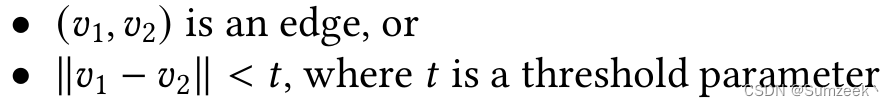目录
一、模糊C均值聚类的原理
二、不使用skfuzzy的python代码
三、 使用skfuzzy的python代码
一、模糊C均值聚类的原理


二、不使用skfuzzy的python代码
import numpy as np
import random
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False'''初始化隶属矩阵'''
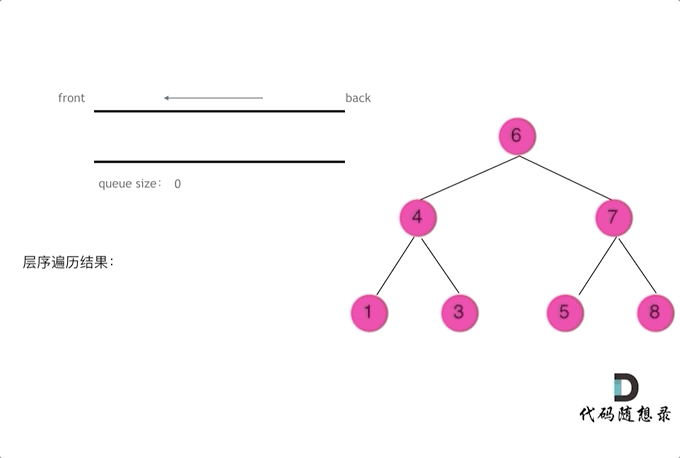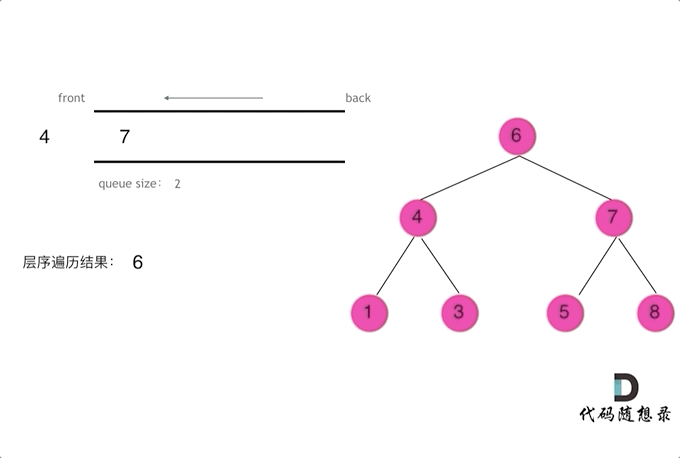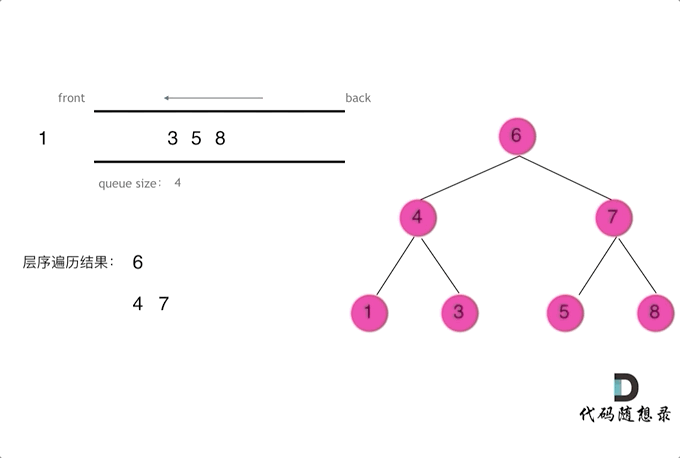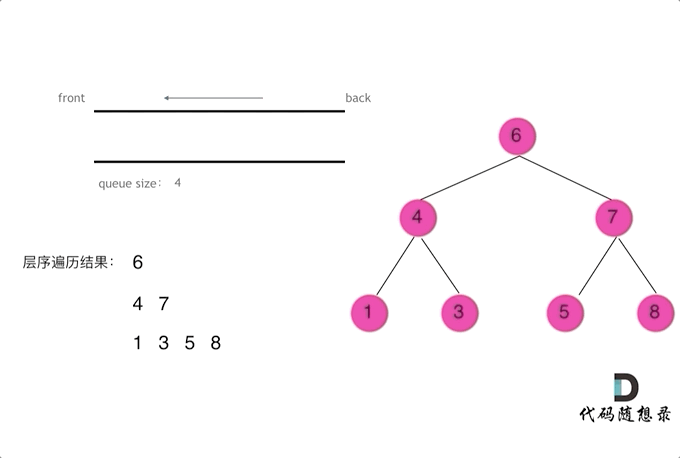
def initial_u0(n,K):''':param n:样本数量:param K:簇的数量:return: 初始化的隶属矩阵'''u0=np.zeros((K,n))for i in range(K):for j in range(n):if i==0:u0[i][j]=random.uniform(0,1)elif i<K-1:s=0for k in range(i):s=s+u0[k][j]u0[i][j]=random.uniform(0,1-s)else:s=0for k in range(i):s=s+u0[k][j]u0[i][j]=1-sreturn u0'''聚类函数'''
def Cluster(U,n):''':param U:隶属度矩阵:param n: 样本数量:return: 聚类结果'''cluster=[]for i in range(n):A=U.T[i].tolist()a=A.index(max(A))cluster.append(int(a))return cluster'''计算隶属中心矩阵'''
def center(data,U,m,n,K,dim):''':param data:样本数据:param U: 隶属度矩阵:param m: 模糊加权参数,一般取2:param n: 样本数量:param K: 聚类数目:param dim: 维度:return: 隶属中心矩阵''''''进行初始聚类'''cluster=Cluster(U,n)'''初始化隶属中心矩阵'''Z=np.zeros((K,dim))'''计算隶属中心矩阵'''#初始化u_x=[np.zeros((1,dim)) for i in range(K)]u=[0 for i in range(K)]#计算for i in range(n):c=cluster[i] #类别u[c]=u[c]+(U[c][i])**mu_x[c]=u_x[c]+((U[c][i])**m)*data[i]for i in range(K):Z[i]=u_x[i]/u[i]'''返回隶属中心矩阵'''return Z'''基于欧氏距离计算各点到聚类中心的距离矩阵'''
def distinct(data,n,dim,Z,K):''':param data:样本数据:param n: 样本数量:param dim: 数据维度:param Z: 隶属中心矩阵:param K: 聚类数目:return: 基于欧氏距离的距离矩阵''''''初始化距离矩阵'''D=np.zeros((K,n))'''计算欧式距离'''for i in range(K):for j in range(n):z=Z[i] #隶属中心df=data[j] #数据点df_z=df-zd=0for k in range(dim):d=d+(df_z[k])**2d=np.sqrt(d)D[i][j]=d'''返回距离矩阵'''return D'''定义目标函数并返回目标函数值'''
