文章目录
- FutureTask
- CompletionService
- CompletableFuture
- Disruptor
- Disruptor 核心概念
- 运行流程
- 不同生产者模式的区别
- Disruptor设计精髓
FutureTask
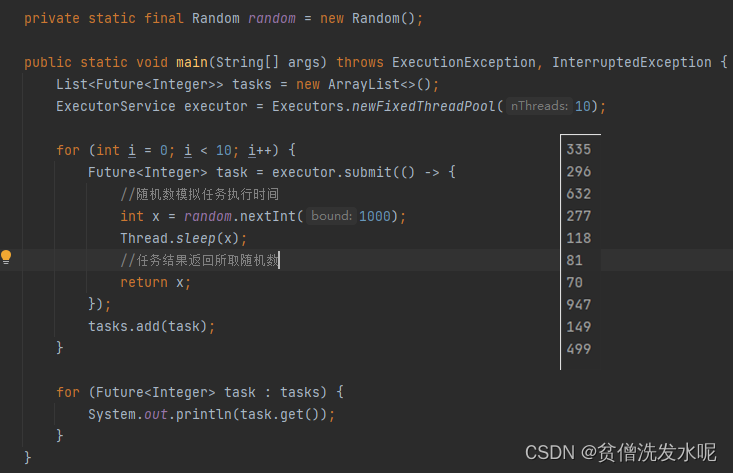
现有一个场景,10个线程执行10个任务,然后主线程获取任务结果。
比较广泛的一个说法就是,runnable是没有返回值的线程,callable是有返回值的线程。所以最先想到的是用callable接口去获取线程返回值。
实际上,"runnable是没有返回值的线程,callable是有返回值的线程"这种说法。
我个人认为是错误的,我认为运行线程的方式只有一种,就是实现runnable接口!不管你是new Thread,还是使用线程池最终都要实现runnable接口。就算是用callable接口的方式也不例外。
callable的返回值是如何实现的?
提交的callable作为成员变量封装到RunnableFuture(最常用的实现类就是FutureTask),而RunnableFuture又继承自Runnable,所以其实线程池真正提交的还是一个Runnable(RunnableFuture)。
RunnableFuture.run方法调用了callable.call方法,并将call方法结果存起来,唤醒等待结果的线程。
