redis缓存穿透
模拟一个缓存穿透的环境:
- redis缓存穿透
- 1. 准备一个GET请求并且在第一次访问的时候将数据写入缓存
- 2. 再次访问的时候首先判断缓存是否命中
- 3. 命中了直接返回,未命中重建缓存
- 1. 缓存空对象
- 2. 布隆过滤器
1. 准备一个GET请求并且在第一次访问的时候将数据写入缓存
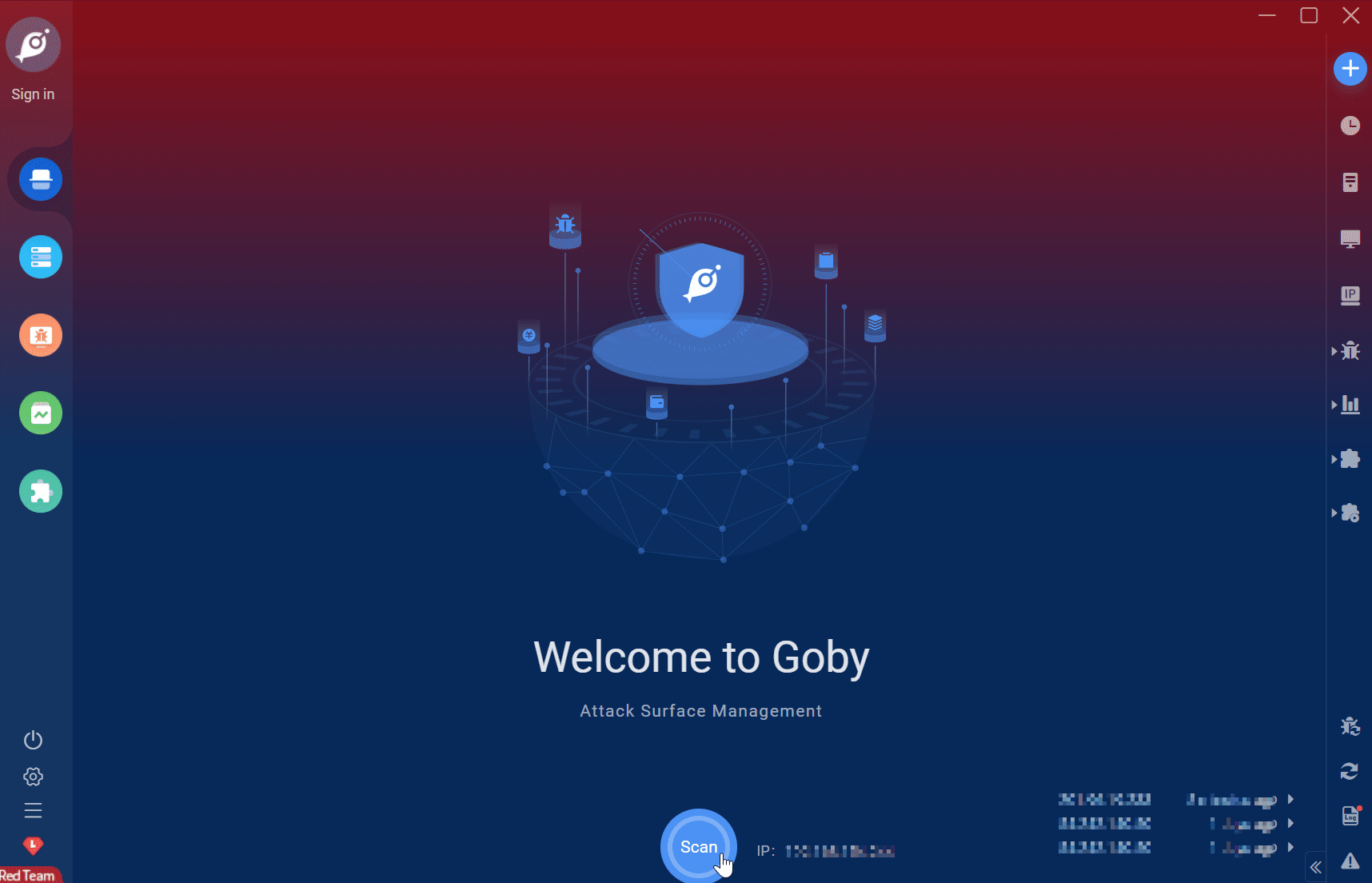