是作用当前跳,通过代理后可能会被重新编码
④Server Push
在http1中,上一个响应发送完了,服务器才能发送下一个请求,但在http2里,可以将多个响应一起发送。例如在一个html文件中有个多js,css文件,为了快速解析页面,可以直接向客户端推送js文件,从而减少客户端请求的时间。http2多路复用的好处:
- 连接少,握手成本就少。
- 压缩比高,因为一个连接上积累的信息很多,压缩比会更高。
- 更好地利用 TCP 的特性,为什么?因为 TCP 的拥塞控制流量控制都是基于单个连接的,如果使用很多个连接,特别是在网络拥塞的情况下,会放大拥塞的系数,加剧网络拥塞,如果使用一个连接,当得知该窗口已经拥塞,响应很慢便不会继续发送了,但是多个连接的情况,可能大家都会尝试发一下,而导致加剧网络拥塞。
- 使用更少的域名,这也是为了更好地使用连接,并且减少了 DNS 解析时间。
http2存在的缺陷:http2虽然实现了多路复用,但是并没有解决tcp方面的队头阻塞。而且,同一个连接内多个流传输,可能会导致RTT时间变长,相比http1容易出现超时重传;再者,h2适合于大量冗余的请求,对于少量请求并没有太大优势。




4.HTTP3
前面提过http2虽然解决了http方面的队头阻塞,但是并没有解决传输层的队头阻塞(tcp层),那么tcp层的队头阻塞是什么意思?
- tcp是可靠的传输层协议,所以我们的http以及ftp都是用tcp作为传输层协议,但是也是因为tcp的可靠传输造就了tcp的队头阻塞问题;因为tcp为了保证数据准确且有序的发送到接收端,使用了滑动窗口协议。
滑动窗口协议:发送端会为发送的数据标上序列号(便于接收端组装处理),接收端接收只有接收到按需到达的数据后才能交给应用层;如果有发送报文丢失,那么未按序列到达的报文只能等待之前序列号的报文到达才行。例如,发送依次发送1,2,3,4,5,6六段报文,到达顺序为1,2,4,3,6,5报文丢失,那么12报文按序到达可以直接交给应用层处理,4报文需要等到3报文到达后才能交给应用层,6报文属于未按序列到达,此时只能等到5报文超时重传才能向上传递。所以,即使http2使用流分帧技术,但是tcp层还是需要一个个的按序传输才行。除此之外,为了提高了网络传输的性能,人们开始研究新型的http协议。如果还从tcp协议入手,不仅不能解决http2的队头阻塞,还有一些其他的问题:
- 中间设备的僵化,一些路由器、网关或者防火墙默认tcp协议的端口和选项导致tcp无法出现使用新的格式。
- 操作系统的僵化,tcp协议栈是属于内核的一部分,我们只能使用了socket接口。一旦修改tcp,可以需要修改操作系统的代码。
- 握手时间长,tcp建立连接总是需要三次握手,四次挥手,这样无形中增加了浪费。
udp可以很好的避开上面的所有问题,所以新的http3协议使用udp为传输层协议,但是udp是不可靠的传输层协议,所以就需要自己实现tcp的流量控制和拥塞控制。
4.1http3还是比http2的优点
- 更快的连接时延
http1一次tcp握手,两次tls握手,至少需要三次握手才能发送数据;TLS1.3可以实现两次握手就发送数据;到后来的TFO+TLS1.3的session reuse才能真正实现0RTT的握手连接,但是这需要通信双发都支持TFO,TLS1.3而且是session复用的情况下。
而udp不需要握手就可以直接发送数据,再加上支持tls1.3,所以可以实现1RTT或者0RTT的连接。
- 没有tcp的队头阻塞
没有使用tcp,自然也不会有tcp的队头阻塞,但是如何保证数据有序到达呢?
http3使用http2中流的思想,在应用层和传输层加了个quic协议层,将从http3应用层收到的数据封装成quic帧,每帧都有流id和字节长度。这样接收到数据后就可以根据流id和字节长度重新拼接数据。同样的,一个连接可以建立多个流,而每个流可都以不影响的发送各自的帧,因为udp不需要整个字节序列按序达到就可以交给quic层,而quic则可以根据流id组装数据。

