目录
1、原理
2、代码实现
1、原理
图像风格迁移是一种将一张图片的内容与另一张图片的风格进行合成的技术。
风格(style)是指图像中不同空间尺度的纹理、颜色和视觉图案,内容(content)是指图像的高级宏观结构。
实现风格迁移背后的关键概念与所有深度学习算法的核心思想是一样的:定义一个损失函数来指定想要实现的目标,然后将这个损失最小化。你知道想要实现的目标是什么,就是保存原始图像的内容,同时采用参考图像的风格。
在Python中,我们可以使用基于深度学习的模型来实现这一技术。神经风格迁移可以用任何预训练卷积神经网络来实现。我们这里将使用 Gatys等人所使用的 VGG19网络。
2、代码实现
以下是一个基于VGG19模型的简单图像风格迁移的实现过程:
(1)创建一个网络,它能够同时计算风格参考图像、目标图像和生成图像的 VGG19层激活。
(2)使用这三张图像上计算的层激活来定义之前所述的损失函数,为了实现风格迁移,需要将这个损失函数最小化。
(3)设置梯度下降过程来将这个损失函数最小化
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.optim as optim
from torchvision import transforms, models
vgg = models.vgg19(pretrained=True).features
for param in vgg.parameters():param.requires_grad_(False)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
vgg.to(device)
def load_image(img_path, max_size=400):
image = Image.open(img_path)if max(image.size) > max_size:size = max_sizeelse:size = max(image.size)image_transform = transforms.Compose([transforms.Resize(size),transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])
image = image_transform(image).unsqueeze(0)return image
content = load_image('dogs_and_cats.jpg').to(device)
style = load_image('picasso.jpg').to(device)
assert style.size() == content.size(), "输入的风格图片和内容图片大小需要一致"
plt.ion()
def imshow(tensor,title=None):image = tensor.cpu().clone().detach()image = image.numpy().squeeze()image = image.transpose(1,2,0)image = image * np.array((0.229, 0.224, 0.225)) + np.array((0.485, 0.456, 0.406))plt.imshow(image)if title is not None:plt.title(title)plt.pause(0.1)
plt.figure()
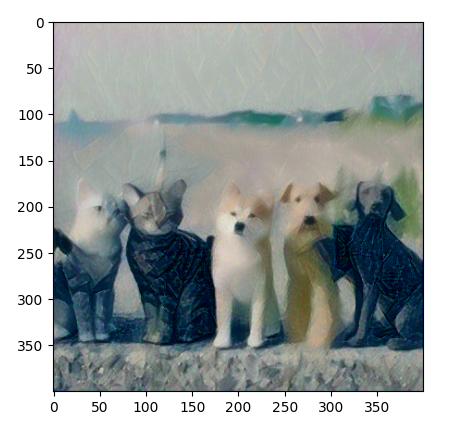
imshow(style, title='Style Image')
plt.figure()
imshow(content, title='Content Image')
def get_features(image, model, layers=None):if layers is None:layers = {'0': 'conv1_1','5': 'conv2_1', '10': 'conv3_1', '19': 'conv4_1','21': 'conv4_2', '28': 'conv5_1'}features = {}x = imagefor name, layer in model._modules.items():x = layer(x)if name in layers:features[layers[name]] = xreturn features
content_features = get_features(content, vgg)
style_features = get_features(style, vgg)
def gram_matrix(tensor):_, d, h, w = tensor.size() tensor = tensor.view(d, h * w)gram = torch.mm(tensor, tensor.t())return gram
style_grams={}
for layer in style_features:style_grams[layer] = gram_matrix(style_features[layer])
import torch.nn.functional as F
def ContentLoss(target_features,content_features):content_loss = F.mse_loss(target_features['conv4_2'],content_features['conv4_2'])return content_loss
def StyleLoss(target_features,style_grams,style_weights):style_loss = 0for layer in style_weights:target_feature = target_features[layer]target_gram = gram_matrix(target_feature)_, d, h, w = target_feature.shapestyle_gram = style_grams[layer]layer_style_loss = style_weights[layer] * F.mse_loss(target_gram,style_gram)style_loss += layer_style_loss / (d * h * w)
return style_loss
style_weights = {'conv1_1': 1.,'conv2_1': 0.75,'conv3_1': 0.2,'conv4_1': 0.2,'conv5_1': 0.2}
alpha = 1 # alpha
beta = 1e6 # beta
show_every = 100
steps = 2000
target = content.clone().requires_grad_(True).to(device)
optimizer = optim.Adam([target], lr=0.003)
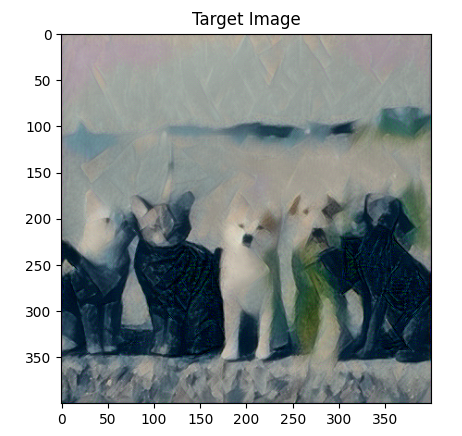
for ii in range(1, steps+1):target_features = get_features(target, vgg)content_loss = ContentLoss(target_features,content_features)style_loss = StyleLoss(target_features,style_grams,style_weights)total_loss = alpha * content_loss + beta * style_lossoptimizer.zero_grad()total_loss.backward()optimizer.step()#print(ii)if ii % show_every == 0:print('Total loss: ', total_loss.item())plt.figure() imshow(target)
plt.figure()
imshow(target,"Target Image")
plt.ioff()
plt.show()