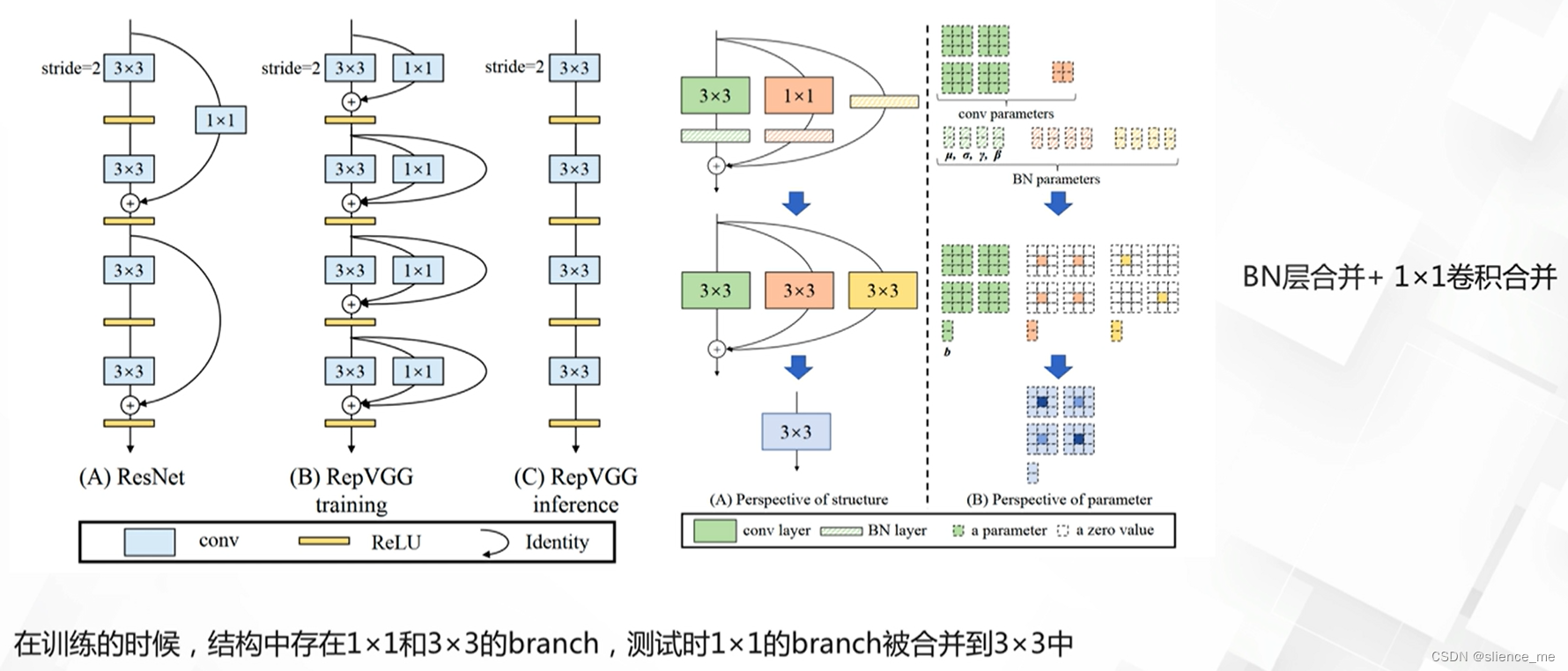
这篇文章介绍Reids最为常见的四种部署模式,其实Reids和数据库的集群模式差不多,可以分为 Redis单机模式部署、Redis主从模式部署、Redis哨兵模式部署、Cluster集群模式部署,其他的部署方式基本都是围绕以下几种方式在进行调整到适应的生产环境,最常见的还是集群模式的部署
接下来我们来主要分析和学习一下的部署方式和利弊。
约定信息:
系统:Linux CentOS 7.9
Redis版本:Redis 7.2.2
方案一:单机模式部署
编译部署
# 设置内核参数
[root@redis ~]# echo "vm.overcommit_memory=1" >> /etc/sysctl.conf
[root@redis ~]# echo "net.core.somaxconn=511" >> /etc/sysctl.conf
[root@redis ~]# sysctl # 查看生效情况# 下载二进制包并编译
[root@redis ~]# wget http://download.redis.io/releases/redis-7.2.2.tar.gz
[root@redis ~]# tar zxf redis-7.2.2.tar.gz -C /usr/local/
[root@redis ~]# cd /usr/local/redis-7.2.2/
[root@redis redis-7.2.2]# make# 编辑redis.conf配置文件
[root@redis redis-7.2.2]# vim redis.conf
# 绑定主机iP
bind 0.0.0.0
# 设置端口号
port 6379
# 启用后台运行
daemonize yes
# 设置redis密码
requirepass 123123# 启动并查看监听和进程
[root@redis ~]# /usr/local/redis-7.2.2/src/redis-server /usr/local/redis-7.2.2/redis.conf [root@redis ~]# ps -ef | grep redis
root 878 1 0 23:24 ? 00:00:00 /sbin/dhclient -q -lf /var/lib/dhclient/dhclient--eth0.lease -pf /var/run/dhclient-eth0.pid -H redis eth0
root 12429 1 0 23:42 ? 00:00:00 /usr/local/redis-7.2.2/src/redis-server 0.0.0.0:6379
root 12505 12289 0 23:43 pts/1 00:00:00 grep --color=auto redis
[root@redis ~]# netstat -tnlp | grep redis
tcp 0 0 0.0.0.0:6379 0.0.0.0:* LISTEN 12429/redis-server# 停止
[root@redis ~]# ./redis-cli -p 6379 -a 123123 shutdown# 客户端连接测试测试
[root@redis ~]# /usr/local/redis-7.2.2/src/redis-cli
127.0.0.1:6379> auth 123123
OK
127.0.0.1:6379> set flag if010.com
OK
127.0.0.1:6379> get flag
"if010.com"
127.0.0.1:6379>
使用systemctl进行管理
[root@redis ~]# cp ../utils/redis_init_script /etc/init.d/redis #不同版本可能位置不同[root@redis ~]# vim /etc/init.d/redisPort : 6379Config file : /usr/local/redis/conf/redis.confLog file : /usr/local/redis/log/redis.logData dir : /usr/local/redis/dataExecutable : /usr/local/redis/bin/redis-server /usr/local/redis/conf/redis.confCli Executable : /usr/local/redis/bin/redis-cli# redis Start up the redis server daemon## chkconfig: 2345 55 25添加chkconfig 开机启动 ....redis.service[Unit]Description=Redis ServerAfter=network-online.target[Service]Type=forkingPIDFile=/var/run/redis_6379.pidExecStart=/etc/init.d/redis startExecStop=/etc/init.d/redis stopExecReload=/etc/init.d/redis reloadPrivateTmp=true[Install]WantedBy=multi-user.target
至此单机模式就部署完成了,优点嘛就是能用,缺点就是故障了就无法提供服务,且没有备份,所以接下来介绍第二种方案—主从模式部署
单点服务器带来的问题
- 单点故障,服务不可用
- 无法处理大量的并发数据
- 数据丢失----大灾难
- 开启多Redis进程
- Redis默认单进程
- 开启多进程导致CPU压力过大
- 对于服务器(纵向)消耗服务器硬件性能CPU
方案二:主从模式部署
Redis主从原理
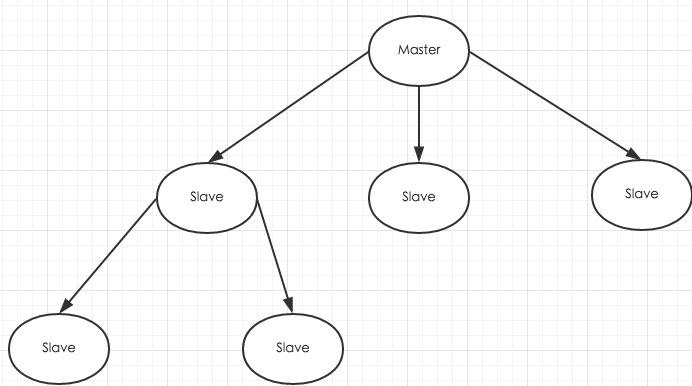
和MySQL需要主从复制的原因一样,Redis虽然读取写入的速度都特别快,但是也会产生性能瓶颈,特别是在读压力上,为了分担压力,Redis支持主从复制。Redis的主从结构一主一从,一主多从或级联结构,复制类型可以根据是否是全量而分为全量同步和增量同步。
下图为级联结构:
Redis主从同步的策略
主从同步刚连接的时候进行全量同步;全量同步结束后开始增量同步。如果有需要,slave在任何时候都可以发起全量同步,其主要策略就是无论如何首先会尝试进行增量同步,如果不成功,则会要求slave进行全量同步,之后再进行增量同步。
注意:如果多个slave同时断线需要重启的时候,因为只要slave启动,就会和master建立连接发送SYNC请求和主机全量同步,如果多个同时发送SYNC请求,可能导致master IO突增而发送宕机。
全量同步
Redis全量同步一般发生在slave的初始阶段,这时slave需要将master上的数据都复制一份,具体步骤如下:
- slave连接master,发送SYNC命令;
- master街道SYNC命令后,执行BGSAVE命令生产RDB文件并使用缓冲区记录此后执行的所有写命令;
- master的BGSAVE执行完成后,向所有的slave发送快照文件,并在发送过程中继续记录执行的写命令;
- slave收到快照后,丢弃所有的旧数据,载入收到的数据;
- master快照发送完成后就会开始向slave发送缓冲区的写命令;
- slave完成对快照的载入,并开始接受命令请求,执行来自master缓冲区的写命令;
- slave完成上面的数据初始化后就可以开始接受用户的读请求了。
大致流程如下:

增量复制
增量复制实际上就是在slave初始化完成后开始正常工作时master发生写操作同步到slave的过程。增量复制的过程主要是master每执行一个写命令就会向slave发送相同的写命令,slave接受并执行写命令,从而保持主从一致。
Redis主从同步的特点
- 采用异步复制;
- 可以一主多从;
- 主从复制对于master来说是非阻塞的,也就是说slave在进行主从复制的过程中,master依然可以处理请求;
- 主从复制对于slave来说也是非阻塞的,也就是说slave在进行主从复制的过程中也可以接受外界的查询请求,只不过这时候返回的数据不一定是正确的。为了避免这种情况发生,可以在slave的配置文件中配置,在同步过程中阻止查询;
- 每个slave可以接受来自其他slave的连接;
- 主从复制提高了Redis服务的扩展性,避免单节点问题,另外也为数据备份冗余提供了一种解决方案;
- 为了降低主redis服务器写磁盘压力带来的开销,可以配置让主redis不在将数据持久化到磁盘,而是通过连接让一个配置的从redis服务器及时的将相关数据持久化到磁盘,不过这样会存在一个问题,就是主redis服务器一旦重启,因为主redis服务器数据为空,这时候通过主从同步可能导致从redis服务器上的数据也被清空;
部署方式
环境约定:Master节点:172.17.0.100、Slave1节点:172.17.0.101、Slave2节点:172.17.0.102
部署思路:先配置好Master节点,然后拷贝到Slave1节点上,在Master节点的配置基础上再配置replicaof和masterauth,其他节点直接拷贝Slave1节点上的配置文件即可
编译安装
编译安装好Redis环境(所有节点操作)
# 下载软件包
[root@Redis-Test1 ~]# wget http://download.redis.io/releases/redis-7.2.2.tar.gz# 解压软件包
[root@Redis-Test1 ~]# tar zxf redis-7.2.2.tar.gz -C /usr/local/
[root@Redis-Test1 ~]# cd /usr/local/redis-7.2.2/
[root@Redis-Test1 redis-7.2.2]# ls
00-RELEASENOTES CODE_OF_CONDUCT.md COPYING INSTALL MANIFESTO redis.conf runtest-cluster runtest-sentinel sentinel.conf tests utils
BUGS CONTRIBUTING.md deps Makefile README.md runtest runtest-moduleapi SECURITY.md src TLS.md# 编译
[root@redis-master-01 ~]# make
编辑配置文件
修改Redis的配置文件(Master节点操作)
[root@Redis-Test1 redis-7.2.2]# vim redis.confbind 0.0.0.0
port 6379
daemonize yes
pidfile /data/redis/redis.pid
logfile "/data/redis/logs/redis.log"
appendonly yes #开启AOF持久化
requirepass 123123
dir /data/redis/
修改Redis的配置文件(Slave节点操作)
[root@Redis-Test2 redis-7.2.2]# vim redis.conf bind 0.0.0.0
port 6379
daemonize yes
pidfile /data/redis/redis.pid
logfile "/data/redis/logs/redis.log"
appendonly yes
requirepass 123123
dir /data/redis/replicaof 172.17.0.100 6379 #指定要同步的master节点ip和端口
masterauth 123123 #指定master的认证口令
启动
