一、为什么要有协程?
以DNS请求为例子,客户端向服务器发送域名,服务器回复该域名对应得IP地址。
我们想要以同步的编程方式获得异步的性能!!!

在Linux下,常使用IO多路复用器epoll来管理客户端连接,其主循环框架如下
while (1){int nready = epoll_wait(epfd, events, EVENT_SIZE, -1);int i=0;for (i=0; i<nready; i++){int sockfd = events[i].data.fd;if (sockfd == listenfd){int connfd = accept(listenfd, addr, &addr_len);setnonblock(connfd); //置为非阻塞ev.events = EPOLLIN | EPOLLET;ev.data.fd = connfd;epoll_ctl(epfd, EPOLL_CTL_ADD,connfd,&ev);}else{handel(sockfd); //进行读写操作}}}
在通过 accept 建立服务端与客户端的连接之后,需要行读写操作,也就是 handel 函数。根据同步和异步,有两种不同的处理方式。
同步的处理方式
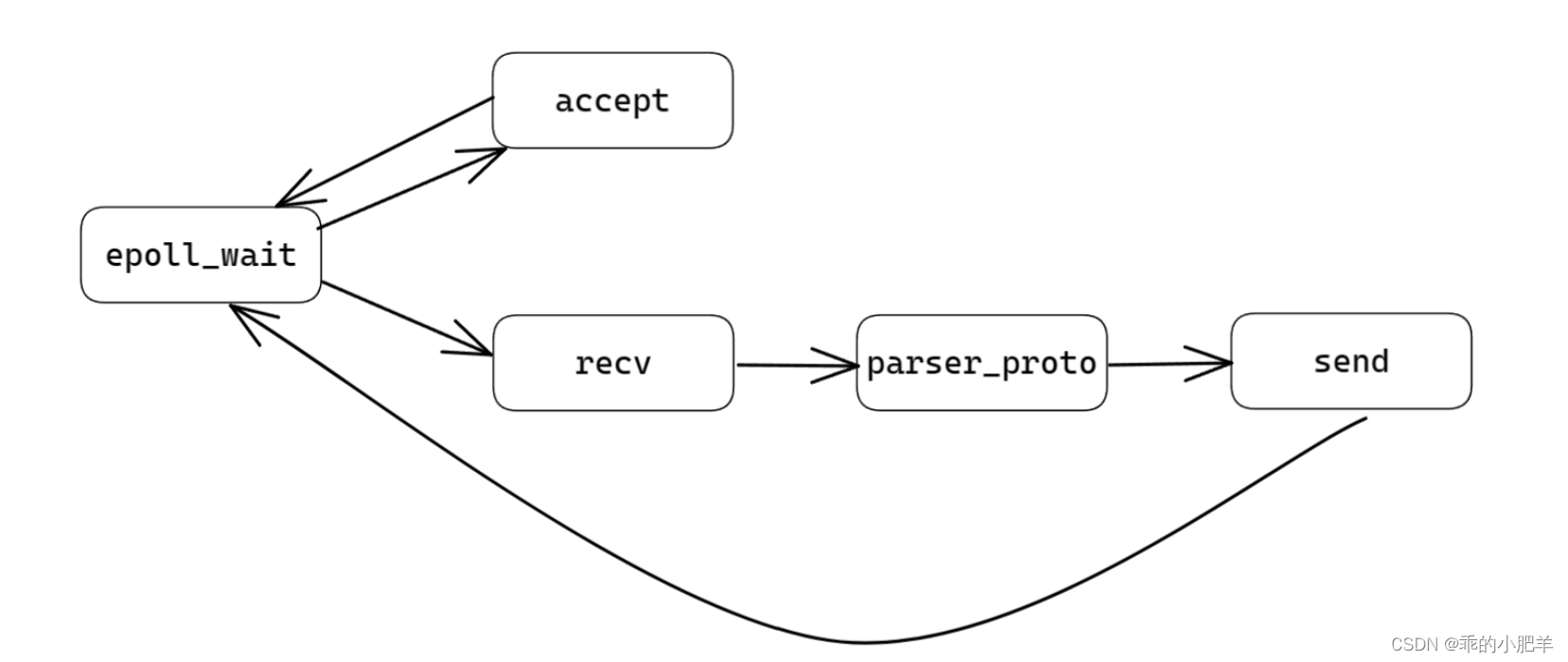
异步的处理方式

