一、说明
这是一个系列文章的第三篇文章, 文章前半部分分别是:
1 、NLP 的文本预处理技术
2、NLP文本预处理技术:词干提取和词形还原
在本文中,我们将介绍标记化主题。在开始之前,我建议您阅读我之前介绍的关于文本预处理的 2 篇文章。
二、什么是记号化Tokenization?
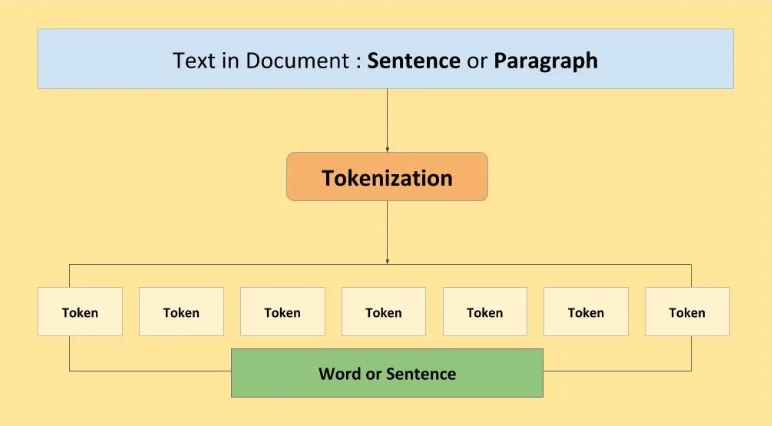
在处理文本数据时,标记化是最常见的任务之一。它是将句子或文本分解为单个单词或子单词(称为标记)的过程。
每个标记(单词、短语或符号)代表一个有意义的单元,它在理解文本的结构和含义方面起着至关重要的作用。
2.1 为什么记号化对 NLP 至关重要?
让我们讨论一下在通过文本分析分析社交媒体评论时标记化的重要性。
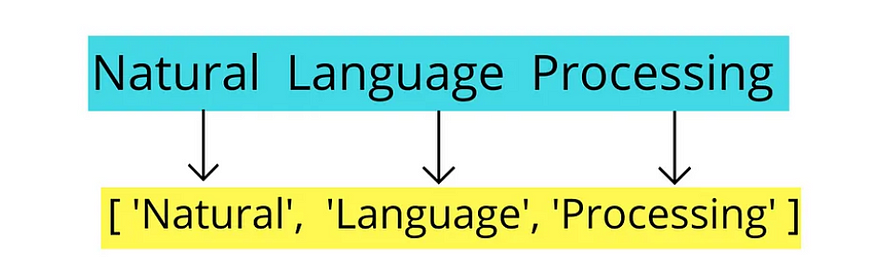
想象一下,一家公司想要监控社交媒体平台上发布的有关其产品和服务的评论。这些评论包含有关客户满意度、产品质量和潜在问题的宝贵信息。然而,这些评论通常写得很复杂、冗长,有时还会出现语言错误。
以下是令牌化在此方案中发挥关键作用的方式:
理解文本: 社交媒体评论通常冗长而复杂。标记化有助于将这些注释分解为单词和句子,有助于理解每个单词或符号的含义。例如,“我非常满意!”这句话可以被标记成两个单独的标记:“我是”和“非常满意”。
情绪分析: 公司旨在了解客户满意度。标记化可以帮助识别正面或负面表达。例如,短语“我有一个很棒的经历”表示一种积极的情绪,因为存在“很棒”这个词。
词频:标记化可用于计算特定单词的频率。通过了解哪些词最常使用,公司可以确定与其产品或服务相关的关键主题。
文本分类:将评论分类为特定类别或情绪至关重要。例如,公司可能希望单独分析与特定产品相关的评论。标记化有助于将评论分类为这些类别。
总之,标记化是 NLP 的基本步骤,它对于从复杂的文本数据(如社交媒体评论)中理解和提取有价值的见解至关重要。它使公司能够根据客户反馈和情绪进行分析并做出明智的决策。这个例子说明了标记化在现实生活中的 NLP 应用程序中如何有效地处理、理解和分析文本数据。