这里要注意一下,先启动Master节点,然后在启动Slave节点
/usr/local/redis-7.2.2/src/redis-server /usr/local/redis-7.2.2/redis.conf
验证主从效果
从日志上分析验证
[root@Redis-Test2 logs]# tailf redis.log
9025:S 01 Nov 2023 17:45:28.450 * Done loading RDB, keys loaded: 0, keys expired: 0.
9025:S 01 Nov 2023 17:45:28.450 * DB loaded from base file appendonly.aof.1.base.rdb: 0.001 seconds
9025:S 01 Nov 2023 17:45:28.450 * DB loaded from append only file: 0.001 seconds
9025:S 01 Nov 2023 17:45:28.450 * Opening AOF incr file appendonly.aof.1.incr.aof on server start
9025:S 01 Nov 2023 17:45:28.450 * Ready to accept connections tcp
9025:S 01 Nov 2023 17:45:28.450 * Connecting to MASTER 172.17.0.100:6379
9025:S 01 Nov 2023 17:45:28.450 * MASTER <-> REPLICA sync started
9025:S 01 Nov 2023 17:45:28.451 * Non blocking connect for SYNC fired the event.
9025:S 01 Nov 2023 17:45:28.451 * Master replied to PING, replication can continue...
9025:S 01 Nov 2023 17:45:28.451 * Partial resynchronization not possible (no cached master)
9025:S 01 Nov 2023 17:45:33.418 * Full resync from master: d9da2499f5cdb878a424e33159ec2b795ea7db17:14
9025:S 01 Nov 2023 17:45:33.419 * MASTER <-> REPLICA sync: receiving streamed RDB from master with EOF to disk
9025:S 01 Nov 2023 17:45:33.419 * MASTER <-> REPLICA sync: Flushing old data
9025:S 01 Nov 2023 17:45:33.419 * MASTER <-> REPLICA sync: Loading DB in memory
9025:S 01 Nov 2023 17:45:33.422 * Loading RDB produced by version 7.2.2
9025:S 01 Nov 2023 17:45:33.422 * RDB age 0 seconds
9025:S 01 Nov 2023 17:45:33.422 * RDB memory usage when created 0.94 Mb
9025:S 01 Nov 2023 17:45:33.422 * Done loading RDB, keys loaded: 0, keys expired: 0.
9025:S 01 Nov 2023 17:45:33.422 * MASTER <-> REPLICA sync: Finished with success
9025:S 01 Nov 2023 17:45:33.422 * Creating AOF incr file temp-appendonly.aof.incr on background rewrite
9025:S 01 Nov 2023 17:45:33.423 * Background append only file rewriting started by pid 9031
9031:C 01 Nov 2023 17:45:33.424 * Successfully created the temporary AOF base file temp-rewriteaof-bg-9031.aof
9031:C 01 Nov 2023 17:45:33.425 * Fork CoW for AOF rewrite: current 4 MB, peak 4 MB, average 4 MB
9025:S 01 Nov 2023 17:45:33.466 * Background AOF rewrite terminated with success
9025:S 01 Nov 2023 17:45:33.466 * Successfully renamed the temporary AOF base file temp-rewriteaof-bg-9031.aof into appendonly.aof.2.base.rdb
9025:S 01 Nov 2023 17:45:33.466 * Successfully renamed the temporary AOF incr file temp-appendonly.aof.incr into appendonly.aof.2.incr.aof
9025:S 01 Nov 2023 17:45:33.469 * Removing the history file appendonly.aof.1.incr.aof in the background
9025:S 01 Nov 2023 17:45:33.469 * Removing the history file appendonly.aof.1.base.rdb in the background
9025:S 01 Nov 2023 17:45:33.472 * Background AOF rewrite finished successfully
从Master节点上查看节点信息
[root@Redis-Test1 redis-7.2.2]# ./src/redis-cli
127.0.0.1:6379> auth 123123
OK
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=172.17.0.101,port=6379,state=online,offset=98,lag=1
slave1:ip=172.17.0.102,port=6379,state=online,offset=98,lag=1
master_failover_state:no-failover
master_replid:d9da2499f5cdb878a424e33159ec2b795ea7db17
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:98
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:98
方案三:哨兵模式部署
Sentinel是Redis官方为集群提供的高可用解决方案。 在实际项目中可以使用sentinel去做redis自动故障转移,减少人工介入的工作量,另外sentinel也给客户端提供了监控消息的通知,这样客户端就可根据消息类型去判断服务器的状态,去做对应的适配操作
Sentinel 哨兵的作用
- Monitoring(集群监控):Sentinel持续检查集群中的master、slave状态,判断是否存活
- Notification(消息通知):在发现某个redis实例死的情况下,Sentinel能通过API通知系统管理员或其他程序脚本
- Automatic failover(故障转移):如果一个master挂掉后,sentinel会启动故障转移,把某个slave提升为master,其他的slave重新配置指向新master
- Configuration provider(配置中心):对于客户端来说sentinel通知是有效可信赖的,客户端会连接sentinel去请求当前master的地址,一旦发生故障sentinel会提供新地址给客户端
核心功能:在主从复制的基础上,哨兵引入了主节点的自动故障转移
哨兵的核心
- 哨兵至少需要 3 个实例,来保证自己的健壮性
- 哨兵 + redis 主从的部署架构,是不保证数据零丢失的,只能保证 redis 集群的高可用性
对于哨兵 + redis 主从这种复杂的部署架构,尽量在测试环境和生产环境,都进行充足的测试和演练
哨兵模式的故障迁移
- 主观下线
哨兵(Sentinel)节点会每秒一次的频率向建立了命令连接的实例发送PING命令,如果在down-after-milliseconds毫秒内没有做出有效响应包括(PONG/ LOADING/MASTERDOWN)以外的响应,哨兵就会将该实例在本结构体中的状态标记为SRI_s_DOWN主观下线 - 客观下线
当一个哨兵节点发现主节点处于主观下线状态是,会向其他的哨兵节点发出询问,该节点是不是已经主观下线了。如果超过配置参数quorum个节点认为是主观下线时,该哨兵节点就会将自己维护的结构体中该主节点标记为SRIO DOWN客观下线询问命令SENTINEL is-master-down-by-addr - master选举
在认为主节点客观下线的情况下,哨兵节点节点间会发起一次选举,命令为:SENTINEL is-master-down-by-addr只是runid这次会将自己的runid带进去, 希望接受者将自己设置为主节点。如果超过半数以上的节点返回将该节点标记为leacer的情况下,会有该leader对故障进行迁移
master选举规则
新主库选择:哨兵在选择新主库时,先按照一定的筛选条件,把不符合条件的从库去掉,再按照一定的规则,给剩下的从库逐个打分,将得分最高的从库选为新主库
从库筛选
在选主时,除了要检查从库的当前在线状态,还要判断它之前的网络连接状态,如果从库总是和主库断连,而且断连次数超出了一定的阈值,表明这个从库的网络状况并不是太好,就可以把这个从库去掉了
在sentinel配置项down-after-milliseconds * 10中,down-after-milliseconds 是认定主从库断连的最大连接超时时间,如果在down-aftermilliseconds毫秒内,主从节点都没有通过网络联系上,就可以认为主从节点断连了,如果发生断连的次数超过了10次,就说明这个从库的网络状况不好,不适合作为新主库
从库分数判断
Sentinle集群选主中,分别按照三个规则依次进行三轮打分,这三个规则分别是从库优先级、从库复制进度以及从库 ID 号,只要在某一轮中,有从库得分最高,那么它就是主库了,选主过程到此结束,如果没有出现得分最高的从库,那么就继续进行下一轮
第一轮:优先级最高的从库得分高
用户可以通过slave-priority配置项,给不同的从库设置不同优先级,比如,有两个从库,它们的内存大小不一样,可以手动给内存大的实例设置一个高优先级,在选主时, 哨兵会给优先级高的从库打高分,如果有一个从库优先级最高,那么它就是新主库了,如果从库的优先级都一样,那么哨兵开始第二轮打分
第二轮:和旧主库同步程度最接近的从库得分高
这个规则的依据是,如果选择和旧主库同步最接近的那个从库作为主库,那么,这个新主库上就有最新的数据
如何判断从库和旧主库间的同步进度呢?