def function(data,Z,n,dim,K,U,m,D):''':param data:样本数据:param Z: 隶属中心矩阵:param n: 样本数量:param dim: 数据维度:param K: 聚类数目:param U: 隶属度矩阵:param m: 模糊加权参数:param D: 距离矩阵:return: 目标函数值''''''初始化聚类'''cluster=Cluster(U,n)'''计算目标函数值'''J=0 #目标函数值W=[0 for i in range(K)]for i in range(n):c=cluster[i] #聚类类别df=data[i] #数据点z=Z[c] #聚类中心d=D[c][i] #数据点到聚类中心的距离u=U[c][i] #隶属度W[c]=W[c]+(u**m)*(d**2)J=sum(W)'''返回目标函数值'''return J'''更新隶属度矩阵'''
def update_U(data,Z,n,dim,K,D,m):''':param data:样本数据:param Z: 隶属中心矩阵:param n: 样本数量:param dim: 数据维度:param K: 聚类数目:param D: 距离矩阵:param m: 模糊加权参数:return: 更新后的隶属度矩阵''''''初始化隶属度矩阵'''U=np.zeros((K,n))'''更新隶属度矩阵'''for i in range(K):for j in range(n):r=0for k in range(K):r=r+(D[i][j]/D[k][j])**(2/(m-1))U[i][j]=1/r'''返回更新后的隶属度矩阵'''return U'''模糊C均值聚类函数'''
def FCM(data,K,Tmax,m,error):''':param data:样本数据:param K: 聚类数目:param Tmax: 最大迭代步数:param m: 模糊加权参数:param error: 迭代停止阈值,一般取0.001至0.01:return: 聚类结果''''''样本数量'''n=data.shape[0]'''数据维度'''dim=data.shape[1]'''初始化隶属度矩阵'''U0=initial_u0(n,K)U=U0.copy()'''存储目标函数值'''J=[]'''循环'''for i in range(Tmax):#计算隶属中心矩阵Z=center(data,U,m,n,K,dim)#基于欧氏距离计算各点到聚类中心的距离矩阵D=distinct(data,n,dim,Z,K)#计算目标函数的值J.append(function(data,Z,n,dim,K,U,m,D))#更新隶属度矩阵U=update_U(data,Z,n,dim,K,D,m)#判断阈值if i!=0 and abs(J[i-1]-J[i])<=error:break'''得到聚类结果'''cluster=Cluster(U,n)'''返回聚类结果(聚类类别,聚类中心,目标函数值)'''return cluster,Z,J[-1]'''主函数'''