可见,同步和异步主要区别在于对于 handle 函数的处理。同步在需要等待 handle 函数处理完成,主循环才能继续执行,阻塞了 epoll_wait。而异步是单独为 handle 函数创建一个线程异步处理,主循环不需要等待 handle 函数。(同步异步的本质是在IO操作的时候的处理方式的不同)
但是问题在于线程的创建、销毁,十分消耗资源。面对来自客户端的数百万连接,每一条都创建线程,很容易把服务器干崩溃。
因此就有了协程,在一个线程里面创建多个协程,共享一个线程的资源,但又能异步(看起来)处理事务。
二、协程的实现原理
前面说到,协程能异步处理事务,这只是看起来而已。协程的异步处理在于对CPU的调度,即需要的时候切入获取CPU操作权,不需要的时候让出CPU操作权。
这边涉及到以下几个问题:
1、切换的时候怎么做到跟切换前一致?
2、有协程1、协程2、协程3,……,怎么决定由那个协程执行?
首先第一个问题,就是协程切换前后需要进行上下文切换。有汇编、ucontext、longjmp / setjmp。当然,汇编效果最快。
其次第二个问题,协程是一种用户态的轻量级线程,协程的调度完全由用户控制。也就是说,由我们自定义的调度器管理。
在讲调度规则之前,我们需要先了解一下协程创建后会有哪些状态:
1、新创建的协程,创建完成后,加入到就绪集合,等待调度器的调度;
2、协程在运行完成后,进行 IO 操作,此时 IO 并未准备好,进入等待状态集合;
3、IO 准备就绪,协程开始运行,后续进行 sleep 操作,此时进入到睡眠状态集合。
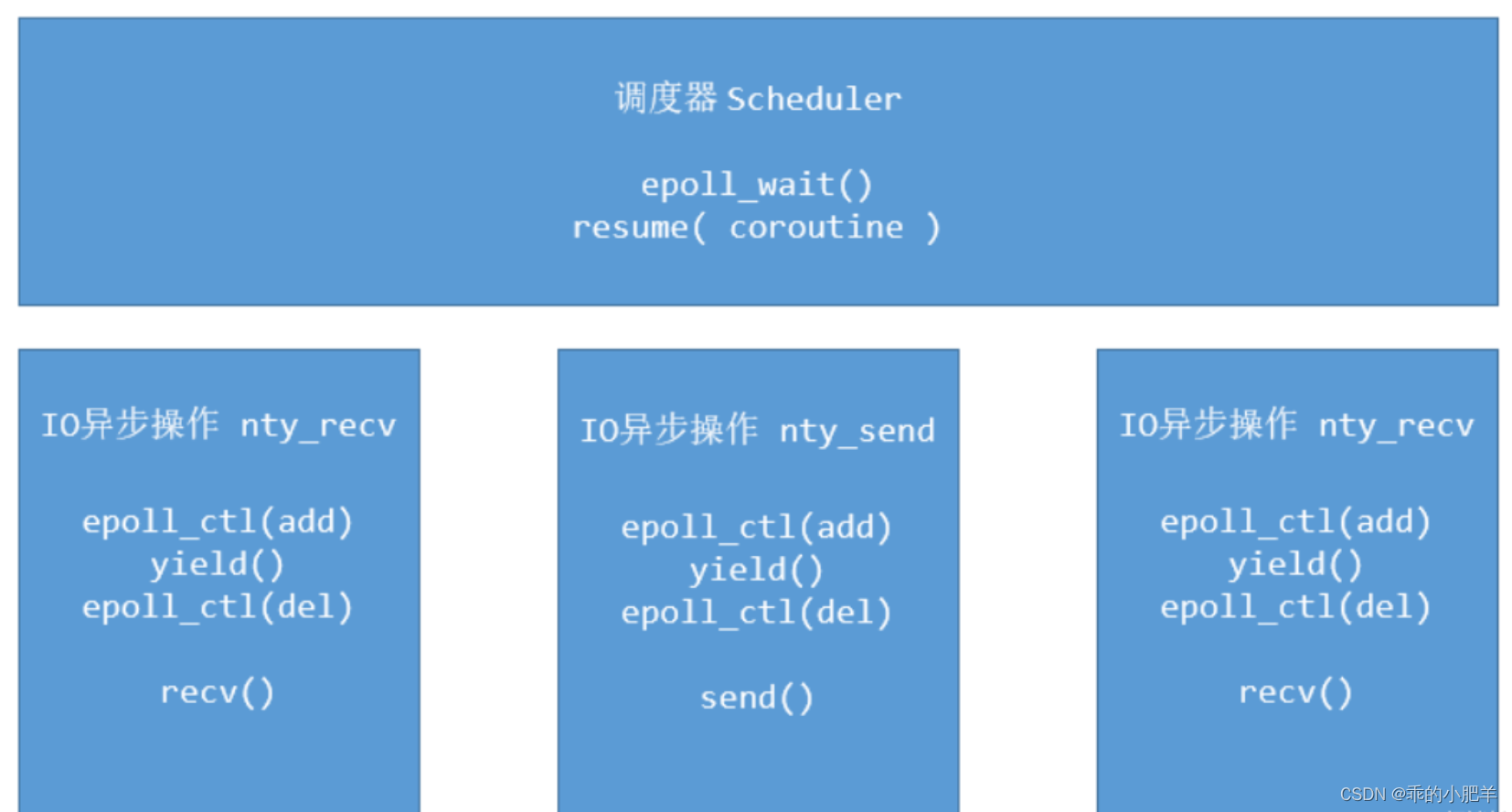
在协程的上下文 IO 异步操作(nty_recv,nty_send)函数,步骤如下:
1)将 sockfd 添加到 epoll 管理中。
2)进行上下文环境切换,由协程上下文 yield 到调度器的上下文。
3)调度器获取下一个协程上下文。Resume 新的协程
IO 异步操作的上下文切换的时序图如下:
就绪:都准备好了,就等着执行。就绪(ready)集合并不没有设置优先级的选型,所有在协程优先级一致,所以可以使用队列来存储就绪的协程,简称为就绪队列
等待:没准备好,比如IO操作的recv,信息还没来,recv就还没准备好。等待(wait)集合,其功能是在等待 IO 准备就绪,等待 IO 也是有时长的,所以等待(wait)集合采用红黑树的来存储,简称等待树(wait_tree)
睡眠:指协程主动挂起,等待某个时间后再恢复执行。比如等待IO我们可以设置一个时间,时间内还是没触发,那就算过期超时了。睡眠(sleep)集合需要按照睡眠时长进行排序,采用红黑树来存储,简称睡眠树(sleep_tree)红黑树在工程实用为<key, value>, key 为睡眠时长,value 为对应的协程结点。
因此,基于以上,协程如何被调度?有两种
1、 生产者消费者模式