主从库同步时有个命令传播的过程。在这个过程中,主库会用master_repl_offset记录当前的最新写操作在 repl_backlog_buffer中的位置,而从库会用slave_repl_offset这个值记录当前的复制进度
此时,我们想要找的从库,它的slave_repl_offset需要最接近master_repl_offset,如果在所有从库中,有从库的slave_repl_offset最接近master_repl_offset,那么它的得分就最高,可以作为新主库,但并不是取slave_repl_offset与master_repl_offset做对比,而是不同从库的slave_repl_offset进行对比的,因为这个时候master已经挂掉了,无法获取master_repl_offset,所以在实际的选主代码中,哨兵在这一步,是通过比较不同从库的slave_repl_offset,找出最大slave_repl_offset的从库,也就是选择salve_repl_offset最大的那个从库
master_repl_offset机制:master_repl_offset是单调增加的,它的值可以大于repl_backlog_size。Redis会用一个名为repl_backlog_idx的值记录在环形缓冲区中的最新写入位置
举个例子,例如写入len的数据,那么 master_repl_offset += len > repl_backlog_idx += len,但是,如果repl_backlog_idx等于repl_backlog_size时,repl_backlog_idx会被置为0,表示从环形缓冲区开始位置继续写入
第三轮:ID 号小的从库得分高
每个实例都会有一个 ID,这个 ID 就类似于这里的从库的编号,目前Redis在选主库时,有一个默认的规定:在优先级和复制进度都相同的情况下,ID 号最小的从库得分最高,会被选为新主库,Redis server启动时,会生成一个40字节长的随机字符串作为runID,具体算法用的是 SHA-1算法
部署方式
环境约定:Master节点:172.17.0.100、Slave1节点:172.17.0.101、Slave2节点:172.17.0.102
部署思路:先配置好主从模式的环境,然后再修改sentinel.conf配置文件,最后启动即可
编译安装
编译安装好Redis环境(所有节点操作)
# 下载软件包
[root@Redis-Test1 ~]# wget http://download.redis.io/releases/redis-7.2.2.tar.gz# 解压软件包
[root@Redis-Test1 ~]# tar zxf redis-7.2.2.tar.gz -C /usr/local/
[root@Redis-Test1 ~]# cd /usr/local/redis-7.2.2/
[root@Redis-Test1 redis-7.2.2]# ls
00-RELEASENOTES CODE_OF_CONDUCT.md COPYING INSTALL MANIFESTO redis.conf runtest-cluster runtest-sentinel sentinel.conf tests utils
BUGS CONTRIBUTING.md deps Makefile README.md runtest runtest-moduleapi SECURITY.md src TLS.md# 编译
[root@redis-master-01 ~]# make
编辑redis配置文件
修改Redis的配置文件(Master节点操作)
[root@Redis-Test1 redis-7.2.2]# vim redis.confbind 0.0.0.0
port 6379
daemonize yes
pidfile /data/redis/redis.pid
logfile "/data/redis/logs/redis.log"
appendonly yes #开启AOF持久化
requirepass 123123
dir /data/redis/
修改Redis的配置文件(Slave节点操作)
[root@Redis-Test2 redis-7.2.2]# vim redis.conf bind 0.0.0.0
port 6379
daemonize yes
pidfile /data/redis/redis.pid
logfile "/data/redis/logs/redis.log"
appendonly yes
requirepass 123123
dir /data/redis/replicaof 172.17.0.100 6379 #指定要同步的master节点ip和端口
masterauth 123123 #指定master的认证口令
启动Redis服务
这里要注意一下,先启动Master节点,然后在启动Slave节点
/usr/local/redis-7.2.2/src/redis-server /usr/local/redis-7.2.2/redis.conf
到此结束主从环境的配置,接下来配置哨兵环节
配置Sentinel配置文件
修改Redis哨兵模式的配置文件(所有节点操作)
[root@Redis-Test1 redis-7.2.2]# vim sentinel.conf bind 0.0.0.0
port 26379
daemonize yes #哨兵的启动模式,yes是后台启动
pidfile /data/redis/redis-sentinel.pid #哨兵的pid文件存放位置
logfile "/data/redis/logs/redis-sentinel.log" #哨兵的日志文件存放位置
dir /data #哨兵进程的工作目录,默认就是/tmp#哨兵监听的master数据库,mymaster是为主数据库起的名称,可以随便起个名字,后面是master的ip和端口
# 最后面的1表示选举个数,含义是需要多少个哨兵认为master挂了才认定master挂掉,这里我设置为1是因为我只有一个哨兵,如果你配置了多个哨兵,建议配置2以上数字。
sentinel monitor mymaster 172.17.0.100 6379 1
sentinel auth-pass mymaster 123123 #配置master的登陆密码,mymaster是你配置的master名称
sentinel down-after-milliseconds mymaster 30000 #30秒内master无响应则认为master挂掉
acllog-max-len 128 #保持默认即可#master重新选举之后,其它节点能同时并行进行数据同步的台数有多少台
#显然该值越大,则所有slave能同步完成的速度越快,但如果此时刚好有人访问slave数据,可能造成读取失败,最保守的值建议设为1
#即同一时间只能有一台进行数据同步,这样其它slave还能继续提供服务,但是所有的slave数据同步完成就会显得缓慢。
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000 #故障转移超时时间,指在该时间内如果故障转移没有成功,则会再发起一次故障转移
sentinel deny-scripts-reconfig yes #保持默认即可
SENTINEL resolve-hostnames no #保持默认即可
SENTINEL announce-hostnames no #保持默认即可
启动哨兵服务
先启master的哨兵,再启slave的哨兵
/usr/local/redis-7.2.2/src/redis-sentinel /usr/local/redis-7.2.2/sentinel.conf
查看相关信息
[root@Redis-Test3 redis-7.2.2]# ./src/redis-cli -p 26379
127.0.0.1:26379> info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_tilt_since_seconds:-1
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=172.17.0.100:6379,slaves=2,sentinels=1
验证故障转移
关闭Master节点,观察日志和sentinel信息
12697:X 01 Nov 2023 19:45:57.990 # +monitor master mymaster 172.17.0.100 6379 quorum 1
12697:X 01 Nov 2023 19:47:10.430 # +sdown master mymaster 172.17.0.100 6379
12697:X 01 Nov 2023 19:47:10.430 # +odown master mymaster 172.17.0.100 6379 #quorum 1/1
12697:X 01 Nov 2023 19:47:10.430 # +new-epoch 1
12697:X 01 Nov 2023 19:47:10.430 # +try-failover master mymaster 172.17.0.100 6379
12697:X 01 Nov 2023 19:47:10.434 * Sentinel new configuration saved on disk
12697:X 01 Nov 2023 19:47:10.434 # +vote-for-leader 02f863db4ebd9962c4557bcad9ec78afd2b86613 1
12697:X 01 Nov 2023 19:47:10.434 # +elected-leader master mymaster 172.17.0.100 6379
12697:X 01 Nov 2023 19:47:10.434 # +failover-state-select-slave master mymaster 172.17.0.100 6379
12697:X 01 Nov 2023 19:47:10.517 # +selected-slave slave 172.17.0.102:6379 172.17.0.102 6379 @ mymaster 172.17.0.100 6379
12697:X 01 Nov 2023 19:47:10.517 * +failover-state-send-slaveof-noone slave 172.17.0.102:6379 172.17.0.102 6379 @ mymaster 172.17.0.100 6379
12697:X 01 Nov 2023 19:47:10.690 * +failover-state-wait-promotion slave 172.17.0.102:6379 172.17.0.102 6379 @ mymaster 172.17.0.100 6379
12697:X 01 Nov 2023 19:47:11.607 * Sentinel new configuration saved on disk
12697:X 01 Nov 2023 19:47:11.607 # +promoted-slave slave 172.17.0.102:6379 172.17.0.102 6379 @ mymaster 172.17.0.100 6379
12697:X 01 Nov 2023 19:47:11.607 # +failover-state-reconf-slaves master mymaster 172.17.0.100 6379