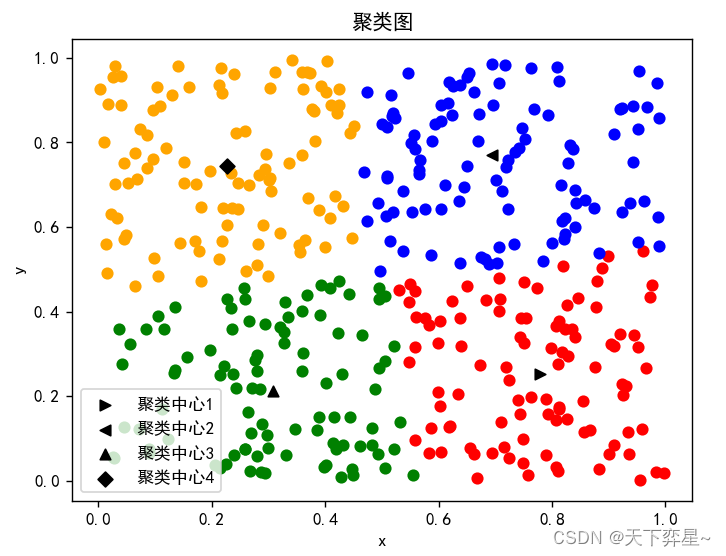
if __name__=="__main__":'''随机产生400组在区间[0,1]上的二维数据'''data=np.array([[random.uniform(0, 1) for i in range(2)] for j in range(400)])'''聚类'''cluster,cntr,J=FCM(data,K=4,Tmax=1000,m=2,error=0.0001)print("聚类结果:\n{}".format(cluster))print("目标函数值:\n{}".format(J))#将数据分类fdata=data.tolist()X1=[]Y1=[]X2=[]Y2=[]X3=[]Y3=[]X4=[]Y4=[]for i in range(400):if cluster[i]==0:X1.append(fdata[i][0])Y1.append(fdata[i][1])if cluster[i]==1:X2.append(fdata[i][0])Y2.append(fdata[i][1])if cluster[i]==2:X3.append(fdata[i][0])Y3.append(fdata[i][1])if cluster[i]==3:X4.append(fdata[i][0])Y4.append(fdata[i][1])# 聚类图plt.scatter(X1, Y1, c='red', marker='o')plt.scatter([cntr[0][0]], [cntr[0][1]], marker='>', c="black", label='聚类中心1')plt.scatter(X2, Y2, c='blue', marker="o")plt.scatter([cntr[1][0]], [cntr[1][1]], marker='<', c="black", label="聚类中心2")plt.scatter(X3, Y3, c='green', marker="o")plt.scatter([cntr[2][0]], [cntr[2][1]], marker='^', c="black", label="聚类中心3")plt.scatter(X4, Y4, c='orange', marker="o")plt.scatter([cntr[3][0]], [cntr[3][1]], marker="D", c="black", label="聚类中心4")plt.legend()plt.xlabel("x")plt.ylabel("y")plt.title("聚类图")plt.show()
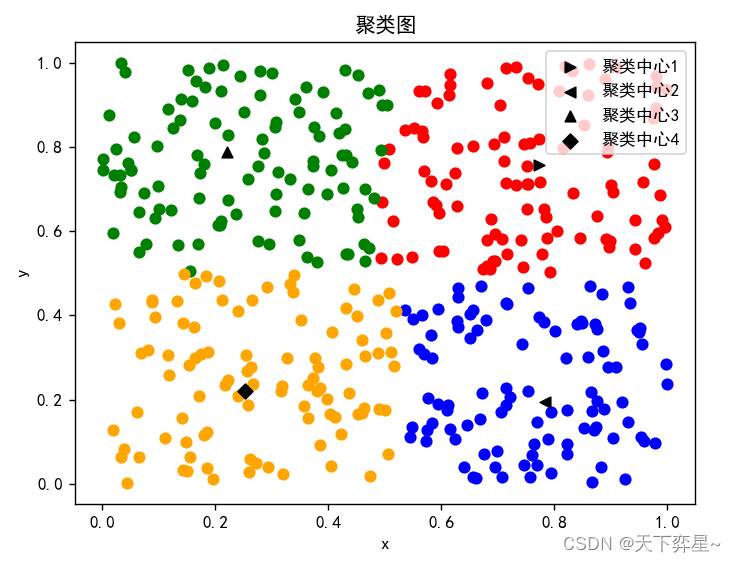
三、 使用skfuzzy的python代码
import numpy as np
import random
import skfuzzy as fuzz
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False'''随机产生400组在区间[0,1]上的二维数据'''
data = np.array([[random.uniform(0,1) for i in range(2)] for j in range(400)])'''初始化隶属度矩阵(聚成4类)'''
'''
cntr:聚类中心
u:最后的隶属度矩阵
u0:初始化的隶属度矩阵