RunnableFuture.get方法如果有结果了就直接返回,如果没有就自旋/阻塞等待唤醒。
CompletionService
单纯使用FutureTask有一个最大的问题就是,在获取任务结果的时候,如果前一个任务还没有结果,即使后面的任务有结果了也无法打印出来。所以有没有那么一种办法,可以让10个任务,谁先完成了就谁先打印。因此,CompletionService 来了。
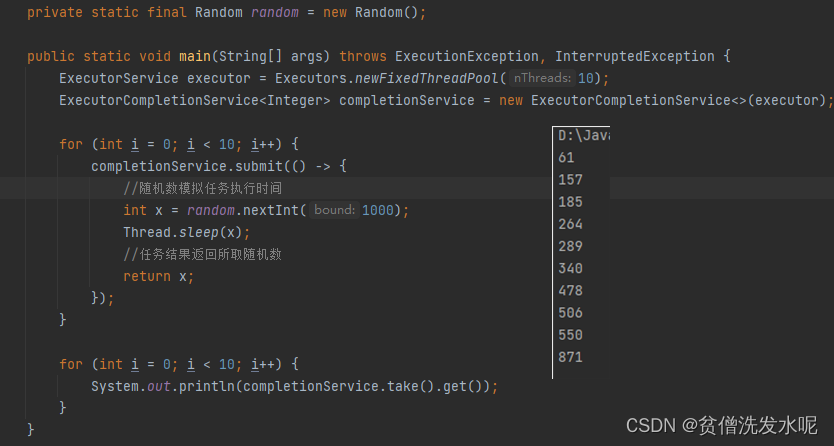
这个实现原理不用看源码也基本可以猜到就是在原来的基础上多加一个阻塞队列,将任务结果统一存入阻塞队列,先进先出。
CompletableFuture
FutureTask还有一个问题就是会阻塞主线程。所以有没有那么一种办法,可以不阻塞主线程(异步回调)。主线程只管提交任务,提交完后就不管了,无需等待任务结果,任务完成后自己回调后续操作。因此,CompletableFuture 来了。
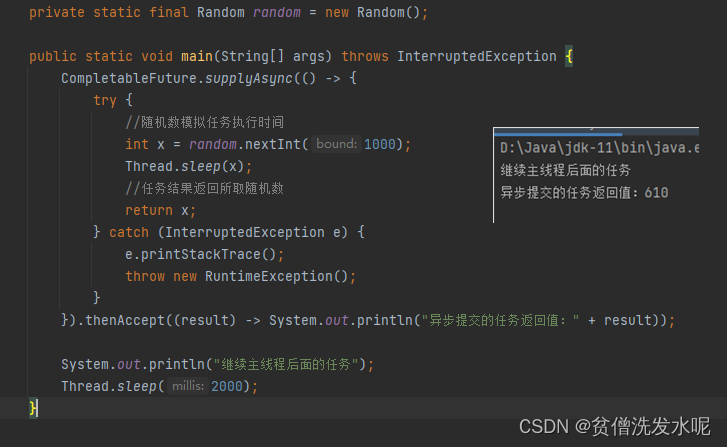
另外,CompletableFuture还支持串行执行。
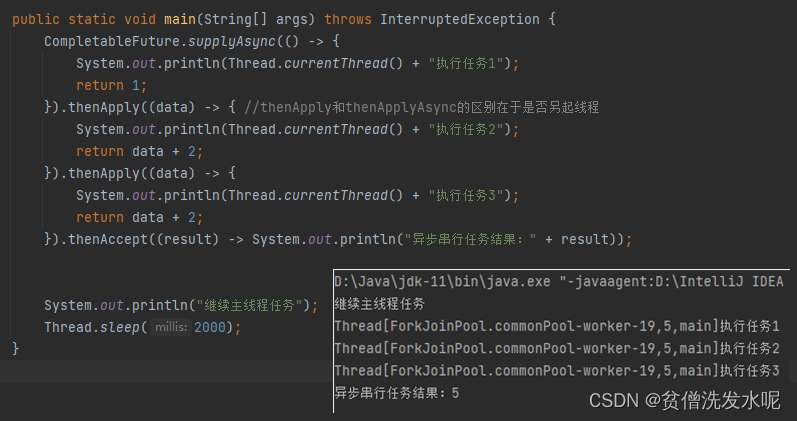
通过打印的信息得知,CompletableFuture使用的线程池是ForkJoinPool.commonPool
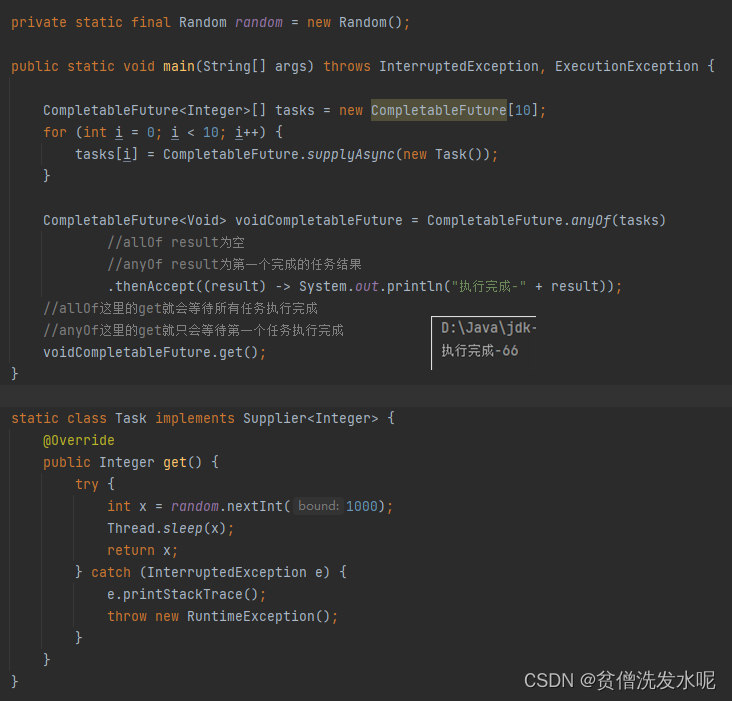