12697:X 01 Nov 2023 19:47:11.703 * +slave-reconf-sent slave 172.17.0.101:6379 172.17.0.101 6379 @ mymaster 172.17.0.100 6379
12697:X 01 Nov 2023 19:47:12.814 * +slave-reconf-inprog slave 172.17.0.101:6379 172.17.0.101 6379 @ mymaster 172.17.0.100 6379
12697:X 01 Nov 2023 19:47:12.814 * +slave-reconf-done slave 172.17.0.101:6379 172.17.0.101 6379 @ mymaster 172.17.0.100 6379
12697:X 01 Nov 2023 19:47:12.866 # +failover-end master mymaster 172.17.0.100 6379
12697:X 01 Nov 2023 19:47:12.866 # +switch-master mymaster 172.17.0.100 6379 172.17.0.102 6379
12697:X 01 Nov 2023 19:47:12.867 * +slave slave 172.17.0.101:6379 172.17.0.101 6379 @ mymaster 172.17.0.102 6379
12697:X 01 Nov 2023 19:47:12.867 * +slave slave 172.17.0.100:6379 172.17.0.100 6379 @ mymaster 172.17.0.102 6379
12697:X 01 Nov 2023 19:47:12.871 * Sentinel new configuration saved on disk
12697:X 01 Nov 2023 19:47:42.911 # +sdown slave 172.17.0.100:6379 172.17.0.100 6379 @ mymaster 172.17.0.102 6379
[root@Redis-Test3 redis-7.2.2]# ./src/redis-cli -p 26379
127.0.0.1:26379> info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_tilt_since_seconds:-1
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=172.17.0.102:6379,slaves=2,sentinels=1[root@Redis-Test3 redis-7.2.2]# ./src/redis-cli
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=172.17.0.101,port=6379,state=online,offset=55358,lag=0
master_failover_state:no-failover
master_replid:1bc5d3796192e6c518baa423a3d24573a0360abd
master_replid2:0963bdef90dddf0294c0972160a9476e40345768
master_repl_offset:55358
second_repl_offset:8434
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:55358
关于切换不成功常见的问题
无法切换,有几种情况:
- redis保护模式开启了
- 选举个数多了或者少了
- 端口没有放开
- master密码和从密码不一致
- master节点的redis.conf没有添加masterauth
方案四:集群模式部署
集群,即Redis Cluster,是Redis 3.0开始引入的分布式存储方案,集群由多个节点(Node)组成,Redis的数据分布在这些节点中,集群中的节点分为主节点和从节点:只有主节点负责读写请求和集群信息的维护,从节点只进行主节点数据和状态信息的复制
Redis-Cluster集群的作用
- 数据分区: 数据分区(或称数据分片)是集群最核心的功能,集群将数据分散到多个节点,一方面突破了Redis单机内存大小的限制,存储容量大大增加,另一方面每个主节点都可以对外提供读服务和写服务,大大提高了集群的响应能力,Redis单机内存大小受限问题,在介绍持久化和主从复制时都有提及,例如,如果单机内存太大,bgsave和bgrewriteaof 的保存操作可能导致主进程阻塞,主从环境下主机切换时可能导致从节点长时间无法提供服务,全量复制阶段主节点的复制缓冲区可能溢出
- 高可用: 集群支持主从复制和主节点的自动故障转移(与哨兵类似)当任一节点发生故障时,集群仍然可以对外提供服务
Redis集群的数据分片
Redis集群引入了哈希槽的概念,Redis集群有16384个哈希槽(编号0-16383)集群的每个节点负责部分哈希槽,每个Key通过CRc16校验后对16384取余来决定放置哪个哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作
以3个节点组成的集群为例:
节点A包含0到5460号哈希槽
节点B包含5461到10922号哈希槽
节点C包含10923到16383号哈希槽
Redis集群的主从复制模型
集群中具有A、B、C三个节点,如果节点B失败了,整个集群就会因缺少5461-10922这个范围的槽而不可以用,为每个节点添加一个从节点A1、B1、C1整个集群便有三个Master节点和三个slave 节点组成,在节点B失败后,集群选举一位为主节点继续服务,但是要注意的是当B和B1都失败后,集群将不可用
Redis Cluster的工作原理
在哨兵sentinel机制中,可以解决redis高可用问题,即当master故障后可以自动将slave提升为master,从而可以保证redis服务的正常使用,但是无法解决redis单机写入的瓶颈问题,即单机redis写入性能受限于单机的内存大小、并发数量、网卡速率等因素
部署方式
环境约定:
- Master节点:172.17.0.101、172.17.0.103、172.17.0.105
- Slave节点:172.17.0.102、172.17.0.104、172.17.0.106
部署思路:安装部署好所有节点的redis服务并启动,然后使用自动部署集群工具设定集群
编译安装
# 下载软件包
[root@redis-master-01 ~]# wget http://download.redis.io/releases/redis-7.2.2.tar.gz# 解压软件包
[root@redis-master-01 ~]# tar zxf redis-7.2.2.tar.gz -C /usr/local/
[root@redis-master-01 ~]# cd /usr/local/redis-7.2.2/
[root@redis-master-01 redis-7.2.2]# ls
00-RELEASENOTES CODE_OF_CONDUCT.md COPYING INSTALL MANIFESTO redis.conf runtest-cluster runtest-sentinel sentinel.conf tests utils
BUGS CONTRIBUTING.md deps Makefile README.md runtest runtest-moduleapi SECURITY.md src TLS.md# 编译
[root@redis-master-01 ~]# make
编辑配置文件
# 编辑配置文件
vim /usr/local/redis-7.2.2/redis.conf
# 监听端口
port 6379# IP不限制,习惯改成0了,必须,避免后面出现麻烦,如果是外网,必须!
bind 0.0.0.0# 设置Redis实例pid文件
pidfile /data/redis/redis.pid# 后台模式,必须
daemonize yes
# 仅追加
appendonly yes
appendfsync always# 集群开启,必须
cluster-enabled yes# 节点信息,可选,因为系统会默认
cluster-config-file nodes.conf# 设置当前节点连接超时毫秒数
cluster-node-timeout 15000# 数据存放目录
dir /data/redis/# 认证密码
requirepass 123123# 设置客户端连接时的超时时间,单位为秒
timeout 60# 日志等级:debug,revbose,notice和warning
loglevel notice
# 配置log文件地址,默认使用标准输出
logfile "/data/redis/logs/redis.log"# 设置数据库的个数,默认使用的数据库是0
databases 16# 设置redis进行数据库镜像的频率
save 900 1 300 10 60 10000# 镜像备份文件的文件名
dbfilename dump.rdb
启动Redis
# 启动Redis
[root@redis-master-01 redis-7.2.2]# /usr/local/redis-7.2.2/src/redis-server /usr/local/redis-7.2.2/redis.conf
[root@redis-master-01 ~]# netstat -tnlp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1083/sshd
tcp 0 0 0.0.0.0:16379 0.0.0.0:* LISTEN 10980/redis-server
tcp 0 0 0.0.0.0:6379 0.0.0.0:* LISTEN 10980/redis-server
验证服务
验证没有问题后其余的节点也是这么配置即可~
自动搭建集群
Redis 3.0 版本之后官方发布了一个集群管理工具 redis-trib.rb,集成在 Redis 源码包的src目录下。其封装了 Redis 提供的集群命令,使用简单、便捷。不过 redis-trib.rb 是 Redis 作者使用 Ruby 语言开发的,故使用该工具之前还需要先在机器上安装 Ruby 环境。后面作者可能意识到这个问题,Redis 5.0 版本开始便把这个工具集成到 redis-cli 中,以–cluster参数提供使用,其中create命令可以用来创建集群。如果您安装的 Redis 是 3.x 和 4.x 的版本可以使用 redis-trib.rb 搭建,不过之前需要安装 Ruby 环境。先使用 yum 安装 Ruby 环境以及其他依赖项:
yum -y install ruby ruby-devel rubygems rpm-build
查看ruby版本
ruby -v
确认没有问题之后,我们就可以创建集群了
./redis-cli -a 123123 --cluster create 172.17.0.101:6379 172.17.0.103:6379 172.17.0.105:6379 172.17.0.102:6379 172.17.0.104:6379 172.17.0.106:6379 --cluster-replicas 1
注意:主节点在前,从节点在后。其中–cluster-replicas参数用来指定一个主节点带有的从节点个数,如上–cluster-replicas 1即表示 1 个主节点有 1 个从节点
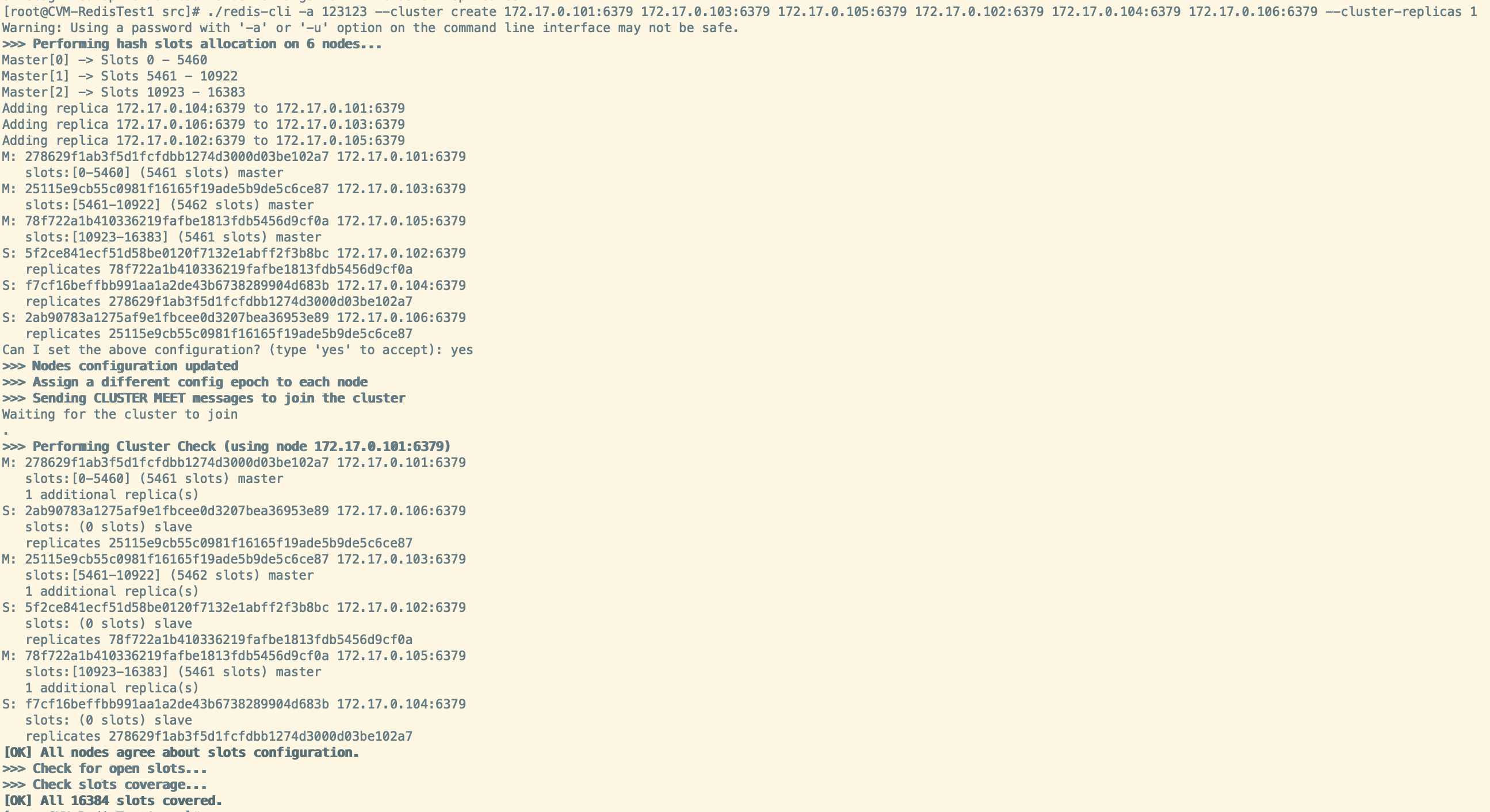
至此,Redis集群搭建完毕!