d:是一个矩阵,记录每一个点到聚类中心的欧式距离
jm:是目标函数的优化历史
p:p是迭代的次数
fpc:全称是fuzzy partition coefficient, 是一个评价分类好坏的指标,它的范围是0到1, 1表示效果最好,后面可以通过它来选择聚类的个数。
'''
cntr, u, u0, d, jm, p, fpc = fuzz.cluster.cmeans(data.T, 4, 2, error=0.0001, maxiter=1000)'''迭代计算'''
cntr, u, u0, d, jm, p, fpc = fuzz.cluster.cmeans(data.T, 4,2, error=0.0001, maxiter=1000)'''获得聚类结果'''
cluster_membership = np.argmax(u, axis=0)'''绘制聚类结果'''
#将数据分类
fdata=data.tolist()
X1=[]
Y1=[]
X2=[]
Y2=[]
X3=[]
Y3=[]
X4=[]
Y4=[]
for i in range(400):if cluster_membership[i]==0:X1.append(fdata[i][0])Y1.append(fdata[i][1])if cluster_membership[i]==1:X2.append(fdata[i][0])Y2.append(fdata[i][1])if cluster_membership[i]==2:X3.append(fdata[i][0])Y3.append(fdata[i][1])if cluster_membership[i]==3:X4.append(fdata[i][0])Y4.append(fdata[i][1])#聚类图
plt.scatter(X1,Y1,c='red',marker='o')
plt.scatter([cntr[0][0]],[cntr[0][1]],marker='>',c="black",label='聚类中心1')
plt.scatter(X2,Y2,c='blue',marker="o")
plt.scatter([cntr[1][0]],[cntr[1][1]],marker='<',c="black",label="聚类中心2")
plt.scatter(X3,Y3,c='green',marker="o")
plt.scatter([cntr[2][0]],[cntr[2][1]],marker='^',c="black",label="聚类中心3")
plt.scatter(X4,Y4,c='orange',marker="o")
plt.scatter([cntr[3][0]],[cntr[3][1]],marker="D",c="black",label="聚类中心4")
plt.legend()
plt.xlabel("x")
plt.ylabel("y")
plt.title("聚类图")
plt.show()print(cluster_membership)
'''
print("cntr:\n{}".format(cntr))
print("u:\n{}".format(u))
print("u0:\n{}".format(u0))
print("d:\n{}".format(d))
print("jm:\n{}".format(jm))
print("p:\n{}".format(p))
print("fpc:\n{}".format(fpc))
'''