除此之外,CompletableFuture还支持并行执行。
Disruptor
本篇只是简单的记录一下Disruptor的基本设计,不涉及太深的源码分析
附上一篇美团的技术文章:https://tech.meituan.com/2016/11/18/disruptor.html
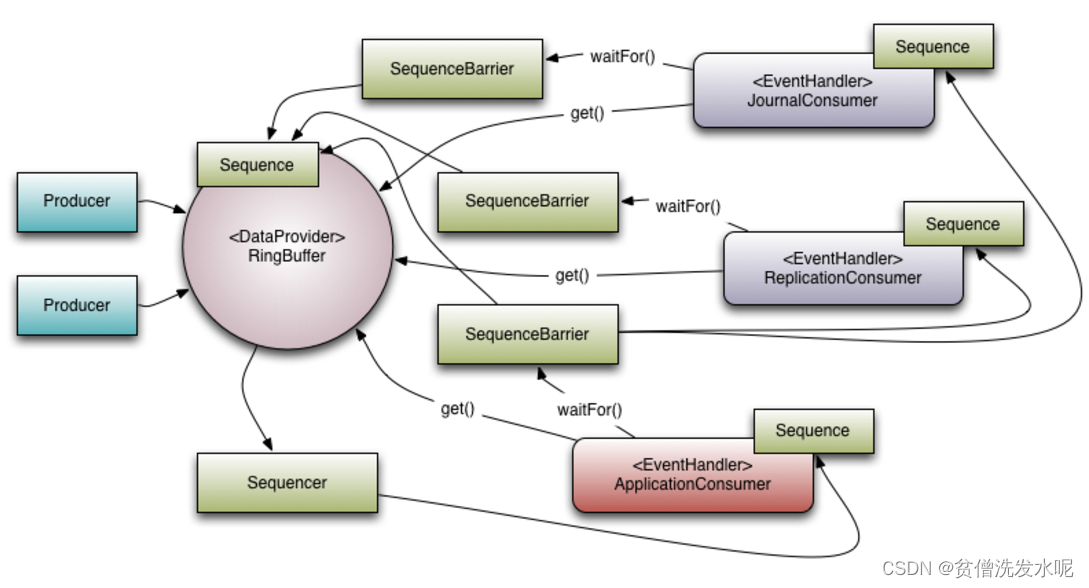
Disruptor 核心概念
- Disruptor(总体执行入口):执行引用。
- RingBuffer(环形缓冲区):基于数组的内存级别环形数组缓存。
- Sequence(序号分配器):通过顺序递增的方式,一个Sequence对应一个事件,同时还能消除伪共享。
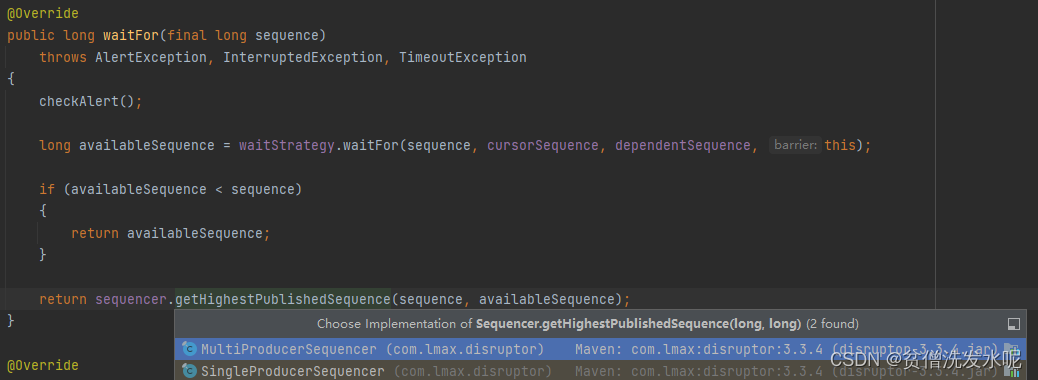
- Sequencer(数据传输器):有两个实现类,SingleProducerSequencer(单生产者实现)、MultiProducerSequencer(多生产者实现)。主要作用是实现生产者和消费者之间的并发算法。
- SequenceBarrier(消费者屏障):用于控制生产者和消费者之间的平衡。
- WaitStrategy(消费者等待策略):当无可消费事件时的等待策略。(目前数组满需要等待时调用LockSupport.parkNanos(1),不过看注释后续可能会与等待策略挂钩)
- Event:使用者自定义的事件数据结构。