我们可以查看一下节点信息,用一下命令或者可查看redis任意一个目录下的 nodes.conf配置文件
[root@redis-master-01 ~]# cat /data/redis/nodes.conf
5f2ce841ecf51d58be0120f7132e1abff2f3b8bc 172.17.0.102:6379@16379,,tls-port=0,shard-id=327de171b1a685bf6f4741253bb8dc7c3134b7b4 slave 78f722a1b410336219fafbe1813fdb5456d9cf0a 0 1698661133000 3 connected
25115e9cb55c0981f16165f19ade5b9de5c6ce87 172.17.0.103:6379@16379,,tls-port=0,shard-id=19c2b46d9a0d0038ae1b57f6c7c4449eb6647c6f master - 0 1698661133000 2 connected 5461-10922
f7cf16beffbb991aa1a2de43b6738289904d683b 172.17.0.104:6379@16379,,tls-port=0,shard-id=8d019b1cdda30d0ad959a197c7cf6308016d1999 slave 278629f1ab3f5d1fcfdbb1274d3000d03be102a7 0 1698661131000 1 connected
2ab90783a1275af9e1fbcee0d3207bea36953e89 172.17.0.106:6379@16379,,tls-port=0,shard-id=19c2b46d9a0d0038ae1b57f6c7c4449eb6647c6f slave 25115e9cb55c0981f16165f19ade5b9de5c6ce87 1698661126915 1698661124000 2 disconnected
278629f1ab3f5d1fcfdbb1274d3000d03be102a7 172.17.0.101:6379@16379,,tls-port=0,shard-id=8d019b1cdda30d0ad959a197c7cf6308016d1999 myself,master - 0 1698661124000 1 connected 0-5460
78f722a1b410336219fafbe1813fdb5456d9cf0a 172.17.0.105:6379@16379,,tls-port=0,shard-id=327de171b1a685bf6f4741253bb8dc7c3134b7b4 master - 0 1698661133000 3 connected 10923-16383
vars currentEpoch 6 lastVoteEpoch 0
或者
[root@redis-master-01 ~]# /usr/local/redis-7.2.2/src/redis-cli -c -h 172.17.0.101 -a 123123
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
172.17.0.101:6379> cluster nodes
5f2ce841ecf51d58be0120f7132e1abff2f3b8bc 172.17.0.102:6379@16379 slave 78f722a1b410336219fafbe1813fdb5456d9cf0a 0 1698661185010 3 connected
25115e9cb55c0981f16165f19ade5b9de5c6ce87 172.17.0.103:6379@16379 master - 0 1698661182000 2 connected 5461-10922
f7cf16beffbb991aa1a2de43b6738289904d683b 172.17.0.104:6379@16379 slave 278629f1ab3f5d1fcfdbb1274d3000d03be102a7 0 1698661184000 1 connected
2ab90783a1275af9e1fbcee0d3207bea36953e89 172.17.0.106:6379@16379 slave 25115e9cb55c0981f16165f19ade5b9de5c6ce87 0 1698661185000 2 connected
278629f1ab3f5d1fcfdbb1274d3000d03be102a7 172.17.0.101:6379@16379 myself,master - 0 1698661180000 1 connected 0-5460
78f722a1b410336219fafbe1813fdb5456d9cf0a 172.17.0.105:6379@16379 master - 0 1698661184008 3 connected 10923-16383

注意:
链接时候,务必选择集群模式链接(如果你链接失败,可以重新看上面配置文件部分,或者往下看)
由于自动生成的nodes.conf文件里面,会默认生成带有内网IP,所以你如果是要使用外网链接,就去把每一个Redis目录下的
/data/redis/nodes.conf配置文件里面IP为内网的改成外网,并且16379端口也要被允许访问(注意防火墙问题),然后再重启所有Redis!不用再重新创建集群!
附录:Redis配置参数介绍
基础配置
bind
默认配置:bind 127.0.0.1,如果没用通过bind命令明确绑定ip,redis可以监听到请求过来的所有网络接口,
bind后面拼接1个或多个ip地址,那么该redis实例只能监听到来自这几个ip的请求,
# 举例
bind 192.168.1.100 10.0.0.1
bind 127.0.0.1 ::1
# redis默认配置的是只允许本机访问:bind 127.0.0.1
# 如果需要redis允许其他ip访问,那么注释掉默认配置即可:#bind 127.0.0.1
port
默认配置:port 6379,port用来配置redis接受连接的端口,即监听端口
protected-mode
默认配置:protected-mode yes,protected mode是一个安全保护层,用来避免redis实例暴漏在互联网被访问或者利用,如果开启保护模式并且没有通过bind绑定外部的ip地址并且没有通过requirepass配置密码,那么该redis实例只能接受本地127.0.0.1回环地址的连接,如果想运行其他主机访问,那么可以将保护模式关闭:protected-mode no
daemonize
默认配置:daemonize no,redis默认不是以守护进程的方式后台运行,如果想后台运行,开启配置:daemonize yes
supervised
默认配置:supervised no,是否Supervised模式运行Redis
pidfile
默认值:pidfile /var/run/redis_6379.pid,如果配置指定了pid 文件,Redis就用该配置的pid文件写入,退出的时候移除对应的pid文件。如果Redis是以非守护进程模式的运行,又没有配置指定的pid文件,那么不会创建pid文件。如果Redis是守护进程的模式,即使没有配置指定的pid文件,会默认使用 /var/run/redis.pid文件
loglevel
默认配置:loglevel notice,指定Server的日志级别,有以下四种级别:
- debug(包含许多具体信息,开发/测试环境下很方便)
- verbose(包含许多不常用的信息,但没有debug级别那么混乱)
- notice(适中的信息,很适合生产环境)
- warning(只记录重要或者非常的信息)
logfile
默认值:logfile “”,指定log文件名。配置成空串的话可以强制Redis在标准输出记录日志。如果使用标准输出进行日志记录且是以守护进程的模式运行,日志会在/dev/null中。
syslog-enabled
默认配置:syslog-enabled no,想让日志记录到系统日志,设置syslog-enabled成yes
syslog-ident
默认配置:syslog-ident redis,指定syslog的身份
syslog-facility
默认配置:syslog-facility local0,指定syslog工具(facility),一定要是USER或者在LOCAL0 - LOCAL7之间
databases
默认配置:databases 16,设置数据库的数量。默认的数据库号是DB 0
always-show-logo
默认配置:always-show-logo yes,Redis会在启动的时候,如果标准输出日志是TTY,则会在开始记录标准输出日志的时候展示一个ASCII字符组成的Redis Logo,也就是说,通常只在交互的会话中会展示该Logo
持久化配置配置
RDB
save
默认配置:save 900 1 300 10 60 10000,rdb保存数据,如果时间秒数seconds和写的次数都配置了,那么一旦达到了配置条件Redis会将DB保存到硬盘
以默认配置举例,达到了以下条件会触发写磁盘:
900秒内(15分钟)且数据库中至少有1个key被改变。