现在我们知道了什么是标记化,让我们看看一些标记化技术。
2.2 NLP中的标记化是如何工作的?
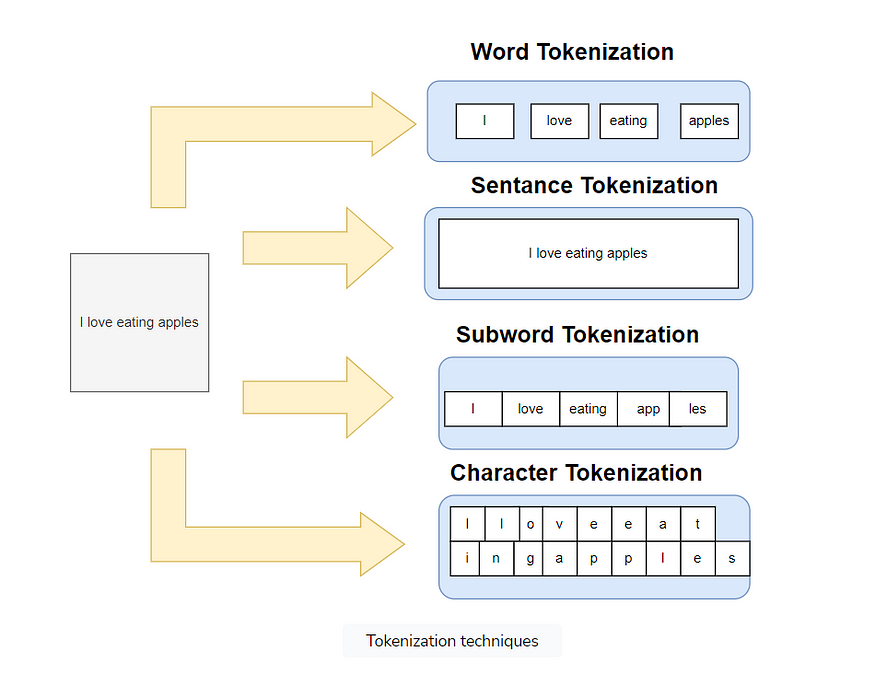
有不同的方法和库可用于执行标记化。 NLTK、Gensim 和 Keras 是可用于完成该任务的一些库。 标记化可用于分隔单词或句子。如果使用某种分离技术将文本拆分为单词,则称为单词标记化,对句子进行相同的分离称为句子标记化。
Word Tokenization
import nltk
from nltk.tokenize import word_tokenizetext = "In this article, we are learning word tokenization using NLTK."tokens = word_tokenize(text)
print(tokens)Output:
['In', 'this', 'article', ',', 'we', 'are', 'learning', 'word', 'tokenization', 'using', 'NLTK', '.']三、句子标记化
首先,安装 NLTK 库并下载 Punkt tokenizer 模型(如果尚未下载)。
pip install nltk
nltk.download('punkt')安装完成后,我们继续使用句子标记化代码。
import nltk
from nltk.tokenize import sent_tokenizetext = "Hello! Sentence tokenization is essential for breaking down a text intoits constituent sentences, which is a fundamental step in natural languageprocessing. It allows you to work with sentences individually, making it easier to perform tasks like sentiment analysis, text summarization,and machine translation. NLTK provides a simple way to achieve sentence tokenization in Python."sentences = sent_tokenize(text)for sentence in sentences:print(sentence)Output:
Hello!
Sentence tokenization is essential for breaking down a text into its constituent sentences, which is a fundamental step in natural language processing.
It allows you to work with sentences individually, making it easier to perform tasks like sentiment analysis, text summarization, and machine translation.
NLTK provides a simple way to achieve sentence tokenization in Python.四、字符标记化
text = "Hello World!"characters = list(text)print("Characters:", characters)Output:
Characters: ['H', 'e', 'l', 'l', 'o', ' ', 'W', 'o', 'r', 'l', 'd', '!']您还可以使用 spaCy、Keras 和 Gensim 执行这些操作。当我将其添加到 Github 时,我将在此处添加链接。
我将在另一篇文章中更详细地介绍“N-gram 标记化”的主题。
五、结论
通过本文,我们了解了 NLTK 的不同分词器。
总之,标记化是许多 NLP 任务中的关键预处理步骤。它是 NLP 的基础,因为它将原始文本数据转换为可以由 NLP 模型和算法有效处理和分析的格式。它是各种 NLP 任务的构建块,能够从文本数据中提取有意义的信息和模式。
艾塞尔·艾丁









![移动路由器Cellular Router命令执行漏洞复现 [附POC]](https://img-blog.csdnimg.cn/67e6655d0ece448aa7d362fcbcf4a8fc.png)