- EventHandler:消费者逻辑。
- EventProcessor:实现了Runnable,并封装了EventHandler,意味着可以线程方式执行消费逻辑。
使用案例
<dependency><groupId>com.lmax</groupId><artifactId>disruptor</artifactId><version>3.3.4</version></dependency>
运行流程
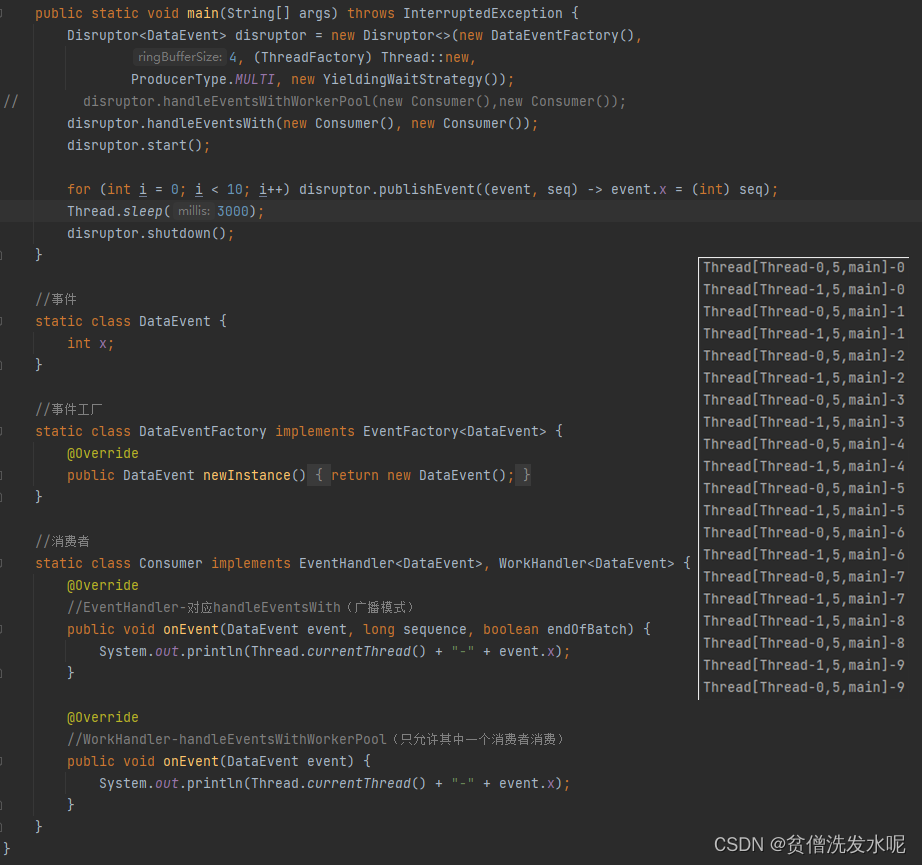
1、构造函数
public Disruptor(final EventFactory<T> eventFactory, //事件工厂final int ringBufferSize, //ringBuffer环形数组大小final ThreadFactory threadFactory, //线程工厂final ProducerType producerType, //生产者类型,SINGLE,MULTI两种类型,不同类型有不同的sequencer实现final WaitStrategy waitStrategy) //等待策略{this(RingBuffer.create(producerType, eventFactory, ringBufferSize, waitStrategy),new BasicExecutor(threadFactory));}