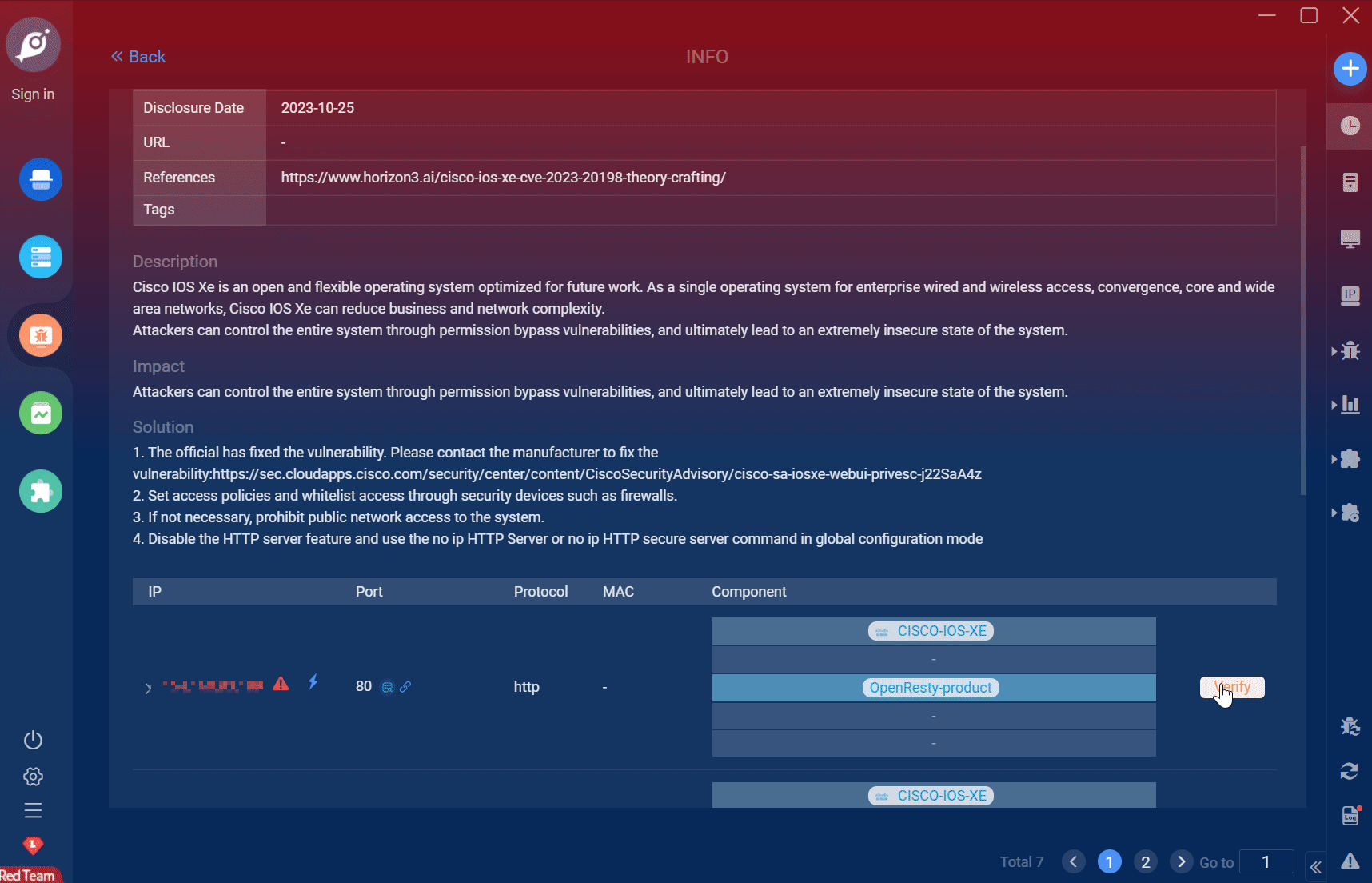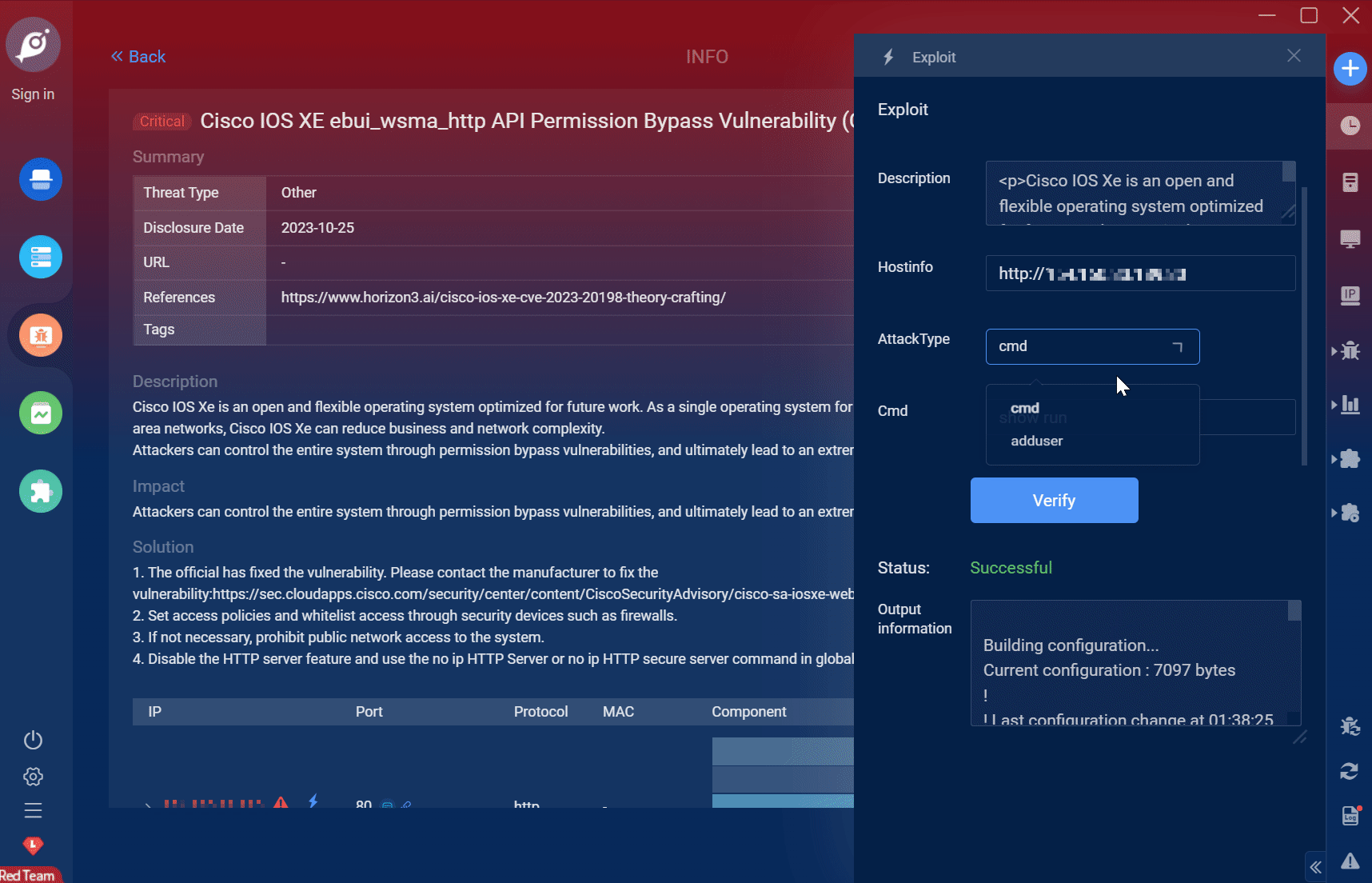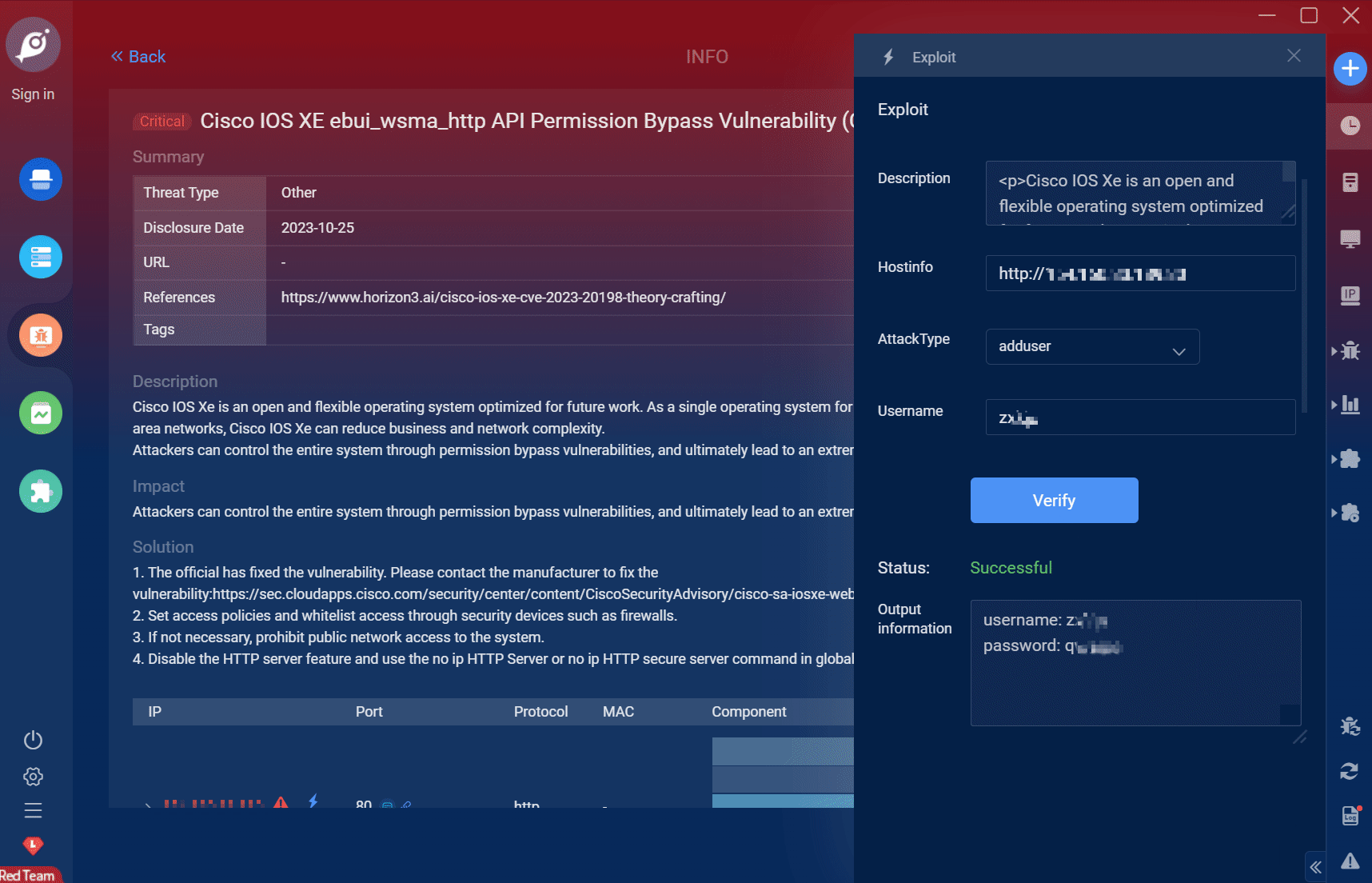
// 首先从缓存中获取数据Object articleObj = redisTemplate.opsForValue().get(ARTICLE_KEY + id);// 拿到缓存了就直接返回if (Objects.nonNull(articleObj)){String articleJSON = (String) articleObj;ApArticle article = JSON.parseObject(articleJSON, ApArticle.class);return ResponseResult.okResult(article);}// 通过数据库获取文章数据ApArticle article = getById(id);// 重建缓存redisTemplate.opsForValue().set(ARTICLE_KEY + id, JSON.toJSONString(article),ARTICLE_EXPIRED);// 返回获得的文章数据return ResponseResult.okResult(article);
2. 再次访问的时候首先判断缓存是否命中
3. 命中了直接返回,未命中重建缓存
什么事缓存穿透?