while (1) {//遍历睡眠集合,将满足条件的加入到 readynty_coroutine *expired = NULL;while ((expired = sleep_tree_expired(sched)) != ) {TAILQ_ADD(&sched->ready, expired);}//遍历等待集合,将满足添加的加入到 readynty_coroutine *wait = NULL;int nready = epoll_wait(sched->epfd, events, EVENT_MAX, 1);for (i = 0;i < nready;i ++) {wait = wait_tree_search(events[i].data.fd);TAILQ_ADD(&sched->ready, wait);}// 使用 resume 回复 ready 的协程运行权while (!TAILQ_EMPTY(&sched->ready)) {nty_coroutine *ready = TAILQ_POP(sched->ready);resume(ready);}
}
2、多状态运行

while (1) {//遍历睡眠集合,使用 resume 恢复 expired 的协程运行权nty_coroutine *expired = NULL;while ((expired = sleep_tree_expired(sched)) != ) {resume(expired);}//遍历等待集合,使用 resume 恢复 wait 的协程运行权nty_coroutine *wait = NULL;int nready = epoll_wait(sched->epfd, events, EVENT_MAX, 1);for (i = 0;i < nready;i ++) {wait = wait_tree_search(events[i].data.fd);resume(wait);}// 使用 resume 恢复 ready 的协程运行权while (!TAILQ_EMPTY(sched->ready)) {nty_coroutine *ready = TAILQ_POP(sched->ready);resume(ready);}
}
三、NtyCo 的接口(纯C的协程框架)

大致介绍一下协程工作的流程:
1、为accept事件创建一个协程co1,并注册监听事件到co1的epoll,加入等待队列,然后yield,让出CPU控制权
2、为recv事件创建一个协程co2,并注册监听事件到co2的epoll,加入等待队列,然后yield,让出CPU控制权
3、为send事件创建一个协程co3,并注册监听事件到co3的epoll,加入等待队列,然后yield,让出CPU控制权
(以上设置默认睡眠时间,同步加入睡眠队列)
(调度器接手)
4、遍历睡眠集合,使用 resume 恢复过期协程 expired 的协程运行权
5、遍历就绪集合,使用 resume 恢复 ready 的协程运行权
6、遍历等待集合,使用 resume 恢复 wait 的协程运行权