其中等待策略有如下几种

2、disruptor.handleEventsWith()
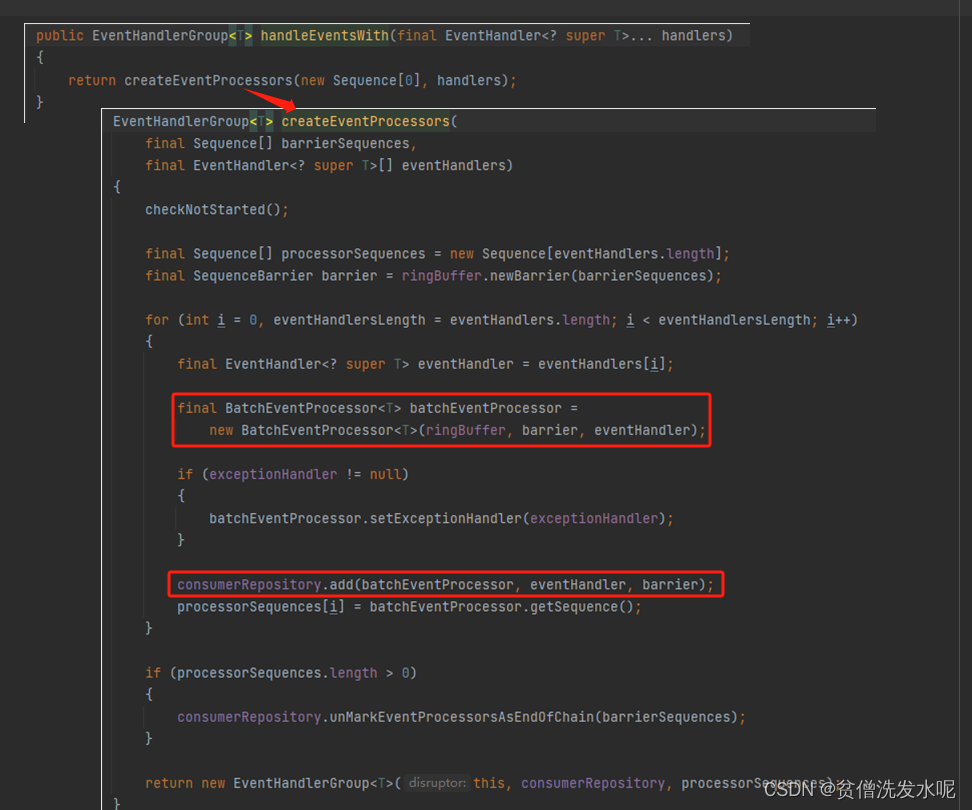
这一步就是将消费者逻辑(EventHandler)封装到消费者线程处理器(EventProcessor),并将所有消费线程处理器加入consumerRepository列表。
3、disruptor.start()
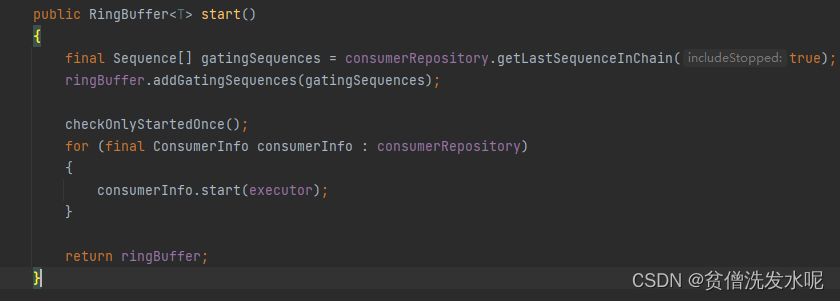
这一步就是启动consumerRepository中的所有消费者线程。
4、消费者线程
以BatchEventProcessor为例
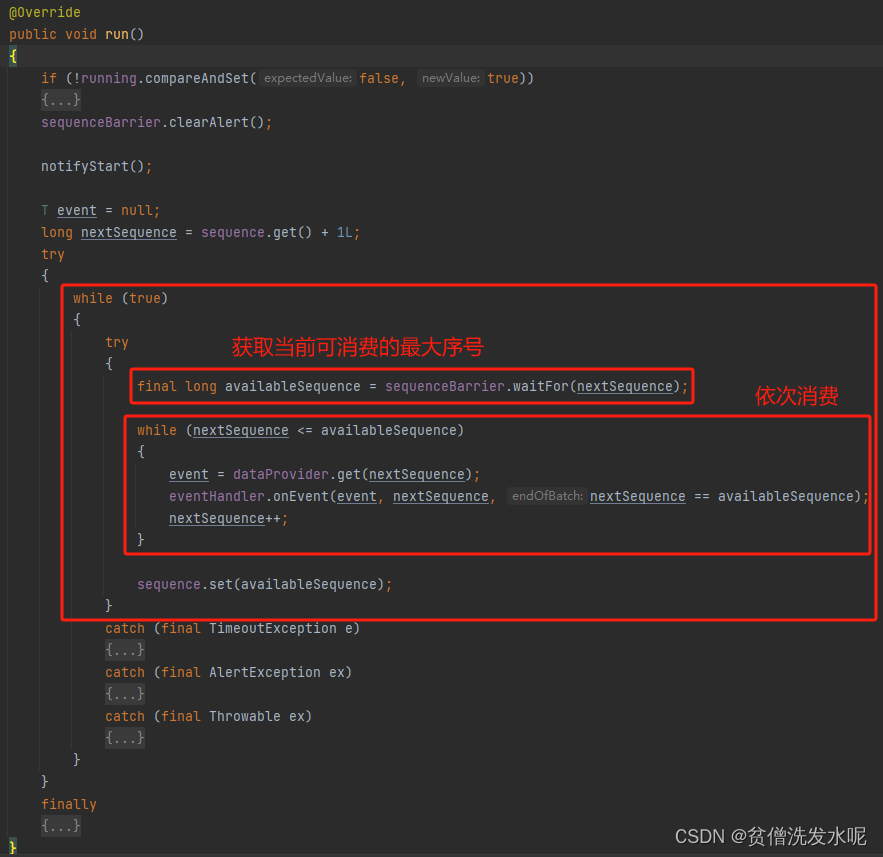
消费者线程的逻辑就是不断的循环,从环形数组中获取事件消费,如果没有事件可以获取了就根据不同的等待策略进行等待。
5、disruptor.publishEvent()

发布一个事件逻辑挺简单的,就是获取一个序号(槽位),然后填充槽位上的事件数据,最后就是发布唤醒等待消费者。
不同生产者模式的区别
一个生产者
一个生产者的情况比较简单
写数据
1、申请写入m个元素
2、判断是否覆盖未消费数据,若无则写入数据
读数据
1、申请读取到序号n
2、从reader cursor开始消费数据到n
多生产者