300秒内(5分钟)且数据库中至少有10个key被改变。
60秒内(1分钟)且数据库中只有一个10000个key被改变。
可以通过添加一个带空串的save指令来让配置的save选择失效,比如:save ""
stop-writes-on-bgsave-error
默认配置:stop-writes-on-bgsave-error yes,在开启了RDB快照后,如果最近的一次RDB快照在后台生成失败的话,Redis默认会拒绝所有的写请求。这么做的目的是为了让用户注意到后台持久化可能出现了问题。否则用户可能一直无法注意到问题,进而可能导致灾难级别的事情发生。如果bgsave正常,Redis会自动的继续处理写请求。如果已经为Redis实例和持久化配置了合适的监控手段,且希望Redis在非理想情况下(比如硬盘问题,权限问题等等)仍继续提供服务,可以将此项配置为no
rdbcompression
默认配置:rdbcompression yes,想要在生成rdb文件的时候使用LZF压缩String对象,将该配置保持默认为yes几乎不会出现意外状况,可以将该配置设置为no来节省CPU开销,但是那些原本可以被压缩的key和value会让数据集更大
dbchecksum
默认配置:rdbchecksum yes,从5.0版本开始RDB文件的末尾会默认放置一个CRC64的校验码,这会让文件的格式更加容易检验验证,代价是生成和加载RDB文件的性能会损失10%左右,你可以把该配置关闭以求更佳的性能,没有开启校验码配置的RDB文件会将校验码设置为0,加载该文件的程序就会跳过校验过程
dbfilename
默认配置:dbfilename dump.rdb,配置rdb文件的名称
dir
默认配置:dir ./,工作目录,存储rdb文件的目录,数据库会使用该配置放置rdb文件,文件的名字使用上面的dbfilename指定的文件名,AOF文件的存储位置也会使用这个配置项,但要注意是配置一个目录而不是文件名
AOF
appendonly
Redis默认使用异步方式转储数据到硬盘,但在Redis处理出现问题或者设备断电的意外期间可能丢失相应的写操作(取决于save配置的时间点),AOF文件是Redis提供的另外一种提供更好的持久性的持久化模式,例如如果使用默认的数据传输策略(根据之后提供的配置)Redis在发生意外情况下比如设备断电,或者Redis本身的进程出现了一些问题的情况下(操作系统正常运行),Redis可以仅仅丢失1秒钟的写操作,AOF和RDB的持久化策略可以同时启用,如果打开了AOF,Redis启动时会加载AOF
常见配置:
appendonly yes #开启AOF
appendfilename "appendonly.aof" #AOF 的文件名
appendfsync
默认配置:appendfsync everysec,函数fsync()会告诉操作系统立即把数据写到磁盘上而不是等输出缓冲区有更多的数据时才进行,有些OS会马上把数据刷到硬盘,有些OS只保证尽快进行刷盘操作
Redis 支持三种模式:
- no:不fsync,让操作系统来决定什么时候进行刷盘,最不会影响Server响应
- always:每写入aof文件就进行fsync,影响Server响应,但是数据更安全
- everysec:默认模式,每秒进行fsync,最稳健的形式,在响应速度和数据安全方面最稳妥的选择,选择no,让OS选择写入时机,这样有更好的性能表现,又或者使用always,可以会让响应变慢一些但是数据的安全性会更高,如果不确定选哪种的话,那就用everysec吧
no-appendfsync-on-rewrite
默认配置:no-appendfsync-on-rewrite no,当AOF fsync策略是always或者everysec,会启动一个后台进程(后台进行保存或者AOF文件的后台重写),该进程会在磁盘上频繁的I/O,在一些Linux配置下Redis的fsync() 调用可能会阻塞太久,需要注意的是目前还没有相应的优化策略,极端情况下在不同线程进行的fsync可能阻塞同步的write(2)调用,为了减缓上面提到的问题,可以在主线程调用BGSAVE或者BGREWRITEAOF命名避免fsync()在主线程上调用,这意味着当其他的子节点在保存的时候,Redis的持久化就和appendfsync no策略一样,这意味着在实际中的最糟糕的场景下(在默认的Linux配置下)有可能丢失超过30s时间粒度的log,如果应用不能忍受延迟问题,将选项配置为yes,否则保持为no,这样在持久化的角度上是最安全的选择。
auto-aof-rewtire-percentage、auto-aof-rewrite-min-size
默认配置:auto-aof-rewtire-percentage 100 、 auto-aof-rewrite-min-size 64mb 自动重写aof文件,Redis支持调用BGREWRITEAOF命名,并在AOF文件达到特定的百分比的时候自动重写AOF文件,一般是这么工作的:Redis会记录最近一次重写后的AOF文件大小(如果启动后没有重写过,则记录启动时的AOF文件大小),基础的文件大小和当前的文件大小进行比较,如果当前的大小比配置的百分比大,则触发重写操作。同时也应该配置一个触发重写的最小文件大小,这么做可以避免当AOF文件达到了配置的百分比,但是AOF文件还是很小的情况触发重写操作,配置百分比为0意味着关闭自动重写AOF的特性。
aof-load-truncated
默认值:aof-load-truncated yes,当AOF文件的数据加载到内存的时候,AOF文件可能在Redis启动的时候在末尾被截断,这可能在跑Redis进程的系统崩溃的情况下出现,特别是当一个ext4文件系统挂载的时候没有使用data=ordered选项(但是在Redis进程自己崩溃或者中止,但是操作系统还正常运行时,这种情况就不会发生),当Redis发现AOF在末尾被截断的时候,Redis可以主动退出进程或者尽可能的加载更多的数据(目前的默认行为)并正常启动,如果aof-load-truncated设置成yes,Redis加载被截断的AOF文件,redis启动并将相关的信息写到log中通知用户有这一现象发生。如果设置成no,Redis错误充电并拒绝启动,当该配置设置为no的时候,就要求用户在重启服务前使用redis-check-aof来修复AOF文件。
注意:如果AOF文件的中间位置出现了问题,Redis仍会错误退出。这个配置选项只在Redis想从AOF文件中读取更多数据但是实在没有新的可以读取的情况下才有作用。
aof-use-rdb-preamble
默认配置:aof-use-rdb-preamble yes,当重写AOF文件的时候,Redis也可以在AOF文件在开头应用RDB文件来更快的重写和恢复。当该配置选项开启,AOF文件的重写组成由这两部分组成:[RDB file][AOF tail],Redis加载AOF文件的时候发现AOF文件里由"REDIS"字符串打头,Redis就会加载预先的RDB文件,接着在尾部加载AOF文件。
生产常见配置
安全配置
requirepass
配置格式:requirepass password,要求客户端先使用命令AUTH进行认证,才能处理其他命令
rename-command
配置格式:rename-command CONFIG abcdef,命令重命名,可以在环境中重命名那些比较危险的命令,比如把CONFIG命令重命名成一个不好猜的名字,这样内部的功能还可以使用,且可以避免大部分的客户端使用
客户端配置
maxclients
默认配置:maxclients 10000,设置可以同时连接客户端的最大数量,一旦达到该限制数Redis会拒绝所有的新连接并返回错误信息max number of clients reached
内存管理
maxmemory
配置格式:maxmemory,设置限定的最大内存使用,当内存使用达到限制Redis会根据配置的淘汰策略(见maxmemory-policy)移除键值对,如果根据淘汰策略,Redis不能移除键值对,Redis会拒绝那些申请更大内存的命令,比如SET,LPUSH等等,但是仍可以处理读请求,比如GET等,该选项对那些使用Redis进行LRU,LFU缓存系统或者硬性限制内存很友好(使用noeviction策略),如果为实例配置了maxmemory,且该实例配置了子节点,那么已使用内存的大小就需要加上为副本配置的输出缓冲区的大小。这样因为网络问题/重新同步不会一直触发键的淘汰行为。相反的,副本缓冲区中充满了对键的删除或淘汰的情况可能触发更多key被淘汰,以此类推直到库完全被清空。简单说就是,如果为实例配置了副本,那么建议设置一个较低的maxmemory值,这样系统中就有更多的内存空间留给副本缓冲区(如果淘汰策略是‘noeviction’那上面说的就没有必要)
maxmemory-policy
默认配置:maxmemory-policy noeviction,在内存使用达到maxmemory后,Redis如何选择键值对进行淘汰。有以下几种:
- volatile-lru:使用LRU算法,在设置了过期时间的key中选择
- allkeys-lru:使用LRU算法,在所有的key中选择
- volatile-lfu:使用LFU算法,在设置了过期时间key中选择
- allkeys-lfu:使用LFU算法,在所有的key中选择
- volatile-random:在设置了过期时间的key中随机选择
- allkeys-random:在所有key中随机选择