四、测试结果
4台Ubuntu虚拟机,其中一台服务端4核12G,另外三台1核4G。测试并发连接。
需要做一些配置测试搭建百万并发项目

五、我们的系统代码怎么改成支持协程呢?
(也就是如何与posix api兼容)
NtyCo的hook
如果我们自己写的代码要引入协程,最傻的办法就是一个函数一个函数的改过来,把每个recv改成nty_recv,这样非常耗时耗力,于是hook就起到了非常好的作用。
我们可以使用hook,帮助我们不用再封装posix api接口取个别的名字的函数,可以直接用和那些posix api接口同名并且不会冲突的函数(recv()、send()等等),并且功能由我们来具体实现。
hook提供了两个接口;1. dlsym()是针对系统的,系统原始的api。2. dlopen()是针对第三方的库。void *dlsym(void *handle, const char *symbol); 头文件是#include <dlfcn.h>
我们用dlsym来处理
在使用hook之前,我们一定要定义一个#define _GNU_SOURCE,定义这个
我们才能使用扩展库,如果不定义的话就不能用
#define _GNU_SOURCE
#include <stdio.h>
#include <unistd.h>
#include <dlfcn.h>
#include<mysql/mysql.h>
//
// Created by 68725 on 2022/7/17.
//typedef int (*connect_t)(int, struct sockaddr *, socklen_t);connect_t connect_f;typedef ssize_t (*recv_t)(int, void *buf, size_t, int);recv_t recv_f;typedef ssize_t (*send_t)(int, const void *buf, size_t, int);send_t send_f;typedef ssize_t (*read_t)(int, void *buf, size_t);read_t read_f;typedef ssize_t (*write_t)(int, const void *buf, size_t);write_t write_f;int connect(int fd, struct sockaddr *name, socklen_t len) {printf("in connect\n");return connect_f(fd, name, len);
}ssize_t recv(int fd, void *buf, size_t len, int flags) {printf("in recv\n");return recv_f(fd, buf, len, flags);
}ssize_t send(int fd, const void *buf, size_t len, int flags) {printf("in send\n");return send_f(fd, buf, len, flags);
}
ssize_t read(int fd, void *buf, size_t len) {printf("in read\n");return read_f(fd, buf, len);
}ssize_t write(int fd, const void *buf, size_t len) {printf("in write\n");return write_f(fd, buf, len);
}static int init_hook() {connect_f = dlsym(RTLD_NEXT, "connect");recv_f = dlsym(RTLD_NEXT, "recv");send_f = dlsym(RTLD_NEXT, "send");read_f = dlsym(RTLD_NEXT, "read");write_f = dlsym(RTLD_NEXT, "write");
}void main() {init_hook();MYSQL *m_mysql = mysql_init(NULL);if (!m_mysql) {printf("mysql_init failed\n");return;}if (!mysql_real_connect(m_mysql, "192.168.109.1", "root", "123456", "cdb", 3306, NULL, 0)) {printf("mysql_real_connect failed\n");return;}else {printf("mysql_real_connect success\n");}
}
//gcc -o hook hook.c -lmysqlclient -I /usr/include/mysql/ -ldl
如果跟mysql,redis建立连接进行io操作,但是不去修改它们提供的客户端源码开发包的时候,就会发现连不上去,因为其源码用的是posix api,recv和send。而协程用的是nty_recv()和nty_send()。两者之间没有关联。
所以解决方法就用hook函数进行替换
这样,在执行协程之前,我们先利用hook进行系统函数替换,下面是替换的原理图

当我们替换掉之后,我们的mysql和redis也就支持我们自己定义的函数了,那么mysql在recv和send的时候也就是用的我们协程支持的recv和send等操作了
那怎么测试呢?
测试mysql和redis要测试二大要点
1.增删改查
2.存储过程
六、协程多核模式
解决协程多核的问题有两种方式
- 多进程(实现起来容易,对协程代码本身不用去改)
- 多线程(复杂,需要对调度器进行加锁)
那么做多线程对调度器进行加锁,锁放在哪呢?锁放在调度器结构体里面,因为调度器是全局唯一的,那么要锁哪里呢?<取协程,恢复协程>,这里需要加锁。