多个生产者的情况下,为防止多个线程重复写同一个元素。Disruptor的做法是:每个线程获取不同的一段数组空间进行操作。对应的实现方式是,在分配元素的时候,通过CAS判断一下这段空间是否已经分配出去,如果分配了就取下一段。
但是这会遇到一个新问题:如何防止读取的时候,读到还未写的元素。Disruptor的做法是:引入了一个与Ring Buffer大小相同的buffer——available Buffer。当某个位置成功写入时,就把相应位置标记为写入成功。读取的时候,通过遍历available Buffer来获取一段最长的连续已写槽位。
写数据:
1、申请写入m个元素
2、若有m个元素可以写,则返回最大的序号,每个生产者会通过CAS被分配一段独享的空间,各自写入自己的空间
3、标记available Buffer对应位置为成功写入
读数据:
1、申请读取到序号n
2、若此时 write cursor > n,说明这时无法确定连续可读的最大下标。就从reader cursor开始读取available Buffer,一直查到第一个不可用的元素,然后返回最大连续可读元素的位置
3、消费者读取元素
Disruptor设计精髓
1、环形数组的数据结构与初始化时提前分配事件内存,可以实现槽位和事件对象的复用,减少垃圾回收次数
2、递增序号配合长度2次幂的数组长度可通过位运算替换求余
3、缓存行填充解决伪共享问题
4、无锁设计,每个生产者或者消费者会申请一个空间,不同线程在不同空间操作
5、实现了基于事件驱动的生产者消费者模型(观察者模式)