缓存穿透其实是一种攻击性的行为。其实是接口访问一个缓存和数据数据库中都不存在的数据,这个数据每次都会去请求数据库,如果没有进行处理的话,恶意的请求会对数据库造成极大的压力。
模拟一个500并发量的请求,单接口的响应耗时已经达到了1500毫秒

解决缓存穿透的问题:
1. 缓存空对象
在数据没有命中缓存的时候这个请求会直接的打到后端数据库上,
那么可以对这个没有命中的数据也对应的缓存到redis中,当请求再次来临的时候就不会去访问数据库
缺点:可能会浪费redis大量的内存,并且可能会出现不一致的问题(例如第一次id为2的没有数据,被缓存了空数据,然而后续2插入了数据,再次访问就会有不一致的问题)
优点:实现简单
2. 布隆过滤器
布隆过滤器
布隆过滤器本质上是一个bitmap
不能保证存在,但是可以保证一定不存在
guava的工具包为我们做了布隆过滤器的实现
- 添加guava工具包
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId></dependency>
- 创建布隆过滤器的Bean并且初始化布隆过滤器。需要使用init方法对布隆过滤器进行数据的初始化,否则布隆过滤器中没有数据,所有的请求来临都会被拒绝掉。
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.heima.article.mapper.ApArticleMapper;
import com.heima.model.article.pojos.ApArticle;
import org.apache.hbase.thirdparty.com.google.common.hash.BloomFilter;
import org.apache.hbase.thirdparty.com.google.common.hash.Funnels;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.annotation.PostConstruct;
import java.util.List;
import static com.heima.model.constant.Constant.BLOOM_FILTER_EXPECTED_SIZE;
import static com.heima.model.constant.Constant.BLOOM_FILTER_FALSE_POSITIVE_RATE;@Configuration
public class BloomFilterConfig {@Autowiredprivate ApArticleMapper apArticleMapper;public final BloomFilter<Long> bloomFilter;public BloomFilterConfig(){// 预期元素数量,误判率this.bloomFilter = BloomFilter
// .create(Funnels.unencodedCharsFunnel(),BLOOM_FILTER_EXPECTED_SIZE,BLOOM_FILTER_FALSE_POSITIVE_RATE);.create(Funnels.longFunnel(),BLOOM_FILTER_EXPECTED_SIZE,BLOOM_FILTER_FALSE_POSITIVE_RATE);}@PostConstructpublic void init(){BloomFilter<String> longBloomFilter = bloomFilter();// 查询缓存,并且写入到布隆过滤器Set<String> keys = redisTemplate.keys("KEYS article:id:*");keys.forEach(longBloomFilter::put);}@Beanpublic BloomFilter<Long> bloomFilter(){// 预期元素数量,误判率return bloomFilter;}}- 注入布隆过滤器进行判断。
// 判断这个id是不是在布隆过滤器中boolean mightContain = bloomFilter.mightContain(ARTICLE_KEY + id);// 不存在直接返回if (!mightContain){return ResponseResult.okResult();}// 首先从缓存中获取数据Object articleObj = redisTemplate.opsForValue().get(ARTICLE_KEY + id);// 拿到缓存了就直接返回if (Objects.nonNull(articleObj)){String articleJSON = (String) articleObj;ApArticle article = JSON.parseObject(articleJSON, ApArticle.class);return ResponseResult.okResult(article);}// 通过数据库获取文章数据ApArticle article = getById(id);// 重建缓存if (Objects.nonNull(article)){redisTemplate.opsForValue().set(ARTICLE_KEY + id, JSON.toJSONString(article),ARTICLE_EXPIRED,TimeUnit.SECONDS);}// 返回获得的文章数据return ResponseResult.okResult(article);