- volatile-ttl:在设置了过期时间的key中,选择过期时间最近的key
- noeviction:不淘汰key,对任何写操作(使用额外内存)返回错误
LRU 代表最近最少使用
LFU 代码最近最不常使用
LRU,LFU和volatile-ttl均由近似的随机算法实现
不管采用了以上的哪种策略,对于新的写请求,如果没有合适的key可以淘汰,Redis均会响应一个error
[post cid=“625” cover=“https://resource.if010.com/redis_maxmemory_policy_banner.jpg” size=“”/]
maxmemory-samples
默认配置:maxmemory-samples 5,LRU、LFU 以及最小TTL的实现都不是精确的而是比较粗略的近似算法(为了节省内存),为了速度或者精确度,可以进行相应的配置。默认Redis会检查5个key,在其中选择最近最少使用的,也可以直接在下面的配置项中配置 Redis 选择的样本数量,默认配置的值5,已经可以有一个很完美的结果,10的话可能会让选择策略更像真正意义上的LRU算法,但是需要更多CPU资源,3的话会更快,但是不够精确
replica-ignore-maxmemory
默认配置:replica-ignore-maxmemory yes,从Redis 5.0之后,副本默认会忽略为其配置的maxmemory选项(除非因为故障转移(failover)或者选择将其晋升为主节点),也就是说key的淘汰只会由主节点执行,副本对应的是主节点发送对应的删除命令给副本作为key的淘汰方式,这个行为模式保证了主副节点的一致性,但是如果副本是可写的或者你想要你的副本有不同的内存配置,而且你也很确认到达副本的写操作能保证幂等性(idempotenet),那你可以修改这个默认值(但是最好保证你理解了这么做的原因)
提示:因为副本默认没有maxmemory和淘汰策略,副本实际的内存占用可能比maxmemeory配置的值大(可能因为副本缓冲区,或者某些数据结构占用了额外的内存等等原因)。所以确保对副本有合适的监控手段,保证在主节点达到配置的maxmemory设置之前,副本有足够的内存保证不会出现真正的out-of-memory条件
主从配置
replicaof
配置格式:replicaof masterip masterport,主从复制,使用replicaof来让一个Redis实例复制另一个Redis实例,Redis复制是异步进行的,但是可以通过配置让Redis主节点拒绝写请求:配置会给定一个值,主节点至少需要和大于该值的从节点个数成功连接,如果 Redis 从节点和主节点意外断连了很少的一段时间,从节点可以向主节点进行增量复制,复制会自动进行且不需要人为介入
masterauth
配置格式:masterauth master-password,如果主节点配置了密码(使用了"requirepass"配置项),从节点需要进行密码认证才能进行复制同步的过程,否则主节点会直接拒绝从节点的复制请求
replica-serve-stale-data
默认配置:replica-serve-stale-data yes,当复制过程与主节点失去连接,或者当复制正在进行时,复制可以有两种行为模式:
- 如果replica-serve-stale-data设置为’yes’(默认设置),从节点仍可以处理客户端请求,但该从节点的数据很可能和主节点不同步,如果这是与主节点进行的第一次同步,从节点的数据也可能是空数据集
- 如果replica-serve-stale-data设置成’no’,从节点会对除了INFO、replicaOF、AUTH、PING、SHUTDOWN、REPLCONF、ROLE、CONFIG、SUBSCRIBE、UNSUBSCRIBE、PSUBSCRIBE、PUNSUBSCRIBE、PUBLISH、PUBSUB、COMMAND、POST、HOST:and LATENCY这些命令之外的请求均返回"SYNC with master in process"
replica-read-only
默认配置:replica-read-only yes,可以配置从节点是否可以处理写请求。针对从节点开启写权限来存储时效低的(ephemeral)数据可能是一种有效的方式(因为写入到从节点的数据很可能随着重新同步而被删除),但是开启该配置也会导致一些问题。从Redis 2.6开始从节点默认是仅可读的
repl-diskless-sync
默认配置:repl-diskless-sync no,同步复制策略:硬盘或者套接字(不使用硬盘的复制策略目前还在实验阶段)新建立连接和重连的副本不会根据数据情况进行恢复传输,只会进行全量复制,主节点会传输在从节点之间传输RDB文件
传输行为有两种方式:
硬盘备份:Redis主节点创建一个子进程来向硬盘写RDB文件,之后由父进程持续的文件传给副本
不使用硬盘:Redis主节点建立一个进程直接向副本的网络套接字写RDB文件,不涉及到硬盘
对于方式1,在生成RDB文件时,多个副本会进行入队并在当前子进程完成RDB文件时立即为副本进行RDB传输,而对于方式2,一旦传输开始,新来的副本传输请求会入队且只在当前的传输断开后才建立新的传输连接,如果使用方式2,主节点会等待一段时间,根据具体的配置,等待是为了可以在开始传输前可以有期望的副本同步请求到达,这样可以使用并行传输提高效率,对于配置是比较慢的硬盘,而网络很快(带宽大)的情况下,使用方式2进行副本同步会更适合
repl-diskless-sync-delay
默认配置:repl-diskless-sync-delay 5,如果diskless sync是开启的话,就需要配置一个延迟的秒数,这样可以服务更多通过socket传输RDB文件的副本,这个配置很重要,因为一旦传输开始,就不能为新来的副本传输服务,只能入队等待下一次RDB传输,所以该配置一个延迟的值就是为了让更多的副本请求到达,延迟配置的单位是秒,默认是 5 秒,不想要该延迟的话可以配置为 0 秒,传输就会立即开始
repl-ping-replica-period
默认配置:repl-ping-replica-period 10,副本会根据配置好的时间间隔(interval)向主节点发送PING命令,可以通过repl_ping_replica_period配置修改时间间隔,默认为10秒
repl-timeout
默认配置:repl-timeout 60,配置副本进行超时处理,在副本的角度,在同步过程中批量进行I/O传输,从副本s的角度,主节点超时了,从主节点的角度,副本超时了,需要重视的一点是确保该选项的配置比repl-ping-replica-period配置的值更高,否则每次主从之间的网络比较拥挤时就容易被判定为超时
repl-disable-tcp-nodelay
默认配置:repl-disable-tcp-nodelay no,同步过后在副本套接字上关闭TCP_NODELAY,如果选择了’yes’,Redis会使用很小的TCP包,占用很低的带宽来想副本发送数据,但是这么做到达副本的数据会有一些延迟,使用默认的配置值且是Linux内核该延迟最多可能40毫秒,如果选择’no’,副本的数据延迟会更低但是占用的带宽会更多一些,默认会为了低延迟进行优化,但是在比较拥挤网络情况下或者是主节点和副本之间的网络情况比较复杂,比如中间有很多路由跳转的情况下,把选项设置为’yes’应该会比较适合
repl-backlog-size
默认配置:repl-backlog-size 1mb,配置副本的缓冲区(backlog)大小,该缓冲区用来在副本断开连接后暂存副本数据,这样做是因为副本重新连接后,不一定要重新进行全量复制,很多时候增量复制同步(仅同步断连期间副本可能丢失的数据)完全足够了,配置的缓冲区越大,副本可以承受的断连时间可以更长,至少有一个副本连接时缓冲区才会进行分配
repl-backlog-ttl
默认配置:repl-backlog-ttl 3600,主节点如果一段时间没有副本连接,上面提到的缓冲区会被释放,可以通过配置一个指定的时间来释放缓冲区,如果主节点在这个时间内还没有与新的副本建立连接,需要注意的是副本不会因为超时释放缓冲区,因为副本可能会被晋升(promot)为主节点,需要保持对其他副本进行增量复制的能力:因此他们总是积累缓冲区,配置为’0’意味着不释放缓冲区
replica-priority
默认配置:replica-priority 100,副本的优先级是一个整型数字,可以由Redis的INFO命令显示,优先级的作用在于当主节点无法提供服务后,Redis哨兵会使用到优先级进行选举副本,晋升为主节点,值越低,代表该副本晋升成为主节点的优先级越高,比如说有三个副本,优先级的值分别为10、100、25,Redis哨兵会选择最低的那个,即优先级配置为10的那个,但是,一个特殊的配置值’0’,意味着该副本不可能充当主节点的角色,故优先级配置为0的副本永远不会被Redis哨兵选择晋升。默认的优先级配置是100
min-replicas-to-write 、 min-replicas-max-lag
主节点可以根据目前连接的延迟慢于M秒的副本数量,选择是否拒绝写请求,数量N的副本需要是"online"的状态,延迟的秒数(The lag(落后) in seconds)M,计算方式是根据上一次副本发送ping命令到主节点的时间计算,通常每秒都会发送ping命令,这个选项不保证N个副本会接受写请求,但是如果没有足够的副本可用,则会限制那些丢失写请求的暴露窗口至特定的秒数,比如要求至少有三个延迟小等于10秒的副本,可以这么配置:
# 配置设置为 0 会关闭该功能。
# 默认的 min-replicas-to-write 被设置为 0(功能关闭)
# min-replicas-max-lag 设置为 10.
min-replicas-to-write 3
min-replicas-max-lag 10
replica-announce-ip 、 replica-announce-port
主节点应该有多种方式来列举出依附与它的副本的信息(ip和port),比如"INFO replication"就可以提供这些信息,它也会被其他的功能使用,比如Redis哨兵就会使用该命令列举副本实例,还有一种方式是在主节点运行"ROLE"命令来获取这些信息
副本获取监听的IP和地址分别通过以下的方式:
- IP:IP地址在副本和主节点建立的socket连接中自动被检测到
- Port:端口信息会在副本进行复制的TCP握手中交流传递,端口也是副本用来监听连接的一部分
如果使用了端口转发或者NAT(Network Address Translation),实际连接到副本很可能通过的是不同的IP和端口对。下面的两个配置选项用来让副本上报特定的IP和端口集合给它连接的主节点,之后主节点使用"INFO"或者"ROLE"命令都可以输出这些上报的值
# 如果只想上报ip或端口其中一个,就没有必要两个都使用
replica-announce-ip 1.1.1.1
replica-announce-port 6379
集群配置
cluster-enabled
默认配置:cluster-enabled yes,是否打开集群模式
cluster-config-file
默认配置:cluster-config-file nodes-6379.conf,设定节点配置文件名
cluster-node-timeout
默认配置:cluster-node-timeout 15000,设定节点失联时间,超过该时间(毫秒),集群自动进行主从切换
cluster-require-full-coverage
默认配置:cluster-require-full-coverage yes,如果某一段插槽的主从都挂掉,而cluster-require-full-coverage为yes,那么 ,整个集群都挂掉,反之,cluster-require-full-coverage配置为no,那么,该插槽数据全都不能使用,也无法存储
其他配置
CLUSTER DOCKER/NAT support
在某些部署情况中,Redis集群节点可能会出现地址发现失败,原因是地址是NAT-ted或者端口转发(一个典型的场景就是 Docker 或者其他容器),为了让 Redis 集群在这种环境下正常工作,就需要个静态的配置文件来让集群节点知晓他们的公共地址,下面选项就有这个作用:
cluster-announce-ip
cluster-announce-port
cluster-announce-bus-port
SLOW LOG(慢日志)
默认配置:slowlog-log-slower-than 10000 、slowlog-max-len 128,Redis的慢日志用来记录那些执行了超过特定时间的查询行为。这里的执行时间不包括I/O操作,比如和客户端的通信,发送回复的时间等等,而应该只是执行了这个命令本身需要的时间(就是说执行这个命令期间,线程会阻塞且不会同时响应其他的请求),慢日志有两个属性可以配置:一个用来告诉Redis执行时间的定义,什么样的执行时间才要被记录,另一个用来配置慢日志的长度,记录一个新的命令,队列中的最旧的命令会被移除,要注意的是配置的时间单位为微秒,所以1000000相当于1秒,如果配置的是负值,慢日志则不起作用,如果是0的话,慢日志则会记录每个命令,长度的配置没有任何限制,但是主要内存的消耗,可以使用慢日志的SLOWLOG RESET来回收内存
LATENCY MONITOR(延迟监控)
默认配置:latency-monitor-threshold 0,Redis的延迟监控系统会在Redis运行期间以不同的操作对象为样本,收集和Redis实例相关的延迟行为,用户可以通过LETENCY命令,打印相关的图形信息和获取相关的报告,延迟监控系统只会收集那些执行时间超过了我们通过latency-monitor-threshold配置的值的操作,当latency-monitor-threshold的值设置为0的时候,延迟监控系统就会关闭,默认情况下延迟监控是关闭的,因为大多数情况下可能没有延迟相关的问题,而且收集数据对性能表现是有影响的,虽然影响很小,但是在系统高负载运行情况下还是不能忽视的,延迟监控系统可以在运行期间使用CONFIG SET latency-monitor-threshold milliseconds开启
LAZY FREEING(懒释放)
Redis有两个可以删除key的原语(primitive),其中一种是调用DEL,阻塞地删除对象。也就是说Redis Server需要通过同步的方式确认回收了所有和刚才删除的key相关的内存后,才能处理接下来的命令。如果要删除的key很小,执行DEL命令的时间也很短,和其他时间复杂度为O(1)或O(log_N)的命令差不多。但是,如果要删除的key涉及到一个存储着百万级别元素的集合,Redis Server就可能因此阻塞一段时间(甚至到秒的级别)
由于同步的处理方式可能带来的问题,Redis提供了非阻塞的删除原语比如UNLINK以及异步的选项比如FLUSHALL和FLUSHDB命名,为的就是在后台回收内存,这些命名会在固定时间执行(in constant time),另外的线程会在后台以尽可能快的速度释放这些对象
DEL、UNLINK和带有ASYNC选项的FLUSHALL和FLUSHDB命名都可以由用户控制,这取决于应用层面是否理解且合适的使用相应的命令来达到目的,但是还是有一些情况要注意,Redis有时会因为其他操作的副作用导致触发key 的删除或者刷新整个数据库,特别是在用户调用了对象删除的以下场景:
- 在淘汰策略下,因为配置了maxmemory和maxmemory policy,为了在不超过配置的内存限制下腾出空间给新来的数据
- 因为过期时间的配置,当一个key配置了expire时间且时间到了,那它必须从内存中移除。命名在已经存在的key上进行数据的存储操作的副作用。比如RENAME命名在替换的时候需要删除原本的key的内容。类似的带有STORE选项的SUNIONSTORE或者SORT命名可能会删除已存在的key。SET命令本身为了用新的值替换,会将要操作的key的旧值先删除掉。在REPLICATION期间,当副本执行了全量同步复制,副本的整个数据库会被清空,然后加载传输来的RDB文件。
上面的场景在默认情况下都是以阻塞的方式删除对象,比如调用DEL的时候。你在本配置项中为每个场景进行配置,这样就可以像 UNLINK 被调用时以非阻塞的方式释放内存
lazyfree-lazy-eviction no
lazyfree-lazy-expire no
lazyfree-lazy-server-del no
lazyfree-lazy-flush no
附录:关于哨兵的常规命令
常用命令
PING
返回 PONG。
SENTINEL masters
列出所有被监视的主服务器,以及这些主服务器的当前状态。
SENTINEL slaves
列出给定主服务器的所有从服务器,以及这些从服务器的当前状态。
SENTINEL get-master-addr-by-name
返回给定名字的主服务器的 IP 地址和端口号。 如果这个主服务器正在执行故障转移操作, 或者针对这个主服务器的故障转移操作已经完成, 那么这个命令返回新的主服务器的 IP 地址和端口号。
SENTINEL reset
重置所有名字和给定模式 pattern 相匹配的主服务器。 pattern 参数是一个 Glob 风格的模式。 重置操作清除主服务器目前的所有状态, 包括正在执行中的故障转移, 并移除目前已经发现和关联的, 主服务器的所有从服务器和 Sentinel 。
SENTINEL failover
当主服务器失效时, 在不询问其他 Sentinel 意见的情况下, 强制开始一次自动故障迁移 (不过发起故障转移的 Sentinel 会向其他 Sentinel 发送一个新的配置,其他 Sentinel 会根据这个配置进行相应的更新)。
ACL(>=6.2)
此命令管理Sentinel访问控制列表。有关更多信息,请参阅ACL文档页面和Sentinel访问控制列表验证。
AUTH(>=5.0.1)
对客户端连接进行身份验证。有关更多信息,请参阅AUTH命令和配置带有身份验证的Sentinel实例部分。
CLIENT
此命令管理客户端连接。有关详细信息,请参阅其子命令页面。
COMMAND(>=6.2)
此命令返回有关命令的信息。有关详细信息,请参阅COMMAND命令及其各种子命令。
HELLO(>=6)
切换连接的协议。有关详细信息,请参阅HELLO命令。
INFO
返回有关Sentinel服务器的信息和统计信息。有关更多信息,请参阅INFO命令。
ROLE
此命令返回字符串“sentinel”和受监控主机的列表。
SHUTDOWN
关闭Sentinel实例。
其他命令
SENTINEL CONFIG GET<name>(>=6.2)
获取全局SENTINEL配置参数的当前值。指定的名称可以是通配符,类似于Redis CONFIG GET命令。
SENTINEL CONFIG SET<name><value>(>=6.2)
设置全局SENTINEL配置参数的值。
SENTINEL CKQUORUM<master name>
检查当前SENTINEL配置是否能够达到故障转移主机所需的仲裁,以及授权故障转移所需的多数仲裁。该命令应在监控系统中使用,以检查Sentinel部署是否正常。
SENTINEL FLUSHCONFIG
强制SENTINEL在磁盘上重写其配置,包括当前的SENTINEL状态。通常情况下,每当状态发生变化时,Sentinel都会重写配置(在重新启动时保留在磁盘上的状态子集的上下文中)。但是,有时配置文件可能会因为操作错误、磁盘故障、包升级脚本或配置管理器而丢失。在这些情况下,强制Sentinel重写配置文件的方法很方便。即使以前的配置文件完全丢失,此命令也能工作。
SENTINEL FAILOVER<master name>
强制进行故障切换,就好像无法访问主机一样,并且不要求与其他SENTINEL达成一致(但是,将发布新版本的配置,以便其他Sentinels更新其配置)。
1.不会与其他Sentinel进行协商;
2.转移完成后会通知其他Sentinel节点(根据转移结果进行更新);
SENTINEL GET-MASTER-ADDR-BY-NAME<MASTER NAME>
返回具有该名称的主机的ip和端口号。如果此主机的故障转移正在进行或已成功终止,它将返回升级的复制副本的地址和端口。
SENTINEL INFO-CACHE(>=3.2)
从主控和副本返回缓存的INFO输出。
SENTINEL IS-MASTER-DOWN-BY-ADDR
检查ip:port指定的主机是否从当前SENTINEL的角度关闭。此命令主要用于内部使用。
- 为*时,Sentinel节点直接交换对主节点下线的判断;
- 为运行ID时,Sentinel节点希望其他Sentinel节点投票自己成为领导者Sentinel(运行ID为Sentinel的运行ID)
- 返回值由以下3个参数构成:
返回参数说明
down_state 0:代表Redis主节点仍在线 ;1:代表Redis主节点已下线
leader_runid *:不同意做为领导者运行;Sentinel ID:该运行ID代表的Sentinel同意
leader_epoch 领导者
SENTINEL MASTER<MASTER name>
显示指定主机的状态和信息。
SENTINEL MASTERS
显示受监控主机及其状态的列表。
SENTINEL MONITOR
启动SENTINEL的监控。
SENTINEL MYID(>=6.2)
返回SENTINEL实例的ID。
SENTINEL PENDING-SCRIPTS
此命令返回有关挂起脚本的信息。
SENTINEL REMOVE
停止哨兵的监控。
SENTINEL REPLICAS<master name>(>=5.0)
显示此master的副本列表及其状态。老版本可以用SENTINEL SENTINELS <master name>
SENTINEL SENTINELS<master name>
显示此master的SENTINEL实例及其状态的列表。
SENTINEL SET
设置SENTINEL的监控配置。
SENTINEL SIMULATE-FAILURE(选举后崩溃|晋升后崩溃|帮助)(>=3.2)
此命令模拟不同的SENTINEL崩溃场景。
SENTINEL RESET<pattern>
此命令将重置具有匹配名称的所有主机。模式参数是glob样式的模式。重置过程会清除主机中以前的任何状态(包括正在进行的故障转移),并删除已发现并与主机关联的每个复制副本和哨兵。