- 加密的报文头部
tcp使用tls虽然能加密报文数据,但是tcp首部没有加密。所以在传输过程中很容易被中间网络设备篡改,注入和窃听。比如修改序列号、滑动窗口。quic 的 packet 可以说是武装到了牙齿。除了个别报文外所有报文头部都是经过认证的,报文 Body 都是经过加密的。
- 连接迁移
什么叫连接迁移?就是当网络环境发生变化时,这条连接不中断。一般我们使用手机上网时,可能会因为移动或者切换网络而导致IP地址变化,这样我们又需要与原来的服务器进行重新连接。而我们的请求可能也需要重发。又比如,我们使用一个公共ip上网时,可能会因为竞争需要重新进行端口映射。这是因为传统网络使用四元组(源ip,目的ip,源端口,目的端口)来辨别连接,http3不使用四元组,而是用conntion id来标识连接。即使ip或者端口发生变化,连接也不会中断,上层逻辑不感知变化。
4.2拥塞控制 [QUIC-流量控制]
拥塞控制是为了防止过多的数据进入网络导致网络阻塞,网络数据丢失率高(例如中间设备未能及时的接收数据包而丢弃)
http3的udp并没有完成拥塞控制算法,这就需要我们自己实现与拥塞控制相同的功能。虽然工作量多了,但是现在设计的拥塞控制功能可以使用最新的算法,弥补或者避免过去tcp的缺陷。
①可插拔的算法设计:
- 我们可以在用户层实现自己的拥塞控制算法,可以很方便的升级和修改配置,不需要改变内核部分。
- 不同应用程序的不同连接可以配置不同的拥塞控制算法,更精准有效。
②避免RTT计算的歧义
RTT是一次数据在客户端接收端往返的时间,它会根据上次数据的往返时间(从发送数据开始到接收到数据的Ack为止)不断更新。但是如果发生重传,原来数据的Ack与重传数据Ack的序列号相同,这就会在计算RTT的时候就会发生歧义。无论以哪个计算都不能确定RTT一定是准确的。为了解决这个问题,http3在每个quic帧上都添加了自增的Packet Number,这样就可以区分到底是哪个数据的ack了。但是单纯依靠严格递增的 Packet Number 肯定是无法保证数据的顺序性和可靠性。QUIC 又引入了一个 Stream Offset 的概念。quic帧可以依靠 Stream 的 Offset 来保证应用数据的顺序,即使发生重传,帧也可以根据offset进行排序。
④更多的sack块
如果帧没有按序到达,为了减少重传的帧序列,会在tcp帧的首部增加已经到达的帧的范围,例如,1,2,3,4,5,如果1245到达,3缺失,在发送ack帧时就可以选择发送2的确认ack以及4至5的sack。这就告诉发送端帧2收到,可以从帧3发送,但是帧45已经收到,不需要再发送了。原来的tcp首部由于长度的限制最多填写3个帧范围。而现在的quic首部可以填写更多sack帧范围。
⑤不允许Reneging
什么叫 Reneging 呢?就是接收方已经接收并且上报给 SACK 选项的内容 ,但是接收方因为服务器资源有限,比如 Buffer 溢出,内存不够等情况而丢弃数据,这种方式在http3中不被允许,可以减少干扰。

4.3流量控制 QUIC-流量控制
流量控制用于解决发送端和接收端速度不匹配的情况,如果发送端发送太快会导致接收端无法接收而丢弃数据包,数据接收率低;如果接收端太快而发送端比较慢,也会使得网络传输率低。流量控制就是为了平衡接收端和发送端的速度问题或者特定数据流的传输请求等(例如视频倍速播放等)。
http3流控中接收端发送WINDOW_UPDATE帧通知对端接收窗口的大小增长,比如说能接收更多的数据,发送端也可以发送BLOCKED帧表明数据发送受制于接收端的窗口,无法发送数据。
流量控制的大致过程:图中flow control receive offset表示最大的接收窗口,也可以看成初始时服务器端允许客户端发送的最大窗口,绿色部分表示接收端读取的数据,黄色部分表示到达但还没有接受的数据(空白间隙表示没有按序到达的块),flow control receive window表示接收窗口,当接收端读取的数据(绿色部分)大于最大接收窗口(flow control receive offset)的一半时,会增加最大接收窗口(读取多少,扩大多少),同时发送WINDOW_UPDATE帧通知客户端发送窗口。如果接收窗口(flow control receive window)小于0,则发送BLOCKED帧通知发送端停止发送。quic的流量控制与tcp的不同在于:TCP 为了保证可靠性,窗口左边沿向右滑动时的长度取决于已经确认的字节数。如果中间出现丢包,就算接收到了更大序号的 Segment,窗口也无法超过这个序列号;而QUIC 不同,它的滑动只取决于接收到的最大偏移字节数(图中黄色最右边的位置),即使中间有包未收到,也跟接收窗口没有关系。
此外,http3和http2一样,同时提供流级和链接级别的流量控制。还有流和连接两种流量控制,连接的流量控制是针对连接内所有流的。

参考:哈夫曼编码的理解
https过程解析
浅谈SSL/TLS工作原理 - 知乎 (zhihu.com)
ALPN协议
HTTP/2协议
使用 Wireshark 抓取 HTTP1/2 流量
TLS 1.3 协议详解
TCP选项之SACK选项概述
TCP 的那些事 | D-SACK
TCP中的RST标志(Reset)详解
TCP的快速重传机制与累计确认机制
HTTP协议学习笔记–http1.0、http1.1、http2.0、https、http3
面试官:一个TCP连接可以发多少个HTTP请求? - 知乎 (zhihu.com)
图解 ECDHE 密钥交换算法 - 爱码网 (likecs.com)
几幅图,拿下 HTTPS (qq.com)
关于队头阻塞(Head-of-Line blocking),看这一篇就足够了
HPACK 介绍 (gohalo.me)
HTTP2 详解 - 简书 (jianshu.com)
QUIC详解-网络编程/专项技术区
HTTP 协议概述 - 博客园 (cnblogs.com)